![]()
計算機系統
大作業
題 ????目 ?程序人生-Hello’s P2P?
專?????? 業 ??計算機與電子通信類? ??
學 ?? 號 ???????2023112915??????
班 ?? 級 ???????23L0505?? ???????
學?????? 生 ???????楊昕彥? ?????????
指 導 教 師 ????????劉宏偉 ???????????
計算機科學與技術學院
2024年5月
摘? 要
本文詳細描述了“Hello”程序從源代碼到可執行文件的全生命周期,涵蓋了預處理、編譯、匯編、鏈接、運行及回收的各個階段。通過分析每個階段的具體操作和工具,深入探討了計算機系統的工作原理。文章首先介紹了預處理階段如何展開宏和頭文件,生成中間文件hello.i;接著闡述了編譯階段將hello.i轉換為匯編代碼hello.s的過程;隨后討論了匯編階段將hello.s匯編成目標文件hello.o的步驟;最后講解了鏈接階段如何將hello.o與庫文件合并生成可執行文件hello。在運行階段,文章詳細描述了Shell如何通過fork和execve創建并執行hello進程,并探討了虛擬地址到物理地址的轉換機制。此外,文章還分析了printf和getchar等函數的實現原理,揭示了Linux I/O設備管理的核心思想。通過這一系列步驟,文章展示了計算機系統從源代碼到硬件執行的復雜流程,強調了理論與實踐結合的重要性,并總結了學習計算機系統的深刻體會。
關鍵詞:Hello;CSAPP;P2P;Linux; VM;I/O;Shell;Cache;Ubuntu;進程;
目? 錄
目錄
第1章 概述
1.1 Hello簡介
1.1.1 P2P
1.1.2 020
1.2 環境與工具
1.2.1 硬件環境
1.2.2 軟件環境
1.2.3 開發工具
1.3 中間結果
1.4 本章小結
第2章 預處理
2.1 預處理的概念與作用
2.1.1 預處理的概念
2.1.2 預處理的作用
2.2在Ubuntu下預處理的命令
2.3 Hello的預處理結果解析
2.4 本章小結
第3章 編譯
3.1 編譯的概念與作用
3.1.1 編譯的概念
3.1.2 編譯的作用
3.2 在Ubuntu下編譯的命令
3.3 Hello的編譯結果解析
3.3.1 數據
3.3.1.1 常量
3.3.1.2 變量(全局/局部/靜態)
3.3.1.2 表達式
3.3.1.4 類型
3.3.1.5 宏
3.3.2 賦值
3.3.3 算術操作
3.3.4 關系操作
3.3.5 數組/指針/結構操作
3.3.6 控制轉移
3.3.7函數操作
3.3.7.1參數傳遞(地址/值)
3.3.7.2函數調用
3.3.7.3函數返回
3.4 本章小結
第4章 匯編
4.1 匯編的概念與作用
4.1.1 匯編的概念
4.1.2 匯編的作用
4.2 在Ubuntu下匯編的命令
4.3 可重定位目標elf格式
??? 4.3.1文件頭
??? 4.3.2程序頭表
??? 4.3.2節表
4.4 Hello.o的結果解析
4.4.1 hello.o反匯編與hello.s的比較
4.4.2 機器語言的構成
4.4.3 與匯編語言的映射關系
4.5 本章小結
第5章 鏈接
5.1 鏈接的概念與作用
5.1.1 鏈接的概念
5.1.2 鏈接的作用
5.2 在Ubuntu下鏈接的命令
5.3 可執行目標文件hello的格式
?? ?5.3.1 ELF頭信息
??? 5.3.2節頭
??? 5.3.3程序頭
??? 5.3.4符號表
??? 5.3.5重定位節
5.4 hello的虛擬地址空間
5.5 鏈接的重定位過程分析
5.6 hello的執行流程
5.7 Hello的動態鏈接分析
5.8 本章小結
第6章 hello進程管理
6.1 進程的概念與作用
6.1.1 進程的概念
6.1.2 進程的作用
6.2 簡述殼Shell-bash的作用與處理流程
6.3 Hello的fork進程創建過程
6.4 Hello的execve過程
6.5 Hello的進程執行
6.6 hello的異常與信號處理
6.6.1 異常的類型
6.6.2 異常的處理方式
6.7本章小結
第7章 hello的存儲管理
7.1 hello的存儲器地址空間
7.2 Intel邏輯地址到線性地址的變換-段式管理
??? 7.2.1段描述與段選擇符
?? 7.2.2邏輯地址到線性地址的轉換過程
7.2.3段寄存器與描述符緩存
7.3 Hello的線性地址到物理地址的變換-頁式管理
7.3.1虛擬內存的組織結構
7.3.2頁表與地址映射
7.3.2缺頁異常處理
7.4 TLB與四級頁表支持下的VA到PA的變換
7.5 三級Cache支持下的物理內存訪問
7.6 hello進程fork時的內存映射
7.6.1 fork()時的內存映射
7.6.2 寫時復制(COW)具體過程
7.7 hello進程execve時的內存映射
7.8 缺頁故障與缺頁中斷處理
7.9動態存儲分配管理
7.10本章小結
第8章 hello的IO管理
8.1 Linux的IO設備管理方法
8.2 簡述Unix IO接口及其函數
8.3 printf的實現分析
8.4 getchar的實現分析
8.5本章小結
結論
附件
參考文獻
第1章 概述
1.1 Hello簡介
1.1.1 P2P
P2P,即“從程序到進程”(From Program to Process),指的就是將人可讀的源程序轉變為操作系統可調度執行的進程的全過程。以hello為例,其生命周期始于一份用 C 語言編寫、易于理解的源代碼文件 hello.c,隨后由 GCC 編譯驅動程序接管,將其翻譯成可執行文件 hello。整個翻譯過程分為四個階段:首先,預處理器 cpp 對 hello.c 進行預處理,生成含有展開宏和頭文件內容的中間文件 hello.i;接著,編譯器前端 cc1 將 hello.i 轉換為匯編代碼 hello.s;然后,匯編器 as 將 hello.s 匯編成目標文件 hello.o;最后,鏈接器 ld 將 hello.o 與所引用的標準庫或其他庫文件進行鏈接,輸出最終的可執行文件 hello。生成可執行文件后,當在 Shell 中運行時,系統首先通過 fork() 創建一個子進程,再通過 execve() 將 hello 的代碼和數據加載到該子進程的內存空間中,至此,一個新的進程便誕生了。
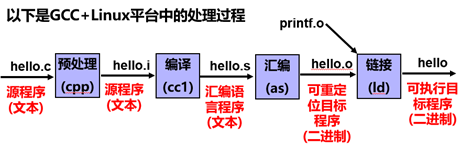
圖1 編譯系統
1.1.2 020
