關注gongzhonghao【計算機sci論文精選】
3D傳感技術起源于工業領域高精度測量需求,早期以激光三角測量、結構光等技術為主,主要服務于制造業的零部件檢測與形變分析。隨著消費電子智能化升級,蘋果iPhone X的Face ID將結構光技術推向大眾市場,微軟Kinect、華為Mate 30 Pro等產品進一步驗證了ToF方案的商用價值。
今天小圖給大家精選3篇AAAI有關3D傳感方向的論文,帶大家探索3D傳感技術的奧秘!
論文一:SimDistill: Simulated Multi-modal Distillation for BEV 3D Object Detection
方法:
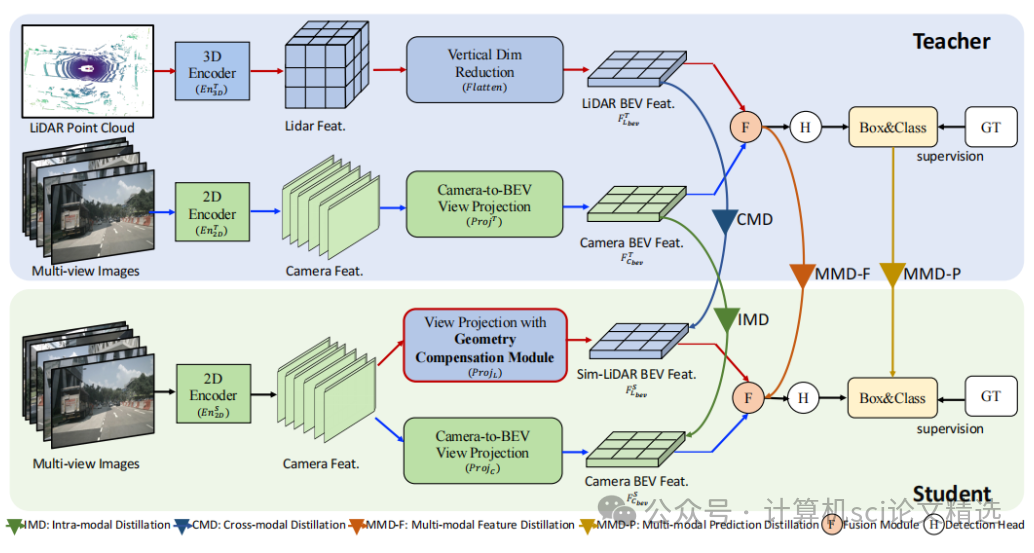
文章首先設計了多模態架構,包括基于BEVFusion的教師模型和基于BEVFusion-C的學生模型,并在學生模型中引入額外的模擬激光雷達分支來模擬激光雷達特征。接著,提出了模擬多模態蒸餾方案,涵蓋模態內蒸餾、跨模態蒸餾以及多模態融合蒸餾,并采用均方誤差損失和質量感知預測蒸餾來實現知識轉移。最后,通過在nuScenes數據集上進行實驗,證明了該方法在提升3D目標檢測性能方面的有效性。
創新點:
提出了一種獨特的多模態蒸餾框架,通過確保教師和學生模型具有幾乎相同的流程,有效減少了模態間的差距。
呈現了一種新的模擬多模態蒸餾方案,可同時支持模態內、跨模態以及多模態融合蒸餾,輕松適應不同模型。
