文章目錄
- 5. RAG的架構
- 5.1 Naive RAG
- 5.2 Advanced RAG
- 5.2.1 檢索前處理和數據索引技術
- 5.2.2 知識分片技術
- 5.2.3 分層索引
- 5.2.4 檢索技術
- 5.2.4.1 優化用戶查詢
- 5.2.4.2 通過假想文檔嵌入修復查詢和文檔不對稱
- 5.2.4.3 Routing
- 5.2.4.5 自查詢檢索
- 5.2.4.6 混合搜索
- 5.2.4.7 圖檢索
- 5.2.4.8 微調嵌入模型
- 5.2.5 檢索后技術
- 5.2.5.1 通過重新排名確定搜索的優先級
- 5.2.5.2 使用上下文提示壓縮優化搜索結果
- 5.2.5.3 Corrective RAG
- 5.2.5.4 擴展查詢
- 5.2.6 生成技術
- 5.2.6.1 思維鏈
- 5.2.6.2 通過 Self-RAG 使系統具備自我反思能力
- 5.2.6.3 微調LLM
- 5.3 模塊化RAG
- 5.3.1 模塊化RAG系統組成
- 5.3.2 模塊化RAG的工作流程
- 5.3.3 模塊化RAG的優勢
- 5.3.4 模塊化RAG的挑戰
本篇是 【RAG】RAG綜述|一文了解RAG|從零開始(下)的后續,重點講解RAG的結構與重點技術。
5. RAG的架構
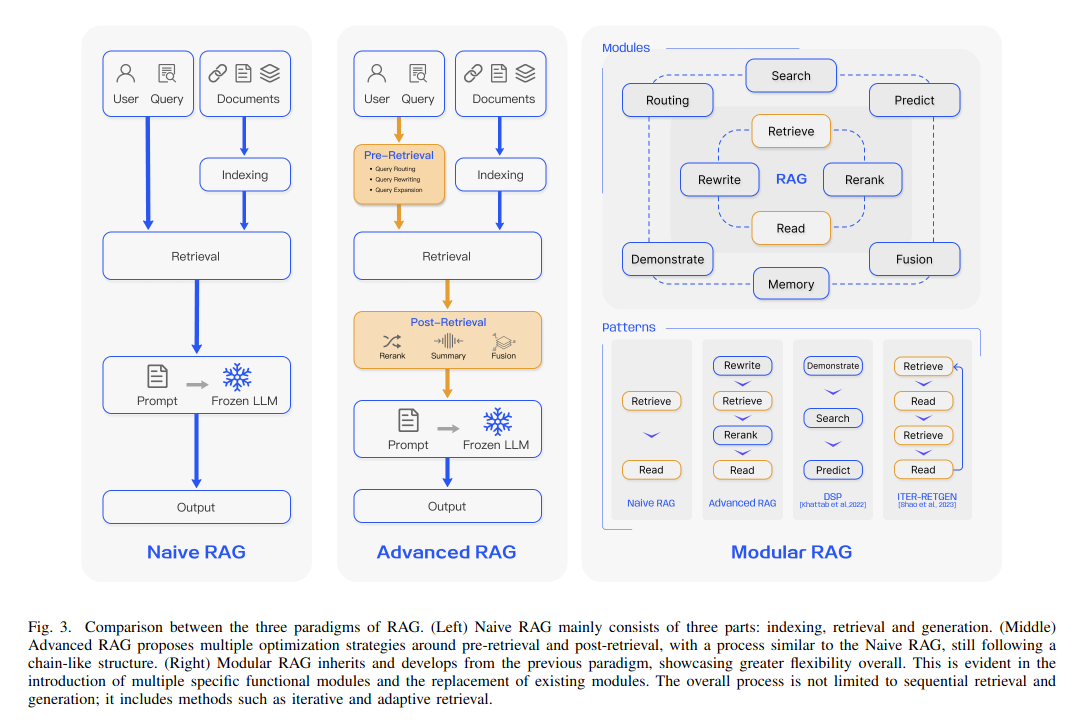
5.1 Naive RAG
這是最簡單的RAG架構,其工作流程為:
- 用戶查詢
- 檢索信息
- 利用prompt技術增強
- 將prompt輸入到LLM生成結果
5.2 Advanced RAG
相比于樸素RAG,高級RAG主要優化了索引步驟和生成步驟。高級RAG技術提高了信息檢索和后續內容生成的效率、準確性和相關性。