020,即From Zero-0 to Zero-0,描述了程序從加載到結束的完整生命周期。當用戶在終端輸入 ./hello 時,Shell 先調用 fork() 創建子進程,子進程再通過 execve() 將可執行文件映入進程虛擬地址空間,并借助 mmap 將必要的代碼和數據從存儲介質載入物理內存,隨后交由 CPU 調度執行。CPU 為該進程分配時間片,依次進行取指、譯碼、執行等流水線操作;在此過程中,內存管理單元通過多級頁表和 TLB 進行地址轉換,并利用 L1、L2、L3 緩存加速數據訪問;I/O 子系統則根據程序指令完成外部設備的讀寫輸出。待程序執行結束后,子進程將進入僵尸狀態,由父進程調用 wait() 或類似機制回收,內核隨即釋放其虛擬內存空間并清除相關進程表項,從而完成程序從zero到zero的過程。
1.2 環境與工具
1.2.1 硬件環境
X64 CPU;2GHz;2G RAM;256GHD Disk 以上
1.2.2 軟件環境
Windows7/10 64位以上;VirtualBox/Vmware 11以上;Ubuntu 16.04 LTS 64位/優麒麟 64位 以上
1.2.3 開發工具
Visual Studio 2010 64位以上;CodeBlocks 64位;vi/vim/gedit+gcc;edb
1.3 中間結果
| 文件的名字 | 文件的作用 |
| hello.c | 源程序文件 |
| hello.i | hello.c通過預處理器cpp預處理后的文本文件 |
| hello.s | hello.i通過編譯器ccl編譯后的匯編程序 |
| hello.o | hello.s通過匯編器as匯編后的文件 |
| hello | hello.o通過鏈接器ld鏈接后的可執行文件 |
1.4 本章小結
本章首先以 “Hello” 程序為例,闡述了從可讀的 C 語言源代碼到操作系統可調度進程的全流程:源文件通過 cpp、cc1、as 和 ld 四個階段依次生成可執行文件,再由 Shell 調用 fork() 與 execve() 在內存中創建并運行進程;隨后通過 mmap、多級頁表、TLB 及 L1/L2/L3 緩存進行內存管理,并由 CPU 按時間片執行取指—譯碼—執行流水線,I/O 子系統負責外設讀寫;進程結束后由父進程 wait() 回收,內核釋放資源,完成從“零”到“零”的閉環。此外,本章還介紹了硬件(X64、2 GHz、2 GB RAM、256 GB 硬盤及以上)、軟件(Windows 7/10 64 位或 Ubuntu 16.04 LTS/優麒麟)、虛擬化(VirtualBox/VMware 11+)與開發工具(Visual Studio、Code::Blocks、GCC、edb 等)環境,并列出了 hello.c→hello.i→hello.s→hello.o→hello 及相關 ELF 和反匯編文件的中間產物及其作用。
第2章 預處理
2.1 預處理的概念與作用
2.1.1 預處理的概念
預處理是由預處理器(cpp)負責完成的源代碼準備階段,它會識別以 # 開頭的指令并對 .c 文件進行改寫與擴展。主要操作包括:
宏定義替換(define):將代碼中出現的宏標識符替換為對應的文本或表達式;
文件包含(include):將被包含文件的內容嵌入到當前源文件中;
條件編譯(ifdef、if 等):根據條件決定是否保留或丟棄特定代碼段。
完成預處理后,生成的中間結果仍是一份合法的 C 語言源代碼,通常以 .i 為擴展名,供后續編譯階段使用。
2.1.2 預處理的作用
預處理階段通過解析以 # 開頭的指令,對源代碼進行初步轉換和組織,為后續的編譯、匯編和鏈接打下基礎。其主要功能包括以下三方面:
- 宏定義替換
允許程序員使用 define 定義符號常量或代碼片斷,在預處理時將這些宏標識符替換為對應的文本或表達式,從而減少重復代碼、提升可維護性和可讀性。 - 文件包含
通過 include 指令將頭文件或其他源文件的內容插入到當前文件中,這不僅能集中管理函數聲明、數據結構和宏定義,還能實現模塊化編程。 - 條件編譯
使用 if、ifdef、ifndef 等指令,根據編譯環境或自定義宏的定義情況選擇性地保留或剔除代碼片段,以便同一份源代碼在不同平臺、不同配置下能夠靈活編譯。
總體而言,預處理使得程序在邏輯上更簡潔、有條理,并增強了可移植性與調試效率,是現代 C/C++ 開發流程中不可或缺的第一步。
2.2在Ubuntu下預處理的命令
圖2 cpp hello.c >hello.i
2.3 Hello的預處理結果解析
預處理階段生成中間文件 hello.i,此時預處理器已根據源代碼中 #include 指令在進入 main 函數之前,按順序讀取并展開了系統頭文件 stdio.h、unistd.h 和 stdlib.h 的全部內容;若這些頭文件內部仍包含以 # 開頭的指令,預處理器同樣會繼續處理直至展開完畢。所有注釋被剔除,宏定義在預處理完成后不再保留,最終得到一份標準且完整的 C 源代碼,可直接供后續的編譯階段使用。
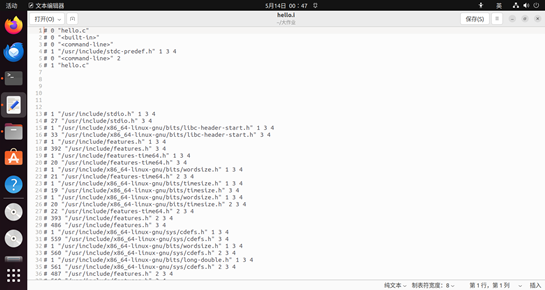
圖3 預處理結果
2.4 本章小結
本節首先闡述了預處理在 C 語言編譯流程中的概念與作用,然后在 Ubuntu 環境下使用gcc -E 命令對 hello.c 進行了預處理,生成了中間文件 hello.i。通過查看 hello.i,可以直觀地看到:所有以 include 引入的系統頭文件(如 stdio.h、unistd.h、stdlib.h)已按順序展開插入;注釋被清除;宏定義亦已展開且在結果文件中不再保留,從而形成一份可直接送入編譯器的標準 C 源代碼,有助于更深入地理解預處理階段的核心功能與工作原理。
第3章 編譯
3.1 編譯的概念與作用
3.1.1 編譯的概念
編譯階段由編譯器(cc1)負責,將預處理后生成的 hello.i 文件作為輸入,翻譯成目標平臺對應的匯編代碼,并輸出為 hello.s。該過程首先進行詞法和語法分析,驗證代碼的正確性;接著在語義分析中檢查類型與作用域;隨后生成中間表示(IR),并對其進行必要的優化;最后將經過優化的 IR 轉換為具體的匯編指令,形成包含 main 函數定義及所有函數實現的匯編程序。整個流程不僅完成了從高級語言到匯編語言的轉換,還為后續的匯編和鏈接階段提供了可讀且高效的匯編源碼。
3.1.2 編譯的作用
編譯階段由編譯器(cc1)接管,將預處理生成的 .i 文件翻譯成目標平臺對應的匯編代碼(.s 文件),其主要功能包括以下幾個方面:
- 語法與語義檢查
編譯器首先對源代碼進行詞法分析和語法分析,確保程序符合語言規范;隨后進行語義分析,檢查類型一致性與作用域正確性,為生成正確的低級代碼奠定基礎。 - 中間表示與優化
在分析通過后,代碼會被轉換為中間表示(IR),編譯器可在此階段對其進行多種優化,如常量折疊、循環展開等,以提升最終生成代碼的執行效率。 - 匯編生成
優化后的 IR 會被映射為具體的匯編指令,形成包含 main 函數定義及所有程序邏輯的匯編程序,便于后續的匯編和鏈接環節處理。
總體而言,編譯不僅完成了將人類可讀的高級語言轉換為機器可執行的低級指令,還通過一系列檢查和優化手段,保證了生成代碼的正確性與高效性,同時為后續匯編和鏈接階段提供了結構清晰、性能優良的匯編源文件。 ?
