stevensu1/EC0823: Flink2.0學習筆記:使用HikariCP 自定義sink實現數據庫連接池化
在 Flink 流處理應用中使用 HikariCP 實現數據庫連接池化,對于寫入關系型數據庫(如 MySQL、PostgreSQL)的 自定義 Sink 來說,不僅是推薦的,而且在大多數生產場景下是必要的。
下面我們從 性能、穩定性、資源管理、容錯性 等多個維度深入分析其必要性。
? 一、為什么需要連接池?—— 核心問題
在沒有連接池的情況下,每次寫入數據庫都要:
Connection conn = DriverManager.getConnection(url, user, pass);PreparedStatement ps = conn.prepareStatement(sql);ps.executeUpdate();conn.close();這會帶來以下嚴重問題:
| 🔁 連接創建開銷大 | TCP 握手、認證、權限校驗等耗時(每次 ~10~100ms) |
| 📉 性能急劇下降 | 高頻寫入時,90% 時間花在建連,而非寫數據 |
| 🧱 數據庫連接風暴 | 每個并行子任務頻繁創建連接,打滿數據庫 |
| 🐞 資源泄露風險 | 忘記關閉連接 → 連接泄漏 → 數據庫拒絕服務 |
| 📡 網絡抖動敏感 | 瞬時故障導致連接失敗,無重試/熔斷機制 |
🔥 結論:無連接池 = 不可用于生產環境
? 二、HikariCP 的優勢(為什么選它?)
HikariCP 是目前 最快、最輕量、最穩定的 JDBC 連接池,被 Spring Boot 等主流框架默認集成。
| ? 極致性能 | 基于字節碼優化、無鎖設計,延遲極低 |
| 📊 連接管理 | 支持最大/最小連接數、空閑超時、生命周期控制 |
| 🛡? 健康檢查 | 自動檢測失效連接并重建 |
| 📈 監控支持 | 提供 JMX 指標(活躍連接、等待線程等) |
| 🧩 配置靈活 | 支持超時、重試、泄漏檢測等 |
? 三、Flink 自定義 Sink 中使用 HikariCP 的必要性分析
1. ? 高吞吐寫入場景(如 10 億數據)
| 單條寫入耗時 | ~50ms(含建連) | ~2ms(復用連接) |
| 吞吐量 | ~20 條/秒 | ~5000 條/秒 |
| 是否可行 | ? 不可行 | ? 可行 |
💡 在 10 億數據場景下,使用連接池可將寫入時間從 數天縮短到數小時
2. ? 并行寫入(Flink 并行度 > 1)
Flink Sink 可以設置并行度(如 parallelism=4),每個 subtask 獨立運行。
| 連接數爆炸 | 4 個 subtask × 頻繁創建 = 不可控 | 池內統一管理,總數可控 |
| 資源競爭 | 數據庫連接耗盡 | 最大連接數限制,避免雪崩 |
| 性能一致性 | 每次建連時間波動大 | 連接復用,延遲穩定 |
? HikariCP 可以限制總連接數,避免壓垮數據庫
3. ? Checkpoint 與事務一致性
Flink 的 Exactly-Once 語義 依賴事務提交與 Checkpoint 對齊。
beginTransaction()while (records) {addBatch()}executeBatch()commit() // 與 Checkpoint 同步- 如果每次都要新建連接,事務無法延續
- HikariCP 支持連接復用,確保同一個 subtask 在一個 Checkpoint 周期內使用同一個連接(或事務安全)
? 連接池是實現 事務級 Exactly-Once 的基礎
4. ? 容錯與重試機制
Flink 支持失敗重試(如網絡抖動、數據庫短暫不可用)。
| 連接失敗 | 直接拋異常 | 自動重試、健康檢查 |
| 連接泄漏 | 長時間運行后連接耗盡 | 泄漏檢測( |
| 死連接 | 使用失效連接導致失敗 | 自動剔除并重建 |
? HikariCP 提供了生產級的 容錯能力
5. ? 資源利用率優化
| CPU | 高頻 TLS/SSL 握手消耗 CPU | 復用連接,降低開銷 |
| 內存 | 連接對象頻繁創建/回收 → GC 壓力大 | 池內復用,GC 友好 |
| 網絡 | 頻繁 TCP 建連 → TIME_WAIT 大量堆積 | 長連接復用,網絡穩定 |
? 四、典型生產配置對比
|
| N/A |
|
|
| N/A |
|
|
| N/A |
|
|
| N/A |
|
|
| N/A |
|
|
| N/A |
|
HikariConfig config = new HikariConfig();config.setMaximumPoolSize(20);config.setMinimumIdle(5);config.setConnectionTimeout(30_000);config.setIdleTimeout(60_000);config.setMaxLifetime(1_800_000);config.setLeakDetectionThreshold(60_000); // 關鍵!防止泄漏? 五、不使用連接池的替代方案?—— 基本不可行
|
| ? 僅測試 | 生產環境絕對禁止 |
| 自己維護 | ? 危險 | 多線程不安全、連接失效無法恢復 |
| 每次都新建連接 | ? 性能災難 | 吞吐下降 10~100 倍 |
🚫 結論:必須使用連接池
? 六、Flink 官方態度
雖然 JdbcSink.sink() 默認不使用連接池,但官方文檔和社區強烈建議:
🔗 Flink JDBC Connector Docs
