DAY 44 預訓練模型
知識點回顧:
1.? 預訓練的概念
2.? 常見的分類預訓練模型
3.? 圖像預訓練模型的發展史
4.? 預訓練的策略
5.? 預訓練代碼實戰:resnet18
作業:
1.? 嘗試在cifar10對比如下其他的預訓練模型,觀察差異,盡可能和他人選擇的不同
2.? 嘗試通過ctrl進入resnet的內部,觀察殘差究竟是什么
一、預訓練的概念
我們之前在訓練中發現,準確率最開始隨著epoch的增加而增加。隨著循環的更新,參數在不斷發生更新。
所以參數的初始值對訓練結果有很大的影響:
1. 如果最開始的初始值比較好,后續訓練輪數就會少很多
2. 很有可能陷入局部最優值,不同的初始值可能導致陷入不同的局部最優值
所以很自然的想到,如果最開始能有比較好的參數,即可能導致未來訓練次數少,也可能導致未來訓練避免陷入局部最優解的問題。這就引入了一個概念,即預訓練模型。
如果別人在某些和我們目標數據類似的大規模數據集上做過訓練,我們可以用他的訓練參數來初始化我們的模型,這樣我們的模型就比較容易收斂。
Q&A:
1. 那為什么要選擇類似任務的數據集預訓練的模型參數呢?
因為任務差不多,他提取特征的能力才有用,如果任務相差太大,他的特征提取能力就沒那么好。
所以本質預訓練就是拿別人已經具備的通用特征提取能力來接著強化能力使之更加適應我們的數據集和任務。
2. 為什么要求預訓練模型是在大規模數據集上訓練的,小規模不行么?
因為提取的是通用特征,所以如果數據集數據少、尺寸小,就很難支撐復雜任務學習通用的數據特征。比如你是一個物理的博士,讓你去做小學數學題,很快就能上手;但是你是一個小學數學速算高手,讓你做物理博士的課題,就很困難。所以預訓練模型一般就挺強的。
我們把用預訓練模型的參數,然后接著在自己數據集上訓練來調整該參數的過程叫做微調,這種思想叫做遷移學習。把預訓練的過程叫做上游任務,把微調的過程叫做下游任務。
二、經典的預訓練模型
2.1 CNN 架構預訓練模型
| 模型 | 預訓練數據集 | 核心特點 | 在 CIFAR10 上的適配要點 |
|---|---|---|---|
| AlexNet | ImageNet | 首次引入 ReLU / 局部響應歸一化,參數量 6000 萬 + | 需修改首層卷積核大小(原 11x11→適配 32x32) |
| VGG16 | ImageNet | 純卷積堆疊,結構統一,參數量 1.38 億 | 凍結前 10 層卷積,僅微調全連接層 |
| ResNet18 | ImageNet | 殘差連接解決梯度消失,參數量 1100 萬 | 直接適配 32x32 輸入,需調整池化層步長 |
| MobileNetV2 | ImageNet | 深度可分離卷積,參數量 350 萬 + | 輕量級設計,適合計算資源有限的場景 |
2.2 Transformer 類預訓練模型
適用于較大尺寸圖像(如 224×224),在 CIFAR10 上需上采樣圖像尺寸或調整 Patch 大小。
| 模型 | 預訓練數據集 | 核心特點 | 在 CIFAR10 上的適配要點 |
|---|---|---|---|
| ViT-Base | ImageNet-21K | 純 Transformer 架構,參數量 8600 萬 | 圖像 Resize 至 224×224,Patch 大小設為 4×4 |
| Swin Transformer | ImageNet-22K | 分層窗口注意力,參數量 8000 萬 + | 需調整窗口大小適配小圖像 |
| DeiT | ImageNet | 結合 CNN 歸納偏置,參數量 2200 萬 | 輕量級 Transformer,適合中小尺寸圖像 |
2.3 自監督預訓練模型
無需人工標注,通過 pretext task(如掩碼圖像重建)學習特征,適合數據稀缺場景。
| 模型 | 預訓練方式 | 典型數據集 | 在 CIFAR10 上的優勢 |
|---|---|---|---|
| MoCo v3 | 對比學習 | ImageNet | 無需標簽即可遷移,適合無標注數據 |
| BEiT | 掩碼圖像建模 | ImageNet-22K | 特征語義豐富,微調時收斂更快 |
三、常見的分類預訓練模型介紹
3.1 預訓練模型的發展史
模型對比表
| 模型 | 年份 | 提出團隊 | 關鍵創新點 | 層數 | 參數量 | ImageNet Top-5 錯誤率 | 典型應用場景 | 預訓練權重可用性 |
|---|---|---|---|---|---|---|---|---|
| LeNet-5 | 1998 | Yann LeCun 等 | 首個 CNN 架構,卷積層 + 池化層 + 全連接層,Sigmoid 激活函數 | 7 | ~60K | N/A | 手寫數字識別(MNIST) | 無(歷史模型) |
| AlexNet | 2012 | Alex Krizhevsky 等 | ReLU 激活函數、Dropout、數據增強、GPU 訓練 | 8 | 60M | 15.3% | 大規模圖像分類 | PyTorch/TensorFlow 官方支持 |
| VGGNet | 2014 | Oxford VGG 團隊 | 統一 3×3 卷積核、多尺度特征提取、結構簡潔 | 16/19 | 138M/144M | 7.3%/7.0% | 圖像分類、目標檢測基礎骨干網絡 | PyTorch/TensorFlow 官方支持 |
| GoogLeNet | 2014 | Inception 模塊(多分支并行卷積)、1×1 卷積降維、全局平均池化 | 22 | 5M | 6.7% | 大規模圖像分類 | PyTorch/TensorFlow 官方支持 | |
| ResNet | 2015 | 何愷明等 | 殘差連接(解決梯度消失)、Batch Normalization | 18/50/152 | 11M/25M/60M | 3.57%/3.63%/3.58% | 圖像 / 視頻分類、檢測、分割 | PyTorch/TensorFlow 官方支持 |
| DenseNet | 2017 | Gao Huang 等 | 密集連接(每層與后續所有層相連)、特征復用、參數效率高 | 121/169 | 8M/14M | 2.80% | 小數據集、醫學圖像處理 | PyTorch/TensorFlow 官方支持 |
| MobileNet | 2017 | 深度可分離卷積(減少 75% 計算量)、輕量級設計 | 28 | 4.2M | 7.4% | 移動端圖像分類 / 檢測 | PyTorch/TensorFlow 官方支持 | |
| EfficientNet | 2019 | 復合縮放(同時優化深度、寬度、分辨率)、NAS 搜索最佳配置 | B0-B7 | 5.3M-66M | 2.6% (B7) | 高精度圖像分類(資源受限場景) | PyTorch/TensorFlow 官方支持 |
補充說明:
- 層數含義:代表模型不同版本,如 ResNet 有 18/50/152 層,EfficientNet 有 B0-B7 等變體。
