全棧監控系統架構
可觀測性從數據層面可分為三類:
- 指標度量(Metrics):記錄系統的總體運行狀態。
- 事件日志(Logs):記錄系統運行期間發生的離散事件。
- 鏈路追蹤(Tracing):記錄一個請求接入到結束的處理過程,主要用于排查故障。
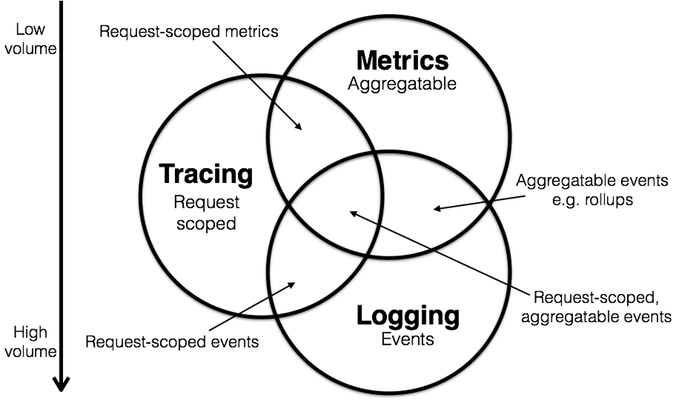
圖片來自:Metrics, Tracing, and Logging
CNCF 的 Observability Whitepaper(可觀測性白皮書) 將上述數據統稱為 Signal(信號),除了以上三種,又提出來額外兩種信號:
- 性能剖析(Profiling):記錄代碼級別的的詳細視圖,比如 CPU、內存的使用,幫助診斷環境中的性能瓶頸。
- 核心轉儲(Core Dumps):程序崩潰時的內存快照。
從系統架構層面可分為三層:
-
基礎層:對底層主機資源的監控。比如 CPU、內存、磁盤用量、磁盤IO、網絡IO 、系統日志等。
-
中間層:對中間件的監控。比如 MySQL、Redis、ElasticSearch、Nginx 等中間件的關鍵指標。
-
應用層 :監控應用的指標。比如 JVM 指標、JDBC 指標、HTTP 的吞吐、響應時間和返回碼分布等。當然也包括客戶端的監控,比如移動客戶端的性能監控。
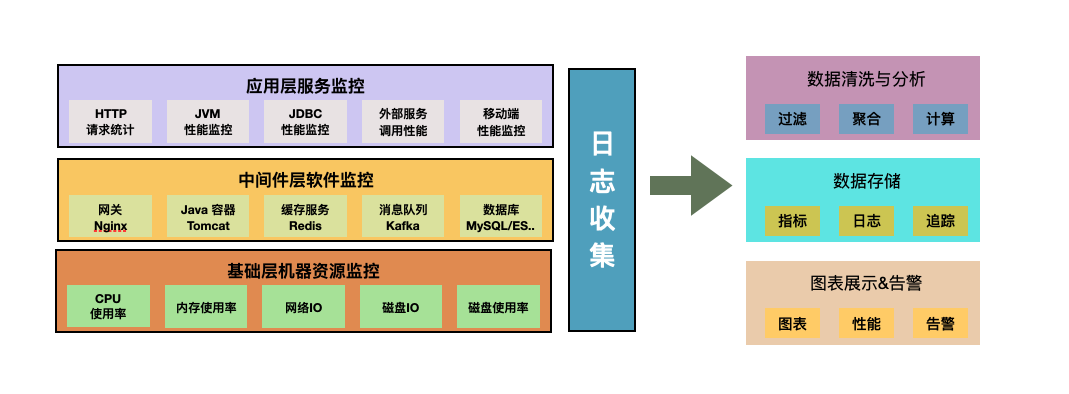
我們知道分布式系統的架構和運維極其復雜,只有實現一個全棧監控系統,將上述各層的指標、日志、追蹤數據收集并關聯保存好,讓它成為分布式系統的眼睛,我們才能更好的了解系統運行狀態,及時發現問題,進而解決問題。
一個分布式系統、一個自動化運維系統、或是一個Cloud Native的云化系統,最重要的事就是把監控系統做好,在把數據收集好的同時更重要的是把數據關聯好。開發和運維才可能很快地定位故障,進而根據故障原因做出相應的(自動化)處置,將故障恢復或把故障控制在影響范圍之內。 《左耳聽風》
監控系統功能要求
一個好的監控系統,主要為兩個場景服務:
-
體檢
-
容量管理。提供一個全局的系統運行時數據監控大盤,可以讓工程師團隊知道是否需要增加機器或是其它資源。
-
性能管理。可以通過查看大盤,找到系統瓶頸,并有針對性的優化系統和相應代碼。
