本文介紹了上帝之心的算法及其Python實現,使用Python語言的性能分析工具測算性能瓶頸,將算法最耗時的部分重構至CUDA C語言在純GPU上運行,利用GPU核心更多并行更快的優勢顯著提高算法運算速度,實現了結果不變的情況下將耗時縮短五十倍的目標。
2.1 簡單Python畫曼德勃羅特集算法
2.1.1 “上帝之心”的由來
曼德勃羅特集是一個幾何圖形,曾被稱為“上帝的指紋”。

只要計算的點足夠多,不管把圖案放大多少倍,都能顯示出更加復雜的局部,這些局部既與整體不同,又有某種相似的地方。
圖案具有無窮無盡的細節和自相似性。如圖所示形產生過程,其中后一個圖均是前一個圖的某一局部放大:

來源:百度百科
2.2.2 簡單py算法實現
跟任意GPT要一個簡單Python實現的曼德勃羅特集算法,可以得到以下源碼:
def simple_mandelbrot(width, height, real_low, real_high, imag_low, imag_high, max_iters, upper_bound):real_vals = np.linspace(real_low, real_high, width)imag_vals = np.linspace(imag_low, imag_high, height) mandelbrot_graph = np.ones((height, width), dtype=np.float32) for x in range(width):for y in range(height):c = np.complex64(real_vals[x] + imag_vals[y] * 1j)z = np.complex64(0) for i in range(max_iters):z = z ** 2 + c if np.abs(z) > upper_bound:mandelbrot_graph[y, x] = 0break return mandelbrot_graph加上具體的圖片大小,實部虛部,迭代次數,發散閾值,進行計算,并記錄計算時間,且保存圖像,記錄保存時間。
if __name__ == '__main__':t1 = time()mandel = simple_mandelbrot(512, 512, -2, 2, -2, 2, 256, 2.5)t2 = time()mandel_time = t2 - t1t1 = time()fig = plt.figure(1)plt.imshow(mandel, extent=(-2, 2, -2, 2))plt.savefig('mandelbrot.png', dpi=fig.dpi)t2 = time()dump_time = t2 - t1print('It took {} seconds to calculate the Mandelbrot graph.'.format(mandel_time))print('It took {} seconds to dump the image.'.format(dump_time))在筆者的i5-13490F的CPU上,Python3.12.3版本,輸出結果是:
~/Desktop/EXAMPLES/02$ ../bin/python mandelbrot.py
It took 3.529670000076294 seconds to calculate the Mandelbrot graph.
It took 0.06651782989501953 seconds to dump the image.計算過程耗時3.53秒,存成圖片耗時0.067秒。圖片如圖:
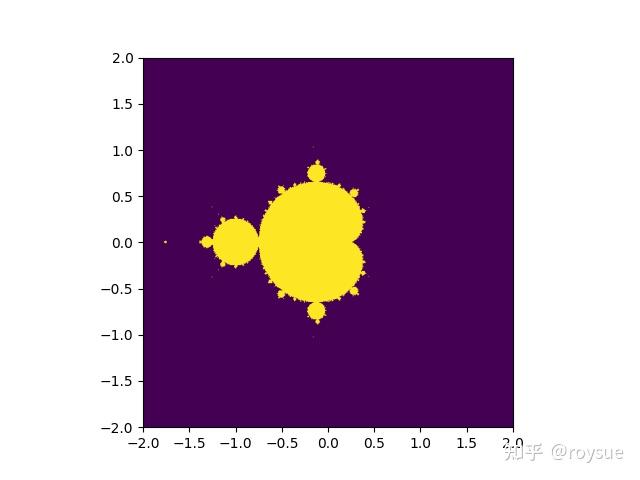
2.2 cProfile性能分析算法函數瓶頸
2.2.1 函數粒度分析性能瓶頸
Python 的 cProfile 模塊是一個內置的性能分析工具(Profiler),用于統計代碼中各個函數的執行時間、調用次數等詳細信息,幫助開發者找出程序的性能瓶頸。
主要功能特點包括:
- 統計每個函數的調用次數和時間:記錄函數的總執行時間(包括子函數調用)和單獨執行時間(不包括子函數)。
- 生成性能報告:以表格形式輸出結果,方便分析熱點代碼。
- 低開銷:相比 profile 模塊(純 Python 實現),cProfile 是 C 語言實現的,對程序運行速度影響較小。
使用-m參數調用cProfile模塊,按照累計運行時間降序排列-s cumtime,結果重定向至mandelbrot_cProfile.txt文件。
$ ../bin/python -m cProfile -s cumtime mandelbrot.py > mandelbrot_cProfile.txt最終結果輸出前20行可以得知,mandelbrot.py:10(simple_mandelbrot)就調用了1次,耗時4.016秒,為tottime指標最高的單一函數。
$ head -20 mandelbrot_cProfile.txt
It took 4.01598596572876 seconds to calculate the Mandelbrot graph.