在nuScenes基準測試中,通過廣泛的實驗和消融研究驗證了SimDistill的有效性和優越性,相較于現有方法,分別提高了基線檢測器的mAP和NDS指標4.8%和4.1%。
論文鏈接:
?https://arxiv.org/abs/2303.16818
圖靈學術論文輔導
論文二:ScanERU: Interactive 3D Visual Grounding based on Embodied Reference Understanding
方法:
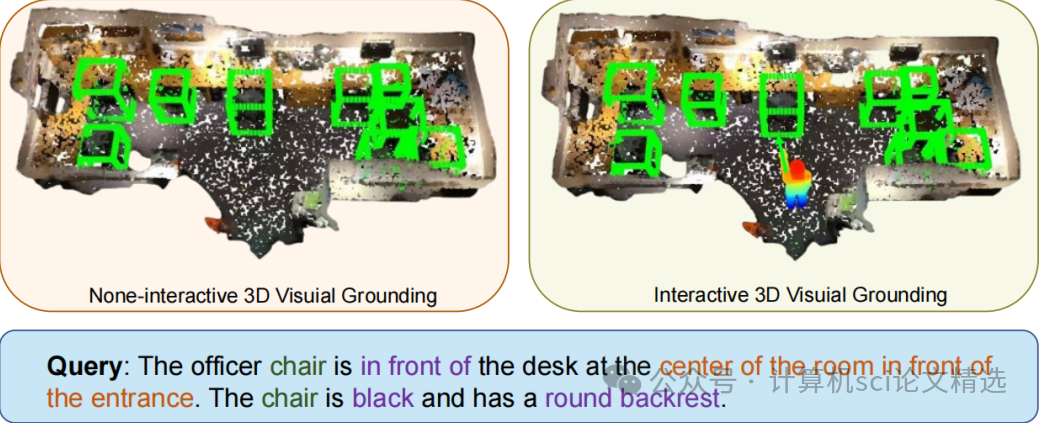
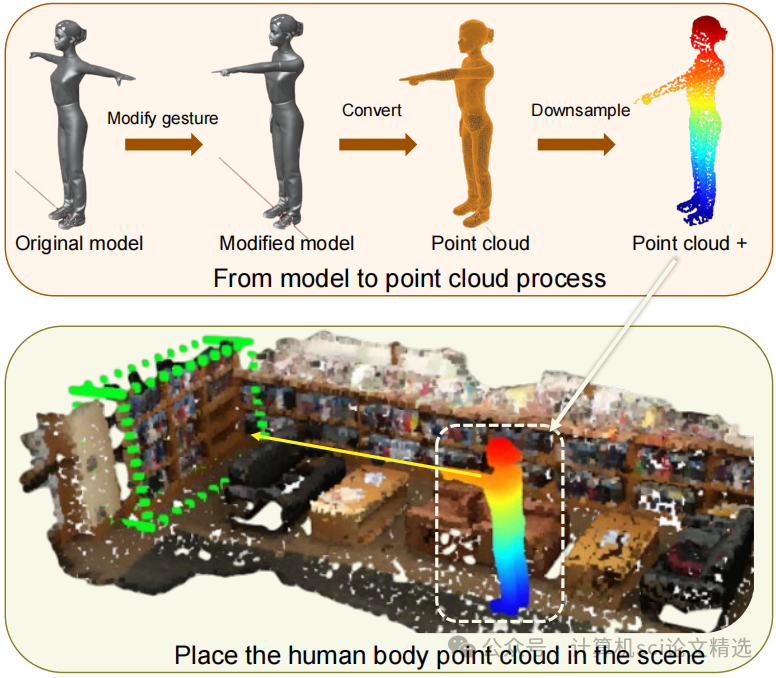
文章通過構建新的ScanERU數據集引入了具身引用理解任務,該數據集融合了文本、視覺和姿態信息。接著,提出了一種包含提案生成、姿態編碼、語言編碼和多模態融合模塊的框架,利用注意力機制整合不同模態的特征,最終通過優化定義的損失函數來訓練模型,從而實現對3D場景中被引用物體的精準定位。
創新點:
首次設計了面向3D點云環境的具身引用理解任務,將語言和姿態信息聯合用于物體引用。
構建了ScanERU數據集,這是首個涵蓋文本、真實視覺和合成姿態信息的半合成場景數據集。
提出了一種基于注意力機制和人體運動的啟發式框架,有效提高了對多個相同物體或復雜空間關系的識別能力。
論文鏈接:
https://arxiv.org/abs/2303.13186
圖靈學術論文輔導