高級RAG涉及的主要技術:檢索前處理和數據索引技術、知識分片技術、檢索技術、后檢索技術和生成技術。
5.2.1 檢索前處理和數據索引技術
檢索前處理側重在數據進入向量庫或知識圖譜之前提高數據的質量。干凈、格式良好的數據可以提高檢索數據的質量,而嘈雜的數據會顯著降低檢索結果,從而更容易導致LLM幻覺的產生。
預處理數據的常見方法:
- 增加信息密度:可以通過LLM對查詢進行改寫,總結、提取或清理后查詢信息密度更高。
- 刪除數據中的重復信息:同樣能用LLM對查詢進行去重,輸出LLM更容易理解、更簡潔的查詢語句。
- 使用假設問題索引提高索引對稱性
- 使用語言模型為數據庫中每個數據塊生成一個或多個問題,并將它們與文檔塊一起存儲。這些問題可用于索引。
- 在檢索的時候,用戶查詢在語義上與模型生成的所有問題匹配。然后索引與用戶查詢類似的問題,然后將與檢索問題關聯的文檔塊傳遞給LLM以生成響應。
5.2.2 知識分片技術
知識分片就是將大文檔分解成較小的文本塊,以便更高效的進行檢索和生成。這些較小的文本塊,稱為chunk,它可以是段落,句子,子句或短語,具體取決于實際應用需求。
常見的分片技術有:
- 基于文本長度的切塊:例如固定300個詞或500個字符對文本進行切分。
- 滑動窗口技術:這種方法通過在連續的文本塊之間使用重疊區域來進行切塊,確保每個塊都可以包含部分上下文信息。這在需要上下文連貫性的應用中非常有用,比如生成模型需要更大的上下文信息來生成準確的內容。
- 基于句子的切塊:按句子對文本進行切分,適用于短且結構簡單的文檔。
- 基于語義的切塊:可以根據章節、段落、主題或關鍵字進行切分。這種切分出來的塊更具有語義一致性。
- 自然語言處理技術:通過分句、分詞、主題建模等NLP技術對文本進行切分。好處就是能用NLP技術識別到文本中的語義邊界,使得切出來的塊更具語義。