- ImageNet Top-5 準確率:模型預測概率前五的類別中包含正確類別的比例,是圖像分類任務的重要評估指標(共 1000 類)。
模型架構演進關鍵點總結
- 深度突破:從 LeNet 的 7 層到 ResNet152 的 152 層,殘差連接解決了深度網絡的訓練難題。
(沒上過復試班 CV 部分的自行了解殘差連接,非常重要!) - 計算效率:GoogLeNet(Inception)和 MobileNet 通過結構優化,在保持精度的同時大幅降低參數量。
- 特征復用:DenseNet 的密集連接設計使模型能更好地利用淺層特征,適合小數據集。
- 自動化設計:EfficientNet 使用神經架構搜索(NAS)自動尋找最優網絡配置,開創了 AutoML 在 CNN 中的應用。
預訓練模型使用建議
| 任務需求 | 推薦模型 | 理由 |
|---|---|---|
| 快速原型開發 | ResNet50/18 | 結構平衡,預訓練權重穩定,社區支持完善 |
| 移動端部署 | MobileNetV3 | 參數量小,計算高效,專為移動設備優化 |
| 高精度分類(資源充足) | EfficientNet-B7 | 目前 ImageNet 準確率領先,適合 GPU/TPU 環境 |
| 小數據集或特征復用需求 | DenseNet | 密集連接設計減少過擬合,特征復用能力強 |
| 多尺度特征提取 | Inception-ResNet | 結合 Inception 多分支和 ResNet 殘差連接,適合復雜場景 |
說明:
模型預訓練權重均可通過主流框架(如 PyTorch 的torchvision.models、Keras 的applications模塊)直接加載,便于快速遷移到新任務。
總結:CNN 架構發展脈絡
1. 早期探索(1990s-2010s):LeNet 驗證 CNN 可行性,但受限于計算和數據。
2. 深度學習復興(2012-2015):AlexNet、VGGNet、GoogLeNet 通過加深網絡和結構創新突破性能。
3. 超深網絡時代(2015 年后):ResNet 解決退化問題,開啟殘差連接范式,后續模型圍繞效率(MobileNet)、特征復用(DenseNet)、多分支結構(Inception)等方向優化。
3.2預訓練模型的訓練策略
那么什么模型會被選為預訓練模型呢?比如一些調參后表現很好的cnn神經網絡(固定的神經元個數+固定的層數等)。
所以調用預訓練模型做微調,本質就是 用這些固定的結構+之前訓練好的參數 接著訓練
所以需要找到預訓練的模型結構并且加載模型參數
相較于之前用自己定義的模型有以下幾個注意點
1. 需要調用預訓練模型和加載權重
2. 需要resize 圖片讓其可以適配模型
3. 需要修改最后的全連接層以適應數據集
其中,訓練過程中,為了不破壞最開始的特征提取器的參數,最開始往往先凍結住特征提取器的參數,然后訓練全連接層,大約在5-10個epoch后解凍訓練。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt# 設置中文字體支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題# 檢查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用設備: {device}")# 1. 數據預處理(訓練集增強,測試集標準化)
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加載CIFAR-10數據集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform
)# 3. 創建數據加載器(可調整batch_size)
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 訓練函數(支持學習率調度器)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 設置為訓練模式train_loss_history = []test_loss_history = []train_acc_history = []test_acc_history = []all_iter_losses = []iter_indices = []for epoch in range(epochs):running_loss = 0.0correct_train = 0total_train = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 記錄Iteration損失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 統計訓練指標running_loss += iter_loss_, predicted = output.max(1)total_train += target.size(0)correct_train += predicted.eq(target).sum().item()# 每100批次打印進度if (batch_idx + 1) % 100 == 0:print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "f"| 單Batch損失: {iter_loss:.4f}")# 計算 epoch 級指標epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct_train / total_train# 測試階段model.eval()correct_test = 0total_test = 0test_loss = 0.0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 記錄歷史數據train_loss_history.append(epoch_train_loss)test_loss_history.append(epoch_test_loss)train_acc_history.append(epoch_train_acc)test_acc_history.append(epoch_test_acc)# 更新學習率調度器if scheduler is not None:scheduler.step(epoch_test_loss)# 打印 epoch 結果print(f"Epoch {epoch+1} 完成 | 訓練損失: {epoch_train_loss:.4f} "f"| 訓練準確率: {epoch_train_acc:.2f}% | 測試準確率: {epoch_test_acc:.2f}%")# 繪制損失和準確率曲線plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最終測試準確率# 5. 繪制Iteration損失曲線
