本周又在同一方向上刷到兩篇文章,可以說,……同學們確實卷啊,要不卷卷開放場域的推理呢?
這兩篇都在講:如何巧妙的利用帶有分支能力的token來提高推理性能或效率的。
第一篇叫 Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning 后面簡稱二八定律
第二篇叫 R2R: Efficiently Navigating Divergent Reasoning Paths with Small-Large Model Token Routing,后面簡稱R2R
一句話總結兩篇文章
兩篇文章都發現了
在推理任務上,一個完整的COT中只有少量的token帶有【指引推理路徑向左或者向右的能力】——我這里簡化稱為導航功能,其他大部分token的確定性都比較高。
比如二八定律文中的這張圖
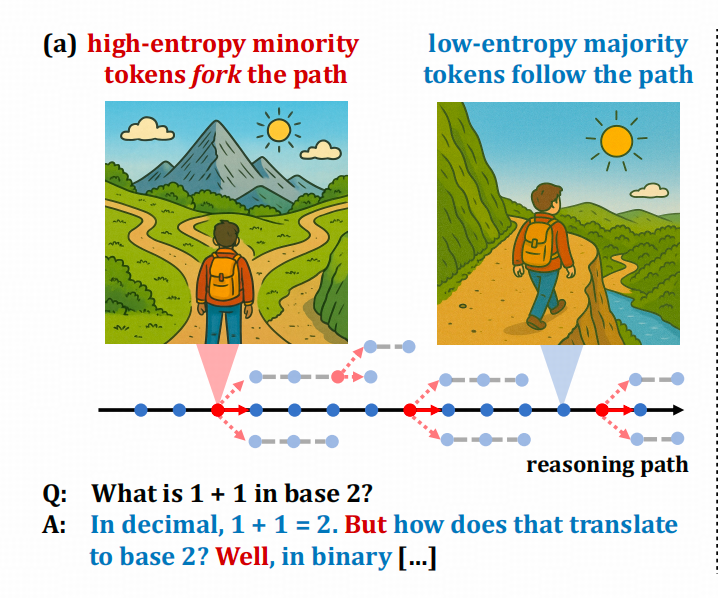
圖中的紅點和紅色詞,就是具備導航功能的token。
那怎么利用這個特性呢?
二八定律選擇訓練的時候專攻這些有導航功能的token,以提升LLM的推理能力;
R2R用這個性質來加速解碼→有導航功能的token用大模型來解,其他token用小模型(1.5B)來解。
兩篇文章的關鍵不同
觀測角度不同
二八定律是從熵的角度來觀測和判別導航token的,token分布中熵top前20的就是導航token;
R2R是通過比較大模型(LLM)和小模型(SLM)在回答同一問題時,從哪個token開始出現差異,再讓LLM驗證從這個token開始生成的路徑是否有本質區別(如思路和答案的正確性)。如果從這個token開始,后續結果確實顯著不同,那么這個站在命運的十字路口的token就是導航token。