-
-
急診
-
定位問題。可以快速的暴露并找到問題的發生點,幫助技術人員診斷問題。
-
性能分析。當出現不預期的流量提升,可以快速的找到系統的瓶頸,并可以幫助開發人員深入代碼。
-
具體需要有如下功能:
全棧監控
做到對基礎、中間件和應用層的指標、日志、鏈路追蹤的整體監控。
整體 SLA 分析
需要根據用戶的 API 訪問計算整體的 SLA。比如下面的一系列指標:
- 吞吐量:M1,M5,M15 的吞吐量,即最近 1、5、15 分鐘的 QPS。
- 響應時間:P99 、P95 、P90、P75、P50 等延時時長,
- 錯誤率:2XX、3XX、4XX、5XX 的各自占比;最近 1、5、15 分鐘的 400、500 錯誤請求數。
- Apdex(Application Performance Index) 指標
這是工業界用來衡量系統運行是否健康的指標。Apdex 有三種狀態來描述用戶的使用體驗:
- 滿意(Satisfied):請求服務響應時間小于某個閾值 T。
- 可容忍(Tolerating):請求服務響應時間高于 T,但低于一個可容忍值 F,通常 F = 4T。
- 失望(Frustrated):請求服務響應時間大于可容忍值 F。
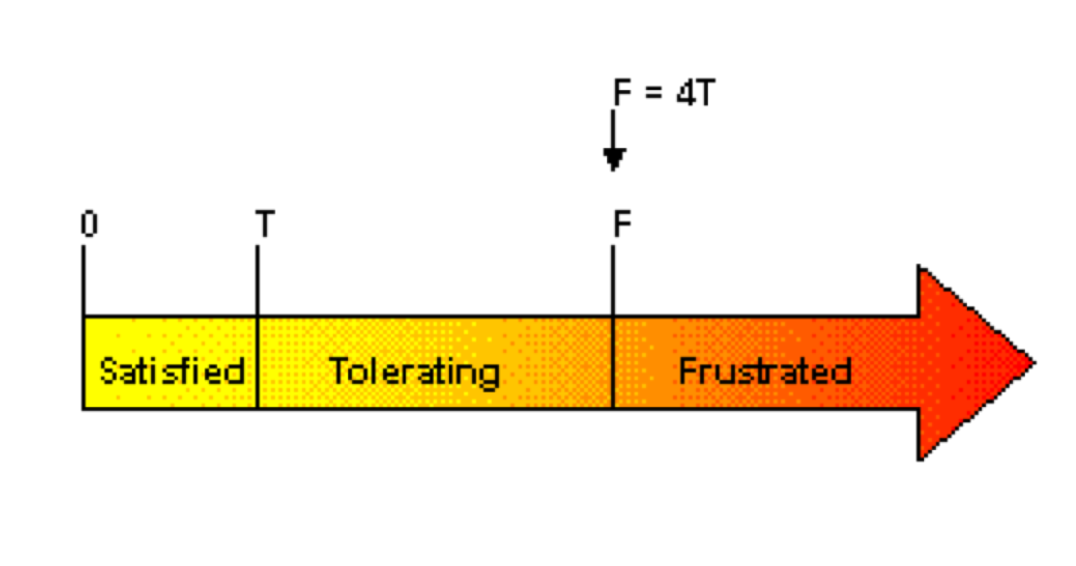
基于以上值,Apdex 的計算公式如下:
// 滿意的請求數加上可容忍的請求數的一半,除以總的請求數。
Apdex = (Satisfied count + Tolerating count / 2) / Total count
假設我們系統有 100 個請求,滿意響應時間為 200ms。這 100 個請求中:
- 80 個請求響應時間小于 200ms,即滿意的請求數為 80。
- 15 個請求響應時間在 200ms 到 800ms(4 * 200) 之間,即可容忍的請求數為 15。
- 5 個請求響應時間大于 800ms,即失望的請求數為 5。
那么 Apdex 的值為:
Apdex = (80 + 15 / 2) / 100 = 0.875
一般來說,Apdex 的值大于 0.9 時系統可以認為運行正常,用戶體驗良好;低于 0.8 時需要告警,并進行優化;在 0.5 以下時可以認為系統運行不正常,需要將服務實例下線。
