八、過擬合與欠擬合
訓練深層神經網絡時,由于模型參數較多,數據不足的時候容易過擬合,正則化技術就是防止過擬合,提升模型的泛化能力和魯棒性 (對新數據表現良好 對異常數據表現良好)
1、概念
1.1過擬合
在訓練模型數據擬合能力很強,表現很好,在測試數據上表現很差
原因
數據不足;模型太復雜;正則化強度不足
1.2 欠擬合
模型學習能力不足,無法捕捉數據中的關系
?1.3 如何判斷
過擬合:訓練時候誤差低,驗證時候誤差高 說明過度擬合了訓練數據中的噪聲或特定模式
欠擬合:訓練和測試的誤差都高,說明模型太簡單,無法捕捉到復雜模式
2.解決欠擬合
增加模型復雜度,增加特征,減少正則化強度,訓練更長時間
3.解決過擬合
考慮損失函數,損失函數的目的是使預測值與真實值無限接近,如果在原來的損失函數上添加一個非0的變量
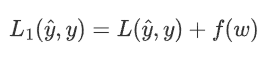
其中f(w)是關于權重w的函數,f(w)>0
要使L1變小,就要使L變小的同時,也要使f(w)變小。從而控制權重w在較小的范圍內。
3.1 L2正則化
L2在損失函數中添加權重參數的平方和來實現,目標是懲罰過大的參數
3.1.1 數字表示
損失函數L(tθ),其中θ表示權重參數,加入L2正則化后
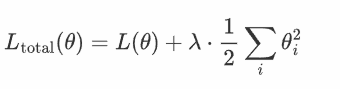
其中:
L(θ) 是原始損失函數(比如均方誤差、交叉熵等)。
λ是正則化強度,控制正則化的力度。
θi 是模型的第 i 個權重參數。
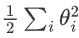 是所有權重參數的平方和,稱為 L2 正則化項。
是所有權重參數的平方和,稱為 L2 正則化項。
3.1.2 梯度更新
L2正則下,梯度更新時,不僅考慮原始損失函數梯度,還要考慮正則化的影響
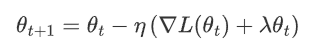
其中:
η 是學習率。
![]() 是損失函數關于參數 \theta_t 的梯度。
是損失函數關于參數 \theta_t 的梯度。
![]() 是 L2 正則化項的梯度,對應的是參數值本身的衰減。
是 L2 正則化項的梯度,對應的是參數值本身的衰減。
很明顯,參數越大懲罰力度就越大,從而讓參數逐漸趨向于較小值,避免出現過大的參數。
3.1.4 代碼
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt# 設置支持中文的字體
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定字體為黑體
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題
# 設置種子
torch.manual_seed(42)# 隨機數據
n_samples = 100
n_features = 20
x = torch.randn(n_samples, n_features)
y = torch.randn(n_samples,1)# 定義全鏈接神經網絡
class SimpleNet(nn.Module):def __init__(self):super(SimpleNet,self).__init__()self.fc1 = nn.Linear(n_features,50)self.fc2 = nn.Linear(50,1)def forward(self,x):x = torch.relu(self.fc1(x))return self.fc2(x)
# 訓練函數
def train_model(use_l2 = False,weight_decay = 0.01,n_epoches = 100):model = SimpleNet()criterion = nn.MSELoss()# 選擇優化器if use_l2:optimizer = optim.SGD(model.parameters(),lr = 0.01,weight_decay = weight_decay)else:optimizer = optim.SGD(model.parameters(),lr = 0.01,)train_losses = []for epoch in range(n_epoches):optimizer.zero_grad()outputs = model(x)loss = criterion(outputs,y)loss.backward()optimizer.step()train_losses.append(loss.item())if(epoch+1) % 10 == 0:print(F":Epoches[{epoch+1}/{n_epoches},Loss:{loss.item():.4f}]")return train_losses# 訓練比較兩種模型
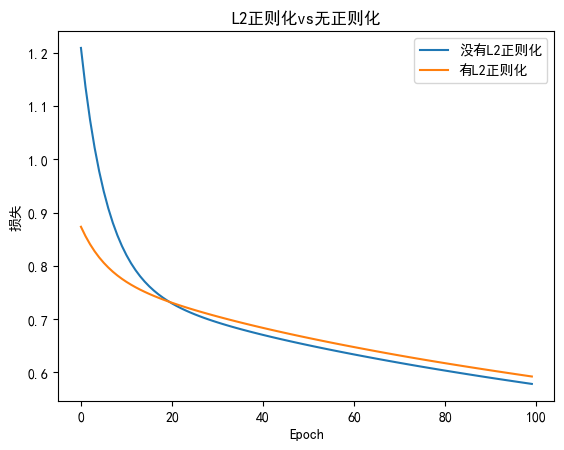
train_losses_no_l2 = train_model(use_l2 = False)
train_losses_with_l2 = train_model(use_l2 = True,weight_decay=0.01)# 繪制損失曲線
plt.plot(train_losses_no_l2,label = "沒有L2正則化")
plt.plot(train_losses_with_l2,label = "有L2正則化")
plt.xlabel("Epoch")
plt.ylabel("損失")
plt.title('L2正則化vs無正則化')
plt.legend()
plt.show()
?
