報表作為綜合業務,數據來源多種多樣。傳統實現多源混合查詢報表要通過 ETL 將數據同庫,但這種方式數據時效性太差使用場景受限。通過邏輯數倉能獲得較強的數據實時性,但體系又過于沉重,為報表業務搭建邏輯數倉有點得不償失。需要一種更為簡單輕量的多源報表實現方式。
SPL 能很好解決這個問題。作為輕量級計算引擎,SPL 具備天然多源混算能力,可以嵌入到報表中快速實現多源混算報表。
SPL 之所以具備天然混算能力,除了豐富的多樣性數據源支持,更重要的是所有數據源接入后都會轉換成統一數據對象:序表或游標,任何數據源只要能訪問到就能混算。
目前主流報表工具潤乾報表已經集成了 SPL,可以直接獲得多源混合查詢能力。
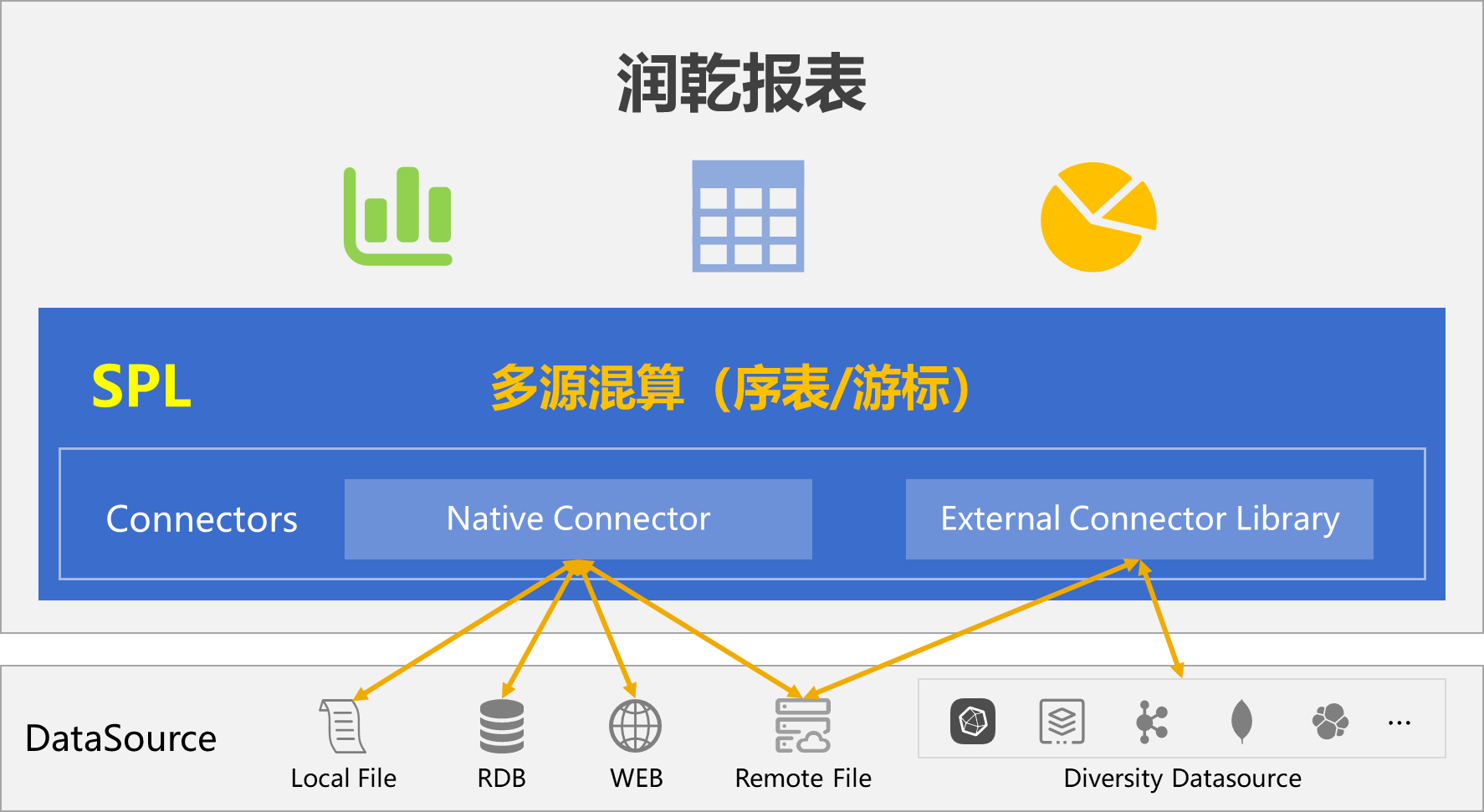
SPL 為多源計算設計了兩種 Connector,最常見的 RDB,文本、Excel、JSON 等本地文件,以及 HTTP 數據源等屬于原生 Connector 內置在 SPL 核心體系中。而對于一些沒那么常用的數據源,像 MongoDB、Kafka、ES 這些,SPL 基于數據源的原生接口進行了簡單封裝,以外部 Connector 的形式提供,用到時單獨引入即可。采用這種輕封裝(相對邏輯數倉要深度定制開發)的模式可以讓報表對數據源的支持更容易擴展,同時還能保留數據源的原生語法充分發揮數據源自身的能力。
