用于精確實時滑坡檢測的雙向LSTM模型:以印度梅加拉亞邦毛永格里姆為例的研究
IEEE Internet of Things Journal(簡稱 IoT?J)是一份 IEEE 自 2014 年起雙月刊發表的國際頂級學術期刊,專注于物聯網各領域的研究。
作者: J. Sharailin Gidon
🧠 研究目標
建立一個基于深度學習的預測模型,用于:
- 精確預測滑坡區域的斜坡位移(slope displacement)、
- 地下水位(WL) 和
- 基質吸力(matric suction, MS),
主要以 降雨、水壓、時間等氣象/水文變量 作為輸入,不依賴傳統的土壤物理參數或復雜地質信息。
🔍 方法概述
-
使用 自回歸多變量 Bi-LSTM(Bidirectional Long Short-Term Memory)模型,可以:
- 同時處理多個輸入變量(multivariate);
- 捕捉時序前后依賴(bidirectional);
- 利用前一步預測值作為下一步的輸入(auto-regressive)。
-
模型結構特點:
- 輸入層 → 兩個 LSTM 隱藏層 → 輸出層;
- 激活函數選擇上對比了 ReLU 和 tanh;
- 多組 LSTM 單元數量和 dropout 比例組合對性能進行了測試;
- 模型結構如圖 5 和圖 6 所示,參數配置如表 I。
📊 結果
-
最佳模型具有:
- 最多 LSTM 單元、
- 最大 dropout 比例、
- 使用 tanh 激活函數,
在所有測試中取得最高 R 2 R^2 R2(0.93)和最低 MSE。
-
訓練準確率達 95.9%,測試準確率為 93%;
-
模型成功預測了:
- 不同深度(10m、20m、30m)及方向的斜坡位移;
- 三個測量點的基質吸力;
- 地下水位。
🔁 對比分析
-
與傳統 LSTM、Bi-LSTM 模型對比:
- 本文提出的模型處理的是多變量輸入和輸出,而傳統模型多用于單變量;
- 能同時捕捉時間(時序)和空間(多傳感器)之間的關系;
- 擁有更強的泛化能力和預測精度。
? 結論
- 模型對滑坡形變預測高度準確;
- 降雨是滑坡變形最關鍵的外部因素;
- 提出的 Bi-LSTM 模型為滑坡預警提供了一種高效、經濟、無需復雜地質數據的解決方案;
- 可輕松遷移至其他區域,只要有降雨、水位和基質吸力數據;
- 相較以往方法,本研究的模型預測精度高、誤差低,適合實際部署用于滑坡預警。
摘要——本文提出了一種用于滑坡檢測的雙向長短期記憶(LSTM)模型。以往在該領域應用機器學習(ML)已經展示出其整體潛力,這也促使有必要實現一種合適的算法。滑坡是一種自然災害,會對受影響區域造成嚴重破壞和干擾。滑坡的早期檢測是減少其影響的關鍵,因此開發準確且高效的模型顯得尤為重要。
本研究選取了位于印度梅加拉亞邦毛永格里姆(Mawiongrim)的一個活躍滑坡區域作為研究對象。所提出的模型采用雙向LSTM,旨在捕捉從該地區部署的長期實時監測系統中收集的輸入數據的時間模式。為評估模型預測的有效性,研究使用包含多種與滑坡相關特征的數據集進行訓練,這些特征包括地形、降雨、水文及土壤屬性等。
結果表明,所提出的模型相比其他模型在滑坡檢測方面具有更高的準確率和更低的誤差值。此外,該模型還能提供實時預警系統,使其成為滑坡早期檢測的可行工具。研究還重點分析了基質吸力與地下水位的預測模型,這兩者對判斷邊坡穩定性具有關鍵作用。
關鍵詞:人工智能(AI)、滑坡、長短期記憶網絡(LSTM)、實時監測、邊坡檢測。
一、引言
在一個多雨或持續降雨的地區,如果斜坡本身已經處于不穩定狀態,那么該斜坡就更容易發生塌陷。當降雨入滲引起的土壤應力行為變化超過土體的抗剪強度時,斜坡就會發生崩塌。如果不研究滑坡在特定氣候事件下的運動模式,就很難對其發生進行準確預測 [1]。僅僅監測斜坡位移是不夠的,還需要結合環境和巖土工程方面的其他因素。
