文章目錄
- ES8
- 1 ES架構
- 2 ES適用場景
- 3 ES使用
- 3.1對比mysql
- 3.2 索引(Index)
- 3.3 類型(Type)
- 3.4 文檔(Document)
- 3.5 字段(Field)
- 3.6 映射(Mapping)
- 4 ElasticSearch 基礎功能
- 4.1 分詞器
- 4.2 索引操作
- 4.2.1 創建索引
- 4.2.2 查看所有索引
- 4.2.3 查看單個索引
- 4.2.4 刪除索引
- 4.3 文檔操作
- 4.3.1 創建文檔
- 4.3.2 查看文檔
- 4.3.3 查詢所有文檔
- 語法: GET /{索引名稱}/_search
- 4.3.4 修改文檔
- 4.3.5 修改局部屬性
- 4.3.6 刪除文檔
- 4.4 映射mapping
- 4.4.1 查看映射
- 4.4.2 動態映射
- 4.4.3 靜態映射(推薦)
- 4.4.4 nested 介紹
- 5 DSL高級查詢
- 5.1 DSL概述
- 5.2 DSL查詢
- 5.2.1 查詢所有文檔
- 5.2.2 匹配查詢(match)
- 5.2.3 多字段匹配
- 5.2.4 關鍵字精確查詢
- 5.2.6 多關鍵字精確查詢
- 5.2.7 范圍查詢
- 5.2.8 指定返回字段
- 5.2.9 組合查詢
- must
- should
- must_not
- filter
- 5.2.10 聚合查詢
- max
- min
- avg
- sum
- stats
- terms
- 5.2.11 排序
- 5.2.12 分頁查詢
- 5.2.13 高亮
- 6 Java Api操作ES
- 6.1 ElasticSearch Java API Client
- 6.1.1 搭建項目
- 6.1.2 配置連接
- 6.1.3 實體類
- 6.1.3 測試查詢
- 6.2 Spring Data ElasticSearch
- 6.2.1 搭建項目
- 6.2.2 document映射
- 6.2.3 測試查詢
- 6.2.4 模板對象測試
- ES插件
- 1. **Ingest Node 插件**
- 2. **Analysis Plugins(分析插件)**
- 3. **Repository Plugins(倉庫插件)**
- 4. **Discovery Plugins(發現插件)**
- 5. **Alerting and Monitoring Plugins(監控和告警插件)**
- 注意事項
- ES部分場景八股回答重點
- 如何在es中設計實現多層次緩存
- 2es如何實現分布式事務
- 3.Finite State Transducer是什么?有什么用
- es中的Fielddata是什么?如何優化其性能?
- es集群滾動升級如何實現?
- 1. **ES實現機器學習模型推理**
- 2. **倒排表的 FOR 和 RBM 壓縮算法**
- 3. **確保數據一致性前提下更新 ES 倒排索引**
- 4. **ES 中的倒排列表**
- 5. **如何利用 ES 實現大數據聚合查詢**
- 6. **ES 集群架構調優**
- 7. **如何優化 ES GC**
- 8. **為什么 ES 內存 32G 以上性能幾乎無提升**
- 9. **如何優化 ES 寫入性能**
- 10. **ES 集群腦裂問題**
- 11. **ES 底層如何執行文檔的更新和刪除**
- 12. **如何優化文檔評分**
- 13. **如何處理評分偏差**
- 14. **ES 聚合查詢、組合查詢**
- 15. **ES 深分頁問題**
- 16. **ES 如何實現滾動更新**
- 1. **ES 聚合優化**
- **優化策略**
- **示例:聚合性能提升**
- 2. **ES 中如何去重**
- **方法一:`cardinality` 聚合**
- **方法二:`terms` 聚合 + `size`**
- **注意事項**:
- 3. **ES 實現日志關聯查詢**
- **方法一:使用 `join` 字段(父子文檔)**
- **方法二:使用 `script` 關聯字段**
- 4. **ES 中的 ANN(近似最近鄰搜索)**
- **實現方式:KNN 插件(ES 8.x)**
- 5. **ES 創建只讀索引**
- **方法一:通過 API 設置**
- **方法二:通過索引生命周期管理(ILM)**
- 6. **ES 不同節點類型的區別**
- 7. **ES 中如何管理索引**
- **核心方法**
ES8
1 ES架構
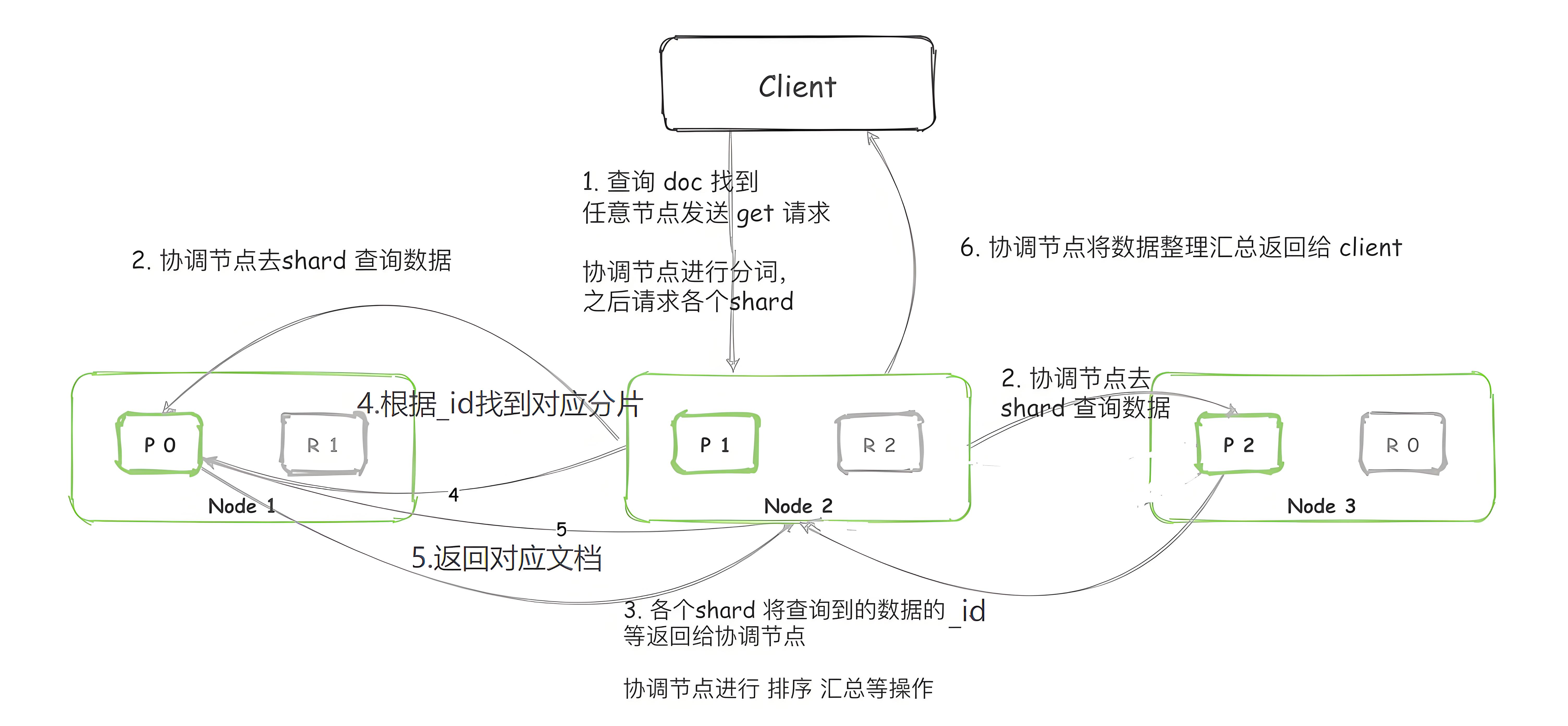
2 ES適用場景
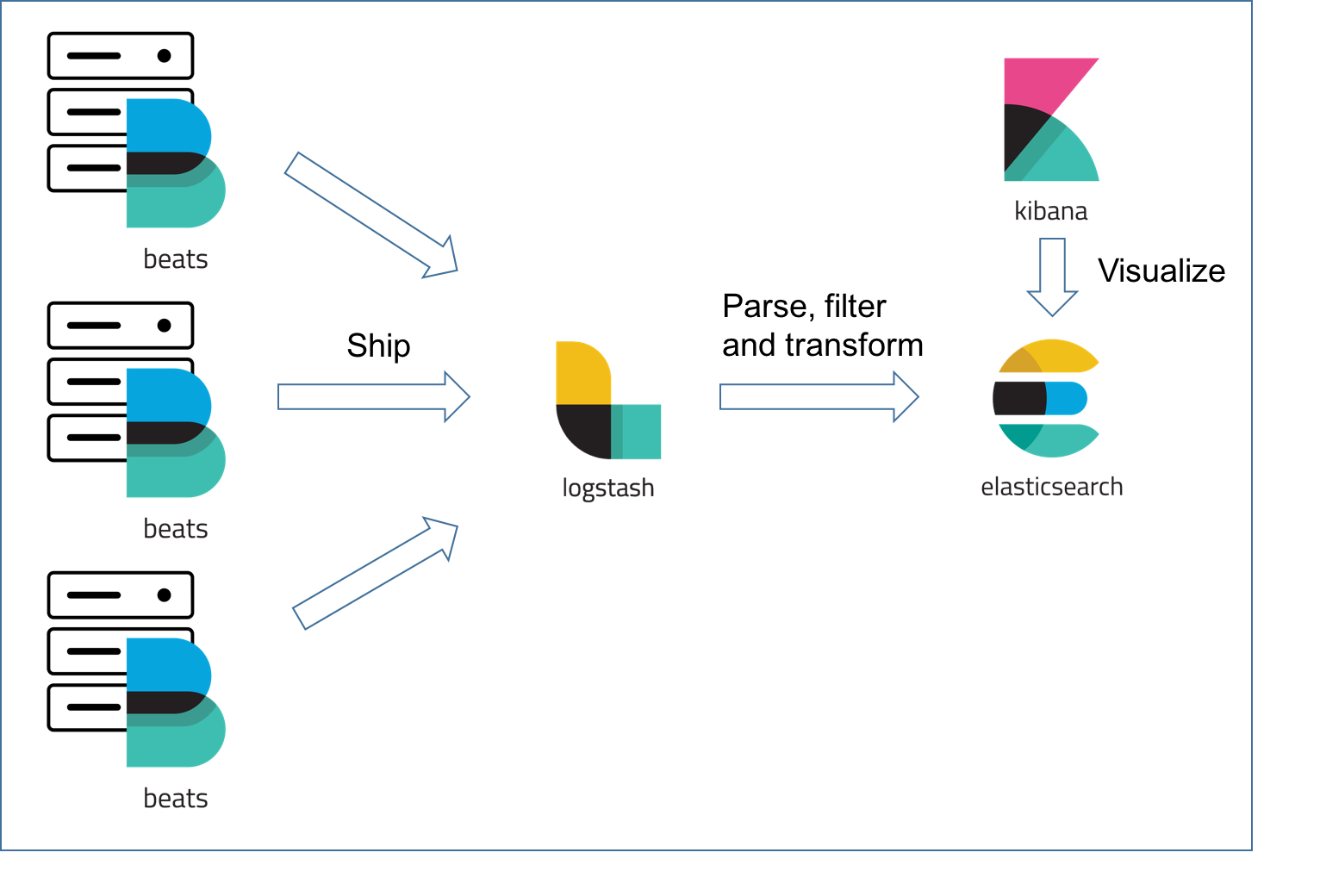
搭建日志系統
ELK套件日志系統應該是ElasticSearch使用最廣泛的場景之一了,ElasticSearch支持海量數據的存儲和查詢,特別適合日志搜索場景。廣泛使用的ELK套件(ElasticSearch、Logstash、Kibana)是日志系統最經典的案例,使用Logstash和Beats組件進行日志收集,ElasticSearch存儲和查詢應用日志,Kibana提供日志的可視化搜索界面。
搭建數據分析系統
Elasitcsearch支持數據分析,例如強大的數據聚合功能,通過搭配Kibana,提供諸如直方圖、統計分組、范圍聚合等方便使用的功能,能夠快速實現一些數據報表等功能。
在數字化轉型的大行其道的當下,需要從海量數據中發現數據的規律,從而做出一定的決策,ElasticSearch一定是最適合的解決方案之一。
搭建搜索系統
ElasticSearch為搜索而生,用于搭建全文搜索系統是自然而然的事情,它能夠提供快速的索引和搜索功能,還有相關的評分功能、分詞插件等,支持豐富的搜索特性,可以用于搭建大型的搜索引擎,更加常用語實現站內搜索,例如銀行App、購物App等站內商品、服務搜索。
構建海量數據業務系統即席查詢服務
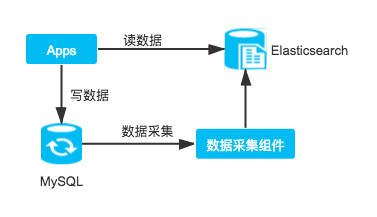
目前大量的需要支持事務的系統使用MySQL作為數據庫,但隨著業務的開展,數據量會越來越大,而MySQL的性能會越來越差,雖然可以通過分庫分表的方案進行解決,但是操作比較復雜,而且往往每隔一段時間就需要進行擴展,且代碼需要配合修改。
這種情況下可以將數據從MySQL同步到ElasticSearch,針對實時性要求不太高或者主要查詢歷史數據且數據量比較大的場景使用ElasticSearch提供查詢,而對需要事務實時控制的即時數據還是通過MySQL存儲和查詢。
作為獨立數據庫系統
ElasticSearch本身提供了數據持久化存儲的能力,并且提供了增刪改查的功能,在某些應用場景下可以直接當做數據庫系統來使用,既提供了存儲能力,又能夠同時具備搜索能力,整體技術架構會比較簡單,例如博客系統、評論系統。需要注意的是,ElasticSearch不支持事務,且寫入的性能相對關系型數據庫稍弱,所有需要使用事務的場景都不能將ElasticSearch當做唯一的數據庫系統,這使得這種使用場景很少見。
3 ES使用
3.1對比mysql
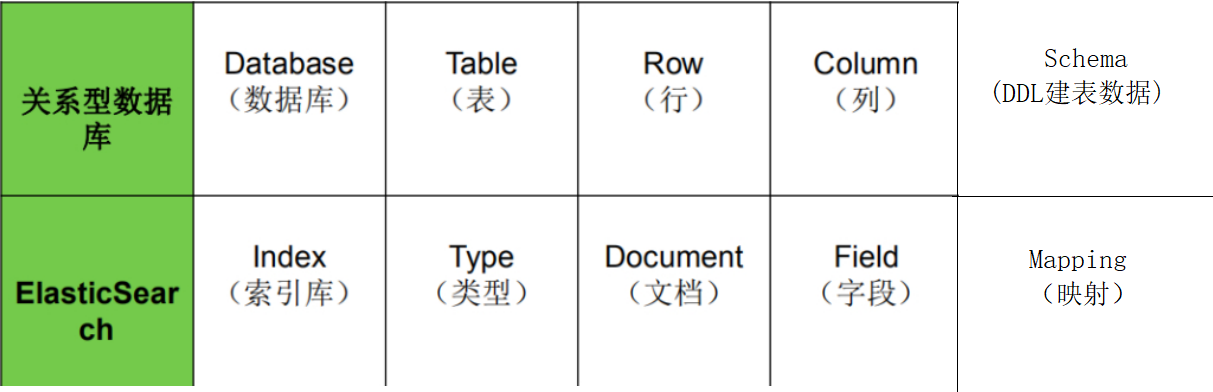
3.2 索引(Index)
一個索引就是一個擁有幾分相似特征的文檔的集合。比如說,你可以有一個客戶數據的索引,另一個產品目錄的索引,還有一個訂單數據的索引。一個索引由一個名字來標識(必須全部是小寫字母),并且當我們要對這個索引中的文檔進行索引、搜索、更新和刪除的時候,都要使用到這個名字。在一個集群中,可以定義任意多的索引。
能搜索的數據必須索引,這樣的好處是可以提高查詢速度,比如:新華字典前面的目錄就是索引的意思,目錄可以提高查詢速度。
ElasticSearch索引的精髓:一切設計都是為了提高搜索的性能。
3.3 類型(Type)
在一個索引中,你可以定義一種或多種類型。
一個類型是你的索引的一個邏輯上的分類/分區,其語義完全由你來定。通常,會為具有一組共同字段的文檔定義一個類型。不同的版本,類型發生了不同的變化
| 版本 | Type |
|---|---|
| 5.x | 支持多種type |
| 6.x | 只能有一種type |
| 7.x | 默認不再支持自定義索引類型(默認類型為:_doc) |
| 8.x | 默認類型為:_doc |
3.4 文檔(Document)
一個文檔是一個可被索引的基礎信息單元,也就是一條數據
比如:你可以擁有某一個客戶的文檔,某一個產品的一個文檔,當然,也可以擁有某個訂單的一個文檔。文檔以JSON(Javascript Object Notation)格式來表示,而JSON是一個到處存在的互聯網數據交互格式。
在一個index/type里面,你可以存儲任意多的文檔。
3.5 字段(Field)
相當于是數據表的字段,對文檔數據根據不同屬性進行的分類標識。
3.6 映射(Mapping)
mapping是處理數據的方式和規則方面做一些限制,如:某個字段的數據類型、默認值、分析器、是否被索引等等。這些都是映射里面可以設置的,其它就是處理ES里面數據的一些使用規則設置也叫做映射,按著最優規則處理數據對性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能對性能更好。
4 ElasticSearch 基礎功能
參考文檔:https://www.elastic.co/guide/en/ElasticSearch/reference/8.5/ElasticSearch-intro.html
我們在Kibana(前面已經安裝過) 軟件給大家演示基本操作
詳見《軟件環境安裝》
4.1 分詞器
官方提供的分詞器有這么幾種: Standard、Letter、Lowercase、Whitespace、UAX URL Email、Classic、Thai等,中文分詞器可以使用第三方的比如IK分詞器。前面我們已經安裝過了。
IK分詞器:
POST _analyze
{"analyzer": "ik_smart","text": "我是中國人"
}
結果:
{"tokens": [{"token": "我","start_offset": 0,"end_offset": 1,"type": "CN_CHAR","position": 0},{"token": "是","start_offset": 1,"end_offset": 2,"type": "CN_CHAR","position": 1},{"token": "中國人","start_offset": 2,"end_offset": 5,"type": "CN_WORD","position": 2}]
}POST _analyze
{"analyzer": "ik_max_word","text": "我是中國人"
}
結果:
{"tokens": [{"token": "我","start_offset": 0,"end_offset": 1,"type": "CN_CHAR","position": 0},{"token": "是","start_offset": 1,"end_offset": 2,"type": "CN_CHAR","position": 1},{"token": "中國人","start_offset": 2,"end_offset": 5,"type": "CN_WORD","position": 2},{"token": "中國","start_offset": 2,"end_offset": 4,"type": "CN_WORD","position": 3},{"token": "國人","start_offset": 3,"end_offset": 5,"type": "CN_WORD","position": 4}]
