深度學習 — 過擬合與欠擬合
文章目錄
- 深度學習 --- 過擬合與欠擬合
- 一.概念
- 1.1 過擬合
- 1.2 欠擬合
- 1.3 判斷方式
- 二,解決欠擬合
- 三,解決過擬合
- 3.1 L2正則化
- 3.1.1 定義以及作用
- 3.1.2 代碼
- 3.2 L1正則化
- 3.3 L1與L2對比
- 3.4 Dropout
- 示例
- 3.5 數據增強
- 3.5.1 圖片縮放
- 3.5.2 隨機裁剪
- 3.5.3 隨機水平翻轉
- 3.5.4 調整圖片顏色
- 3.5.5 隨機旋轉
- 3.5.6 圖片轉Tensor
- 3.5.7 Tensor轉圖片
- 3.5.8 歸一化
- 3.5.9 數據增強整合
一.概念
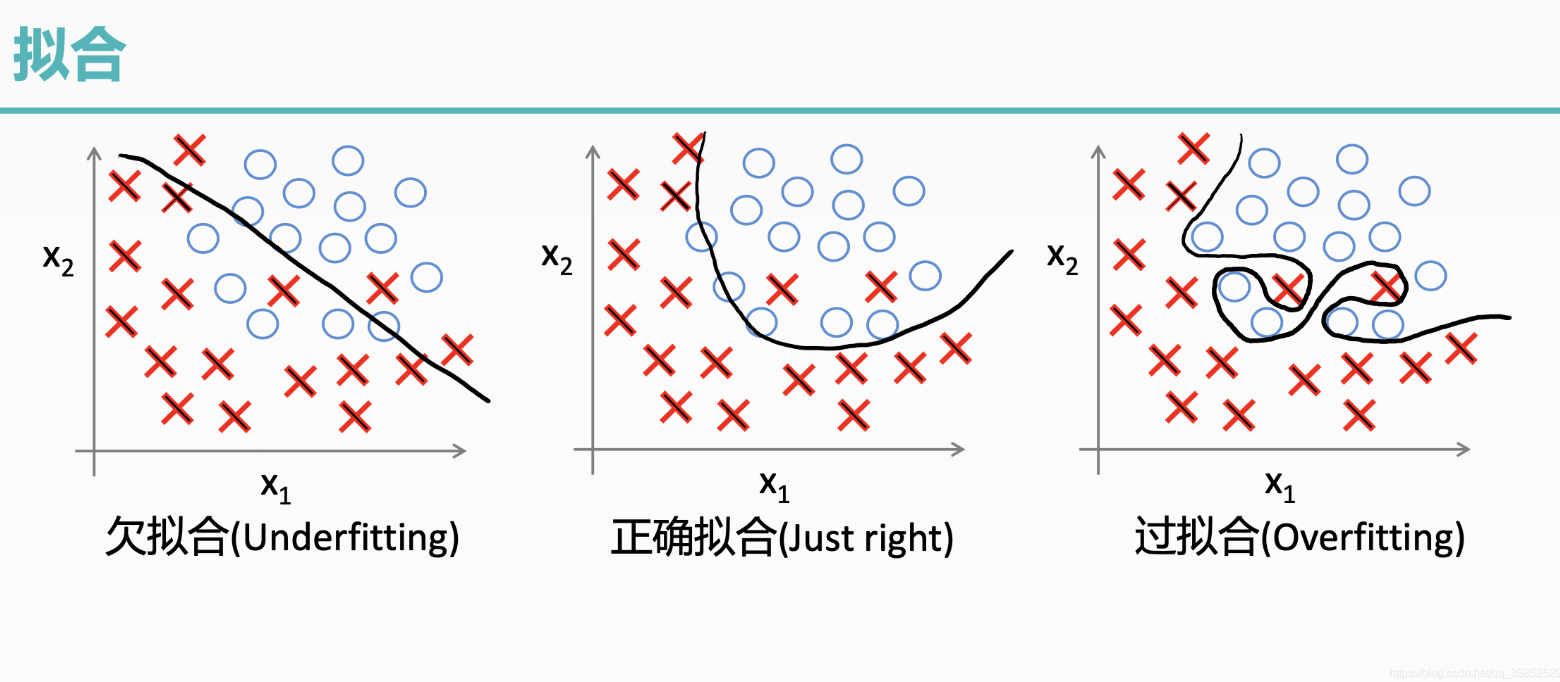
1.1 過擬合
過擬合是指模型對訓練數據擬合能力很強并表現很好,但在測試數據上表現較差。
過擬合常見原因有:
- 數據量不足:當訓練數據較少時,模型可能會過度學習數據中的噪聲和細節。
- 模型太復雜:如果模型很復雜,也會過度學習訓練數據中的細節和噪聲。
- 正則化強度不足:如果正則化強度不足,可能會導致模型過度學習訓練數據中的細節和噪聲。
1.2 欠擬合
欠擬合是由于模型學習能力不足,無法充分捕捉數據中的復雜關系。
1.3 判斷方式
過擬合
? 訓練誤差低,但驗證時誤差高。模型在訓練數據上表現很好,但在驗證數據上表現不佳,說明模型可能過度擬合了訓練數據中的噪聲或特定模式。
欠擬合
? 訓練誤差和測試誤差都高。模型在訓練數據和測試數據上的表現都不好,說明模型可能太簡單,無法捕捉到數據中的復雜模式。
二,解決欠擬合
欠擬合的解決思路比較直接:
- 增加模型復雜度:引入更多的參數、增加神經網絡的層數或節點數量,使模型能夠捕捉到數據中的復雜模式。
- 增加特征:通過特征工程添加更多有意義的特征,使模型能夠更好地理解數據。
- 減少正則化強度:適當減小 L1、L2 正則化強度,允許模型有更多自由度來擬合數據。
- 訓練更長時間:如果是因為訓練不足導致的欠擬合,可以增加訓練的輪數或時間.
三,解決過擬合
避免模型參數過大是防止過擬合的關鍵步驟之一。
模型的復雜度主要由權重w決定,而不是偏置b。偏置只是對模型輸出的平移,不會導致模型過度擬合數據。
怎么控制權重w,使w在比較小的范圍內?
考慮損失函數,損失函數的目的是使預測值與真實值無限接近,如果在原來的損失函數上添加一個非0的變量
L1(y^,y)=L(y^,y)+f(w)L_1(\hat{y},y) = L(\hat{y},y) + f(w) L1?(y^?,y)=L(y^?,y)+f(w)
其中f(w)f(w)f(w)是關于權重w的函數,f(w)>0f(w)>0f(w)>0
要使L1變小,就要使L變小的同時,也要使f(w)f(w)f(w)變小。從而控制權重w在較小的范圍內。
3.1 L2正則化
L2 正則化通過在損失函數中添加權重參數的平方和來實現,目標是懲罰過大的參數值。
3.1.1 定義以及作用
| 維度 | 內容 | 數學表達式 | 解釋與作用 |
|---|---|---|---|
| 原始損失函數 | 模型未加正則化的損失函數(如 MSE、交叉熵) | L(θ)L(\theta)L(θ) | 僅衡量模型在訓練數據上的誤差。 |
| L2 正則化項 | 所有權重參數的平方和 | 12∑iθi2\frac{1}{2} \sum_i \theta_i^221?∑i?θi2? | 懲罰大權重,防止模型復雜度過高。 |
| 總損失函數 | 原始損失 + L2 正則化項 | Ltotal(θ)=L(θ)+λ2∑iθi2L_{\text{total}}(\theta) = L(\theta) + \frac{\lambda}{2} \sum_i \theta_i^2Ltotal?(θ)=L(θ)+2λ?∑i?θi2? | 加入懲罰項,平衡擬合能力與復雜度。 |