基于大量反映斜坡在雨水入滲影響下行為的數據集,可以模擬基于物理和經驗的模型,以構建可靠的預警系統 [2]。多個物理因素,如斜坡材料、強度、地下水、降雨入滲和斜坡幾何形狀都會影響其穩定性。為了理解斜坡可能崩塌的條件,有必要對這些因素進行觀測。滲流與變形可以與斜坡穩定性同時進行監測,這有助于在不同條件下評估斜坡行為,并為防護策略的有效性提供數據支持。
實時監測可以對可能的斜坡失穩事件發出預警。各種設備可以用來驗證這些特征隨時間的變化。例如:
- 使用 irrometer 測量土壤吸力或負孔隙水壓力;
- 使用 孔隙水壓力計(piezometer) 監測地下水位變化;
- 使用 雨量計(rain gauge) 跟蹤降雨量和降雨時長 [3]。
在滑坡監測中常用的工具還包括:傾斜計、全球定位系統(GPS)、全站儀、孔隙水壓力計等。過去 50 年里,大量基于人工智能(AI)和機器學習(ML)的預測研究模型被開發出來 [4]。先進研究廣泛采用了循環神經網絡(RNN)、神經動力學求解器、殘差神經網絡下的非負潛因子建模、以及多層結構的采樣型潛因子模型(MLF)等方法 [5]-[10]。
有研究提出了一種博弈論框架,用以指導 RNN 的設計,用于多個冗余機械臂的分布式協調控制。此外,也有針對含時延問題的冗余機械臂協同控制,提出了一種時延與分布式神經動態方案 [6]。另一研究提出了一種基于交替方向乘子法(ADMM)的對稱非負潛因子分析(ASNL)模型,用于準確表達網絡對稱性,并有效處理大型無向加權網絡中的缺失數據 [8]。
AI 模型的應用不僅限于機械臂控制、性能優化、機器翻譯等領域,還擴展到了滑坡預測和邊坡位移預測。滑坡過程的主要指標是邊坡位移,研究和預測滑坡位移對于預判斜坡失穩具有重要意義和實際價值。
本研究所用數據來自于印度梅加拉亞邦地區一個獨特的實時監測系統。滑坡預測的研究可以追溯到 1960 年代 [11],而長短期記憶網絡(LSTM)則是其中非常相關的模型。LSTM 是一種強大的 RNN 結構,主要為了解決傳統 RNN 在學習長期依賴問題時的梯度爆炸/消失問題。該模型能夠高效利用本地實時信息來預測區域斜坡的運動情況。
LSTM 后來經過進一步發展,被眾多研究者采用和改進 [12], [13]。多項測試表明,這一框架比先進方法表現更為穩健和出色。在機器學習文獻中,基于 RNN 的 LSTM 已被證實可用于預測土體移動 [14], [15]。這些循環模型作為前饋神經網絡的擴展,具有內部記憶結構。模型當前的輸入結果依賴于先前的計算過程,每條數據輸入都執行相同的函數運算。
已有研究者設計了單層 LSTM 模型,通過時間序列形式的歷史土體移動數據來預測潛在的邊坡移動 [15]-[18]。為了預測印度喜馬拉雅地區已知滑坡事件中的土體移動,有人提出了一種雙向堆疊式(BM)LSTM 集成模型 [19]。在標準計算智能方法無法勝任時,LSTM 網絡在時間序列分析中的預測和識別能力已經被證明非常有效 [20]。
近年來也有研究開發出單變量和多變量的深度學習預測模型。文獻 [21] 展示了這些模型的性能評估,并討論了影響其預測能力的因素。盡管已有方法在準確度和均方根誤差(RMSE)上表現良好,但仍存在在滑坡預測中誤差偏大的問題。
因此,本研究提出了一種誤差更低、預測更精準的滑坡/邊坡位移預測方法。該方法基于 RNN 架構的 LSTM 網絡,專門用于降雨誘發的滑坡預測,選用此模型正是因為它擅長處理長期數據預測。模型中使用的斜坡數據來自于部署在印度梅加拉亞邦毛永格里姆地區的實時監測系統。LSTM 模型被用于研究斜坡位移與降雨模式、基質吸力變化和雨季期間地下水位之間的依賴關系。同時,模型也分析了降雨下基質吸力和地下水位的變化。