優化方向不同
二八定律從改進RLVR的訓練目標出發,希望直接產出一個更強的模型。
R2R 從改進投機解碼的角度出發,希望對同一個模型更快的產出結果。
由于這兩篇文章除了【都是研究怎么利用高熵token】以外,實現細節上基本沒有什么交集,下面還是分開介紹
關鍵細節
二八定律的思路
發現現象→驗證現象→對癥提出優化方案→Ablation驗證優化點
發現的現象與分析
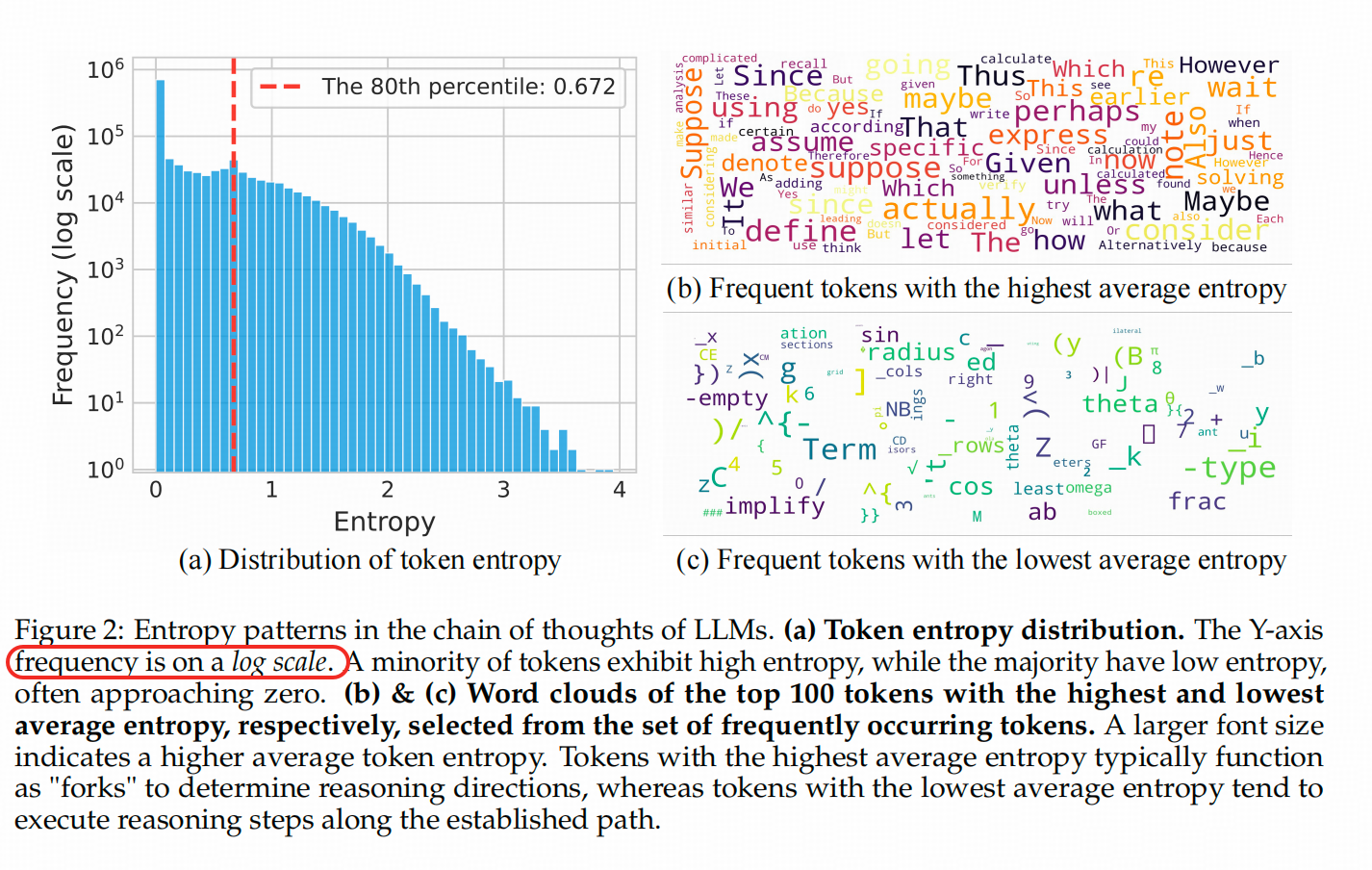
觀察上圖左側,這是Qwen3-8B在回答AIME’24和AIME’25問題時,COT中token對應熵的直方圖。注意,這個直方圖的縱軸是對數縮放的,也就是說,在原始Y軸上,紅線左側的柱子非常高。這個圖的目的是為了說明為什么選擇2-8分而不是3-7分等其他分法。因為過了紅線后,右側的柱子開始逐漸變短;而紅線左側(80%的token)的分布類似于一個平臺。雖然2-8分仍然是一種基于分析的直覺選擇,但是咋說呢,作者嘗試給你園了一下😁。
倒回來說一下這個熵具體是什么,是生成位last hidden 映射回詞表維度,并softmax以后得到的偽概率作為 p ∈ R 1 ? V \mathbf{p} \in R^{1*V} p∈R1?V(即一個詞表長度的向量) 算出來的熵 ? ∑ p i log ? ( p i ) -\sum{p_i\log(p_i)} ?∑pi?log(pi?)
上圖右側展示了熵較高的token對應的詞,這和我們的認知相似,一方面屬于認知行為中比較關鍵 驗證、定義、歸因等等,一方面在語言表述中,這些詞的出現確實會給后面的子句定個調子。
另外,這個紅線位置的熵是0.672,后面有用。
驗證現象
熵的分布上有這樣的特點,那又能帶來什么呢?擾動一下,看看結果?