比如,在實際的電商業務中,MySQL 存儲訂單相關信息。同時,由于商品信息會根據類型動態變化,比如電子產品有品牌、型號和規格,而服裝則包括品牌、尺寸和顏色,因此使用 MongoDB 來存儲商品信息。
現在基于訂單銷售統計報表,查詢指定時間段內不同類型('Tablets', 'Wearables', 'Audio')、品牌、商品的銷售總額,這需要跨 MySQL 和 MongoDB 混合查詢。
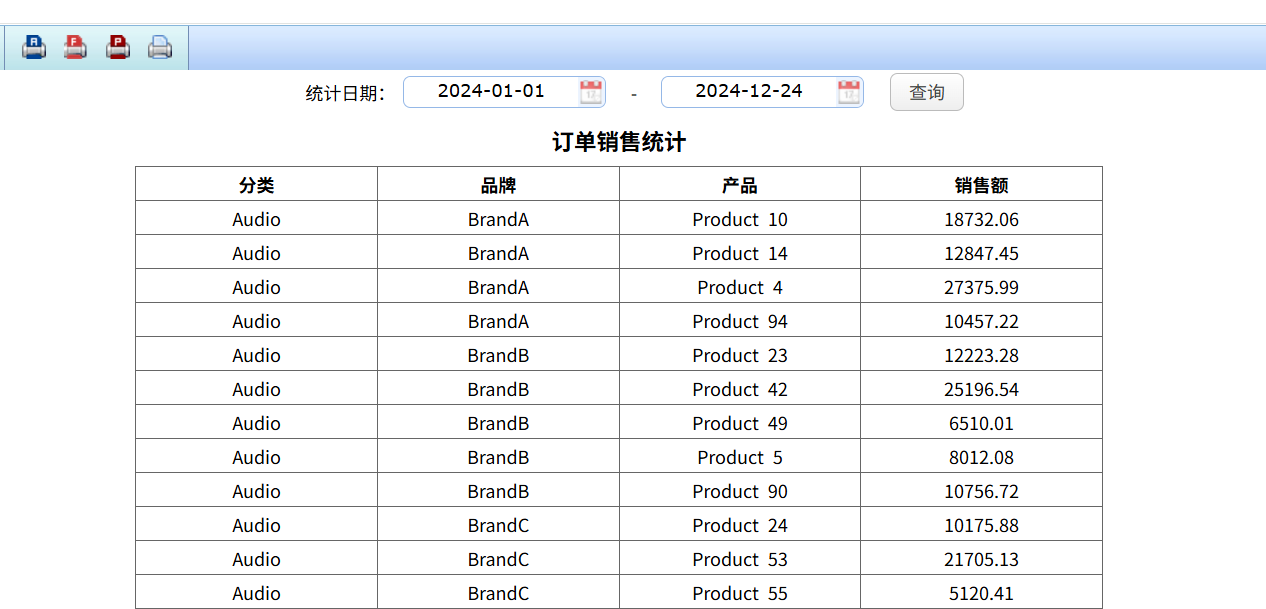
先通過 SPL 做跨庫查詢準備數據,編寫 MySQL+Mongo.splx 腳本:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x ("SELECT o.order_id, o.user_id, o.order_date, oi.product_id, oi.quantity, oi.price FROM orders o JOIN order_items oi ON o.order_id = oi.order_id WHERE o.order_date>=? and o.order_date<=?",begin,end) |
| 3 | =mongo_open("mongodb://127.0.0.1:27017/raqdb") |