}
Standard分詞器:
POST _analyze
{"analyzer": "standard","text": "我是中國人"
}結果:
{"tokens": [{"token": "我","start_offset": 0,"end_offset": 1,"type": "<IDEOGRAPHIC>","position": 0},{"token": "是","start_offset": 1,"end_offset": 2,"type": "<IDEOGRAPHIC>","position": 1},{"token": "中","start_offset": 2,"end_offset": 3,"type": "<IDEOGRAPHIC>","position": 2},{"token": "國","start_offset": 3,"end_offset": 4,"type": "<IDEOGRAPHIC>","position": 3},{"token": "人","start_offset": 4,"end_offset": 5,"type": "<IDEOGRAPHIC>","position": 4}]
}
4.2 索引操作
ES 軟件的索引可以類比為 MySQL 中表的概念,創建一個索引,類似于創建一個表
所有RestFul風格API不用記憶,知道每個接口作用即可,會查詢官方文檔:https://www.elastic.co/guide/index.html
- RestFul文檔:https://www.elastic.co/guide/en/elastic-stack/8.5/index.html
4.2.1 創建索引
語法: PUT /{索引名稱}
PUT /my_index結果:
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "my_index"
}
4.2.2 查看所有索引
GET /_cat/indices?v
4.2.3 查看單個索引
語法: GET /{索引名稱}
GET /my_index
結果:
{"my_index": {"aliases": {},"mappings": {},"settings": {"index": {"routing": {"allocation": {"include": {"_tier_preference": "data_content"}}},"number_of_shards": "1","provided_name": "my_index","creation_date": "1693294063006","number_of_replicas": "1","uuid": "kYMuXUZQRumMGqHoV0fDJw","version": {"created": "8050099"}}}}
}
4.2.4 刪除索引
語法: DELETE /{索引名稱}
DELETE /my_index
結果:
{"acknowledged" : true
}
4.3 文檔操作
文檔是 ES 軟件搜索數據的最小單位, 不依賴預先定義的模式,所以可以將文檔類比為表的一行JSON類型的數據。我們知道關系型數據庫中,要提前定義字段才能使用,在ElasticSearch中,對于字段是非常靈活的,有時候我們可以忽略該字段,或者動態的添加一個新的字段。
4.3.1 創建文檔
語法:
PUT /{索引名稱}/{類型}/{id}
{
jsonbody
}
在創建數據時,需要指定唯一性標識,那么請求范式 POST,PUT 都可以
PUT /my_index/_doc/1
{"title": "小米手機","brand": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 3999
}返回結果:
{"_index": "my_index","_id": "1","_version": 3,"_seq_no": 2,"_primary_term": 1,"found": true,"_source": {"title": "小米手機","brand": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 3999}
}
4.3.2 查看文檔
語法:GET /{索引名稱}/{類型}/{id}
GET /my_index/_doc/1
結果:
{"_index" : "my_index","_type" : "_doc","_id" : "1","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true,"_source" : {"title" : "小米手機","brand" : "小米","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 3999}
}
4.3.3 查詢所有文檔
語法: GET /{索引名稱}/_search
GET /my_index/_search結果:
{"took": 941,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 1,"hits": [{"_index": "my_index","_id": "1","_score": 1,"_source": {"title": "小米手機","brand": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 3999}}]}
}
4.3.4 修改文檔
語法:
PUT /{索引名稱}/{類型}/{id}
{
jsonbody
}
PUT /my_index/_doc/1
{"title": "小米手機","brand": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 4500
}
4.3.5 修改局部屬性
語法:
POST /{索引名稱}/_update/{docId}
{
“doc”: {
“屬性”: “值”
}
}
注意:這種更新只能使用post方式。
POST /my_index/_update/1
{"doc": {"price": 4500}
}
4.3.6 刪除文檔
語法: DELETE /{索引名稱}/{類型}/{id}
DELETE /my_index/_doc/1
結果:
{"_index": "my_index","_id": "1","_version": 5,"result": "deleted","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 6,"_primary_term": 1
}
4.4 映射mapping
創建數據庫表需要設置字段名稱,類型,長度,約束等;索引庫也一樣,需要知道這個類型下有哪些字段,每個字段有哪些約束信息,這就叫做映射(mapping)。
4.4.1 查看映射
語法: GET /{索引名稱}/_mapping
GET /my_index/_mapping
結果:
{"my_index": {"mappings": {"properties": {"brand": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"images": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"price": {"type": "long"},"title": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}}}
}
4.4.2 動態映射
在關系數據庫中,需要事先創建數據庫,然后在該數據庫下創建數據表,并創建 表字段、類型、長度、主鍵等,最后才能基于表插入數據。而ElasticSearch中不 需要定義Mapping映射(即關系型數據庫的表、字段等),在文檔寫入 ElasticSearch時,會根據文檔字段自動識別類型,這種機制稱之為動態映射。
映射規則對應:
| 數據 | 對應的類型 |
|---|---|
| null | 字段不添加 |
| true|flase | boolean |
| 字符串 | text/keyword |
| 數值 | long |
| 小數 | float |
| 日期 | date |
特殊類型:字符串
- text:用于長文本,對本文內容進行分詞(產生倒排索引文檔列表),支持多關鍵字全文查詢。例如:電商項目中商品名稱,或者博客項目文章標題,正文設置為text 缺點:不能進行聚合(分組),不支持排序。
- keyword:用于詞條精確查詢,支持等值查詢,不需要進行分詞字符串(分詞后無意義)。例如:用戶昵稱、用戶手機號、身份證號、圖片地址。場景:根據品牌名稱等值查詢。支持聚合(分組)、排序 不支持全文查詢查詢
4.4.3 靜態映射(推薦)
靜態映射是在ElasticSearch中也可以事先定義好映射,即手動映射,包含文檔的各字段類型、分詞器等,這稱為靜態映射。
字符串進行全文查詢(多關鍵字模糊查詢):需要對字段值進行分詞(中文分詞器),查詢分詞器,指定為text
字符串進行等值查詢:指定為keyword
#刪除原創建的索引
DELETE /my_index#創建索引,并同時指定映射關系和分詞器等。
PUT /my_index
{"mappings": {"properties": {"title": {"type": "text","index": true,"store": true,"analyzer": "ik_max_word","search_analyzer": "ik_smart"},"brand": { "type": "keyword","index": true,"store": true},"images": {"type": "keyword","index": false,"store": true},"price": {"type": "integer","index": true,"store": true}}}
}結果:
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "my_index"
}
type分類如下:
- 字符串:text(支持分詞)和 keyword(不支持分詞)。
- text:該類型被用來索引長文本,在創建索引前會將這些文本進行分詞,轉化為詞的組合,建立索引;允許es來檢索這些詞,text類型不能用來排序和聚合。
- keyword:該類型不能分詞,可以被用來檢索過濾、排序和聚合,keyword類型不可用text進行分詞模糊檢索。
- 數值型:long、integer、short、byte、double、float
- 日期型:date
- 布爾型:boolean
4.4.4 nested 介紹
