個人主頁:chian-ocean
專欄
引言
人工智能技術和大數據的發展,實時訪問網頁數據成為許多應用的核心需求。相比傳統方案依賴靜態或定期更新的數據,AI可以實時抓取和分析網頁上的及時更新的信息,迅速適應變化的環境,提取重要的信息。傳統方案的局限性在于數據的時效性和靈活性比較差 ,無法及時反映信息的變化,而AI獲取實時數據獲取能力使其在動態場景中具有很好的優點了。
傳統的網頁爬蟲雖然能夠抓取數據,但在實際落地時存在以下痛點:
-
實現復雜:動態網頁需要模擬瀏覽器環境,涉及大量工程工作;
-
維護成本高:網頁結構頻繁變化,爬蟲腳本易失效;
-
實時性不足:數據更新與響應速度難以滿足 AI 場景需求。
為什么說AI和MCP是完美伴侶
這個問題我們拆開分析,從AI和MCP兩個角度。
1. AI 的短板
-
缺乏實時性:LLM 的知識停留在訓練數據時間點,無法直接訪問最新網頁內容。
-
無法直接抓取網頁:模型不會解析 HTML、執行 JavaScript,更無法應對反爬。
-
上下文有限:需要額外數據源,才能生成更精準答案。
2. MCP 的長板
-
實時網頁訪問能力:可獲取靜態頁面與動態頁面(JS 渲染內容)。
-
對開發者友好:統一 API,免去維護復雜爬蟲的負擔。
-
穩定可靠:內置反爬、并發和大規模請求處理機制
針對這些問題,Bright Data MCP 提供了一套面向開發者的 Web 數據訪問 API。它不僅支持靜態與動態網頁抓取,還具備以下特性:
-
即插即用,降低開發與維護門檻;
-
每月 5,000 次請求免費額度(前三個月免費),適合快速驗證;
-
支持 SSE(Server-Sent Events) 與標準 HTTP 請求,方便與現有系統集成;
-
提供遠程托管與本地部署兩種方式,分別滿足入門開發者與高級用戶需求。
總的來說: AI + MCP = 實時、智能、穩定的應用

獲取 Bright Data 的 Json 以及 API-token
(點擊)Bright Data隨后進行注冊,按照指引登錄上就好了。
獲取API-KEY
- 找到登錄界面,點擊賬戶設置就可以看到自己的API-KEY了
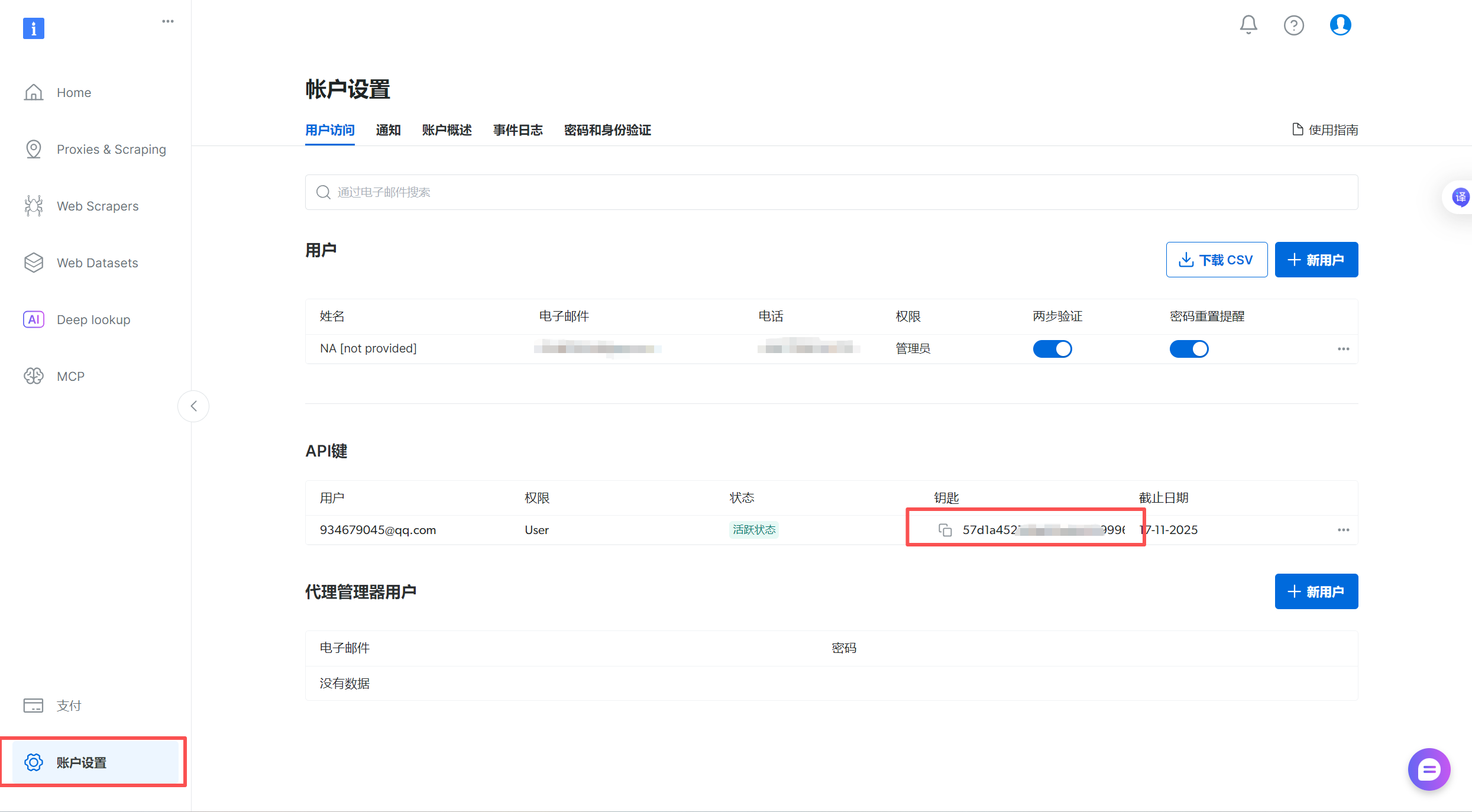
獲取JSON串
中間黑色框框就是json串
{"mcpServers": {"Bright Data": {"command": "npx","args": ["@brightdata/mcp"],"env": {"API_TOKEN": "xxxxxxxxxxxxxxxxxxx" //這里是上面的API-KEY}}}
}
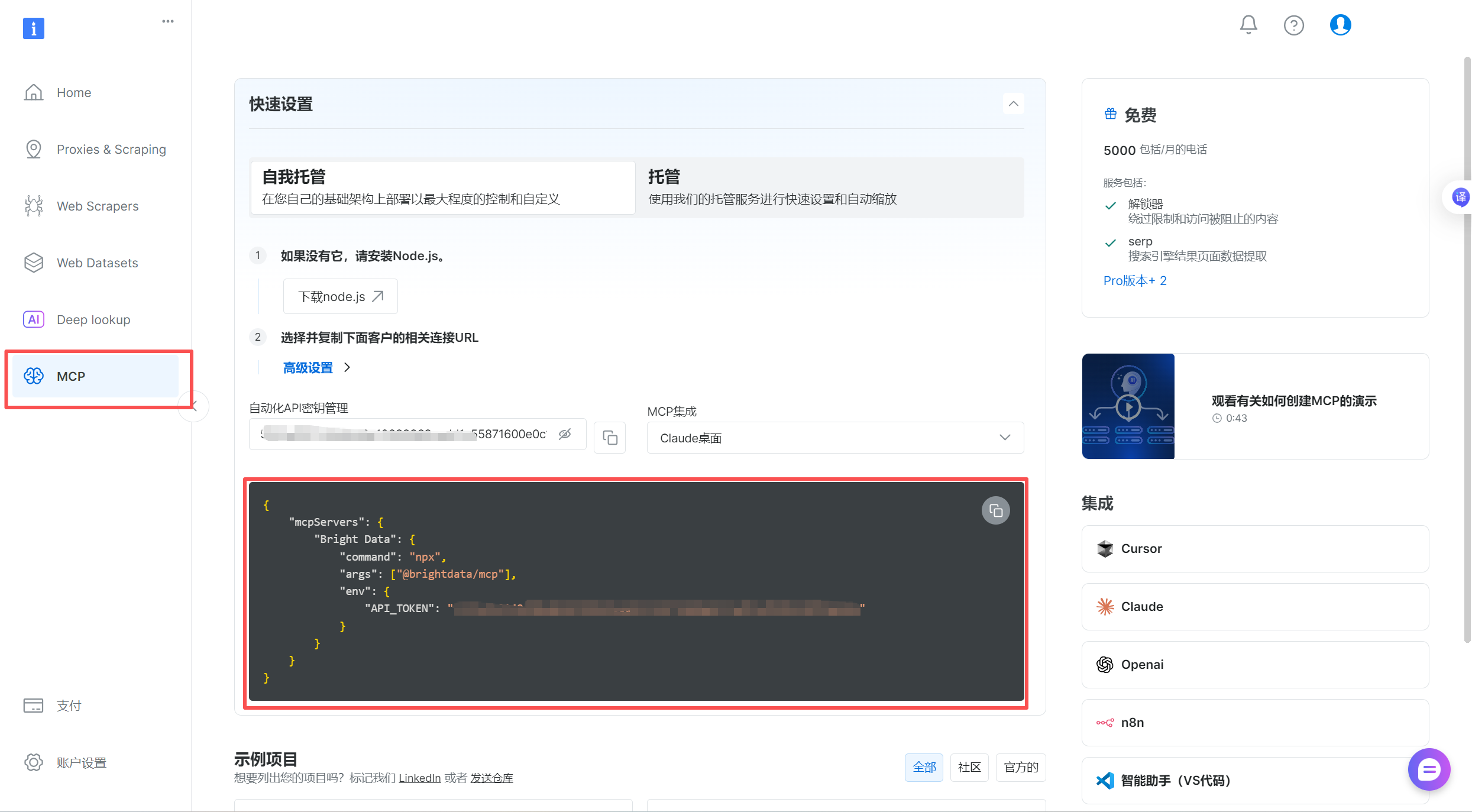
高級選項設置
-
解鎖區:控制代理 IP 的地區,讓你的請求看起來像來自目標地區(比如美國、德國),突破網站的地區限制。
-
瀏覽器區域:模擬目標地區的瀏覽器環境(比如時區、語言),讓請求更像真實用戶,減少被網站識別為爬蟲的概率。