關聯分析
監控系統需要對三層數據進行統一全面的關聯、分析,并能夠通過調用關系幫助我們定位故障的根因。
以一個報 500 的請求為例,我們能夠通過鏈路追蹤日志獲取該請求的整個請求鏈路,鏈路中的所有服務、中間件以及對應的服務器信息都能關聯查詢出來。查詢到鏈路中的每個 Span 時,對應的日志、指標都能關聯展示出來。
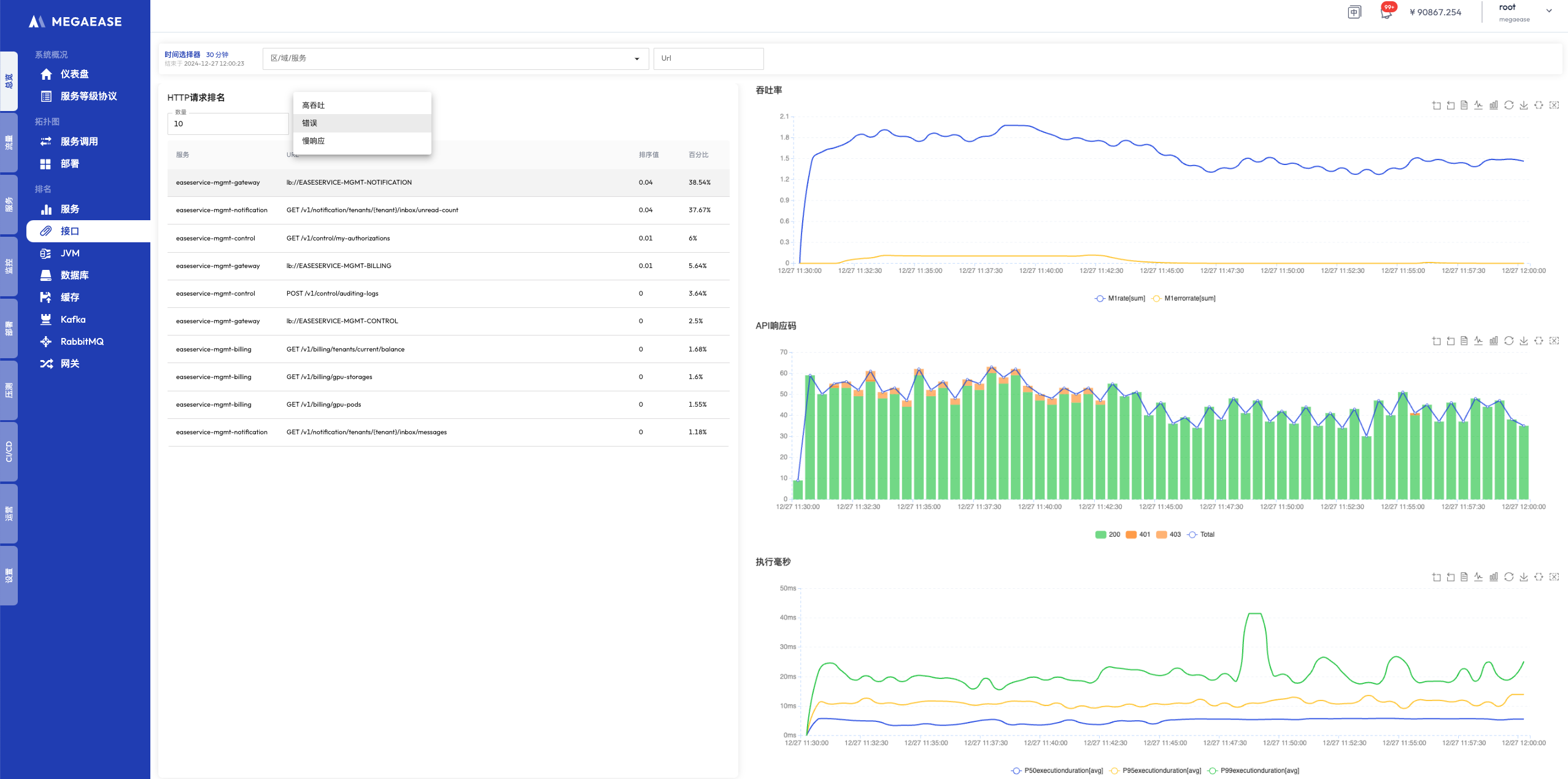
下圖是使用 MegaEase Cloud 云平臺監控的一個微服務系統的調用鏈追蹤展示以及點擊某個 Span 時所能關聯查詢的所有數據。整個調用鏈的拓撲圖、日志、請求、JDBC 等信息全部能關聯查詢出來。
- 調用鏈拓撲圖

- Span 信息

- Span 詳情,包括日志、指標、請求、JDBC 等
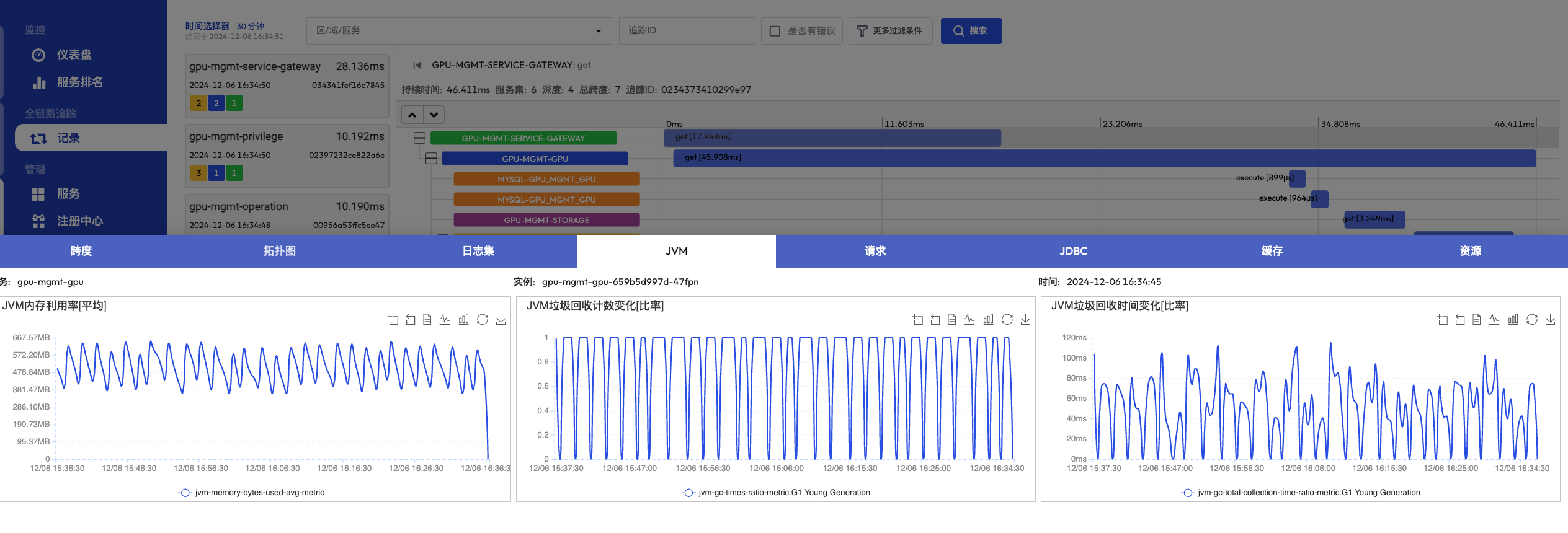
圖片來自 MegaEase 官網
實時告警與自動處理
通過設置告警規則,當系統異常時能夠及時的發出告警。在此基礎上要有一定的自動故障處理能力,比如自動擴縮容、彈力處理等。
對于常見的指標,比如服務器的 CPU、內存、磁盤的用量,JVM 的 Memory、GC 等最好有默認的告警規則模版,每當有新的機器、服務上線時,能夠自動生成告警規則。
系統容量與性能分析
通過對過去一段時段的監控數據分析,獲取系統的 SLA、負載、容量使用等情況,為系統的容量規劃提供參考依據。
監控系統技術架構
數據采集
數據采集通常會有一個客戶端,與被采集的目標實例運行在一起,采集目標實例的運行指標、日志、追蹤等信息,并將采集到的數據通過 API 進行暴露或者直接上報。
指標全局字段
為了后續的關聯分析,采集的數據需要標明來源等信息,通常需要以下全局字段:
| 字段 | 說明 |
|---|---|
| category | 指標分類,通常可以分為 infrastructure、platform、application 三類,即對應基礎設施層、中間件層、應用層 |
| host_name | 采集客戶端所在的主機名稱 |
| host_ipv4 | 采集客戶端所在的主機 IP |
| system | 被監控服務的系統名稱(一般是所屬的業務系統) |
