激活函數和損失函數在深度學習中扮演著至關重要的角色。通過選擇合適的激活函數和損失函數,可以顯著提高神經網絡的表達能力和優化效果。
其中激活函數是神經網絡中的非線性函數,用于在神經元之間引入非線性關系,從而使模型能夠學習和表示復雜的數據模式,常見的激活函數有 Sigmoid、Tanh、ReLU 和 Leaky ReLU;損失函數則是評估模型預測值與真實值之間的差異,通過最小化損失函數來優化模型參數,常見的損失函數有 MSE和交叉熵損失(Cross-Entropy Loss)。
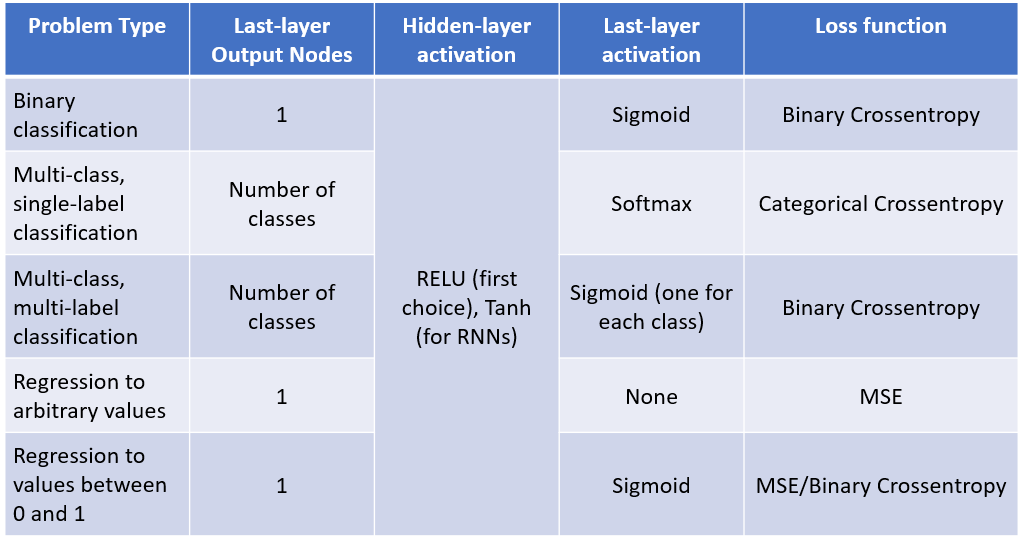
一、激活函數
激活函數(Activation Function)是什么?在深度學習中,激活函數是神經網絡中的非線性函數,用于在神經元之間引入非線性關系,從而使模型能夠學習和表示復雜的數據模式。
如果神經網絡沒有像Relu這樣的激活函數(也叫非線性激活函數),神經網絡每層就只包含兩個線性運算,即點積與加法:output = dot(input, W) + b。
神經網絡中的每一層若僅進行線性變換(仿射變換),則其假設空間受限,無法充分利用多層表示的優勢。因為多個線性層堆疊后,其整體運算仍然是線性的,增加層數并不能擴展假設空間。為了獲得更豐富的假設空間,需要引入非線性因素,即激活函數。
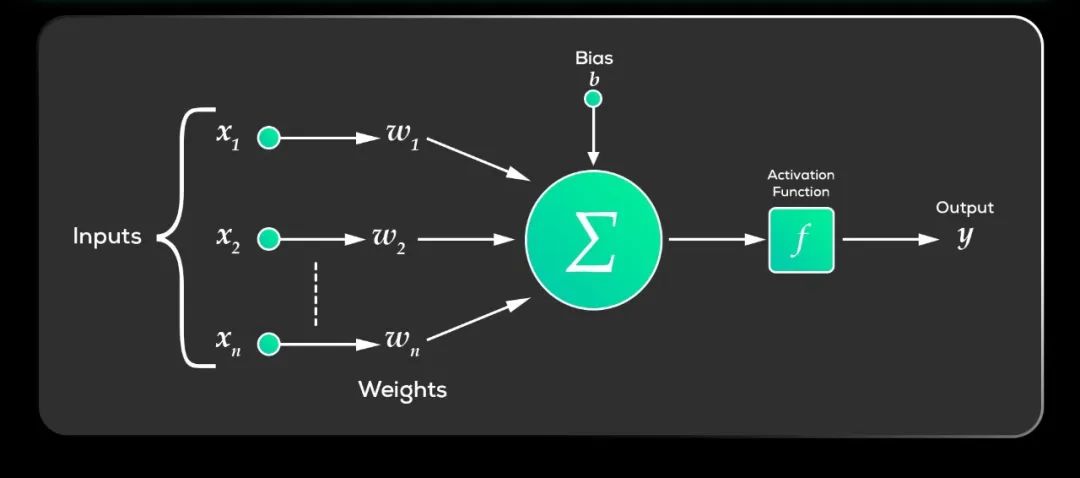
