領域LLM九講——第4講 構建可測評、可優化的端到端商業AI Agent 系統
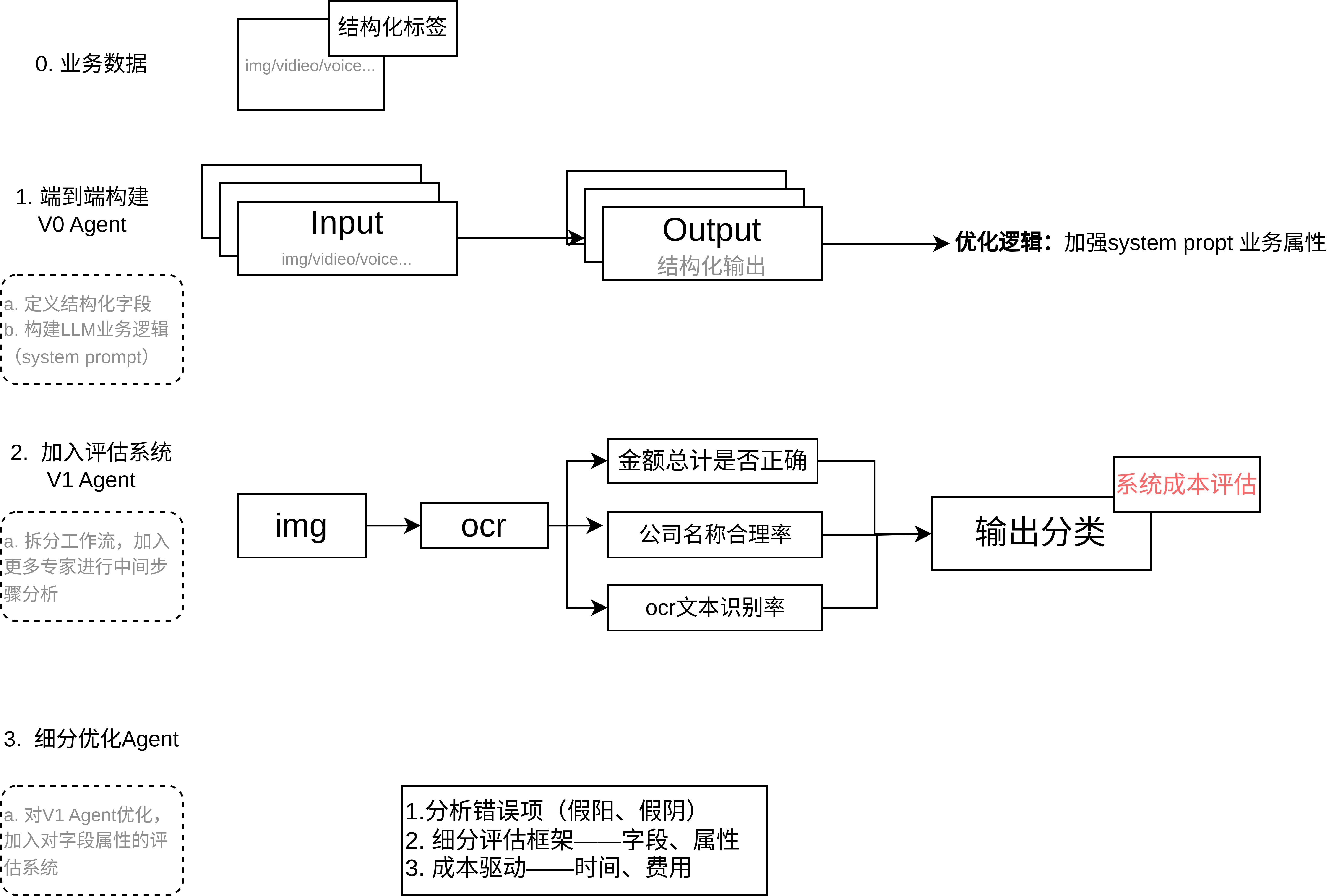
以 OpenAI Cookbook 的《receipt_inspection》示例為基礎,探討如何設計一個可測試、可優化的端到端 AI Agent 系統。整體流程分為三個階段:
(1) 端到端 Agent 構建(基線測試),
(2) 拆分中間任務與評分系統(可解釋性與對齊),
(3) 構建收益/成本框架(系統優化)。
文章目錄
- 領域LLM九講——第4講 構建可測評、可優化的端到端商業AI Agent 系統
- 1. 構建端到端系統 —— V0 Agent(基線)
- 2. 拆分中間任務與評分系統 —— V1 Agent(可解釋性與對齊)
- 3. 構建收益/成本框架 —— V2 Agent(系統優化)
- 附錄
1. 構建端到端系統 —— V0 Agent(基線)
- 構建最簡化系統
首先搭建一個最基礎的 Agent:直接使用一個 LLM 通過單次提示(或調用)完成整體任務。例如在收據解析場景中,可使用大模型對收據圖片進行文字識別,并一次性輸出所有字段信息與審核決策。示例中使用了 Pydantic 定義結構化輸出模型(包含商戶名稱、地點、時間、條目列表等字段),并調用 LLM 填充這些字段。該階段的目標是快速獲得一個粗粒度的可行解,并建立性能基準。此時可記錄關鍵指標(如整體識別準確率、誤判率等)作為后續優化的對比基線。 - 優點與風險
端到端設計簡單直接,開發迭代速度快。但也存在風險:缺乏內部可觀察性,一旦結果錯誤很難定位原因,容易出現“碰運氣”式的盲目迭代。沒有中間檢查點的系統可能隱藏關鍵錯誤,對復雜任務或高風險場景(如醫療診斷)欠妥。正如 OpenAI 所言,如果沒有將評估內置于流程核心,開發往往陷入“拍腦袋”的猜測和印象式判斷。因此該階段僅作為起點,一方面需要對輸出結果進行初步人工或規則驗證,另一方面需意識到端到端方案的局限。
2. 拆分中間任務與評分系統 —— V1 Agent(可解釋性與對齊)
-
任務拆解
在基線驗證后,將復雜任務拆分為可管理的子任務或步驟,增強系統可解釋性。例如,可按邏輯階段分別處理:先用 OCR 獲取文本,再讓 LLM 提取字段、計算總額,最后再讓 LLM 給出審核判定。示例中通過 Pydantic 模型來定義每個子任務的輸出(如交易項目列表、總金額等)。分解后,每個子任務的輸出都成為可獨立評估的中間結果,這有助于理解整體過程并針對性優化某一步。 -
引入 Grader 評分
針對每個中間輸出,引入一個Grader(評判器)來自動評估其質量,即“LLM 作為評判者”的思路。具體做法是設計多個評分模塊,對不同子輸出進行檢查:可以是簡單的相等檢查、文本相似度計算,或再次調用 LLM 作為評判模型。例如,收據示例定義了幾類 grader:字符串嚴格匹配檢查(如總額是否一致)、文本相似度檢查(如商戶名稱相似度)、以及基于模型的評分(如判斷提取的條目是否缺漏)。這些 grader 分別針對輸出的不同部分進行驗證(有的只看輸出本身,有的則需要對照正確答案)。Databricks 的 Agent Evaluation 也采用類似方法,使用一組 LLM 評判器分別對答案的正確性、相關性等方面進行評估。 -
控制節點與瓶頸定位