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7)plt.xlabel('Iteration(Batch序號)')plt.ylabel('損失值')plt.title('訓練過程中的Iteration損失變化')plt.grid(True)plt.show()# 6. 繪制Epoch級指標曲線
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 5))# 準確率曲線plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='訓練準確率')plt.plot(epochs, test_acc, 'r-', label='測試準確率')plt.xlabel('Epoch')plt.ylabel('準確率 (%)')plt.title('準確率隨Epoch變化')plt.legend()plt.grid(True)# 損失曲線plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='訓練損失')plt.plot(epochs, test_loss, 'r-', label='測試損失')plt.xlabel('Epoch')plt.ylabel('損失值')plt.title('損失值隨Epoch變化')plt.legend()plt.grid(True)plt.tight_layout()plt.show()
# 導入ResNet模型
from torchvision.models import resnet18# 定義ResNet18模型(支持預訓練權重加載)
def create_resnet18(pretrained=True, num_classes=10):# 加載預訓練模型(ImageNet權重)model = resnet18(pretrained=pretrained)# 修改最后一層全連接層,適配CIFAR-10的10分類任務in_features = model.fc.in_featuresmodel.fc = nn.Linear(in_features, num_classes)# 將模型轉移到指定設備(CPU/GPU)model = model.to(device)return model# 創建ResNet18模型(加載ImageNet預訓練權重,不進行微調)
model = create_resnet18(pretrained=True, num_classes=10)
model.eval() # 設置為推理模式# 測試單張圖片(示例)
from torchvision import utils# 從測試數據集中獲取一張圖片
dataiter = iter(test_loader)
images, labels = next(dataiter)
images = images[:1].to(device) # 取第1張圖片# 前向傳播
with torch.no_grad():outputs = model(images)_, predicted = torch.max(outputs.data, 1)# 顯示圖片和預測結果
plt.imshow(utils.make_grid(images.cpu(), normalize=True).permute(1, 2, 0))
plt.title(f"預測類別: {predicted.item()}")
plt.axis('off')
plt.show()
在 CIFAR-10 數據集中,類別標簽是固定的 10 個,分別對應:
| 標簽(數字) | 類別名稱 | 說明 |
|---|---|---|
| 0 | airplane | 飛機 |
| 1 | automobile | 汽車(含轎車、卡車等) |
| 2 | bird | 鳥類 |
| 3 | cat | 貓 |
| 4 | deer | 鹿 |
| 5 | dog | 狗 |
| 6 | frog | 青蛙 |
| 7 | horse | 馬 |
| 8 | ship | 船 |
| 9 | truck | 卡車(重型貨車等) |
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import os# 設置中文字體支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題# 檢查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用設備: {device}")# 1. 數據預處理(訓練集增強,測試集標準化)
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加載CIFAR-10數據集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform
)# 3. 創建數據加載器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定義ResNet18模型
def create_resnet18(pretrained=True, num_classes=10):model = models.resnet18(pretrained=pretrained)# 修改最后一層全連接層in_features = model.fc.in_featuresmodel.fc = nn.Linear(in_features, num_classes)return model.to(device)# 5. 凍結/解凍模型層的函數
def freeze_model(model, freeze=True):"""凍結或解凍模型的卷積層參數"""# 凍結/解凍除fc層外的所有參數for name, param in model.named_parameters():if 'fc' not in name:param.requires_grad = not freeze# 打印凍結狀態frozen_params = sum(p.numel() for p in model.parameters() if not p.requires_grad)total_params = sum(p.numel() for p in model.parameters())if freeze:print(f"已凍結模型卷積層參數 ({frozen_params}/{total_params} 參數)")else:print(f"已解凍模型所有參數 ({total_params}/{total_params} 參數可訓練)")return model# 6. 訓練函數(支持階段式訓練)