| 4 | =mongo_shell@d(A3, "{'find':'products', 'filter': { 'category': {'$in': ['Tablets', 'Wearables', 'Audio'] } }}” ) |
| 5 | =A2.join@i(product_id,A4:product_id,name,brand,category,attributes) |
| 6 | =A5.groups(category,brand,name;sum(price*quantity):amount) |
| 7 | return ifn(A6,create(category,brand,name,amount)) |
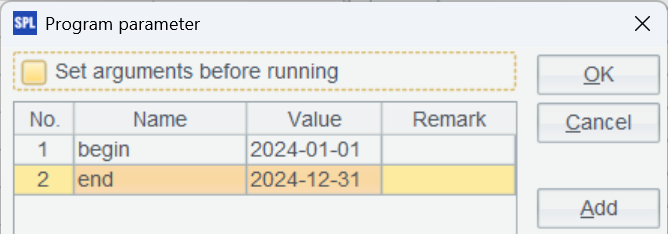
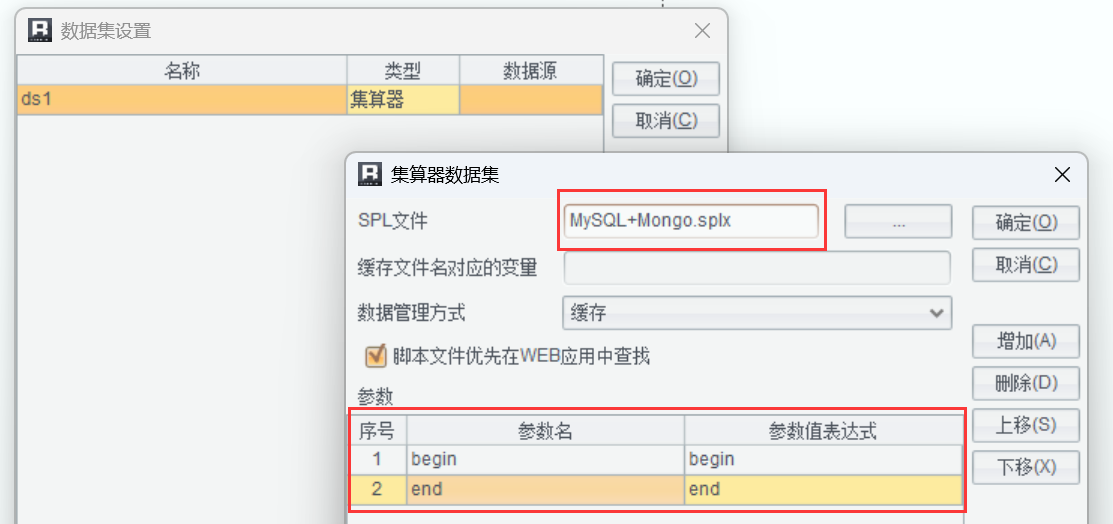
先連接 MySQL 并查詢指定時間段的數據,begin 和 end 是報表中傳遞過來的參數,需要在腳本中增加相應的參數設置:
然后讀取 MongoDB 數據,這里的語法都是 MongoDB 原生語法(在 Mongoshell 中可以直接執行)。
最后兩部分數據進行關聯計算并分組匯總返回計算結果。