本研究提出了一種深度學習模型,用于預測邊坡傾斜、基質吸力和地下水位(WL),這些都是判斷滑坡可能性的關鍵因素。此外,與現有研究相比,該模型在誤差率方面表現最佳。本研究共開發了 5 個斜坡傾斜模型(INC)、3 個基質吸力模型(MS)以及若干地下水位模型。
II. 背景
總體上,這些研究可以分為基于物理原理的模型和基于數據驅動的模型 [16], [22]。隨著深度學習的發展,特別是 LSTM 的出現,使得處理具有長期依賴關系的時間序列數據成為可能,從而有望構建可靠的預測解決方案。由于滑坡位移本質上是典型的時間序列數據,因此時間序列分析方法經常被用于研究與建立預測模型 [15], [23]。
滑坡預測模型所期望的位移值范圍(而非單一值)決定了預測結果的準確性 [17], [24], [25]。Xie 等人 [26] 使用 LSTM 模型直接預測滑坡位移,同時考慮了坡度、土地利用因素、滑坡特征剖面和巖體性質等多種因素。通過模型得到的位移信息可以反映滑坡本身隨時間的穩定性及其變化狀態 [27]。為了驗證位移預測的準確性,該研究將模型預測結果與一年期的累計位移實測值進行比較,證明了其有效性 [26]。
此外,研究者還提出結合 LSTM 的變分模態分解(VMD)算法,用于動態建模邊坡周期性與隨機性位移行為。然而,該算法在性能上受到限制,主要是因為參數設置通常依賴經驗判斷。
考慮到滑坡位移的非線性動態特性,研究中引入了 雙向 LSTM(Bi-LSTM) 模型來探究階梯狀滑坡的位移情況。該方法能夠有效捕捉監測數據中過去與未來的成分 [18]。
邊坡失穩通常由土壤基質吸力的降低所引起,這種變化會導致土體強度下降。因此,掌握降雨參數及其對土體抗剪強度、土水相互作用、地下水位變化的影響,對于了解滑坡成因是十分有益的 [28]。
在印度,西北部和東北部的喜馬拉雅山脈以及半島地區的西高止山脈,是最容易在降雨季節發生滑坡的地區。而 梅加拉亞邦(Meghalaya) 位于印度東北部,該地由于強降雨頻發,滑坡災害屢見不鮮。
在此背景下,雙向 LSTM 網絡 可用于序列標注任務,因為它們可以在某一時刻同時訪問過去和未來的輸入數據。通過這種方式,我們能夠有效利用過去(通過前向狀態)和未來(通過后向狀態)特征來建模一段時間內的動態過程 [29]。
反向傳播算法(Backpropagation Through Time, BPTT) 被用于訓練雙向 LSTM 網絡。訓練過程中,模型會在展開的網絡上執行正向與反向的掃描操作,類似于普通神經網絡中的前向傳播與反向傳播,但在每一個時間步都需要顯式地展開隱藏狀態。
另外,在處理序列的起始和結束數據點時需要特殊的處理策略。本研究中采用了批處理實現(batch implementation),這使得可以同時處理多條時間序列數據。
III. 研究區域
Mawiong Rim 是印度 梅加拉亞邦(Meghalaya) 的一個偏遠地區,位于國家公路 6 號線(NH-6)——古瓦哈提至西隆(Guwahati–Shillong, GS)沿線(見圖 1)。該地區以其陡峭的山坡、深谷和脆弱的基巖而聞名,這些地質特征顯著增加了滑坡發生的風險。

此外,該地區的降雨量極高,而強降雨已知會進一步破壞山區的穩定性。Mawiong Rim 的基礎設施高度暴露于滑坡等自然災害之中,一旦發生滑坡,將可能對該區域造成嚴重破壞。
該地區也容易發生突發性的山洪和積水現象,進一步導致邊坡失穩甚至滑坡。因此,為了降低滑坡災害的風險,必須采取合理的土地管理措施,尤其是在季風季節更顯重要。