| 梯度更新規則 | 參數更新時考慮原始梯度 + L2 項的梯度 | θt+1=θt?η(?L(θt)+λθt)\theta_{t+1} = \theta_t - \eta \left( \nabla L(\theta_t) + \lambda \theta_t \right)θt+1?=θt??η(?L(θt?)+λθt?) | 每次更新都“衰減”參數(乘以 1?ηλ1 - \eta \lambda1?ηλ),防止權重過大。 |
| 12\frac{1}{2}21? 的作用 | 簡化梯度計算 | ??θi(12θi2)=θi\frac{\partial}{\partial \theta_i} \left( \frac{1}{2} \theta_i^2 \right) = \theta_i?θi???(21?θi2?)=θi? | 消去系數 2,使梯度更新公式更簡潔(避免 2λθi2\lambda \theta_i2λθi?)。 |
| 防止過擬合 | 抑制權重過大,降低模型對訓練噪聲的敏感性 | - | 權重越小,模型對輸入擾動越不敏感,泛化能力增強。 |
| 限制模型復雜度 | 強制權重接近 0,避免過擬合 | - | 通過懲罰大權重,減少模型自由度,降低 VC 維。 |
| 提高泛化能力 | 在訓練集和測試集上表現更均衡 | - | 正則化項使模型更關注數據的真實規律,而非噪聲。 |
| 平滑權重分布 | 權重逐漸縮小但不直接為 0 | - | 保留所有特征貢獻,避免稀疏性(與 L1 不同),使模型更平滑。 |
3.1.2 代碼
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt# 設置隨機種子以保證可重復性
torch.manual_seed(42)# 生成隨機數據
n_samples = 100
n_features = 20
X = torch.randn(n_samples, n_features) # 輸入數據
y = torch.randn(n_samples, 1) # 目標值# 定義一個簡單的全連接神經網絡
class SimpleNet(nn.Module):def __init__(self):super(SimpleNet, self).__init__()self.fc1 = nn.Linear(n_features, 50)self.fc2 = nn.Linear(50, 1)def forward(self, x):x = torch.relu(self.fc1(x))return self.fc2(x)# 訓練函數
def train_model(use_l2=False, weight_decay=0.01, n_epochs=100):# 初始化模型model = SimpleNet()criterion = nn.MSELoss() # 損失函數(均方誤差)# 選擇優化器if use_l2:optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=weight_decay) # 使用 L2 正則化else:optimizer = optim.SGD(model.parameters(), lr=0.01) # 不使用 L2 正則化# 記錄訓練損失train_losses = []# 訓練過程for epoch in range(n_epochs):optimizer.zero_grad() # 清空梯度outputs = model(X) # 前向傳播loss = criterion(outputs, y) # 計算損失loss.backward() # 反向傳播optimizer.step() # 更新參數train_losses.append(loss.item()) # 記錄損失if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch + 1}/{n_epochs}], Loss: {loss.item():.4f}')return train_losses# 訓練并比較兩種模型
train_losses_no_l2 = train_model(use_l2=False) # 不使用 L2 正則化