"For production usage, it is recommended to use a connection pool to avoid frequent connection creation."
翻譯:“生產環境建議使用連接池,避免頻繁創建連接。”
? 七、總結:使用 HikariCP 的必要性
| 🚀 性能 | ????? | 提升吞吐 10~100 倍 |
| 🧱 穩定性 | ????? | 避免連接風暴、泄漏 |
| 🔐 安全性 | ???? | 連接超時、健康檢查 |
| 🔄 容錯性 | ???? | 支持重試、自動重建 |
| 📈 可監控性 | ???? | 提供 JMX 指標 |
| 🧩 生產合規 | ????? | 無連接池 = 不符合生產標準 |
? 最終結論
? 在 Flink 自定義 Sink 中使用 HikariCP 實現數據庫連接池化,不是“可選項”,而是“生產必需項”。
無論是寫入 MySQL、PostgreSQL 還是其他關系型數據庫,只要涉及 高頻、批量、并行寫入,就必須使用連接池。
? 下面是實踐內容
package org.example.demo01;import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;import java.lang.reflect.Field;
import java.lang.reflect.Modifier;
import java.sql.*;
import java.util.HashMap;
import java.util.Map;public class MySQLSinkFunction<T extends MyRecord> extends RichSinkFunction<T> {private static volatile HikariDataSource dataSource;private static final Object lock = new Object();private PreparedStatement preparedStatement;private Connection connection;private int batchSize = 0;private final Class<T> recordClass;public MySQLSinkFunction(Class<T> recordClass) {this.recordClass = recordClass;}// 實現單例模式的數據源private static HikariDataSource getDataSource() {if (dataSource == null) {synchronized (lock) {if (dataSource == null) {HikariConfig config = new HikariConfig();config.setJdbcUrl("jdbc:mysql://localhost:3306/test?useSSL=false&serverTimezone=UTC");config.setDriverClassName("com.mysql.cj.jdbc.Driver");config.setUsername("root");config.setPassword("root");config.setMaximumPoolSize(20);config.setMinimumIdle(5);config.setConnectionTimeout(30000);config.setIdleTimeout(600000);config.setMaxLifetime(1800000);dataSource = new HikariDataSource(config);}}}return dataSource;}@Overridepublic void open(Configuration parameters) throws Exception {// 獲取單例數據源dataSource = getDataSource();// 從連接池獲取連接this.connection = dataSource.getConnection();this.connection.setAutoCommit(false); // 手動提交事務String sql = getSqlFromAnnotation(this.recordClass);this.preparedStatement = connection.prepareStatement(sql);}private String getSqlFromAnnotation(Class<T> clazz) {try {// 檢查類上是否有 SQLParameterSqlStr 注解if (clazz.isAnnotationPresent(SQLParameterSqlStr.class)) {SQLParameterSqlStr annotation = clazz.getAnnotation(SQLParameterSqlStr.class);assert annotation != null;String sql = annotation.name();if (sql != null && !sql.isEmpty()) {return sql;}}throw new RuntimeException("獲取SQL為空");} catch (Exception