目錄
- YOLOX
- 1. AttributeError: 'VOCDetection' object has no attribute 'cache'
- 2. ValueError: operands could not be broadcast together with shapes (8,5) (0,)
- 3. windows遠程查看服務器的tensorboard
- 4. AttributeError: 'int' object has no attribute 'numel'
YOLOX
1. AttributeError: ‘VOCDetection’ object has no attribute ‘cache’
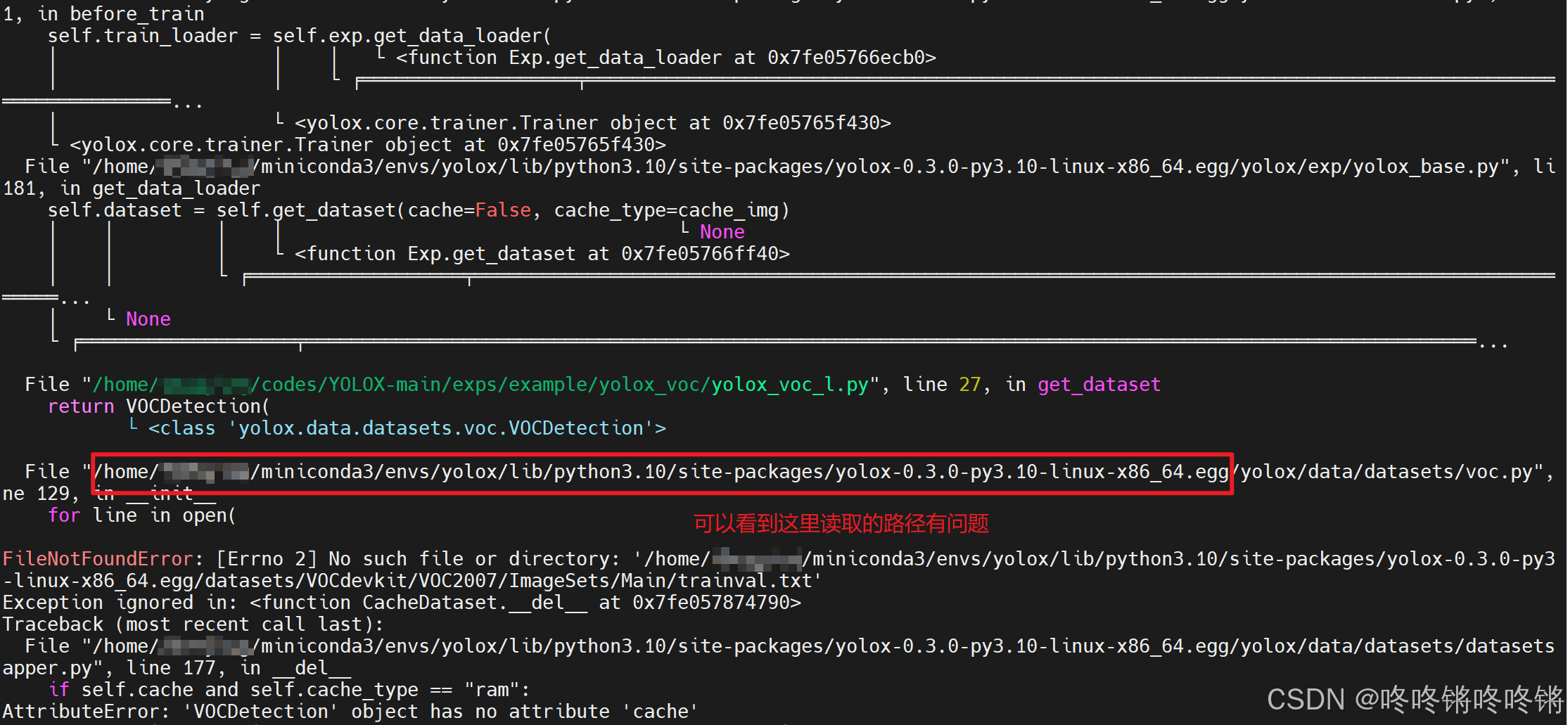
conda activate yolox
pip uninstall yolox
python3 setup.py develop
莫名其妙就行了
2. ValueError: operands could not be broadcast together with shapes (8,5) (0,)
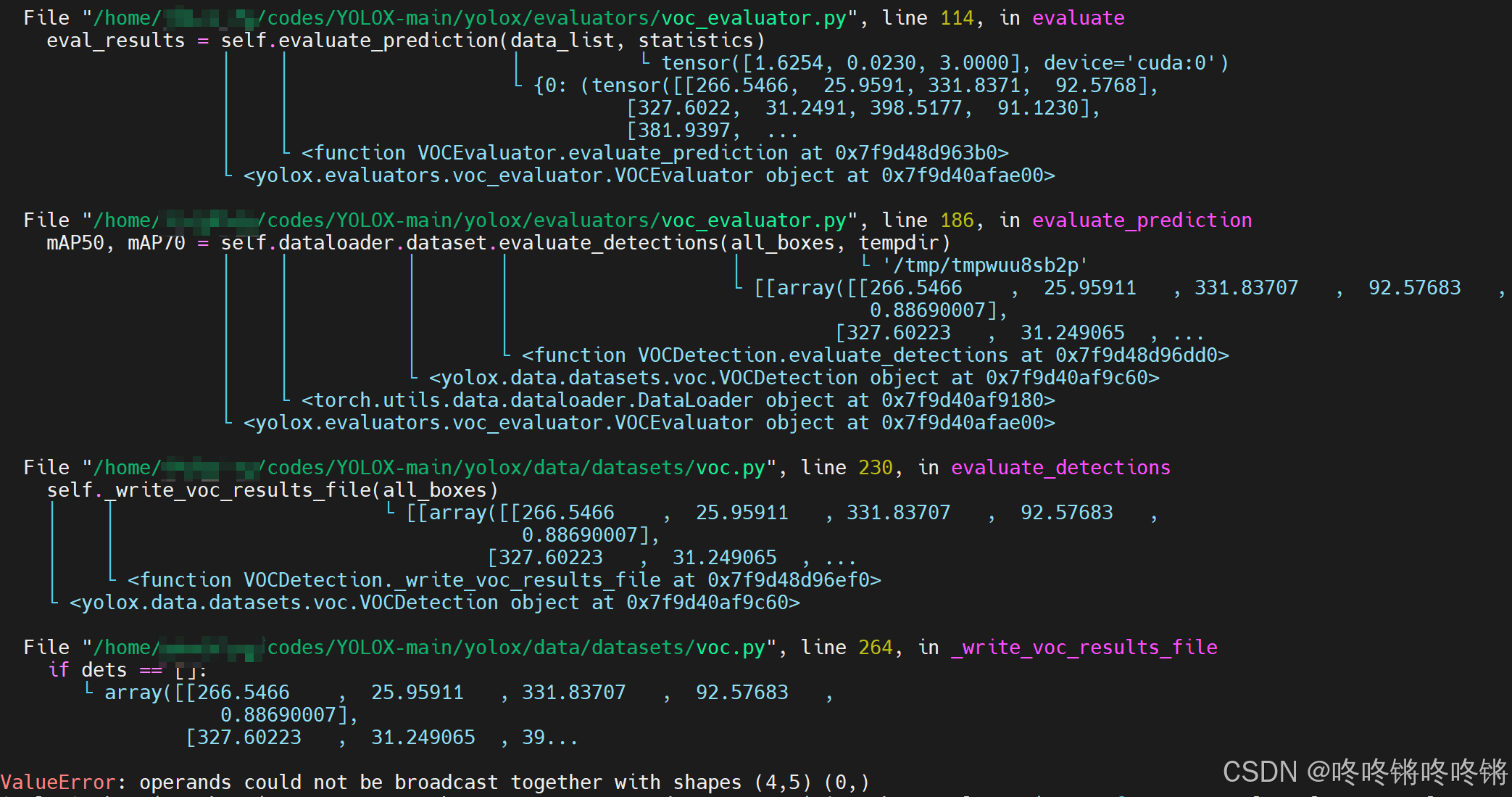
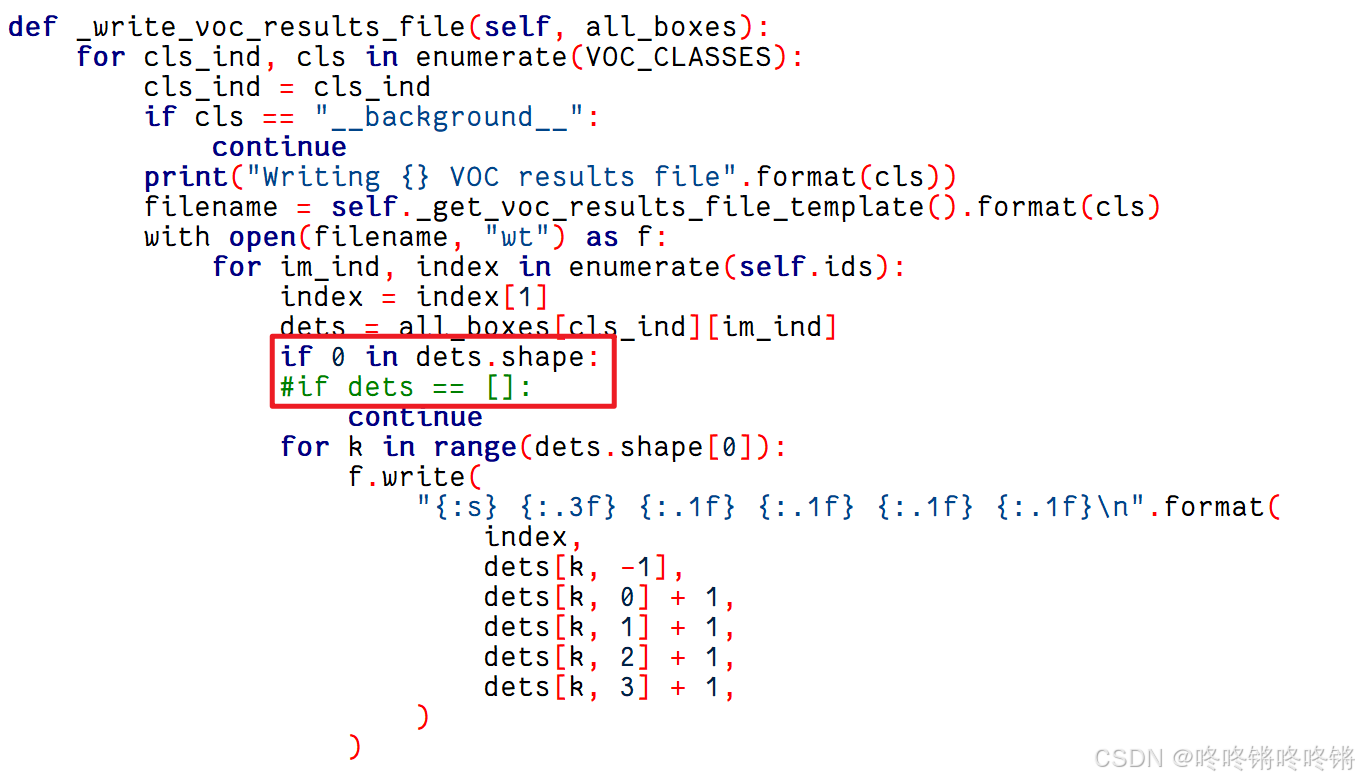
修改YOLOX-main/yolox/data/datasets/voc.py中
3. windows遠程查看服務器的tensorboard
服務器端
tensorboard --lodir=/path/ --port 6006
window本地
ssh -L 6007:localhost:6006 root@xx.xx.xxx.xx -p 22
連接成功要輸入登錄密碼,其中6007是本地指定的端口,6006是服務器段指定的端口,22是ssh連接的端口。
然后網頁打開http://127.0.0.1:6007/就可以查看了
4. AttributeError: ‘int’ object has no attribute ‘numel’
使用yolox_voc_nano.py進行訓練的時候會報錯
報錯的:
# encoding: utf-8
import os
import torch.nn as nnfrom yolox.data import get_yolox_datadir
from yolox.exp import Exp as MyExpclass Exp(MyExp):def __init__(self):super(Exp, self).__init__()self.num_classes = 1self.depth = 0.33self.width = 0.25self.input_size = (416, 416)self.random_size = (10, 20)self.mosaic_scale = (0.5, 1.5)self.test_size = (416, 416)self.mosaic_prob = 0.5self.enable_mixup = Falseself.exp_name = os.path.split(os.path.realpath(__file__))[1].split(".")[0]def get_model(self, sublinear=False):def init_yolo(M):for m in M.modules():if isinstance(m, nn.BatchNorm2d):m.eps = 1e-3m.momentum = 0.03if "model" not in self.