train_losses_with_l2 = train_model(use_l2=True, weight_decay=0.01) # 使用 L2 正則化# 繪制訓練損失曲線
plt.plot(train_losses_no_l2, label='Without L2 Regularization')
plt.plot(train_losses_with_l2, label='With L2 Regularization')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss: L2 Regularization vs No Regularization')
plt.legend()
plt.show()
3.2 L1正則化
設模型的原始損失函數為 L(θ)L(\theta)L(θ),其中 θ\thetaθ 表示模型權重參數,則加入 L1 正則化后的損失函數表示為:
Ltotal(θ)=L(θ)+λ∑i∣θi∣L_{\text{total}}(\theta) = L(\theta) + \lambda \sum_{i} |\theta_i| Ltotal?(θ)=L(θ)+λi∑?∣θi?∣
- 梯度更新
在 L1 正則化下,梯度更新時的公式是:
θt+1=θt?η(?L(θt)+λ?sign(θt))\theta_{t+1} = \theta_t - \eta \left( \nabla L(\theta_t) + \lambda \cdot \text{sign}(\theta_t) \right) θt+1?=θt??η(?L(θt?)+λ?sign(θt?)) - 作用:
-
稀疏性:L1 正則化的一個顯著特性是它會促使許多權重參數變為 零。這是因為 L1 正則化傾向于將權重絕對值縮小到零,使得模型只保留對結果最重要的特征,而將其他不相關的特征權重設為零,從而實現 特征選擇 的功能。
-
防止過擬合:通過限制權重的絕對值,L1 正則化減少了模型的復雜度,使其不容易過擬合訓練數據。相比于 L2 正則化,L1 正則化更傾向于將某些權重完全移除,而不是減小它們的值。
-
簡化模型:由于 L1 正則化會將一些權重變為零,因此模型最終會變得更加簡單,僅依賴于少數重要特征。這對于高維度數據特別有用,尤其是在特征數量遠多于樣本數量的情況下。
-
特征選擇:因為 L1 正則化會將部分權重置零,因此它天然具有特征選擇的能力,有助于自動篩選出對模型預測最重要的特征。
3.3 L1與L2對比
| 特性 | L2 正則化(Ridge) | L1 正則化(Lasso) |
|---|---|---|
| 懲罰項 | ∑iθi2\sum_i \theta_i^2∑i?θi2? | ∑_iθ_i\sum\_i \theta\_i∑_iθ_i |
| 效果 | 權重平滑趨近于 0 | 權重稀疏(部分變為 0) |
| 梯度 | λθi\lambda \theta_iλθi? | λ?sign(θi)\lambda \cdot \text{sign}(\theta_i)λ?sign(θi?) |
| 適用場景 | 特征共線性強、需要保留所有特征 | 特征選擇(自動忽略無關特征) |
3.4 Dropout
Dropout 的工作流程如下:
- 在每次訓練迭代中,隨機選擇一部分神經元(通常以概率 p丟棄,比如 p=0.5)。
- 被選中的神經元在當前迭代中不參與前向傳播和反向傳播。
- 在測試階段,所有神經元都參與計算,但需要對權重進行縮放(通常乘以 1?p),以保持輸出的期望值一致。
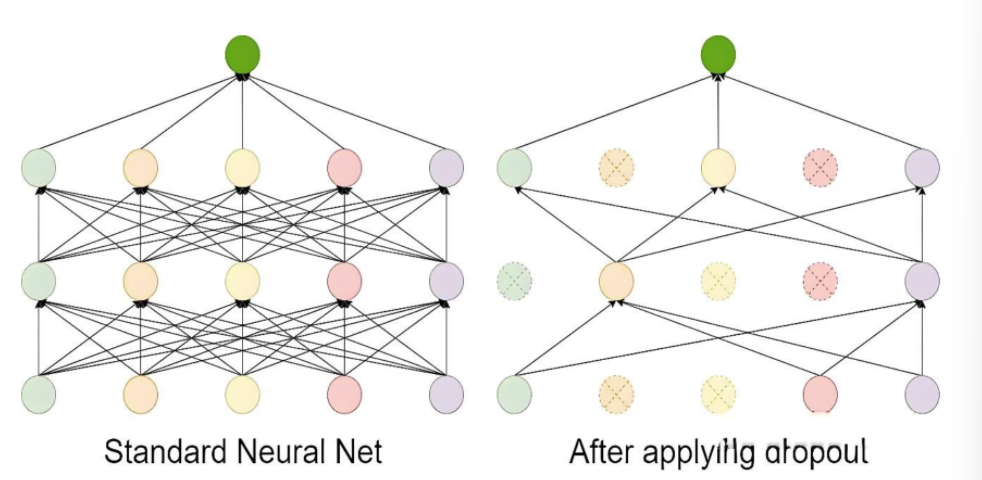
Dropout 是一種在訓練過程中隨機丟棄部分神經元的技術。它通過減少神經元之間的依賴來防止模型過于復雜,從而避免過擬合。
import torchimport torch.nn as nndef test01():x=torch.randint(1,10,(5,5),dtype=torch.float)dropout=nn.Dropout(p=0.5)print(x)print(dropout(x))if __name__ == '__main__':test01()示例