| service | 被監控服務的服務名,最重要的一個字段,大盤需要根據該字段確定要查詢的目標數據以及關聯分析 |
| instance | 被監控服務的實例名稱,一個服務通常會有多個實例,該字段用來標識具體的實例信息, 方便關聯分析和故障定位 |
| type | 指標類型分類,更加細化的指標分類,比如 mysql、jvm、cpu、memory 等,可以基于該 type 將數據存儲在不同的索引庫中 |
| timestamp | 指標和日志產生的時間戳 |
通過這些字段,我們能精確定位某個系統下的任意服務實例位于哪臺機器上,從而去目標主機查看實例的狀態;也可以在監控系統中通過這些字段關聯查詢到具體實例的日志、指標、追蹤等信息。
基礎層與中間件層采集
Linux 系統內核以及幾乎所有的的中間件都有運行時的統計信息。比如 Linux 的 /proc 目錄,MySQL 的 performance schema 等。
對于基礎層和中間件層,有非常多的優秀成熟開源的監控組件可以使用:
-
Telegraf:一款開源的基于 Go 語言開發的指標采集軟件,有眾多的采集、處理和輸出插件,基本能覆蓋日常開發的指標采集需求。
-
Elastic Beats:ElasticSearch 公司開發的一系列采集客戶端。比如用于采集日志的
Filebeat;用于采集指標的Metricbect;用于采集網絡的:Packetbeat。 -
Prometheus Exporter:圍繞 Prometheus 開發的一系列 Exporter,會暴露指標采集 API,供 Prometheus 定時拉取。
-
OpenTelemetry:由 CNCF 的 OpenTracing 和 Google/微軟支持的 OpenCensus 合并而來,最初是為了實現鏈路追蹤的標準化,后來逐漸演化為一套完整的可觀測性解決方案。自 2019 年發布以來,逐漸成為了云原生領域可觀測性數據收集的事實標準。

應用層指標采集
應用層的指標采集要相對更麻煩一些,因為不同的語言實現通常需要不同的方式采集。但總體來看有三種如下方式:
-
應用 API 暴露:比如 SpringBoot 應用就通過
