【JVM】流程匯總
- 【一】編譯過程和內存分布
- 【1】案例程序:簡單的 Java 類
- 【2】Java 編譯過程:從.java到.class
- (1)編譯命令
- (2)編譯結果
- (3)字節碼的作用
- 【3】Java 運行過程:從.class到 JVM 執行
- (1)類加載:將.class加載到 JVM 方法區
- (2)類加載器層級
- (3)內存分配:JVM 各區域的存儲內容
- (4)JDK版本的JVM內存區域變化
- (5)對象創建的過程
- 【4】代碼執行:JVM 解釋 / 編譯字節碼
- 【5】Idea中的編譯案例
- (1)對Math.java文件進行反編譯,得到Math.class文件
- (2)從Math.class開始分析流程
- 【1】Math.class進入JVM
- 【2】認識方法區
- 【3】認識棧內存
- 【4】認識程序計數器
- 【5】認識堆
- 【6】方法區,棧、堆之間的過程
- 【二】JVM 內存清理:垃圾回收(GC)機制
- 【1】如何判斷對象 “可回收”?
- 【2】垃圾回收的核心流程
- 【3】觸發時機
- 【4】垃圾回收的詳細過程
- (1)觸發條件:何時需要垃圾回收?
- (2)階段 1:對象存活判定
- (3)階段 2:垃圾標記(確定可回收對象)
- (4)階段 3:垃圾回收(清除可回收對象)
- (5)階段 4:內存整理(可選)
- (6)垃圾收集器的影響
- 【三】jvm常用的配置參數
- 【1】內存區域配置(核心)
- 【2】垃圾收集器配置
- 【3】日志與調試配置
- 【4】JVM 優化案例
- (1)場景 1:Web 應用頻繁 Minor GC,響應時間長
- (2)場景 2:大內存應用(8G 堆)Full GC 頻繁,停頓時間長
- 【5】參數調優原則
- 【四】內存溢出(OOM):當內存不足時
- 【1】堆內存溢出(最常見)
- 【2】虛擬機棧溢出
- (1)案例 1:遞歸過深
- (2)案例 2:線程過多
- 【3】方法區(元空間)溢出
- 【4】內存溢出(OOM)排查與解決案例
- (1)場景:堆內存溢出(Java heap space)
- (2)排查步驟
- (3)解決措施
- (4)總結流程
【一】編譯過程和內存分布
【1】案例程序:簡單的 Java 類
先定義一個簡單的 Java 類 UserDemo.java,用于后續分析:
import java.util.ArrayList;
import java.util.List;// 用戶類
class User {private String name;private int age;public User(String name, int age) {this.name = name;this.age = age;}public void printInfo() {System.out.println("Name: " + name + ", Age: " + age);}
}// 主程序類
public class UserDemo {// 靜態變量(類級別)private static List<User> userList = new ArrayList<>();public static void main(String[] args) {// 局部變量(方法棧中)String prefix = "User_";for (int i = 0; i < 3; i++) {// 創建對象(堆中)User user = new User(prefix + i, 20 + i);userList.add(user); // 靜態列表引用對象(避免被GC回收)user.printInfo(); // 調用方法(棧幀入棧)}}
}
【2】Java 編譯過程:從.java到.class
Java 是跨平臺語言,需要先編譯為字節碼(.class),再由 JVM 解釋執行。
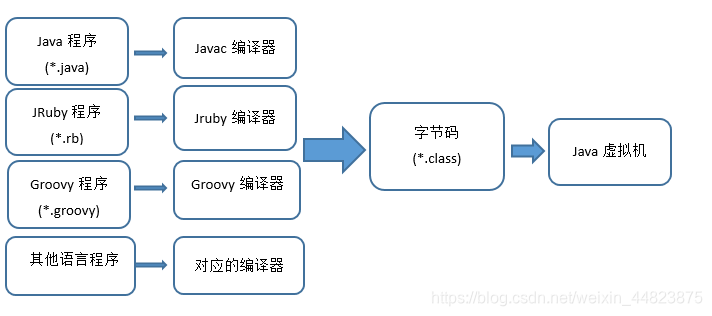
(1)編譯命令