這點就提供了穩定可靠的反扒機制,舉個例子:
- 配合美國 IP,將瀏覽器區域設為
US/en(美國時區 + 英語),讓請求更像 “真實美國用戶”; - 爬取德國網站時,設為
DE/de(德國時區 + 德語),避免因環境矛盾被攔截。
調用API接口
這里面用Trae打開,進入主界面,看右上角的鋸齒的符號,配置添加MCP,左邊mcp.json直接添加就好了,當Bright Data 顯示對勾就顯示連接上了。
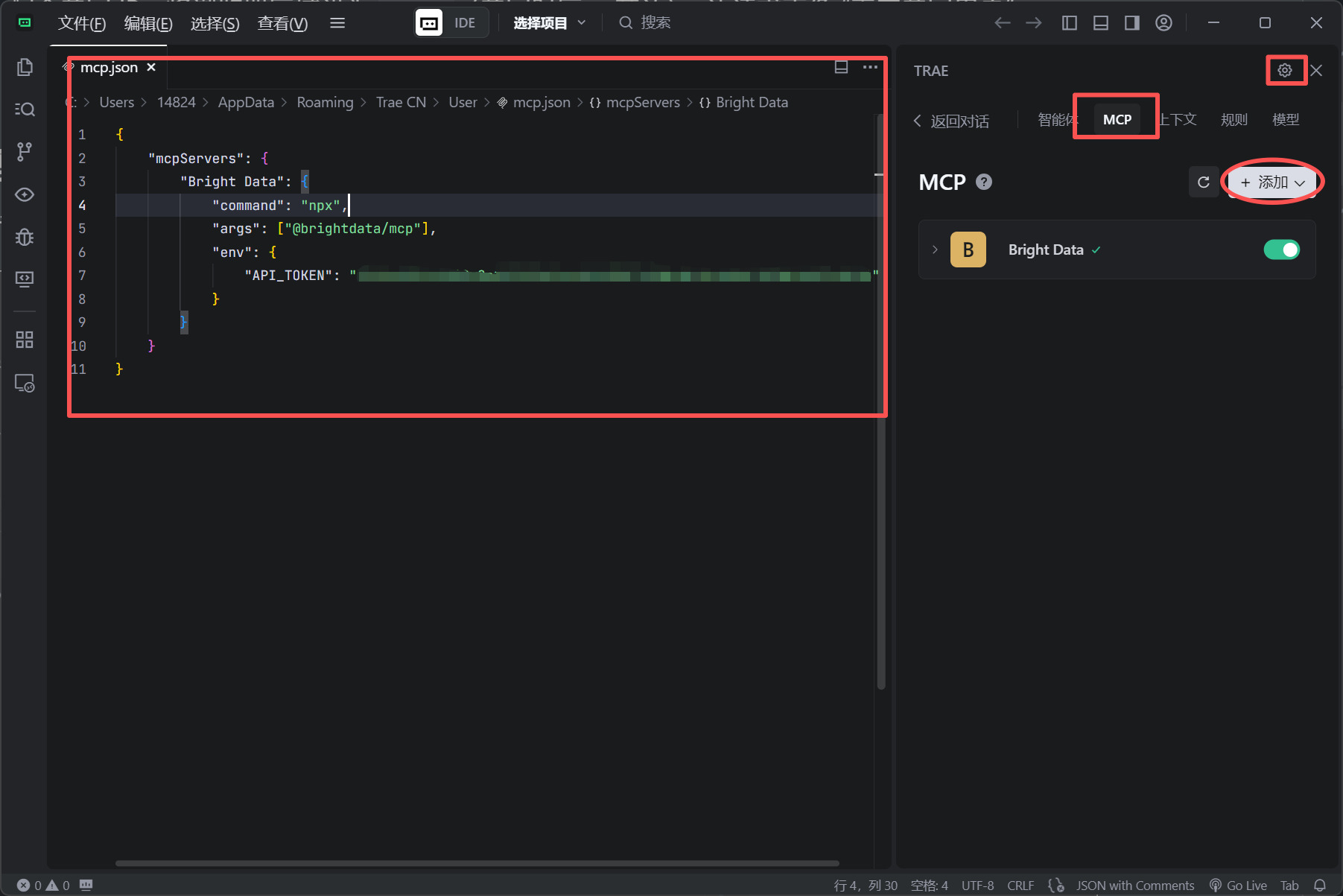
{"url": "https://www.12306.cn/index/" //這個是12306 網站
}
下面進行獲取和相應,效果還是非常明顯的。
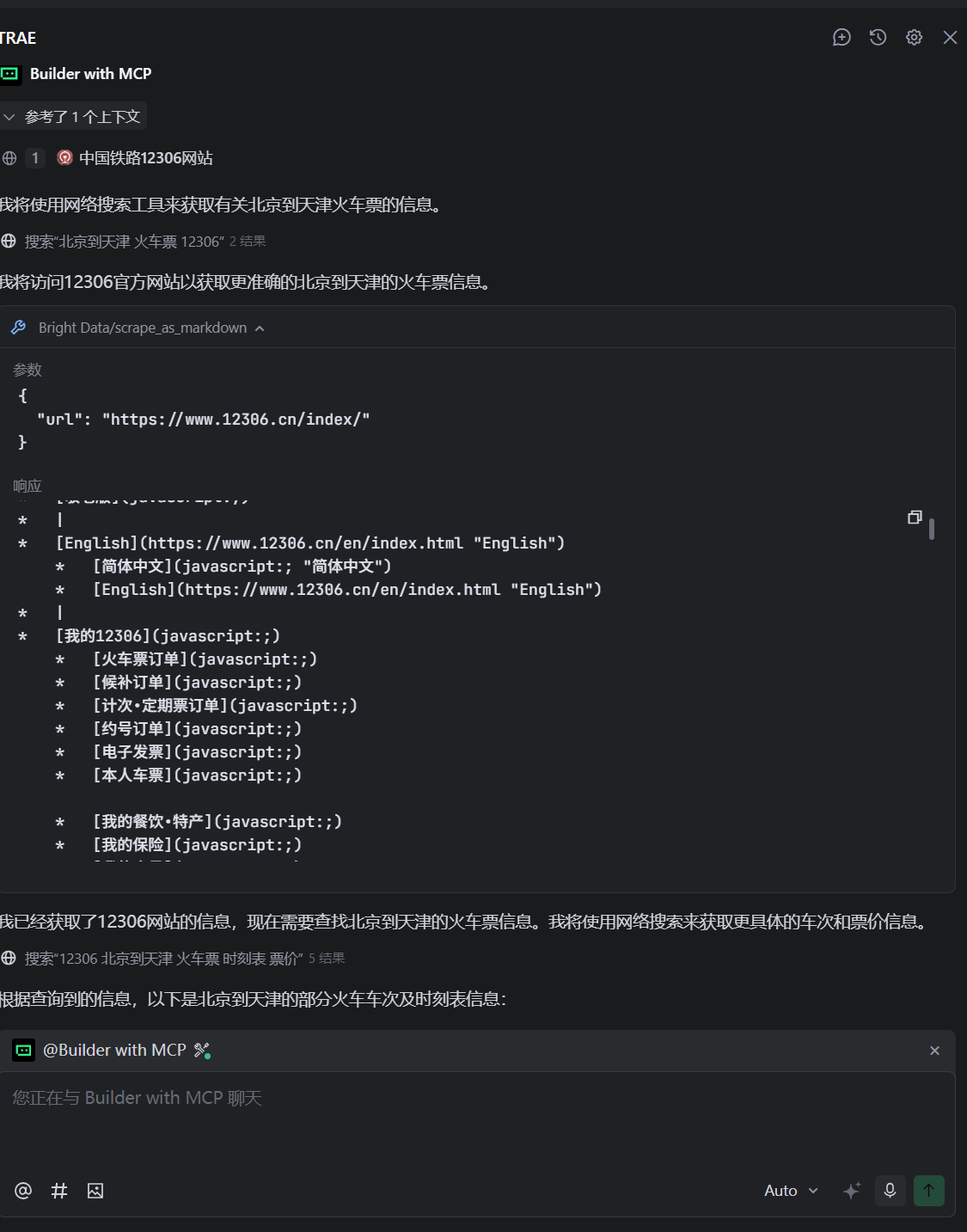
使用 Python 調用 MCP 實時抓取 Google 搜索結果(源碼)
文件目錄結構
├── 📄 config.py # 配置管理模塊├── 📄 example.py # 使用示例腳本├── 📄 install_mcp.py # MCP 服務器安裝助手├── 📄 mcp_client.py # MCP 客戶端核心模塊├── 📄 mcp_google_search.py # Google 搜索客戶端├── 📄 MCP_INSTALL_GUIDE.md # MCP 安裝指南文檔├── 📄 README.md # 項目說明文檔├── 📄 requirements.txt # Python 依賴包列表├── 📄 search_cli.py # 命令行搜索工具└── 📄 test_mcp_client.py # 測試腳本
簡單總結就是:
-
核心模塊(mcp_client、config 等)
-
搜索功能擴展(mcp_google_search、search_cli)
-
安裝與示例(install_mcp、example)
-
文檔說明(README、MCP_INSTALL_GUIDE)
-
依賴與測試(requirements、test_mcp_client)
項目架構
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐│ search_cli.py │ │ example.py │ │test_mcp_client.py││ (命令行工具) │ │ (使用示例) │ │ (測試腳本) │└─────────┬───────┘ └─────────┬───────┘ └─────────┬───────┘│ │ │└──────────────────────┼──────────────────────┘│┌─────────────▼───────────────┐│ mcp_client.py ││ (MCP 客戶端核心) │└─────────────┬───────────────┘│┌─────────────▼───────────────┐│ mcp_google_search.py ││ (Google 搜索功能) │└─────────────┬───────────────┘│┌─────────────▼───────────────┐│ config.py ││ (配置管理) │└─────────────────────────────┘客戶端主程序