因此,必須實施切實可行的 減災措施,例如:建立早期預警系統,制定人員轉移策略等,以保障該區域居民的生命安全和財產安全。
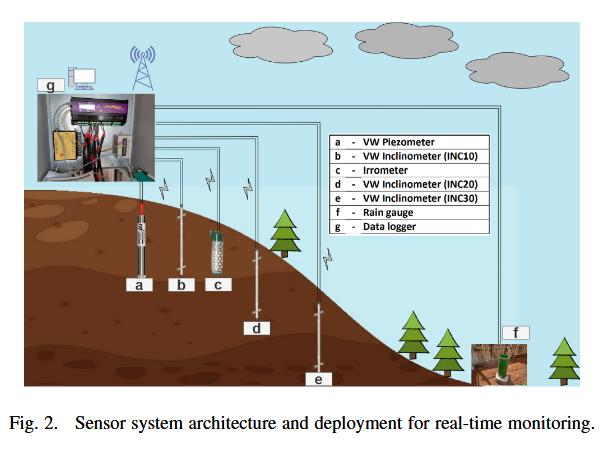
IV. 方法論
A. 實時監測系統
該區域滑坡的主要誘因是持續性的強降雨。本次監測選址位于印度梅加拉亞邦 NH-6(古瓦哈提-西隆)路段的 Maw?ong Rim 地區(見圖2)。理解降雨引發邊坡失穩的機制至關重要,因為降雨滲入坡體會改變土體應力狀態,最終削弱其抗剪強度。
影響邊坡行為的因素包括:土體的巖土工程性質、降雨量、有無植被、水文參數等。雨季時,邊坡周圍存在張裂縫,這些裂縫使雨水易于滲入。
為了研究降雨對邊坡的影響,系統地安裝了一個實時監測系統,監測周期超過一年,覆蓋了旱季與雨季的坡體行為。通過持續監測土體水文行為、邊坡的巖土特性與當地降雨情況,可以更好地理解邊坡對降雨的響應。
在 Mawiong Rim 的目標坡面布設了多個傳感器,監測基質吸力、地下水變化、坡面位移以及降雨的影響。2021 年 5 月進行現場開挖并鉆孔,以安裝振弦(VW)孔壓計和振弦傾斜儀,分別用于實時監測地下水位變化和邊坡位移。
所安裝的 VW 傾斜儀為雙向傳感器( A + A ? A^+A^- A+A? 與 B + B ? B^+B^- B+B?),分別記錄東南(SE)方向和西南(SW)方向的傾角(見圖2)。共安裝了三組雙向 VW 垂直多點傾斜儀,分別在深度為 10 m、20 m 和 30 m 的鉆孔中測量水平位移。
VW 孔壓計是一種壓力傳感器,根據其頂部所感應的壓力進行讀數。**張力計(Tensiometer)**用于監測基質吸力(即負孔隙水壓力)。其測量范圍為 50 k g / c m 3 50\ \mathrm{kg/cm^3} 50?kg/cm3,輸出單位為 centibar( 10 ? 2 10^{-2} 10?2 kPa),量程為 200 centibar。
坡體地下共安裝了三個水印傳感器(I1、I2、I3)。雨量計用于監測降雨持續時間與強度(見圖2)。通過 **數據記錄儀(Data Logger)**收集傳感器數據,數據容量最大支持 512 MB,同時內置一張宏尺寸 SIM 卡。
數據通過 SIM 卡連接互聯網,發送到指定郵箱以供存儲和分析(見圖2)。
B. 雙向 LSTM 模型(Bidirectional LSTM)
雙向 LSTM 由兩個獨立的 LSTM 層組成,一個處理正向序列,另一個處理反向序列。正向 LSTM 從第一個時間步開始,順序處理輸入序列直至末尾(見圖3),每個時間步 t t t處的 LSTM 單元根據當前輸入與前一個隱藏狀態輸出新的隱藏狀態與輸出。
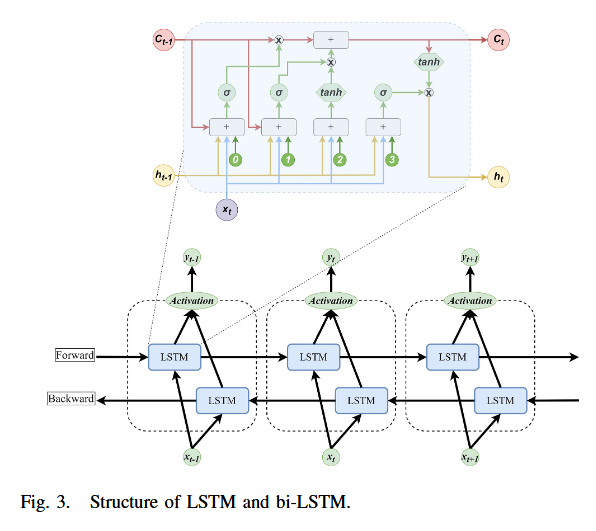
反向 LSTM 從最后一個時間步開始,倒序處理輸入,同樣計算每個時間步的輸出與隱藏狀態。兩個方向的輸出在對應時間步進行拼接,得到包含前向與后向上下文的完整特征表示,便于捕捉時序依賴性。
最終,拼接后的輸出將傳遞至后續層或輸出層用于預測。
設輸入序列為:
X ~ = ( x 1 , x 2 , … , x T ) \tilde{X} = (x_1, x_2, \ldots, x_T) X~=(x1?,x2?,…,xT?)
標準 RNN 生成的隱藏狀態序列與輸出序列分別為:
h ~ = ( h 1 , h 2 , … , h T ) , Y ~ = ( y 1 , y 2 , … , y T ) \tilde{h} = (h_1, h_2, \ldots, h_T), \quad \tilde{Y} = (y_1, y_2, \ldots, y_T) h~=(h1?,h2?,…,hT?),Y~=(y1?,y2?,…,yT?)