def train_with_freeze_schedule(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, freeze_epochs=5):"""前freeze_epochs輪凍結卷積層,之后解凍所有層進行訓練"""train_loss_history = []test_loss_history = []train_acc_history = []test_acc_history = []all_iter_losses = []iter_indices = []# 初始凍結卷積層if freeze_epochs > 0:model = freeze_model(model, freeze=True)for epoch in range(epochs):# 解凍控制:在指定輪次后解凍所有層if epoch == freeze_epochs:model = freeze_model(model, freeze=False)# 解凍后調整優化器(可選)optimizer.param_groups[0]['lr'] = 1e-4 # 降低學習率防止過擬合model.train() # 設置為訓練模式running_loss = 0.0correct_train = 0total_train = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 記錄Iteration損失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 統計訓練指標running_loss += iter_loss_, predicted = output.max(1)total_train += target.size(0)correct_train += predicted.eq(target).sum().item()# 每100批次打印進度if (batch_idx + 1) % 100 == 0:print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "f"| 單Batch損失: {iter_loss:.4f}")# 計算 epoch 級指標epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct_train / total_train# 測試階段model.eval()correct_test = 0total_test = 0test_loss = 0.0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 記錄歷史數據train_loss_history.append(epoch_train_loss)test_loss_history.append(epoch_test_loss)train_acc_history.append(epoch_train_acc)test_acc_history.append(epoch_test_acc)# 更新學習率調度器if scheduler is not None:scheduler.step(epoch_test_loss)# 打印 epoch 結果print(f"Epoch {epoch+1} 完成 | 訓練損失: {epoch_train_loss:.4f} "f"| 訓練準確率: {epoch_train_acc:.2f}% | 測試準確率: {epoch_test_acc:.2f}%")# 繪制損失和準確率曲線plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最終測試準確率# 7. 繪制Iteration損失曲線
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7)plt.xlabel('Iteration(Batch序號)')plt.ylabel('損失值')plt.title('訓練過程中的Iteration損失變化')plt.grid(True)plt.show()# 8. 繪制Epoch級指標曲線
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 5))# 準確率曲線plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='訓練準確率')plt.plot(epochs, test_acc, 'r-', label='測試準確率')plt.xlabel('Epoch')plt.ylabel('準確率 (%)')plt.title('準確率隨Epoch變化')plt.legend()plt.grid(True)# 損失曲線plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='訓練損失')plt.plot(epochs, test_loss, 'r-', label='測試損失')plt.xlabel('Epoch')plt.ylabel('損失值')plt.title('損失值隨Epoch變化')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 主函數:訓練模型
def main():# 參數設置epochs = 40 # 總訓練輪次freeze_epochs = 5 # 凍結卷積層的輪次learning_rate = 1e-3 # 初始學習率weight_decay = 1e-4 # 權重衰減# 創建ResNet18模型(加載預訓練權重)model = create_resnet18(pretrained=True, num_classes=10)# 定義優化器和損失函數optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)criterion = nn.CrossEntropyLoss()# 定義學習率調度器scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=2, verbose=True)# 開始訓練(前5輪凍結卷積層,之后解凍)final_accuracy = train_with_freeze_schedule(model=model,train_loader=train_loader,test_loader=test_loader,criterion=criterion,optimizer=optimizer,scheduler=scheduler,device=device,epochs=epochs,freeze_epochs=freeze_epochs)print(f"訓練完成!最終測試準確率: {final_accuracy:.2f}%")# # 保存模型# torch.save(model.state_dict(), 'resnet18_cifar10_finetuned.pth')# print("模型已保存至: resnet18_cifar10_finetuned.pth")if __name__ == "__main__":main()
 ?