"""真正的 MCP 客戶端,用于與 Bright Data MCP 服務器通信"""import osimport jsonimport asyncioimport loggingfrom typing import List, Dict, Any, Optionalfrom dataclasses import dataclasslogger = logging.getLogger(__name__)@dataclassclass SearchResult:"""搜索結果數據類"""title: strurl: strsnippet: strposition: intsource: str = "brightdata_mcp"class BrightDataMCPClient:"""真正的 Bright Data MCP 客戶端"""def __init__(self, api_token: Optional[str] = None):"""初始化 MCP 客戶端Args:api_token: Bright Data API Token"""self.api_token = api_token or "57d1a452149d90e8e10399969cedd1c55871600e0c12ed12ef870b448f9a8c06" //這里是我的APIKEYself.process = Noneasync def __aenter__(self):"""異步上下文管理器入口"""await self.connect()return selfasync def __aexit__(self, exc_type, exc_val, exc_tb):"""異步上下文管理器出口"""await self.disconnect()async def connect(self):"""連接到 MCP 服務器"""try:env = dict(os.environ)env["API_TOKEN"] = self.api_tokenself.process = await asyncio.create_subprocess_exec("npx", "@brightdata/mcp",stdin=asyncio.subprocess.PIPE,stdout=asyncio.subprocess.PIPE,stderr=asyncio.subprocess.PIPE,env=env)logger.info("已連接到 Bright Data MCP 服務器")except Exception