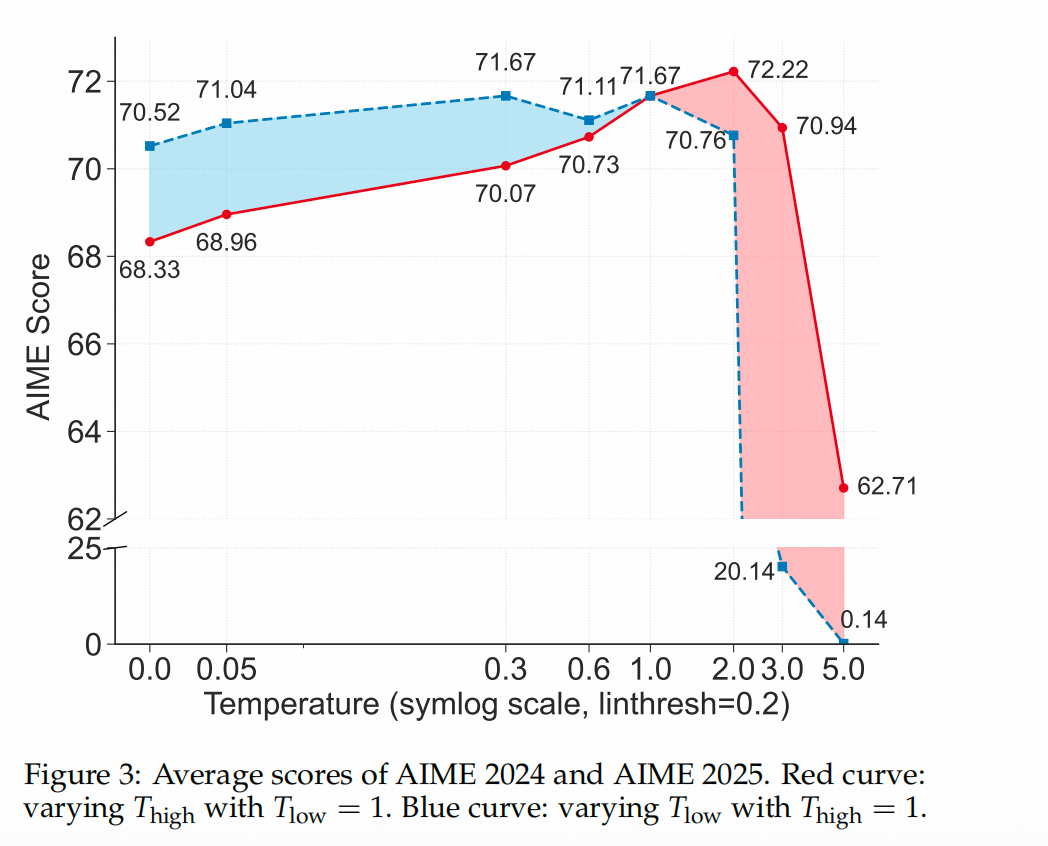
↑上圖中,二八定律作者還是用AIME的24和25 數據集作為實驗場,擾動了COT的生成過程:他用0.672作為經驗閾值,對熵高于這個值的token(導航token)
給予更高的采樣溫度,增加不確定性;對熵低于閾值的token則不作處理,形成紅線。藍線則相反,對熵低于0.672的token賦予更高的溫度。圖中紅藍兩條線的交點代表了基線,即沒有調整采樣溫度的情況。
結果顯示,提高導航token的溫度能讓模型達到更高的精度(但溫度超過2后效果變差),而對非導航token的情況則相反,溫度小于1時模型推理效果更好。
既然這種策略在生產時能優化模型,那么在訓練階段能否利用這種性質讓模型變得更強呢?