使用 javac 命令編譯 UserDemo.java:
javac UserDemo.java
(2)編譯結果
編譯成功后,會生成兩個字節碼文件:
User.class:User類的字節碼(包含類結構、方法指令等)
UserDemo.class:UserDemo類的字節碼(包含main方法等)
(3)字節碼的作用
字節碼是一種中間代碼,不依賴具體操作系統,僅面向 JVM。它包含:
(1)類的元信息(類名、父類、接口等)
(2)方法的指令(如創建對象、調用方法、循環等操作的二進制指令)
(3)常量池(字符串常量、類引用、方法引用等)
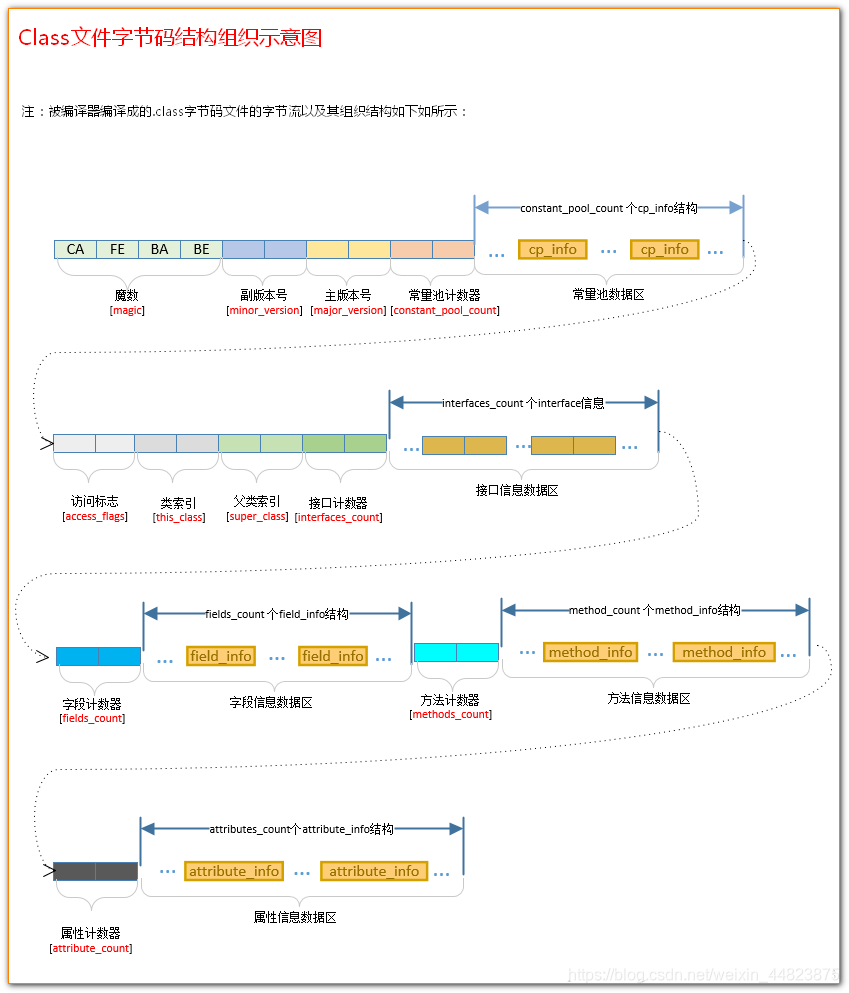
【3】Java 運行過程:從.class到 JVM 執行
使用 java 命令運行程序:
java UserDemo
運行過程可分為類加載、內存分配、代碼執行三個核心階段。
(1)類加載:將.class加載到 JVM 方法區
JVM 通過類加載器(ClassLoader) 加載.class文件到內存的方法區(JDK8 + 中為 “元空間”),加載過程分為 5 步:
(1)加載:通過類全限定名(如UserDemo)找到.class文件,讀取字節流到內存。
(2)驗證:校驗字節碼合法性(如是否符合 JVM 規范、是否有安全漏洞)。
(3)準備:為類的靜態變量分配內存并設置默認值(如userList默認值為null)。
(4)解析:將常量池中的符號引用(如User類的引用)替換為直接內存地址(真實引用)。
(5)初始化:執行靜態代碼塊和靜態變量賦值(如userList = new ArrayList<>())。
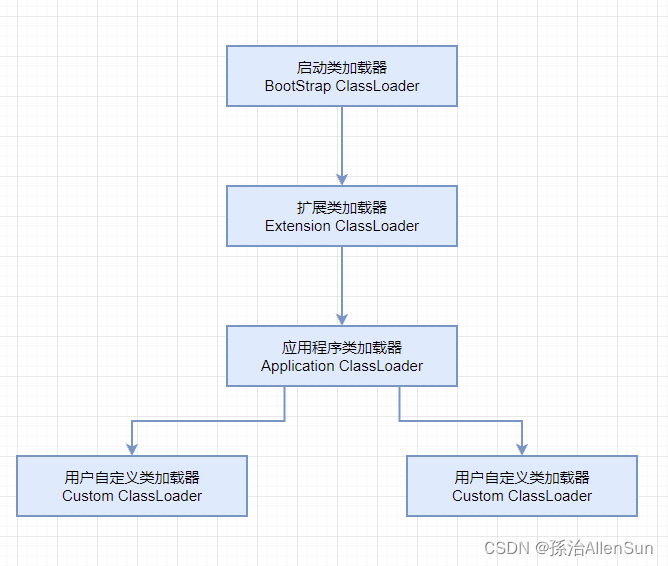
(2)類加載器層級
啟動類加載器(Bootstrap ClassLoader):加載 JDK 核心類(如java.lang.String)。
擴展類加載器(Extension ClassLoader):加載 JDK 擴展類。
應用程序類加載器(Application ClassLoader):加載用戶自定義類(如UserDemo)。
(3)內存分配:JVM 各區域的存儲內容
JVM 運行時內存分為 5 個區域,UserDemo運行時的內存分配如下:
(1)程序計數器(線程私有)
記錄當前線程執行的字節碼指令地址(如main方法中循環的當前步驟)。
(2)虛擬機棧(線程私有)
存儲方法調用的棧幀:
1、局部變量表(如prefix、i、user等局部變量)
2、操作數棧(方法執行時的臨時數據)
3、方法返回地址。
(3)本地方法棧(線程私有)
類似虛擬機棧,但用于執行本地方法(如Object.hashCode()等 native 方法)。
(4)堆(Heap)(線程共享)
存儲對象實例:
1、new ArrayList<>()創建的集合對象
2、new User(…)創建的 3 個User對象。
(5)方法區(元空間)(線程共享)
存儲類信息:
1、User和UserDemo的類結構(屬性、方法定義)
2、常量池(如字符串"User_")
3、靜態變量userList。
關鍵邏輯:
(1)main方法執行時,虛擬機棧會創建一個棧幀,包含局部變量prefix(字符串引用)、i(int 值)、user(User對象引用)。
(2)user引用指向堆中的User對象(真實數據存儲在堆中)。
(3)靜態變量userList存儲在方法區,其引用指向堆中的ArrayList對象。
(4)JDK版本的JVM內存區域變化
(5)對象創建的過程
【4】代碼執行:JVM 解釋 / 編譯字節碼
JVM 通過解釋器逐行解釋字節碼指令(如new創建對象、invokevirtual調用printInfo方法),或通過JIT 編譯器(即時編譯)將熱點代碼(頻繁執行的代碼)編譯為本地機器碼(提高執行效率)。
UserDemo的執行流程:
(1)main方法棧幀入棧,初始化局部變量prefix = “User_”。
(2)循環 3 次:
1、執行new User(…):在堆中創建User對象,調用構造方法初始化name和age。
2、將User對象引用賦值給局部變量user。
3、調用user.printInfo():虛擬機棧創建printInfo方法的棧幀,執行打印邏輯后棧幀出棧。
4、將user添加到userList(User對象被靜態列表引用,不會被 GC 回收)。
(3)循環結束,main方法棧幀出棧,程序執行完成。
【5】Idea中的編譯案例
(1)對Math.java文件進行反編譯,得到Math.class文件
編寫一個簡單的Math.java文件
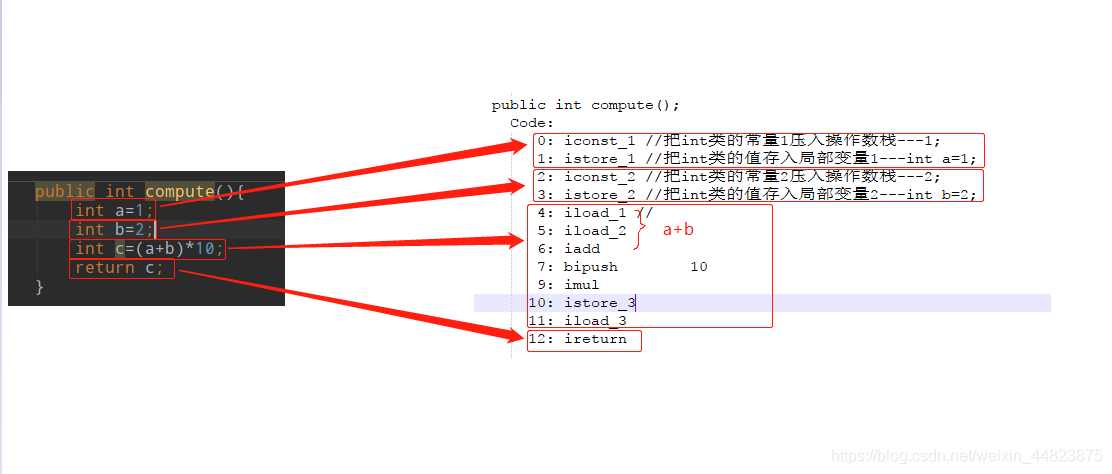
public class Math {public static final int initData = 666;public static User user = new User();public int compute(){int a=1;int b=2;int c=(a+b)*10;return c;}public static void main(String[] args) {Math math=new Math();math.compute();System.out.println("test");}
}
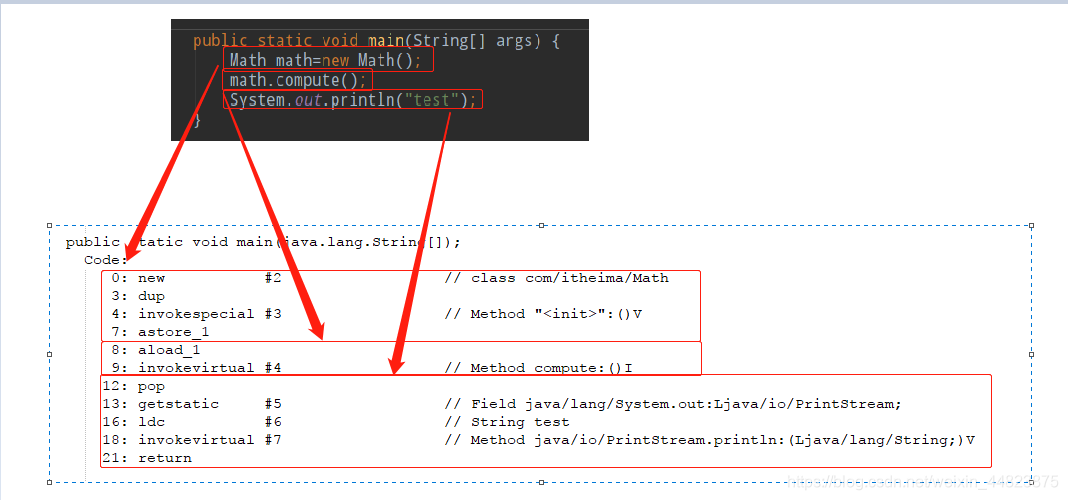
(1)先執行main方法,然后找到target目錄下已經編譯好的Math.class文件,在控制器中打開
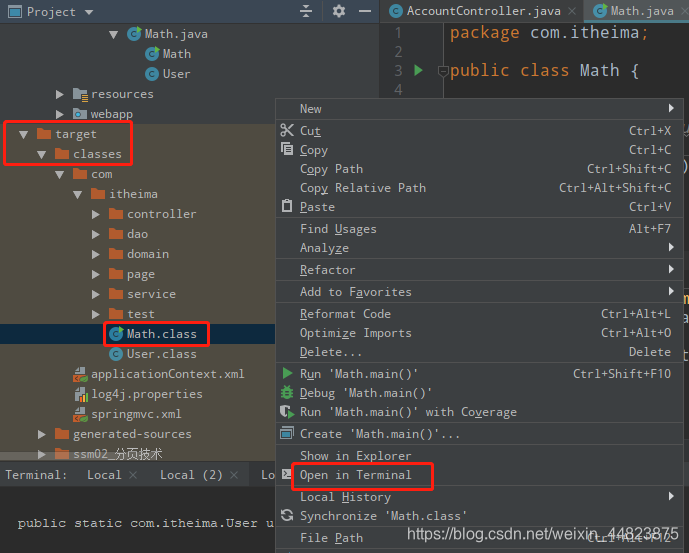
(2)此時雖然已經得到class文件,但是文件里都是字節碼,不方便閱讀,于是使用命令進行反編譯,得到一個我們容易閱讀的代碼內容
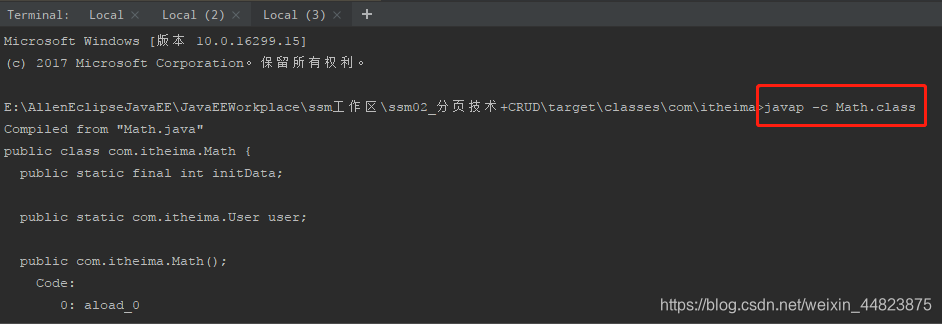 (3)在控制器中得到我們想要的字節碼文件內容
(3)在控制器中得到我們想要的字節碼文件內容
public class com.itheima.Math {public static final int initData;public static com.itheima.User user;public com.itheima.Math();Code:0: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: returnpublic int compute();Code:0: iconst_1 //把int類的常量1壓入操作數棧---1;1: istore_1 //把int類的值存入局部變量1---int a=1;2: iconst_2 //把int類的常量2壓入操作數棧---2;3: istore_2 //把int類的值存入局部變量2---int b=2;4: iload_1 //5: iload_26: iadd7: bipush 109: imul10: istore_311: iload_312: ireturnpublic static void main(java.lang.String[]);Code:0: new #2 // class com/itheima/Math3: dup4: invokespecial #3 // Method "<init>":()V7: astore_18: aload_19: invokevirtual #4 // Method compute:()I12: pop13: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream;16: ldc #6 // String test18: invokevirtual #7 // Method java/io/PrintStream.println:(Ljava/lang/String;)V21: returnstatic {};Code:0: new #8 // class com/itheima/User3: dup4: invokespecial #9 // Method com/itheima/User."<init>":()V7: putstatic #10 // Field user:Lcom/itheima/User;10: return