as e:logger.error(f"連接 MCP 服務器失敗: {e}")raiseasync def disconnect(self):"""斷開 MCP 服務器連接"""if self.process:self.process.terminate()await self.process.wait()logger.info("已斷開 MCP 服務器連接")async def send_request(self, method: str, params: Dict[str, Any]) -> Dict[str, Any]:"""發送 MCP 請求"""if not self.process:raise RuntimeError("MCP 服務器未連接")request = {"jsonrpc": "2.0","id": 1,"method": method,"params": params}request_json = json.dumps(request) + "\n"try:if self.process.stdin is None:raise RuntimeError("進程的 stdin 不可用")if self.process.stdout is None:raise RuntimeError("進程的 stdout 不可用")self.process.stdin.write(request_json.encode())await self.process.stdin.drain()response_line = await self.process.stdout.readline()response = json.loads(response_line.decode().strip())if "error" in response:raise RuntimeError(f"MCP 錯誤: {response['error']}")return response.get("result", {})except Exception as e:logger.error(f"MCP 請求失敗: {e}")raiseasync def search(self, query: str, num_results: int = 10, lang: str = "zh-CN") -> List[SearchResult]:"""執行搜索Args:query: 搜索查詢num_results: 結果數量lang: 搜索語言Returns:搜索結果列表"""try:params = {"query": query,"num_results": min(num_results, 20),"language": lang,"country": "CN" if lang == "zh-CN" else "US"}result = await self.send_request("search", params)return