nested:類型是一種特殊的對象object數據類型(specialised version of the object datatype ),允許對象數組彼此獨立地進行索引和查詢。
demo: 建立一個普通的index
如果linux 中有這個my_comment_index 先刪除!DELETE /my_comment_index
步驟1:建立一個索引( 存儲博客文章及其所有評論)
PUT my_comment_index/_doc/1
{"title": "狂人日記","body": "《狂人日記》是一篇象征性和寓意很強的小說,當時,魯迅對中國國民精神的麻木愚昧頗感痛切。","comments": [{"name": "張三","age": 34,"rating": 8,"comment": "非常棒的文章","commented_on": "30 Nov 2023"},{"name": "李四","age": 38,"rating": 9,"comment": "文章非常好","commented_on": "25 Nov 2022"},{"name": "王五","age": 33,"rating": 7,"comment": "手動點贊","commented_on": "20 Nov 2021"}]
}
如上所示,所以我們有一個文檔描述了一個帖子和一個包含帖子上所有評論的內部對象評論。
但是ElasticSearch搜索中的內部對象并不像我們期望的那樣工作。
步驟2 : 執行查詢
GET /my_comment_index/_search
{"query": {"bool": {"must": [{"match": {"comments.name": "李四"}},{"match": {"comments.age": 34}}]}}
}查詢結果正常的響應
原因分析:comments字段默認的數據類型是Object,故我們的文檔內部存儲為:
{
“title”: [ 狂人日記],
“body”: [ 《狂人日記》是一篇象征性和寓意很強的小說,當時… ],
“comments.name”: [ 張三, 李四, 王五 ],
“comments.comment”: [ 非常棒的文章,文章非常好,王五,… ],
“comments.age”: [ 33, 34, 38 ],
“comments.rating”: [ 7, 8, 9 ]
}
我們可以清楚地看到,comments.name和comments.age之間的關系已丟失。這就是為什么我們的文檔匹配李四和34的查詢。
步驟3:刪除當前索引
DELETE /my_comment_index
步驟4:建立一個nested 類型的(comments字段映射為nested類型,而不是默認的object類型)
PUT my_comment_index
{"mappings": {"properties": {"comments": {"type": "nested" }}}
}PUT my_comment_index/_doc/1
{"title": "狂人日記","body": "《狂人日記》是一篇象征性和寓意很強的小說,當時,魯迅對中國國民精神的麻木愚昧頗感痛切。","comments": [{"name": "張三","age": 34,"rating": 8,"comment": "非常棒的文章","commented_on": "30 Nov 2023"},{"name": "李四","age": 38,"rating": 9,"comment": "文章非常好","commented_on": "25 Nov 2022"},{"name": "王五","age": 33,"rating": 7,"comment": "手動點贊","commented_on": "20 Nov 2021"}]
}
重新執行步驟1,使用nested 查詢
GET /my_comment_index/_search
{"query": {"nested": {"path": "comments","query": {"bool": {"must": [{"match": {"comments.name": "李四"}},{"match": {"comments.age": 34}}]}}}}
}
結果發現沒有返回任何的文檔,這是何故?
當將字段設置為nested 嵌套對象將數組中的每個對象索引為單獨的隱藏文檔,這意味著可以獨立于其他對象查詢每個嵌套對象。文檔的內部表示:
{
{
“comments.name”: [ 張三],
“comments.comment”: [ 非常棒的文章 ],
“comments.age”: [ 34 ],
“comments.rating”: [ 9 ]
},
{
“comments.name”: [ 李四],
“comments.comment”: [ 文章非常好 ],
“comments.age”: [ 38 ],
“comments.rating”: [ 8 ]
},
{
“comments.name”: [ 王五],
“comments.comment”: [手動點贊],
“comments.age”: [ 33 ],
“comments.rating”: [ 7 ]
},
{
“title”: [ 狂人日記 ],
“body”: [ 《狂人日記》是一篇象征性和寓意很強的小說,當時,魯迅對中國… ]
}
}
每個內部對象都在內部存儲為單獨的隱藏文檔。 這保持了他們的領域之間的關系。
5 DSL高級查詢
5.1 DSL概述
本質調用ES提供檢索數據restful接口
Query DSL概述: Domain Specific Language(領域專用語言),ElasticSearch提供了基于JSON的DSL來定義查詢。
創建索引庫設置好映射:
#創建索引,并同時指定映射關系和分詞器等。
PUT /my_index
{"mappings": {"properties": {"title": {"type": "text","index": true,"store": true,"analyzer": "ik_max_word","search_analyzer": "ik_smart"},"brand": { "type": "keyword","index": true,"store": true},"images": {"type": "keyword","index": false,"store": true},"price": {"type": "integer","index": true,"store": true}}}
}
準備數據:
PUT /my_index/_doc/1
{"id":1,"title":"華為筆記本電腦","brand":"華為","images":"http://www.gulixueyuan.com/xm.jpg","price":5388}PUT /my_index/_doc/2
{"id":2,"title":"華為手機","brand":"華為","images":"http://www.gulixueyuan.com/xm.jpg","price":5500}PUT /my_index/_doc/3
{"id":3,"title":"VIVO手機","brand":"vivo","images":"http://www.gulixueyuan.com/xm.jpg","price":3600}
5.2 DSL查詢
5.2.1 查詢所有文檔
match_all:
POST /my_index/_search
{"query": {"match_all": {}}
}結果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"id" : 1,"title" : "華為筆記本電腦","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5388}},{"_index" : "my_index","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"id" : 2,"title" : "華為手機","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5500}},{"_index" : "my_index","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"id" : 3,"title" : "VIVO手機","brand" : "vivo","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 3600}}]}
}
5.2.2 匹配查詢(match)
match:
POST /my_index/_search
{"query": {"match": {"title": "華為智能手機"}}
}結果:
{"took" : 3,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 0.5619608,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "2","_score" : 0.5619608,"_source" : {"id" : 2,"title" : "華為手機","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5500}},{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : 0.35411233,"_source" : {"id" : 1,"title" : "華為筆記本電腦","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5388}}]}
}5.2.3 多字段匹配
POST /my_index/_search
{"query": {"multi_match": {"query": "華為智能手機","fields": ["title","brand"]}}
}結果:
{"took" : 3,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 0.5619608,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "2","_score" : 0.5619608,"_source" : {"id" : 2,"title" : "華為手機","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5500}},{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : 0.35411233,"_source" : {"id" : 1,"title" : "華為筆記本電腦","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5388}}]}
}5.2.4 關鍵字精確查詢
term:關鍵字不會進行分詞。
POST /my_index/_search
{"query": {"term": {"title": {"value": "華為手機"}}}