}
(2)從Math.class開始分析流程
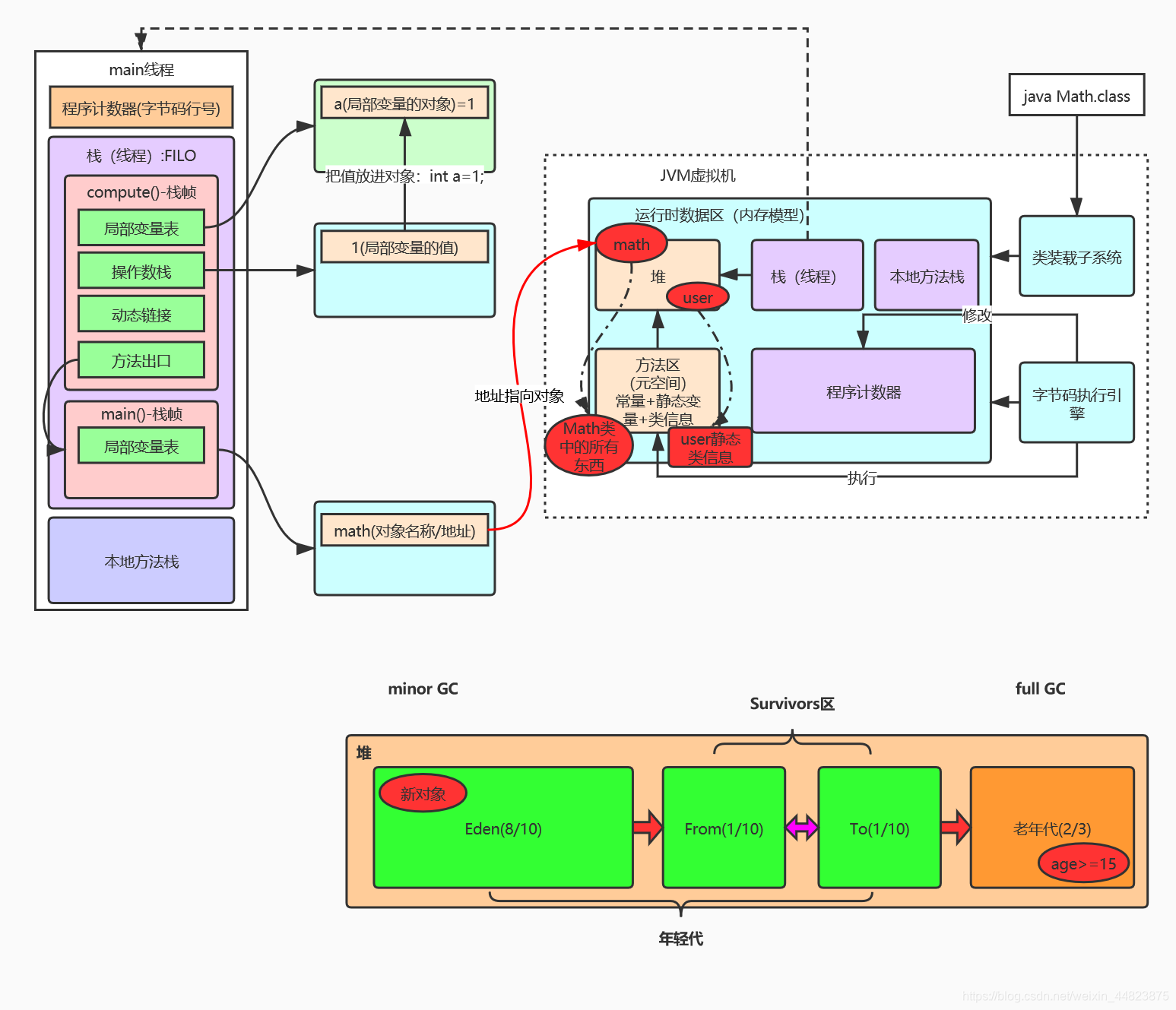
【1】Math.class進入JVM
Math.class文件最開始放在磁盤中,然后經過【類裝載子系統】裝入【方法區】,字節碼執行引擎讀取方法區的字節碼自適應解析,邊解析邊運行,然后PC寄存器指向了main函數所在的位置,虛擬機開始在棧中為main函數預留一個棧幀,然后開始運行main函數,main函數里的代碼被字節碼執行引擎映射成本地操作系統里相應的實現,然后調用本地方法接口,本地方法運行的時候,操縱系統會為本地方法分配本地方法棧,用來儲存一些臨時變量,然后運行本地方法,調用操作系統APIi等等。
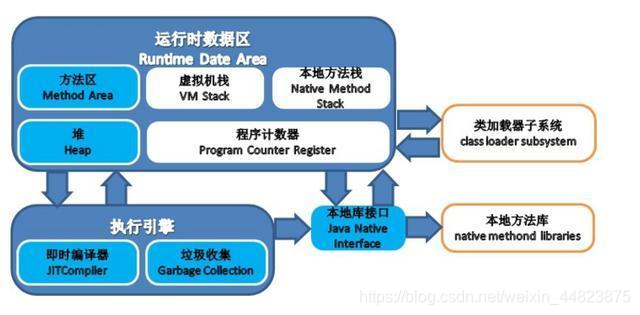
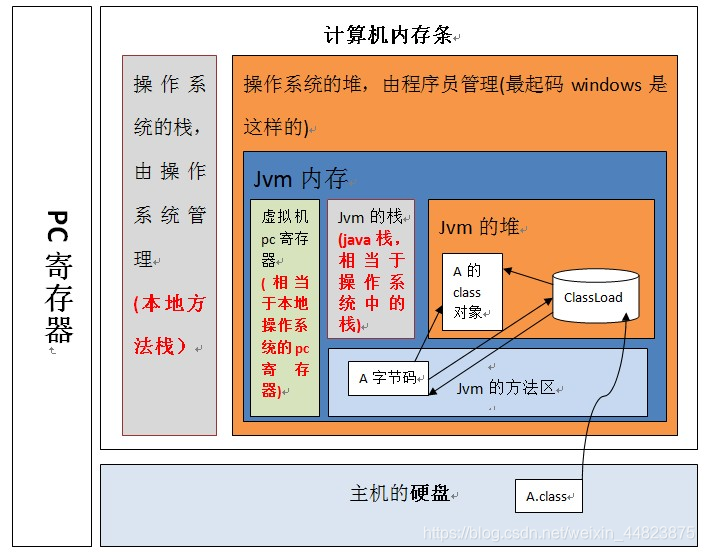
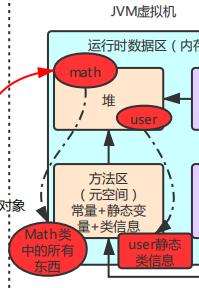
上圖表明:jvm 虛擬機位于操作系統的堆中,并且,程序員寫好的類加載到虛擬機執行的過程是:當一個 classLoder 啟動的時候,classLoader 的生存地點在 jvm 中的堆,然后它會去主機硬盤上將A.class裝載到jvm的方法區,方法區中的這個字節文件會被虛擬機拿來new A字節碼(),然后在堆內存生成了一個A字節碼的對象,然后A字節碼這個內存文件有兩個引用一個指向A的class對象,一個指向加載自己的classLoader。
【2】認識方法區
類加載器把加載到的所有信息放入方法區,也就是說方法區里存放了類的信息,有類的static靜態變量、final類型變量、field自動信息、方法信息,處理邏輯的指令集,我們仔細想想一個類里面也就這些東西。
而堆中存放是對象和數組,
1-這里的對應關系就是 “方法區–類” “堆–對象”,以“人”為例就是,堆里面放的是你這個“實實在在的人,有血有肉的”,而方法區中存放的是描述你的文字信息,如“你的名字,身高,體重,還有你的行為,如吃飯,走路等”。
2-再者我們從另一個角度理解,就是從前我們得知方法區中的類是唯一的,同步的。但是我們在代碼中往往同一個類會new幾次,也就是有多個實例,既然有多個實例,那么在堆中就會分配多個實例空間內存。
方法區的內容是邊加載邊執行,例如我們使用tomcat啟動一個spring工程,通常啟動過程中會加載數據庫信息,配置文件中的攔截器信息,service的注解信息,一些驗證信息等,其中的類信息就會率先加載到方法區。但如果我們想讓程序啟動的快一點就會設置懶加載,把一些驗證去掉,如一些類信息的加載等真正使用的時候再去加載,這樣說明了方法區的內容可以先加載進去,也可以在使用到的時候加載。
方法區是被字節碼執行引擎直接執行的,所以靜態信息都是在類加載的時候就創建了的,非靜態的信息是在堆內存實例化對象的時候才創建,所以靜態方法中不能調用非靜態的方法和變量
【3】認識棧內存
(1)在之前學習Static關鍵字的時候了解到,Math math=new Math();,在這個代碼執行時分為三塊:
- Math math:負責在棧內存開辟內存空間,用來存放類對象的名稱,其實就是對象的地址,此時對象還沒有完成初始化,還不能使用
- new Math():負責在堆內存開辟內存空間,用來存放類對象,此時完成對象的初始化,對象可以使用了
- Math math=new Math():負責將棧內存里的地址指向堆內存里的對象,此時類對象的名字和類對象的實例合為一體,我們就可以通過類對象名稱來調用對象中的信息了
(2)我們把棧放大,可以看到在棧里面,每一個方法都有一個自己的棧幀,main方法有一個棧幀,compute方法有一個棧幀,在代碼中main方法還調用了compute方法,那么它們是怎么存放信息、處理信息并相互傳遞信息的呢?