3.2 L1正則化
通過在損失函數中添加權重參數的絕對值來之和來約束模型復雜度
3.2.1 數學表示
設模型的原始損失函數為 L(θ),其中θ表示模型權重參數,則加入 L1 正則化后的損失函數表示為:
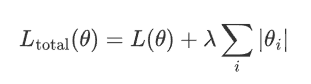
其中:
L(θ) 是原始損失函數。
λ是正則化強度,控制正則化的力度。
|θi| 是模型第i 個參數的絕對值。
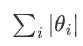 是所有權重參數的絕對值之和,這個項即為 L1 正則化項。
是所有權重參數的絕對值之和,這個項即為 L1 正則化項。
3.2.2 梯度更新
L1的正則化下 梯度更新公式
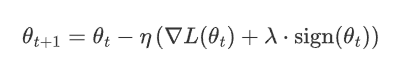
其中:
η是學習率。
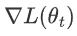 是損失函數關于參數 \theta_t 的梯度。
是損失函數關于參數 \theta_t 的梯度。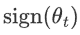 是參數 \theta_t 的符號函數,表示當 \theta_t 為正時取值為 1,為負時取值為 -1,等于 0 時為 0。
是參數 \theta_t 的符號函數,表示當 \theta_t 為正時取值為 1,為負時取值為 -1,等于 0 時為 0。
L1正則化依賴參數的絕對值,梯度更新不說簡單的線性縮小,而是通過符號函數來調整參數的方向,這就是為什么L1正則化促使參數變為0
3.2.3 作用
稀疏性:L1 正則化的一個顯著特性是它會促使許多權重參數變為 零。這是因為 L1 正則化傾向于將權重絕對值縮小到零,使得模型只保留對結果最重要的特征,而將其他不相關的特征權重設為零,從而實現 特征選擇 的功能。
防止過擬合:通過限制權重的絕對值,L1 正則化減少了模型的復雜度,使其不容易過擬合訓練數據。相比于 L2 正則化,L1 正則化更傾向于將某些權重完全移除,而不是減小它們的值。
簡化模型:由于 L1 正則化會將一些權重變為零,因此模型最終會變得更加簡單,僅依賴于少數重要特征。這對于高維度數據特別有用,尤其是在特征數量遠多于樣本數量的情況下。
特征選擇:因為 L1 正則化會將部分權重置零,因此它天然具有特征選擇的能力,有助于自動篩選出對模型預測最重要的特征。
3.2.4 與L2對比
L1 正則化 更適合用于產生稀疏模型,會讓部分權重完全為零,適合做特征選擇。
L2 正則化 更適合平滑模型的參數,避免過大參數,但不會使權重變為零,適合處理高維特征較為密集的場景。
3.3 Dropout
每次訓練迭代中,一部分神經元被丟棄(p為丟棄概率)
被選中的神經元不參與傳播
在測試階段,所有的神經元都參與計算,但對權重進行縮放(1-p),以保持輸出的期望值一致
Dropout是一種訓練過程中隨機丟棄部分神經元的計算,減少神經元之間的依賴防止模型過于復雜,避免過擬合
3.3.1 實現
import torch
import torch.nn as nndropout = nn.Dropout(p=0.5)
x = torch.randint(0, 10, (5, 6),dtype=torch.float)
print(x)print(dropout(x))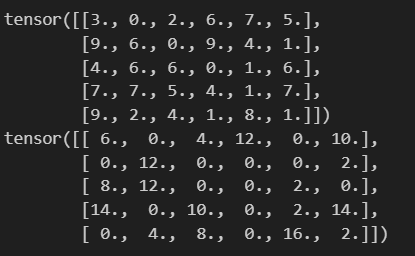
Dropout過程:
按照指定概率把部分神經元值設為0
為避免該操作帶來的影響,需要對非0的元素使用縮放因子1/(1-p)進行強化
假設某個神經元的輸出為 x,Dropout 的操作可以表示為:
在訓練階段:

在測試階段:
y=x
為什么要使用縮放因子1/(1-p)?