}結果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]}
}
5.2.6 多關鍵字精確查詢
POST /my_index/_search
{"query": {"terms": {"title": ["華為手機","華為"]}}
}結果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"id" : 1,"title" : "華為筆記本電腦","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5388}},{"_index" : "my_index","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"id" : 2,"title" : "華為手機","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5500}}]}
}
5.2.7 范圍查詢
范圍查詢使用range。
- gte: 大于等于
- lte: 小于等于
- gt: 大于
- lt: 小于
POST /my_index/_search
{"query": {"range": {"price": {"gte": 3000,"lte": 5000}}}
}
結果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"title" : "VIVO手機","brand" : "vivo"}}]}
}5.2.8 指定返回字段
query同級增加_source進行過濾。
POST /my_index/_search
{"query": {"terms": {"title": ["華為手機","華為"]}},"_source": ["title","brand"]
}
5.2.9 組合查詢
bool 各條件之間有and,or或not的關系
- must: 各個條件都必須滿足,所有條件是and的關系
- should: 各個條件有一個滿足即可,即各條件是or的關系
- must_not: 不滿足所有條件,即各條件是not的關系
- filter: 與must效果等同,但是它不計算得分,效率更高點。
must
POST /my_index/_search
{"query": {"bool": {"must": [{"match": {"title": "華為"}},{"range": {"price": {"gte": 3000,"lte": 5400}}}]}}
}
結果:
{"took": 1,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 1.2923405,"hits": [{"_index": "my_index","_id": "1","_score": 1.2923405,"_source": {"id": 1,"title": "華為筆記本電腦","brand": "華為","images": "http://www.gulixueyuan.com/xm.jpg","price": 5388}}]}
}
should
POST /my_index/_search
{"query": {"bool": {"should": [{"match": {"title": "華為"}},{"range": {"price": {"gte": 3000,"lte": 5000}}}]}}
}結果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"id" : 3,"title" : "VIVO手機","brand" : "vivo","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 3600}},{"_index" : "my_index","_type" : "_doc","_id" : "2","_score" : 0.5619608,"_source" : {"id" : 2,"title" : "華為手機","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5500}},{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : 0.35411233,"_source" : {"id" : 1,"title" : "華為筆記本電腦","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5388}}]}
}如果should和must同時存在,他們之間是and關系:
POST /my_index/_search
{"query": {"bool": {"should": [{"match": {"title": "華為"}},{"range": {"price": {"gte": 3000,"lte": 5000}}}],"must": [{"match": {"title": "華為"}},{"range": {"price": {"gte": 3000,"lte": 5000}}}]}}
}結果:
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]}
}must_not
POST /my_index/_search
{"query": {"bool": {"must_not": [{"match": {"title": "華為"}},{"range": {"price": {"gte": 3000,"lte": 5000}}}]}}
}
結果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]}
}
filter
_score的分值為0
POST /my_index/_search
{"query": {"bool": {"filter": [{"match": {"title": "華為"}}]}}
}結果:
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 0.0,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : 0.0,"_source" : {"id" : 1,"title" : "華為筆記本電腦","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5388}},{"_index" : "my_index","_type" : "_doc","_id" : "2","_score" : 0.0,"_source" : {"id" : 2,"title" : "華為手機","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5500}}]}
}
5.2.10 聚合查詢
聚合允許使用者對es文檔進行統計分析,類似與關系型數據庫中的group by,當然還有很多其他的聚合,例如取最大值、平均值等等。
聚合三要素:聚合名稱(給不同聚合業務其名稱-用于解析結果)、聚合字段(對哪個字段進行分組)、聚合類型(如何聚合-常見:字段值相同放在一組)
max
POST /my_index/_search
{"query": {"match_all": {}},"size": 0, "aggs": {"max_price": {"max": {"field": "price"}}}
}結果:
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"max_price" : {"value" : 5500.0}}
}min
POST /my_index/_search
{"query": {"match_all": {}},"size": 0, "aggs": {"min_price": {"min": {"field": "price"}}}
}結果:
{"took" : 12,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"max_price" : {"value" : 3600.0}}
}
avg
POST /my_index/_search
{"query": {"match_all": {}},"size": 0, "aggs": {"avg_price": {"avg": {"field": "price"}}}
}
結果:
{"took" : 12,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"avg_price" : {"value" : 4829.333333333333}}
}
sum
POST /my_index/_search
{"query": {"match_all": {}},"size": 0, "aggs": {"sum_price": {"sum": {"field": "price"}}}
}
結果:
{"took" : 3,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"sum_price" : {"value" : 14488.0}}
}
stats
POST /my_index/_search
{"query": {"match_all": {}},"size": 0, "aggs": {"stats_price": {"stats": {"field": "price"}}}
}
結果:
{"took" : 20,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"stats_price" : {"count" : 3,"min" : 3600.0,"max" : 5500.0,"avg" : 4829.333333333333,"sum" : 14488.0}}
}
terms
桶聚合相當于sql中的group by語句
POST /my_index/_search
{"query": {"match_all": {}},"size": 0, "aggs": {"groupby_brand": {"terms": {"field": "brand","size": 10}}}
}
結果:
{"took" : 16,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"groupby_brand" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "華為","doc_count" : 2},{"key" : "vivo","doc_count" : 1}]}}
}
還可以對桶繼續下鉆:
POST /my_index/_search
{"query": {"match_all": {}},"size": 0, "aggs": {"groupby_brand": {"terms": {"field": "brand","size": 10},"aggs": {"avg_price": {"avg": {"field": "price"}}}}}
}
