
近年來,社交媒體趨勢分析逐漸成為品牌監控、市場洞察和消費者研究的必備工具。而當談到全球趨勢數據分析,很多人都會立即想到 Twitter趨勢(逼近連美麗國的總統都喜歡在上面發表自己的看法- -!!!)。Twitter趨勢,即Twitter提供的熱門話題榜單,透過其中的關鍵詞或話題標簽(#tag),你可以快速了解當前全球用戶關注的焦點。因此,分析這些數據,能夠為市場營銷、輿情監控、品牌競爭研究等提供基礎信息。
但埋頭獲取趨勢數據,并不像看起來那么簡單。一旦讓Twitter檢測到異常采集行為,你的賬號訪問權限可能會被凍結。因此,我們需要采用Python結合海外代理IP,高效獲取數據。
所以今天,我要分享的是:通過海外代理IP與Python的力量,如何一步步完成Twitter趨勢數據的抓取和分析。
在開始前特別說明,我們此次內容是合法與合規的學習和技術探討,獲取和分析數據時,應嚴格遵守相關網站的服務協議與數據隱私法律。
一、為什么需要海外代理IP?
在進行社交數據采集時,你的關鍵是:穩定性與可用率。如果只有一臺采集設備,想獲取大量數據,往往會面臨訪問頻率限制,但通過高質量的海外代理IP,你可以輕松解決這一難題。
1.使用海外代理IP有哪些好處?
-
完整性:獲取特定地區的數據(如美國、印度或英國等國家的趨勢話題)。
-
穩定性:避免因高并發請求導致本地IP被暫時限制。
-
精準性:確保收集的數據來源于目標區域,提高數據分析的有效性。
2.為什么是青果網絡海外代理IP?
-
行業領先的技術架構:支持全球200+城市的精準IP定位,資源池覆蓋2000萬級以上純凈IP資源池,可無縫切換不同地區網絡環境,滿足跨境電商、市場調研等場景的地域模擬需求;
-
自研IP分池技術實現動態資源調度,使采集成功率比行業平均水平高出30%,支持大規模高并發場景的數據抓取、TikTok直播等高風控場景,避免因IP污染導致的封禁風險;
-
海外代理IP默認禁用中國大陸網絡環境接入,從源頭規避IP濫用風險,符合跨境業務合規要求,確保用戶在使用過程中不會遭遇風控預警,降低風險。
-
成本優勢顯著,設有不限流量計費模式,相比傳統按流量計費方案,有效規避了因流量超標而產生的高額費用風險,讓用戶能夠以更加經濟實惠的方式獲取穩定的代理 IP 服務,大幅降低了運營成本,大大提升了業務的經濟效益。
二、準備階段:必要的工具與環境
在開展Twitter趨勢數據分析工作之前,以下是您需要準備的幾樣基本工具與資源:
-
Python開發環境:Python是數據分析領域的主力語言,推薦安裝Anaconda,攜帶了豐富的科學計算庫。
-
代理IP服務商賬號:選擇自己可信賴的代理IP服務提供商。
-
相關Python第三方庫:
-
Pandas:用于處理數據表格。
-
Matplotlib和Seaborn:用于數據可視化。
-
通過安裝以下命令完成依賴庫的安裝:
pip install tweepy pandas matplotlib seaborn三、實戰操作
第一步:配置代理IP,連接目標地區
首先,為了確保腳本能通過特定地區IP訪問Twitter,我們需要配置代理。
import requests
?
# 青果網絡海外代理IP
proxy_url = "https://overseas.proxy.qg.net/get?key=yourkey&num=1&area=&isp=&format=txt&seq=\r\n&distinct=false"
?
# 測試代理是否可用
test_url = "https://httpbin.org/ip" # 用于顯示當前IP
response = requests.get(test_url, proxies=proxies)