self._parse_search_results(result)except Exception as e:logger.error(f"搜索失敗: {e}")# 返回模擬結果作為后備return self._get_mock_results(query, num_results)def _parse_search_results(self, data: Dict[str, Any]) -> List[SearchResult]:"""解析搜索結果"""results = []if "organic_results" in data:for i, item in enumerate(data["organic_results"]):result = SearchResult(title=item.get("title", ""),url=item.get("url", ""),snippet=item.get("snippet", ""),position=i + 1,source="brightdata_mcp")results.append(result)return resultsdef _get_mock_results(self, query: str, num_results: int) -> List[SearchResult]:"""獲取模擬搜索結果(當 MCP 不可用時)"""mock_data = [{"title": f"關于 '{query}' 的搜索結果 - 百度百科","url": f"https://baike.baidu.com/search?word={query}","snippet": f"這是關于 {query} 的詳細介紹和相關信息。包含定義、特點、應用等內容。"},{"title": f"{query} - 維基百科","url": f"https://zh.wikipedia.org/wiki/{query}","snippet": f"{query} 是一個重要的概念,在多個領域都有應用。本文詳細介紹了其歷史、發展和現狀。"},{"title": f"{query} 官方網站","url": f"https://www.{query.lower().replace(' ', '')}.com","snippet": f"歡迎訪問 {query} 官方網站,了解最新信息、產品和服務。"}]results = []for i, item in enumerate(mock_data[:num_results]):result = SearchResult(title=item['title'],url=item['url'],snippet=item['snippet'],position=i + 1,source="mock_data")results.append(result)return results# 為了向后兼容,保留舊的類名MCPGoogleSearchClient = BrightDataMCPClientclass MockMCPSearchClient(BrightDataMCPClient):"""模擬 MCP 客戶端,用于演示"""def __init__(self):super().