Sigmoid和Tanh是較早使用的激活函數,但存在梯度消失問題。ReLU及其變體(如Leaky ReLU、PReLU、ELU等)通過改進梯度消失問題,成為了當前隱藏層常用的激活函數。而softmax函數則專門用于多分類問題的輸出層,將輸出轉換為概率分布。
-
Sigmoid:將輸入值壓縮到(0, 1)之間,常用于二分類問題的輸出層。但存在梯度消失問題,且輸出不以零為中心。
-
Tanh:將輸入值壓縮到(-1, 1)之間,輸出均值為0,更適合隱藏層。但同樣存在梯度消失問題。
-
ReLU:當輸入大于0時,輸出等于輸入;當輸入小于0時,輸出為0。具有計算簡單、梯度消失問題較輕的優點,是隱藏層常用的激活函數。但存在神經元死亡問題。
-
Leaky ReLU:解決了ReLU在輸入小于0時梯度為0的問題,允許小的梯度流過。
-
Softmax:將輸入向量中的每個元素映射到(0, 1)區間內,并且所有輸出元素的和為1。用于多分類問題的輸出層,將神經網絡的輸出轉換為概率分布。
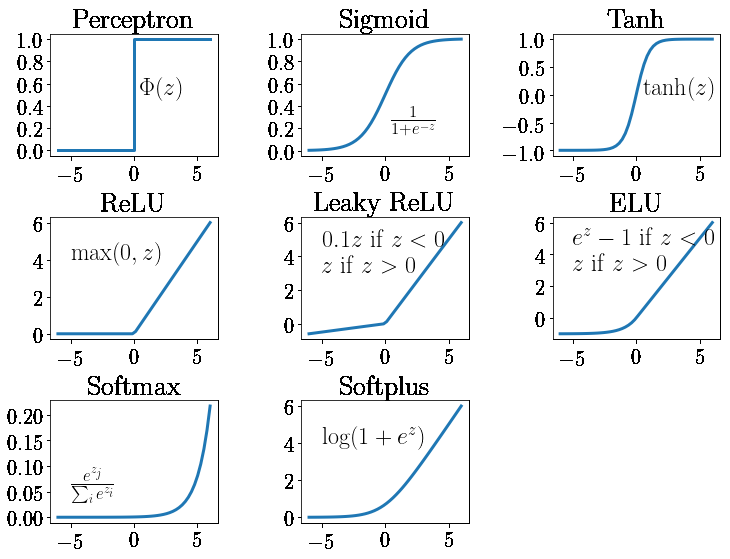
“一圖 + 一句話”徹底搞懂激活函數。
“激活函數是神經網絡中的非線性組件,用于在神經元間引入非線性關系,使模型能捕捉復雜數據模式,其中ReLU及其變體常用于隱藏層,而Softmax則專用于多分類輸出層。”
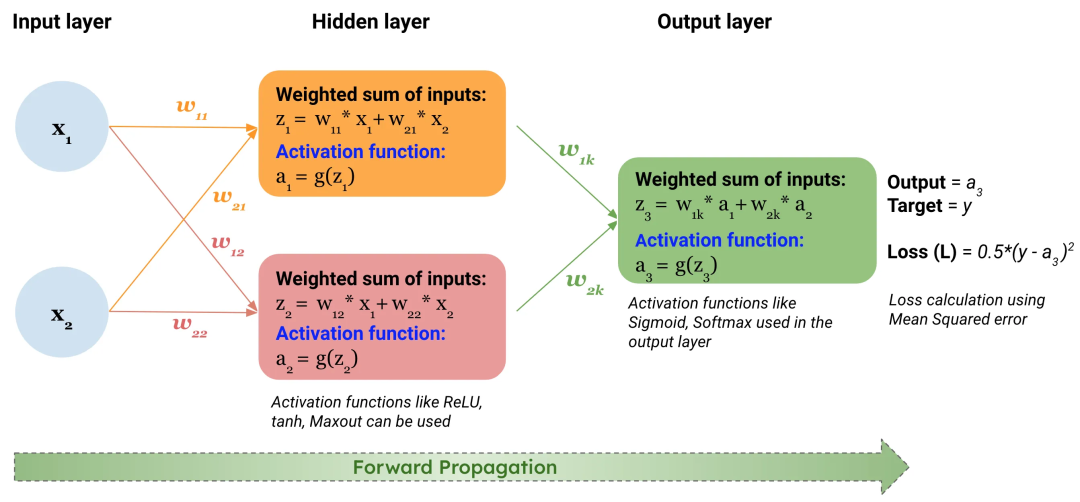
二、損失函數