3.2 在Ubuntu下編譯的命令
在Ubuntu中,hello.i文件進行編譯的操作命令為:gcc -S hello.i -o hello.s
圖4 編譯命令
3.3 Hello的編譯結果解析
3.3.1 數據
3.3.1.1 常量
字符串常量,位于只讀數據段(.rodata)
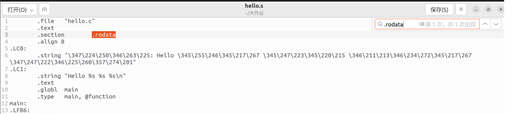
圖5 字符串常量
3.3.1.2 變量(全局/局部/靜態)
1)無全局與靜態變量。
全局變量在匯編語言中通常存儲在數據段(Data Segment)中。數據段是程序的一部分,用于存儲全局變量和靜態變量。全局變量在程序的整個生命周期內都存在,而不僅僅在特定的函數調用期間。需要注意的是,全局變量的修改和訪問是在整個程序執行期間有效的,因此它可以被程序中的任何函數訪問和修改。這使得全局變量在需要在不同部分之間共享數據時非常有用。由于hello.c中不含全局變量,這里就不詳細描述了。
2)局部變量
局部變量通常使用棧指針(%rsp)和基址指針(%rbp)進行訪問。在此段匯編代碼中,可以看到通過基址指針(%rbp)來訪問局部變量。
-20(%rbp):該偏移量用于在棧幀中存放來自 main 函數的第一個參數 argc 的值,對應匯編指令 movl %edi, -20(%rbp)。
-32(%rbp):該偏移量用于在棧幀中存放來自 main 函數的第二個參數 argv 的地址,對應匯編指令 movq %rsi, -32(%rbp)。
-4(%rbp):存儲局部變量i,用于在循環中計數。匯編代碼中通過movl $0, -4(%rbp)初始化該變量。
通過addl $1, -4(%rbp)遞增該變量。
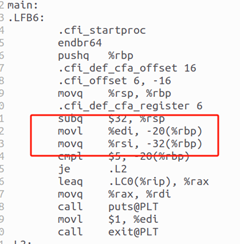
圖6 局部變量
函數調用結束后的清理: 在函數返回前,棧幀會被清理。這包括將棧指針恢復到原始的位置,以及彈出保存的幀指針值。這個過程確保了棧的一致性。
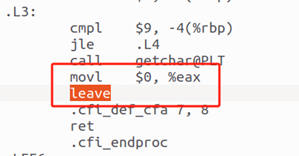
圖7函數調用結束后的清理
3.3.1.2 表達式
.c中的表達式argc!=5,在.s文件中表示為:

圖8 .c中的表達式argc!=5在.s文件
i<10表示為:
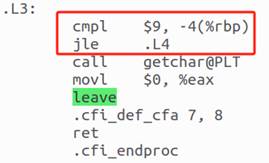
圖9 .c中的表達式i<10在.s文件
3.3.1.4 類型
類型的解析通過匯編指令的選擇和操作數的大小來體現。根據變量類型使用不同的mov指令。

圖10 不同的mov指令
3.3.1.5 宏
如果源代碼中沒有定義任何宏,那么在預處理階段就不會進行宏替換操作。即使存在宏定義,所有的宏替換也都在預處理階段完成,編譯器不會再進行宏相關的處理。這意味著宏的作用僅限于預處理階段,編譯器處理的是已經展開了宏的代碼。
3.3.2 賦值
將參數的值從寄存器(%edi 和 %rsi)移動到了相對于基址指針 %rbp 的棧上的位置(偏移 -20 和 -32 處)。

圖11 賦值不同的參數
賦值0給i
圖12 賦值0給i
3.3.3 算術操作
i++由addl $1,-4(%rbp)完成.
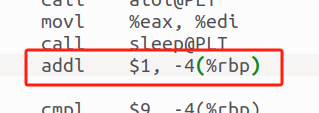
圖13 i++的完成方式
3.3.4 關系操作
編譯器首先識別關系表達式中的關系運算符和操作數,并構建語法分析樹或抽象語法樹(AST)來表示表達式的結構。檢查操作數的類型,確保它們與關系運算符兼容。根據C語言的運算符優先級和結合性規則,編譯器確定關系表達式的求值順序。
i<10: 并沒有用10,而是用9在比較,若等于9后則跳轉到下部分代碼不再循環。
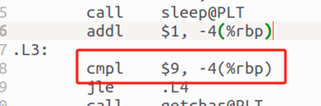
圖14 i<10的完成方式
3.3.5 數組/指針/結構操作
??????? main接收的argv[]數組。
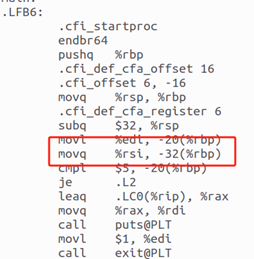
圖14 main接收的argv[]數組
3.3.6 控制轉移
編譯器首先識別控制轉移語句的語法結構,如if、else、switch、for、while等,檢查控制轉移語句的語義,確保條件表達式的類型是可比較的,并驗證循環變量的初始化和更新表達式等。分析控制轉移語句的控制流。
由于hello程序只涉及到了if和for,下面我們著重對這兩個語法結構進行分析:
- if條件語句
if(argc!=4),被編譯器轉換為兩行匯編語言,用指令cmpl和je來完成判定。
![]()
圖15 if(argc!=4)
- for循環語句
for(i=0;i<8;i++),被編譯器轉換為兩部分,分別是循環體L4和循環終止條件L3.
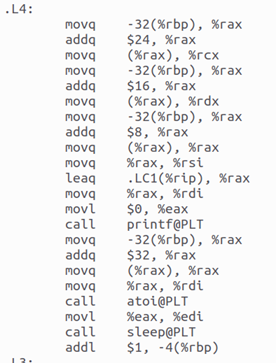
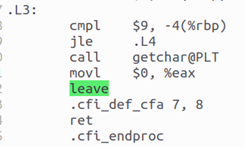
圖16 for(i=0;i<8;i++)
3.3.7函數操作
3.3.7.1參數傳遞(地址/值)
在 C 語言中,函數參數的傳遞方式主要有兩種:值傳遞和地址傳遞。在值傳遞中,實參的值被復制到形參中,函數內部對形參的修改不會影響實參。而在地址傳遞中,實參的地址被傳遞給形參,函數內部通過該地址可以直接修改實參的值。
在調用 main 函數時,操作系統會將命令行參數的個數(argc)和參數數組的地址(argv)傳遞給程序。在 x86-64 架構下,按照調用約定,前幾個函數參數通過寄存器傳遞。具體來說,argc 會被傳遞到 %edi 寄存器,argv 的地址會被傳遞到 %rsi 寄存器。
在 main 函數的匯編代碼中,可以看到以下指令:

圖17 參數傳遞
這兩條指令將寄存器中的值保存到棧幀中,以便在函數內部使用。其中,-20(%rbp) 用于存儲 argc 的值,-32(%rbp) 用于存儲 argv 的地址。
因此,參數的傳遞過程如下:操作系統將參數傳遞到指定的寄存器中,函數開始執行時將這些寄存器的值保存到棧幀中,供函數內部使用。這種機制確保了函數能夠正確地接收到并處理傳遞給它的參數。
3.3.7.2函數調用
對于函數調用,編譯器需要生成代碼來傳遞參數、保存返回地址以及跳轉到函數入口點。它還需要處理函數的返回,包括恢復調用點的上下文和獲取返回值(如果有的話)。編譯器將函數定義和調用轉換為機器代碼。通過call指令調用,如圖,分別調用了頭文件提供的printf, sleep, getchar函數。hello程序涉及到的函數包括main printf exit sleep getchar atoi等,其中的參數包含如下:
main函數包括argc和argv兩個參數;
printf函數包括字符串參數"用法: Hello 學號 姓名 秒數!\n";
exit參數為0x1;
sleep參數為atoi(argv[3]);
atoi參數為argv[3];
getchar沒有參數;
![]()