通過以下迭代公式計算(KaTeX parse error: Undefined control sequence: \[ at position 7: t \in \?[?1, T]):
- $ \tilde{h}t = H\left(\tilde{W}{xh}x_t + \tilde{W}{hh}h{t-1} + \tilde{b}_h \right) $ ?(1)
- $ \tilde{y}t = \tilde{W}{hy}h_t + \tilde{b}_y $ ?(2)
其中:
- H H H 為激活函數,如 Sigmoid、Tanh 或 ReLU;
- W ~ \tilde{W} W~ 表示權重矩陣, b ~ \tilde{b} b~ 表示偏置向量。
LSTM 架構通過 記憶單元(memory cells) 有效保留長程信息。在 LSTM 中, H H H 的計算方式如下:
- i _ t = tanh ? ( W ~ ? x f x _ t + W ~ ? h f h _ t ? W ~ _ c f c _ t ? b ~ _ i ) i\_t = \tanh\left( \tilde{W}*{xf} x\_t + \tilde{W}*{hf} h\_t - \tilde{W}\_{cf} c\_t - \tilde{b}\_i \right) i_t=tanh(W~?xfx_t+W~?hfh_t?W~_cfc_t?b~_i)?(3)
- f _ t = tanh ? ( W ~ ? x f x _ t + W ~ ? h f h _ t ? 1 + W ~ ? c f c ? t ? 1 + b ~ _ f ) f\_t = \tanh\left( \tilde{W}*{xf} x\_t + \tilde{W}*{hf} h\_{t-1} + \tilde{W}*{cf} c*{t-1} + \tilde{b}\_f \right) f_t=tanh(W~?xfx_t+W~?hfh_t?1+W~?cfc?t?1+b~_f)?(4)
- c _ t = f _ t ? c _ t ? 1 + tanh ? ( W ~ ? x c x _ t + W ~ ? h c h _ t ? 1 + b ~ _ c ) c\_t = f\_t \cdot c\_{t-1} + \tanh\left( \tilde{W}*{xc} x\_t + \tilde{W}*{hc} h\_{t-1} + \tilde{b}\_c \right) c_t=f_t?c_t?1+tanh(W~?xcx_t+W~?hch_t?1+b~_c)?(5)