※碎碎念:其實我相信作者在這個階段應該是試過放大溫度以外的方法的,要是成了后面可能不會往訓練推。
提出優化方案
文章的這個部分,思路有些斷檔,因為作者選擇的是優化DAPO算法,所以他先分析了DAPO給模型的熵帶來的影響。這里先回放一下DAPO的優化目標公式。

公式里面 A A A是advantage,跟GRPO一樣,是共享的, r r r跟PPO一樣,新舊模型的比值。
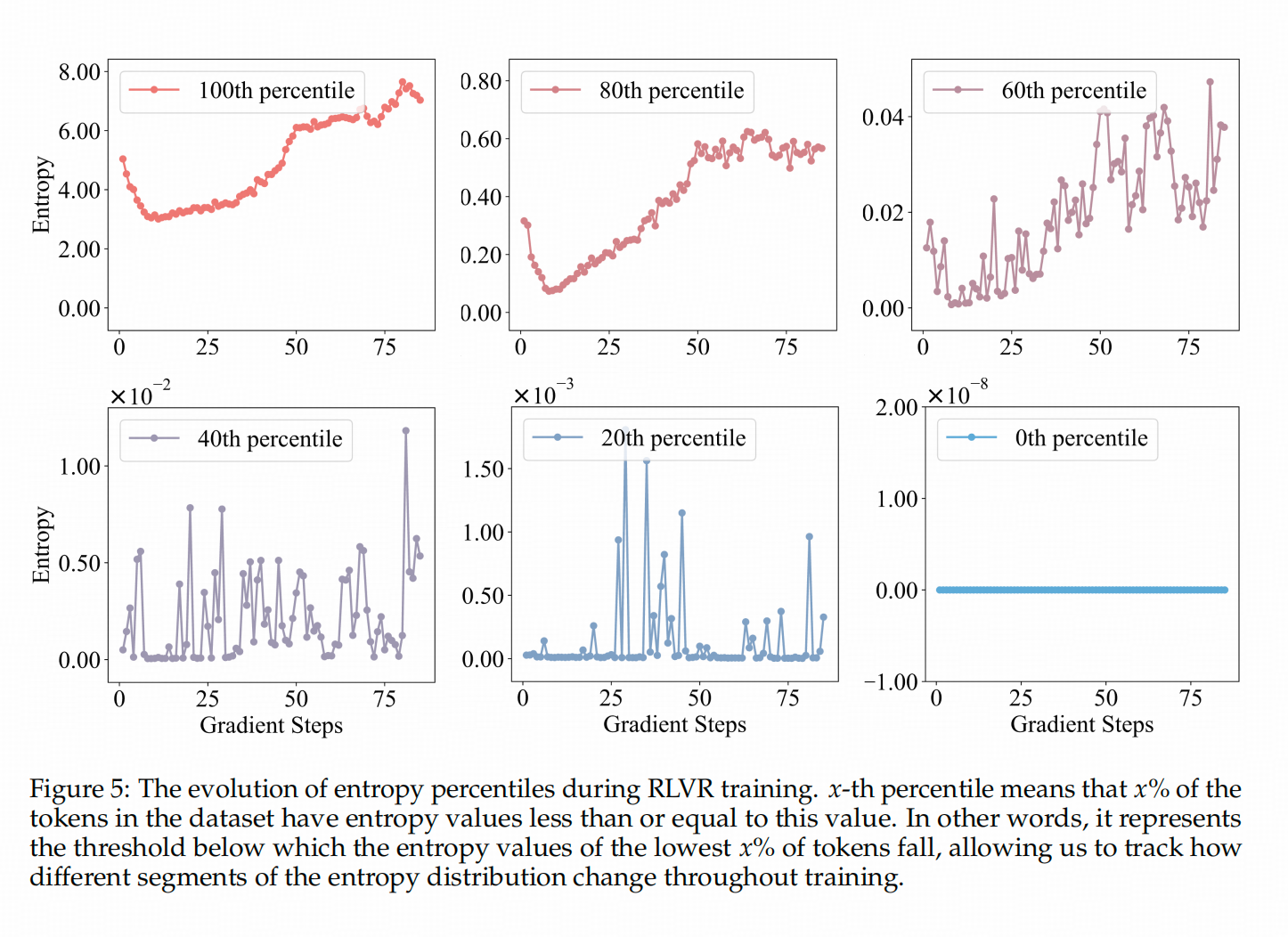
在RL訓練前,作者將原模型的token按熵的大小分成0%(熵最小的組)、20%、40%、60%、80%和100%(熵最大的組)這幾組,觀察訓練過程中,
這些token的熵變化趨勢。←上圖展示了這個變化過程,可以看到,上面一行(熵大小前60%的token)在訓練中熵還在增加,而下面一行(熵較高的token)基本沒有變化。也就是說,DAPO在訓練過程中對熵的影響,確實是「旱的旱死,澇的澇死」。既然如此,猛踩油門(在高熵token上加點)還管用嗎?↓
單獨優化熵高的token能夠繼續拉高模型的推理能力
這就是作者給出的RL的優化目標。公式中標紅的部分就是二八定律文給出的優化。
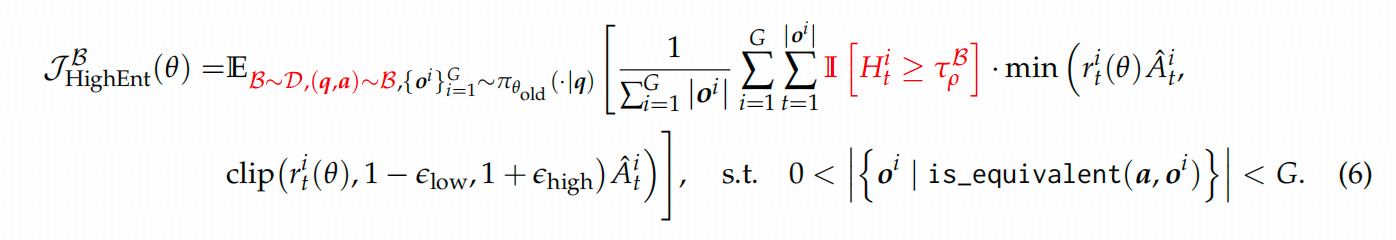
這個優化包含兩個點:
- 只優化