__dict__:from yolox.models import YOLOX, YOLOPAFPN, YOLOXHeadin_channels = [256, 512, 1024]# NANO model use depthwise = True, which is main difference.backbone = YOLOPAFPN(self.depth, self.width, in_channels=in_channels,act=self.act, depthwise=True,)head = YOLOXHead(self.num_classes, self.width, in_channels=in_channels,act=self.act, depthwise=True)self.model = YOLOX(backbone, head)self.model.apply(init_yolo)self.model.head.initialize_biases(1e-2)return self.modeldef get_dataset(self, cache: bool, cache_type: str = "ram"):from yolox.data import VOCDetection, TrainTransformreturn VOCDetection(data_dir=os.path.join(get_yolox_datadir(), "VOCdevkit"),image_sets=[('2007', 'trainval')],img_size=self.input_size,preproc=TrainTransform(max_labels=50,flip_prob=self.flip_prob,hsv_prob=self.hsv_prob),cache=cache,cache_type=cache_type,)def get_eval_dataset(self, **kwargs):from yolox.data import VOCDetection, ValTransformlegacy = kwargs.get("legacy", False)return VOCDetection(data_dir=os.path.join(get_yolox_datadir(), "VOCdevkit"),image_sets=[('2007', 'test')],img_size=self.test_size,preproc=ValTransform(legacy=legacy),)def get_evaluator(self, batch_size, is_distributed, testdev=False, legacy=False):from yolox.evaluators import VOCEvaluatorreturn VOCEvaluator(dataloader=self.get_eval_loader(batch_size, is_distributed,testdev=testdev, legacy=legacy),img_size=self.test_size,confthre=self.test_conf,nmsthre=self.nmsthre,num_classes=self.num_classes,)修改為:
# encoding: utf-8
import osimport torch
import torch.distributed as distimport torch.nn as nnfrom yolox.data import get_yolox_datadir
from yolox.exp import Exp as MyExpclass Exp(MyExp):def __init__(self):super(Exp, self).__init__()self.num_classes = 1self.depth = 0.33self.width = 0.25self.input_size = (416, 416)self.random_size = (10, 20)self.mosaic_scale = (0.5, 1.5)self.test_size = (416, 416)self.max_epoch = 500self.enable_mixup = Falseself.exp_name = os.path.split(os.path.realpath(__file__))[1].split(".")