- o _ t = tanh ? ( W ~ ? x o x _ t + W ~ ? h o h _ t ? 1 + W ~ _ c o c _ t + b ~ _ o ) o\_t = \tanh\left( \tilde{W}*{xo} x\_t + \tilde{W}*{ho} h\_{t-1} + \tilde{W}\_{co} c\_t + \tilde{b}\_o \right) o_t=tanh(W~?xox_t+W~?hoh_t?1+W~_coc_t+b~_o)?(6)
- h _ t = o _ t ? tanh ? ( c _ t ) h\_t = o\_t \cdot \tanh(c\_t) h_t=o_t?tanh(c_t)?(7)
在 雙向神經網絡 中,除正向隱藏序列 h ~ + \tilde{h}^+ h~+ 外,還需計算反向隱藏序列 h ~ ? \tilde{h}^- h~?,以及最終輸出序列 Y ~ \tilde{Y} Y~,計算過程為:
- $ \tilde{h}t^+ = \tilde{H}(\tilde{W}{xh^+} x_t + \tilde{W}{hh^+} h{t-1}^+ + \tilde{b}_{h^+})$?(8)
- $ \tilde{h}t^- = \tilde{H}(\tilde{W}{xh^-} x_t + \tilde{W}{hh^-} h{t+1}^- + \tilde{b}_{h^-})$?(9)
- $ \tilde{y}t = 2 \cdot \tilde{W}{hy^+} h_t^+ - \tilde{W}_{hy^-} h_t^- + \tilde{b}_y$?(10)
通過將兩個方向的輸出拼接,可獲得雙向上下文表示(見圖4),使模型具備從兩個方向學習長距離依賴的能力。
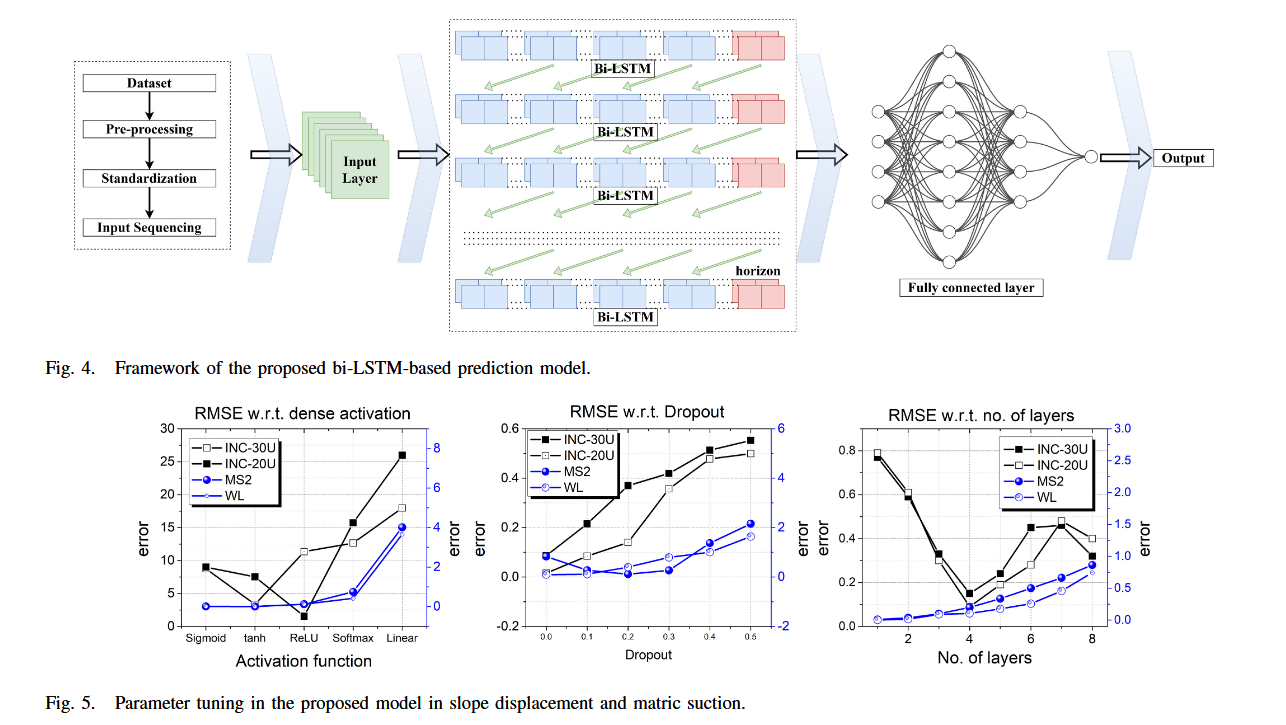
為實現滑坡預測,構建了以下 Bi-LSTM 模型:
-
坡體傾角預測模型(SE/SW方向):以降雨模式、基質吸力、地下水位變化與時間為輸入;
-
坡面位移預測模型(6個模型):
- INC-30U、INC-30D
- INC-20U、INC-20D
- INC-10U、INC-10D
-
基質吸力預測模型(3個模型:MS1, MS2, MS3):以降雨模式、地下水位變化與時間為輸入;
-
地下水位變化預測模型(1個模型:WL):以降雨模式與時間為輸入。
模型使用的數據集時間范圍為:2022年8月21日 至 2023年1月16日。
在建模前,對數據進行了歸一化處理,并將數據按 75% 訓練集與 25% 測試集的比例劃分,使用 sklearn 中的 train_test_split 函數隨機劃分數據集。