導航token:訓練中不適用經驗閾值來確定導航token,而是由訓練中的token的熵分布的前20%percentile決定的。 - 改用一個batch訓練:這里必須使用batch,因為計算熵分布時需要足夠的數據來確保其可信度。畢竟,如果只對一個QA對的16個樣本中的所有token計算分布,結果會有偏差。訓練中使用的batch_size為512。
效果如何
跟基線比,漲點了;跟原版DAPO比,也漲點了。
作者訓練了Qwen3的三個模型:8B-base、14B-base和32B-base,并在AIME24數據集上進行對比。8B模型在Qwen的tech report中的指標為29.1%,經過DAPO處理后為33.33%,使用作者的改良版DAPO后提升至34.58%。32B模型在Qwen的tech report中的指標為81.4%,經過DAPO處理后為55.83%,使用改良版DAPO后提升至63.54%。盡管這種訓練方法提高了32B-base的推理能力,但仍不及開源的32B模型。
當然,這是一篇純方法論的論文,比較一個把好數據和好方法都堆上的模型也是有點欺負人。
跟DAPO比,scaler能力更強
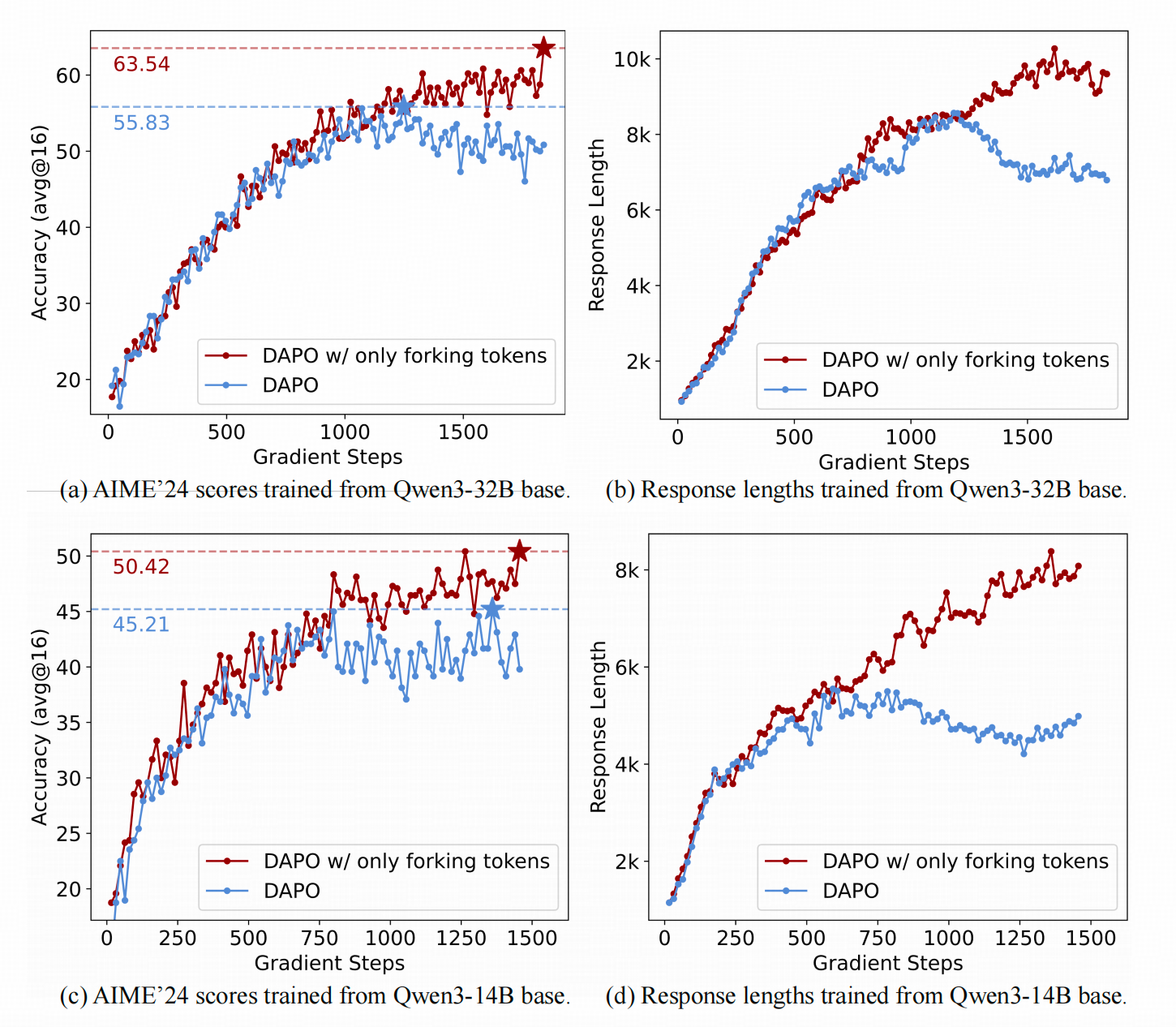
上面兩張圖展示了用DAPO和改良版DAPO訓練Qwen3-32B(上行)和Qwen3-14B(下行)在訓練過程中的模型準確率和生成長度的變化。