損失函數(Loss Function)是什么?在深度學習中,損失函數則是評估模型預測值與真實值之間的差異,通過最小化損失函數來優化模型參數。
在深度學習中,通過計算損失值,可以直觀地了解模型的預測性能,從而指導模型的優化方向。神經網絡通常使用梯度下降等優化算法來調整模型參數。
損失函數為這些優化算法提供了明確的目標和方向。通過不斷減小損失值,可以逐步優化模型參數,提高模型的預測性能。常見類型包括均方誤差、交叉熵損失等,選擇時需根據任務類型、數據分布和特定需求進行考慮。
-
均方誤差(MSE):用于回歸問題,計算預測值與真實值之間差的平方的平均值。
-
交叉熵損失:用于分類問題,衡量模型預測概率分布與真實概率分布之間的差異。包括二分類交叉熵損失和多類別交叉熵損失。
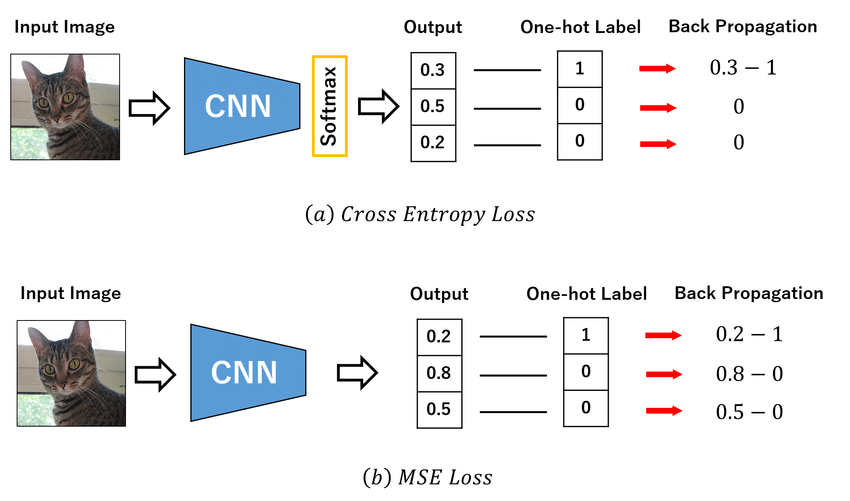
“一圖 + 一句話”徹底搞懂損失函數。
“損失函數是衡量模型預測值與真實值差異的函數,通過最小化損失函數優化模型參數,常見類型有均方誤差(回歸)和交叉熵損失(分類),選擇時需根據任務需求。”
?資料分享
為了方便大家學習,我整理了一份深度學習資料+80G人工智能資料包(如下圖)
不僅有入門級教程,配套課件,還有進階實戰,源碼數據集,更有面試題幫你提升~

需要的兄弟可以按照這個圖的方式免費獲取




的原理推導)


因無法找到頭文件導致的結構體成員不自動補全問題。)




第5章析因設計引導5.7節思考題5.7 R語言解題)





AI繪畫帶來的挑戰解題全過程文檔及程序)