關于chunk優化的代碼實踐:https://blog.csdn.net/2401_85325557/article/details/143359056
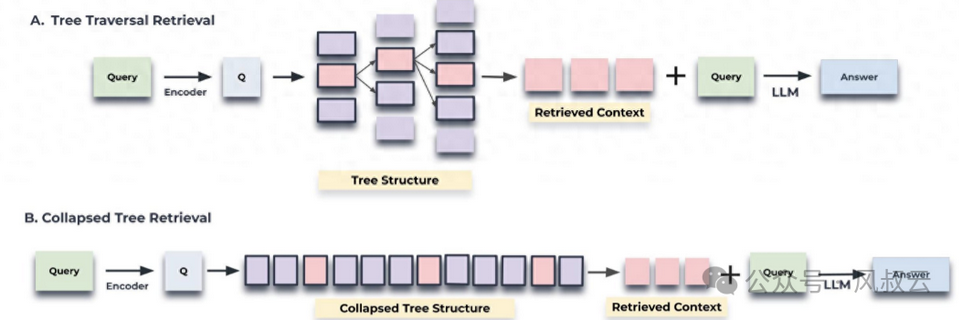
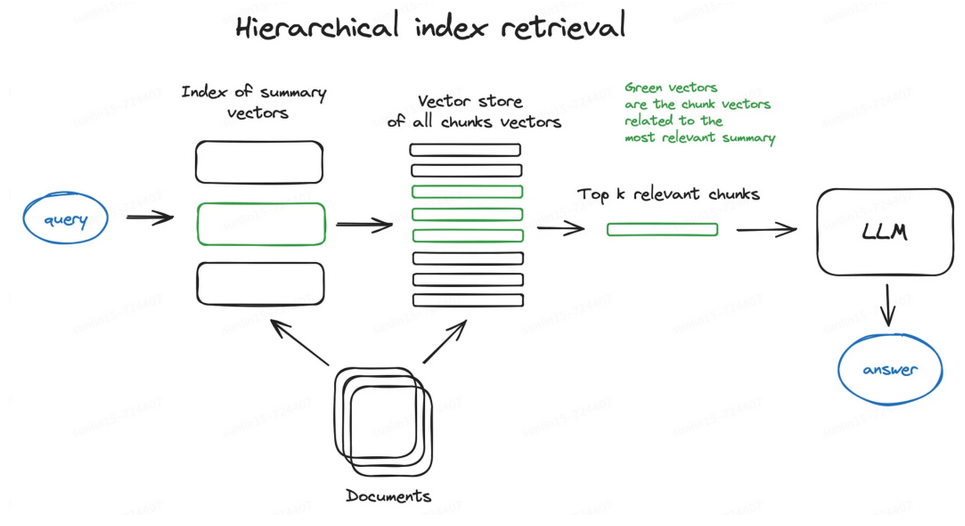
5.2.3 分層索引
使用分層索引來提高RAG應用程序的精度。在這種方法中,數據被組織成一個分層結構,信息根據相關性和關系進行分類和子分類。
檢索過程從較寬的數據塊或父節點開始,然后再鏈接到所選父節點的較小數據塊或子節點中進行更集中的搜索。分層索引不僅可以提高檢索效率,還可以最大限度減少最終輸出中包含不相關的數據。
5.2.4 檢索技術
5.2.4.1 優化用戶查詢
該技術將用戶的查詢重構為LLM更容易理解且檢索器更容易使用的格式。技術實現上可通過微調的語言模型處理用戶查詢,以優化和構建它。此過程會刪除任何不相關的上下文并添加必要的元數據,從而確保查詢針對底層數據存儲進行定制。
例子:
原始:who was the director of the Godfather?
LLM處理后:(Movice: “The Godfather” …)
5.2.4.2 通過假想文檔嵌入修復查詢和文檔不對稱
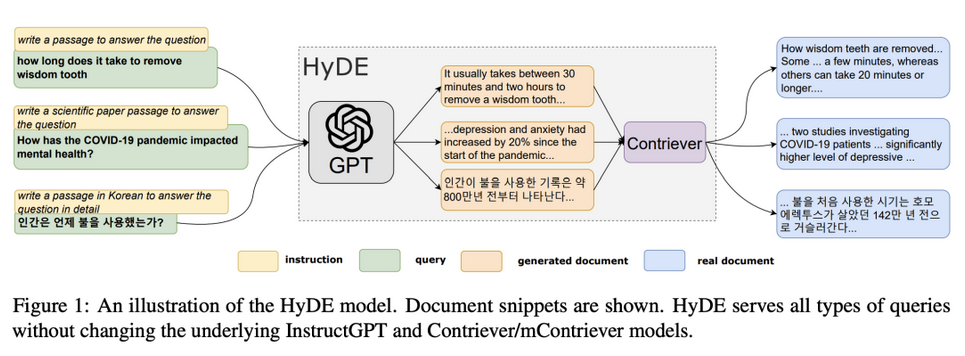
假想文檔嵌入(HyDE)技術是一個新穎且強大的方法。它通過生成一個假想的文檔來增強查詢的檢索效果,再通過嵌入向量查找與假想文檔相似的實際文檔,從而實現更高效的檢索。
在傳統的檢索增強生成(RAG)架構中,用戶的查詢直接用于查找文檔。然而,這種方式可能會受到語義偏差的影響,導致檢索效果不佳。
)






)

:STUN服務和TURN服務的作用)


)