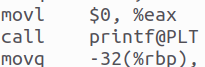
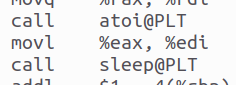
圖18 函數調用
3.3.7.3函數返回
ret 指令用于將程序的控制權返回到調用該函數的位置,并且通常在函數的結尾處使用。指令 .cfi_endproc 表示這是一個函數結束的標記,它用于通知調試器和其他工具函數的結束位置。
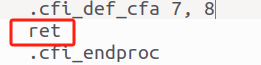
圖19 函數返回
3.4 本章小結
本章深入探討了 C 語言編譯過程中的第二階段——編譯(Compilation),即將預處理后的 C 語言源文件(如 hello.i)轉換為匯編語言代碼(如 hello.s)的過程。通過在 Ubuntu 環境下使用 gcc -S hello.i -o hello.s 命令,生成了匯編文件 hello.s,并對其內容進行了詳細分析。
在生成的匯編代碼中,展示了變量的聲明與初始化、表達式的計算、條件判斷、函數調用以及循環控制等關鍵編譯結果。例如,movl $0, -4(%rbp) 表示將整數 0 賦值給局部變量 i,cmpl $9, -4(%rbp) 用于比較變量 i 與常數 9 的大小,call printf@PLT 表示調用標準庫函數 printf。這些匯編指令體現了高級語言結構在低級語言中的具體實現方式。
通過對 hello.s 文件的分析,進一步理解了編譯器如何將高級語言的語法結構轉換為匯編語言指令,為后續的匯編和鏈接階段奠定了基礎。這不僅加深了對編譯過程的理解,也為學習程序的底層執行機制提供了實用的視角。
第4章 匯編
4.1 匯編的概念與作用
4.1.1 匯編的概念
匯編是將人可讀的匯編語言文本(如?hello.s)交由匯編器(as)處理,翻譯成對應的機器指令,并將生成的二進制代碼按可重定位目標文件格式打包,最終輸出一個不可直接打開的目標文件(如?hello.o)。這一過程完成了從匯編語言到機器語言的轉換,使得上層編寫的匯編程序能夠被鏈接器進一步處理,最終組成可執行文件。
4.1.2 匯編的作用
- 機器指令翻譯
將上層編寫的匯編代碼轉譯成機器指令,使其在鏈接完成后生成的可執行文件能夠被計算機硬件直接識別并運行。 - 底層控制
匯編語言可直接操作計算機的核心硬件資源——包括 CPU 寄存器、內存地址、以及各類輸入/輸出設備等——因此極大地增強了對系統底層行為的掌控能力,適用于驅動程序、實時系統和嵌入式開發等場景。 - 性能優化
由于無需經過高級語言的抽象層,匯編程序員能夠精細地調度指令執行順序、利用特定架構指令集、以及合理分配寄存器使用,從而最大限度地提升代碼執行效率,實現對關鍵路徑或性能瓶頸的深度優化。 - 最高效率的硬件執行
機器語言是計算機能夠直接執行的最低級語言,其指令無需解釋或編譯開銷,完全由硬件電路驅動,因而在速度和資源利用率上都達到最優。
4.2 在Ubuntu下匯編的命令
在Ubuntu中,hello.s文件進行編譯的操作命令為:gcc hello.s -c -o hello.o或者as -o hello.o hello.s
圖20 gcc hello.s -c -o hello.o指令執行
4.3 可重定位目標elf格式
ELF 是 Unix 及類 Unix 系統中最常見的可執行文件與可重定位目標文件格式。一個標準的 ELF 文件由下圖展示:
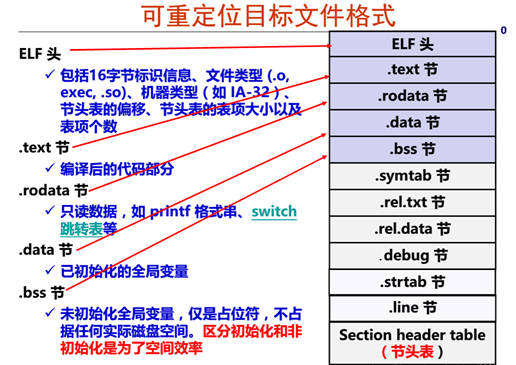
圖21 可重定位目標文件格式
這種結構既支持最終生成可執行文件,也便于鏈接器將多個目標文件和庫文件組合成完整程序。
??? 4.3.1文件頭
首先查看文件頭(ELF Header)。其包含了描述ELF文件整體結構和屬性的信息,包括ELF標識、目標體系結構、節表偏移、程序頭表偏移等。
命令:readelf -h hello.o
得到hello.o的ELF頭
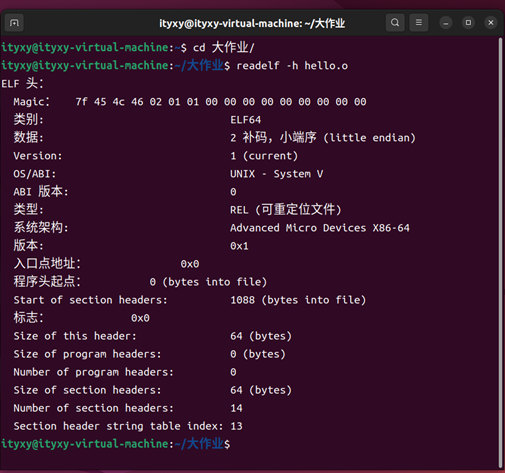
圖22 hello.o的ELF頭
??? 4.3.2程序頭表
對于目標文件,程序頭表(Program Header Table)可能為空。查詢后確實如此。
命令:readelf -l hello.o

圖23 程序頭表的查詢
??? 4.3.2節表
節表記錄了 ELF 文件中各個節(Section)的關鍵信息,包括節名稱、節類型、在文件中的偏移地址、節大小以及其他屬性等。ELF 文件中的代碼和數據都被組織存放在不同的節中:例如,.text 節用于存放可執行代碼,.data 節用于存放已初始化的全局和靜態數據。通常,.text 與 .data 是在匯編源文件中顯式聲明的節,而諸如符號表節、字符串表節、重定位節等其他節,則由匯編器自動生成并插入到目標文件中,以便鏈接器和調試器后續使用。
命令:readelf -S hello.o
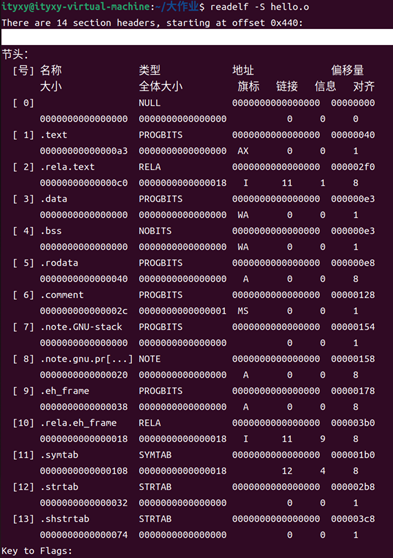
圖24 readelf -S hello.o查詢
之后用readelf -a hello.o探查 ELF 頭部、程序頭(若有)、節區表、重定位表、符號表、注釋節等全部內容。以下為關鍵部分的摘錄與解析:
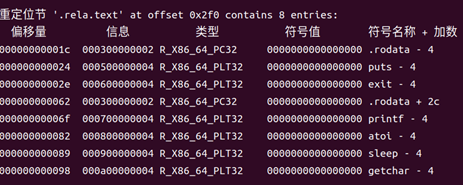
圖25 .rela.text的更詳細信息
重定位節 .rela.eh_frame 記錄了需要進行地址重定位的異常處理框架(exception handling frame)信息。其作用是調整異常處理框架(EH frame)中對代碼地址的引用,保證運行時拋出或捕獲異常時能正確定位。以下是查看 .rela.eh_frame 的輸出:
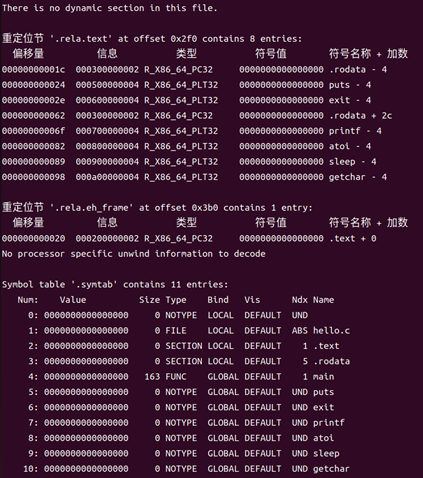
圖26 .rela.eh_frame
符號表 .symtab 是目標文件中非常重要的一部分,它列出目標文件中所有符號(函數名、全局變量、節引用等),對鏈接器分配最終地址及調試器符號解析至關重要。以下是符號表 .symtab 的具體內容和解釋:
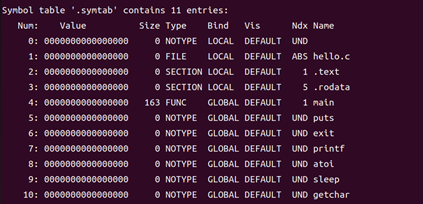
圖27 .symtab的具體內容和解釋
.note.gnu.property節包含平臺或編譯器特定屬性注釋,如 x86 架構的 IBT(Indirect Branch Tracking)與 SHSTK(Shadow Stack)支持標記,便于加載器或安全機制進行相應配置。
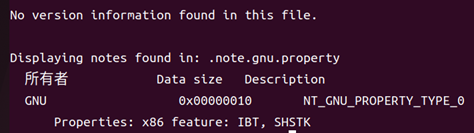
圖28 .note.gnu.property的具體內容和解釋
4.4 Hello.o的結果解析
4.4.1 hello.o反匯編與hello.s的比較
objdump -d -r hello.o
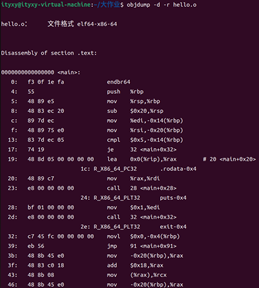 ?