結果:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"groupby_brand" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "華為","doc_count" : 2,"avg_price" : {"value" : 5444.0}},{"key" : "vivo","doc_count" : 1,"avg_price" : {"value" : 3600.0}}]}}
}
5.2.11 排序
POST /my_index/_search
{"query": {"bool": {"must": [{"match": {"title": "華為"}}]}},"sort": [{"price": {"order": "asc"}},{"_score": {"order": "desc"}}]
}
結果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : 0.35411233,"_source" : {"id" : 1,"title" : "華為筆記本電腦","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5388},"sort" : [5388,0.35411233]},{"_index" : "my_index","_type" : "_doc","_id" : "2","_score" : 0.5619608,"_source" : {"id" : 2,"title" : "華為手機","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5500},"sort" : [5500,0.5619608]}]}
}5.2.12 分頁查詢
分頁的兩個關鍵屬性:from、size。
- from: 當前頁的起始索引,默認從0開始。 from = (pageNum - 1) * size
- size: 每頁顯示多少條
POST /my_index/_search
{"query": {"match_all": {}},"from": 0,"size": 2
}
結果:
{"took" : 3,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"id" : 1,"title" : "華為筆記本電腦","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5388}},{"_index" : "my_index","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"id" : 2,"title" : "華為手機","brand" : "華為","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 5500}}]}
}
5.2.13 高亮
高亮三要素:
- 高亮字段
- 高亮前置標簽(HTML標簽)
- 高亮后置標簽(HTML標簽)
根據關鍵詞查詢商品
#高亮 必須要求用戶錄入關鍵字
GET my_index/_search
{"query": {"match": {"title": "華為 手機"}},"highlight": {"fields": {"title": {}},"pre_tags": "<font style='color:red'>","post_tags": "</font>"}
}
結果:
{"took": 96,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 4,"relation": "eq"},"max_score": 1.2155836,"hits": [{"_index": "my_index","_id": "2","_score": 1.2155836,"_source": {"id": 2,"title": "華為手機","brand": "華為","images": "http://www.gulixueyuan.com/xm.jpg","price": 5500},"highlight": {"title": ["<font style='color:red'>華為</font><font style='color:red'>手機</font>"]}},{"_index": "my_index","_id": "1","_score": 0.49191093,"_source": {"id": 1,"title": "華為筆記本電腦","brand": "華為","images": "http://www.gulixueyuan.com/xm.jpg","price": 5388},"highlight": {"title": ["<font style='color:red'>華為</font>筆記本電腦"]}},{"_index": "my_index","_id": "3","_score": 0.41299206,"_source": {"id": 3,"title": "VIVO手機","brand": "vivo","images": "http://www.gulixueyuan.com/xm.jpg","price": 3600},"highlight": {"title": ["VIVO<font style='color:red'>手機</font>"]}},{"_index": "my_index","_id": "4","_score": 0.41299206,"_source": {"id": 3,"title": "OPPO手機","brand": "oppo","images": "http://www.gulixueyuan.com/xm.jpg","price": 5500},"highlight": {"title": ["OPPO<font style='color:red'>手機</font>"]}}]}
}
6 Java Api操作ES
6.1 ElasticSearch Java API Client
官方文檔:https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/8.5/_getting_started.html
6.1.1 搭建項目
1、創建項目:elasticSearch_demo
2、導入pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.atguigu</groupId><artifactId>ElasticSearch_demo</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>co.elastic.clients</groupId><artifactId>elasticsearch-java</artifactId><version>8.5.3</version></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.12.3</version></dependency><dependency><groupId>jakarta.json</groupId><artifactId>jakarta.json-api</artifactId><version>2.0.1</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13.2</version><scope>test</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.30</version></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>
6.1.2 配置連接
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch.core.*;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import com.atguigu.demo.Goods;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.elasticsearch.client.RestClient;
import org.junit.Before;
import org.junit.Test;import java.io.IOException;public class DocumentCurdTest {ElasticsearchClient client = null;@Beforepublic void initElasticsearchClient() {BasicCredentialsProvider credsProv = new BasicCredentialsProvider();credsProv.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials("elastic", "111111"));RestClient restClient = RestClient.builder(HttpHost.create("http://192.168.200.6:9200")).setHttpClientConfigCallback(hc -> hc.setDefaultCredentialsProvider(credsProv)).build();// Create the transport with a Jackson mapperRestClientTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());// And create the API clientclient = new ElasticsearchClient(transport);}
}
6.1.3 實體類
package com.atguigu.elasticSearch_demo.model;import lombok.Data;@Data
public class Goods {private String id;private String title;private String images;private String brand;private Integer price;
}
6.1.3 測試查詢
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch.core.*;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import com.atguigu.demo.Goods;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.elasticsearch.client.RestClient;
import org.junit.Before;