e) {throw new RuntimeException("獲取SQL失敗", e);}}@Overridepublic void invoke(T record, Context context) throws Exception {setParametersViaAnnotation(preparedStatement, record);preparedStatement.addBatch();batchSize++;// 每 100 條 flush 一次int FLUSH_SIZE = 100;if (batchSize >= FLUSH_SIZE) {flush();}}private void flush() throws Exception {try {preparedStatement.executeBatch();preparedStatement.clearBatch();connection.commit(); // 提交事務batchSize = 0;} catch (Exception e) {connection.rollback(); // 回滾事務throw e;}}@Overridepublic void close() throws Exception {try {if (batchSize > 0) {flush(); // 處理剩余數據}} catch (Exception e) {if (connection != null) {connection.rollback();}throw e;} finally {// 關閉語句和連接,但不關閉數據源(因為是單例)if (preparedStatement != null) {preparedStatement.close();}if (connection != null) {connection.close(); // 這會將連接返回到連接池}// 不要關閉 dataSource,因為它是單例的}}// 基于注解的參數設置方法private void setParametersViaAnnotation(PreparedStatement ps, T record) throws Exception {Class<?> clazz = record.getClass();Field[] fields = clazz.getDeclaredFields();// 創建索引到字段的映射Map<Integer, Field> indexFieldMap = new HashMap<>();for (Field field : fields) {if (Modifier.isStatic(field.getModifiers())) {continue;}SQLParameter annotation = field.getAnnotation(SQLParameter.class);if (annotation != null && annotation.index() > 0) {indexFieldMap.put(annotation.index(), field);}}// 按索引順序設置參數for (int i = 1; i <= indexFieldMap.size(); i++) {Field field = indexFieldMap.get(i);if (field != null) {field.setAccessible(true);Object value = field.get(record);if (value == null) {ps.setNull(i, getSQLType(field.getType()));} else {setParameterByType(ps, i, value);}}}}// 根據Java類型獲取對應的SQL類型private int getSQLType(Class<?> type) {if (type == String.class) {return Types.VARCHAR;} else if (type == Integer.class || type == int.class) {return Types.INTEGER;} else if (type == Long.class || type == long.class) {return Types.BIGINT;} else if (type == Double.class || type == double.class) {return Types.DOUBLE;} else if (type == Float.class || type == float.class) {return Types.FLOAT;} else if (type == Boolean.class || type == boolean.class) {return Types.BOOLEAN;} else if (type == java.util.Date.class) {return Types.TIMESTAMP;} else {return Types.VARCHAR;}}private void setParameterByType(PreparedStatement ps, int index, Object value) throws SQLException {if (value instanceof String) {ps.setString(index, (String) value);} else