因為先運行main方法,所以main方法先入棧,再調用compute方法,再入棧,因為棧的特點是先入后出,所以compute先出棧,接下分析compute的結構和信息處理過程。
方法棧幀的內存又可以分為4個部分:局部變量表、操作數棧、動態鏈接、方法出口。其中局部變量表用來存放變量的名稱a、b、c等,操作數棧存放要進行賦值的操作數1、2。操作流程如下:
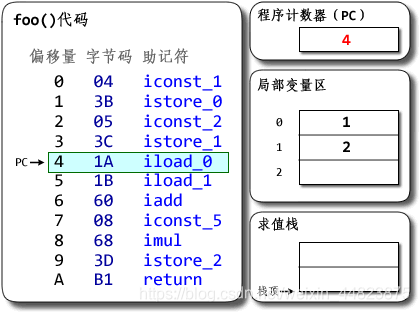
把操作數棧里的值賦值給局部變量表中的變量,還有其他一系列操作,操作結果就得到了 c=30,并且使用return語句把結果返回了,但是這個值是怎么傳遞給main方法的呢?那就是通過方法出口,把結果傳遞給棧中的下一個方法(方法棧幀是按照調用順序入棧的,所以結果都是順著往下傳遞),此時compute方法棧幀完成出棧。
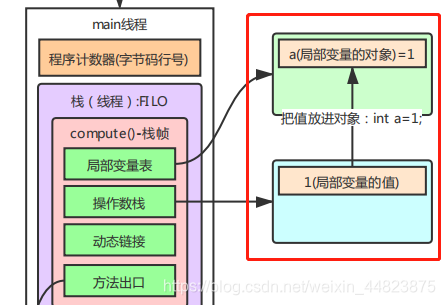
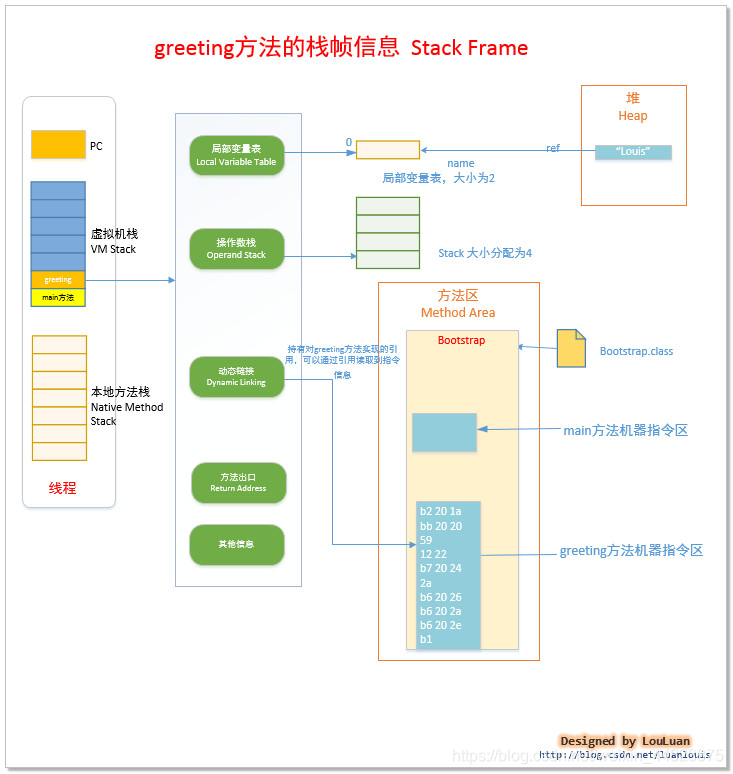
再來分析main方法棧幀,它同樣也包含局部變量表
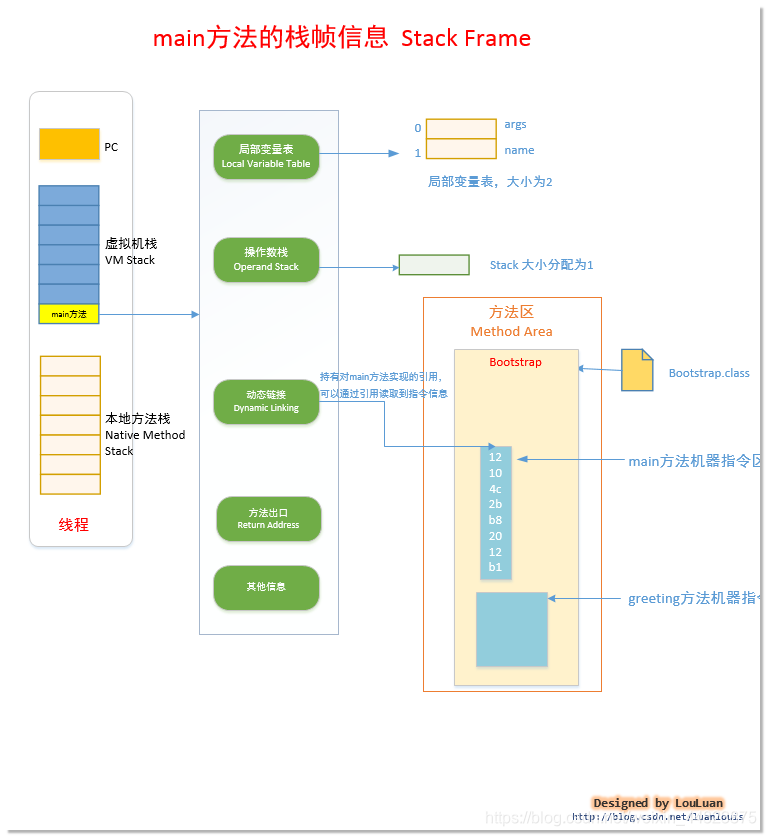
從上面的分析可以看出,通過棧和命令使得方法完成了數據的賦值和處理,還有方法的調用和處理等操作,最后把方法的處理的結果通過方法出口傳遞給調用者。
【4】認識程序計數器
在Math.class文件中可以看到,每一行指令都有一個行數,如果線程在執行指令的時候突然被掛起了,等線程被喚醒后要接著上次被掛起的位置執行怎么辦?