import org.junit.Test;import java.io.IOException;public class DocumentCurdTest {ElasticsearchClient client = null;@Beforepublic void initElasticsearchClient() {BasicCredentialsProvider credsProv = new BasicCredentialsProvider();credsProv.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials("elastic", "111111"));RestClient restClient = RestClient.builder(HttpHost.create("http://192.168.200.6:9200")).setHttpClientConfigCallback(hc -> hc.setDefaultCredentialsProvider(credsProv)).build();// Create the transport with a Jackson mapperRestClientTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());// And create the API clientclient = new ElasticsearchClient(transport);}private static final String INDEX_NAME = "my_index";/*** 文檔新增* Lambda表達式寫法 : 通過XxxRqeustBuilder對象.build方法 產生XxxReqeust對象簡化過程*/@Testpublic void saveDoc() throws IOException {//1.準備保存文檔對象GoodsGoods goods = new Goods();goods.setTitle("華為meta50手機");goods.setBrand("華為");goods.setId(3);goods.setPrice(19999);//2.調用客戶端對象新增文檔 - 采用lambda表達式寫法IndexResponse response = client.index(i -> i.index(INDEX_NAME) //指定索引庫名稱.id(goods.getId().toString()) //文檔主鍵 _id.document(goods) //文檔對象);System.out.println(response);//2.調用客戶端對象新增文檔 - 傳統寫法IndexRequest.Builder<Goods> goodsBuilder = new IndexRequest.Builder<>();goodsBuilder.index(INDEX_NAME);goodsBuilder.id(goods.getId().toString());goodsBuilder.document(goods);//IndexResponse response1 = client.index(goodsBuilder.build());//System.out.println(response1);}@Testpublic void testGetDoc() throws IOException {//GetRequest.Builder builder = new GetRequest.Builder();//builder.index(INDEX_NAME);//builder.id("1");//GetResponse<Goods> response = client.get(builder.build(), Goods.class);//Goods source = response.source();//System.out.println(source);GetResponse<Goods> goodsGetResponse = client.get(g -> g.index(INDEX_NAME).id("1"), Goods.class);System.out.println(goodsGetResponse.source());}/*** 刪除文檔* @throws IOException*/@Testpublic void testDeleteDoc() throws IOException {//DeleteRequest.Builder builder = new DeleteRequest.Builder();//builder.index(INDEX_NAME);//builder.id("1");//DeleteResponse response = client.delete(builder.build());//System.out.println(response);System.out.println(client.delete(d -> d.index(INDEX_NAME).id("2")));}
}
6.2 Spring Data ElasticSearch
官方文檔:https://spring.io/projects/spring-data-elasticsearch
Spring Data是一個用于簡化數據庫、非關系型數據庫、索引庫訪問,并支持云服務的開源框架。其主要目標是使得對數據的訪問變得方便快捷。 Spring Data可以極大的簡化JPA(ElasticSearch…)的寫法,可以在幾乎不用寫實現的情況下,實現對數據的訪問和操作。除了CRUD外,還包括如分頁、排序等一些常用的功能。
Spring Data ElasticSearch 基于 spring data API 簡化 ElasticSearch操作,將原始操作ElasticSearch的客戶端API 進行封裝 。Spring Data為ElasticSearch項目提供集成搜索引擎。Spring Data ElasticSearch POJO的關鍵功能區域為中心的模型與Elastichsearch交互文檔和輕松地編寫一個存儲索引庫數據訪問層。
6.2.1 搭建項目
1、創建項目:elasticSearch_demo_springdata_es
2、導入pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.atguigu</groupId><artifactId>elasticSearch_demo_springdata_es</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.0.5</version><relativePath/> <!-- lookup parent from repository --></parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build>
</project>
3、啟動類、配置文件
package com.atguigu;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;/*** @author: atguigu* @create: 2023-12-12 15:07*/
@SpringBootApplication
public class SpringDataESDemoApp {public static void main(String[] args) {SpringApplication.run(SpringDataESDemoApp.class, args);}
}
application.yml
spring:elasticsearch:uris: http://192.168.200.6:9200username: elasticpassword: 111111
6.2.2 document映射
package com.atguigu.model;import lombok.Data;
import org.springframework.data.elasticsearch.annotations.Document;/*** @author: atguigu* @create: 2024-08-07 14:21*/
@Data
@Document(indexName = "my_index")
public class Goods {private Integer id;private String title;private String images;private String brand;private int price;
}
映射
Spring Data通過注解來聲明字段的映射屬性,有下面的三個注解:
@Document 作用在類,標記實體類為文檔對象, indexName:對應索引庫名稱
@Id 作用在成員變量,標記一個字段作為id主鍵
@Field 作用在成員變量,標記為文檔的字段,并指定字段映射屬性:
type:字段類型,取值是枚舉:FieldType
index:是否索引,布爾類型,默認是true
store:是否存儲,布爾類型,默認是false
analyzer:分詞器名稱:ik_max_word
package com.atguigu.repository;import com.atguigu.model.Goods;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;/*** SpringData會自動掃描繼承自*Repository接口產生代理對象*/
public interface GoodsRepository extends ElasticsearchRepository<Goods, Integer> {
}啟動項目,自動新增索引庫
6.2.3 測試查詢
引入spring-boot-starter-data-ElasticSearch后,添加配置文件,springboot會自動配置es連接
package com.atguigu;import co.elastic.clients.elasticsearch.ElasticsearchClient;
import com.atguigu.model.Goods;
import com.atguigu.repository.GoodsRepository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.elasticsearch.client.elc.ElasticsearchTemplate;import java.io.IOException;
import java.util.Optional;import static org.junit.jupiter.api.Assertions.*;@SpringBootTest