It took 0.10479903221130371 seconds to dump the image.1272295 function calls (1250243 primitive calls) in 4.610 secondsOrdered by: cumulative timencalls tottime percall cumtime percall filename:lineno(function)65/2 0.000 0.000 4.503 2.252 text.py:926(get_window_extent)101/2 0.002 0.000 4.503 2.252 text.py:358(_get_layout)1 4.016 4.016 4.016 4.016 mandelbrot.py:10(simple_mandelbrot)32 0.001 0.000 0.632 0.020 __init__.py:1(<module>)349/7 0.001 0.000 0.424 0.061 <frozen importlib._bootstrap>:1349(_find_and_load)346/7 0.001 0.000 0.424 0.061 <frozen importlib._bootstrap>:1304(_find_and_load_unlocked)331/7 0.001 0.000 0.423 0.060 <frozen importlib._bootstrap>:911(_load_unlocked)PS: tottime(直接運行時間)表示函數本身運行的時間,不包括調用其他函數的時間,它是函數內部執行代碼的時間總和,不考慮子函數的執行時間。而 cumtime(累積運行時間)表示函數及其所有子函數運行的總時間,它包括函數本身的時間(tottime)加上所有被該函數調用的子函數的時間總和。
2.2.2 逐行耗時分析性能瓶頸
cProfile模塊最小粒度為函數,如果想逐行分析,可以使用line_profiler模塊。
line_profiler 是一個第三方庫,可以顯示每行代碼的執行時間、次數和耗時占比。
首先安裝該模塊:
$ ../bin/pip install line_profiler
Collecting line_profilerDownloading line_profiler-4.2.0-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (34 kB)
Downloading line_profiler-4.2.0-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (720 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 720.1/720.1 kB 3.9 MB/s eta 0:00:00
Installing collected packages: line_profiler
Successfully installed line_profiler-4.2.0然后在需要分析的函數名稱前加上@profile裝飾器。
@profile
def simple_mandelbrot(width, height, real_low, real_high, imag_low, imag_high, max_iters, upper_bound):real_vals = np.linspace(real_low, real_high, width)imag_vals = np.linspace(imag_low, imag_high, height)...最后使用kernprof命令行工具運行腳本,-l 表示逐行分析,-v 表示運行后立即顯示結果。
~/Desktop/EXAMPLES/02$ ../bin/kernprof -l -v mandelbrot.py
It took 8.354495286941528 seconds to calculate the Mandelbrot graph.
It took 0.07214522361755371 seconds to dump the image.
