前言
- 學習視頻:深入Sharding-JDBC分庫分表從入門到精通【黑馬程序員】
- 本內容僅用于個人學習筆記,如有侵擾,聯系刪除
1、概述
1.1、分庫分表是什么
小明是一家初創電商平臺的開發人員,他負責賣家模塊的功能開發,其中涉及了店鋪、商品的相關業務,設計如下
數據庫:
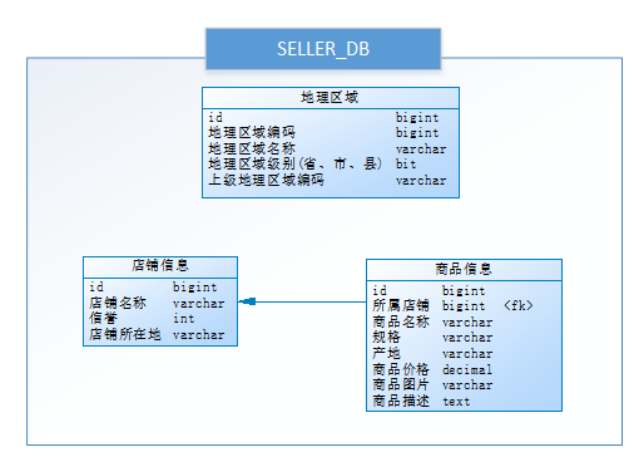
通過以下SQL能夠獲取到商品相關的店鋪信息、地理區域信息:
SELECT p.*,r.[地理區域名稱],s.[店鋪名稱],s.[信譽]
FROM [商品信息] p
LEFT JOIN [地理區域] r ON p.[產地] = r.[地理區域編碼]
LEFT JOIN [店鋪信息] s ON p.id = s.[所屬店鋪]
WHERE p.id = ?
形成類似以下列表展示:
隨著公司業務快速發展,數據庫中的數據量猛增,訪問性能也變慢了,優化迫在眉睫。分析一下問題出現在哪兒呢? 關系型數據庫本身比較容易成為系統瓶頸,單機存儲容量、連接數、處理能力都有限。當單表的數據量達到1000W或100G以后,由于查詢維度較多,即使添加從庫、優化索引,做很多操作時性能仍下降嚴重。
方案1:
通過提升服務器硬件能力來提高數據處理能力,比如增加存儲容量 、CPU等,這種方案成本很高,并且如果瓶頸在MySQL本身那么提高硬件也是有很的。
方案2:
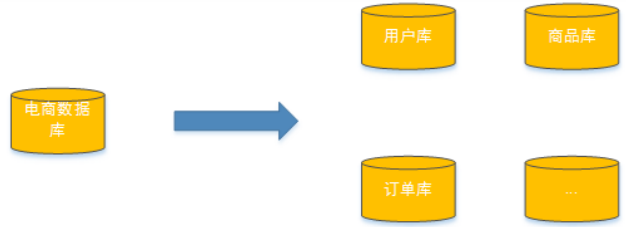
把數據分散在不同的數據庫中,使得單一數據庫的數據量變小來緩解單一數據庫的性能問題,從而達到提升數據庫性能的目的,如下圖:將電商數據庫拆分為若干獨立的數據庫,并且對于大表也拆分為若干小表,通過這種數據庫拆分的方法來解決數據庫的性能問題。
分庫分表就是為了解決由于數據量過大而導致數據庫性能降低的問題,將原來獨立的數據庫拆分成若干數據庫組成,將數據大表拆分成若干數據表組成,使得單一數據庫、單一數據表的數據量變小,從而達到提升數據庫性能的目的。
1.2、分庫分表的方式
分庫分表包括分庫和分表兩個部分,在生產中通常包括:垂直分庫、水平分庫、垂直分表、水平分表四種方式。
1.2.1、垂直分表
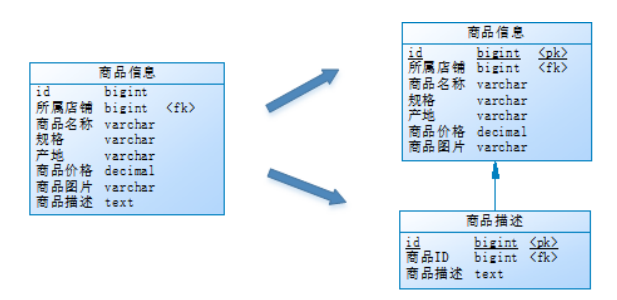
下邊通過一個商品查詢的案例講解垂直分表:
通常在商品列表中是不顯示商品詳情信息的,如下圖:
用戶在瀏覽商品列表時,只有對某商品感興趣時才會查看該商品的詳細描述。因此,商品信息中商品描述字段訪問頻次較低,且該字段存儲占用空間較大,訪問單個數據IO時間較長;商品信息中商品名稱、商品圖片、商品價格等其他字段數據訪問頻次較高。
由于這兩種數據的特性不一樣,因此他考慮將商品信息表拆分如下:
將訪問頻次低的商品描述信息單獨存放在一張表中,訪問頻次較高的商品基本信息單獨放在一張表中。
商品列表可采用以下sql:
SELECT p.*,r.[地理區域名稱],s.[店鋪名稱],s.[信譽]
FROM [商品信息] p
LEFT JOIN [地理區域] r ON p.[產地] = r.[地理區域編碼]
LEFT JOIN [店鋪信息] s ON p.id = s.[所屬店鋪]
WHERE...ORDER BY...LIMIT...
需要獲取商品描述時,再通過以下sql獲取:
SELECT *
FROM [商品描述]
WHERE [商品ID] = ?
小明進行的這一步優化,就叫垂直分表。
垂直分表定義:將一個表按照字段分成多表,每個表存儲其中一部分字段。
它帶來的提升是:
- 為了避免IO爭搶并減少鎖表的幾率,查看詳情的用戶與商品信息瀏覽互不影響
- 充分發揮熱門數據的操作效率,商品信息的操作的高效率不會被商品描述的低效率所拖累。
一般來說,某業務實體中的各個數據項的訪問頻次是不一樣的,部分數據項可能是占用存儲空間比較大的BLOB或是TEXT。例如上例中的商品描述。所以,當表數據量很大時,可以將表按字段切開,將熱門字段、冷門字段分開放置在不同庫中,這些庫可以放在不同的存儲設備上,避免IO爭搶。垂直切分帶來的性能提升主要集中在熱門數據的操作效率上,而且磁盤爭用情況減少。
通常我們按以下原則進行垂直拆分:
- 把不常用的字段單獨放在一張表;
- 把text,blob等大字段拆分出來放在附表中;
- 經常組合查詢的列放在一張表中;
1.2.2、垂直分庫
通過垂直分表性能得到了一定程度的提升,但是還沒有達到要求,并且磁盤空間也快不夠了,因為數據還是始終限制在一臺服務器,庫內垂直分表只解決了單一表數據量過大的問題,但沒有將表分布到不同的服務器上,因此每個表還是競爭同一個物理機的CPU、內存、網絡IO、磁盤。
經過思考,他把原有的SELLER_DB(賣家庫),分為了PRODUCT_DB(商品庫)和STORE_DB(店鋪庫),并把這兩個庫分散到不同服務器,如下圖:
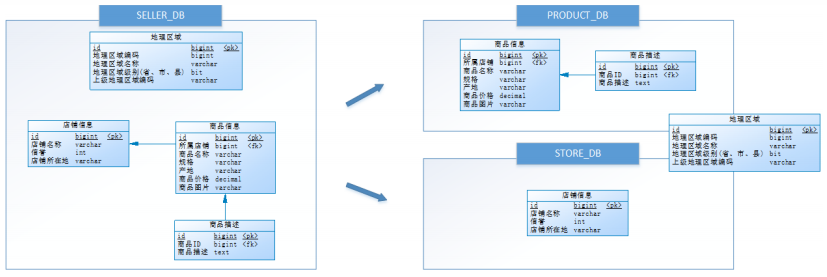
由于商品信息與商品描述業務耦合度較高,因此一起被存放在PRODUCT_DB(商品庫);而店鋪信息相對獨立,因此單獨被存放在STORE_DB(店鋪庫)。
小明進行的這一步優化,就叫垂直分庫。
垂直分庫是指按照業務將表進行分類,分布到不同的數據庫上面,每個庫可以放在不同的服務器上,它的核心理念是專庫專用。
它帶來的提升是:
- 解決業務層面的耦合,業務清晰
- 能對不同業務的數據進行分級管理、維護、監控、擴展等
- 高并發場景下,垂直分庫一定程度的提升IO、數據庫連接數、降低單機硬件資源的瓶頸
垂直分庫通過將表按業務分類,然后分布在不同數據庫,并且可以將這些數據庫部署在不同服務器上,從而達到多個服務器共同分攤壓力的效果,但是依然沒有解決單表數據量過大的問題。
1.2.3、水平分庫
經過垂直分庫后,數據庫性能問題得到一定程度的解決,但是隨著業務量的增長,PRODUCT_DB(商品庫)單庫存儲數據已經超出預估。粗略估計,目前有8w店鋪,每個店鋪平均150個不同規格的商品,再算上增長,那商品數量得往1500w+上預估,并且PRODUCT_DB(商品庫)屬于訪問非常頻繁的資源,單臺服務器已經無法支撐。此時該如何優化?
再次分庫?但是從業務角度分析,目前情況已經無法再次垂直分庫。
嘗試水平分庫,將店鋪ID為單數的和店鋪ID為雙數的商品信息分別放在兩個庫中。
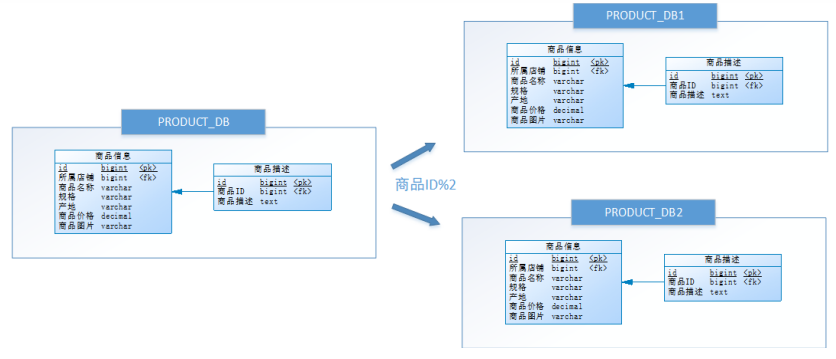
也就是說,要操作某條數據,先分析這條數據所屬的店鋪ID。如果店鋪ID為雙數,將此操作映射至RRODUCT_DB1(商品庫1);如果店鋪ID為單數,將操作映射至RRODUCT_DB2(商品庫2)。此操作要訪問數據庫名稱的表達式為RRODUCT_DB[店鋪ID%2 + 1] 。
小明進行的這一步優化,就叫水平分庫。
水平分庫是把同一個表的數據按一定規則拆到不同的數據庫中,每個庫可以放在不同的服務器上。
它帶來的提升是:
- 解決了單庫大數據,高并發的性能瓶頸。
- 提高了系統的穩定性及可用性。
當一個應用難以再細粒度的垂直切分,或切分后數據量行數巨大,存在單庫讀寫、存儲性能瓶頸,這時候就需要進行水平分庫了,經過水平切分的優化,往往能解決單庫存儲量及性能瓶頸。但由于同一個表被分配在不同的數據庫,需要額外進行數據操作的路由工作,因此大大提升了系統復雜度。
1.2.4、水平分表
按照水平分庫的思路對他把PRODUCT_DB_X(商品庫)內的表也可以進行水平拆分,其目的也是為解決單表數據量大的問題,如下圖:
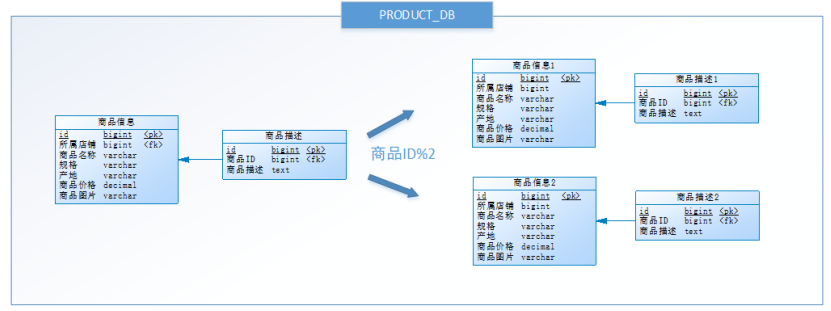
與水平分庫的思路類似,不過這次操作的目標是表,商品信息及商品描述被分成了兩套表。如果商品ID為雙數,將此操作映射至商品信息1表;如果商品ID為單數,將操作映射至商品信息2表。此操作要訪問表名稱的表達式為商品信息[商品ID%2 + 1] 。
小明進行的這一步優化,就叫水平分表。
水平分表是在同一個數據庫內,把同一個表的數據按一定規則拆到多個表中。
它帶來的提升是:
- 優化單一表數據量過大而產生的性能問題
- 避免IO爭搶并減少鎖表的幾率
庫內的水平分表,解決了單一表數據量過大的問題,分出來的小表中只包含一部分數據,從而使得單個表的數據量變小,提高檢索性能。
1.2.5、小結
本章介紹了分庫分表的各種方式,它們分別是垂直分表、垂直分庫、水平分庫和水平分表:
垂直分表: 可以把一個寬表的字段按訪問頻次、是否是大字段的原則拆分為多個表,這樣既能使業務清晰,還能提升部分性能。拆分后,盡量從業務角度避免聯查,否則性能方面將得不償失。
垂直分庫: 可以把多個表按業務耦合松緊歸類,分別存放在不同的庫,這些庫可以分布在不同服務器,從而使訪問壓力被多服務器負載,大大提升性能,同時能提高整體架構的業務清晰度,不同的業務庫可根據自身情況定制優化方案。但是它需要解決跨庫帶來的所有復雜問題。
水平分庫: 可以把一個表的數據(按數據行)分到多個不同的庫,每個庫只有這個表的部分數據,這些庫可以分布在不同服務器,從而使訪問壓力被多服務器負載,大大提升性能。它不僅需要解決跨庫帶來的所有復雜問題,還要解決數據路由的問題(數據路由問題后邊介紹)。
水平分表: 可以把一個表的數據(按數據行)分到多個同一個數據庫的多張表中,每個表只有這個表的部分數據,這樣做能小幅提升性能,它僅僅作為水平分庫的一個補充優化。
一般來說,在系統設計階段就應該根據業務耦合松緊來確定垂直分庫,垂直分表方案,在數據量及訪問壓力不是特別大的情況,首先考慮緩存、讀寫分離、索引技術等方案。若數據量極大,且持續增長,再考慮水平分庫水平分表方案。
1.3、分庫分表帶來的問題
分庫分表能有效的緩解了單機和單庫帶來的性能瓶頸和壓力,突破網絡IO、硬件資源、連接數的瓶頸,同時也帶來了一些問題。
1.3.1、事務一致性問題
由于分庫分表把數據分布在不同庫甚至不同服務器,不可避免會帶來分布式事務問題。
1.3.2、跨節點關聯查詢
在沒有分庫前,我們檢索商品時可以通過以下SQL對店鋪信息進行關聯查詢:
SELECT p.*,r.[地理區域名稱],s.[店鋪名稱],s.[信譽]
FROM [商品信息] p
LEFT JOIN [地理區域] r ON p.[產地] = r.[地理區域編碼]
LEFT JOIN [店鋪信息] s ON p.id = s.[所屬店鋪]
WHERE...ORDER BY...LIMIT...
但垂直分庫后[商品信息]和[店鋪信息]不在一個數據庫,甚至不在一臺服務器,無法進行關聯查詢。
可將原關聯查詢分為兩次查詢,第一次查詢的結果集中找出關聯數據id,然后根據id發起第二次請求得到關聯數據,最后將獲得到的數據進行拼裝。
1.3.3、跨節點分頁、排序函數
跨節點多庫進行查詢時,limit分頁、order by排序等問題,就變得比較復雜了。需要先在不同的分片節點中將數據進行排序并返回,然后將不同分片返回的結果集進行匯總和再次排序。
如,進行水平分庫后的商品庫,按ID倒序排序分頁,取第一頁:
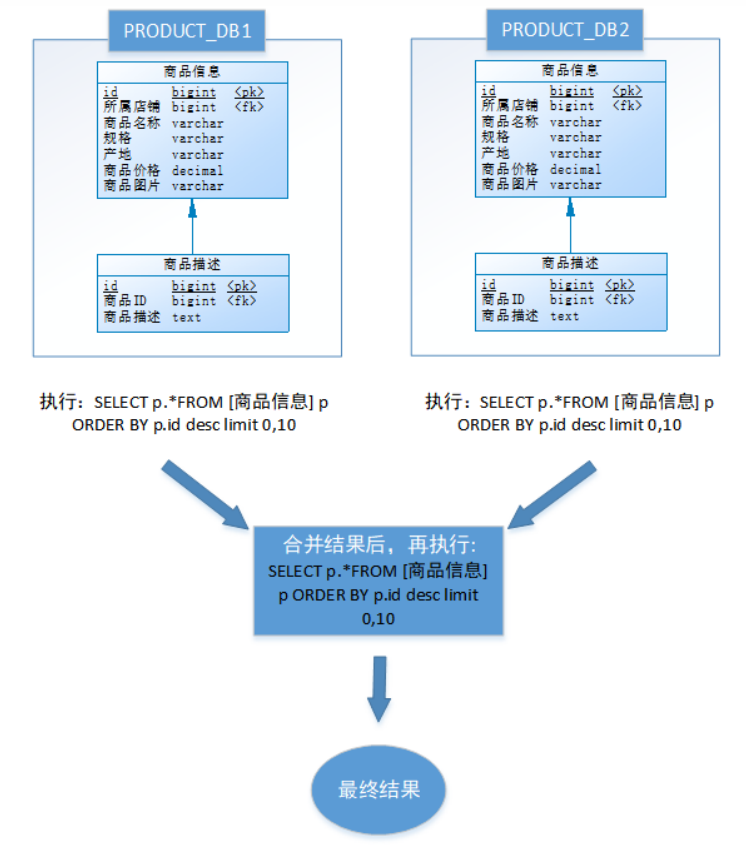
以上流程是取第一頁的數據,性能影響不大,但由于商品信息的分布在各數據庫的數據可能是隨機的,如果是取第N頁,需要將所有節點前N頁數據都取出來合并,再進行整體的排序,操作效率可想而知。所以請求頁數越大,系統的性能也會越差。
在使用Max、Min、Sum、Count之類的函數進行計算的時候,與排序分頁同理,也需要先在每個分片上執行相應的函數,然后將各個分片的結果集進行匯總和再次計算,最終將結果返回。
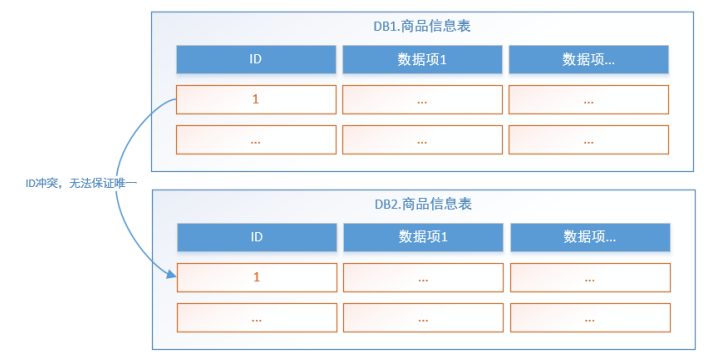
1.3.4、主鍵避重
在分庫分表環境中,由于表中數據同時存在不同數據庫中,主鍵值平時使用的自增長將無用武之地,某個分區數據庫生成的ID無法保證全局唯一。因此需要單獨設計全局主鍵,以避免跨庫主鍵重復問題。
1.3.5、公共表
實際的應用場景中,參數表、數據字典表等都是數據量較小,變動少,而且屬于高頻聯合查詢的依賴表。例子中地理區域表也屬于此類型。
可以將這類表在每個數據庫都保存一份,所有對公共表的更新操作都同時發送到所有分庫執行。
由于分庫分表之后,數據被分散在不同的數據庫、服務器。因此,對數據的操作也就無法通過常規方式完成,并且它還帶來了一系列的問題。好在,這些問題不是所有都需要我們在應用層面上解決,市面上有很多中間件可供我們選擇,其中Sharding-JDBC使用流行度較高,我們來了解一下它。
1.4、Sharding-JDBC介紹
1.4.1、Sharding-JDBC介紹
Sharding-JDBC是當當網研發的開源分布式數據庫中間件,從 3.0 開始Sharding-JDBC被包含在 Sharding-Sphere中,之后該項目進入進入Apache孵化器,4.0版本之后的版本為Apache版本。
ShardingSphere是一套開源的分布式數據庫中間件解決方案組成的生態圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(計劃中)這3款相互獨立的產品組成。 他們均提供標準化的數據分片、分布式事務和數據庫治理功能,可適用于如Java同構、異構語言、容器、云原生等各種多樣化的應用場景。
官方地址:https://shardingsphere.apache.org/document/current/cn/overview/
咱們目前只需關注Sharding-JDBC,它定位為輕量級Java框架,在Java的JDBC層提供的額外服務。 它使用客戶端直連數據庫,以jar包形式提供服務,無需額外部署和依賴,可理解為增強版的JDBC驅動,完全兼容JDBC和各種ORM框架。
Sharding-JDBC的核心功能為數據分片和讀寫分離,通過Sharding-JDBC,應用可以透明的使用jdbc訪問已經分庫分表、讀寫分離的多個數據源,而不用關心數據源的數量以及數據如何分布。
- 適用于任何基于Java的ORM框架,如: Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 基于任何第三方的數據庫連接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意實現JDBC規范的數據庫。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
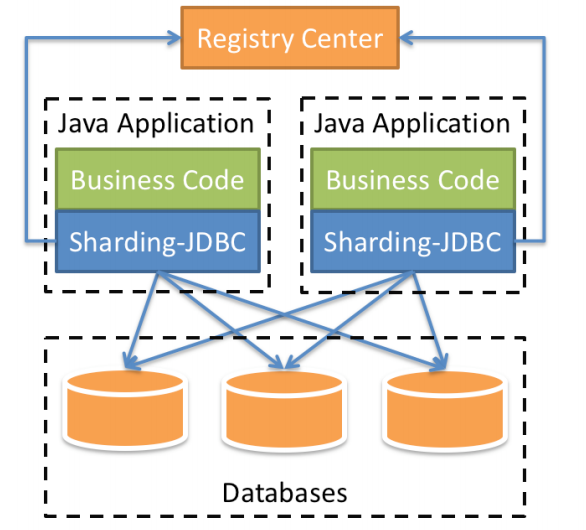
上圖展示了Sharding-Jdbc的工作方式,使用Sharding-Jdbc前需要人工對數據庫進行分庫分表,在應用程序中加入Sharding-Jdbc的Jar包,應用程序通過Sharding-Jdbc操作分庫分表后的數據庫和數據表,由于Sharding-Jdbc是對Jdbc驅動的增強,使用Sharding-Jdbc就像使用Jdbc驅動一樣,在應用程序中是無需指定具體要操作的分庫和分表的。
1.4.2、與jdbc性能對比
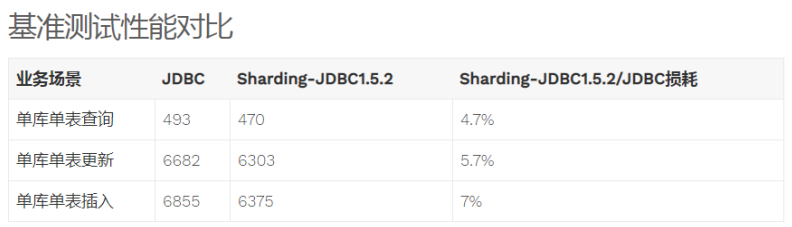
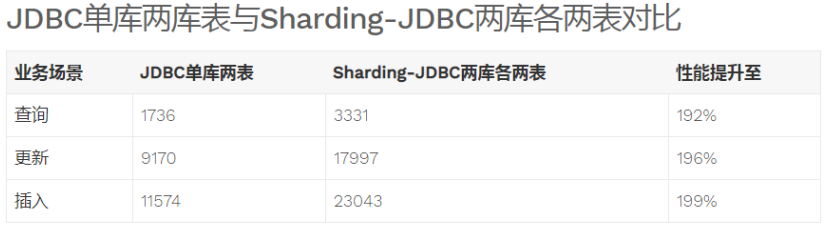
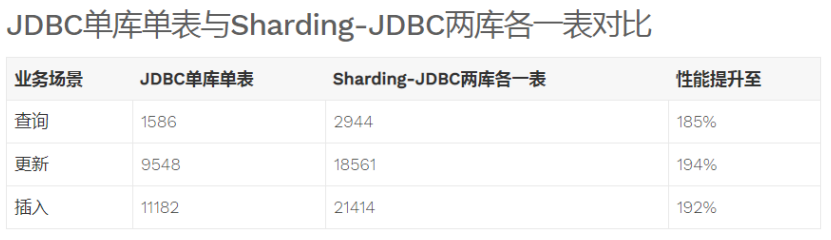
- 性能損耗測試:服務器資源充足、并發數相同,比較JDBC和Sharding-JDBC性能損耗,Sharding-JDBC相對JDBC損耗不超過7%。