在訓練階段,Dropout 會以概率 p隨機將某些神經元的輸出設置為 0,而以概率 1?p 保留這些神經元。
假設某個神經元的原始輸出是 x,那么在訓練階段,它的期望輸出值為:
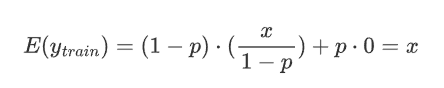
通過這種縮放,訓練階段的期望輸出值仍然是 x,與沒有 Dropout 時一致。
3.3.2 權重影響
import torch
import torch.nn as nn
from PIL import Image
from torchvision import transforms
import os
from matplotlib import pyplot as plt
torch.manual_seed(42)def load_img(path,resize = (224,224)):pil_img = Image.open(path).convert('RGB')print("Original Image Size: ", pil_img.size)transform = transforms.Compose([transforms.Resize(resize),transforms.ToTensor()])return transform(pil_img)# dirpath = os.path.dirname(__file__)
# path = os.path.join(dirpath,"img","100.jpg")
path = "./100.jpg"trans_img = load_img(path)
trans_img = trans_img.unsqueeze(0)
dropout = nn.Dropout2d(p=0.2)
drop_img = dropout(trans_img)
trans_img = trans_img.squeeze(0).permute(1,2,0).numpy()
drop_img = drop_img.squeeze(0).permute(1,2,0).numpy()drop_img = drop_img.clip(0,1)
fig = plt.figure(figsize = (10,5))ax1 = fig.add_subplot(1,2,1)
ax1.imshow(trans_img)ax2 = fig.add_subplot(1,2,2)
ax2.imshow(drop_img)plt.show()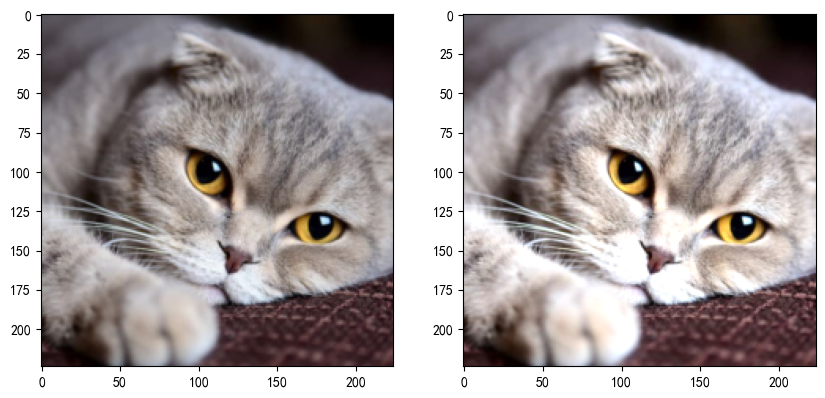
?