?

幾個明顯的現象
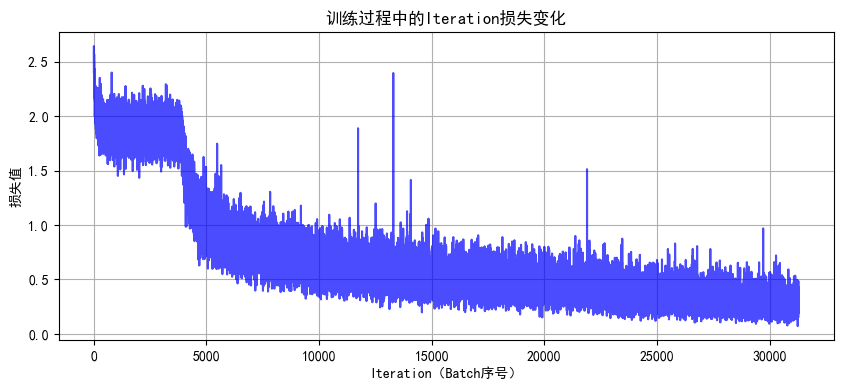
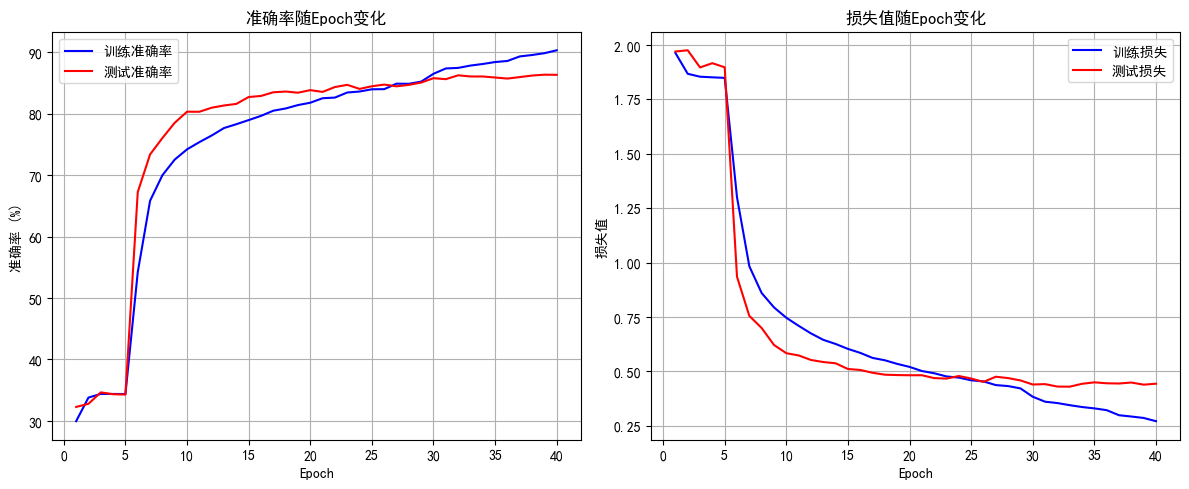
1. 解凍后幾個epoch即可達到之前cnn訓練20輪的效果,這是預訓練的優勢
2. 由于訓練集用了 RandomCrop(隨機裁剪)、RandomHorizontalFlip(隨機水平翻轉)、ColorJitter(顏色抖動)等數據增強操作,這會讓訓練時模型看到的圖片有更多 “干擾” 或變形。比如一張汽車圖片,訓練時可能被裁剪成只顯示局部、顏色也有變化,模型學習難度更高;而測試集是標準的、沒增強的圖片,模型預測相對輕松,就可能出現訓練集準確率暫時低于測試集的情況,尤其在訓練前期增強對模型影響更明顯。隨著訓練推進,模型適應增強后會緩解。
3. 最后收斂后的效果超過非預訓練模型的80%,大幅提升
作業
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import os# 設置中文字體支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False# 設備配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用設備: {device}")# 數據預處理
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 加載數據集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)def create_resnet50(pretrained=True, num_classes=10):model = models.resnet50(pretrained=pretrained) in_features = model.fc.in_featuresmodel.fc = nn.Linear(in_features, num_classes) return model.to(device)# 訓練函數
def train_with_freeze_schedule(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, freeze_epochs=5):"""前freeze_epochs輪凍結卷積層,之后解凍所有層進行訓練"""train_loss_history = []test_loss_history = []train_acc_history = []test_acc_history = []all_iter_losses = []iter_indices = []# 初始凍結卷積層if freeze_epochs > 0:model = freeze_model(model, freeze=True)for epoch in range(epochs):# 解凍控制:在指定輪次后解凍所有層if epoch == freeze_epochs:model = freeze_model(model, freeze=False)# 解凍后調整優化器(可選)optimizer.param_groups[0]['lr'] = 1e-4 # 降低學習率防止過擬合model.train() # 設置為訓練模式running_loss = 0.0correct_train = 0total_train = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 記錄Iteration損失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 統計訓練指標running_loss += iter_loss_, predicted = output.max(1)total_train += target.size(0)correct_train += predicted.eq(target).sum().item()# 每100批次打印進度if (batch_idx + 1) % 100 == 0:print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "f"| 單Batch損失: {iter_loss:.4f}")# 計算 epoch 級指標epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct_train / total_train# 