對圖片進行隨機丟棄
import torch
from torch import nn
from PIL import Image
from torchvision import transforms
import osfrom matplotlib import pyplot as plttorch.manual_seed(42)def load_img(path, resize=(224, 224)):pil_img = Image.open(path).convert('RGB')print("Original image size:", pil_img.size) # 打印原始尺寸transform = transforms.Compose([transforms.Resize(resize),transforms.ToTensor() # 轉換為Tensor并自動歸一化到[0,1]])return transform(pil_img) # 返回[C,H,W]格式的tensorif __name__ == '__main__':dirpath = os.path.dirname(__file__)path = os.path.join(dirpath, 'img', 'torch-fcnn/fcnn-demo/100.jpg') # 使用os.path.join更安全# 加載圖像 (已經是[0,1]范圍的Tensor)trans_img = load_img(path)# 添加batch維度 [1, C, H, W],因為Dropout默認需要4D輸入trans_img = trans_img.unsqueeze(0)# 創建Dropout層dropout = nn.Dropout2d(p=0.2)drop_img = dropout(trans_img)# 移除batch維度并轉換為[H,W,C]格式供matplotlib顯示trans_img = trans_img.squeeze(0).permute(1, 2, 0).numpy()drop_img = drop_img.squeeze(0).permute(1, 2, 0).numpy()# 確保數據在[0,1]范圍內drop_img = drop_img.clip(0, 1)# 顯示圖像fig = plt.figure(figsize=(10, 5))ax1 = fig.add_subplot(1, 2, 1)ax1.imshow(trans_img)ax2 = fig.add_subplot(1, 2, 2)ax2.imshow(drop_img)plt.show()
3.5 數據增強
樣本數量不足(即訓練數據過少)是導致過擬合(Overfitting)的常見原因之一,可以從以下角度理解:
- 當訓練數據過少時,模型容易“記住”有限的樣本(包括噪聲和無關細節),而非學習通用的規律。
- 簡單模型更可能捕捉真實規律,但數據不足時,復雜模型會傾向于擬合訓練集中的偶然性模式(噪聲)。
- 樣本不足時,訓練集的分布可能與真實分布偏差較大,導致模型學到錯誤的規律。
- 小數據集中,個別樣本的噪聲(如標注錯誤、異常值)會被放大,模型可能將噪聲誤認為規律。
數據增強(Data Augmentation)是一種通過人工生成或修改訓練數據來增加數據集多樣性的技術,常用于解決過擬合問題。數據增強通過“模擬”更多訓練數據,迫使模型學習泛化性更強的規律,而非訓練集中的偶然性模式。其本質是一種低成本的正則化手段,尤其在數據稀缺時效果顯著。
在了解計算機如何處理圖像之前,需要先了解圖像的構成元素。
圖像是由像素點組成的,每個像素點的值范圍為: [0, 255], 像素值越大意味著較亮。比如一張 200x200 的圖像, 則是由 40000 個像素點組成, 如果每個像素點都是 0 的話, 意味著這是一張全黑的圖像。
我們看到的彩色圖一般都是多通道的圖像, 所謂多通道可以理解為圖像由多個不同的圖像層疊加而成, 例如我們看到的彩色圖像一般都是由 RGB 三個通道組成的,還有一些圖像具有 RGBA 四個通道,最后一個通道為透明通道,該值越小,則圖像越透明。