- 性能對比測試:服務器資源使用到極限,相同的場景JDBC與Sharding-JDBC的吞吐量相當。
- 性能對比測試:服務器資源使用到極限,Sharding-JDBC采用分庫分表后,Sharding-JDBC吞吐量較JDBC不分表有接近2倍的提升。
2、Sharding-JDBC快速入門
2.1、需求說明
本章節使用Sharding-JDBC完成對訂單表的水平分表,通過快速入門程序的開發,快速體驗Sharding-JDBC的使用方法。
人工創建兩張表,t_order_1和t_order_2,這兩張表是訂單表拆分后的表,通過Sharding-Jdbc向訂單表插入數據,按照一定的分片規則,主鍵為偶數的進入t_order_1,另一部分數據進入t_order_2,通過Sharding-Jdbc 查詢數據,根據 SQL語句的內容從t_order_1或t_order_2查詢數據。
2.2、環境搭建
2.2.1、環境說明
- 操作系統:Win10
- 數據庫:MySQL-5.7.25
- JDK:64位 jdk1.8.0_201
- 應用框架:spring-boot-2.7.6,mybatis-plus 3.5.3.1
- Sharding-JDBC:sharding-jdbc-spring-boot-starter-4.0.0-RC1
2.2.2、創建數據庫
創建訂單庫order_db
CREATE DATABASE `order_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
在order_db中創建t_order_1、t_order_2表
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (`order_id` bigint(20) NOT NULL COMMENT '訂單id',`price` decimal(10, 2) NOT NULL COMMENT '訂單價格',`user_id` bigint(20) NOT NULL COMMENT '下單用戶id',`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '訂單狀態',PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (`order_id` bigint(20) NOT NULL COMMENT '訂單id',`price` decimal(10, 2) NOT NULL COMMENT '訂單價格',`user_id` bigint(20) NOT NULL COMMENT '下單用戶id',`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '訂單狀態',PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
2.2.3、引入maven依賴
引入 sharding-jdbc和SpringBoot整合的Jar包:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.6</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.wts</groupId><artifactId>springboot_sharding_jdbc</artifactId><version>0.0.1-SNAPSHOT</version><name>springboot_sharding_jdbc</name><description>springboot_sharding_jdbc</description><properties><java.version>1.8</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><spring-boot.version>2.7.6</spring-boot.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.3.1</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.18</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.0.0-RC1</version></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>${spring-boot.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>
2.3、編寫程序
2.3.1、分片規則配置
分片規則配置是sharding-jdbc進行對分庫分表操作的重要依據,配置內容包括:數據源、主鍵生成策略、分片策略等。
在application.properties中配置
server.port=56081
server.servlet.context‐path = /sharding‐jdbc‐simple‐demo
server.servlet.encoding.enabled = true
server.servlet.encoding.charset = UTF-8
server.servlet.encoding.force = true
spring.main.allow‐bean‐definition‐overriding = true
mybatis.configuration.map‐underscore‐to‐camel‐case = true# 以下是分片規則配置
# 定義數據源
spring.shardingsphere.datasource.names = m1
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver‐class‐name = com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = root
# 指定t_order表的數據分布情況,配置數據節點
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = m1.t_order_$->{1..2}# 指定t_order表的主鍵生成策略為SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.column = order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type = SNOWFLAKE
# 指定t_order表的分片策略,分片策略包括分片鍵和分片算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column = order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression = t_order_$->{order_id % 2 + 1}
# 打開sql輸出日志
spring.shardingsphere.props.sql.show = true
swagger.enable = true
logging.level.root = info
logging.level.org.springframework.web = info
logging.level.com.itheima.dbsharding = debug
logging.level.druid.sql = debug
- 首先定義數據源m1,并對m1進行實際的參數配置。
- 指定t_order表的數據分布情況,他分布在m1.t_order_1,m1.t_order_2
- 指定t_order表的主鍵生成策略為SNOWFLAKE,SNOWFLAKE是一種分布式自增算法,保證id全局唯一
- 定義t_order分片策略,order_id為偶數的數據落在t_order_1,為奇數的落在t_order_2,分表策略的表達式為t_order_$->{order_id % 2 + 1}
2.3.2、數據操作
@Mapper
@Component
public interface OrderDao {/*** 新增訂單** @param price 訂單價格* @param userId 用戶id* @param status 訂單狀態* @return*/@Insert("insert into t_order(price, user_id, status) value(#{price}, #{userId}, #{status})")int insertOrder(@Param("price") BigDecimal price, @Param("userId") Long userId, @Param("status") String status);/*** 根據id列表查詢多個訂單** @param orderIds 訂單id列表* @return*/@Select({"<script>" +"select " +" * " +" from t_order t" +" where t.order_id in " +"<foreach collection='orderIds' item='id' open='(' separator=',' close=')'>" +" #{id} " +"</foreach>" +"</script>"})List<Map> selectOrderbyIds(@Param("orderIds") List<Long> orderIds);
}
2.3.3、測試
編寫單元測試:
@SpringBootTest
class SpringbootShardingJdbcApplicationTests {@Testvoid contextLoads() {}@Autowiredprivate OrderDao orderDao;@Testpublic void testInsertOrder() {for (int i = 0; i < 10; i++) {orderDao.insertOrder(new BigDecimal((i + 1) * 5), 1L, "WAIT_PAY");}}@Testpublic void testSelectOrderByIds() {List<Long> ids = new ArrayList<>();ids.add(1138054658762211328L);ids.add(1138054658510553089L);List<Map> maps = orderDao.selectOrderbyIds(ids);System.out.println(maps);}
}
執行testInsertOrder:
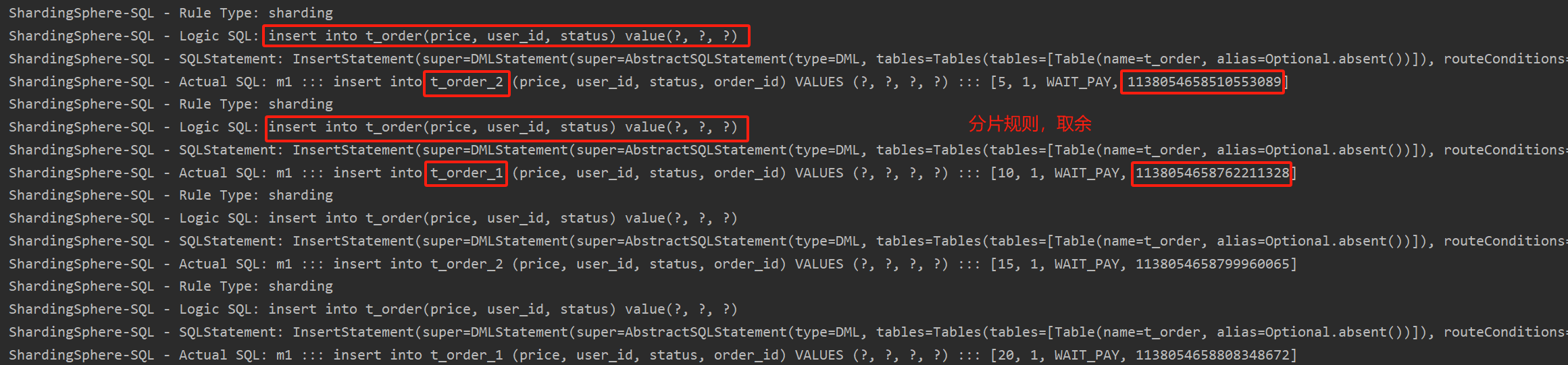
通過日志可以發現order_id為奇數的被插入到t_order_2表,為偶數的被插入到t_order_1表,達到預期目標。
執行testSelectOrderbyIds:

通過日志可以發現,根據傳入order_id的奇偶不同,sharding-jdbc分別去不同的表檢索數據,達到預期目標。
2.4、流程分析
通過日志分析,Sharding-JDBC在拿到用戶要執行的sql之后干了哪些事兒:
(1)解析sql,獲取片鍵值,在本例中是order_id
(2)Sharding-JDBC通過規則配置 t_order_$->{order_id % 2 + 1},知道了當order_id為偶數時,應該往t_order_1表插數據,為奇數時,往t_order_2插數據。
(3)于是Sharding-JDBC根據order_id的值改寫sql語句,改寫后的SQL語句是真實所要執行的SQL語句。
(4)執行改寫后的真實sql語句
(5)將所有真正執行sql的結果進行匯總合并,返回。
2.5、其他集成方式
Sharding-JDBC不僅可以與spring boot良好集成,它還支持其他配置方式,共支持以下四種集成方式。
1)、Spring Boot Yaml 配置
定義application.yml,內容如下:
server:port: 56081servlet:context-path: /sharding-jdbc-demoencoding:enabled: truecharset: UTF-8force: true
spring:application:name: sharding-jdbc-demomain:allow-bean-definition-overriding: truesharding-sphere:datasource:names: m1 # 數據源名稱列表m1: # 數據源具體配置type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driver # MySQL 8.0+ 驅動url: jdbc:mysql://localhost:3306/order_db?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghaiusername: rootpassword: rootsharding:tables:t_order:actual-data-nodes: m1.t_order_$->{1..2}key-generator:column: order_idtype: SNOWFLAKEtable-strategy:inline:sharding-column: order_idalgorithm-expression: t_order_$->{order_id % 2 + 1}props:sql:show: truemybatis:configuration:map-underscore-to-camel-case: trueswagger:enable: truelogging:level:root: infoorg.springframework.web: infocom.wf.game.sdk: debugdruid.sql: debug
如果使用application.yml則需要屏蔽原來的application.properties文件。
2)、Java 配置
添加配置類:
@Configuration
public class ShardingJdbcConfig {/*** 定義數據源** @return*/Map<String, DataSource> createDataSourceMap() {DruidDataSource dataSource1 = new DruidDataSource();dataSource1.setDriverClassName("com.mysql.jdbc.Driver");dataSource1.setUrl("jdbc:mysql://172.28.133.3:3306/order_db?useUnicode=true&characterEncoding=UTF-8&useSSL=true&serverTimezone=Asia/Shanghai");dataSource1.setUsername("root");dataSource1.setPassword("root");Map<String, DataSource> result = new HashMap<>();result.put("m1", dataSource1);return result;}/*** 定義主鍵生成策略** @return*/private static KeyGeneratorConfiguration getKeyGeneratorConfiguration() {KeyGeneratorConfiguration result = newKeyGeneratorConfiguration("SNOWFLAKE", "order_id");return result;}/*** 定義t_order表的分片策略** @return*/TableRuleConfiguration getOrderTableRuleConfiguration() {TableRuleConfiguration result = new TableRuleConfiguration("t_order", "m1.t_order_$->{1..2}");result.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order_$->{order_id % 2 + 1}"));result.setKeyGeneratorConfig(getKeyGeneratorConfiguration());return result;}/*** 定義sharding‐Jdbc數據源** @return* @throws SQLException*/@BeanDataSource getShardingDataSource() throws SQLException {ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();shardingRuleConfig.getTableRuleConfigs().add(getOrderTableRuleConfiguration());//spring.shardingsphere.props.sql.show = trueProperties properties = new Properties();properties.put("sql.show", "true");return ShardingDataSourceFactory.createDataSource(createDataSourceMap(), shardingRuleConfig, properties);}
}
由于采用了配置類所以需要屏蔽原來application.properties文件中spring.shardingsphere開頭的配置信息。
server.port=56081
server.servlet.context‐path = /sharding‐jdbc‐simple‐demo
server.servlet.encoding.enabled = true
server.servlet.encoding.charset = UTF-8
server.servlet.encoding.force = true
spring.main.allow‐bean‐definition‐overriding = true
mybatis.configuration.map‐underscore‐to‐camel‐case = true# 以下是分片規則配置
# 定義數據源
#spring.shardingsphere.datasource.names = m1
#spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
#spring.shardingsphere.datasource.m1.driver‐class‐name = com.mysql.cj.jdbc.Driver
#spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai
#spring.shardingsphere.datasource.m1.username = root
#spring.shardingsphere.datasource.m1.password = root
## 指定t_order表的數據分布情況,配置數據節點
#spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = m1.t_order_$->{1..2}
#
## 指定t_order表的主鍵生成策略為SNOWFLAKE
#spring.shardingsphere.sharding.tables.t_order.key-generator.column = order_id
#spring.shardingsphere.sharding.tables.t_order.key-generator.type = SNOWFLAKE
## 指定t_order表的分片策略,分片策略包括分片鍵和分片算法
#spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column = order_id
#spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression = t_order_$->{order_id % 2 + 1}
## 打開sql輸出日志
#spring.shardingsphere.props.sql.show = trueswagger.enable = true
logging.level.root = info
logging.level.org.springframework.web = info
logging.level.com.itheima.dbsharding = debug
logging.level.druid.sql = debug
還需要在SpringBoot啟動類中屏蔽使用spring.shardingsphere配置項的類SpringBootConfiguration
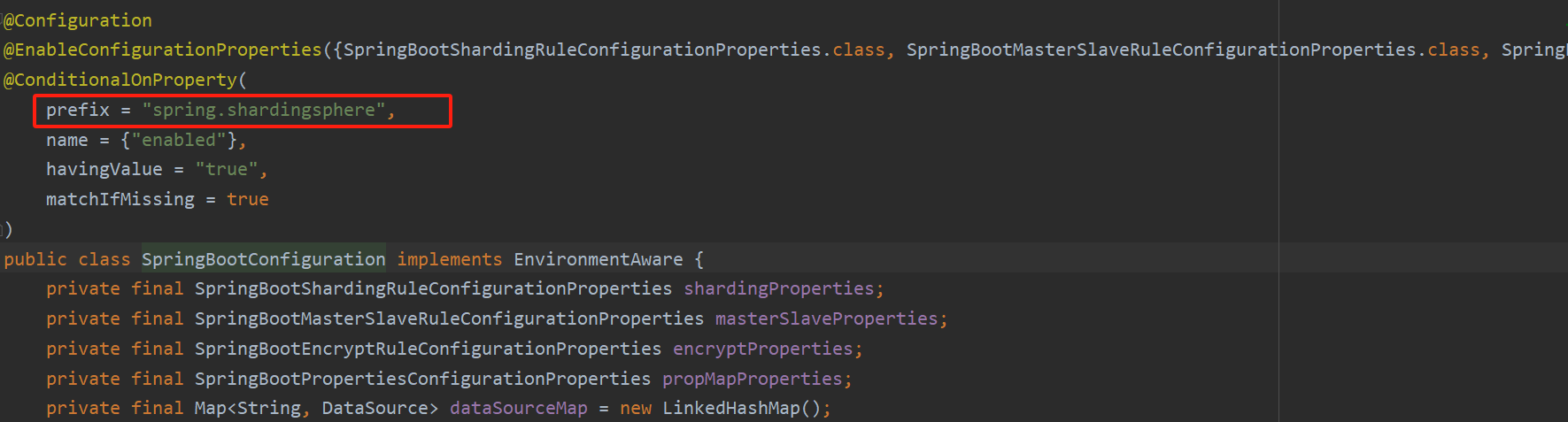
package com.wts;import org.apache.shardingsphere.shardingjdbc.spring.boot.SpringBootConfiguration;
import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication(exclude = SpringBootConfiguration.class)
public class SpringbootShardingJdbcApplication {public static void main(String[] args) {SpringApplication.run(SpringbootShardingJdbcApplication.class, args);}}
不然springboot執行test測試會報以下錯誤
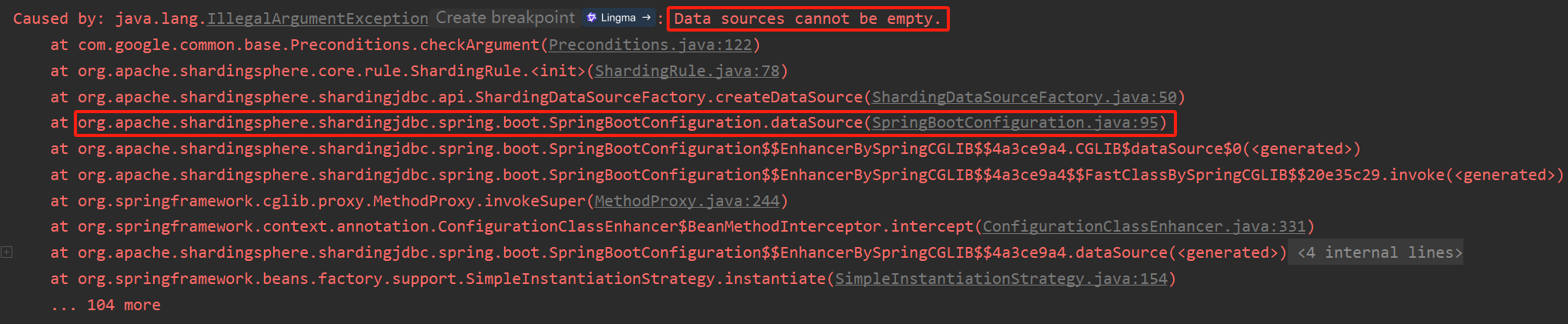
這是因為sharding-jdbc和springboot集成的時候,默認會使用SpringbootConfiguration類,自動的從配置文件中讀spring.shardingsphere配置,但是讀不到,因為我們通過配置類配置的,所以我們在啟動類中排除SpringBootConfiguration
此方式同快速入門程序 Spring Boot properties配置。
# 定義數據源
spring.shardingsphere.datasource.names = m1
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver‐class‐name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db?useUnicode=true
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = root# 指定t_order表的主鍵生成策略為SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key‐generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key‐generator.type=SNOWFLAKE# 指定t_order表的數據分布情況
spring.shardingsphere.sharding.tables.t_order.actual‐data‐nodes = m1.t_order_$‐>{1..2}# 指定t_order表的分表策略
spring.shardingsphere.sharding.tables.t_order.table‐strategy.inline.sharding‐column = order_id
spring.shardingsphere.sharding.tables.t_order.table‐strategy.inline.algorithm‐expression =
t_order_$‐>{order_id % 2 + 1}
3)、Spring命名空間配置(不推薦)
此方式使用xml方式配置,不推薦使用。
<?xml version="1.0" encoding="UTF‐8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema‐instance"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:sharding="http://shardingsphere.apache.org/schema/shardingsphere/sharding"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring‐beans.xsd
http://shardingsphere.apache.org/schema/shardingsphere/sharding
http://shardingsphere.apache.org/schema/shardingsphere/sharding/sharding.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring‐context.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring‐tx.xsd">
<context:annotation‐config />
<!‐‐定義多個數據源‐‐>
<bean id="m1" class="com.alibaba.druid.pool.DruidDataSource" destroy‐method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/order_db_1?useUnicode=true" />
<property name="username" value="root" />
<property name="password" value="root" />
</bean>
<!‐‐定義分庫策略‐‐>
<sharding:inline‐strategy id="tableShardingStrategy" sharding‐column="order_id" algorithm‐
expression="t_order_$‐>{order_id % 2 + 1}" />
<!‐‐定義主鍵生成策略‐‐>
<sharding:key‐generator id="orderKeyGenerator" type="SNOWFLAKE" column="order_id" />
<!‐‐定義sharding‐Jdbc數據源‐‐>
<sharding:data‐source id="shardingDataSource">
<sharding:sharding‐rule data‐source‐names="m1">
<sharding:table‐rules>
<sharding:table‐rule logic‐table="t_order" table‐strategy‐
ref="tableShardingStrategy" key‐generator‐ref="orderKeyGenerator" />
</sharding:table‐rules>
</sharding:sharding‐rule>
</sharding:data‐source>
</beans>
2.6、Sharding-JDBC 的分布式事務:
-
Sharding-JDBC 作為輕量級的 Java JDBC 驅動,確實內置了分布式事務功能
-
它支持多種分布式事務模式:
-
本地事務:僅限于單一數據源
-
XA 事務:基于兩階段提交的標準分布式事務
-
Seata 柔性事務:基于 AT 模式的最終一致性事務
-
Narayana 事務:另一種 XA 事務實現
-
BASE 事務:通過 SAGA 模式實現
-
3、Sharding-JDBC執行原理
3.1、基本概念
在了解Sharding-JDBC的執行原理前,需要了解以下概念:
邏輯表
水平拆分的數據表的總稱。例:訂單數據表根據主鍵尾數拆分為10張表,分別是 t_order_0 、 t_order_1 到 t_order_9 ,他們的邏輯表名為 t_order 。
真實表
在分片的數據庫中真實存在的物理表。即上個示例中的 t_order_0 到 t_order_9 。
數據節點
數據分片的最小物理單元。由數據源名稱和數據表組成,例: ds_0.t_order_0 。
綁定表
指分片規則一致的主表和子表。例如: t_order 表和 t_order_item 表,均按照 order_id 分片,綁定表之間的分區鍵完全相同,則此兩張表互為綁定表關系。綁定表之間的多表關聯查詢不會出現笛卡爾積關聯,關聯查詢效率將大大提升。舉例說明,如果SQL為:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置綁定表關系時,假設分片鍵 order_id 將數值10路由至第0片,將數值11路由至第1片,那么路由后的SQL
應該為4條,它們呈現為笛卡爾積:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置綁定表關系后,路由的SQL應該為2條:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
廣播表
指所有的分片數據源中都存在的表,表結構和表中的數據在每個數據庫中均完全一致。適用于數據量不大且需要與海量數據的表進行關聯查詢的場景,例如:字典表。
分片鍵
用于分片的數據庫字段,是將數據庫(表)水平拆分的關鍵字段。例:將訂單表中的訂單主鍵的尾數取模分片,則訂單主鍵為分片字段。 SQL中如果無分片字段,將執行全路由,性能較差。 除了對單分片字段的支持,ShardingJdbc也支持根據多個字段進行分片。
分片算法
通過分片算法將數據分片,支持通過 = 、 BETWEEN 和 IN 分片。分片算法需要應用方開發者自行實現,可實現的靈活度非常高。包括:精確分片算法 、范圍分片算法 ,復合分片算法 等。例如:where order_id = ? 將采用精確分片算法,where order_id in (?,?,?)將采用精確分片算法,where order_id BETWEEN ? and ? 將采用范圍分片算法,復合分片算法用于分片鍵有多個復雜情況。
分片策略
包含分片鍵和分片算法,由于分片算法的獨立性,將其獨立抽離。真正可用于分片操作的是分片鍵 + 分片算法,也就是分片策略。內置的分片策略大致可分為尾數取模、哈希、范圍、標簽、時間等。由用戶方配置的分片策略則更加靈活,常用的使用行表達式配置分片策略,它采用Groovy表達式表示,如: t_user_$->{u_id % 8} 表示t_user表根據u_id模8,而分成8張表,表名稱為 t_user_0 到 t_user_7 。
自增主鍵生成策略
通過在客戶端生成自增主鍵替換以數據庫原生自增主鍵的方式,做到分布式主鍵無重復。
3.2、SQL解析
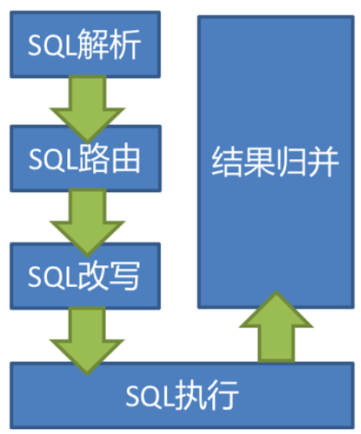
當Sharding-JDBC接受到一條SQL語句時,會陸續執行 SQL解析 => 查詢優化 => SQL路由 => SQL改寫 => SQL執行 =>結果歸并 ,最終返回執行結果。
SQL解析過程分為詞法解析和語法解析。 詞法解析器用于將SQL拆解為不可再分的原子符號,稱為Token。并根據不同數據庫方言所提供的字典,將其歸類為關鍵字,表達式,字面量和操作符。 再使用語法解析器將SQL轉換為抽象語法樹。
例如,以下SQL:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
解析之后的為抽象語法樹見下圖:
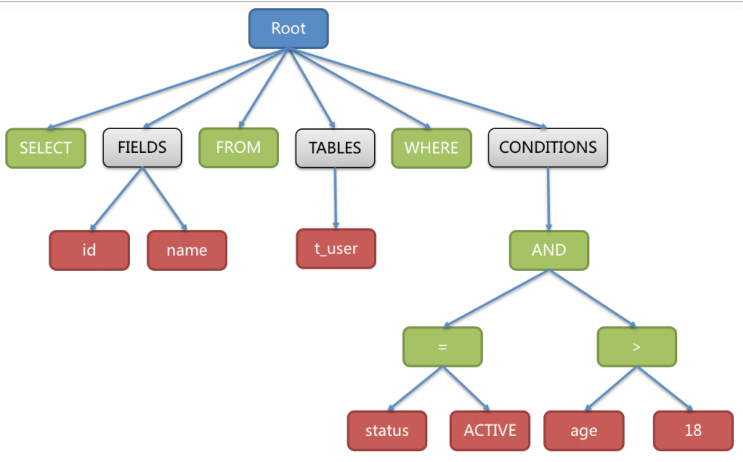
為了便于理解,抽象語法樹中的關鍵字的Token用綠色表示,變量的Token用紅色表示,灰色表示需要進一步拆分。