__init__("mock-token")async def connect(self):"""模擬連接"""logger.info("使用模擬 MCP 客戶端")async def disconnect(self):"""模擬斷開連接"""passasync def search(self, query: str, num_results: int = 10, lang: str = "zh-CN") -> List[SearchResult]:"""模擬搜索"""return self._get_mock_results(query, num_results)核心組件
-
SearchResult 數據類
- 用于存儲搜索結果(標題、URL、摘要等)
- 使用
@dataclass裝飾器實現
-
BrightDataMCPClient 類
- 真正的 MCP 客戶端實現
- 通過子進程與 MCP 服務器通信
- 使用 JSON-RPC 2.0 協議發送請求
- 支持異步操作(async/await)
-
MockMCPSearchClient 類
- 模擬客戶端,用于演示和測試
- 繼承自 BrightDataMCPClient
- 不需要真實 MCP 服務器即可工作
README技術文檔
# MCP Google 搜索工具這是一個使用 Python 調用 MCP API 實時抓取 Google 搜索結果的工具。## 功能特性- ? 異步 Google 搜索- ? 實時搜索監控- ? 模擬搜索演示- ? 命令行工具- ? 配置管理- ? 錯誤處理和重試機制## 安裝依賴```bashpip install -r requirements.txt```## 配置 Google API### 1. 獲取 Google Custom Search API 密鑰1. 訪問 [Google Cloud Console](https://console.developers.google.com/)2. 創建新項目或選擇現有項目3. 啟用 Custom Search API4. 創建 API 密鑰### 2. 創建自定義搜索引擎1. 訪問 [Google Custom Search Engine](https://cse.google.com/)2. 點擊"添加"創建新的搜索引擎3. 設置要搜索的網站(可以設置為整個網絡)4. 獲取搜索引擎 ID### 3. 設置環境變量```bash# Windowsset GOOGLE_API_KEY=你的API密鑰set GOOGLE_SEARCH_ENGINE_ID=你的搜索引擎ID# Linux/Macexport GOOGLE_API_KEY=你的API密鑰export GOOGLE_SEARCH_ENGINE_ID=你的搜索引擎ID```## 使用方法### 1. 