?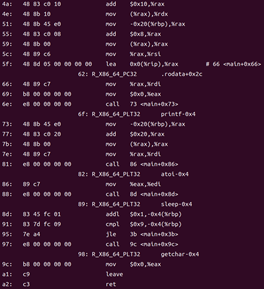
圖29 hello.o的反匯編查看
對照分析:
在反匯編輸出中,每行末尾的指令與原 hello.s 中的匯編代碼保持一致,但在每條指令前,還會多出一串對應的十六進制機器碼。與純粹的匯編語言不同,匯編代碼是一種面向人類、帶有助記符的抽象表示;而從目標文件反匯編得到的內容,則完整地展示了機器語言——即計算機能夠直接識別和執行的二進制編碼。機器語言沒有任何抽象層,完全由 0 和 1 組成,因而才能被處理器硬件所驅動。分支轉移時,.s文件中會跳轉到諸如.L3的代碼段,像這樣:
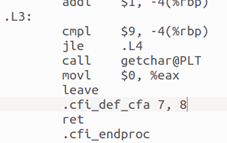
圖30 hello.s的L3指令
而反匯編文件中,每條指令前的十六進制數表示該指令在地址空間(或文件)中的位置;而當指令本身是跳轉(jmp、call 等)時,其操作數中包含的偏移量會被加到當前指令的地址上,計算出跳轉目標的絕對地址,并在反匯編輸出中一并顯示:
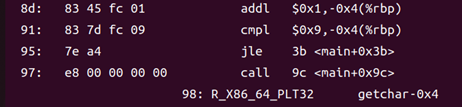
圖31 hello.o的反匯編代碼
函數調用時,匯編文件中,call指令直接調用函數,call后緊跟函數的名字:
![]()

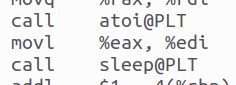
圖32 匯編文件中的函數調用
在反匯編文件中,86: 表示受重定位條目影響的地址偏移量,是 call 指令中地址字段在指令流中的起始位置。
重定位表中的每個條目(Elf64_Rela 結構)記錄了符號索引、類型和加數等信息,以便鏈接器根據這些數據修正目標文件中對應的地址域。
R_X86_64_PLT32 是重定位類型,表明對過程鏈接表(Procedure Linkage Table)的 32 位 PC 相對重定位,這種重定位用于支持運行時的延遲綁定調用。
在第一次調用時,PLT 條目會引導程序跳轉到動態鏈接器,由其解析符號地址并寫入全局偏移表(GOT),之后對同一函數的調用將直接透過 GOT 完成,從而加速后續調用性能。
在 readelf -r 或 objdump -r 的重定位輸出中,可以看到這些條目詳細列出偏移量(Offset)、Info 字段、重定位類型、符號名稱和加數(Addend)等信息 Mindfruit。
“atoi-0x4” 表示重定位目標符號為?atoi,加數為?-4,這正是因為 x86?64 的 call 指令采用 PC 相對尋址方式,其位移是相對于下一條指令(P)的偏移數,因此需減去 4?字節來校正。
盡管名稱為?R_X86_64_PLT32,鏈接器仍沿用 R_X86_64_PC32 的計算方法?S + A ? P?來生成最終的重定位值,從而簡化對 PC 相對分支的處理。
鏈接器在處理 R_X86_64_PLT32 重定位時,會根據公式?S + A ? P?(S 為符號值、A 為重定位加數、P 為調用指令下一地址)計算并填充至 call 指令的立即數域中,保證在運行時能跳轉到正確的函數入口。
call 指令執行時,CPU 會將返回地址壓入棧,并根據已填充的位移計算出目標地址后跳轉,完成對目標函數(如 atoi)的調用。
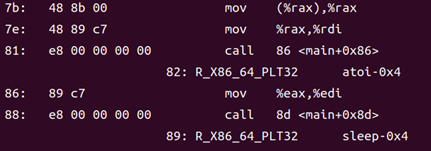
圖33 反匯編文件中的函數調用
4.4.2 機器語言的構成
x86?64 指令采用可變長度編碼,任何一條指令的長度介于?1?到?15?字節之間;例如操作數很少的 pop?%rbx 僅需單字節操作碼?0x5B,而更復雜或帶更多操作數的指令則更長。指令格式由前綴(Legacy/REX)、操作碼、ModR/M、SIB、可選位移和立即數等字段按固定順序組成,CPU 從指令流起點逐字節地解析即可唯一識別出完整指令,無需回溯。若指令攜帶多字節常數或內存地址,這些字段必須按照小端序的方式依次編碼,以保證加載時各寬度訪問均能正確讀取。
4.4.3 與匯編語言的映射關系
反匯編器只是基于機器代碼文件中的字節序列來確定匯編代碼。它不需要訪問該程序的源代碼或匯編代碼;反匯編器使用的指令命名規則與GCC生成的匯編代碼使用的有些細微的差別。
在函數調用和分支跳轉時,二者也是有差別的。
1)函數調用:
函數調用在匯編語言中通常涉及到將參數壓入棧中,然后跳轉到函數入口點。函數返回時,通常會從棧中彈出返回值,并跳轉到調用點之后的指令。
2)分支跳轉:
在機器語言中,分支轉移和函數調用通常涉及到特定的指令和操作數來表示跳轉的目標地址。這些地址可能是絕對的,也可能是相對于當前指令或某個基準點的偏移量。
在匯編語言中,這些跳轉目標通常使用標簽來表示,如JMP label表示跳轉到標簽label處。在編譯或匯編過程中,這些標簽會被替換為實際的內存地址或偏移量。
4.5 本章小結
本章首先介紹了匯編階段的基本流程:使用匯編器將匯編源文件(.s)轉換為可重定位的目標文件(.o),這一過程僅完成從助記符到機器指令的翻譯,而符號引用留待鏈接階段處。
接著,通過 readelf -S hello.o 觀察節區表,掌握了各節的名稱、類型、在文件中的偏移與大小,以及標志屬性等關鍵信息。
隨后,使用 readelf -a hello.o 全面查看了 ELF 頭部、重定位表(.rela.text、.rela.eh_frame)、符號表(.symtab)及注釋節(.note.gnu.property)等,深入了解了鏈接器和動態加載所需的元數據。
在反匯編階段,將目標文件中的二進制內容還原為匯編指令,并與原始匯編源對比,清晰地看到機器碼(十六進制編碼)是如何對應到匯編助記符的,進一步理解了指令執行邏輯與重定位機制。
