bg:對比決策樹來說,搞多幾棵樹就是隨機森林了
????????
rlf_1 = []
rlf_2 = []
for i in range(10):rfc = RandomForestClassifier(n_estimators=25)rfc_s = cross_val_score(rfc, wine.data, wine.target, cv=10).mean()rlf_1.append(rfc_s)clf = DecisionTreeClassifier()clf_s = cross_val_score(clf, wine.data, wine.target, cv=10).mean()rlf_2.append(clf_s)plt.plot(range(1, 11), rlf_1, label="Random Forest")
plt.plot(range(1, 11), rlf_2, label="Decision Forest")
plt.legend()
plt.show()? ?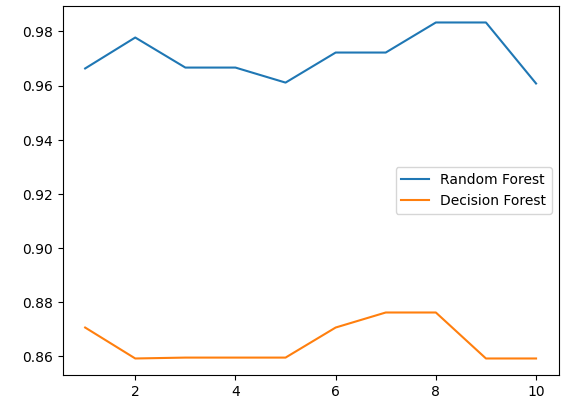
一、參數
? ? ?1、n_estimatiors
? ? ? ? ????????越大就效果越好,同時也消耗更多資源
superpa = []
for i in range(200):rfc = RandomForestClassifier(n_estimators=i+1, n_jobs=-1) # n_jobs是調整調用的cpu核心rfc_s = cross_val_score(rfc, wine.data, wine.target, cv=10).mean()superpa.append(rfc_s)
print(max(superpa), superpa.index(max(superpa)))
plt.figure(figsize=[20, 5]) # 調整生成的尺寸
plt.plot(range(1, 201), superpa)
plt.show()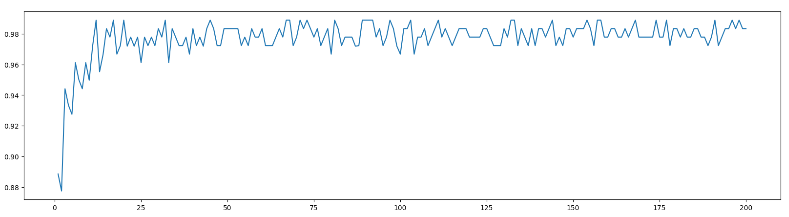
? ? ?2、n_jobs
? ? ? ? ? ? ? ? 調用的cpu核心,-1就是調用全部
? ? ?3、oob_score
? ? ? ? ? ? ? ? true的時候,所有的數據都會用于測試和訓練,對單棵樹自動分測試和訓練集,如果想要整個森林的測試得分就直接“模型.oob_score_”。
二、接口
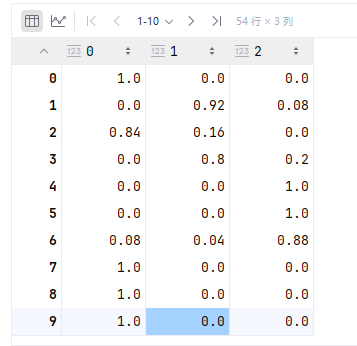
? ? ? ? 1、predict_proba
? ? ? ? ? ? ? ? 在每個target的概率
????????



)



)
 視頻教程 - 微博評論數據可視化分析-點贊區間折線圖實現)




配置測試)


)
)

)