引入 grader 后,系統就有了“中控節點”,可以在每一步檢測失敗并采取措施。多個 Grader 評分后可合并結果,總結整體質量。如果整體評估失敗,系統能指出是哪一個子任務的 grader 首先未通過。比如若“總額檢查”未通過,就說明金額提取有問題;若“缺失條目檢查”未通過,就說明提取遺漏條目。這樣一方面提高了可解釋性,另一方面可針對性地調整模型或提示,形成閉環改進。使用 LLM-作為評判者的做法在實踐中被廣泛采用,它能自動化評估文本質量并提供明確評分指標,是人工評估的可擴展替代方案。綜上,在拆分任務并引入 Grader 后,我們可定位并修復 Agent 的弱點,從而對齊業務需求并逐步提升可靠性。
3. 構建收益/成本框架 —— V2 Agent(系統優化)
- 多維度成本度量
除準確率外,引入成本度量是優化的關鍵。首先要明確定義成本項:例如每張收據的處理成本(包含模型調用和基礎設施開銷)、低置信輸出的人力校驗成本、系統開發維護成本,以及因為錯誤帶來的業務損失(如漏檢或錯判的罰款等)。在 Agent 層面,可量化的成本指標包括:調用模型所用的 token 數(直接對應 API 費用)、端到端響應延遲(影響用戶體驗或業務處理速率)、人工干預頻率等。Databricks Agent Evaluation 就自動統計了整個任務過程中的總 token 數(含輸入、輸出)作為成本近似,也計算總時延。這些指標匯總到每次請求的評估報告中,幫助開發者了解資源消耗。 - 性能/成本權衡
系統優化即在多維指標上做權衡:精度、成本、延遲之間往往需要平衡。正如相關指導所指出的,需要權衡模型規模與延遲、質量與成本等因素。例如,可以先使用最強大的模型驗證正確性,再嘗試用更小模型或分步調用來降低成本;也可接受小幅度精度下降以換取大幅度的時間和費用節省。業務方可能愿意為降低延遲或費用而犧牲一定的準確率,反之亦然。因此需要明確量化:如每增加多少 token 花費多少美元、響應延遲對用戶體驗的影響,以及人工干預一次的成本等。通過這些量化指標,可以建立收益/成本模型,判斷在何種改進措施下投入產出比最高。例如,如果某個子模塊的 grader 失敗率很高,就算投入更大模型減少錯誤,增加的成本是否值得?這樣的分析需要具體計算錯誤降低帶來的收益和新增成本。綜合考慮后,可制定策略:如對重點子任務使用高質量模型,對一般子任務用小模型,或只對 grader 評分未通過的例外場景啟用人工復核,將資源聚焦到最需要的環節上。
如在文章中,作者建立的成本體系:
公司每年處理 100 萬張收據,基準成本為每張收據 0.20 美元, 審計收據的成本約為 2 美元
未能審計我們應該審計的收據,平均成本為 30 美元,5% 的收據需要審計
現有流程
- 識別 97% 情況下需要審計的收據
- 2% 的情況下錯誤識別不需要審計的收據
這給了我們兩個基準比較:
- 如果我們正確識別每張收據,我們將花費 100,000 美元進行審計
- 我們目前的流程在審計上花費了 135,000 美元,并因未審計的費用損失了 45,000 美元
除此之外,人工驅動的過程還需額外花費 20 萬美元。
這里只是構建了審核系統中構建節約成本的高效Agent,但本質上沒有帶來利潤。如果在成本基礎上添加利潤,如生圖框架、廣告視頻生成等,首先要考慮整個工作流pipeline的節點構造(結果為導向);然后考慮生成過程中的穩定可控性(結果為導向);其次考慮成本(LLM選擇)與利潤(生成時間與效果),利潤這塊還可以通過增加用戶復用率(如生成視頻的精修)。
附錄
本人github項目地址:https://github.com/oncecoo
歡迎關注!
:MySQL目錄與啟動配置全解析)

)


強化學習專題(1))



 的變化導致的影響(那部分被分給了鏈式項))

 類,加深對拷貝構造函數的理解)
)



語音/字幕標注 通過via(via_subtitle_annotator))