class SpringDataESDemoAppTest {@Autowiredprivate GoodsRepository goodsRepository;@Testpublic void testRepository(){Goods goods = new Goods();goods.setId(6);goods.setBrand("小米");goods.setTitle("小米16最新上市-全新旗艦手機");goods.setPrice(7777);//goodsRepository.save(goods);//goodsRepository.save(goods);//Optional<Goods> optional = goodsRepository.findById(6);//if(optional.isPresent()){// Goods goods1 = optional.get();// System.out.println(goods1);//}//for (Goods goods1 : goodsRepository.findAll()) {// System.out.println(goods1);//}goodsRepository.deleteById(6);}
}
6.2.4 模板對象測試
@SpringBootTest
class SpringDataESDemoAppTest {@Autowiredprivate ElasticsearchTemplate elasticsearchTemplate;@Testpublic void testTempalte(){//Goods goods = elasticsearchTemplate.get("3", Goods.class);//System.out.println(goods);Goods goods = new Goods();goods.setId(6);goods.setBrand("小米");goods.setTitle("小米16最新上市");goods.setPrice(66666);//elasticsearchTemplate.save(goods);//elasticsearchTemplate.update(goods);elasticsearchTemplate.delete("6", Goods.class);}
}
總結:簡單查詢與創建索引及映射推薦使用Spring Data ElasticSearch Api;復雜查詢使用ElasticSearch Java API Client,結合使用,方便開發
ES插件
騰訊云es服務提供的插件列表
Elasticsearch 提供了豐富的插件系統,允許用戶擴展其功能。以下是 Elasticsearch 8.x 中一些常用的插件以及它們的基本用法:
1. Ingest Node 插件
- 描述:用于在數據被索引之前進行處理。
- 示例插件:
ingest-user-agent:解析 User-Agent 字符串。- 使用方法:
# 安裝插件 bin/elasticsearch-plugin install ingest-user-agent# 使用示例 PUT _ingest/pipeline/user_agent {"description": "Add user agent information","processors": [{"user_agent": {"field": "agent"}}] }POST my-index/_doc?pipeline=user_agent {"agent": "Mozilla/5.0..." }
2. Analysis Plugins(分析插件)
- 描述:提供額外的分詞器、過濾器等文本分析工具。
- 示例插件:
analysis-icu:提供了基于 ICU 庫的 Unicode 支持。- 使用方法:
# 安裝插件 bin/elasticsearch-plugin install analysis-icu# 在索引設置中使用 PUT my_index {"settings": {"analysis": {"analyzer": {"my_icu_analyzer": {"type": "icu_analyzer"}}}} }
3. Repository Plugins(倉庫插件)
- 描述:支持將快照存儲到不同的存儲系統中。
- 示例插件:
repository-s3:允許將快照存儲到 Amazon S3 中。- 使用方法:
# 安裝插件 bin/elasticsearch-plugin install repository-s3# 配置并創建倉庫 PUT _snapshot/my_s3_repository {"type": "s3","settings": {"bucket": "my_bucket","region": "us-west"} }
4. Discovery Plugins(發現插件)
- 描述:改變集群節點發現機制。
- 示例插件:
discovery-ec2:適用于 AWS 環境下的自動發現。- 使用方法:
# 安裝插件 bin/elasticsearch-plugin install discovery-ec2# 配置文件中添加必要的配置項 discovery.ec2.tag.my_tag: my_value
5. Alerting and Monitoring Plugins(監控和告警插件)
- 描述:提供對集群健康狀態的監控及異常情況的通知功能。
- 示例插件:
- X-Pack(現已被集成至默認發行版中,但需要單獨啟用相關功能)。
- 使用方法:
啟用后可通過 Kibana 進行管理,或者直接通過 REST API 設置監控規則。
注意事項
- 在安裝任何插件之前,請確保它與你的 Elasticsearch 版本兼容。
- 某些插件可能需要重啟 Elasticsearch 實例才能生效。
- 對于生產環境,在安裝新插件前最好先在測試環境中驗證其兼容性和性能影響。
ES部分場景八股回答重點
如何在es中設計實現多層次緩存
- 訪問模式
- es自帶緩存
- 緩存中間件(Memcached)
- 數據分層
- 索引優化
2es如何實現分布式事務
- 消息隊列(kafka)
- 雙寫架構(2pc)
- 分布式事務協調(saga)
- 擴展ecs
3.Finite State Transducer是什么?有什么用
- 有限狀態機
- 倒排索引、自動補全、拼寫糾正、性能優化、索引存儲
es中的Fielddata是什么?如何優化其性能?
- 硬盤數據加載內存
- doc_values
- 預加載
- 控制大小
- 語句優化
es集群滾動升級如何實現?
- 數據備份
- 禁用shard分配
- 升級單個節點
1. ES實現機器學習模型推理
Elasticsearch 通過以下方式支持機器學習模型推理:
- ML 插件:Elasticsearch 提供了內置的機器學習插件(如
ml模塊),支持異常檢測、預測等任務。例如,使用anomaly detection功能對時間序列數據進行實時分析。 - 外部模型集成:通過
Inference Pipeline或Search Script調用外部機器學習模型(如 TensorFlow、PyTorch)。例如:POST _ml/inference/my_model/_predict {"input": {"features": [1.2, 3.4, 5.6]} } - Elasticsearch SQL:結合 SQL 查詢與機器學習模型,實現復雜的數據分析。
2. 倒排表的 FOR 和 RBM 壓縮算法
- FOR (Frame of Reference):
- 適用場景:數值型倒排列表(如整數 ID)。
- 原理:將倒排列表中的文檔 ID 轉換為相對于某個基準值的增量值,利用 Golomb 編碼壓縮。例如,文檔 ID
[1001, 1002, 1005]會被編碼為[0, 1, 3](基準值為 1001)。 - 優點:高效壓縮連續或近似連續的數值數據。
- RBM (Roaring Bitmaps):
- 適用場景:高基數集合的位圖壓縮。
- 原理:將文檔 ID 分割為 16 位塊,每個塊用不同的數據結構(如數組、位圖、運行長度編碼)存儲。例如,塊
0x1234中的文檔 ID 用位圖存儲。 - 優點:快速支持集合操作(交集、并集),適合聚合查詢。
3. 確保數據一致性前提下更新 ES 倒排索引
- 版本控制:每次更新文檔時,Elasticsearch 會檢查版本號(
_version),確保寫入的原子性。 - 主分片與副本分片同步:
- 寫請求先發送到主分片。
- 主分片成功寫入后,同步到副本分片。
- 成功后返回客戶端。
- 沖突處理:若多個寫請求同時修改同一文檔,Elasticsearch 會拒絕并發寫入,返回
VersionConflictEngineException。
4. ES 中的倒排列表
- 結構:倒排索引由
Term Dictionary(術語詞典)和Postings List(倒排列表)組成。- Term Dictionary:存儲所有唯一術語及其對應的倒排列表指針。
- Postings List:每個術語對應一個倒排列表,包含文檔 ID、詞頻、位置信息等。
- 示例:
{"term": "elasticsearch","postings": [{"doc_id": 1, "tf": 3, "positions": [0, 5, 10]},{"doc_id": 2, "tf": 2, "positions": [2, 8]}] }
5. 如何利用 ES 實現大數據聚合查詢
- 聚合類型:
- Terms 聚合:按字段值分組統計(如統計用戶性別分布)。
- Histogram 聚合:按數值范圍分桶(如統計訂單金額分布)。
- Cardinality 聚合:統計唯一值數量(如統計獨立訪客數)。
- 優化技巧:
- 使用
filter替代match減少計算開銷。 - 對高頻字段使用
keyword類型(避免分詞)。 - 控制聚合桶數量(
size參數)。
- 使用
6. ES 集群架構調優
- 分片策略:
- 主分片數:根據數據量預估,通常設置為節點數的 3-5 倍。
- 副本數:生產環境建議至少 1 個副本,確保高可用。
- 節點角色:
- 數據節點:存儲數據,執行搜索和聚合。
- 主節點:管理集群狀態,避免資源競爭。
- 協調節點:處理客戶端請求,減輕數據節點壓力。
- JVM 調優:限制堆內存不超過物理內存的 50%(推薦 31GB 以下)。
7. 如何優化 ES GC
- GC 策略:
- G1 GC:默認使用 G1 垃圾收集器,適用于大堆內存。
- 調整參數:
-XX:MaxGCPauseMillis=200 # 控制最大停頓時間 -XX:G1HeapRegionSize=4M # 調整區域大小
- 監控工具:使用
jstat或 Elasticsearch 內置監控 API 分析 GC 日志。 - 減少 Full GC:避免頻繁創建臨時對象,合理設置緩存(如
request_cache)。
8. 為什么 ES 內存 32G 以上性能幾乎無提升
- JVM 堆內存限制:
- Elasticsearch 堆內存超過 31GB 時,會觸發 Compressed Oops 的失效,導致性能下降。
- 大堆內存增加 GC 停頓時間(G1 GC 在 31GB 以上時,Full GC 時間顯著增長)。
- 操作系統限制:Linux 系統對大內存管理效率較低,可能導致內存碎片化。
9. 如何優化 ES 寫入性能
- 批量寫入:
- 使用
Bulk API批量提交文檔,減少網絡往返。 - 控制批量大小(通常 5MB-15MB)。
- 使用
- 調整刷新策略:
PUT /my_index/_settings {"index": {"refresh_interval": "30s" # 減少刷新頻率} } - 禁用副本:寫入時臨時禁用副本,寫入完成后再啟用。