Wrote profile results to mandelbrot.py.lprof
Timer unit: 1e-06 sTotal time: 6.02906 s
File: mandelbrot.py
Function: simple_mandelbrot at line 9Line # Hits Time Per Hit % Time Line Contents
==============================================================9 @profile 10 def simple_mandelbrot(width, height, real_low, real_high, imag_low, imag_high, max_iters, upper_bound):11 1 57.4 57.4 0.0 real_vals = np.linspace(real_low, real_high, width)12 1 16.5 16.5 0.0 imag_vals = np.linspace(imag_low, imag_high, height)13 14 # we will represent members as 1, non-members as 0.15 1 274.7 274.7 0.0 mandelbrot_graph = np.ones((height, width), dtype=np.float32)16 17 513 53.5 0.1 0.0 for x in range(width):18 262656 28811.2 0.1 0.5 for y in range(height):19 262144 306395.3 1.2 5.1 c = np.complex64(real_vals[x] + imag_vals[y] * 1j)20 262144 75984.6 0.3 1.3 z = np.complex64(0)21 22 7282380 791951.4 0.1 13.1 for i in range(max_iters):23 7257560 1193944.6 0.2 19.8 z = z ** 2 + c24 25 7257560 3568029.4 0.5 59.2 if np.abs(z) > upper_bound:26 237324 40273.0 0.2 0.7 mandelbrot_graph[y, x] = 027 237324 23266.9 0.1 0.4 break28 29 1 1.0 1.0 0.0 return mandelbrot_graph使用line_profiler模塊會拖慢函數,從3秒慢到了8秒。運行結果是函數逐行的耗時,其中: - Hits:該行執行次數 - Time:該行總耗時(微秒) - % Time:該行占函數總耗時的百分比。
耗時最多的三行,功能分別是控制每個像素點的迭代次數(max_iters 次)、曼德勃羅集的迭代公式(復數運算)、和檢查曼德勃羅集(Mandelbrot)的逃逸條件(判斷復數 z 的模是否超過閾值 upper_bound),耗時多的原因是執行次數過多,各執行了7,257,560 次,每次都要運行復數平方運算(z ** 2)和復數的模(np.abs(z))需要浮點計算。
for i in range(max_iters):z = z ** 2 + cif np.abs(z) > upper_bound:這三行代碼的運算時間之和占整體的92.1%,如果優化這里可以顯著降低算法運行時間,提高效率。
2.3 PyCUDA之gpuarray顯卡跑算法
2.3.1 “Hello World”
跟任意GPT要個gpuarray的“Hello World”代碼,可以得到類似如下代碼。注釋部分也是GPT添加的。
import numpy as np
#自動內存管理:使用 pycuda.autoinit 自動管理CUDA上下文,簡化了代碼,適合簡單的腳本。
import pycuda.autoinit
#PyCUDA 提供了類似 NumPy 的接口,使得在 GPU 上進行數組操作非常直觀和方便。
from pycuda import gpuarray
#創建主機數組:使用 NumPy 創建一個數組 host_data,包含元素 [1, 2, 3, 4, 5],數據類型為 float32。dtype=np.float32 確保數組的數據類型為單精度浮點數,這對于GPU計算很重要,因為 GPU 在處理浮點數時通常更高效。確保主機數組和GPU數組的數據類型一致(如 float32)可以避免潛在的錯誤和性能問題。
host_data = np.array([1,2,3,4,5] , dtype=np.float32)
#將主機數組傳輸到 GPU:使用 gpuarray.to_gpu() 方法將主機數組 host_data 傳輸到 GPU 上,并存儲在 device_data 中。device_data 現在是一個GPU數組,存儲在 GPU 的顯存中。
device_data=gpuarray.to_gpu(host_data)
#在 GPU 上進行逐元素乘法操作:使用 2 * device_data 對 GPU 數組 device_data 中的每個元素乘以 2。這個操作在 GPU 上并行執行,速度比在 CPU 上逐元素操作快得多。結果存儲在新的 GPU 數組 device_data_x2 中。
device_data_x2 = 2 * device_data
#將結果從 GPU 傳輸回主機,使用 .get() 方法將 GPU 數組 device_data_x2 中的數據傳輸回主機內存,并存儲在 host_data_x2 中。host_data_x2 是一個 NumPy 數組,包含操作后的結果。
host_data_x2=device_data_x2.get()
print(host_data_x2)運行一下,得到如下結果:
$ ../bin/python gpuarray.py
[ 2. 4. 6. 8. 10.]這是我們第一段在顯卡上直接運行代碼。
需要注意的是,向顯卡發送數據時,需要通過NumPy顯示聲明數據類型。這樣做的好處有兩個:
- 避免類型轉換帶來不必要的開銷,消耗更多的計算時間或內存;
- 后續會用CUDA C語言來內聯編寫代碼,必須為變量聲明規定具體的類型,否則C代碼無法工作,畢竟C是編譯型語言
2.3.2 GPU和CPU工作原理的差異
前文的案例中,逐元素乘以常量的操作,是可以并行化運行的,因為一個元素的計算并不依賴其他任何元素的計算結果。
所以在gpuarray的線程上執行該操作時,PyCUDA可以將乘法操作轉移至一個個單獨的線程上,而不用像CPU一樣一個接一個地串行計算。這也是GPU高吞吐的原因,CPU則是高性能。
- 可以將GPU類比于迅雷,每秒下載幾兆的數據,倘若有延遲一兩秒大家也不關心,大家更關心傳輸量大,此處“網很快、下載得快”的意思就是吞吐大,每秒多少兆。
- CPU類似于打網絡游戲,延遲一般要求低于30ms,倘若延遲大于200ms網絡游戲就幾乎沒有體驗可言了,技能釋放慢個幾百毫秒結果就完全不同,但是絲毫不關心吞吐量,此處“網絡很快”的意思就是延遲極低。
日常使用電腦的過程中,主要追求的也是低延遲。鼠標拖動的時候,肉眼不可以看到停頓,鍵盤按下去屏幕上立刻出現字符,桌面快捷方式雙擊后,程序窗口要立即出現,在程序之間切換要流暢自如毫無拖沓。
而什么場景需要顯卡呢?典型場景,也是顯卡迄今為止最為主要的工作內容,就是游戲畫面渲染,一草一木、光影追蹤,游戲兩個最為核心的指標,畫質和幀率,也就是渲染的畫面的質量(像素點的多少)和每秒可以渲染多少張,此時評價顯卡很快的意思就是,每秒出的圖又細又多,也就是高吞吐。每秒出10張480p的圖,相比每秒出100張1080p的圖,玩的游戲體驗不在一個次元上。
再來看一段GPU和CPU跑相同算法的速度對比。編寫一段代碼(time_calc.py),分別在CPU和GPU上運行同樣的常量乘法計算,對比執行速度。
import numpy as np
import pycuda.autoinit
from pycuda import gpuarray
from time import time
#創建五千萬個隨機單精度浮點數
host_data = np.float32(np.random.random(50000000))
#CPU計算耗時
t1 = time()
host_data_2x = host_data * np.float32(2)
t2 = time()
print('total time to compute on CPU: %f' % (t2 - t1))
#傳輸到顯卡進行計算耗時
device_data = gpuarray.to_gpu(host_data)
t1 = time()
device_data_2x = device_data * np.float32(2)
t2 = time()
#數據從顯卡傳回主機
from_device = device_data_2x.get()
#比較 CPU 和 GPU 的計算結果是否相同
print('total time to compute on GPU: %f' % (t2 - t1))
print('Is the host computation the same as the GPU computation? : {}'.format(np.allclose(from_device, host_data_2x)))在筆者機器i5-13490F、RTX5060ti 12G上運行三次,對比差異:
$ ../bin/python time_calc.py
total time to compute on CPU: 0.043279
total time to compute on GPU: 0.058837
Is the host computation the same as the GPU computation? : True
$ ../bin/python time_calc.py
total time to compute on CPU: 0.047776
total time to compute on GPU: 0.058785
Is the host computation the same as the GPU computation? : True
$ ../bin/python time_calc.py
total time to compute on CPU: 0.046850
total time to compute on GPU: 0.057116
Is the host computation the same as the GPU computation? : True可以發現CPU的速度幾乎和GPU一樣的快,這是什么原因呢?因為NumPy可以利用現代CPU中的SSE指令來加速計算,在某些場景中性能可以與GPU相媲美。
可以把浮點數的個數設置成五億個:
host_data = np.float32(np.random.random(500000000))再運行三次對比差異:
$ ../bin/python time_calc.py
total time to compute on CPU: 0.437335
total time to compute on GPU: 0.263772
Is the host computation the same as the GPU computation? : True
$ ../bin/python time_calc.py
total time to compute on CPU: 0.436809
total time to compute on GPU: 0.056556
Is the host computation the same as the GPU computation? : True