通過本章學習,不僅掌握了從匯編程序到目標文件的完整流程,還能夠借助 readelf 和反匯編工具分析二進制文件結構與機器代碼執行邏輯,為后續的鏈接、調試和逆向工程奠定了堅實基礎。
第5章 鏈接
5.1 鏈接的概念與作用
5.1.1 鏈接的概念
鏈接是由鏈接器(ld)完成的一項關鍵步驟,其主要功能是將編譯或匯編階段產生的多個可重定位目標文件(.o)以及所需的庫文件(靜態庫 .a 或動態庫 .so)收集、符號解析并合并,生成可以被操作系統加載器裝入內存的最終可執行文件或共享庫。靜態鏈接通常在編譯時完成,將所有符號和代碼打包進單一可執行文件;動態鏈接則可以在加載時或運行時延遲解析符號,常見于使用 dlopen/dlsym 的場景。
可通過鏈接實現將若干獨立模塊編譯輸出的.o文件合并為一個完整程序,也可將未定義符號留給運行時鏈接器再解析,因而鏈接機制既支持靜態可執行,也支持共享庫與動態加載。
5.1.2 鏈接的作用
鏈接將多個預編譯好的目標文件整合為一個可執行文件,從而支持模塊化的分離編譯,使得大型應用不必寫成單一龐大源程序,而是可以拆分為可獨立修改、編譯的功能模塊。這樣不僅大幅縮短了每次修改后重建的時間,提升了開發效率,還簡化了代碼組織與維護,增強了程序生成的靈活性和跨平臺可移植性。鏈接器通過解析各目標文件間的符號引用,自動合并并解決模塊間依賴,最終輸出符合平臺 ABI 規范的可執行映像)。
5.2 在Ubuntu下鏈接的命令
在Ubuntu中,hello.s文件進行編譯的操作命令為:
ld -o hello -dynamic-linker /lib64/ld-linux-x86-64.so.2 /usr/lib/x86_64-linux-gnu/crt1.o /usr/lib/x86_64-linux-gnu/crti.o hello.o /usr/lib/x86_64-linux-gnu/libc.so /usr/lib/x86_64-linux-gnu/crtn.o
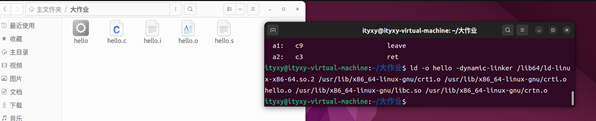
圖34 ld的操作過程
5.3 可執行目標文件hello的格式
?? ?5.3.1 ELF頭信息
命令:readelf -h hello
得到hello的ELF頭信息
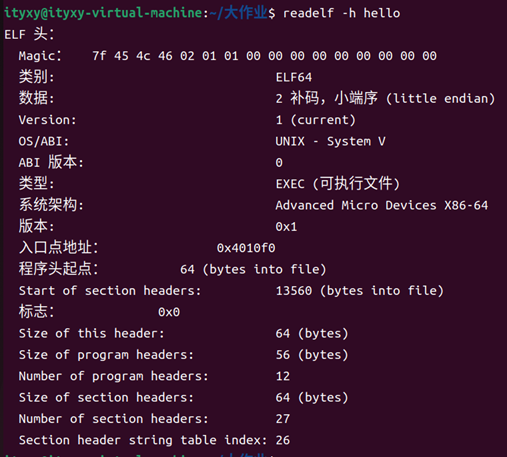
圖35 hello的ELF頭信息
??? 5.3.2節頭
描述了各個節的大小、起始位置和其他屬性。鏈接器鏈接時,會將各個文件的相同段合并成一個大段,并且根據這個大段的大小以及偏移量重新設置各個符號的地址。
命令:readelf -S hello
得到hello的節頭部表
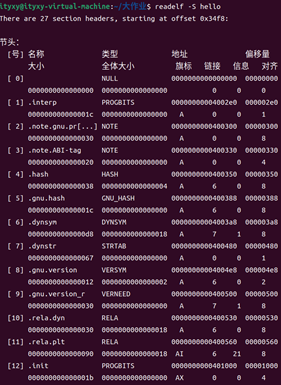 ?
?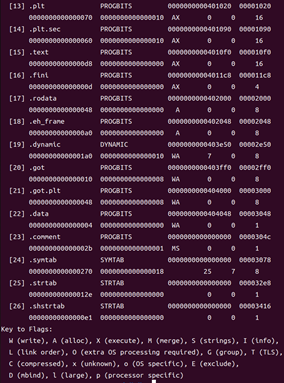
圖36 hello的節頭部表
??? 5.3.3程序頭
命令:readelf -l hello
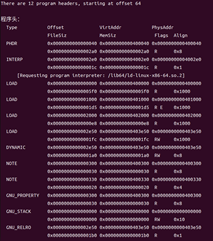
圖37 hello的程序頭表
??? 5.3.4符號表
命令:readelf -s hello
得到ELF符號表:
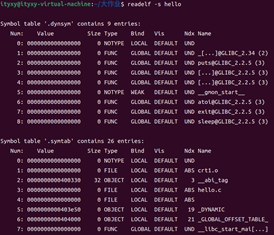 ?
?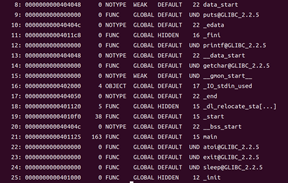
圖38 hello的符號表
??? 5.3.5重定位節
命令:readelf -r hello
得到hello的重定位節
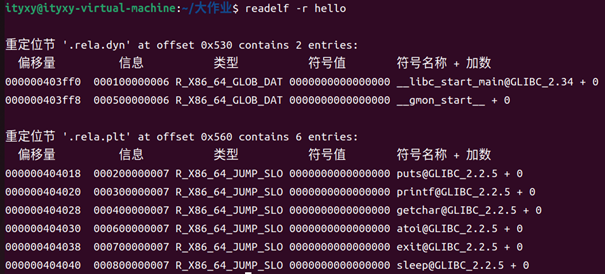
圖39 hello的重定位節
5.4 hello的虛擬地址空間
命令:edb --run hello
使用edb加載hello
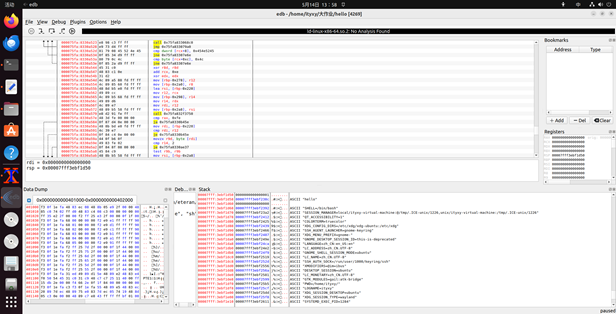
?? 圖40 edb查看
可以看出,虛擬地址均從0x401000開始,從開始到結束這之間的每一個節對應5.3中的每一個節頭表的聲明。例如,在起始地址0x401000可與在ELF中看到對應:init。

? 圖41 hello的節頭中的.init
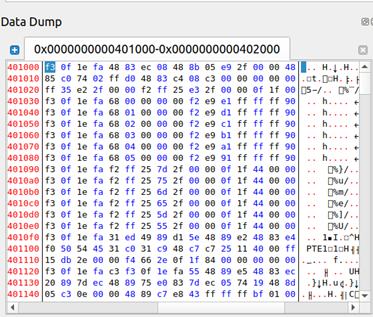
? 圖42 edb查看
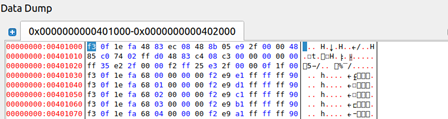
圖43 0x401000
5.5 鏈接的重定位過程分析
hello反匯編文件中,每行指令都有唯一的虛擬地址,而hello.o的反匯編沒有,只是相對于代碼段(通常是 .text 段)的偏移地址。這是因為目標文件只是一個中間產物,還沒有被鏈接到最終的內存地址空間。這是因為hello經過鏈接,已經完成重定位,每條指令分配了唯一的虛擬地址,每條指令的地址關系已經確定;
命令:objdump -d -r hello
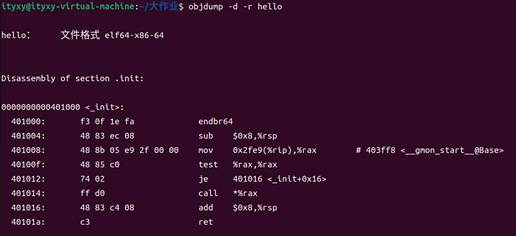
圖44 得到hello的反匯編
hello:
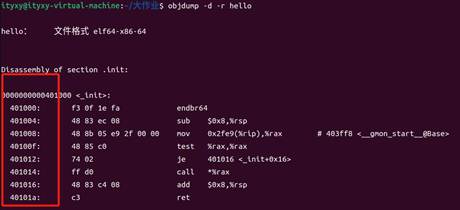
圖45 hello的反匯編
hello.o:
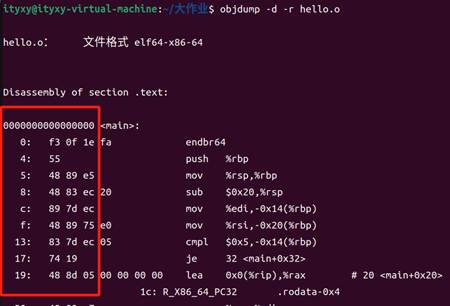
圖46 hello.o的反匯編
hello:
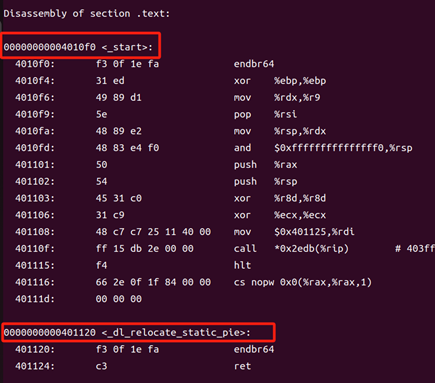
圖47 hello的反匯編
hello已經完成鏈接,故其反匯編的地址關系已經確定,直接給出即可。
hello.o:
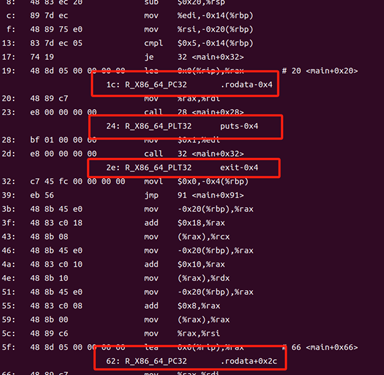