10. ES 集群腦裂問題
- 原因:網絡分區導致部分節點無法通信,形成多個獨立的“腦”。
- 解決方法:
- 設置
discovery.zen.minimum_master_nodes為(number_of_masters / 2) + 1。 - 使用
Zen2或Elasticsearch 7.0+的cluster.initial_master_nodes配置。
- 設置
- 預防:部署奇數個主節點,避免偶數節點導致的投票平局。
11. ES 底層如何執行文檔的更新和刪除
- 更新操作:
- 客戶端發送更新請求到協調節點。
- 協調節點查詢主分片獲取當前文檔版本。
- 將新文檔寫入主分片,生成新版本。
- 同步到副本分片。
- 刪除操作:
- 標記文檔為
_deleted,不立即物理刪除。 - 定期通過
Merge操作(段合并)清除已刪除文檔。
- 標記文檔為
12. 如何優化文檔評分
- 相關性算法:
- BM25:默認評分算法,平衡詞頻和文檔長度。
- TF-IDF:適用于簡單匹配場景。
- 自定義評分:
- 使用
function_score結合權重、腳本評分:{"function_score": {"query": { "match": { "text": "elasticsearch" }},"functions": [{ "weight": 2, "filter": { "term": { "category": "books" }}}]} }
- 使用
13. 如何處理評分偏差
- 數據預處理:
- 對長文本使用
shingle分詞,避免關鍵詞漏匹配。 - 對稀有詞賦予更高權重。
- 對長文本使用
- 評分模型校準:
- 使用
script_score調整評分公式:{"script_score": {"query": { "match_all": {} },"script": {"source": "Math.log(1 + doc['sales'].value)"}} }
- 使用
14. ES 聚合查詢、組合查詢
- 組合查詢:
- Bool Query:結合
must、should、must_not實現復雜邏輯。 - Multi Match:跨多個字段匹配。
- Bool Query:結合
- 聚合查詢:
- 嵌套聚合:支持多級分組(如按地區->城市統計銷售額)。
- Pipeline 聚合:對聚合結果進行二次計算(如求平均值)。
15. ES 深分頁問題
- 問題:
from/size分頁在深度分頁時性能急劇下降(需加載所有前 N 條數據)。 - 解決方案:
- Scroll API:適用于離線導出,不支持實時性:
POST /_search?scroll=2m { "size": 100, "query": { "match_all": {} } } - Search After:基于排序值的分頁,適合實時查詢:
POST /_search {"size": 100,"query": { "match_all": {} },"search_after": ["123456"] }
- Scroll API:適用于離線導出,不支持實時性:
16. ES 如何實現滾動更新
- 步驟:
- 更新第一個節點:停止數據寫入,重啟節點加載新配置。
- 等待節點重新加入集群并恢復分片。
- 重復上述步驟更新其他節點。
- 注意事項:
- 確保
cluster.blocks.read_only未啟用。 - 使用
cluster:monitor/task/get監控分片恢復狀態。 - 避免在滾動更新期間執行大規模寫入操作。
- 確保
1. ES 聚合優化
優化策略
- 字段類型優化:
- 數值類型:確保聚合字段使用
long、double等數值類型,而非text。 - 關鍵詞聚合:使用
keyword類型(如text.keyword),避免全文索引。
- 數值類型:確保聚合字段使用
- Doc Values:
- 啟用
doc_values(默認啟用),用于高效聚合。例如:"fields": {"price": { "type": "double", "doc_values": true } }
- 啟用
- 分片設計:
- 合理設置分片數,避免過多或過少。通常分片數 = 節點數 × 3~5。
- 使用
search_after替代from/size深分頁,減少性能損耗。
- 預聚合:
- 對高頻查詢的字段使用
script或fielddata預處理,減少實時計算。
- 對高頻查詢的字段使用
示例:聚合性能提升
GET /sales/_search
{"size": 0,"aggs": {"avg_price": {"avg": { "field": "price" }},"top_regions": {"terms": {"field": "region.keyword","size": 10},"aggs": {"region_avg": { "avg": { "field": "price" } }}}}
}
2. ES 中如何去重
方法一:cardinality 聚合
- 原理:基于 HyperLogLog 算法,速度快但結果是近似值(誤差約 0.5%)。
- 示例:
GET /your_index/_search {"size": 0,"aggs": {"unique_user_count": {"cardinality": {"field": "user_id.keyword","precision_threshold": 10000}}} }
方法二:terms 聚合 + size
- 原理:通過獲取所有唯一值后統計數量,結果精確但性能較差。
- 示例:
GET /your_index/_search {"size": 0,"aggs": {"unique_users": {"terms": {"field": "user_id.keyword","size": 10000},"aggs": {"total_unique": {"value_count": { "field": "user_id.keyword" }}}}} }
注意事項:
- 字段類型:確保目標字段是
keyword類型(非text)。 - 分組去重:若需按分組字段(如日期)統計每組的唯一值,可嵌套聚合:
GET /your_index/_search {"size": 0,"aggs": {"group_by_date": {"date_histogram": {"field": "@timestamp","calendar_interval": "day"},"aggs": {"daily_unique_users": {"cardinality": {"field": "user_id.keyword","precision_threshold": 1000}}}}} }
3. ES 實現日志關聯查詢
方法一:使用 join 字段(父子文檔)
- 場景:日志與上下文(如請求ID)關聯。
- 映射:
{"mappings": {"properties": {"log_type": { "type": "keyword" },"request_id": { "type": "keyword" },"parent": { "type": "join", "relations": { "request": "log" } }}} } - 查詢:
POST /logs/_search {"query": {"has_child": {"type": "log","query": { "match": { "log_type": "error" } }}} }
方法二:使用 script 關聯字段
- 場景:跨索引關聯(如日志與用戶行為)。
- 示例:
POST /logs/_search {"query": {"script": {"source": "doc['user_id'].value == 'user123'"}} }
4. ES 中的 ANN(近似最近鄰搜索)
實現方式:KNN 插件(ES 8.x)
- 安裝插件:
bin/elasticsearch-plugin install https://artifacts.elastic.co/downloads/elasticsearch-plugins/knn/knn-8.12.0.zip - 映射定義:
{"mappings": {"properties": {"vector": { "type": "dense_vector", "dims": 128 }}} } - 查詢示例:
POST /my_index/_search {"size": 5,"query": {"knn": {"vector": [0.1, 0.2, ..., 0.128],"k": 5}} }
5. ES 創建只讀索引
方法一:通過 API 設置
PUT /my_index/_settings
{"index.blocks.read_only": true
}
方法二:通過索引生命周期管理(ILM)
- 策略示例:
PUT _ilm/policy/readonly_policy {"policy": {"phases": {"cold": {"min_age": "30d","actions": {"set_read_only": {}}}}} }
6. ES 不同節點類型的區別
| 節點類型 | 角色與功能 |
|---|---|
| 主節點 | 管理集群元數據(索引創建、分片分配),不處理數據讀寫。 |
| 數據節點 | 存儲數據,執行搜索、聚合等操作,消耗 CPU/內存/磁盤資源。 |
| 協調節點 | 路由請求、聚合結果,減輕數據節點壓力,通常用于高并發查詢場景。 |
| 冷熱架構節點 | 熱節點:處理高頻寫入/查詢;冷節點:存儲低頻訪問的冷數據,優化存儲成本。 |
7. ES 中如何管理索引
核心方法
-
索引生命周期管理(ILM):
- 自動管理索引從熱到冷再到刪除的流程。
- 示例策略:
PUT _ilm/policy/logs_policy {"policy": {"phases": {"hot": { "min_age": "0s", "actions": { "rollover": { "max_size": "50gb" } } },"warm": { "min_age": "7d", "actions": { "set_priority": 50 } },"delete": { "min_age": "30d", "actions": { "delete": {} } }}} }
-
索引模板:
- 自動應用映射、設置到新索引。
- 示例:
PUT _index_template/logs_template {"index_patterns": ["logs-*"],"template": {"settings": { "number_of_shards": 3, "number_of_replicas": 1 },"mappings": { "dynamic": "strict" }} }
-
快照備份:
- 使用
repository配置存儲路徑,定期備份索引。 - 示例:
PUT _snapshot/my_backup/snapshot_1?wait_for_completion=true {"indices": "my_index","ignore_unavailable": true }
- 使用
)

















:映射)