print("當前IP為:", response.json())推薦使用API自動獲取可用IP地址,確保IP數據的動態性和穩定性。此外,在高并發數據采集中具有巨大優勢。
第2步:解析Twitter趨勢的HTML結構
研究Twitter數據的第一步始終是搞清楚網頁的結構。趨勢榜單是一個容器,所有的趨勢內容都嵌套在類似的HTML結構里,我們可以通過瀏覽器開發者工具(F12)檢查頁面的HTML結構。
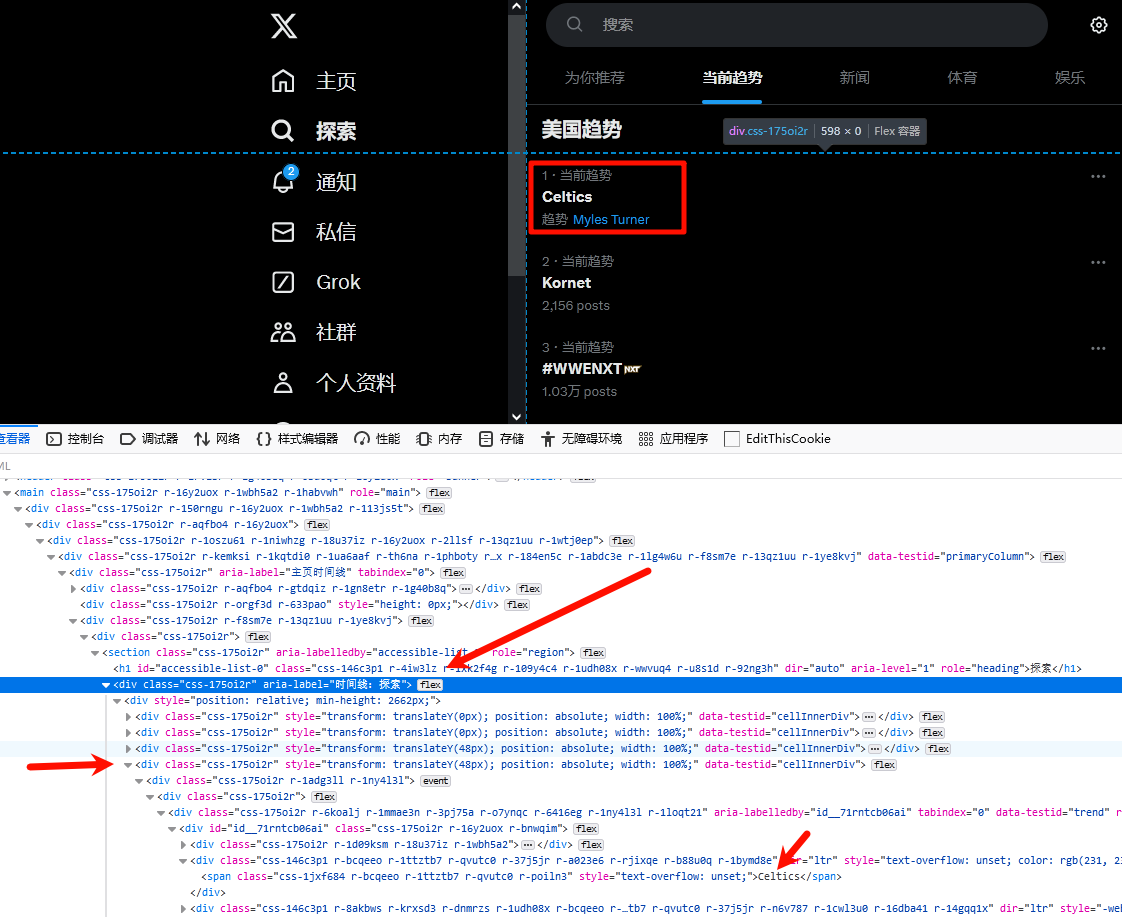
當你打開 Twitter 的“Explore”頁面,可以發現趨勢榜單的數據結構歸屬于一個 aria-label 屬性為“時間線:探索”的 div 節點下。通過XPath路徑解析,你可以輕松抓取到所需的趨勢數據。
趨勢板塊的所有內容,都嵌套于一個主容器節點中:
<div aria-label="時間線:探索"><!-- 包含所有趨勢信息的內容 -->
</div>
通過XPath路徑解析,我們進一步確認每一條趨勢關鍵字(如#WorldCup)位于<span>標簽中。以下便是提取趨勢內容的XPath://div[@aria-label="時間線:探索"]/div/div//div/div/div/div/div[2]/span簡化來說,這是我們抓取趨勢內容的入口!
第3步:撰寫爬蟲代碼,結合海外代理IP
下面是一個Python數據采集的小例子,在這里我們通過requests調用目標頁面,并結合代理IP來進行抓取。
核心代碼如下:
import requests as rq
from bs4 import BeautifulSoup
?
?
# 模擬瀏覽器頭
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/115.0",
}
?
# 目標URL
url = 'https://x.com/explore/tabs/keyword'
?
# 配置青果網絡海外代理IP
proxy = {'https://overseas.proxy.qg.net/get?key=yourkey&num=1&area=&isp=&format=txt&seq=\r\n&distinct=false',
}
?
# 定義頁面處理函數
def process_page(page_content):soup = BeautifulSoup(page_content, 'html.parser')trends = soup.select('div[aria-label="時間線:探索"] span')return [trend.get_text() for trend in trends]
?
# 請求頁面數據
try:response = rq.get(url, headers=headers, proxies=proxy)if response.status_code == 200:trend_data = process_page(response.content)print("抓取到的趨勢數據:", trend_data)else:print("請求失敗,狀態碼:", response.status_code)
except Exception as e:print("請求過程中出錯:", e)第四步:代理和多線程的配合使用
當批量抓取數據時,利用代理池和多線程請求可以極大提高效率:
import _thread
import time
?
def worker():# 重復調用爬蟲代碼流程response = rq.get(url, headers=headers, proxies=proxy)trend_data = process_page(response.content)print(trend_data) # 可進一步保存數據
