前言
我在上一篇文章中介紹了 RNN,它是一個隱變量模型,主要通過隱藏狀態連接時間序列,實現了序列信息的記憶與建模。然而,RNN在實踐中面臨嚴重的“梯度消失”與“長期依賴建模困難”問題:
- 難以捕捉相隔很遠的時間步之間的關系
- 隱狀態在不斷更新中容易遺忘早期信息。
為了解決這些問題,LSTM(Long Short-Term Memory)?網絡于 1997 年被 Hochreiter等人提出,該模型是對RNN的一次重大改進。
一、LSTM相比RNN的核心改進
接下來,我們通過對比RNN、LSTM,來看一下具體的改進:
| 模型 | 特點 | 優勢 | 缺點 |
| RNN | 單一隱藏轉態,時間步傳遞 | 結構簡答 | 容易造成梯度消失/爆炸,對長期依賴差 |
| LSTM | 多門控機制 + 單獨的“記憶單元” | 解決長距離依賴問題,保留長期信息 | 結構復雜,計算開銷大 |
通過對比,我們可以發現,其實LSTM的核心思想是:引入了一個專門的“記憶單元”,在通過門控機制對信息進行有選擇的保留、遺忘與更新。
二、LSTM的核心結構
LSTM的核心結構如下圖所示:
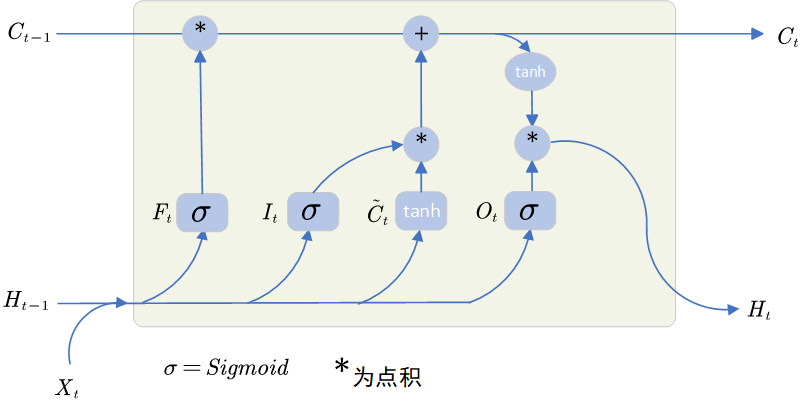
?如圖可以輕松的看出,LSTM主要由門控機制和候選記憶單元組成,對于每個時間步,LSTM都會進行以下操作:
1. 忘記門
忘記門()主要的作用是:控制保留多少之前的記憶:
2. 輸入門
輸入門()主要的作用是:決定當前輸入中哪些信息信息被寫入記憶:
3. 候選記憶單元
4. 輸出門
輸出門()的作用是:決定是是否使用隱狀態:
5. 真正記憶單元
記憶單元(??)用于長期存儲信息,解決RNN容易遺忘的問題:
7. 隱藏轉態
LSTM引入了專門的記憶單元?
??,長期存儲信息,解決了傳統RNN容易遺忘的問題。
三、手寫LSTM
通過上面的介紹,我們現在已經知道了LSTM的實現原理,現在,我們試著手寫一個LSTM核心層:
首先,初始化需要訓練的參數:
import torch
import torch.nn as nn
import torch.nn.functional as Fdef params(input_size, output_size, hidden_size):W_xi, W_hi, b_i = torch.randn(input_size, hidden_size) * 0.1, torch.randn(hidden_size, hidden_size) * 0.1, torch.zeros(hidden_size)W_xf, W_hf, b_f = torch.randn(input_size, hidden_size) * 0.1, torch.randn(hidden_size, hidden_size) * 0.1, torch.zeros(hidden_size)W_xo, W_ho, b_o = torch.randn(input_size, hidden_size) * 0.1, torch.randn(hidden_size, hidden_size) * 0.1, torch.zeros(hidden_size)W_xc, W_hc, b_c = torch.randn(input_size, hidden_size) * 0.1, torch.randn(hidden_size, hidden_size) * 0.1, torch.zeros(hidden_size)W_hq = torch.randn(hidden_size, output_size) * 0.1b_q = torch.zeros(output_size)params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q]for param in params:param.requires_grad = Truereturn params
接著,我們需要初始化0時刻的隱藏轉態:
import torchdef init_state(batch_size, hidden_size):return (torch.zeros((batch_size, hidden_size)), torch.zeros((batch_size, hidden_size)))
然后, 就是LSTM的核心操作:
import torch
import torch.nn as nn
def lstm(X, state, params):[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = params(H, C) = stateoutputs = []for x in X:I = torch.sigmoid(torch.mm(x, W_xi) + torch.mm(H, W_hi) + b_i)F = torch.sigmoid(torch.mm(x, W_xf) + torch.mm(H, W_hf) + b_f)O = torch.sigmoid(torch.mm(x, W_xo) + torch.mm(H, W_ho) + b_o)C_tilde = torch.tanh(torch.mm(x, W_xc) + torch.mm(H, W_hc) + b_c)C = F * C + I * C_tildeH = O * torch.tanh(C)Y = torch.mm(H, W_hq) + b_qoutputs.append(Y)return torch.cat(outputs, dim=1), (H, C)四、使用Pytroch實現簡單的LSTM
在Pytroch中,已經內置了lstm函數,我們只需要調用就可以實現上述操作:
import torch
import torch.nn as nnclass mylstm(nn.Module):def __init__(self, input_size, output_size, hidden_size):super(mylstm, self).__init__()self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x, h0, c0):out, (hn, cn) = self.lstm(x, h0, c0)out = self.fc(out)return out, (hn, cn)# 示例
input_size = 10
hidden_size = 20
output_size = 10
batch_size = 1
seq_len = 5
num_layer = 1 # lstm堆疊層數h0 = torch.zeros(num_layer, batch_size, hidden_size)
c0 = torch.randn(num_layer, batch_size, hidden_size)
x = torch.randn(batch_size, seq_len, hidden_size)model = mylstm(input_size=input_size, hidden_size=hidden_size, output_size=output_size)out, _ = model(x, (h0, c0))
print(out.shape)總結
在現實中,LSTM的實際應用場景很多,比如語言模型、文本生成、時間序列預測、情感分析等長序列任務重,這是因為相比于RNN而言,LSTM能夠更高地捕捉長期依賴,而且也更好的緩解了梯度消失問題;但是由于LSTM引入了三個門控機制,導致參數量比RNN要多,訓練慢。
總的來說,LSTM是對傳統RNN的一次革命性升級,引入門控機制和記憶單元,使模型能夠選擇性地記憶與遺忘,從而有效地捕捉長距離依賴。盡管LSTM近年來Transformer所取代,但LSTM依然是理解深度學習序列模型不可繞開的一環,有時在其他任務上甚至優于Transformer。
如果小伙伴們覺得本文對各位有幫助,歡迎:👍點贊 |?? 收藏 | ?🔔 關注。我將持續在專欄《人工智能》中更新人工智能知識,幫助各位小伙伴們打好扎實的理論與操作基礎,歡迎🔔訂閱本專欄,向AI工程師進階!
)











)





認證)