$ ../bin/python time_calc.py
total time to compute on CPU: 0.438307
total time to compute on GPU: 0.060931
Is the host computation the same as the GPU computation? : True可以看到在第二次、第三次運行時,GPU的耗時約為CPU的十分之一,并行提速效果顯著。可以推理得到倘若數據量更大會提速更多。
那為什么第一次GPU耗時偏多呢?因為PyCUDA編寫的代碼中的CUDA邏輯部分第一次運行時需要使用NVCC編譯器編譯成字節碼,以供PyCUDA調用,所以第一次運行時間會長一些;后續再次調用時,如果代碼沒有修改,則直接使用已經編譯好的緩存即可,這與我們玩一些3A大作的游戲,第一次運行需要進行“著色器編譯”是相同的原理。
2.4 PyCUDA之內聯CUDA C算法提速
對gpuarray對象進行操作,默認會在純GPU上執行,上一節對元素乘以2時,這個對象2會傳輸到GPU上,由GPU在顯存中創建對象,在顯卡的核心上并行計算。
如果操作涉及gpuarray與主機數據(或變量如numpy數組)的混合運算,PyCUDA會報錯,因為它無法隱式決定數據位置。比如:
# 會報錯!不能直接混合gpuarray和CPU創建的numpy數組
device_data_2x = device_data * np.ones(100)必須顯式將數據放置在純GPU(或純CPU)上。那具體代碼如何寫呢?這里就可以引入ElementwiseKernel函數,直接內聯CUDA C代碼編程,追求最為設備原生的高性能。下面上案例(simple_element_kernel_example0.py):
import numpy as np
import pycuda.autoinit
from pycuda import gpuarray
from time import time
#用于創建元素級操作的CUDA內核
from pycuda.elementwise import ElementwiseKernel
host_data = np.float32(np.random.random(500000000))
# 定義一個CUDA元素級內核:輸入參數:兩個float指針(in和out),操作:將輸入數組的每個元素乘以2,結果存入輸出數組,內核名稱:"gpu_2x_ker"
gpu_2x_ker = ElementwiseKernel("float *in, float *out","out[i] = 2*in[i];","gpu_2x_ker"
)
def speedcomparison():t1 = time()host_data_2x = host_data * np.float32(2)t2 = time()print('total time to compute on CPU: %f' % (t2 - t1))device_data = gpuarray.to_gpu(host_data)# 在GPU上分配與輸入數組大小相同的空輸出數組device_data_2x = gpuarray.empty_like(device_data)t1 = time()# 調用之前定義的CUDA內核在GPU上執行計算gpu_2x_ker(device_data, device_data_2x)t2 = time()from_device = device_data_2x.get()print('total time to compute on GPU: %f' % (t2 - t1))print('Is the host computation the same as the GPU computation? : {}'.format(np.allclose(from_device, host_data_2x)))
if __name__ == '__main__':speedcomparison()這樣包括輸入的所有參數、運算符和輸出,都是在純GPU的設備里操作,達到設備級別的原生高性能。同樣多運行幾次,觀察速度差異:
$ ../bin/python simple_element_kernel_example0.py
total time to compute on CPU: 0.431743
total time to compute on GPU: 0.565969
Is the host computation the same as the GPU computation? : True
$ ../bin/python simple_element_kernel_example0.py
total time to compute on CPU: 0.436628
total time to compute on GPU: 0.062304
Is the host computation the same as the GPU computation? : True
$ ../bin/python simple_element_kernel_example0.py
total time to compute on CPU: 0.433212
total time to compute on GPU: 0.055214
Is the host computation the same as the GPU computation? : True同樣可以觀察到與前文一樣的現象,首次運行CUDA C部分需要先用NVCC編譯,再次運行速度才會獲得顯著提升。
PS:思考:前文的混合運算這樣寫:device_data_2x = device_data * device_data,可以嗎?答案是可以的,這表示兩個GPU數組(gpuarray)之間的逐元素乘法,PyCUDA會將乘法運算符轉成CUDA C的乘法,這個操作會完全在純GPU上并行執行。
2.5 純GPU重構算法比CPU快五十倍