數據增強是提高模型泛化能力(魯棒性)的一種有效方法,尤其在圖像分類、目標檢測等任務中。數據增強可以模擬更多的訓練樣本,從而減少過擬合風險。數據增強通過torchvision.transforms模塊來實現。
3.5.1 圖片縮放
def test01():path="torch-fcnn/fcnn-demo/datasets/100.jpg"img=Image.open(path)print(img.size)transform=transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor()])t_img=transform(img)print(t_img.shape)t_img = torch.permute(t_img, (1, 2, 0))plt.imshow(t_img)plt.show()3.5.2 隨機裁剪
def test02():path="torch-fcnn/fcnn-demo/datasets/100.jpg"img=Image.open(path)print(img.size)transform=transforms.Compose([transforms.RandomCrop((224,224)),transforms.ToTensor()])t_img=transform(img)# print(t_img.shape)t_img = torch.permute(t_img, (1, 2, 0))plt.imshow(t_img)plt.show()3.5.3 隨機水平翻轉
def test03():path="torch-fcnn/fcnn-demo/datasets/100.jpg"img=Image.open(path)print(img.size)transform=transforms.Compose([transforms.RandomHorizontalFlip(p=1),transforms.ToTensor()])t_img=transform(img)# print(t_img.shape)t_img = torch.permute(t_img, (1, 2, 0))plt.imshow(t_img)plt.show()3.5.4 調整圖片顏色
img = Image.open('./img/100.jpg')transform = transforms.Compose([transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2), transforms.ToTensor()])r_img = transform(img)print(r_img.shape)r_img = r_img.permute(1, 2, 0)plt.imshow(r_img)plt.show()
3.5.5 隨機旋轉
def test04():path="torch-fcnn/fcnn-demo/datasets/100.jpg"img=Image.open(path)print(img.size)transform=transforms.RandomRotation((30,60), expand=False, center=None, fill=0)
3.5.6 圖片轉Tensor
def test05():t=torch.randn(3,224,224)transform=transforms.Compose([# 轉換為PIL圖片transforms.ToPILImage(),transforms.ToTensor(),])t_img=transform(t)# print(t_img.shape)t_img = torch.permute(t_img, (1, 2, 0))plt.imshow(t_img)plt.show()
3.5.7 Tensor轉圖片
import torch
from PIL import Image