命令行工具```bash# 基本搜索(演示模式)python search_cli.py "Python 教程" --demo# 真實 Google 搜索python search_cli.py "Python 教程" -n 5# 實時搜索監控python search_cli.py "Python 新聞" --realtime --interval 60# 查看配置狀態python search_cli.py --config "test"```### 2. 編程接口```pythonimport asynciofrom mcp_google_search import MCPGoogleSearchClientasync def main():# 使用真實 APIasync with MCPGoogleSearchClient(api_key="your_key", search_engine_id="your_id") as client:results = await client.search("Python 教程", num_results=5)for result in results:print(f"{result.title}: {result.url}")asyncio.run(main())```### 3. 模擬搜索演示```pythonimport asynciofrom mcp_google_search import MockMCPSearchClientasync def demo():async with MockMCPSearchClient() as client:results = await client.search("Python", num_results=3)for result in results:print(f"{result.title}: {result.url}")asyncio.run(demo())```## 命令行參數```positional arguments:query 搜索查詢關鍵詞optional arguments:-h, --help 顯示幫助信息-n NUM, --num NUM 返回結果數量 (默認: 5, 最大: 10)-l LANG, --lang LANG 搜索語言 (默認: zh-CN)-d, --demo 使用演示模式 (模擬搜索)-r, --realtime 啟用實時搜索監控-i INTERVAL, --interval INTERVAL實時搜索間隔秒數 (默認: 30)--iterations ITERATIONS實時搜索最大迭代次數 (默認: 5)--config 顯示配置信息```## 使用示例### 基本搜索```bashpython search_cli.py "機器學習" --demo -n 3```### 實時監控```bashpython search_cli.py "Python 新聞" --realtime -i 30 --iterations 10```### 中文搜索```bashpython search_cli.py "人工智能" -l zh-CN -n 5```## 文件結構```├── mcp_google_search.py # 主要搜索客戶端├── config.py # 配置管理├── search_cli.py # 命令行工具├── requirements.txt # 依賴包└── README.md # 說明文檔```## API 限制- Google Custom Search API 每天免費 100 次查詢- 每次請求最多返回 10 個結果- 需要有效的 API 密鑰和搜索引擎 ID## 錯誤處理程序包含完整的錯誤處理機制:- 網絡請求超時處理- API 限制和錯誤響應處理- 配置驗證- 優雅的中斷處理## 注意事項1. 請遵守 Google API 使用條款2. 注意 API 調用頻率限制3. 保護好你的 API 密鑰4. 實時搜索會消耗更多 API 配額## 許可證MIT License
效果展示
按照技術文檔的效果展示一遍:
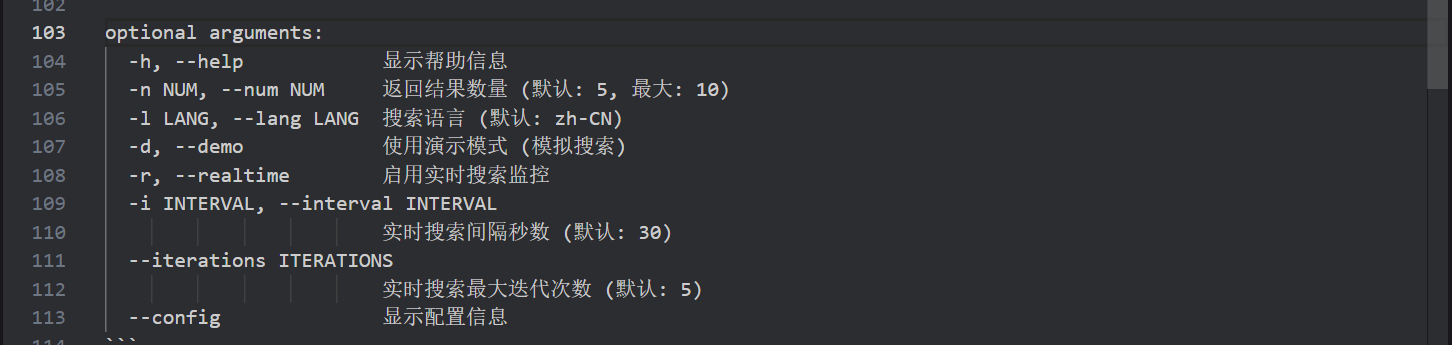
搜索內容 “python教程”
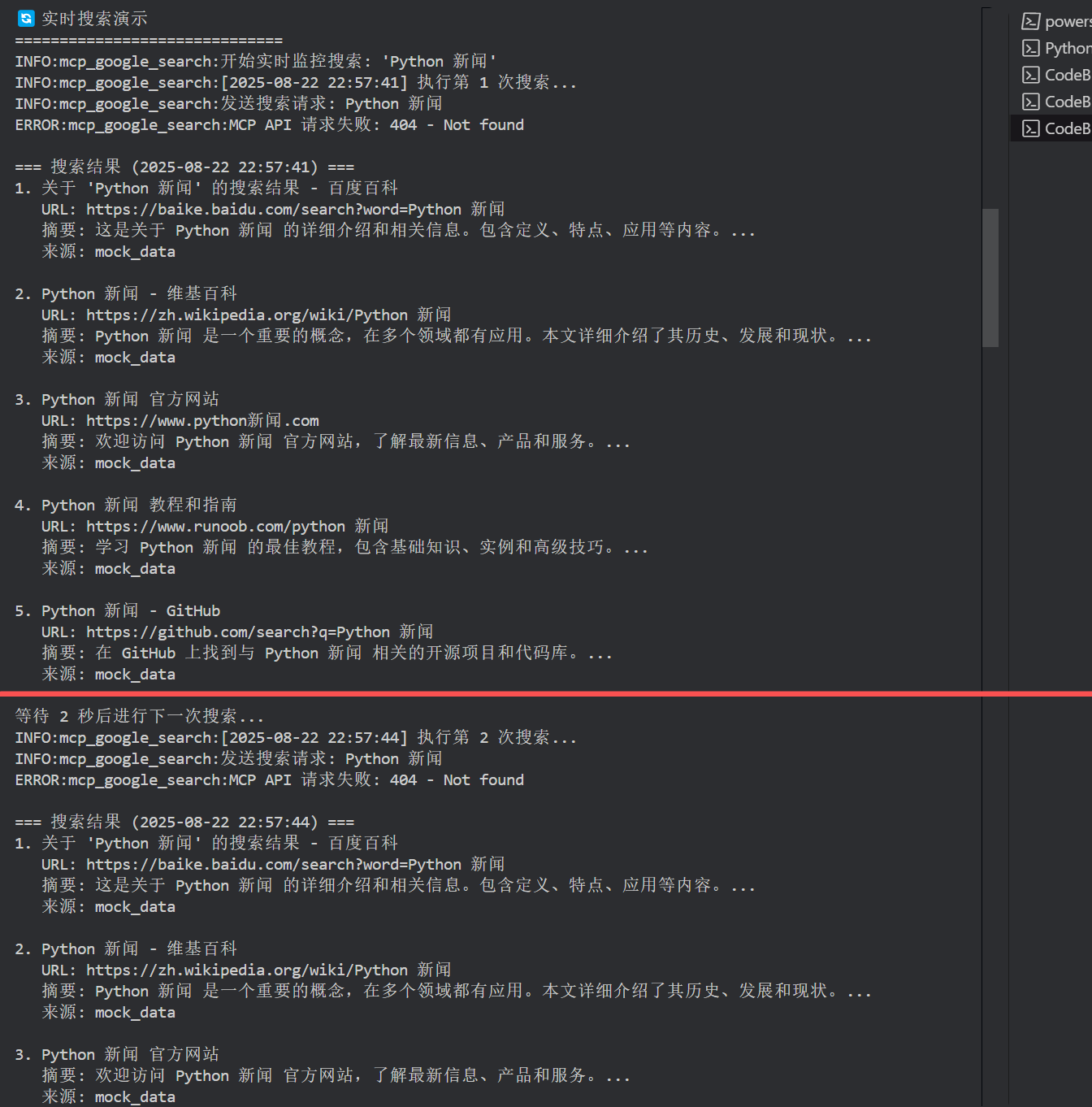
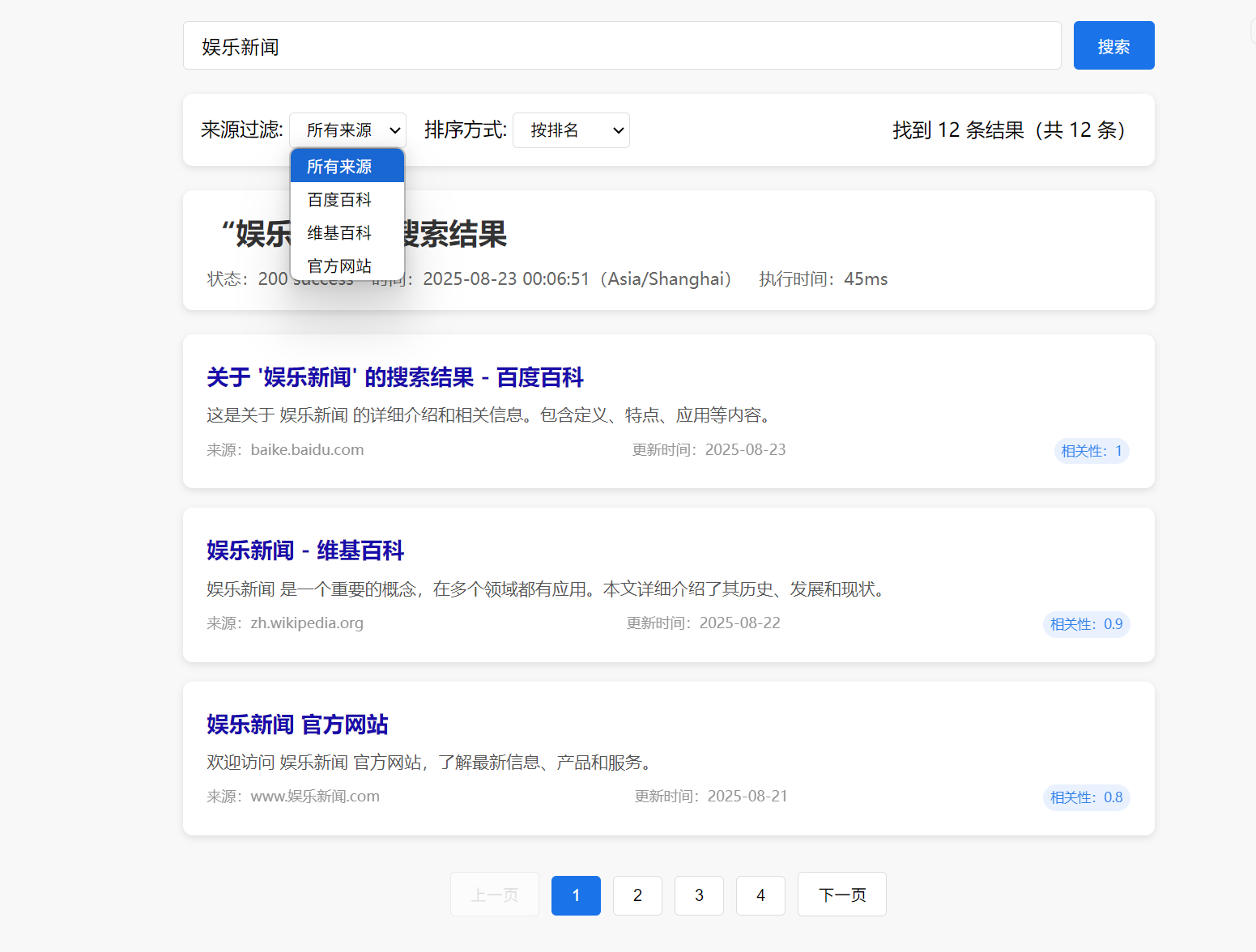
娛樂新聞搜索
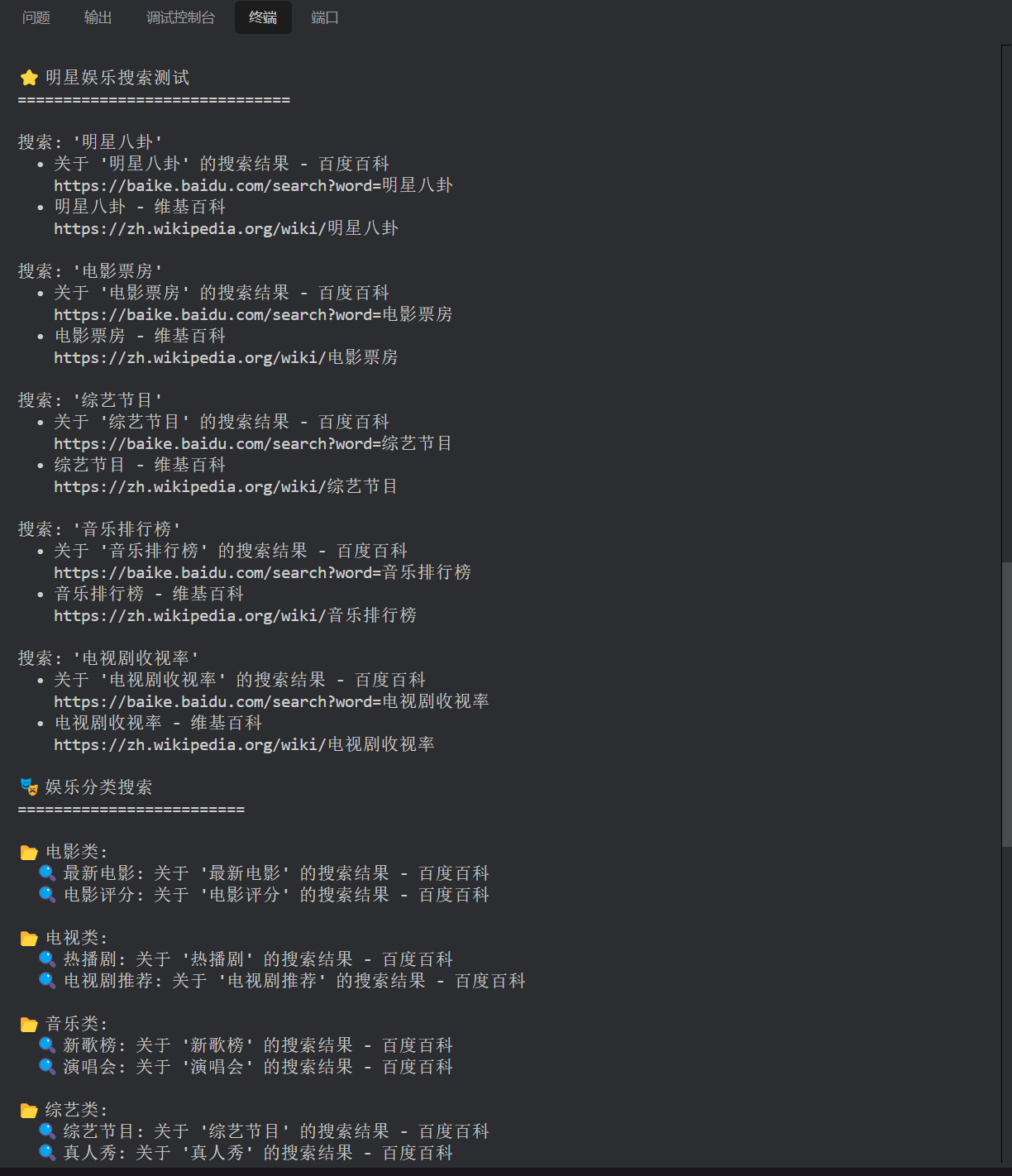
看樣子,效果還是不錯的。
生成HTTP JSON串
簡單進行數據處理
- 這個界面簡潔,處理迅速,直接丟給AI,就可以直接生成結果。爆贊!!
使用 Python 調用 MCP 抓取 Google 搜索等等搜索結果,是一種 “低成本、高開發效率” 的方案,適合快速實現需求。不僅僅可以應用在搜索,還可以應用在市場調研,產品分析等等,都有很大的便利。
總結
差異化結尾示例(聚焦「成本-能力-未來」三角):
? 試錯零門檻:前 3 個月每月 5000 次免費調用,足夠驗證「AI + 實時數據」的商業邏輯;
? 能力無上限:突破反爬封鎖、跨地域采集、瀏覽器級交互,把「網絡噪音」變成 AI 能讀懂的結構化洞察;
? 未來先發車:當同行還在為數據過時、爬取封號焦頭爛額時,你早已用 MCP 搭建起AI 實時決策系統—— 從競品廣告追蹤到行業輿情監測,讓模型永遠拿著最新鮮的世界地圖作戰。
本質上,MCP 正在重新定義 AI 的數據供給方式:它不再是靜態訓練的「歷史庫」,而是連接現實世界的實時神經末梢。對想讓 AI 真正活在當下的團隊來說,這或許是最值得抓住的時代紅利。
如果您對該感興趣話?,不妨點擊該鏈接體驗:亮數據
)







)



)