nn.Dropout2d(p):Dropout2d 是針對二維數據設計的 Dropout 層,它在訓練過程中隨機將輸入張量的某些通道(二維平面)置為零。
| 參數 | 要求格式 | 示例形狀 | 說明 |
|---|---|---|---|
| 輸入 | (N, C, H, W) | (16, 64, 32, 32) | 批大小×通道×高×寬 |
| 輸出 | (N, C, H, W) | (16, 64, 32, 32) | 與輸入同形,部分通道歸零 |
3.5 數據增強
?樣本不足時過擬合的常見原因之一
當訓練數據過少時,模型容易“記住”有限的樣本(包括噪聲和無關細節),而非學習通用的規律。
簡單模型更可能捕捉真實規律,但數據不足時,復雜模型會傾向于擬合訓練集中的偶然性模式(噪聲)。
樣本不足時,訓練集的分布可能與真實分布偏差較大,導致模型學到錯誤的規律。
小數據集中,個別樣本的噪聲(如標注錯誤、異常值)會被放大,模型可能將噪聲誤認為規律。
數據增強的好處:
大幅度降低數據采集和標注成本;
降低過擬合風險,提高模型泛化能力
transforms:
常用變換類
transforms.Compose:將多個變換操作組合成一個流水線。
transforms.ToTensor:將 PIL 圖像或 NumPy 數組轉換為 PyTorch 張量,將圖像數據從 uint8 類型 (0-255) 轉換為 float32 類型 (0.0-1.0)。
transforms.Normalize:對張量進行標準化。
transforms.Resize:調整圖像大小。
transforms.CenterCrop:從圖像中心裁剪指定大小的區域。
transforms.RandomCrop:隨機裁剪圖像。
transforms.RandomHorizontalFlip:隨機水平翻轉圖像。
transforms.RandomVerticalFlip:隨機垂直翻轉圖像。
transforms.RandomRotation:隨機旋轉圖像。
transforms.ColorJitter:隨機調整圖像的亮度、對比度、飽和度和色調。
transforms.RandomGrayscale:隨機將圖像轉換為灰度圖像。
transforms.RandomResizedCrop:隨機裁剪圖像并調整大小。
3.5.1 圖片縮放
from PIL import Image
img1 = plt.imread('./img/100.jpg')
print(img1.shape)
plt.imshow(img1)
plt.show()img = Image.open('./img/100.jpg')
transorm = transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor()])
r_img = transorm(img)
print(r_img.shape)r_img = r_img.permute(1,2,0)plt.imshow(r_img)
plt.show()?
 ?
?
3.5.2 隨機裁剪
# 裁剪
img = Image.open('./img/100.jpg')
transform = transforms.Compose([transforms.RandomCrop(size=(224, 224)),transforms.ToTensor()])
r_img = transform(img)
print(r_img.shape)r_img = r_img.permute(1, 2, 0)plt.imshow(r_img)
plt.show()?
3.5.3 隨機水平翻轉
img = Image.open("./img/100.jpg")
transform = transforms.Compose([transforms.RandomHorizontalFlip(p=1),transforms.ToTensor()])
r_img = transform(img)
print(r_img.shape)r_img = r_img.permute(1, 2, 0)plt.imshow(r_img)
plt.show()?
3.5.4 調整圖片顏色
transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)
brightness表示亮度:
float或者(min,max)
如果是
float(如brightness=0.2),則亮度在[max(0, 1 - 0.2), 1 + 0.2] = [0.8, 1.2]范圍內隨機縮放。如果是
(min, max)(如brightness=(0.5, 1.5)),則亮度在[0.5, 1.5]范圍內隨機縮放。
contrast:
對比度調整的范圍。
格式與 brightness 相同。
saturation:
飽和度調整的范圍。
格式與 brightness 相同。
hue:
色調調整的范圍。
可以是一個浮點數(表示相對范圍)或一個元組 (min, max)。
取值范圍必須為
[-0.5, 0.5](因為色相在 HSV 色彩空間中是循環的,超出范圍會導致顏色異常)。例如,hue=0.1 表示色調在 [-0.1, 0.1] 之間隨機調整。
img = Image.open("./img/100.jpg")transform = transforms.Compose([transforms.ColorJitter(brightness=0.2,contrast= 0.2,saturation= 0.2,hue= 0.2),transforms.ToTensor()])
r_img = transform(img)
print(r_img.shape)
r_img = r_img.permute(1,2,0)plt.imshow(r_img)
plt.show()
3.5.5 隨機旋轉
RandomRotation用于對圖像進行隨機旋轉。
transforms.RandomRotation(degrees, interpolation=InterpolationMode.NEAREST, expand=False, center=None, fill=0 )
degrees:
旋轉角度的范圍,可以是一個浮點數或元組 (min_degree, max_degree)。
例如,degrees=30 表示旋轉角度在 [-30, 30] 之間隨機選擇。
例如,degrees=(30, 60) 表示旋轉角度在 [30, 60] 之間隨機選擇。
interpolation:
插值方法,用于旋轉圖像。
默認是 InterpolationMode.NEAREST(最近鄰插值)。
其他選項包括 InterpolationMode.BILINEAR(雙線性插值)、InterpolationMode.BICUBIC(雙三次插值)等。
expand:
是否擴展圖像大小以適應旋轉后的圖像。如:當需要保留完整旋轉后的圖像時(如醫學影像、文檔掃描)
如果為 True,旋轉后的圖像可能會比原始圖像大。
如果為 False,旋轉后的圖像大小與原始圖像相同。
center:
旋轉中心點的坐標,默認為圖像中心。
可以是一個元組 (x, y),表示旋轉中心的坐標。
fill:
旋轉后圖像邊緣的填充值。
可以是一個浮點數(用于灰度圖像)或一個元組(用于 RGB 圖像)。默認填充0(黑色)
image = Image.open("./img/100.jpg")
transform = transforms.RandomRotation(degrees=90)rotated_image = transform(image)plt.imshow(rotated_image)
plt.axis('off')
plt.show()?