from torchvision import transformsdef test002():# 1. 隨機一個數據表示圖片img_tensor = torch.randn(3, 224, 224)# 2. 創建一個transformstransform = transforms.ToPILImage()# 3. 轉換為圖片img = transform(img_tensor)img.show()# 4. 保存圖片img.save("./test.jpg")if __name__ == "__main__":test002()
3.5.8 歸一化
def test06():path="torch-fcnn/fcnn-demo/datasets/100.jpg"img=Image.open(path)print(img.size)t=torch.randn(3,224,224)transform = transforms.Compose([transforms.ToTensor(),# 歸一化transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])t_img=transform(t)# print(t_img.shape)t_img = torch.permute(t_img, (1, 2, 0))plt.imshow(t_img)plt.show()
3.5.9 數據增強整合
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import torch
from torchvision import transforms, datasets, utilsdef test01():# 定義數據增強和歸一化transform = transforms.Compose([transforms.RandomHorizontalFlip(), # 隨機水平翻轉transforms.RandomRotation(10), # 隨機旋轉 ±10 度transforms.RandomResizedCrop(32, scale=(0.8, 1.0)), # 隨機裁剪到 32x32,縮放比例在0.8到1.0之間transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 隨機調整亮度、對比度、飽和度、色調transforms.ToTensor(), # 轉換為 Tensortransforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # 歸一化,這是一種常見的經驗設置,適用于數據范圍 [0, 1],使其映射到 [-1, 1]])# 加載 CIFAR-10 數據集,并應用數據增強trainset = datasets.CIFAR10(root="./cifar10_data", train=True, download=True, transform=transform)dataloader = DataLoader(trainset, batch_size=4, shuffle=False)# 獲取一個批次的數據images, labels = next(iter(dataloader))# 還原圖片并顯示plt.figure(figsize=(10, 5))for i in range(4):# 反歸一化:將像素值從 [-1, 1] 還原到 [0, 1]img = images[i] / 2 + 0.5# 轉換為 PIL 圖像img_pil = transforms.ToPILImage()(img)# 顯示圖片plt.subplot(1, 4, i + 1)plt.imshow(img_pil)plt.axis('off')plt.title(f'Label: {labels[i]}')plt.show()if __name__ == "__main__":test01()












等級考試試卷(三級))



)