以下是你提供的**第五章“結果與討論”和第六章“結論”**的中文翻譯,所有公式均已使用 KaTeX 格式,關鍵變量和字母均已用美元符號 $ 包裹:
V. 結果與討論
為了評估模型誤差,采用均方誤差(MSE),即實際值與預測值之間差值的平方的平均值。MSE 越大,表示誤差越高。
一個衡量因變量中有多少變異可以被自變量解釋的指標是決定系數 R 2 R^2 R2,它用于評估模型的擬合優度。因此, R 2 R^2 R2 越高,表示模型擬合越好;反之則越差。
斜坡位移是通過安裝在地下 10 米、20 米和 30 米處的測斜儀獲得的。每個測斜儀提供兩個方向(東南 SE 和西南 SW)的數據,因此總共獲得六組位移數據。在讀取數據集后,僅篩選出所需的輸入變量和目標變量。
用于預測坡面位移(INC)的輸入變量包括降雨、地下水壓力、水位 WL、時間和基質吸力 MS。預測 MS 的輸入變量為降雨和時間。
A. 預測模型
模型中用于預測土壤運動的各個參數如表 I 所示。定義隱藏狀態或輸出維度的單元數和 LSTM 層的參數數量分別為:
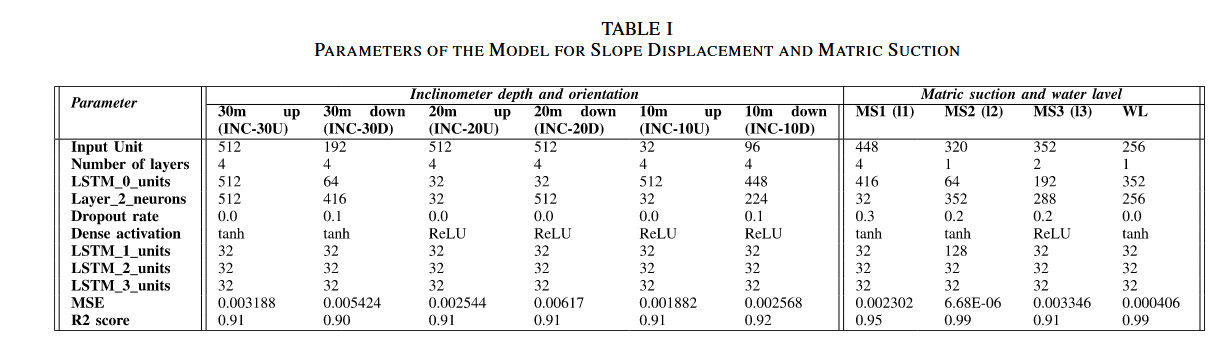
- 512 512 512:INC-30U、INC-20U、INC-20D;
- 192 192 192:INC-30D;
- 32 32 32:INC-10U;
- 96 96 96:INC-10D。
所有模型均包含四層結構:一個輸入層、兩個隱藏層和一個輸出層。
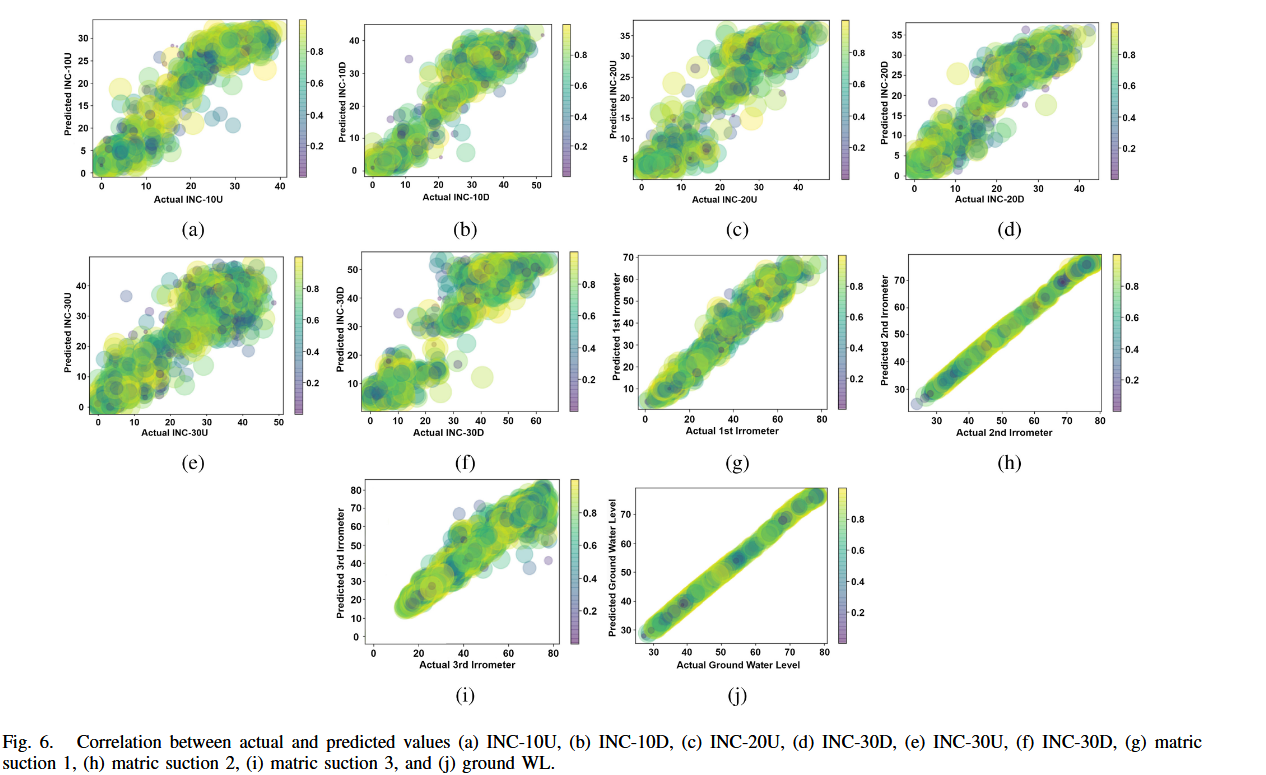
圖 6 比較了多個基于 LSTM 層的深度學習模型訓練設置,包括:
- 層數、
- LSTM 單元數、
- 每層神經元數量、
- Dropout 比例、
- 激活函數、
- 訓練時的批次大小。
使用 MSE 和 R 2 R^2 R2 分數表示訓練結果。研究結果表明,具有最多 LSTM 單元、最多層數和最高 Dropout 率的模型具有最低的 MSE 和最高的 R 2 R^2 R2。
從圖 5 可見,最優模型為具有最多層數、LSTM 單元和 Dropout 率的結構。此外,激活函數的選擇也影響結果,tanh 激活函數的表現優于 ReLU 激活函數。由于所有模型在 epoch 和 batch size 上參數相近,因此這兩個參數對結果影響不大。
神經網絡中的激活函數將節點的總加權輸入轉換為該節點的激活或輸出值。**ReLU(修正線性單元)**是一種分段線性變換,輸入為負時輸出為 0,正數時輸出為其本身。ReLU 由于易于訓練和通常表現更好,已經成為多種神經網絡的默認激活函數。
梯度消失現象限制了 sigmoid 和 tanh 函數在多層網絡中的應用。ReLU 修復了這個問題,使得模型可以更快地學習并表現更好。因此,它在多層感知機和卷積神經網絡中是默認選項。