那就要給每一個方法線程配備一個程序計數器,用來標記線程執行的位置,每執行一行指令,字節碼執行引擎都會命令程序計數器更新到最新的行數。
所以程序計數器的作用為:
- 讀取指令:字節碼解釋器通過改變程序計數器來依次讀取指令,從而實現代碼的流程控制,如:順序執行、選擇、循環、異常處理。
- 標記位置:在多線程的情況下,程序計數器用于記錄當前線程執行的位置,從而當線程被切換回來的時候能夠知道該線程上次運行到哪兒了。

【5】認識堆
在main方法中對Math進行實例化,棧內存中的math地址指向堆內存中的math對象,但是math對象對應的那些屬性和方法不會也都放在堆內存中,這就要講到下一個區域方法區(元空間)了
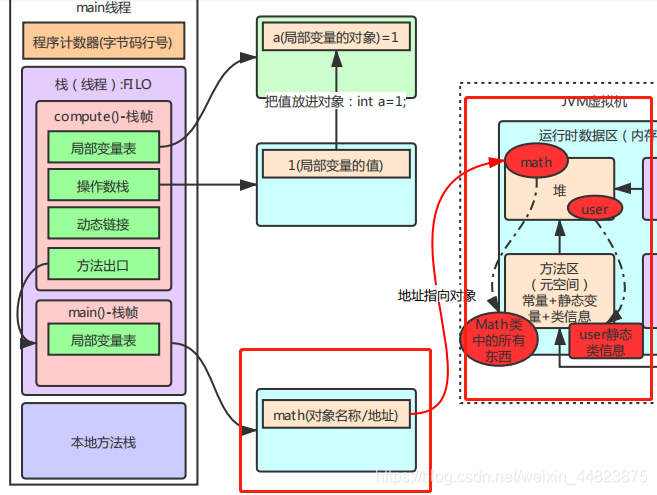
【6】方法區,棧、堆之間的過程
類加載器加載的類信息放到方法區---->執行程序后,方法區的方法壓入棧的棧頂---->棧執行壓入棧頂的方法---->遇到new對象的情況就在堆中開辟這個類的實例空間。(這里棧是有此對象在堆中的地址的)
【二】JVM 內存清理:垃圾回收(GC)機制
當對象不再被引用時,JVM 會通過垃圾回收器自動清理其占用的內存(主要針對堆和方法區)。
【1】如何判斷對象 “可回收”?
JVM 通過可達性分析判斷對象是否存活:
(1)以 “GC Roots”(如虛擬機棧中的局部變量、方法區的靜態變量)為起點,遍歷對象引用鏈。
(2)若對象無法通過任何引用鏈連接到 GC Roots,則標記為 “可回收”。
例如:若UserDemo中userList未引用User對象(即userList.remove(user)),則User對象會被標記為可回收。
【2】垃圾回收的核心流程
以堆內存回收為例(堆分為年輕代和老年代):
(1)標記:通過可達性分析標記所有可回收對象。
(2)清除:刪除標記的對象,釋放內存(不同 GC 算法實現不同)。
年輕代(存放新創建的對象):采用復制算法(將存活對象復制到另一塊區域,清空原區域)。
老年代(存放存活久的對象):采用標記 - 整理算法(移動存活對象到一端,清空另一端)。
(3)內存分配:新對象優先在年輕代的 Eden 區分配內存。
【3】觸發時機
Minor GC:年輕代內存不足時觸發(頻繁,回收速度快)。
Major GC/Full GC:老年代內存不足時觸發(較少,回收速度慢,會暫停所有用戶線程)。
【4】垃圾回收的詳細過程
JVM 垃圾回收(Garbage Collection,GC)的核心目的是自動釋放不再被使用的對象所占用的內存,避免內存泄漏和溢出。其過程可分為對象存活判定、垃圾標記、垃圾回收、內存整理四個核心階段,結合 JVM 內存分代模型(年輕代、老年代等)會有更具體的執行邏輯。以下是詳細過程:
(1)觸發條件:何時需要垃圾回收?
垃圾回收并非隨時執行,而是當滿足特定條件時觸發,常見觸發條件包括:
(1)年輕代空間不足:對象優先在年輕代的 Eden 區分配,當 Eden 區滿時,觸發Minor GC(僅回收年輕代)。
(2)老年代空間不足:當對象從年輕代晉升到老年代后,若老年代剩余空間不足以容納新對象,觸發Major GC(主要回收老年代,通常伴隨 Minor GC)。
(3)方法區(元空間)不足:當加載的類、常量等信息超過方法區容量時,觸發方法區回收。
(4)手動調用:通過 System.gc() 建議 JVM 執行回收(但 JVM 可忽略該建議)。
(2)階段 1:對象存活判定
垃圾回收的前提是確定 “哪些對象已經死亡(不再被使用)”。JVM 主要通過可達性分析算法判斷對象存活狀態:
(1)核心原理
以 “GC Roots” 為起點,遍歷對象引用鏈(對象之間的引用關系):
1、若一個對象能被 GC Roots 直接或間接引用,則為 “存活對象”;
2、若一個對象無法被 GC Roots 引用(引用鏈斷裂),則為 “可回收對象”。
(2)GC Roots 包含哪些對象?