[0]def get_model(self, sublinear=False):def init_yolo(M):for m in M.modules():if isinstance(m, nn.BatchNorm2d):m.eps = 1e-3m.momentum = 0.03if "model" not in self.__dict__:from yolox.models import YOLOX, YOLOPAFPN, YOLOXHeadin_channels = [256, 512, 1024]# NANO model use depthwise = True, which is main difference.backbone = YOLOPAFPN(self.depth, self.width, in_channels=in_channels,act=self.act, depthwise=True,)head = YOLOXHead(self.num_classes, self.width, in_channels=in_channels,act=self.act, depthwise=True)self.model = YOLOX(backbone, head)self.model.apply(init_yolo)self.model.head.initialize_biases(1e-2)return self.modeldef get_data_loader(self, batch_size, is_distributed, no_aug=False, cache_img=False):from yolox.data import (VOCDetection,TrainTransform,YoloBatchSampler,DataLoader,InfiniteSampler,MosaicDetection,worker_init_reset_seed,)from yolox.utils import (wait_for_the_master,get_local_rank,)local_rank = get_local_rank()with wait_for_the_master(local_rank):dataset = VOCDetection(data_dir=os.path.join(get_yolox_datadir(), "VOCdevkit"),image_sets=[('2007', 'trainval')],img_size=self.input_size,preproc=TrainTransform(max_labels=50,flip_prob=self.flip_prob,hsv_prob=self.hsv_prob),cache=cache_img,)dataset = MosaicDetection(dataset,mosaic=not no_aug,img_size=self.input_size,preproc=TrainTransform(max_labels=120,flip_prob=self.flip_prob,hsv_prob=self.hsv_prob),degrees=self.degrees,translate=self.translate,mosaic_scale=self.mosaic_scale,mixup_scale=self.mixup_scale,shear=self.shear,enable_mixup=self.enable_mixup,mosaic_prob=self.mosaic_prob,mixup_prob=self.mixup_prob,)self.dataset = datasetif