/_actuatorAPI 對外暴露了一系列應用相關信息。我們也可以自行編寫相應的 API 對外暴露指標。這里需要注意指標標記的合理性,避免表示不準確和數據量爆炸,對服務本身和監控系統造成影響。一般來說除了指標名、時間戳和指標值外,其他 lable 都是固定的,這樣 Prometheus 等時序數據庫在存儲時會進行壓縮,節省存儲空間。可以參考這篇文章 程序的 Metrics 優化——Prometheus 文檔缺失的一章。 -
SDK 采集上報:將采集上報功能以 SDK 的形式集成到服務中。好處是靈活性高,可以自行編寫 SDK,最大程度滿足自身的需求,但壞處是會對業務服務造成侵入。主流語言通常會有很多優秀開源庫,即使是自己造輪子通常也是在其基礎之上做進一步的封裝。以筆者比較熟悉的 Java 生態為例,一些優秀的開源工具庫:
- OSHI: Operating System and Hardware Information 用來收集操作系統和硬件信息的 Java 開源庫。
- Dropwizard Metrics 用來測量 Java 應用的相關指標的開源庫。
- opentelemetry-java:opentelemetry 提供的 Java SDK。
-
無侵入式采集:SDK 的方式一般需要應用添加依賴,修改配置等操作,通常會影響到線上的服務運行。更好的方式是使用無侵入技術,將采集功能無縫集成到應用中。一些常見的技術有:
-
Java Agent: Java 提供了字節碼編程,可以動態的修改服務配置。MegaEase 就使用了該技術實現了 EaseAgent 無侵入式觀測系統
-
ServiceMesh SideCar: 在 Service Mesh 架構下,可以將服務發現、流量調度、指標日志和分布式追蹤收集等非業務性功能放到 SideCar 中,從而避免對應用造成影響。
在 MegaEase,我們結合 JavaAgent 和 SideCar 實現了 EaseMesh 服務網格, 可以在不改變一行源代碼的情況下將 Spring Cloud 應用遷移到服務網格架構,整個架構已經被賦予了全功能的服務治理、彈性設計和完整的可觀察性,而用戶不需要修改一行代碼。具體參考 與 Spring Cloud 完全兼容的服務網格可以干什么樣的事。
-
采集端注意事項
-
監控系統屬于控制面的功能,和業務邏輯沒有直接關系。因此業務系統不應該感知到監控系統的存在,更重要的,監控系統的資源占用要盡可能小,不應該影響到業務系統的正常運行。