1、虛擬機棧(棧幀中的局部變量表)中引用的對象(如方法參數、局部變量);
2、方法區中類靜態屬性引用的對象(如 static 變量);
3、方法區中常量引用的對象(如 final 常量);
4、本地方法棧中 Native 方法引用的對象;
5、JVM 內部的引用(如類加載器、基本數據類型對應的 Class 對象)。
(3)階段 2:垃圾標記(確定可回收對象)
通過可達性分析后,需對 “可回收對象” 進行標記,具體分為兩次標記(給對象最后一次 “自救” 機會):
(1)第一次標記
所有不可達對象被初步標記為 “待回收”,但并非立即被回收。此時會檢查對象是否重寫了 finalize() 方法:
1、若未重寫 finalize() 或該方法已執行過,則直接判定為 “可回收”;
2、若重寫了且未執行過,則將對象放入 F-Queue 隊列,由 JVM 自動創建的 Finalizer 線程(低優先級)執行其 finalize() 方法。
(2)第二次標記
Finalizer 線程執行完 F-Queue 中對象的 finalize() 后,JVM 會再次檢查這些對象是否可達:
1、若在 finalize() 中對象重新與 GC Roots 建立引用(如賦值給其他存活對象),則被移除 “待回收” 列表;
2、若仍不可達,則最終標記為 “可回收對象”。
(4)階段 3:垃圾回收(清除可回收對象)
標記完成后,JVM 會根據內存區域(年輕代 / 老年代)的特點,選擇合適的垃圾回收算法清除可回收對象:
(1)年輕代:標記 - 復制算法(Copying)
年輕代對象存活時間短(朝生夕死),回收頻繁,適合用標記 - 復制算法:
年輕代分為 1 個 Eden 區 + 2 個 Survivor 區(From/To),默認比例為 8:1:1;
回收過程:
1、新對象優先分配到 Eden 區和 Survivor From 區;
2、當 Eden 區滿時,觸發 Minor GC,標記 Eden 和 From 區中的存活對象;
3、將存活對象復制到 Survivor To 區(年齡計數器 +1);
4、清空 Eden 區和 From 區,交換 From 和 To 區的角色(下次回收時 To 變為 From);
5、若存活對象體積超過 To 區容量,直接晉升到老年代(“分配擔保” 機制);
6、當對象年齡計數器達到閾值(默認 15,可通過 -XX:MaxTenuringThreshold 調整),也會晉升到老年代。
(2)老年代:標記 - 清除(Mark-Sweep)或標記 - 整理(Mark-Compact)
老年代對象存活時間長(存活率高),回收頻率低,適合用以下算法:
1、標記 - 清除算法:
標記所有可回收對象;
直接清除這些對象,釋放內存。
缺點:會產生大量內存碎片,可能導致后續大對象無法分配連續內存。
2、標記 - 整理算法:
標記所有存活對象;
將存活對象向內存空間的一端移動,集中排列;
清除邊界外的所有內存(即回收對象)。
優點:無內存碎片,適合老年代(避免頻繁復制大對象)。
(5)階段 4:內存整理(可選)
回收后,部分算法(如標記 - 整理、標記 - 復制)會自動完成內存整理,目的是:
(1)消除內存碎片,保證后續大對象能分配到連續內存;
(2)提高內存分配效率(連續內存可快速定位空閑區域)。
(6)垃圾收集器的影響
不同的垃圾收集器(如 SerialGC、ParallelGC、CMS、G1、ZGC 等)會影響回收過程的效率和停頓時間:
(1)SerialGC:單線程執行回收,STW(Stop-The-World)時間長,適合簡單應用;
(2)ParallelGC:多線程回收,注重吞吐量(回收時間占比低);
(3)CMS:并發標記清除,STW 時間短,適合響應時間敏感的應用;
(4)G1/ZGC:區域化分代式收集,兼顧吞吐量和響應時間,支持大堆內存。
【三】jvm常用的配置參數
JVM 參數分為標準參數(如-version)、非標準參數(如-Xms)和高級參數(如-XX:+UseG1GC),以下是開發中最常用的核心參數
【1】內存區域配置(核心)
(1)-Xms:初始堆內存大小
-Xms512m 建議與-Xmx一致,避免頻繁擴容堆
(2)-Xmx:最大堆內存大小
-Xmx1024m 堆內存上限,根據服務器內存調整(如 8G 服務器可設 4G)
(3)-Xmn:年輕代內存大小(Eden+Survivor)
-Xmn256m 年輕代占堆的 1/3~1/2 較合理(小了易頻繁 Minor GC)
(4)-XX:NewRatio:老年代與年輕代的比例(默認 2:1)
-XX:NewRatio=3 老年代:年輕代 = 3:1(即年輕代占堆 1/4)
(5)-XX:SurvivorRatio:Eden 區與 Survivor 區的比例(默認 8:1:1)
-XX:SurvivorRatio=4 Eden:From Survivor:To Survivor=4:1:1
(6)-XX:MetaspaceSize:元空間初始大小(JDK8+,替代永久代)
-XX:MetaspaceSize=128m 元空間不足時會擴容,直到MaxMetaspaceSize
(7)-XX:MaxMetaspaceSize:元空間最大大小
-XX:MaxMetaspaceSize=256m 避免元空間無限增長(默認無上限)
(8)-Xss:每個線程的棧內存大小
-Xss256k
【2】垃圾收集器配置
(1)-XX:+UseSerialGC 使用串行收集器(年輕代 Serial + 老年代 Serial Old) 單線程環境、小內存應用(如桌面程序)
(2)-XX:+UseParallelGC 年輕代使用 Parallel Scavenge(并行收集) 多 CPU、批處理應用(追求吞吐量)
(3)-XX:+UseParallelOldGC 老年代使用 Parallel Old(并行收集) 與UseParallelGC配合,適合吞吐量優先
(4)-XX:+UseConcMarkSweepGC 老年代使用 CMS 收集器(并發標記清除) 低延遲應用(如 Web 服務,避免長時間停頓)
(5)-XX:+UseG1GC 使用 G1 收集器(區域化分代式) 大堆(>4G)、低延遲 + 高吞吐量兼顧場景
(6)-XX:MaxGCPauseMillis G1 目標最大停頓時間(默認 200ms) -XX:MaxGCPauseMillis=100 調小可減少停頓,但可能增加 GC 頻率
【3】日志與調試配置
(1)-XX:+PrintGCDetails 打印詳細 GC 日志 配合-Xloggc:gc.log輸出到文件
(2)-XX:+PrintGCDateStamps GC 日志帶時間戳 便于分析 GC 發生時間點
(4)-XX:+HeapDumpOnOutOfMemoryError OOM 時自動生成堆轉儲文件(.hprof) -XX:HeapDumpPath=./oom.hprof 用于后續分析內存溢出原因
(4)-verbose:class 打印類加載日志 排查類沖突、類重復加載問題
【4】JVM 優化案例
(1)場景 1:Web 應用頻繁 Minor GC,響應時間長
問題現象:
某 Spring Boot 應用(處理用戶請求)頻繁卡頓,監控發現每秒發生 3-5 次 Minor GC,每次耗時 50ms 以上,影響接口響應時間(P99>500ms)。
分析:
查看 GC 日志(通過-XX:+PrintGCDetails -Xloggc:gc.log),發現年輕代(Eden 區)僅 512MB,而應用每秒創建大量臨時對象(如請求 DTO、JSON 序列化對象),Eden 區很快填滿,導致頻繁 Minor GC。
老年代使用率穩定(約 30%),無 Full GC,排除老年代問題。
優化措施:
調整年輕代大小:增大 Eden 區,減少 Minor GC 頻率。
原參數:-Xms2g -Xmx2g -Xmn512m(年輕代 512M,老年代 1.5G)
新參數:-Xms4g -Xmx4g -Xmn2g(年輕代 2G,占堆的 50%,Eden 區約 1.6G)。
效果:
Minor GC 頻率降至每 30 秒 1 次,每次耗時 10-20ms。
接口 P99 降至 200ms 以內,卡頓消失。
(2)場景 2:大內存應用(8G 堆)Full GC 頻繁,停頓時間長
問題現象:
某數據分析應用(堆內存 8G)每小時發生 2-3 次 Full GC,每次停頓 1-2 秒,導致任務執行中斷。
分析:
原使用ParallelGC(吞吐量優先),老年代采用Parallel Old收集器,Full GC 時會 Stop The World(STW),對 8G 堆進行標記 - 整理,耗時較長。