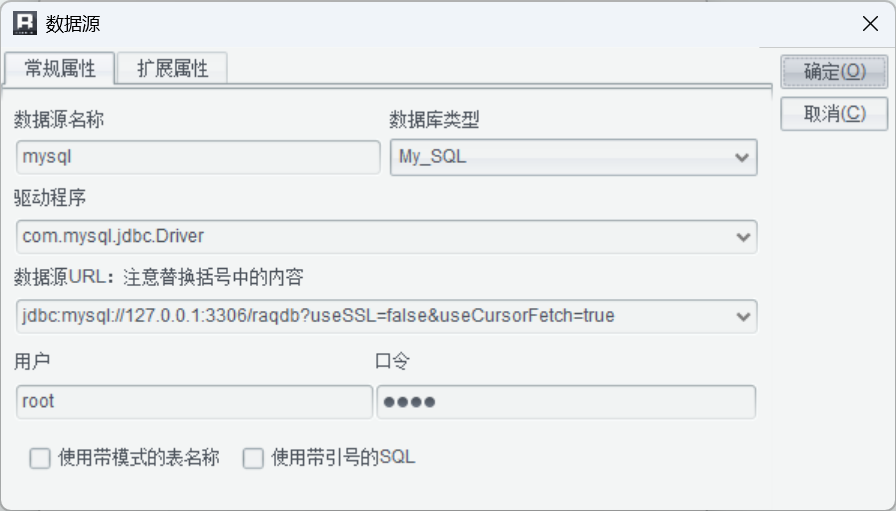
接下來設計報表展現模板。報表模板開發時需要先在潤乾報表中需要配置 MySQL 數據連接:
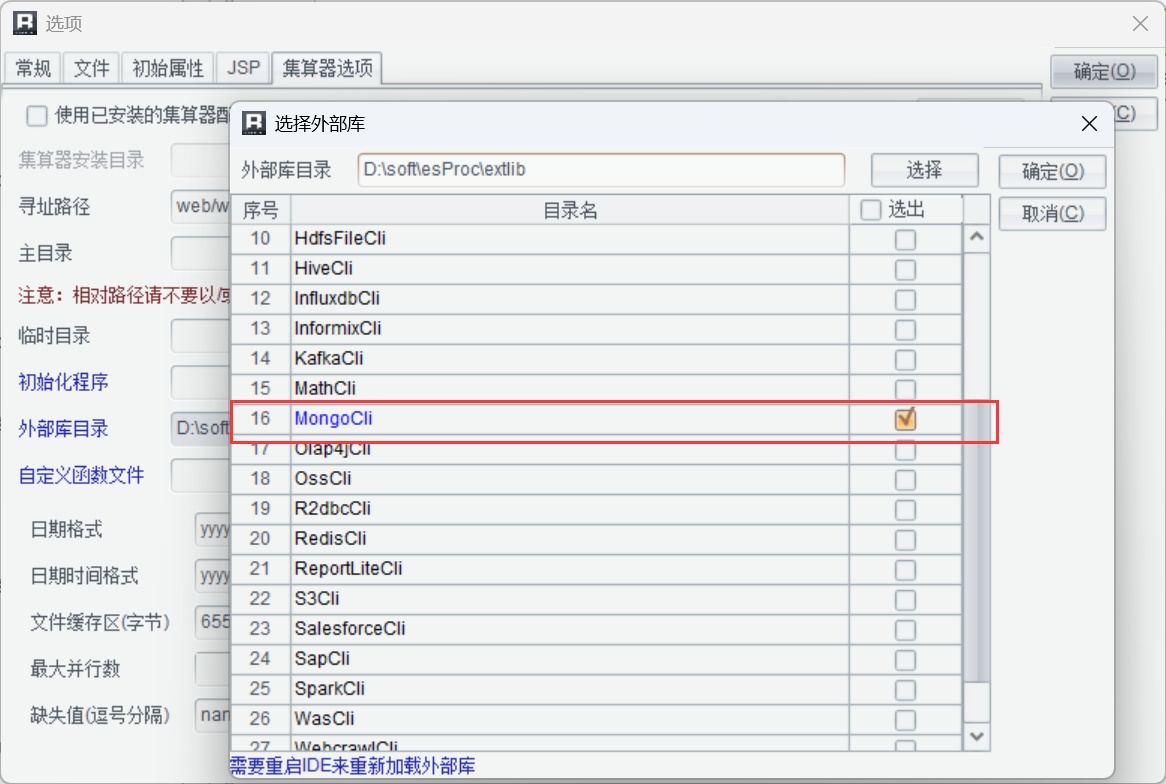
MongoDB 要先引入外部庫,在選項中選擇外部庫目錄:
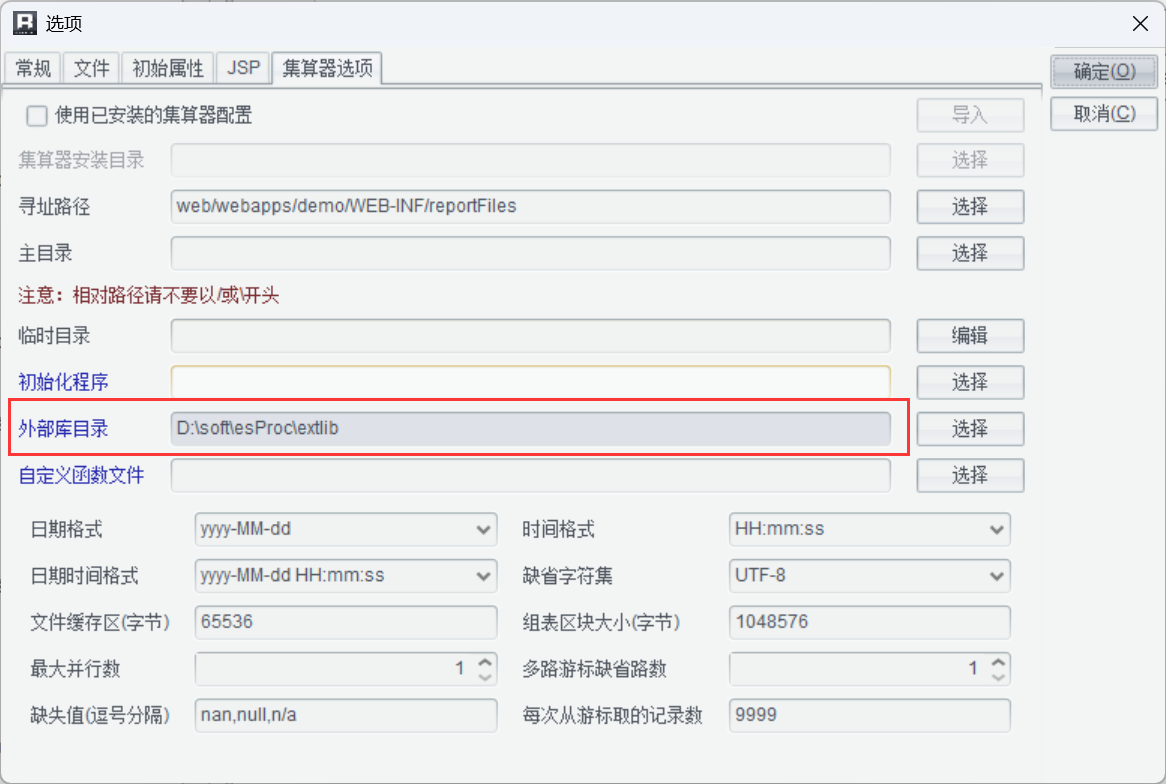
所有外部庫接口到這下載: 集算器 (SPL) 最新版發布啦『發布日期 20250605』
然后勾選 MongoDB 就可以了:
上面這些配置都是一次性的。
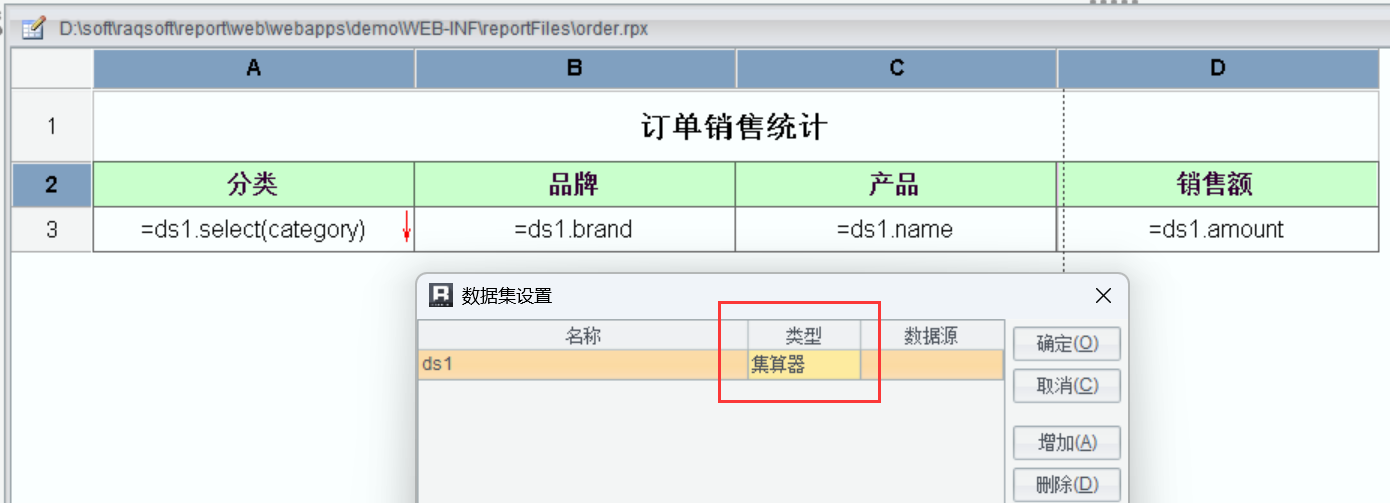
因為 SPL 已經內置到潤乾報表中,開發報表模板的時候選擇數據集為“集算器”,然后指定 SPL 腳本即可。
指定腳本并傳遞參數:
整個過程報表模板很簡單,主要還是 SPL 完成數據混算部分。數據源都是直連混算,不涉及數據搬遷,也不需要做邏輯映射,任何數據源只要連上就能混算。比如 Kafka 和 MongoDB 混算也是類似的:
| A | |
| 1 | =kafka_open("/mafia/my.properties","topic-order") |
| 2 | =kafka_poll(A1) |
| 3 | =json(A2.value) |