可以看到,作者的改良版DAPO相比原版具有更高的上限,并且生成長度在訓練中后期還在增加(這實際上是好事,因為它給test-time scaling留下了更多空間,但作者沒有在后續實驗中討論這一點)。
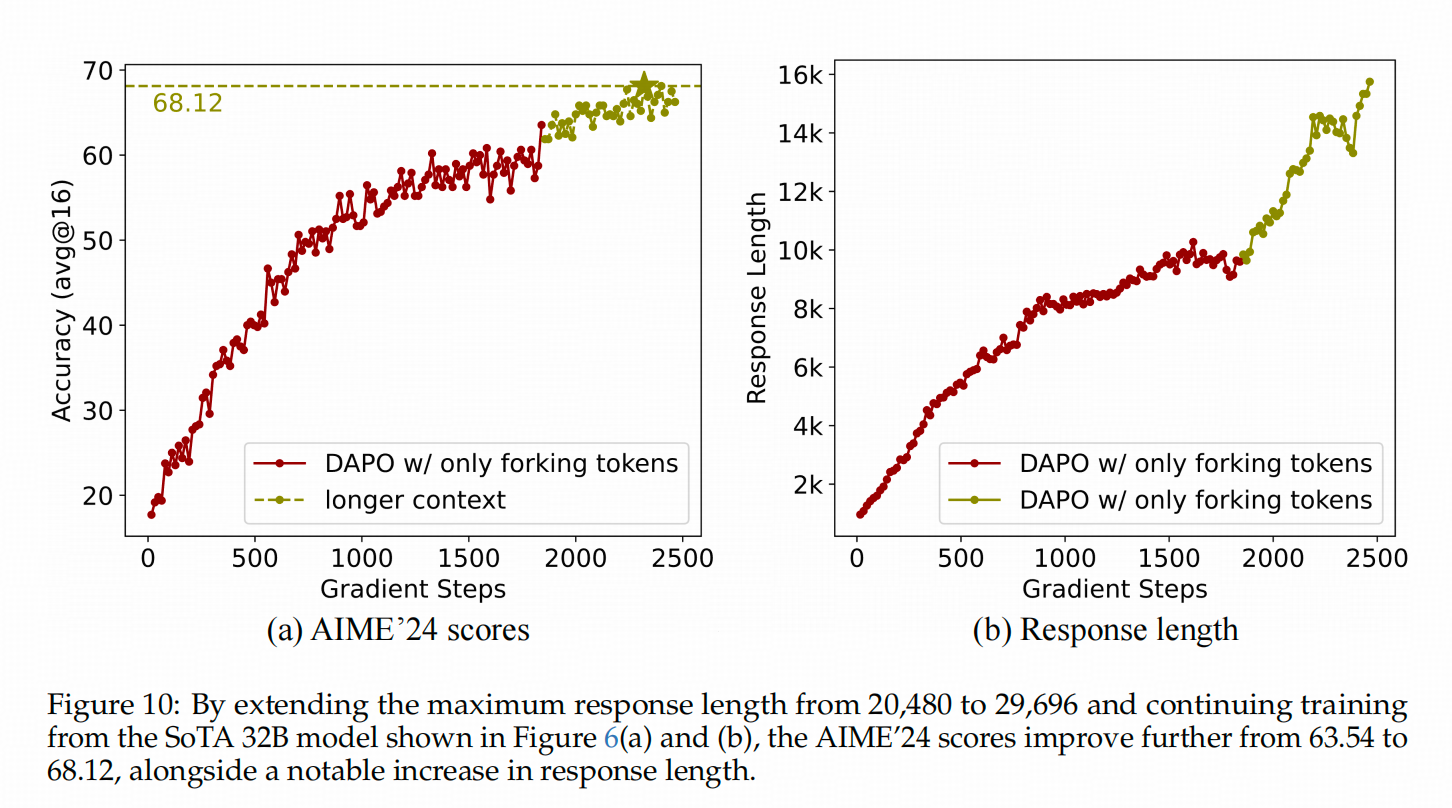
隨后,作者將推理長度限制從20K延長到29K,繼續訓練后,32B模型的性能確實有所提升。下圖黃色部分展示了在擴展長度后的模型準確率和生成長度的變化。
R2R 的方法
R2R的思路是,“我有一個假想,我按照這個假想試試”
他的假想是
※1-大模型能力強,小模型能力弱,這兩個模型的能力的差異體現到token級別的時候,就是看到同樣的問題生成token的不一樣。↓
※2-這些不一樣的token中,可能有一些是無關緊要的(一個意思的不同表示方法,這個在Softthinking哪篇文章展示的案例中恰恰有體現),有一些token可能決定后面的發展,即我們通篇在提的導航token。這種導航token無疑在解碼的時候是不能錯的。↓
※3-那解碼的時候,怎么保證不用小模型來解導航token呢?得先識別出來。
要識別導航token,離線時固然可以用樣本分析然后歸因的方法,但生產時候這個套路就玩不轉了。最簡單的方法就是建個模型來識別哪個是導航token。↓
※4-在生產的時候,這個模型接受小模型的last_hidden等輸入,并判斷該token是否 就是導航token,是的話用大模型解碼,不是的話用小模型解碼。