最后,通過對抽象語法樹的遍歷去提煉分片所需的上下文,并標記有可能需要 SQL改寫(后邊介紹) 的位置。 供分片使用的解析上下文包含查詢選擇項(Select Items)、表信息(Table)、分片條件(Sharding Condition)、自增主鍵信息(Auto increment Primary Key)、排序信息(Order By)、分組信息(Group By)以及分頁信息(Limit、Rownum、Top)。
3.3、SQL路由
SQL路由就是把針對邏輯表的數據操作映射到對數據結點操作的過程。
根據解析上下文匹配數據庫和表的分片策略,并生成路由路徑。 對于攜帶分片鍵的SQL,根據分片鍵操作符不同可以劃分為單片路由(分片鍵的操作符是等號)、多片路由(分片鍵的操作符是IN)和范圍路由(分片鍵的操作符是BETWEEN),不攜帶分片鍵的SQL則采用廣播路由。根據分片鍵進行路由的場景可分為直接路由、標準路由、笛卡爾路由等。
標準路由
標準路由是Sharding-Jdbc最為推薦使用的分片方式,它的適用范圍是不包含關聯查詢或僅包含綁定表之間關聯查詢的SQL。 當分片運算符是等于號時,路由結果將落入單庫(表),當分片運算符是BETWEEN或IN時,則路由結果不一定落入唯一的庫(表),因此一條邏輯SQL最終可能被拆分為多條用于執行的真實SQL。 舉例說明,如果按照 order_id 的奇數和偶數進行數據分片,一個單表查詢的SQL如下:
SELECT * FROM t_order WHERE order_id IN (1, 2);
那么路由的結果應為:
SELECT * FROM t_order_0 WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 WHERE order_id IN (1, 2);
綁定表的關聯查詢與單表查詢復雜度和性能相當。舉例說明,如果一個包含綁定表的關聯查詢的SQL如下:
SELECT * FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
那么路由的結果應為:
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
可以看到,SQL拆分的數目與單表是一致的。
笛卡爾路由
笛卡爾路由是最復雜的情況,它無法根據綁定表的關系定位分片規則,因此非綁定表之間的關聯查詢需要拆解為笛卡爾積組合執行。 如果上個示例中的SQL并未配置綁定表關系,那么路由的結果應為:
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
笛卡爾路由查詢性能較低,需謹慎使用。
全庫表路由
對于不攜帶分片鍵的SQL,則采取廣播路由的方式。根據SQL類型又可以劃分為全庫表路由、全庫路由、全實例路由、單播路由和阻斷路由這5種類型。其中全庫表路由用于處理對數據庫中與其邏輯表相關的所有真實表的操作,
主要包括不帶分片鍵的DQL(數據查詢)和DML(數據操縱),以及DDL(數據定義)等。例如:
SELECT * FROM t_order WHERE good_prority IN (1, 10);
則會遍歷所有數據庫中的所有表,逐一匹配邏輯表和真實表名,能夠匹配得上則執行。路由后成為
SELECT * FROM t_order_0 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_1 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_2 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_3 WHERE good_prority IN (1, 10);
3.4、SQL改寫
工程師面向邏輯表書寫的SQL,并不能夠直接在真實的數據庫中執行,SQL改寫用于將邏輯SQL改寫為在真實數據庫中可以正確執行的SQL。
如一個簡單的例子,若邏輯SQL為:
SELECT order_id FROM t_order WHERE order_id=1;
假設該SQL配置分片鍵order_id,并且order_id=1的情況,將路由至分片表1。那么改寫之后的SQL應該為:
SELECT order_id FROM t_order_1 WHERE order_id=1;
再比如,Sharding-JDBC需要在結果歸并時獲取相應數據,但該數據并未能通過查詢的SQL返回。 這種情況主要是針對GROUP BY和ORDER BY。結果歸并時,需要根據 GROUP BY 和 ORDER BY 的字段項進行分組和排序,但如果原始SQL的選擇項中若并未包含分組項或排序項,則需要對原始SQL進行改寫。 先看一下原始SQL中帶有結果歸并所需信息的場景:
SELECT order_id, user_id FROM t_order ORDER BY user_id;
由于使用user_id進行排序,在結果歸并中需要能夠獲取到user_id的數據,而上面的SQL是能夠獲取到user_id數據的,因此無需補列。
如果選擇項中不包含結果歸并時所需的列,則需要進行補列,如以下SQL:
SELECT order_id FROM t_order ORDER BY user_id;
由于原始SQL中并不包含需要在結果歸并中需要獲取的user_id,因此需要對SQL進行補列改寫。補列之后的SQL是:
SELECT order_id, user_id AS ORDER_BY_DERIVED_0 FROM t_order ORDER BY user_id;
3.5、SQL執行
Sharding-JDBC采用一套自動化的執行引擎,負責將路由和改寫完成之后的真實SQL安全且高效發送到底層數據源執行。 它不是簡單地將SQL通過JDBC直接發送至數據源執行;也并非直接將執行請求放入線程池去并發執行。它更關注平衡數據源連接創建以及內存占用所產生的消耗,以及最大限度地合理利用并發等問題。 執行引擎的目標是自動化的平衡資源控制與執行效率,他能在以下兩種模式自適應切換:
內存限制模式
使用此模式的前提是,Sharding-JDBC對一次操作所耗費的數據庫連接數量不做限制。 如果實際執行的SQL需要對某數據庫實例中的200張表做操作,則對每張表創建一個新的數據庫連接,并通過多線程的方式并發處理,以達成執行效率最大化。
連接限制模式
使用此模式的前提是,Sharding-JDBC嚴格控制對一次操作所耗費的數據庫連接數量。 如果實際執行的SQL需要對某數據庫實例中的200張表做操作,那么只會創建唯一的數據庫連接,并對其200張表串行處理。 如果一次操作中的分片散落在不同的數據庫,仍然采用多線程處理對不同庫的操作,但每個庫的每次操作仍然只創建一個唯一的數據庫連接。
內存限制模式適用于OLAP操作,可以通過放寬對數據庫連接的限制提升系統吞吐量; 連接限制模式適用于OLTP操作,OLTP通常帶有分片鍵,會路由到單一的分片,因此嚴格控制數據庫連接,以保證在線系統數據庫資源能夠被更多的應用所使用,是明智的選擇。
3.6、結果歸并
將從各個數據節點獲取的多數據結果集,組合成為一個結果集并正確的返回至請求客戶端,稱為結果歸并。
Sharding-JDBC支持的結果歸并從功能上可分為遍歷、排序、分組、分頁和聚合5種類型,它們是組合而非互斥的關系。
歸并引擎的整體結構劃分如下圖。
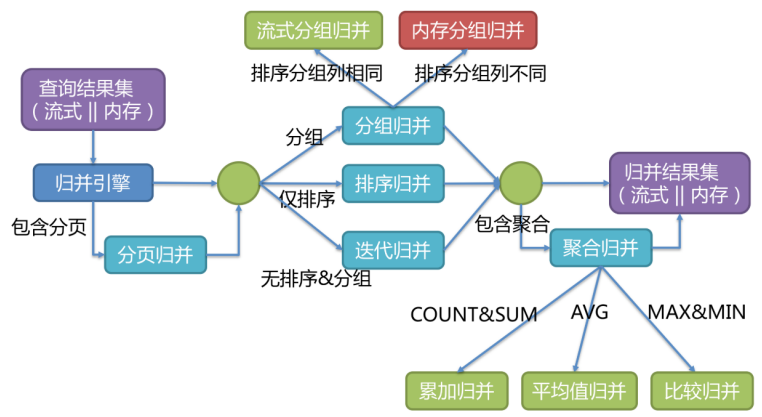
結果歸并從結構劃分可分為流式歸并、內存歸并和裝飾者歸并。流式歸并和內存歸并是互斥的,裝飾者歸并可以在流式歸并和內存歸并之上做進一步的處理。
內存歸并很容易理解,他是將所有分片結果集的數據都遍歷并存儲在內存中,再通過統一的分組、排序以及聚合等計算之后,再將其封裝成為逐條訪問的數據結果集返回。
流式歸并是指每一次從數據庫結果集中獲取到的數據,都能夠通過游標逐條獲取的方式返回正確的單條數據,它與數據庫原生的返回結果集的方式最為契合。
下邊舉例說明排序歸并的過程,如下圖是一個通過分數進行排序的示例圖,它采用流式歸并方式。 圖中展示了3張表返回的數據結果集,每個數據結果集已經根據分數排序完畢,但是3個數據結果集之間是無序的。 將3個數據結果集的當前游標指向的數據值進行排序,并放入優先級隊列,t_score_0的第一個數據值最大,t_score_2的第一個數據值次之,t_score_1的第一個數據值最小,因此優先級隊列根據t_score_0,t_score_2和t_score_1的方式排序隊列。
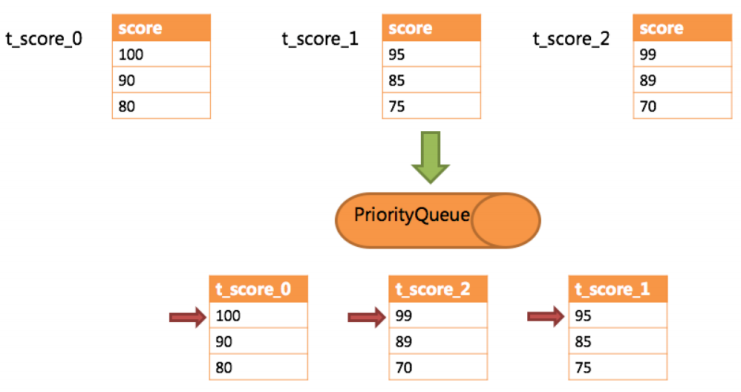
下圖則展現了進行next調用的時候,排序歸并是如何進行的。 通過圖中我們可以看到,當進行第一次next調用時,排在隊列首位的t_score_0將會被彈出隊列,并且將當前游標指向的數據值(也就是100)返回至查詢客戶端,并且將游標下移一位之后,重新放入優先級隊列。 而優先級隊列也會根據t_score_0的當前數據結果集指向游標的數據值(這里是90)進行排序,根據當前數值,t_score_0排列在隊列的最后一位。 之前隊列中排名第二的t_score_2的數據結果集則自動排在了隊列首位。
在進行第二次next時,只需要將目前排列在隊列首位的t_score_2彈出隊列,并且將其數據結果集游標指向的值返回至客戶端,并下移游標,繼續加入隊列排隊,以此類推。 當一個結果集中已經沒有數據了,則無需再次加入隊列。
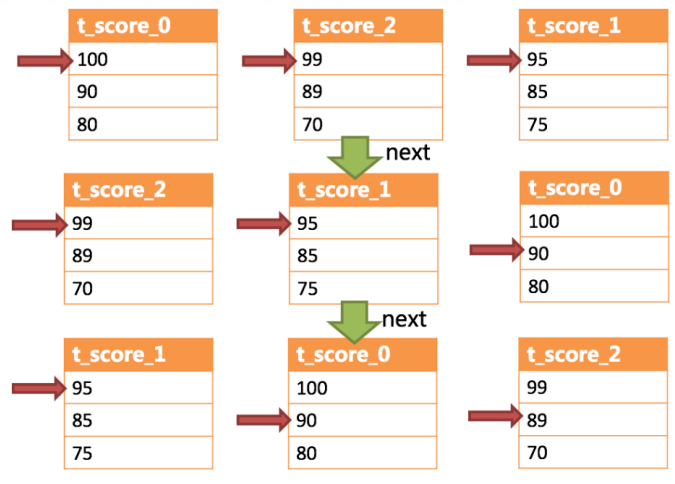
可以看到,對于每個數據結果集中的數據有序,而多數據結果集整體無序的情況下,Sharding-JDBC無需將所有的數據都加載至內存即可排序。 它使用的是流式歸并的方式,每次next僅獲取唯一正確的一條數據,極大的節省了內存的消耗。
裝飾者歸并是對所有的結果集歸并進行統一的功能增強,比如歸并時需要聚合SUM前,在進行聚合計算前,都會通過內存歸并或流式歸并查詢出結果集。因此,聚合歸并是在之前介紹的歸并類型之上追加的歸并能力,即裝飾者模式。
3.7、總結
通過以上內容介紹,相信大家已經了解到Sharding-JDBC基礎概念、核心功能以及執行原理。
基礎概念:邏輯表,真實表,數據節點,綁定表,廣播表,分片鍵,分片算法,分片策略,主鍵生成策略
核心功能:數據分片,讀寫分離
執行流程: SQL解析 => 查詢優化 => SQL路由 => SQL改寫 => SQL執行 => 結果歸并
接下來我們將通過一個個demo,來演示Sharding-JDBC實際使用方法。
.水平分表
前面已經介紹過,水平分表是在同一個數據庫內,把同一個表的數據按一定規則拆到多個表中。在快速入門里,我
們已經對水平分庫進行實現,這里不再重復介紹。
4、水平分表
前面已經介紹過,水平分表是在同一個數據庫內,把同一個表的數據按一定規則拆到多個表中。在快速入門里,我們已經對水平分庫進行實現,這里不再重復介紹。
5、水平分庫
前面已經介紹過,水平分庫是把同一個表的數據按一定規則拆到不同的數據庫中,每個庫可以放在不同的服務器上。接下來看一下如何使用Sharding-JDBC實現水平分庫,咱們繼續對快速入門中的例子進行完善。
1)、將原有order_db庫拆分為order_db_1、order_db_2
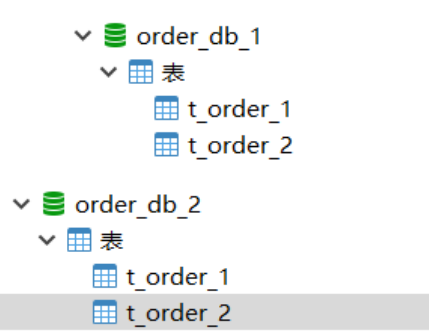
2)、分片規則修改
由于數據庫拆分了兩個,這里需要配置兩個數據源。
分庫需要配置分庫的策略,和分表策略的意義類似,通過分庫策略實現數據操作針對分庫的數據庫進行操作。
# 以下是分片規則配置
# 數據源1
spring.shardingsphere.datasource.names = m1,m2
spring.shardingsphere.datasource.m1.type= com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver‐class‐name = com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = root
# 數據源2
spring.shardingsphere.datasource.m2.type= com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver‐class‐name = com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m2.url = jdbc:mysql://localhost:3306/order_db?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.m2.username = root
spring.shardingsphere.datasource.m2.password = root# 指定t_order表的數據分布情況,配置數據節點
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = m1.t_order_$->{1..2}# 指定t_order表的主鍵生成策略為SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.column = order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type = SNOWFLAKE# 指定t_order表的分片策略,分片策略包括分片鍵和分片算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column = order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression = t_order_$->{order_id % 2 + 1}# 分庫策略,以user_id為分片鍵,分片策略為user_id % 2 + 1,user_id為偶數操作m1數據源,否則操作m2。
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression =m$‐>{user_id % 2 + 1}# 打開sql輸出日志
spring.shardingsphere.props.sql.show = true
分庫策略定義方式如下:
#分庫策略,如何將一個邏輯表映射到多個數據源
spring.shardingsphere.sharding.tables.<邏輯表名稱>.database‐strategy.<分片策略>.<分片策略屬性名>= #
分片策略屬性值
#分表策略,如何將一個邏輯表映射為多個實際表
spring.shardingsphere.sharding.tables.<邏輯表名稱>.table‐strategy.<分片策略>.<分片策略屬性名>= #分
片策略屬性值
Sharding-JDBC支持以下幾種分片策略:
不管理分庫還是分表,策略基本一樣。
- standard:標準分片策略,對應StandardShardingStrategy。提供對SQL語句中的=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持單分片鍵,提供PreciseShardingAlgorithm和
RangeShardingAlgorithm兩個分片算法。PreciseShardingAlgorithm是必選的,用于處理=和IN的分片。
RangeShardingAlgorithm是可選的,用于處理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND將按照全庫路由處理。 - complex:符合分片策略,對應ComplexShardingStrategy。復合分片策略。提供對SQL語句中的=, IN和
BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片鍵,由于多分片鍵之間的關系復
雜,因此并未進行過多的封裝,而是直接將分片鍵值組合以及分片操作符透傳至分片算法,完全由應用開發者實現,提供最大的靈活度。 - inline:行表達式分片策略,對應InlineShardingStrategy。使用Groovy的表達式,提供對SQL語句中的=和IN的分片操作支持,只支持單分片鍵。對于簡單的分片算法,可以通過簡單的配置使用,從而避免繁瑣的Java代碼開發,如: t_user_$->{u_id % 8} 表示t_user表根據u_id模8,而分成8張表,表名稱為 t_user_0 到t_user_7 。
- hint:Hint分片策略,對應HintShardingStrategy。通過Hint而非SQL解析的方式分片的策略。對于分片字段非SQL決定,而由其他外置條件決定的場景,可使用SQL Hint靈活的注入分片字段。例:內部系統,按照員工登錄主鍵分庫,而數據庫中并無此字段。SQL Hint支持通過Java API和SQL注釋(待實現)兩種方式使用。
- none:不分片策略,對應NoneShardingStrategy。不分片的策略。
目前例子中都使用inline分片策略,若對其他分片策略細節若感興趣,請查閱官方文檔:
https://shardingsphere.apache.org
3)、創建數據庫
創建訂單庫order_db_1
CREATE DATABASE `order_db_1` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
在order_db_1中創建t_order_1、t_order_2表
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (`order_id` bigint(20) NOT NULL COMMENT '訂單id',`price` decimal(10, 2) NOT NULL COMMENT '訂單價格',`user_id` bigint(20) NOT NULL COMMENT '下單用戶id',`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '訂單狀態',PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (`order_id` bigint(20) NOT NULL COMMENT '訂單id',`price` decimal(10, 2) NOT NULL COMMENT '訂單價格',`user_id` bigint(20) NOT NULL COMMENT '下單用戶id',`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '訂單狀態',PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
創建訂單庫order_db_2
CREATE DATABASE `order_db_2` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
在order_db_2中創建t_order_1、t_order_2表
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (`order_id` bigint(20) NOT NULL COMMENT '訂單id',`price` decimal(10, 2) NOT NULL COMMENT '訂單價格',`user_id` bigint(20) NOT NULL COMMENT '下單用戶id',`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '訂單狀態',PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (`order_id` bigint(20) NOT NULL COMMENT '訂單id',`price` decimal(10, 2) NOT NULL COMMENT '訂單價格',`user_id` bigint(20) NOT NULL COMMENT '下單用戶id',`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '訂單狀態',PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
4)、插入測試
修改testInsertOrder方法,插入數據中包含不同的user_id
/*** 水平分庫測試*/@Testpublic void testInsertOrderByVSDB() {for (int i = 0; i < 10; i++) {orderDao.insertOrder(new BigDecimal((i + 1) * 5), 1L, "SUCCESS");}for (int i = 0; i < 10; i++) {orderDao.insertOrder(new BigDecimal((i + 1) * 10), 2L, "SUCCESS");}}
執行testInsertOrder:
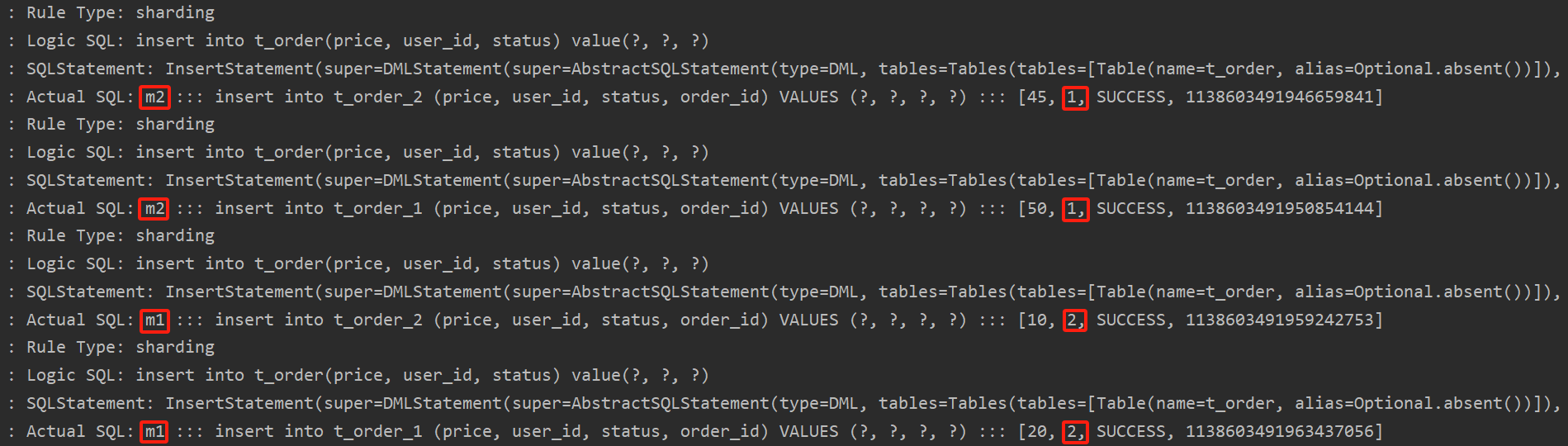
通過日志可以看出,根據user_id的奇偶不同,數據分別落在了不同數據源,達到目標。
5)、查詢測試
調用水平分庫查詢的接口進行測試
/*** 水平分庫查詢測試*/@Testpublic void testSelectOrderVSDBByIds() {List<Long> ids = new ArrayList<>();ids.add(1138603491963437056L);ids.add(1138603491678224385L);List<Map> maps = orderDao.selectOrderbyIds(ids);System.out.println(maps);}
通過日志發現,sharding-jdbc將sql都路由到m1:


問題分析:
由于我們sharding-jdbc配置數據節點只配置了m1,所以看到的sharding-jdbc將sql都路由到m1

解決辦法:
我們sharding-jdbc配置數據節點配置m1,m2
# 指定t_order表的數據分布情況,配置數據節點
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = m$->{1..2}.t_order_$->{1..2}
我們再次調用水平分庫查詢的接口進行測試


由于查詢語句中并沒有使用分片鍵user_id,所以sharding-jdbc將廣播路由到每個數據結點。
下邊我們在sql中添加分片鍵進行查詢。
在OrderDao中定義接口:
@Select({"<script>"," select"," * "," from t_order t ","where t.order_id in","<foreach collection='orderIds' item='id' open='(' separator=',' close=')'>","#{id}","</foreach>"," and t.user_id = #{userId} ","</script>"})List<Map> selectOrderbyUserAndIds(@Param("userId") Integer userId, @Param("orderIds") List<Long> orderIds);
編寫測試方法:
@Testpublic void testSelectOrderbyUserAndIds() {List<Long> orderIds = new ArrayList<>();orderIds.add(1138603491963437056L);orderIds.add(1138603491678224385L);//查詢條件中包括分庫的鍵user_idint user_id = 1;List<Map> orders = orderDao.selectOrderbyUserAndIds(user_id, orderIds);JSONArray jsonOrders = new JSONArray(orders);System.out.println(jsonOrders);}


查詢條件user_id為1,根據分片策略m$->{user_id % 2 + 1}計算得出m2,此sharding-jdbc將sql路由到m2,見上圖日志。
6、垂直分庫
前面已經介紹過,垂直分庫是指按照業務將表進行分類,分布到不同的數據庫上面,每個庫可以放在不同的服務器上,它的核心理念是專庫專用。接下來看一下如何使用Sharding-JDBC實現垂直分庫。
1)、創建數據庫
創建數據庫user_db
CREATE DATABASE `user_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
在user_db中創建t_user表
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`user_id` bigint(20) NOT NULL COMMENT '用戶id',
`fullname` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '用戶姓名',
`user_type` char(1) DEFAULT NULL COMMENT '用戶類型',
PRIMARY KEY (`user_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
2)、在Sharding-JDBC規則中修改
# 新增m0數據源,對應user_db
spring.shardingsphere.datasource.names = m0,m1,m2
# 數據源0
spring.shardingsphere.datasource.m0.type= com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver‐class‐name = com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url = jdbc:mysql://localhost:3306/order_db_1?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.m0.username = root
spring.shardingsphere.datasource.m0.password = root....
# t_user分表策略,固定分配至m0的t_user真實表
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes = m$->{0}.t_user
spring.shardingsphere.sharding.tables.t_user.database-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.t_user.database-strategy.inline.algorithm-expression = m$->{0}
3)、數據操作
新增UserDao:
@Mapper
public interface UserDao {/*** 新增用戶* @param userId 用戶id* @param fullname 用戶姓名* @return*/@Insert("insert into t_user(user_id, fullname) value(#{userId},#{fullname})")int insertUser(@Param("userId")Long userId, @Param("fullname")String fullname);/*** 根據id列表查詢多個用戶* @param userIds 用戶id列表* @return*/@Select({"<script>"," select"," * "," from t_user t "," where t.user_id in","<foreach collection='userIds' item='id' open='(' separator=',' close=')'>","#{id}","</foreach>","</script>"})List<Map> selectUserbyIds(@Param("userIds") List<Long> userIds);
}
執行testInsertUser:
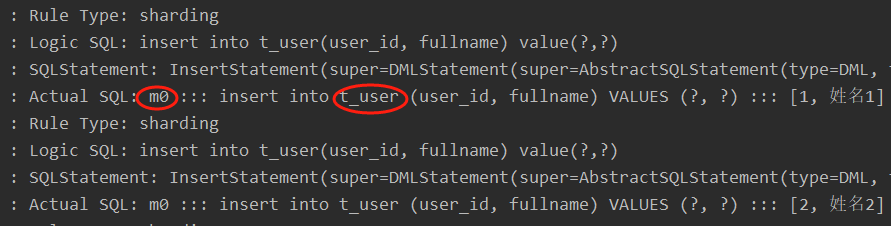
通過日志可以看出t_user表的數據被落在了m0數據源,達到目標。
執行testSelectUserbyIds:


通過日志可以看出t_user表的查詢操作被落在了m0數據源,達到目標
4)、測試
新增單元測試方法:
7、公共表
公共表屬于系統中數據量較小,變動少,而且屬于高頻聯合查詢的依賴表。參數表、數據字典表等屬于此類型。可以將這類表在每個數據庫都保存一份,所有更新操作都同時發送到所有分庫執行。接下來看一下如何使用Sharding-JDBC實現公共表。
1)、創建數據庫
分別在user_db、order_db_1、order_db_2中創建t_dict表:
CREATE TABLE `t_dict` (`dict_id` BIGINT ( 20 ) NOT NULL COMMENT '字典id',`type` VARCHAR ( 50 ) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典類型',`code` VARCHAR ( 50 ) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典編碼',`value` VARCHAR ( 50 ) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典值',PRIMARY KEY ( `dict_id` ) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
2)、在Sharding-JDBC規則中修改
# 指定t_dict為公共表
spring.shardingsphere.sharding.broadcast‐tables=t_dict
3)、數據操作
新增DictDao:
@Mapper
public interface DictDao {/*** 新增字典** @param dictId id* @param type 字典類型* @param code 字典編碼* @param value 字典值* @return*/@Insert("insert into t_dict(dict_id, type, code, value) value(#{dictId}, #{type}, #{code}, #{value})")int insertDict(@Param("dictId") Long dictId, @Param("type") String type, @Param("code") Stringcode, @Param("value") String value);/*** 刪除字典** @param dictId 字典id* @return*/@Delete("delete from t_dict where dict_id = #{dictId}")int deleteDict(@Param("dictId") Long dictId);
}
4)、字典操作測試
新增單元測試方法:
@Testpublic void testInsertDict(){dictDao.insertDict(1L,"user_type","0","管理員");dictDao.insertDict(2L,"user_type","1","操作員");}@Testpublic void testDeleteDict(){dictDao.deleteDict(1L);dictDao.deleteDict(2L);}
執行testInsertDict:
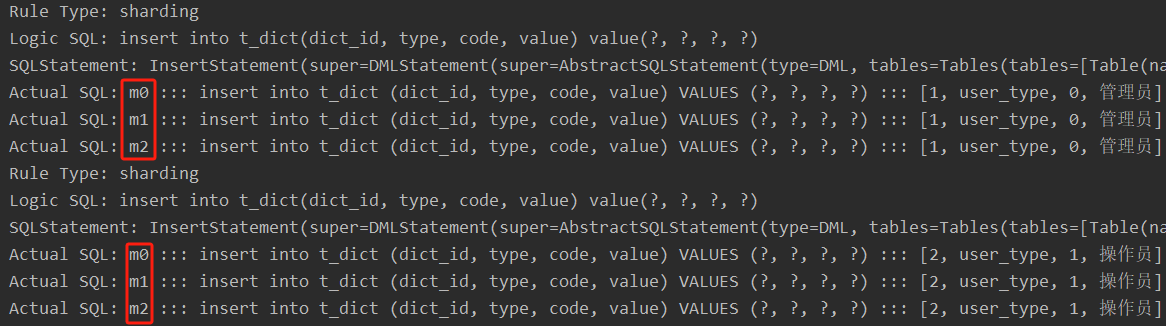
通過日志可以看出,對t_dict的表的操作被廣播至所有數據源。
測試刪除字典,觀察是否把所有數據源中該 公共表的記錄刪除。
5)、字典關聯查詢測試
字典表已在各各分庫存在,各業務表即可和字典表關聯查詢。
定義用戶關聯查詢dao:
在UserDao中定義:
/*** 根據id列表查詢多個用戶,關聯查詢字典表** @param userIds 用戶id列表* @return*/@Select({"<script>"," select"," * "," from t_user t ,t_dict b"," where t.user_type = b.code and t.user_id in","<foreach collection='userIds' item='id' open='(' separator=',' close=')'>","#{id}","</foreach>","</script>"})List<Map> selectUserInfobyIds(@Param("userIds") List<Long> userIds);
定義測試方法:
@Testpublic void testSelectUserInfobyIds(){List<Long> userIds = new ArrayList<>();userIds.add(1L);userIds.add(2L);List<Map> users = dictDao.selectUserInfobyIds(userIds);JSONArray jsonUsers = new JSONArray(users);System.out.println(jsonUsers);}
執行測試方法,查看日志,成功關聯查詢字典表:

8、讀寫分離
8.1、理解讀寫分離
面對日益增加的系統訪問量,數據庫的吞吐量面臨著巨大瓶頸。 對于同一時刻有大量并發讀操作和較少寫操作類型的應用系統來說,將數據庫拆分為主庫和從庫,主庫負責處理事務性的增刪改操作,從庫負責處理查詢操作,能夠有效的避免由數據更新導致的行鎖,使得整個系統的查詢性能得到極大的改善。
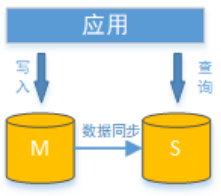
通過一主多從的配置方式,可以將查詢請求均勻的分散到多個數據副本,能夠進一步的提升系統的處理能力。 使用多主多從的方式,不但能夠提升系統的吞吐量,還能夠提升系統的可用性,可以達到在任何一個數據庫宕機,甚至磁盤物理損壞的情況下仍然不影響系統的正常運行。
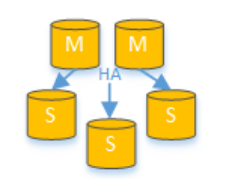
讀寫分離的數據節點中的數據內容是一致的,而水平分片的每個數據節點的數據內容卻并不相同。將水平分片和讀寫分離聯合使用,能夠更加有效的提升系統的性能。
Sharding-JDBC讀寫分離則是根據SQL語義的分析,將讀操作和寫操作分別路由至主庫與從庫。它提供透明化讀寫分離,讓使用方盡量像使用一個數據庫一樣使用主從數據庫集群。
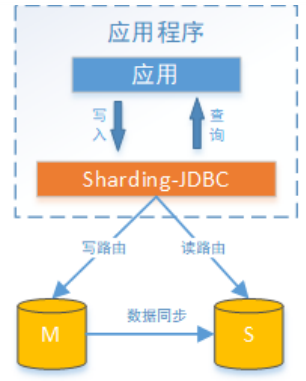
sharding-JDBC提供一主多從的讀寫分離配置,可獨立使用,也可配合分庫分表使用,同一線程且同一數據庫連接內,如有寫入操作,以后的讀操作均從主庫讀取,用于保證數據一致性。Sharding-JDBC不提供主從數據庫的數據同步功能,需要采用其他機制支持。
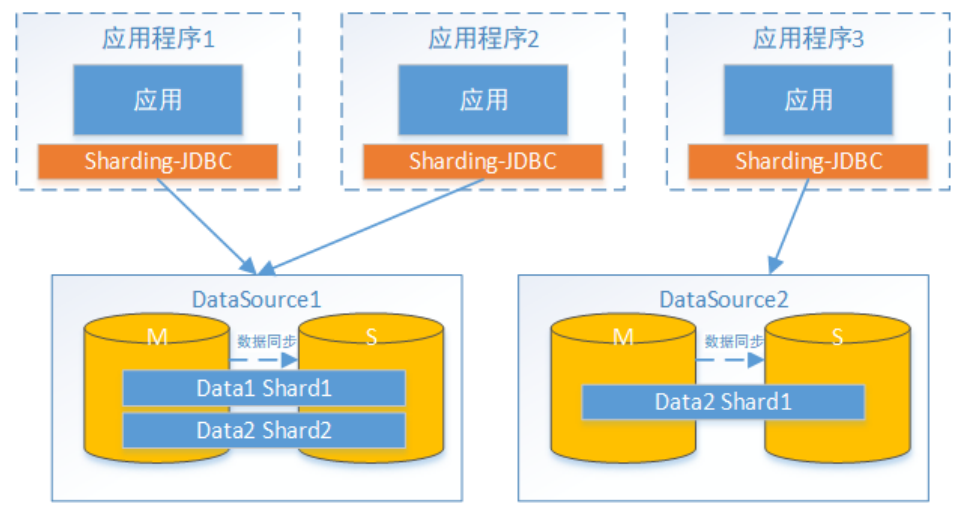
接下來,咱們對上面例子中user_db進行讀寫分離實現。為了實現Sharding-JDBC的讀寫分離,首先,要進行
mysql的主從同步配置。
8.2、mysql主從同步(docker)
8.2.1、新建主服務器容器實例3307
-
下載 mysql 鏡像
docker pull mysql:5.7 -
創建 Master 實例并啟動
docker run -p 3307:3306 --name mysql-master \ -v /mydata/mysql/mysql-master/log:/var/log/mysql \ -v /mydata/mysql/mysql-master/data:/var/lib/mysql \ -v /mydata/mysql/mysql-master/conf:/etc/mysql \ -e MYSQL_ROOT_PASSWORD=root \ -d mysql:5.7參數說明:
- -p 3307:3306:將容器的 3306 端口映射到主機的 3307 端口
- -v /mydata/mysql/mysql-master/conf:/etc/mysql:將配置文件夾掛在到主機
- -v /mydata/mysql/mysql-master/log:/var/log/mysql:將日志文件夾掛載到主機
- -v /mydata/mysql/mysql-master/data:/var/lib/mysql/:將配置文件夾掛載到主機
- -e MYSQL_ROOT_PASSWORD=root:初始化 root 用戶的密碼
-
修改 master 基本配置
進入/mydata/mysql/mysql-master/conf目錄下新建my.cnfvim /mydata/mysql/mysql-master/conf/my.cnf[mysqld] ## 設置server_id,同一局域網中需要唯一 server_id=101 ## 指定不需要同步的數據庫名稱 binlog-ignore-db=mysql ## 開啟二進制日志功能 log-bin=mall-mysql-bin ## 設置二進制日志使用內存大小(事務) binlog_cache_size=1M ## 設置使用的二進制日志格式(mixed,statement,row) binlog_format=mixed ## 二進制日志過期清理時間。默認值為0,表示不自動清理。 expire_logs_days=7 ## 跳過主從復制中遇到的所有錯誤或指定類型的錯誤,避免slave端復制中斷。 ## 如:1062錯誤是指一些主鍵重復,1032錯誤是因為主從數據庫數據不一致。 slave_skip_errors=1062 -
修改完配置后重啟master實例
docker restart mysql-master -
進入mysql-master容器
docker exec -it mysql-master /bin/bashmysql -uroot -proot -
master容器實例內創建數據同步用戶
創建一個具有連接數據庫權限的用戶 ‘slave’,并設置了密碼為 ‘123456’,允許從任何主機連接到MySQL數據庫CREATE USER 'slave'@'%' IDENTIFIED BY '123456';授予了用戶 ‘slave’ 在任何主機上執行MySQL數據庫復制操作和查看復制狀態的權限。這是配置MySQL主從復制所必需的權限之一
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'%';
8.2.2、新建從服務器容器實例3308
-
創建 slave實例并啟動
docker run -p 3308:3306 --name mysql-slave \ -v /mydata/mysql/mysql-slave/log:/var/log/mysql \ -v /mydata/mysql/mysql-slave/data:/var/lib/mysql \ -v /mydata/mysql/mysql-slave/conf:/etc/mysql \ -e MYSQL_ROOT_PASSWORD=root \ -d mysql:5.7 -
修改 slave基本配置
進入/mydata/mysql/mysql-slave/conf目錄下新建my.cnfvim /mydata/mysql/mysql-slave/conf/my.cnf[mysqld] ## 設置server_id,同一局域網中需要唯一 server_id=102 ## 指定不需要同步的數據庫名稱 binlog-ignore-db=mysql ## 開啟二進制日志功能,以備Slave作為其它數據庫實例的Master時使用 log-bin=mall-mysql-slave1-bin ## 設置二進制日志使用內存大小(事務) binlog_cache_size=1M ## 設置使用的二進制日志格式(mixed,statement,row) binlog_format=mixed ## 二進制日志過期清理時間。默認值為0,表示不自動清理。 expire_logs_days=7 ## 跳過主從復制中遇到的所有錯誤或指定類型的錯誤,避免slave端復制中斷。 ## 如:1062錯誤是指一些主鍵重復,1032錯誤是因為主從數據庫數據不一致 slave_skip_errors=1062 ## relay_log配置中繼日志 relay_log=mall-mysql-relay-bin ## log_slave_updates表示slave將復制事件寫進自己的二進制日志 log_slave_updates=1 ## slave設置為只讀(具有super權限的用戶除外) read_only=1 -
修改完配置后重啟slave實例
docker restart mysql-slave -
在主數據庫中查看主從同步狀態
show master status;
-
進入mysql-slave容器
docker exec -it mysql-slave /bin/bashmysql -uroot -proot -
在從數據庫中配置主從復制
change master to master_host='192.168.119.128', master_user='slave', master_password='123456', master_port=3307, master_log_file='mall-mysql-bin.000001', master_log_pos=154, master_connect_retry=30;主從復制命令參數說明:
- master_host:主數據庫的IP地址;
- master_port:主數據庫的運行端口;
- master_user:在主數據庫創建的用于同步數據的用戶賬號;
- master_password:在主數據庫創建的用于同步數據的用戶密碼;
- master_log_file:指定從數據庫要復制數據的日志文件,通過查看主數據的狀態,獲取File參數;
- master_log_pos:指定從數據庫從哪個位置開始復制數據,通過查看主數據的狀態,獲取Position參數;
- master_connect_retry:連接失敗重試的時間間隔,單位為秒。
-
在從數據庫中查看主從同步狀態
show slave status \G;
-
在從數據庫中開啟主從同步
start slave; -
查看從數據庫狀態發現已經同步
show slave status \G;
-
主從復制測試
- 主機新建庫-使用庫-新建表-插入數據,ok

- 從機使用庫-查看記錄,ok

- 主機新建庫-使用庫-新建表-插入數據,ok
8.3.3、創建主從同步的數據庫和表
創建數據庫user_db
CREATE DATABASE `user_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
在user_db中創建t_user表
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`user_id` bigint(20) NOT NULL COMMENT '用戶id',
`fullname` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '用戶姓名',
`user_type` char(1) DEFAULT NULL COMMENT '用戶類型',
PRIMARY KEY (`user_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
8.3、實現sharding-jdbc讀寫分離
1)、在Sharding-JDBC規則中修改
# 增加數據源s0,使用上面主從同步配置的從庫。
spring.shardingsphere.datasource.names = m0,m1,m2,s0
# 數據源0
spring.shardingsphere.datasource.m0.type= com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver‐class‐name = com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url = jdbc:mysql://192.168.119.128:3307/user_db?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.m0.username = root
spring.shardingsphere.datasource.m0.password = rootspring.shardingsphere.datasource.s0.type= com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s0.driver‐class‐name = com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.s0.url = jdbc:mysql://192.168.119.128:3308/user_db?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.s0.username = root
spring.shardingsphere.datasource.s0.password = root
....
# 主庫從庫邏輯數據源定義 ds0為user_db
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name = m0
spring.shardingsphere.sharding.master‐slave‐rules.ds0.slave-data-source-names = s0
# t_user分表策略,固定分配至ds0的t_user真實表
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes = ds0.t_user# t_user分表策略,固定分配至m0的t_user真實表
spring.shardingsphere.sharding.tables.t_user.database-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.t_user.database-strategy.inline.algorithm-expression = ds0
....
2)、測試
執行testInsertUser單元測試:
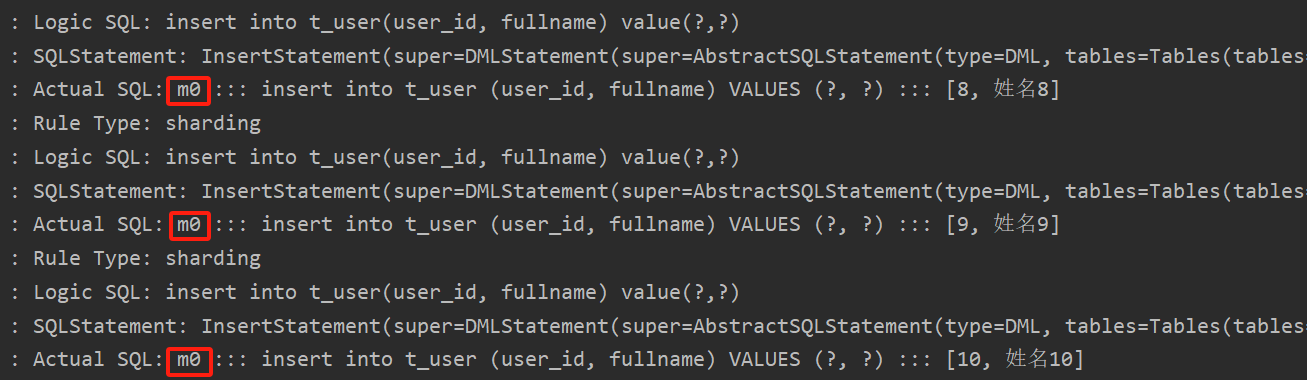
通過日志可以看出,所有寫操作落入m0數據源。
執行testSelectUserbyIds單元測試:

通過日志可以看出,所有寫操作落入s0數據源,達到目標。
9、案例
9.1、需求描述
電商平臺商品列表展示,每個列表項中除了包含商品基本信息、商品描述信息之外,還包括了商品所屬的店鋪信息,如下:
案例實現功能如下:
1、添加商品
2、商品分頁查詢
4、商品統計
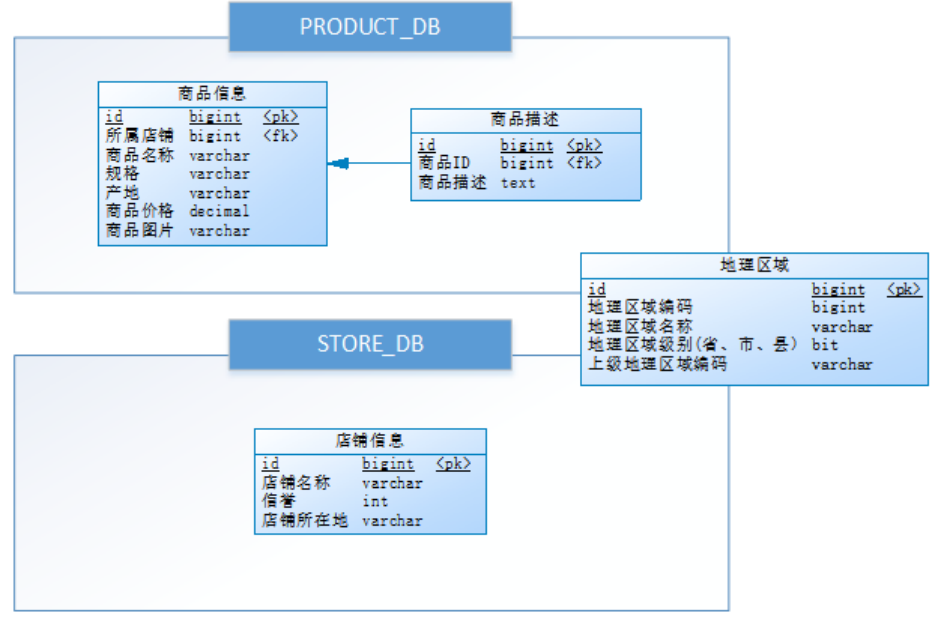
9.2、數據庫設計
數據庫設計如下,其中商品與店鋪信息之間進行了垂直分庫,分為了PRODUCT_DB(商品庫)和STORE_DB(店鋪庫);商品信息還進行了垂直分表,分為了商品基本信息(product_info)和商品描述信息(product_descript),地理區域信息(region)作為公共表,冗余在兩庫中:
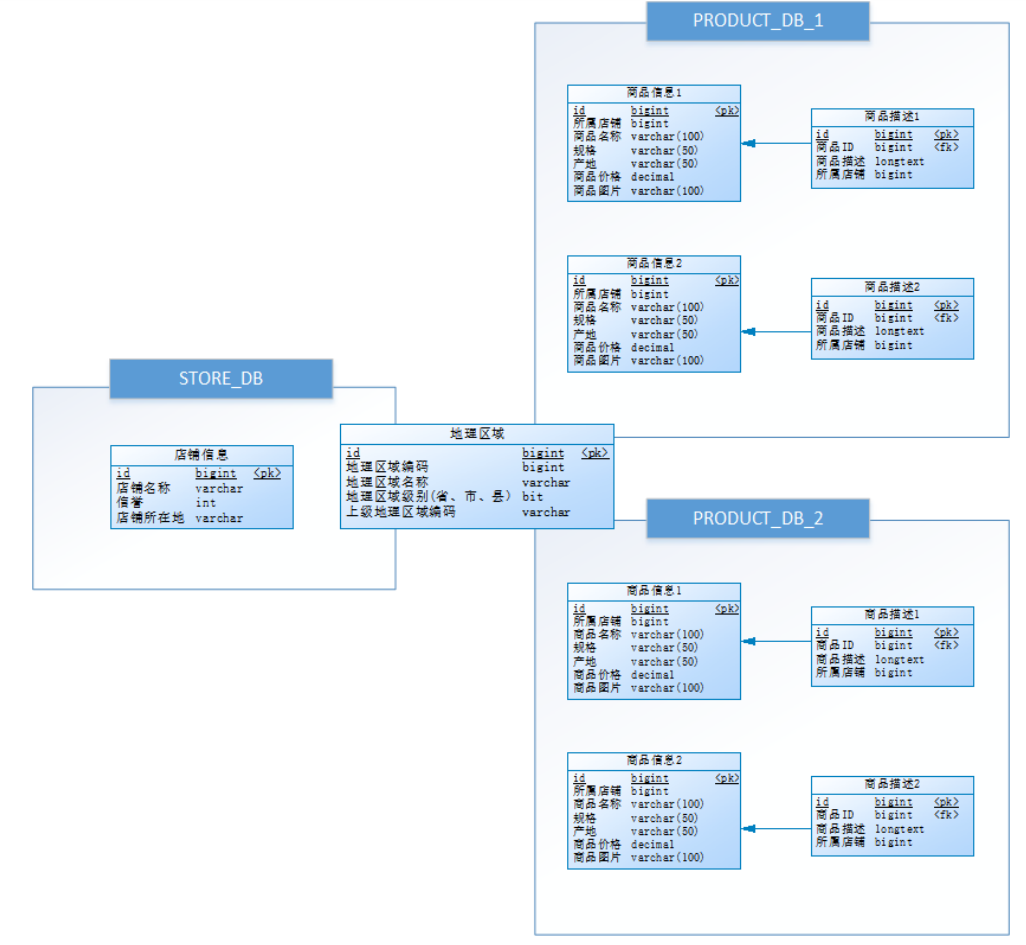
考慮到商品信息的數據增長性,對PRODUCT_DB(商品庫)進行了水平分庫,分片鍵使用店鋪id,分片策略為店鋪 ID%2 + 1,因此商品描述信息對所屬店鋪ID進行了冗余;
對商品基本信息(product_info)和商品描述信息(product_descript)進行水平分表,分片鍵使用商品id,分片策略為商品ID%2 + 1,并將為這兩個表設置為綁定表,避免笛卡爾積join;
為避免主鍵沖突,ID生成策略采用雪花算法來生成全局唯一ID,最終數據庫設計為下圖:
求使用讀寫分離來提升性能,可用性。
9.3、環境說明
- 操作系統:Win10
- 數據庫:MySQL-5.7.25
- JDK:64位 jdk1.8.0_201
- 應用框架:spring-boot-2.7.6,mybatis-plus 3.5.3.1
- Sharding-JDBC:sharding-jdbc-spring-boot-starter-4.0.0-RC1
9.4、環境準備
9.4.1、mysql主從同步(docker)
參考讀寫分離章節,對以下庫進行主從同步配置:
# 設置需要同步的數據庫
binlog‐do‐db=store_db
binlog‐do‐db=product_db_1
binlog‐do‐db=product_db_2
9.4.2、初始化數據庫
創建store_db數據庫,并執行以下腳本創建表:
創建數據庫store_db
CREATE DATABASE `store_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
DROP TABLE IF EXISTS `region`;
CREATE TABLE `region` (
`id` bigint(20) NOT NULL COMMENT 'id',
`region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT
'地理區域編碼',
`region_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
COMMENT '地理區域名稱',
`level` tinyint(1) NULL DEFAULT NULL COMMENT '地理區域級別(省、市、縣)',
`parent_region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
COMMENT '上級地理區域編碼',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `region` VALUES (1, '110000', '北京', 0, NULL);
INSERT INTO `region` VALUES (2, '410000', '河南省', 0, NULL);
INSERT INTO `region` VALUES (3, '110100', '北京市', 1, '110000');
INSERT INTO `region` VALUES (4, '410100', '鄭州市', 1, '410000');
DROP TABLE IF EXISTS `store_info`;
CREATE TABLE `store_info` (
`id` bigint(20) NOT NULL COMMENT 'id',
`store_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT
'店鋪名稱',
`reputation` int(11) NULL DEFAULT NULL COMMENT '信譽等級',
`region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT
'店鋪所在地',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `store_info` VALUES (1, 'XX零食店', 4, '110100');
INSERT INTO `store_info` VALUES (2, 'XX飲品店', 3, '410100');
創建product_db_1、product_db_2數據庫,并分別對兩庫執行以下腳本創建表:
創建數據庫product_db_1
CREATE DATABASE `product_db_1` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
創建數據庫product_db_2
CREATE DATABASE `product_db_2` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
DROP TABLE IF EXISTS `product_descript_1`;
CREATE TABLE `product_descript_1` (
`id` bigint(20) NOT NULL COMMENT 'id',
`product_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所屬商品id',
`descript` longtext CHARACTER SET utf8 COLLATE utf8_general_ci NULL COMMENT '商品描述',
`store_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所屬店鋪id',
PRIMARY KEY (`id`) USING BTREE,
INDEX `FK_Reference_2`(`product_info_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;DROP TABLE IF EXISTS `product_descript_2`;
CREATE TABLE `product_descript_2` (
`id` bigint(20) NOT NULL COMMENT 'id',
`product_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所屬商品id',
`descript` longtext CHARACTER SET utf8 COLLATE utf8_general_ci NULL COMMENT '商品描述',
`store_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所屬店鋪id',
PRIMARY KEY (`id`) USING BTREE,
INDEX `FK_Reference_2`(`product_info_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;DROP TABLE IF EXISTS `product_info_1`;
CREATE TABLE `product_info_1` (
`product_info_id` bigint(20) NOT NULL COMMENT 'id',
`store_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所屬店鋪id',
`product_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
COMMENT '商品名稱',
`spec` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '規
格',
`region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT
'產地',
`price` decimal(10, 0) NULL DEFAULT NULL COMMENT '商品價格',
`image_url` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT
'商品圖片',
PRIMARY KEY (`product_info_id`) USING BTREE,
INDEX `FK_Reference_1`(`store_info_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;DROP TABLE IF EXISTS `product_info_2`;
CREATE TABLE `product_info_2` (
`product_info_id` bigint(20) NOT NULL COMMENT 'id',
`store_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所屬店鋪id',
`product_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
COMMENT '商品名稱',
`spec` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '規
格',
`region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT
'產地',
`price` decimal(10, 0) NULL DEFAULT NULL COMMENT '商品價格',
`image_url` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT
'商品圖片',
PRIMARY KEY (`product_info_id`) USING BTREE,
INDEX `FK_Reference_1`(`store_info_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `region`;CREATE TABLE `region` (
`id` bigint(20) NOT NULL COMMENT 'id',
`region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT
'地理區域編碼',
`region_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
COMMENT '地理區域名稱',
`level` tinyint(1) NULL DEFAULT NULL COMMENT '地理區域級別(省、市、縣)',
`parent_region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
COMMENT '上級地理區域編碼',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `region` VALUES (1, '110000', '北京', 0, NULL);
INSERT INTO `region` VALUES (2, '410000', '河南省', 0, NULL);
INSERT INTO `region` VALUES (3, '110100', '北京市', 1, '110000');
INSERT INTO `region` VALUES (4, '410100', '鄭州市', 1, '410000');
9.5、實現步驟
9.5.1、搭建maven工程
(1)搭建工程maven工程shopping,導入資料中基礎代碼shopping,以dbsharding為總體父工程,并做好
spring boot相關配置。
(2)引入maven依賴
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.6</version><relativePath/> <!-- lookup parent from repository --></parent><modelVersion>4.0.0</modelVersion><artifactId>shopping</artifactId><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-configuration-processor</artifactId><optional>true</optional></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.18</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.3.1</version></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.0.0-RC1</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.10.1</version></dependency><dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger-ui</artifactId><version>2.10.1</version></dependency></dependencies></project>
9.5.2、分片配置
既然是分庫分表,那么就需要定義多個真實數據源,每一個數據庫鏈接信息就是一個數據源定義,如:
spring.shardingsphere.datasource.m0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m0.url = jdbc:mysql://192.168.119.128:3307/store_db?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.m0.username = root
spring.shardingsphere.datasource.m0.password = root
m0,就是這個真實數據源的名稱,然后需要告訴Sharding-JDBC,咱們有哪些真實數據源,如:
spring.shardingsphere.datasource.names = m0,m1,m2,s0,s1,s2
如果需要配置讀寫分離,還需要告訴Sharding-JDBC,這么多真實數據源,那幾個是一套讀寫分離?也就是定義主從邏輯數據源:
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name = m0
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names = s0
我們已經對m0和s0做了mysql主從同步,那我們需要告訴Sharding-JDBC,m0、s0為一組主從同步數據源,其
中m0為主,s0為從,并且定義名稱為ds0,這個ds0就是主從邏輯數據源。
最終配置如下,具體的分庫分表策略參考注釋內容:
server.port=56082spring.application.name = shopping
spring.profiles.active = localserver.servlet.context-path = /shopping
server.servlet.encoding.enabled = true
server.servlet.encoding.charset = UTF-8
server.servlet.encoding.force = truemybatis.configuration.map-underscore-to-camel-case = true#sharding-jdbc分片規則
#配置數據源 m0,m1,m2,s0,s1,s2
spring.shardingsphere.datasource.names = m0,m1,m2,s0,s1,s2spring.shardingsphere.datasource.m0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m0.url = jdbc:mysql://192.168.119.128:3307/store_db?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.m0.username = root
spring.shardingsphere.datasource.m0.password = rootspring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://192.168.119.128:3307/product_db_1?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = rootspring.shardingsphere.datasource.m2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url = jdbc:mysql://192.168.119.128:3307/product_db_2?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.m2.username = root
spring.shardingsphere.datasource.m2.password = rootspring.shardingsphere.datasource.s0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s0.url = jdbc:mysql://192.168.119.128:3308/store_db?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.s0.username = root
spring.shardingsphere.datasource.s0.password = rootspring.shardingsphere.datasource.s1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s1.url = jdbc:mysql://192.168.119.128:3308/product_db_1?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.s1.username = root
spring.shardingsphere.datasource.s1.password = rootspring.shardingsphere.datasource.s2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s2.url = jdbc:mysql://192.168.119.128:3308/product_db_2?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.s2.username = root
spring.shardingsphere.datasource.s2.password = root#主從關系
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name = m0
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names = s0
spring.shardingsphere.sharding.master-slave-rules.ds1.master-data-source-name = m1
spring.shardingsphere.sharding.master-slave-rules.ds1.slave-data-source-names = s1
spring.shardingsphere.sharding.master-slave-rules.ds2.master-data-source-name = m2
spring.shardingsphere.sharding.master-slave-rules.ds2.slave-data-source-names = s2#分庫策略(水平)
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column = store_info_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression = ds$->{store_info_id % 2 + 1}#分表策略
# store_info分表策略
spring.shardingsphere.sharding.tables.store_info.actual-data-nodes = ds$->{0}.store_info
spring.shardingsphere.sharding.tables.store_info.table-strategy.inline.sharding-column = id
spring.shardingsphere.sharding.tables.store_info.table-strategy.inline.algorithm-expression = store_info# product_info分表策略
#數據結點包括,ds1.product_info_1,ds1.product_info_2,ds2.product_info_1,ds2.product_info_2
spring.shardingsphere.sharding.tables.product_info.actual-data-nodes = ds$->{1..2}.product_info_$->{1..2}
spring.shardingsphere.sharding.tables.product_info.table-strategy.inline.sharding-column = product_info_id
spring.shardingsphere.sharding.tables.product_info.table-strategy.inline.algorithm-expression = product_info_$->{product_info_id%2+1}
spring.shardingsphere.sharding.tables.product_info.key-generator.column = product_info_id
spring.shardingsphere.sharding.tables.product_info.key-generator.type =SNOWFLAKE#product_descript分表策略
spring.shardingsphere.sharding.tables.product_descript.actual-data-nodes = ds$->{1..2}.product_descript_$->{1..2}
spring.shardingsphere.sharding.tables.product_descript.table-strategy.inline.sharding-column = product_info_id
spring.shardingsphere.sharding.tables.product_descript.table-strategy.inline.algorithm-expression = product_descript_$->{product_info_id % 2 + 1}
spring.shardingsphere.sharding.tables.product_descript.key-generator.column = id
spring.shardingsphere.sharding.tables.product_descript.key-generator.type = SNOWFLAKE# 設置product_info,product_descript為綁定表
spring.shardingsphere.sharding.binding-tables[0] = product_info,product_descript# 設置region為廣播表(公共表),每次更新操作會發送至所有數據源
spring.shardingsphere.sharding.broadcast-tables = region# 打開sql輸出日志
spring.shardingsphere.props.sql.show = trueswagger.enable = truelogging.level.root = info
logging.level.org.springframework.web = info
logging.level.com.itheima.dbsharding = debug
9.5.3、添加商品
實體類
參考基礎工程:
DAO實現
添加“com.itheima.shopping.dao.ProductDao”類,代碼如下:
@Mapper
public interface ProductDao {/*** 添加商品基本信息** @param productInfo* @return*/@Insert("insert into product_info(store_info_id,product_name,spec,region_code,price) " +" values (#{storeInfoId},#{productName},#{spec},#{regionCode},#{price})")@Options(useGeneratedKeys = true, keyProperty = "productInfoId", keyColumn = "product_info_id")int insertProductInfo(ProductInfo productInfo);/*** 添加商品描述信息** @param productDescript* @return*/@Insert("insert into product_descript(product_info_id,descript,store_info_id) " +" value(#{productInfoId},#{descript},#{storeInfoId})")@Options(useGeneratedKeys = true, keyProperty = "id", keyColumn = "id")int insertProductDescript(ProductDescript productDescript);@Select("select i.*,d.descript,r.region_name placeOfOrigin from product_info i join product_descript d on i.product_info_id = d.product_info_id " +" join region r on i.region_code = r.region_code order by product_info_id desc limit #{start},#{pageSize}")List<ProductInfo> selectProductList(@Param("start") int start, @Param("pageSize") int pageSize);
}
service實現
針對垂直分庫的兩個庫,分別實現店鋪服務、商品服務
添加“com.itheima.shopping.service.ProductService”類,代碼如下:
public interface ProductService {/*** 添加商品** @param product*/void createProduct(ProductInfo product);
}
添加“com.itheima.shopping.service.impl.ProductServiceImpl”類,代碼如下:
@Service
public class ProductServiceImpl implements ProductService {@AutowiredProductDao productDao;/*** 添加商品** @param productInfo 商品信息*/@Override@Transactionalpublic void createProduct(ProductInfo productInfo) {ProductDescript productDescript = new ProductDescript();// 調用dao向商品信息表插入數據productDao.insertProductInfo(productInfo);// 將商品信息id設置到productDescriptproductDescript.setProductInfoId(productInfo.getProductInfoId());// 設置店鋪idproductDescript.setStoreInfoId(productInfo.getStoreInfoId());// 設置商品描述信息productDescript.setDescript(productInfo.getDescript());// 向商品描述信息表插入數據productDao.insertProductDescript(productDescript);}
}
controller實現
添加“com.itheima.shopping.controller.SellerController”類,代碼如下:
@RestController
public class SellerController {@Autowiredprivate ProductService productService;@PostMapping("/products")public String createProject(@RequestBody ProductInfo productInfo) {productService.createProduct(productInfo);return "創建成功!";}
}
單元測試:
@SpringBootTest
public class ShardingTest {@AutowiredProductService productService;@AutowiredProductDao productDao;//添加商品@Testpublic void testCreateProduct() {for (int i = 1; i < 10; i++) {ProductInfo productInfo = new ProductInfo();productInfo.setStoreInfoId(2L);//店鋪idproductInfo.setProductName("Java編程思想" + i);//商品名稱productInfo.setSpec("大號");productInfo.setPrice(new BigDecimal(60));productInfo.setRegionCode("110100");productInfo.setDescript("Java編程思想不錯!!!" + i);//商品描述productService.createProduct(productInfo);}}
}
這里使用了sharding-jdbc所提供的全局主鍵生成方式之一雪花算法,來生成全局業務唯一主鍵。
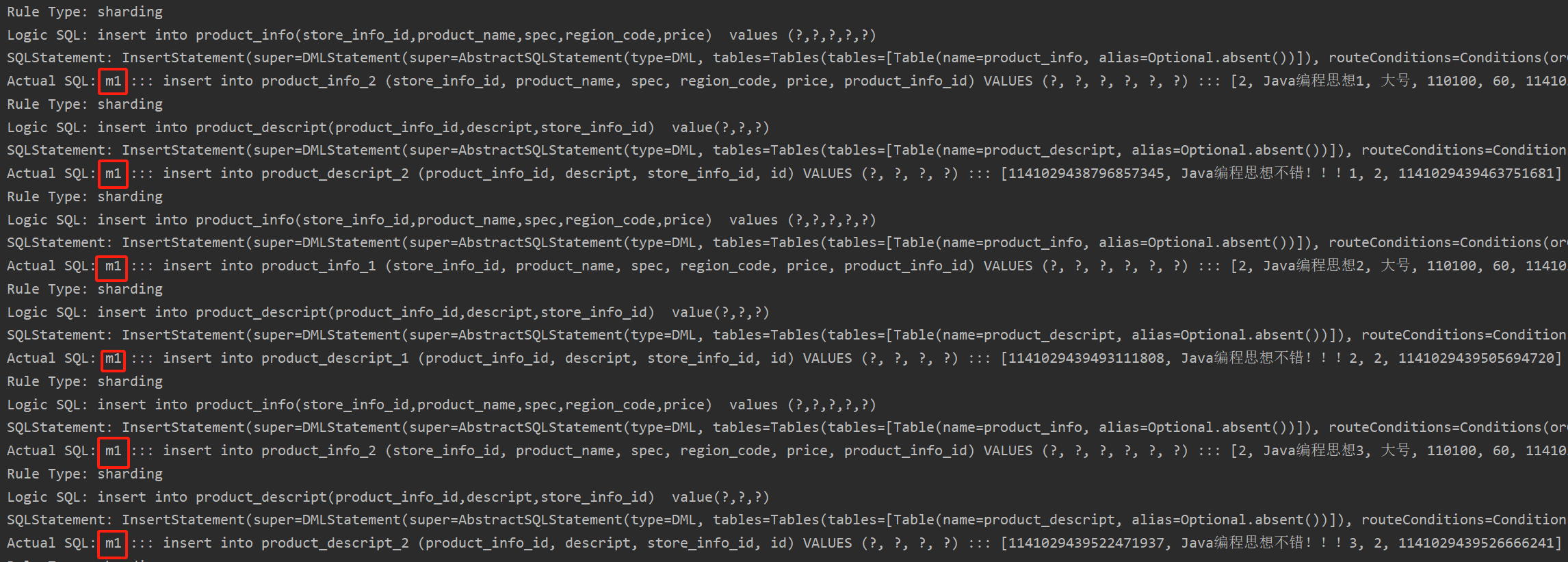
通過添加商品接口新增商品進行分庫驗證,store_info_id為偶數的數據在product_db_1, 為奇數的數據在
product_db_2。
9.5.4、查詢商品
Dao實現
在ProductDao中定義商品查詢方法:
修改“com.itheima.shopping.dao.ProductDao”類,代碼如下:
/*** 查詢商品列表** @param start* @param pageSize* @return*/@Select("select i.*,d.descript,r.region_name placeOfOrigin from product_info i " +"join product_descript d on i.product_info_id = d.product_info_id " +" join region r on i.region_code = r.region_code " +"order by product_info_id " +"desc limit #{start},#{pageSize}")List<ProductInfo> selectProductList(@Param("start") int start, @Param("pageSize") int pageSize);
Service實現
在ProductServiceImpl定義商品查詢方法
修改“com.itheima.shopping.service.ProductService”類,代碼如下:
/*** 查詢商品** @param page* @param pageSize* @return*/List<ProductInfo> queryProduct(int page, int pageSize);
修改“com.itheima.shopping.service.impl.ProductServiceImpl”類,代碼如下:
@Overridepublic List<ProductInfo> queryProduct(int page, int pageSize) {int start = (page - 1) * pageSize;return productDao.selectProductList(start, pageSize);}
Controller實現
修改“com.itheima.shopping.controller.SellerController”類,代碼如下:
@GetMapping(value = "/products/{page}/{pageSize}")public List<ProductInfo> queryProduct(@PathVariable("page") int page, @PathVariable("pageSize") int pageSize) {return productService.queryProduct(page, pageSize);}
單元測試
/*** 查詢商品*/@Testpublic void testSelectProductList() {List<ProductInfo> productInfos = productService.queryProduct(1, 10);System.out.println(productInfos);}