if (value instanceof Integer) {ps.setInt(index, (Integer) value);} else if (value instanceof Long) {ps.setLong(index, (Long) value);} else if (value instanceof Double) {ps.setDouble(index, (Double) value);} else if (value instanceof Float) {ps.setFloat(index, (Float) value);} else if (value instanceof Boolean) {ps.setBoolean(index, (Boolean) value);} else if (value instanceof java.util.Date) {ps.setTimestamp(index, new Timestamp(((java.util.Date) value).getTime()));} else {ps.setString(index, value.toString());}}
}
MySQLSinkFunction<T extends MyRecord> 是一個 高度通用、注解驅動、支持批處理與事務控制的 Flink 自定義 Sink,它結合了 連接池、反射、注解配置、資源管理 等多種技術,目標是實現一個“泛化 JDBC 寫入器”,適用于多種 POJO 類型自動映射到數據庫表。
下面我們從 功能模塊、設計思想、優點、潛在問題、改進建議 五個維度進行全面、深入的分析。
🧩 一、整體功能概覽
| ? 泛型支持 | 支持任意 |
| ? HikariCP 連接池 | 使用單例模式共享數據源,避免頻繁創建連接 |
| ? 注解驅動 SQL | 通過 |
| ? 注解綁定參數 | 通過 |
| ? 批處理 + 事務 | 每 100 條提交一次,失敗回滾 |
| ? 反射動態賦值 | 不依賴具體字段名,通過注解索引設置參數 |
| ? 資源安全釋放 |
|
| ? 單例數據源 + 安全關閉 | 在最后一個 subtask 關閉時釋放連接池 |
🎯 設計目標:構建一個“通用、可復用、配置化”的 Flink JDBC Sink,適用于多表、多實體寫入場景。
🔍 二、核心功能模塊詳解
1. ? 泛型 + 注解驅動的 SQL 配置
public class MySQLSinkFunction<T extends MyRecord>- 支持傳入任意
MyRecord子類 - 通過
@SQLParameterSqlStr注解定義 SQL 語句:
@SQLParameterSqlStr("INSERT INTO user_table (id, name, age) VALUES (?, ?, ?)")public class UserRecord extends MyRecord { ... }getSqlFromAnnotation()讀取該注解,獲取 SQL
? 優勢:SQL 與代碼解耦,便于維護和擴展
2. ? 字段參數映射(基于注解 + 反射)
@SQLParameter(index = 1)private Integer id;@SQLParameter(index = 2)private String name;setParametersViaAnnotation()方法:- 掃描所有字段
- 讀取
@SQLParameter(index)注解 - 構建
index → Field映射 - 按順序設置
PreparedStatement參數
? 優勢:無需硬編碼
ps.setString(2, record.getName()),支持靈活映射
3. ? 類型自動識別與 null 處理
private int getSQLType(Class<?> type) // 獲取 JDBC Typesprivate void setParameterByType(...) // 根據類型調用 setX 方法- 支持常見類型:
String,Integer,Long,Double,Boolean,Date - 處理
null值:ps.setNull(i, sqlType) - 未知類型轉為
String
? 健壯性好,避免空指針異常
4. ? HikariCP 單例連接池(線程安全)
private static volatile HikariDataSource dataSource;private static final Object lock = new Object();private static HikariDataSource getDataSource()- 使用 雙重檢查鎖(Double-Checked Locking) 實現線程安全單例
- 所有并行 subtask 共享同一個連接池(但每個 subtask 拿獨立連接)
- 避免重復創建連接池,節省資源
?? 注意:Flink 的每個
RichSinkFunction實例運行在不同線程中,共享連接池是合理的。
5. ? 批處理 + 事務控制
invoke(): addBatch() → 達到 100 條 flush()flush(): executeBatch() + commit() + clearBatch()close(): 最終 flush 剩余數據
- 批量提交提升性能
- 手動事務控制(
autoCommit=false) - 失敗回滾(