is_distributed:batch_size = batch_size // dist.get_world_size()sampler = InfiniteSampler(len(self.dataset), seed=self.seed if self.seed else 0)batch_sampler = YoloBatchSampler(sampler=sampler,batch_size=batch_size,drop_last=False,mosaic=not no_aug,)dataloader_kwargs = {"num_workers": self.data_num_workers, "pin_memory": True}dataloader_kwargs["batch_sampler"] = batch_sampler# Make sure each process has different random seed, especially for 'fork' methoddataloader_kwargs["worker_init_fn"] = worker_init_reset_seedtrain_loader = DataLoader(self.dataset, **dataloader_kwargs)return train_loaderdef get_eval_loader(self, batch_size, is_distributed, testdev=False, legacy=False):from yolox.data import VOCDetection, ValTransformvaldataset = VOCDetection(data_dir=os.path.join(get_yolox_datadir(), "VOCdevkit"),image_sets=[('2007', 'test')],img_size=self.test_size,preproc=ValTransform(legacy=legacy),)if is_distributed:batch_size = batch_size // dist.get_world_size()sampler = torch.utils.data.distributed.DistributedSampler(valdataset, shuffle=False)else:sampler = torch.utils.data.SequentialSampler(valdataset)dataloader_kwargs = {"num_workers": self.data_num_workers,"pin_memory": True,"sampler": sampler,}dataloader_kwargs["batch_size"] = batch_sizeval_loader = torch.utils.data.DataLoader(valdataset, **dataloader_kwargs)return val_loaderdef get_evaluator(self, batch_size, is_distributed, testdev=False, legacy=False):from yolox.evaluators import VOCEvaluatorval_loader = self.get_eval_loader(batch_size, is_distributed, testdev, legacy)evaluator = VOCEvaluator(dataloader=val_loader,img_size=self.test_size,confthre=self.test_conf,nmsthre=self.nmsthre,num_classes=self.num_classes,)return evaluator





)










)