[
ProductInfo(productInfoId=1141029439648301057, storeInfoId=2, productName=Java編程思想9, spec=大號, regionCode=110100, price=60, imageUrl=null, descript=Java編程思想不錯!!!9, placeOfOrigin=北京市, storeName=null, reputation=0, storeRegionName=null), ProductInfo(productInfoId=1141029439623135232, storeInfoId=2, productName=Java編程思想8, spec=大號, regionCode=110100, price=60, imageUrl=null, descript=Java編程思想不錯!!!8, placeOfOrigin=北京市, storeName=null, reputation=0, storeRegionName=null),
ProductInfo(productInfoId=1141029439606358017, storeInfoId=2, productName=Java編程思想7, spec=大號, regionCode=110100, price=60, imageUrl=null, descript=Java編程思想不錯!!!7, placeOfOrigin=北京市, storeName=null, reputation=0, storeRegionName=null),
ProductInfo(productInfoId=1141029439581192192, storeInfoId=2, productName=Java編程思想6, spec=大號, regionCode=110100, price=60, imageUrl=null, descript=Java編程思想不錯!!!6, placeOfOrigin=北京市, storeName=null, reputation=0, storeRegionName=null),
ProductInfo(productInfoId=1141029439560220673, storeInfoId=2, productName=Java編程思想5, spec=大號, regionCode=110100, price=60, imageUrl=null, descript=Java編程思想不錯!!!5, placeOfOrigin=北京市, storeName=null, reputation=0, storeRegionName=null),
ProductInfo(productInfoId=1141029439539249152, storeInfoId=2, productName=Java編程思想4, spec=大號, regionCode=110100, price=60, imageUrl=null, descript=Java編程思想不錯!!!4, placeOfOrigin=北京市, storeName=null, reputation=0, storeRegionName=null),
ProductInfo(productInfoId=1141029439522471937, storeInfoId=2, productName=Java編程思想3, spec=大號, regionCode=110100, price=60, imageUrl=null, descript=Java編程思想不錯!!!3, placeOfOrigin=北京市, storeName=null, reputation=0, storeRegionName=null),
ProductInfo(productInfoId=1141029439493111808, storeInfoId=2, productName=Java編程思想2, spec=大號, regionCode=110100, price=60, imageUrl=null, descript=Java編程思想不錯!!!2, placeOfOrigin=北京市, storeName=null, reputation=0, storeRegionName=null),
ProductInfo(productInfoId=1141029438796857345, storeInfoId=2, productName=Java編程思想1, spec=大號, regionCode=110100, price=60, imageUrl=null, descript=Java編程思想不錯!!!1, placeOfOrigin=北京市, storeName=null, reputation=0, storeRegionName=null)
]
通過查詢商品列表接口,能夠查詢到所有分片的商品信息,關聯的地理區域,店鋪信息正確。
如果我們查詢第2頁,每頁2條數據,可以看到sharding-jdbc是從0開開始查,查詢4條,排序好之后,返回對應的數據。
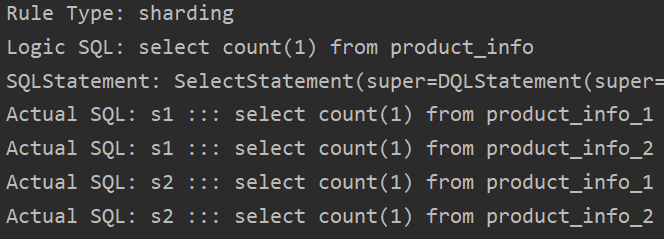
Rule Type: shardingLogic SQL: select i.*,d.descript,r.region_name placeOfOrigin from product_info i join product_descript d on i.product_info_id = d.product_info_id join region r on i.region_code = r.region_code order by product_info_id desc limit ?,?Actual SQL: s1 ::: select i.*,d.descript,r.region_name placeOfOrigin from product_info_1 i join product_descript_1 d on i.product_info_id = d.product_info_id join region r on i.region_code = r.region_code order by product_info_id desc limit ?,? ::: [0, 4]Actual SQL: s1 ::: select i.*,d.descript,r.region_name placeOfOrigin from product_info_2 i join product_descript_2 d on i.product_info_id = d.product_info_id join region r on i.region_code = r.region_code order by product_info_id desc limit ?,? ::: [0, 4]Actual SQL: s2 ::: select i.*,d.descript,r.region_name placeOfOrigin from product_info_1 i join product_descript_1 d on i.product_info_id = d.product_info_id join region r on i.region_code = r.region_code order by product_info_id desc limit ?,? ::: [0, 4]Actual SQL: s2 ::: select i.*,d.descript,r.region_name placeOfOrigin from product_info_2 i join product_descript_2 d on i.product_info_id = d.product_info_id join region r on i.region_code = r.region_code order by product_info_id desc limit ?,? ::: [0, 4]
總結:
分頁查詢是業務中最常見的場景,Sharding-jdbc支持常用關系數據庫的分頁查詢,不過Sharding-jdbc的分頁功能比較容易讓使用者誤解,用戶通常認為分頁歸并會占用大量內存。 在分布式的場景中,將 LIMIT 10000000 , 10改寫為 LIMIT 0, 10000010 ,才能保證其數據的正確性。 用戶非常容易產生ShardingSphere會將大量無意義的數據加載至內存中,造成內存溢出風險的錯覺。 其實大部分情況都通過流式歸并獲取數據結果集,因此ShardingSphere會通過結果集的next方法將無需取出的數據全部跳過,并不會將其存入內存。
但同時需要注意的是,由于排序的需要,大量的數據仍然需要傳輸到Sharding-Jdbc的內存空間。 因此,采用LIMIT這種方式分頁,并非最佳實踐。 由于LIMIT并不能通過索引查詢數據,因此如果可以保證ID的連續性,通過ID進行分頁是比較好的解決方案,例如
SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id;
或通過記錄上次查詢結果的最后一條記錄的ID進行下一頁的查詢,例如:
SELECT * FROM t_order WHERE id > 10000000 LIMIT 10;
排序功能是由Sharding-jdbc的排序歸并來完成,由于在SQL中存在 ORDER BY 語句,因此每個數據結果集自身是有序的,因此只需要將數據結果集當前游標指向的數據值進行排序即可。 這相當于對多個有序的數組進行排序,歸并排序是最適合此場景的排序算法。
9.5.5、統計商品
本小節實現商品總數統計,商品分組統計
Dao實現
修改“com.itheima.shopping.dao.ProductDao”類,代碼如下:
在ProductDao中定義:
/*** 商品總數** @return*/@Select("select count(1) from product_info")int selectCount();/*** 商品分組統計** @return*/@Select("select t.region_code,count(1) as num from product_info t group by t.region_code having num > 1 order by region_code ")List<Map> selectProductGroupList();
單元測試:
/*** 統計商品總數*/@Testpublic void testSelectCount() {int i = productDao.selectCount();System.out.println(i);}/*** 分組統計商品*/@Testpublic void testSelectProductGroupList() {List<Map> maps = productDao.selectProductGroupList();System.out.println(maps);}
結果


總結:
分組統計
分組統計也是業務中常見的場景,分組功能的實現由Sharding-jdbc分組歸并完成。分組歸并的情況最為復雜,它分為流式分組歸并和內存分組歸并。 流式分組歸并要求SQL的排序項與分組項的字段必須保持一致,否則只能通過內存歸并才能保證其數據的正確性。
舉例說明,假設根據科目分片,表結構中包含考生的姓名(為了簡單起見,不考慮重名的情況)和分數。通過SQL獲取每位考生的總分,可通過如下SQL:
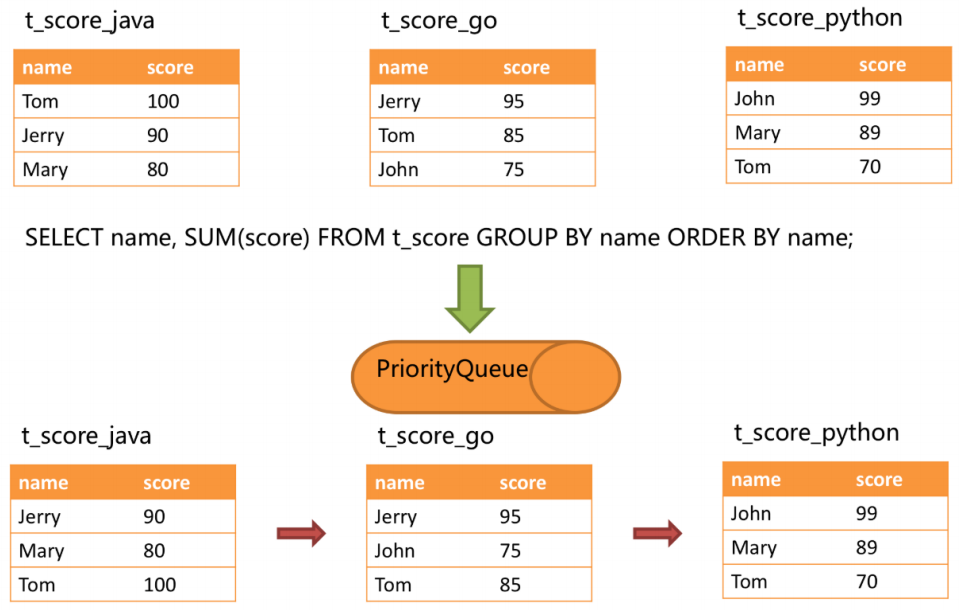
SELECT name, SUM(score) FROM t_score GROUP BY name ORDER BY name;
在分組項與排序項完全一致的情況下,取得的數據是連續的,分組所需的數據全數存在于各個數據結果集的當前游標所指向的數據值,因此可以采用流式歸并。如下圖所示。
進行歸并時,邏輯與排序歸并類似。 下圖展現了進行next調用的時候,流式分組歸并是如何進行的。
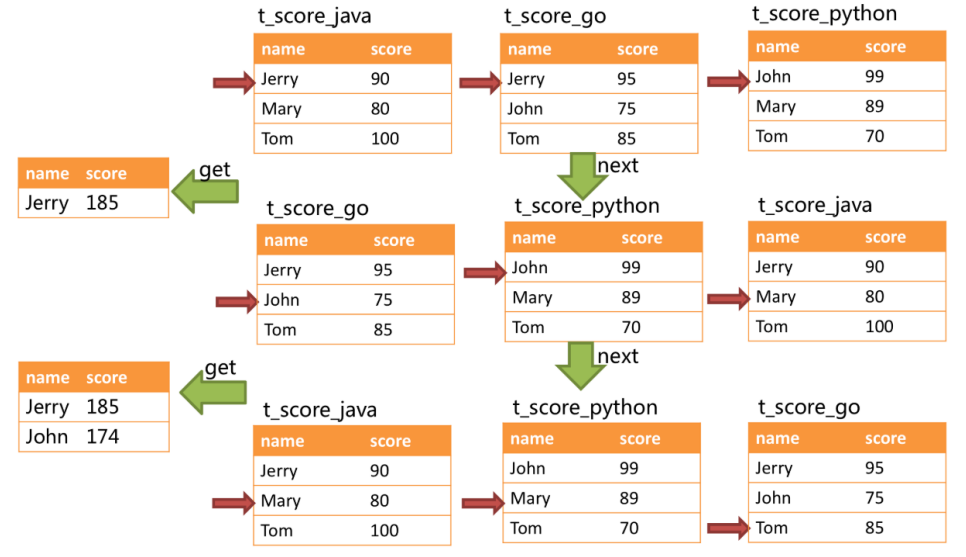
通過圖中我們可以看到,當進行第一次next調用時,排在隊列首位的t_score_java將會被彈出隊列,并且將分組值同為“Jetty”的其他結果集中的數據一同彈出隊列。 在獲取了所有的姓名為“Jetty”的同學的分數之后,進行累加操作,那么,在第一次next調用結束后,取出的結果集是“Jetty”的分數總和。 與此同時,所有的數據結果集中的游標都將下移至數據值“Jetty”的下一個不同的數據值,并且根據數據結果集當前游標指向的值進行重排序。 因此,包含名字順著第二位的“John”的相關數據結果集則排在的隊列的前列。
10、課程總結
重點知識回顧:
為什么分庫分表?分庫分表就是為了解決由于數據量過大而導致數據庫性能降低的問題,將原來獨立的數據庫拆分成若干數據庫組成 ,將數據大表拆分成若干數據表組成,使得單一數據庫、單一數據表的數據量變小,從而達到提升數據庫性能的目的。
分庫分表方式:垂直分表、垂直分庫、水平分庫、水平分表
分庫分表帶來問題:由于數據分散在多個數據庫,服務器導致了事務一致性問題、跨節點join問題、跨節點分頁、排序、函數,主鍵需要全局唯一,公共表。
Sharding-JDBC基礎概念:邏輯表,真實表,數據節點,綁定表,廣播表,分片鍵,分片算法,分片策略,主鍵生成策略
Sharding-JDBC核心功能:數據分片,讀寫分離
Sharding-JDBC執行流程: SQL解析 => 查詢優化 => SQL路由 => SQL改寫 => SQL執行 => 結果歸并
最佳實踐:
系統在設計之初就應該對業務數據的耦合松緊進行考量,從而進行垂直分庫、垂直分表,使數據層架構清晰明了。若非必要,無需進行水平切分,應先從緩存技術著手降低對數據庫的訪問壓力。如果緩存使用過后,數據庫訪問量還是非常大,可以考慮數據庫讀、寫分離原則。若當前數據庫壓力依然大,且業務數據持續增長無法估量,最后可考慮水平分庫、分表,單表拆分數據控制在1000萬以內。



)

 2016. 增量元素之間的最大差值 (數組))







Python實現(帶測試))