作者畫了個圖來展示他整體的思路。下圖中SLM就是1.5Bd大模型,LLM是32B的大模型

導航token的分析
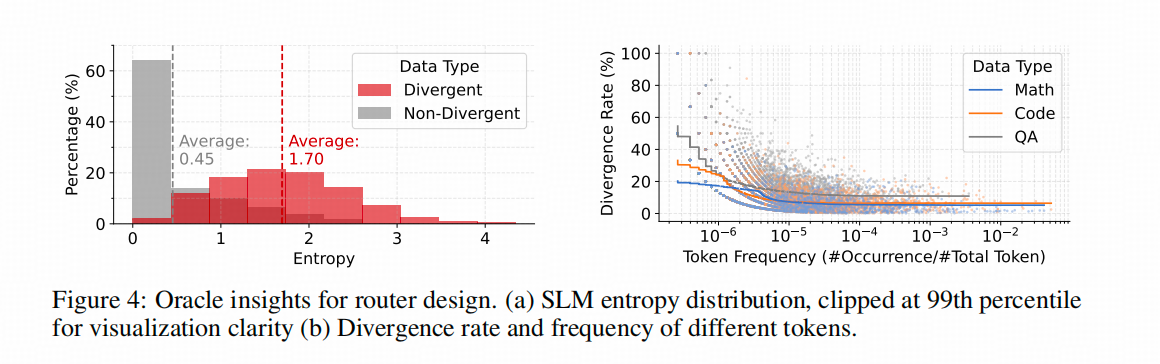
R2R的作者同樣分析了token的熵,不過他分析的是小模型的熵分布。他沒有使用top-p,不知道是不是因為小模型token熵的top-p沒有大模型的對應數值有決定性價值。總之,他先標記了哪些token是大小模型在相同query下不同,且會引發后續推理鏈路大大不同(用大模型評測)。在上圖左側直方圖中,這些token用紅色表示,其他token的分布是灰色。
上圖右側圖的展示邏輯有些復雜,但結論是,訓練語料中出現頻率越高的token,其成為導航token的概率越低。
效果如何
確實快,下表中各個數據集的第一列是accuracy,第二列和第三列的邏輯差不多,第二列顯示實際計算的平均參數量(包括SLM、導航token識別模型和LLM),第三列顯示平均參數量乘以平均長度,所以第三列可以先不看。(因為這個方法對實際生成長度影響不大,可以參考原文表3,我就不展示了)。
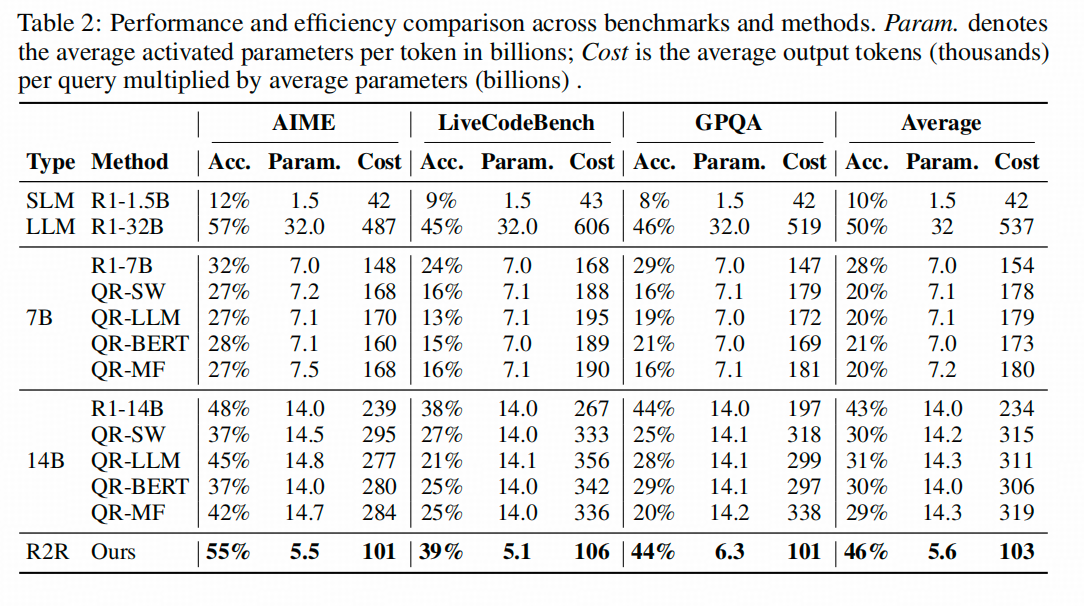
上圖顯示的結論是,R2R比純用32B模型推理的準確率低一點點,但比32B模型實際算的參數量小很多很多(我不太理解為啥不用Flop衡量?我本身對decode了解有限,不瞎嘴了)