-
盡可能對應用開發透明,比如優先使用上述提到的無侵入的方式采集應用的監控數據。
-
如果做不到無侵入,比如要使用 SDK 的方式,也要做到技術收口,采用切面編程的范式來實現,避免對業務邏輯造成影響。
-
采集數據的傳輸應該采用標準的協議,比如 HTTP 協議。
-
采集數據的格式應該采用標準的格式,比如 JSON、ProtoBuf 等,尤其是數據量過大時,盡量使用高效率的二進制協議。
-
如果條件允許,應該使用物理上的專用網絡來隔離業務網絡,避免對業務服務的訪問造成影響。
數據傳輸與清洗
當數據收集上來后,我們需要對數據進行清洗梳理,從而實現
- 日志數據的結構化
- 監控數據的標準化
這里需要兩個組件的支持:
-
數據總線:通過數據總線來對接所有的收集組件,成為數據集散地;另外也作為數據緩存和擴展的中間 Broker。Kafka 可以很好的擔任這樣一個角色。
-
數據 ETL:ETL 工具用來對數據進行清洗,將客戶端采集發送到數據總線的數據解析處理,最終生成結構化的數據寫入到存儲組件中。常用的開源組件有 LogStash,Fluentd 等,當然也可以自研,選擇更合適的高性能語言并滿足內部更加復雜的清洗需求。
數據清洗注意事項
-
清洗組件要做到高性能、高可用。一般來說,指標數據是周期性產生的,其數據量并不會跟隨當前請求并發量的多少變化而變化。另外一些數據(比如日志)則是和系統接受的請求并發量有著直接的關系。因此數據處理管線需要能夠支撐高并發、大數據量的寫入,同時也起到削峰填谷的作用。Kafka 可以非常完美的符合這些要求。
-
清洗邏輯要盡量的簡單,不應該在清洗組件做過多復雜的設計。
-
清洗組件必須是無狀態的,能夠支持水平擴展。
-
盡量提升數據處理的效率,比如使用 Golang 開發清洗組件;對 JVM 的語言做優化,如使用無鎖隊列、固定大小的 buffer 等提升效率。
數據存儲
在存儲方面,以 ElasticSearch 為代表的全文搜索引擎和以 Prometheus 為代表的時序數據庫已經成為事實上的標準。一般來說可以將以日志為主的、需要全文檢索的數據寫入到 ES;將告警相關的數據寫入到 Prometheus 中。
存儲注意事項
-