那最后的任務就是把耗時占92.1%的以下三行代碼用CUDA C重寫,使之充分利用顯卡并行計算大吞吐的特性,進行充分的加速。
for i in range(max_iters):z = z ** 2 + cif np.abs(z) > upper_bound:算法開發和移植是當前工資最高的工作,可惜我不會,我只能問GPT。可悲的是,如果不會算法,連怎么調試,生成的結果對不對,模型有沒有出現幻覺,都無法判斷,畢竟在算法這個領域,GPT的能力大于自己。
幸虧我們的案例來自書籍,有作者調好的版本,同功能的CUDA C算法實現如下,可以說與Python的寫法幾乎一模一樣:
mandelbrot_graph[i] = 1;
pycuda::complex<float> c = lattice[i];
pycuda::complex<float> z(0,0);
for (int j = 0; j < max_iters; j++)
{z = z*z + c; if(abs(z) > upper_bound){mandelbrot_graph[i] = 0;break;}
}同樣算法的各種參數也需要改變:
def gpu_mandelbrot(width, height, real_low, real_high, imag_low, imag_high, max_iters, upper_bound):# we set up our complex lattice as suchreal_vals = np.matrix(np.linspace(real_low, real_high, width), dtype=np.complex64)imag_vals = np.matrix(np.linspace(imag_high, imag_low, height), dtype=np.complex64) * 1jmandelbrot_lattice = np.array(real_vals + imag_vals.transpose(), dtype=np.complex64) # copy complex lattice to the GPU#gpuarray.to_gpu函數只能處理NumPy的array類型,所以發送到GPU之前要進行包裝;mandelbrot_lattice_gpu = gpuarray.to_gpu(mandelbrot_lattice)# allocate an empty array on the GPU#gpuarray.empty函數在GPU上分配內存,指定大小、形狀及類型,可以看作是C語言中的malloc函數;比C的優點是不需要惦記內存釋放或回收,因為gpuarray對象在析構時會自動清理。mandelbrot_graph_gpu = gpuarray.empty(shape=mandelbrot_lattice.shape, dtype=np.float32)#注意CUDA C里的模板類型pycuda::complex和Python代碼里的NumPy的Complex64是對應的,否則參數傳遞過去是無法解析的。比如CUDA C的int類型對應NumPy的int32類型,CUDA C的float類型對應NumPy的float32類型。另外,數組傳遞給CUDA C時,會被視為C指針。mandel_ker(mandelbrot_lattice_gpu, mandelbrot_graph_gpu, np.int32(max_iters), np.float32(upper_bound)) mandelbrot_graph = mandelbrot_graph_gpu.get() return mandelbrot_graph與原來的純Python相比邏輯是一樣的,只是多了各種數據格式的轉換和映射,最后就是激動人心的測速環節,還是i5-13490F、RTX5060ti 12G的機器:
~/Desktop/EXAMPLES/02$ ../bin/python gpu_mandelbrot.py
It took 0.1877138614654541 seconds to calculate the Mandelbrot graph.
It took 0.09330153465270996 seconds to dump the image.
~/Desktop/EXAMPLES/02$ ../bin/python gpu_mandelbrot.py
It took 0.05863165855407715 seconds to calculate the Mandelbrot graph.
It took 0.07119488716125488 seconds to dump the image.
~/Desktop/EXAMPLES/02$ ../bin/python gpu_mandelbrot.py
It took 0.062407732009887695 seconds to calculate the Mandelbrot graph.
It took 0.06969809532165527 seconds to dump the image.同理第一次運行,是NVCC編譯花了一些時間,后面穩定在0.06秒左右的水平,從3.53秒到0.06秒,大概是59倍的性能提升。
當然,需要對比確認下生成的PNG圖片是一致的。本章節的任務成功完成。通過這個實驗相信大家對GPU特性的理解可以說是非常深刻了。
PS:最后又讓deepseek幫助優化了一下代碼,執行ds優化后的版本,生成同樣的圖,速度降到了0.0036秒,是書中代碼的1/20,可見,優化是深不見底的學問。

- 代碼等附件下載地址:https://github.com/r0ysue/5060STUDY
引用來源: - 《GPU編程實戰(基于Python和CUDA)》、deepseek






)


詳細步驟)




)
)



 和 Pearson相似度 (Pearson Correlation))