論文三:DI-V2X: Learning Domain-Invariant Representation for Vehicle-Infrastructure Collaborative 3D Object Detection
方法:
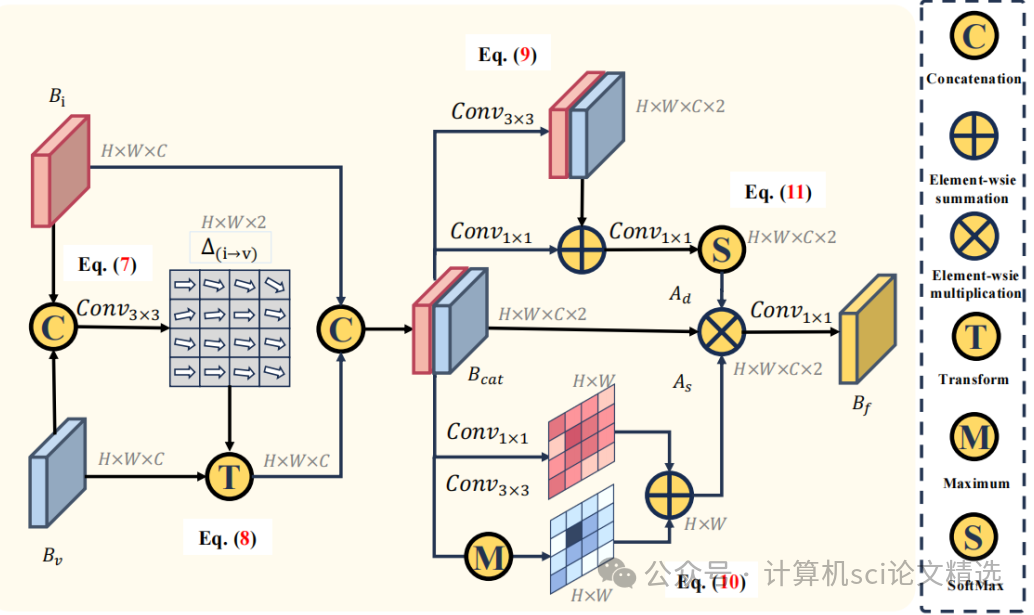
文章采用教師-學生蒸餾框架,通過DMA模塊增強輸入數據多樣性,PDD模塊在融合前后分別進行知識蒸餾,DAF模塊則融合不同領域的特征,最終在DAIR-V2X和V2XSet數據集上驗證了模型的優越性能。
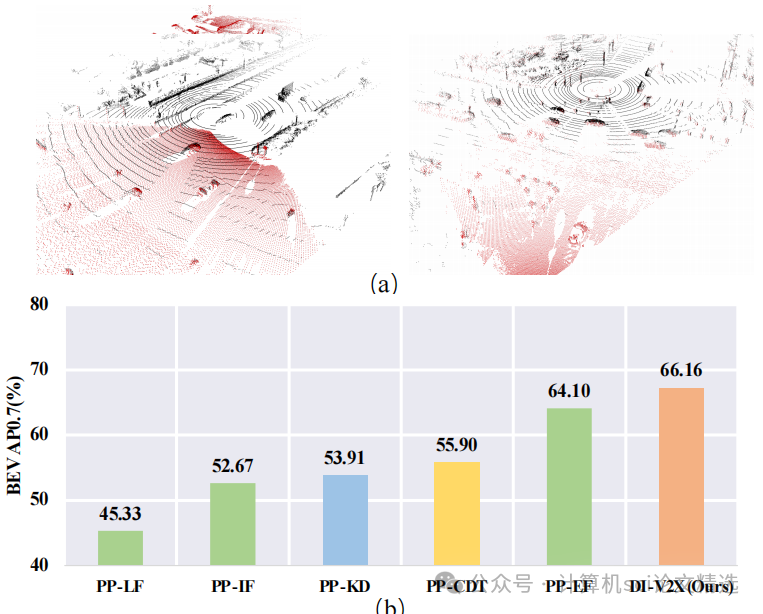
創新點:
首次引入領域混合實例增強模塊,通過構建混合領域實例庫,有效對齊教師和學生模型的數據分布。
提出漸進式領域不變蒸餾模塊,利用重疊區域信息引導知識蒸餾,使學生模型逐步學習領域不變特征。
設計領域自適應融合模塊,結合校準感知的領域自適應注意力,增強特征融合效果,提升模型對姿態誤差的魯棒性。
論文鏈接:
https://arxiv.org/abs/2312.15742
本文選自gongzhonghao【計算機sci論文精選】



LogisticRegression)



接口監控)

)

)


和 ::v-deep選擇器的區別)



![【BUUCTF系列】[極客大挑戰 2019]LoveSQL 1](http://pic.xiahunao.cn/【BUUCTF系列】[極客大挑戰 2019]LoveSQL 1)