圖48 hello.o的反匯編
hello.o并沒有鏈接,所以需要告訴鏈接器在鏈接時需要執行的動作。
例如,6f: R_X86_64_PLT32 printf-0x4告訴鏈接器在鏈接時需要執行的動作。6f 是一個字節偏移量,指示了在某個特定位置發生了重定位動作。
R_X86_64_PLT32 是一個重定位類型,表示這是一個32位的重定位項。printf-0x4 表示需要修改的目標符號是 printf,并且要在鏈接時將其地址減去 0x4。
鏈接后函數數量增加。鏈接后的反匯編文件中,多出了.plt,puts@plt,printf@plt,getchar@plt,exit@plt,sleep@plt等函數的代碼。這是因為動態鏈接器將共享庫中hello.c用到的函數加入可執行文件中。
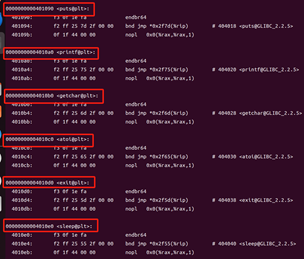
圖49 hello的反匯編
5.6 hello的執行流程
使用gdb/edb執行hello,說明從加載hello到_start,到call main,以及程序終止的所有過程(主要函數)。請列出其調用與跳轉的各個子程序名或程序地址。
Edb查看如下:
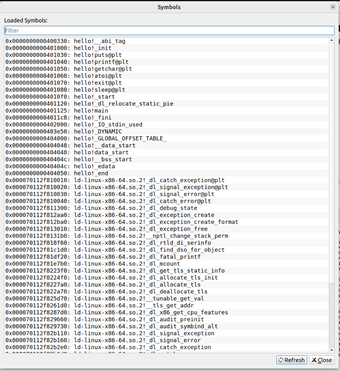
圖50 edb的symbols查看
5.7 Hello的動態鏈接分析
分析hello程序的動態鏈接項目,通過edb/gdb調試,分析在動態鏈接前后,這些項目的內容變化。要截圖標識說明。
在程序調用由共享庫定義的函數時,編譯器無法在編譯階段確定該函數在內存中的準確地址。這是因為共享庫在運行時可能被加載到內存的任意位置。為了解決這個問題,現代編譯系統采用了一種稱為延遲綁定的機制,將函數地址的解析推遲到程序第一次調用該函數的時刻進行。
延遲綁定的數據結構:PLT 與 GOT
延遲綁定依賴于兩個關鍵的數據結構:
PLT
PLT 是一個跳轉表,用于支持共享庫函數的延遲調用。每個外部函數在 PLT 中都有一個對應的入口,該入口包含一段跳轉指令。PLT[0] 是一個特殊條目,用于跳轉至動態鏈接器。其余的 PLT 條目則負責各自對應的函數調用。
GOT
GOT 是一個存儲函數實際地址的數組,每個條目占用 8 字節。GOT 與 PLT 協同工作。GOT[0] 和 GOT[1] 存儲動態鏈接器在運行時使用的特定信息,GOT[2] 保存動態鏈接器的入口地址,其余條目用于存儲各個外部函數的地址,并在第一次調用該函數時由鏈接器進行填充。
調用流程解析
當程序調用一個共享庫函數時,整個延遲綁定過程如下:
- 第一次調用
程序不會直接調用函數地址,而是跳轉到該函數在 PLT 表中的條目。例如,調用 printf 實際上是跳轉到 printf@PLT。該條目第一條指令通過 GOT 表進行間接跳轉,此時 GOT 條目仍未填入真實地址,因此會跳轉回該 PLT 條目的第二條指令。 - 跳轉回自身并調用動態鏈接器
PLT 的第二條指令會將函數標識符壓入棧,然后跳轉到 PLT[0]。PLT[0] 通過 GOT[1] 取出一個地址,壓棧后,再通過 GOT[2] 跳轉至動態鏈接器中的解析函數(位于 ld-linux.so 中)。 - 地址解析與跳轉
動態鏈接器根據壓入棧的參數查找函數的真實地址,并將其寫回對應的 GOT 條目。之后將控制權轉交給真正的函數入口。 - 后續調用優化
一旦 GOT 條目被填充,后續對該函數的調用將直接通過 GOT 中保存的真實地址跳轉,無需再次進入動態鏈接器。這實現了函數調用的延遲綁定與高效性。
動態鏈接與重定位行為差異
程序啟動初期,尚未加載動態鏈接器前,GOT 表中的各個函數地址尚未完成重定位,所有調用都需經過 PLT 路徑進入鏈接器。只有在首次調用并完成重定位后,GOT 表才會更新為實際的函數地址,從而避免重復解析。這也體現了 hello 程序在動態鏈接器加載前后其地址解析行為的變化。
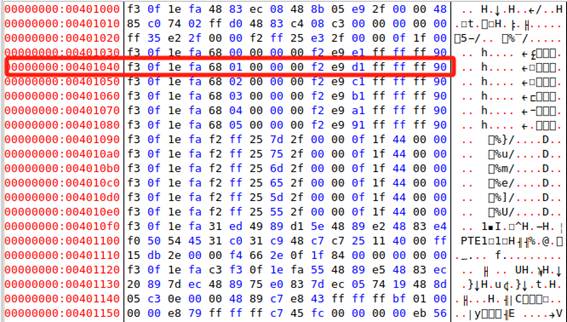
圖51 edb
從地址 0x401020 開始,下面是各條目的結構特征與作用說明:
1. 0x401020 開始的指令塊:PLT[0] 條目(通用入口)
401020: ff 35 e2 2f 00 00???? jmp *0x2fe2(%rip)? ; 實際跳轉到 GOT[2]
401026: 68 00 00 00 00??????? pushq $0x0???????? ; 推入函數ID(index)
40102b: e9 d1 ff ff ff??????? jmp 0x401001?????? ; 跳轉回 .plt 起始
這是 .plt[0] 的內容,作用是跳轉到動態鏈接器,完成函數的地址解析。這是第一次調用共享函數時執行的。
2. 后續條目(從 0x401030 開始,每 16 字節一組):
401030: ff 25 e2 2f 00 00???? jmp *0x2fe2(%rip)?? ; 間接跳轉(通過 GOT)
401036: 68 00 00 00 00??????? push $0x0?????????? ; 函數索引
40103b: e9 d1 ff ff ff??????? jmp 0x401010??????? ; 跳回 plt[0]
這類條目構成了具體函數的 PLT 調用入口,如:
printf@plt
getchar@plt
exit@plt
sleep@plt
這些跳轉首先會通過 GOT 項獲取函數地址,如果是首次調用會回到 .plt[0],進入鏈接器解析地址。
5.8 本章小結