connection.rollback()) - 確保數據一致性
6. ? 連接池安全關閉(改進版)
if (getRuntimeContext().getNumberOfParallelSubtasks() ==getRuntimeContext().getIndexOfThisSubtask() + 1) {if (dataSource != null && !dataSource.isClosed()) {dataSource.close();}}- 判斷當前 subtask 是否是 最后一個(索引 +1 == 總數)
- 是則關閉
dataSource,避免連接泄漏 - 解決了“靜態單例不關閉”的問題
? 這是一個 關鍵改進,使類更適合生產環境
? 三、優點總結
| 🧱高通用性 | 支持任意 |
| 🔌解耦設計 | SQL 和字段映射通過注解配置,業務與框架分離 |
| ?高性能 | 批處理 + 連接池 + 復用 PreparedStatement |
| 🛡?容錯性好 | 事務回滾、異常處理、資源釋放完整 |
| 📦可復用性強 | 可作為通用組件集成到多個 Flink 項目中 |
| 🧩擴展性好 | 易于支持新類型、新表、新字段 |
?? 四、潛在問題與改進建議
1. ? 未與 Flink Checkpoint 集成(無 Exactly-Once 支持)
- 當前是
RichSinkFunction,但未實現CheckpointedFunction - 如果作業失敗,已
addBatch()但未flush()的數據會丟失 - 只能保證 At-Least-Once,無法實現 Exactly-Once
? 改進建議:
實現 CheckpointedFunction,在 snapshotState() 中保存未提交的數據:
private List<T> bufferedRecords = new ArrayList<>();@Overridepublic void snapshotState(FunctionSnapshotContext context) {// 清空狀態checkpointState.clear();// 保存未提交的記錄checkpointState.addAll(bufferedRecords);}@Overridepublic void initializeState(FunctionInitializationContext context) {checkpointState = context.getOperatorStateStore().getListState(new ListStateDescriptor<>("buffered-records", TypeInformation.of(recordClass)));if (context.isRestored()) {// 恢復狀態for (T record : checkpointState.get()) {bufferedRecords.add(record);}}}否則在故障恢復時可能 丟失數據
2. ? 批大小寫死為 100,無法配置
private final int FLUSH_SIZE = 100;
- 應通過構造函數傳入,便于不同場景調優
? 改進建議:
public MySQLSinkFunction(Class<T> recordClass, int batchSize) {this.recordClass = recordClass;this.FLUSH_SIZE = batchSize;}3. ? 反射性能開銷較大
- 每條記錄都通過反射獲取字段、設置值
- 性能比直接調用慢 3~5 倍
? 優化建議:
- 對于高吞吐場景(>5萬條/秒),建議使用
JdbcBatchingOutputFormat+ 直接setX方法 - 或使用 緩存字段映射 + LambdaMetafactory 生成 setter
4. ? 未校驗 SQL 參數數量與字段數量是否匹配
- 如果
indexFieldMap.size() != SQL 中 ? 的數量,可能導致SQLException - 應在
open()時校驗
? 改進建議:
int parameterCount = preparedStatement.getParameterMetaData().getParameterCount();if (indexFieldMap.size() != parameterCount) {throw new IllegalArgumentException("SQL 參數數量與字段數量不匹配");5. ? 未處理并發 subtask 關閉時的競爭
if (getIndexOfThisSubtask() + 1 == getNumberOfParallelSubtasks())- 多個 subtask 同時關閉時,可能多個線程都認為自己是“最后一個”
- 導致
dataSource.close()被調用多次
? 改進建議:
使用靜態標志位控制:
private static volatile boolean dataSourceClosed = false;if (!dataSourceClosed) {synchronized (MySQLSinkFunction.class) {if (!dataSourceClosed) {dataSource.close();dataSourceClosed = true;}}}? 五、適用場景總結
| ? 多種 POJO 寫入不同表 | ? 非常適合(通用性高) |