應用中存在大對象(如 100MB + 的數據集),直接進入老年代,導致老年代碎片化嚴重,觸發 Full GC。
優化措施:
切換為 G1 收集器(適合大堆、低延遲),并設置目標停頓時間。
新參數:-Xms8g -Xmx8g -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:InitiatingHeapOccupancyPercent=70
(InitiatingHeapOccupancyPercent=70:堆占用 70% 時觸發 G1 的混合收集,提前清理老年代)。
效果:
Full GC 消除,改為 G1 的混合收集(部分老年代區域被回收),每次 STW 停頓控制在 200ms 以內。
任務執行流暢,無中斷。
【5】參數調優原則
先監控(GC 頻率、內存使用率、停頓時間),再優化,避免盲目調參。
堆內存:-Xms與-Xmx一致,年輕代占比 1/3~1/2(視對象生命周期)。
收集器:小堆(<4G)用ParallelGC,大堆(>4G)用G1,低延遲用CMS(注意 CMS 的內存碎片問題)。
【四】內存溢出(OOM):當內存不足時
內存溢出(OutOfMemoryError)是指 JVM 無法為新對象分配內存,且垃圾回收也無法釋放足夠空間的情況。不同內存區域的溢出原因和案例如下:
【1】堆內存溢出(最常見)
原因:創建大量對象且長期被引用(無法被 GC 回收),導致堆內存耗盡。
import java.util.ArrayList;
import java.util.List;public class HeapOOM {static class OOMObject {}public static void main(String[] args) {List<OOMObject> list = new ArrayList<>();while (true) {list.add(new OOMObject()); // 不斷創建對象并引用,無法回收}}
}
設置堆內存大小(限制為 20MB):
java -Xms20m -Xmx20m HeapOOM
運行后會拋出:
java.lang.OutOfMemoryError: Java heap space(堆內存不足)。
【2】虛擬機棧溢出
原因:方法調用棧深度過大(如無限遞歸),或創建過多線程(每個線程占用獨立棧空間)。
(1)案例 1:遞歸過深
public class StackOverflow {private int depth = 0;public void recursion() {depth++;recursion(); // 無限遞歸,棧幀不斷入棧}public static void main(String[] args) {StackOverflow oom = new StackOverflow();try {oom.recursion();} catch (StackOverflowError e) {System.out.println("棧深度:" + oom.depth);throw e;}}
}
結果:拋出 StackOverflowError(棧深度超過最大限制)。
(2)案例 2:線程過多
public class StackOOM {public static void main(String[] args) {while (true) {new Thread(() -> {try {Thread.sleep(Integer.MAX_VALUE); // 線程不結束,占用棧空間} catch (InterruptedException e) {}}).start();}}
}
結果:拋出 OutOfMemoryError: Unable to create new native thread(棧內存不足,無法創建新線程)。
【3】方法區(元空間)溢出
原因:動態生成大量類(如反射、CGLib 代理),導致方法區存儲的類信息過多。
案例代碼(需引入 CGLib 依賴):
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;public class MethodAreaOOM {static class OOMClass {}public static void main(String[] args) {while (true) {Enhancer enhancer = new Enhancer();enhancer.setSuperclass(OOMClass.class);enhancer.setUseCache(false); // 禁用緩存,每次生成新類enhancer.setCallback((MethodInterceptor) (obj, method, args1, proxy) -> proxy.invokeSuper(obj, args1));enhancer.create(); // 動態生成OOMClass的子類(新類)}}
}
運行與結果:
設置元空間大小(限制為 10MB):
java -XX:MetaspaceSize=10m -XX:MaxMetaspaceSize=10m MethodAreaOOM
運行后拋出:
java.lang.OutOfMemoryError: Metaspace(元空間內存不足)。
【4】內存溢出(OOM)排查與解決案例
(1)場景:堆內存溢出(Java heap space)
問題:某電商平臺促銷期間,商品詳情頁接口頻繁報OutOfMemoryError: Java heap space,導致服務宕機。
(2)排查步驟
(1)開啟 OOM 自動 dump:
重啟服務時添加參數:-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./heapdump.hprof,確保 OOM 時生成堆轉儲文件。
(2)復現問題并獲取 dump:
促銷流量觸發 OOM 后,得到heapdump.hprof文件(約 2G)。
(3)分析堆轉儲文件:
使用工具MAT(Eclipse Memory Analyzer Tool) 打開 dump 文件:
查看 “Histogram”(對象直方圖),發現HashMap實例占用 60% 堆內存,其中存儲了大量Product對象。
查看 “Dominator Tree”(支配樹),發現ProductCache類的靜態變量cacheMap引用了該HashMap,且cacheMap的 size 超過 100 萬(正常應緩存 10 萬以內)。
(4)定位代碼問題:
檢查ProductCache代碼,發現緩存清理邏輯錯誤:僅在添加時判斷大小,未在過期時移除舊數據,導致cacheMap無限增長,對象無法被 GC 回收。
(3)解決措施
(1)修復緩存邏輯:
將HashMap替換為LinkedHashMap,重寫removeEldestEntry方法,當緩存數量超過 10 萬時自動移除最舊數據。
public class ProductCache {private static final int MAX_SIZE = 100000;private static Map<Long, Product> cacheMap = new LinkedHashMap<Long, Product>(MAX_SIZE, 0.75f, true) {@Overrideprotected boolean removeEldestEntry(Map.Entry<Long, Product> eldest) {return size() > MAX_SIZE; // 超過上限時移除最舊元素}};
}
(2)臨時調大堆內存:
促銷期間臨時調整參數:-Xms6g -Xmx6g,避免短期內再次 OOM。
(3)監控驗證:
修復后,cacheMap大小穩定在 10 萬左右,堆內存使用率降至 40%,OOM 不再發生。
(4)總結流程
① 開啟堆 dump(-XX:+HeapDumpOnOutOfMemoryError)→ ② 用 MAT/JProfiler 分析 dump,定位泄漏對象 → ③ 檢查代碼中不合理的引用(如靜態集合未清理、長生命周期對象持有短生命周期對象)→ ④ 修復并驗證。






)

![P3232 [HNOI2013] 游走,solution](http://pic.xiahunao.cn/P3232 [HNOI2013] 游走,solution)


介紹)

)



如何使用MySQL的慢查詢工具?)
)