測試階段model.eval()correct_test = 0total_test = 0test_loss = 0.0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 記錄歷史數據train_loss_history.append(epoch_train_loss)test_loss_history.append(epoch_test_loss)train_acc_history.append(epoch_train_acc)test_acc_history.append(epoch_test_acc)# 更新學習率調度器if scheduler is not None:scheduler.step(epoch_test_loss)# 打印 epoch 結果print(f"Epoch {epoch+1} 完成 | 訓練損失: {epoch_train_loss:.4f} "f"| 訓練準確率: {epoch_train_acc:.2f}% | 測試準確率: {epoch_test_acc:.2f}%")# 繪制損失和準確率曲線plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最終測試準確率# 繪圖函數
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7)plt.xlabel('Iteration(Batch序號)')plt.ylabel('損失值')plt.title('訓練過程中的Iteration損失變化')plt.grid(True)plt.show()def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 5))# 準確率曲線plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='訓練準確率')plt.plot(epochs, test_acc, 'r-', label='測試準確率')plt.xlabel('Epoch')plt.ylabel('準確率 (%)')plt.title('準確率隨Epoch變化')plt.legend()plt.grid(True)# 損失曲線plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='訓練損失')plt.plot(epochs, test_loss, 'r-', label='測試損失')plt.xlabel('Epoch')plt.ylabel('損失值')plt.title('損失值隨Epoch變化')plt.legend()plt.grid(True)plt.tight_layout()plt.show()def main():epochs = 40freeze_epochs = 5learning_rate = 5e-4 weight_decay = 1e-4# 創建ResNet50模型model = create_resnet50(pretrained=True)# 定義優化器optimizer = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=weight_decay, momentum=0.9 # 添加動量加速收斂)criterion = nn.CrossEntropyLoss()scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=2, verbose=True)# 訓練流程final_accuracy = train_with_freeze_schedule(model=model,train_loader=train_loader,test_loader=test_loader,criterion=criterion,optimizer=optimizer,scheduler=scheduler,device=device,epochs=epochs,freeze_epochs=freeze_epochs)print(f"\nResNet50在CIFAR-10上的最終測試準確率: {final_accuracy:.2f}%")# 保存模型(可選)# torch.save(model.state_dict(), 'resnet50_cifar10_finetuned.pth')if __name__ == "__main__":main()@浙大疏錦行

)




)