根據需要對數據按天、小時或分鐘等級別建立索引,避免單個索引數據量過大。
-
全局字段指標通常需要單獨建立索引,以方便后續的關聯分析。
-
盡量提升磁盤的 IO 性能,比如使用 SSD,使用文件系統 cache 機制。避免使用 NFS 等遠程文件系統。
-
監控數據的特點一般是:數據量大,有效期短。因此可以考慮數據冷熱分離。熱數據存入 ES 和 Prometheus 中做檢索和告警;冷數據以時間區間命名做歸檔存入其他的分布式文件系統做備份。
-
按照業務級別,需要對日志必須分級,高級別日志需要滿足異地容災、冗余。
-
根據業務敏感度,要考慮到數據的脫敏和歸檔安全
數據展示
以圖表的形式展示相關的度量指標,方便我們查看系統的當前狀態。可以使用 Grafana 實現該功能,作為一款非常流行的 dashboard 組件,已經有了眾多現成的圖表模版,對于大多數系統和中間件可以直接使用。當然對于應用層的監控,可能需要自行設計開發進行展示了。
總體而言,需要有以下功能的展示:
-
總體系統健康和容量情況,包括
- 關鍵服務的健康狀態
- 系統的 SLA 指標,包括吞吐量、響應時間(P99、P95、P90、P75、P50)、錯誤率(2XX、3XX、4XX、5XX)。
- 各種中間件的關鍵指標,比如 MySQL 的連接數、Redis 的內存碎片等。
- 服務器基礎資源的健康狀態,比如 CPU、內存、磁盤、網絡等。
-
TopN 視圖:包括最慢請求、最熱請求、錯誤最多請求等
數據告警
當系統容量、性能達到瓶頸,或者某個組件出現問題,需要告警組件及時的通知相關人員介入處理。對于告警,需要定義告警規則,一般需要處理如下一些情況:
-
基礎探活:采用心跳機制,定期檢查某個服務的連通性,讓心跳檢查失敗時,觸發告警。MegaEase 開源了 EaseProbe 可以作為眾多服務的探活工具。
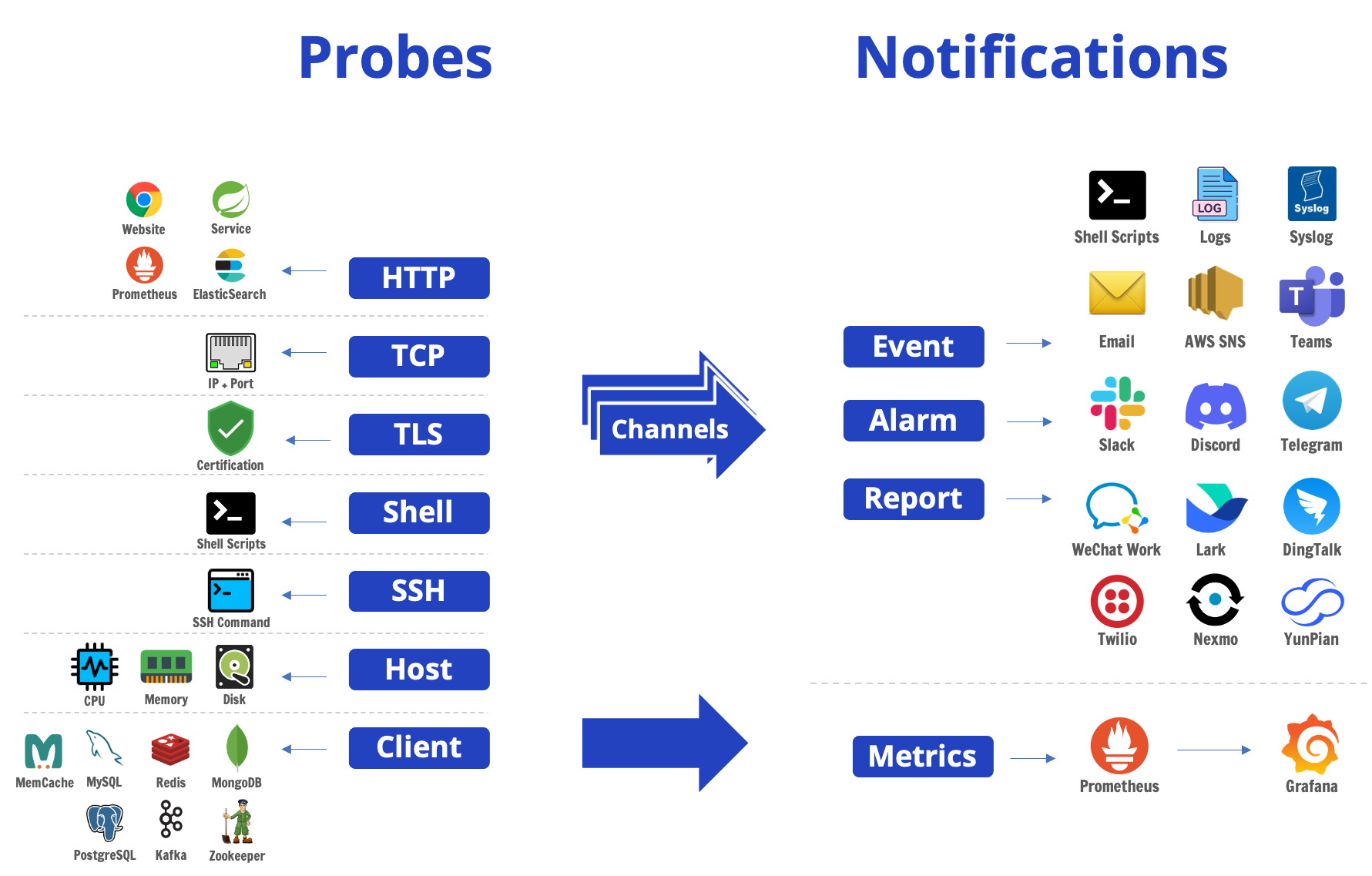 ,
, -
指標 - 持續時間 - 閾值: 當某個指標再一段時間內持續超過某個閾值時,觸發告警。比如 兩分鐘內 CPU 使用率持續超過 90%。
-
指標 - 持續時間 - 百分比 - 閾值: 當某個指標再一段時間內持續超過某個百分比時,觸發告警。比如兩分鐘內 P99 超過 300ms。
-