兩篇文章的整體評價
兩篇文章的實驗分析部分都有遺憾
二八定律的實驗分析中,缺少了test-time scale方面的比較,也沒有進一步展示導航token的變化趨勢—— 比如哪些token會推出top20呢?
R2R 文則一來沒有對導航token進行展示和定性的分析(這些對后續研究是有啟發性的,但作者沒有展示),二來,其比較實驗中的比較組也有點奇怪,雖然比較了很多解碼方案,但是是在14B的模型下比較的?雖然比了投機解碼方法,但是在附錄里比的,主要是效率。
二八定律是否能在推理以外的場景中推廣,需要更多的驗證。
在實驗分析部分,二八定律文展示了在數學任務上訓練的模型在代碼數據集上是否也有優勢——答案是肯定的。然而,目前推理任務的研究主要集中在數學和代碼任務上,也該考慮move-on了。畢竟到了不能直接驗證是否正確的場域,RLVR也要改改。
- 本地部署(后端 1.2版本))

![[技術積累]成熟的前端和后端開發框架](http://pic.xiahunao.cn/[技術積累]成熟的前端和后端開發框架)




:對話風格微調項目(上):數據工程與模型選型)



![[論文閱讀] 系統架構 | 零售 IT 中的微服務與實時處理:開源工具鏈與部署策略綜述](http://pic.xiahunao.cn/[論文閱讀] 系統架構 | 零售 IT 中的微服務與實時處理:開源工具鏈與部署策略綜述)
)




)