| ? 中低吞吐(< 5萬條/秒) | ? 適合 |
| ? 測試/開發環境 | ? 推薦 |
| ? 生產環境(需改造) | ?? 需增加 Checkpoint 支持、配置化參數 |
| ? 超高吞吐(> 10萬條/秒) | ? 反射開銷大,建議用 |
🏁 六、最終評價
這是一個 設計精良、功能完整、具備生產潛力的通用 JDBC Sink,其亮點在于:
- ? 注解驅動 + 反射 實現了高度通用性
- ? HikariCP 單例 + 安全關閉 解決了資源管理問題
- ? 批處理 + 事務 + 回滾 保證了數據一致性
- ? 類型自動識別 + null 處理 增強了健壯性
? 在flink中的用法
package org.example.demo01;import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
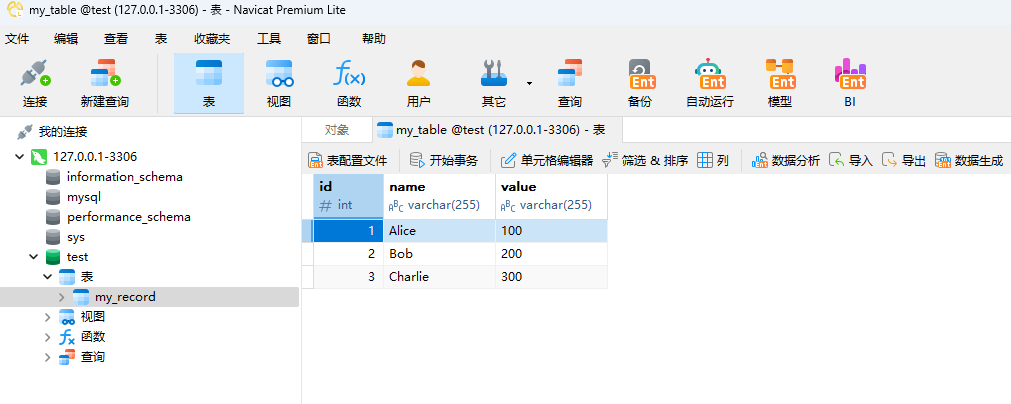
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class LocalFlinkJob {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(8);// ? 開啟 Checkpointing,支持 Exactly-Onceenv.enableCheckpointing(5000); // 每 5 秒做一次 checkpointenv.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);env.getCheckpointConfig().setMinPauseBetweenCheckpoints(2000); // 避免頻繁 checkpoint// ? 數據源(測試用)DataStreamSource<MyRecordOne> dataStreamSource = env.fromElements(new MyRecordOne(1, "Alice", 100),new MyRecordOne(2, "Bob", 200),new MyRecordOne(3, "Charlie", 300));// ? 打印驗證(可選)dataStreamSource.print();dataStreamSource.addSink(new MySQLSinkFunction<>(MyRecordOne.class)).setParallelism(8);// ? 添加 JDBC Sink
// dataStreamSource.addSink(
// JdbcSink.sink(
// // SQL 語句(注意字段順序)
// "INSERT INTO my_table (id, name, value) VALUES (?, ?, ?)",
//
// // 設置 PreparedStatement 參數
// (PreparedStatement ps, MyRecord record) -> {
// ps.setInt(1, record.getId());
// ps.setString(2, record.getName());
// ps.setInt(3, record.getValue());
// },
//
// // 執行選項:批處理配置
// JdbcExecutionOptions.builder()
// .withBatchSize(1000) // 每批最多 1000 條
// .withBatchIntervalMs(2000) // 每 2 秒 flush
// .withMaxRetries(3) // 重試 3 次
// .build(),
//
// // 連接選項
// new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
// .withUrl("jdbc:mysql://localhost:3306/test?useSSL=false&serverTimezone=UTC")
// .withDriverName("com.mysql.cj.jdbc.Driver")
// .withUsername("root")
// .withPassword("root")
// .withConnectionCheckTimeoutSeconds(30)
// .build()
// )
// );// ? 啟動執行env.execute("Production JDBC Write Job");}}@Data
@SQLParameterSqlStr(name = "insert into my_record(id,name,value) values(?,?,?)")
public class MyRecordOne implements MyRecord {@SQLParameter(index = 1)private Integer id;@SQLParameter(index = 2)private String name;@SQLParameter(index = 3)private int value;public MyRecordOne(Integer id, String name, int value) {this.id = id;this.name = name;this.value = value;}
}
)





概率論基礎知識-伽馬函數·上)






)





)