3.5.6 圖片轉Tensor
import torch
from PIL import Image
from torchvision import transforms
import osimg = Image.open('./img/100.jpg')
transform = transforms.ToTensor()
img_tensor = transform(img)
print(img_tensor)?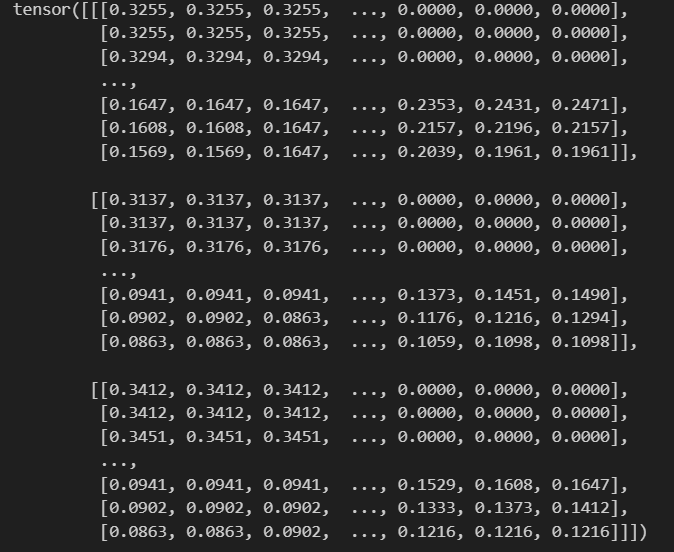
3.5.7 Tensor轉圖片
# img_tensor = torch.rand(3, 224, 224)
img = Image.open('./img/100.jpg')
transform1 = transforms.ToTensor()
img_tensor = transform1(img)transform2 = transforms.ToPILImage()
img = transform2(img_tensor)plt.imshow(img)
plt.show()?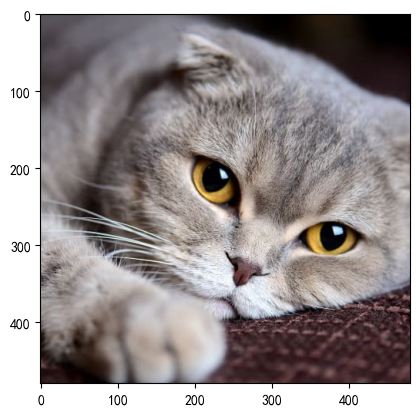
3.5.8 歸一化
標準化:將圖像的像素值從原始范圍([0,255]或[0,1],轉化為均值為0,標準差為1的分布。
加速訓練:標準化后的數據分布更均勻,有利于訓練
提高模型性能
img = Image.open('./img/100.jpg')
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
r_img= transform(img)
print(r_img.shape)r_img = r_img.permute(1,2,0)plt.imshow(r_img)
plt.show()?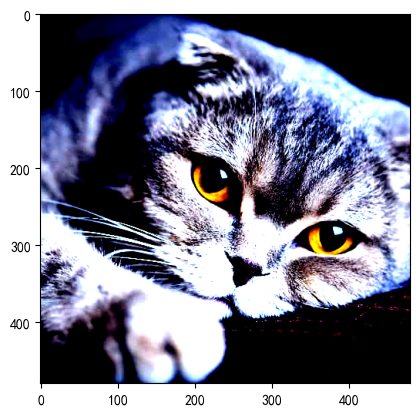

)



和SVN-VS2022插件(visualsvn)官網下載)








硬盤使用情況解析(已房子舉例))