| 4 | =mongo_open("mongodb://127.0.0.1:27017/raqdb") |
| 5 | =mongo_shell@d(A4,"{'find':'products'}") |
| 6 | =A3.join(product_id,A5:product_id,product_id,name,brand,category,attributes) |
| 7 | return A6.select(category== arg_category) |
不僅是小數據,大數據也能輕松支持。前面 MySQL 和 MongoDB 混算如果數據量比較大可以這樣混算:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.cursor@x ("SELECT o.order_id, o.user_id, o.order_date, oi.product_id, oi.quantity, oi.price FROM orders o JOIN order_items oi ON o.order_id = oi.order_id WHERE o.order_date>=? and o.order_date<=? ORDER BY oi.product_id ASC ",begin,end) |
| 3 | =mongo_open("mongodb://127.0.0.1:27017/raqdb") |
| 4 | =mongo_shell@dc(A3,"{'find':'products','filter': {},'sort': {'product_id': 1}}") |
| 5 | =joinx(A2:o,product_id;A4:p,product_id) |
| 6 | =A5.groups(category,brand,name;sum(price*quantity):amount) |
| 7 | return ifn(A6,create(category,brand,name,amount)) |
A2 和 A4 的數據查詢都改成游標分批加載數據,然后進行游標關聯,最后進行分組匯總并返回結果。這里匯總后的結果集已經不大了,所以直接全部返回;如果結果集比較大,SPL 腳本可以直接返回游標,潤乾報表提供了大報表功能可以直接基于游標分批呈現數據(具體參考論壇資料),因此可以滿足任意數據源任意數據規模的報表查詢。
具備如此強大多源混算能力的潤乾報表只要極低成本就可以永久使用:一萬一套,三萬買斷。


:真實的生物神經學中神經元和人腦結構學習)
)
)
:路徑問題)


)
數據挖掘教程(1)--CLHLS簡介和數據下載)

)