指標 - 持續時間 - 函數 - 閾值: 此時需要一些聚合計算,某些函數的計算在一段時間內超過閾值。比如兩分鐘內的 JVM GC 次數(sum 函數計算)超過閾值。
-
指標 - 持續時間 - 關鍵詞 - 匹配次數: 日志中的某個關鍵詞在一段時間內出現的次數超過閾值,關鍵詞需要支持精確匹配和正則匹配。
設置告警規則時,首先需要梳理關鍵業務路徑和非關鍵業務路徑,并以此制定故障分級原則。對于關鍵業務異常要有事件告警,其次需要對如下關鍵指標設置告警:
- 各業務接口的失敗率指標
- P99/P90/P50 指標
- 主機/服務實例的 CPU、內存、JVM 等基礎資源指標
- 主機/服務實例的飽和度指標(磁盤容量、網絡IO、磁盤IO)
- 各中間件關鍵指標
上述提到的組件都提供了告警工具,通常可以滿足需求。比如:
- Prometheus Alert Manager
- Elastic Alerting
- Grafana Alerting
當然也可以自研,梳理出關鍵指標后形成告警規則模版,每當有新服務引入時自動創建告警規則,然后定時監測指標信息,及時告警
至此,如果全部采用開源組件實現一個全棧監控系統,技術棧如下:
- 數據采集端
- 基礎層和中間件指標采集 - Telegraf
- 日志采集 - Filebeat 和 Fluentd
- Java Agent - EaseAgent
- OpenTelemetry - OpenTelemetry
- 數據處理管線
- 數據總線 - Apache Kafka
- 數據 ETL - Logstash,Fluentd
- 數據存儲
- 日志數據存儲 - ElasticSearch
- 指標數據存儲 - Prometheus,InfluxDB
- 數據圖表
- 數據展示:Grafana
- 異常告警:Prometheus Alert Manager,Elastic Alerting,Grafana Alerting
最終形成如下架構

圖片來自MegaEase 官網







:重塑數據安全攻防邊界)
![[python] 使用python設計濾波器](http://pic.xiahunao.cn/[python] 使用python設計濾波器)

)

 服務器: 工作原理)





)