?
for i in range(10): # 啟動10個線程_thread.start_new_thread(worker, ())time.sleep(0.2)
?
time.sleep(5) # 等待所有線程結束第五步:數據存儲與清洗
抓取的Twitter趨勢數據格式為JSON。為了直觀分析,我們需要將數據存儲為表格文件(如CSV格式)。
以下是將趨勢名稱及推文量導出到CSV的代碼:
import pandas as pd
# 示例數據清洗與存儲
trends_list = trends_result[0]["trends"]
trends_df = pd.DataFrame(trends_list)
trends_df = trends_df[["name", "tweet_volume"]].dropna() # 去除為空的列
# 導出到CSV文件
trends_df.to_csv("twitter_trends.csv", index=False)
print("數據已保存為twitter_trends.csv")注意,有時可能會存在缺失值或無效值,這時需要特別處理,比如剔除None,或者填充默認值。
第六步:數據可視化分析
數值不直觀?沒關系!我們可以用可視化工具直觀地展示不同話題的推文量以及趨勢之間的變化。
import matplotlib.pyplot as plt
import seaborn as sns
# 數據可視化
plt.figure(figsize=(10, 6))
top_trends = trends_df.sort_values("tweet_volume", ascending=False).head(10)
sns.barplot(x="tweet_volume", y="name", data=top_trends, palette="vlag")
plt.title("Twitter趨勢話題與推文量分析", fontsize=16)
plt.xlabel("推文量")
plt.ylabel("話題")
plt.show()通過圖表,很容易發現當前哪些話題在Twitter上形成了熱點,我們可以基于這些趨勢預測事件發展或制定內容策略。
第七步:實戰成果展示
| 主趨勢詞 | 熱度級別 | 國家/區域 |
|---|---|---|
| MoonLanding | 高熱 | 全球性 |
| Artificial Intelligence | 垂直趨勢 | 美國 |
| Messi Scores | 短期熱點 | 阿根廷 |
這樣的趨勢統計可以為用戶畫像分析、熱點話題營銷等實時決策提供數據支持。
四、總結
完成了Twitter趨勢數據的抓取與分析,我們該如何更好地優化這一流程?
-
代理池機制:使用動態代理IP池,避免單一代理IP使用的異常風險。青果網絡提供高度靈活的動態IP服務,適合此類需求。
-
擴展采集范圍:除了趨勢(Trending),也可以抓取更多字段數據,如某話題的評論互動,增加分析維度。
-
部署并行任務:通過分布式爬蟲技術提升效率,例如使用多線程模式抓取全球多個城市數據。
這就是關于利用海外代理IP完成Twitter趨勢數據分析的實戰內容。從工具準備,到代理配置,再到數據抓取及分析,是全鏈路的一次深入體驗。

”)

![[MMU]IOMMU的主要職能及詳細的驗證方案](http://pic.xiahunao.cn/[MMU]IOMMU的主要職能及詳細的驗證方案)


:語音識別輸入功能)

)

軟件及安裝教程)

)






)