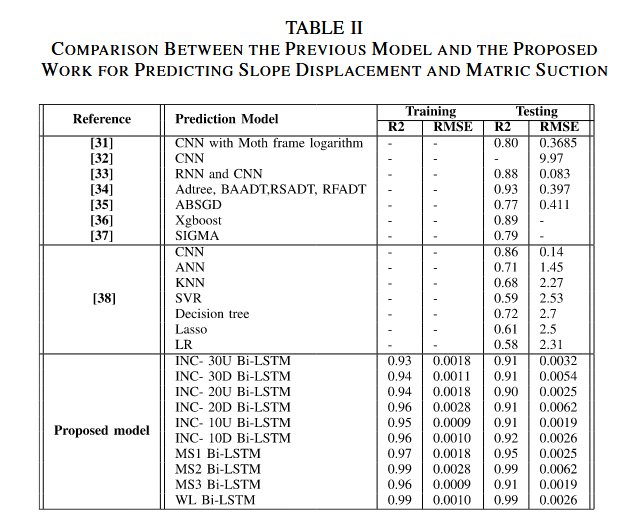
該模型在訓練數據上的整體準確率為 95.9%,在測試數據上的準確率為 93%(見表 II)。模型準確預測了:
- 10、20、30 米深度處斜坡上/下方向的位移(圖 6(a)-(f));
- 第 1、2、3 個吸力傳感器的讀數(圖 6(g)-(i));
- 水位 WL(圖 6(j))。
模型的結果表明,它具有高度準確性,能夠從數據中學習并進行精確預測。它可以在多種地下水位、基質吸力和降雨情景下準確預測滑坡傾角。
B. 對比分析
表 III 中的指標對比了本研究提出的模型與先前在相同數據集上實現的 LSTM 與 Bi-LSTM 模型。
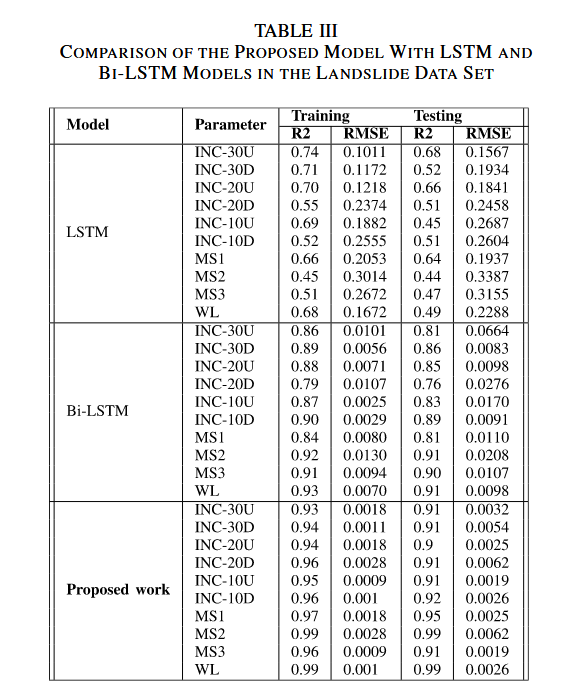
該模型采用自回歸結構(auto-regressive),將前一次的預測結果作為輸入之一用于下一步的預測,從而引入預測反饋。
與通常用于單變量序列的 LSTM 和 Bi-LSTM 不同,自回歸多變量 Bi-LSTM 架構特別適用于處理多變量數據,即每個時間步可以包含多個特征或變量,從而可以同時捕捉多個因素之間的關系。
該模型可以捕捉數據中的空間和時間依賴性。提出的方法利用雙向上下文來捕捉時間依賴關系,同時通過多變量特征來捕捉空間關系。
這種方法被設計為在每個時間步輸出多個預測變量,因而非常適合多變量時間序列數據的預測任務。
綜上,自回歸多變量 Bi-LSTM 是一種集成了雙向建模、多變量處理和自回歸反饋機制的復雜模型,可有效提高多變量時間序列預測的精度。
VI. 結論
本研究利用深度學習,專注于主動預測由局部降雨引起的周期性位移。主要結論如下:
- 預測值與實測位移值高度一致。
- 結果表明,降雨是 Mawiong Rim 滑坡中最主要的動態因素。
- 雙向 LSTM 模型為地面滑坡預警系統提供了潛力巨大的工具,可用于預測斜坡位移、基質吸力與地下水位(使用 INC、MS 與 WL 模型)。
- 提出了一種經濟高效的工具,用于在局部尺度上預測土壤邊坡不穩定性。模型可預測坡面位移、基質吸力與地下水位,而無需土壤參數或幾何信息,因此可適用于其他區域,只需已知初始水位、基質吸力和降雨模式。
- 以往研究雖然具有較高精度,但往往也存在較高的 RMSE 值,說明預測模型在滑坡預測方面可能存在較大誤差。而本研究模型在預測滑坡或坡面位移時,具有更高的準確率和更小的誤差。


強化學習專題(1))



 的變化導致的影響(那部分被分給了鏈式項))

 類,加深對拷貝構造函數的理解)
)



語音/字幕標注 通過via(via_subtitle_annotator))





--linux內核之V4L2框架及ov9281驅動分析(中))