本章通過實驗中的 hello 可執行程序,系統性地介紹了程序鏈接的基本概念和主要作用。首先,通過分析 hello 程序的 ELF 文件格式,掌握了可執行文件中的各個段(如 .text、.data、.bss 等)及其布局特征,并對比了目標文件 hello.o 與最終可執行文件 hello 在結構上的差異,加深了對鏈接后程序組織方式的理解。
接著,探討了 hello 程序的虛擬地址空間分布,明確了各段在內存中的映射情況,為理解程序加載執行提供了基礎支撐。通過對 hello 和 hello.o 進行反匯編分析,詳細比對了各符號的地址與調用過程,從而深入理解了鏈接器在重定位過程中的關鍵作用和實現機制。
此外,實驗中還完整跟蹤了 hello 程序的執行流程,整理并分析了執行過程中涉及的各個子函數調用及其關系,進一步加深了對程序執行邏輯的掌握。
最后,通過使用 gdb 和 edb 等調試工具,對 hello 程序的動態鏈接過程進行了實際分析,對比了程序在鏈接前后 .plt 和 .got 表的內容變化,全面認識了動態鏈接的工作原理及其對程序運行的影響。通過本章的學習與實驗操作,對程序鏈接機制有了更深入和系統的理解。
第6章 hello進程管理
6.1 進程的概念與作用
6.1.1 進程的概念
進程是計算機中已運行程序的一個動態實例,是系統進行資源分配和調度的基本單位,也是操作系統結構的核心組成部分。作為程序的基本執行實體,進程在當代以線程為中心的計算機體系結構中,扮演著線程運行環境的容器角色。簡而言之,進程是程序實際運行時的基本載體和執行單位。
6.1.2 進程的作用
在現代計算機系統中,操作系統為每個進程分配一個唯一的進程標識符(PID),這使得程序員能夠更高效地調度和管理正在運行的程序及其所占用的資源和數據。同時,每個程序獨占一個進程,有助于實現資源隔離,從而增強對程序內部數據和狀態的保護。
由于一個CPU核心在任意時刻只能執行一個進程的指令,這種執行機制促使硬件資源得以合理調度和充分利用。進程為程序提供了兩個關鍵的抽象:邏輯控制流和私有地址空間。邏輯控制流使得每個進程看起來像是獨占處理器在運行,而私有地址空間則確保每個進程擁有獨立的內存區域,從而避免了不同程序之間的直接干擾
6.2 簡述殼Shell-bash的作用與處理流程
Shell是操作系統核心的交互接口,承擔命令解釋與系統控制的雙重職能。其核心作用體現為:作為用戶與內核的翻譯層,將文本指令轉化為系統調用;作為進程控制器,通過創建子進程執行外部程序;同時管理環境變量、實現腳本自動化。典型處理流程為:讀取輸入→解析命令(詞法分析/語法擴展)→執行指令(內置命令直接響應,外部命令通過fork-exec機制啟動子進程)→反饋結果并循環等待。這種機制既保證了系統操作的高效性,又通過進程隔離維護了系統穩定性,成為UNIX/Linux系統運維的核心工具。
6.3 Hello的fork進程創建過程
輸入合法命令,如./hello 2023112915 楊昕彥 15682227797 2,解析后判斷為執行程序,父進程就通過fork函數創建一個新的運行的子進程;子進程得到與父進程用戶級虛擬地址空間相同的一份副本,包括代碼段、數據段、堆、共享庫和用戶棧。子進程中,fork返回0,父進程中,返回子進程的PID;

圖52 運行結果
在UNIX/Linux進程復制機制中,fork()系統調用創建的子進程通過寫時復制(Copy-on-Write)技術生成近乎完整的父進程副本。其核心特征表現為:
地址空間鏡像:子進程繼承父進程虛擬內存空間的精確拷貝(代碼段/數據段/堆棧等),通過COW機制實現物理內存的高效復用
資源繼承性:完整復制父進程的文件描述符表、信號處理程序及執行上下文環境
差異化標識:獨立分配的進程標識符(PID)、父進程標識符(PPID)指向原進程、重置資源使用統計(CPU時間/文件鎖等)、清除未決信號與定時器。
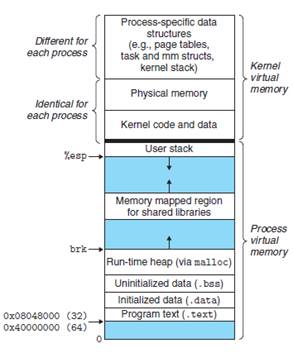
圖53 內存空間示意圖
6.4 Hello的execve過程
在fork創建子進程后,execve系統調用觸發進程映像重構:?
1. 地址空間重置
?? 清空原進程虛擬內存空間?
?? 根據hello的ELF文件結構,重構代碼段、數據段、堆棧及內存映射區域?
?? 保留原進程打開的文件描述符表?
2. 程序裝載階段*
?? 解析hello可執行文件的程序頭部表?
?? 將.text(代碼段)、.data(初始化數據段)載入內存?
?? 建立運行時堆(heap)和用戶棧(stack)結構?
3. 執行控制轉移?
?? 動態鏈接器(ld.so)完成共享庫加載(若需)?
?? 重置寄存器狀態,將程序計數器(EIP/RIP)指向入口點`_start`?
?? 通過`_start→__libc_start_main→main`調用鏈啟動用戶程序?
該過程通過內核態到用戶態的切換,實現進程執行流的無縫轉換。execve成功執行后,原進程上下文被完全替換,僅保留PID和文件資源,形成獨立的新執行環境。整個加載過程通過內存映射技術實現物理內存的按需分配,保證執行效率。
6.5 Hello的進程執行
在程序執行期間,Shell為“hello”進程創建了一個子進程,該子進程具有獨立的控制流。在“hello”進程的運行過程中,如果未受到外部搶占,則繼續正常執行;若被搶占,則會進入內核模式,進行上下文切換,并返回用戶模式,調度其他進程。當“hello”調用sleep系統調用時,為了最大化處理器資源的利用率,系統會將“hello”進程掛起,執行上下文切換進入內核模式,將其狀態轉入等待隊列,同時啟動定時器。當定時器到期后,sleep函數返回,觸發相應中斷,促使“hello”進程被重新調度,移出等待隊列,切換回用戶模式,從而繼續執行其剩余的控制流。這一機制有效實現了進程的掛起與喚醒,確保了系統的調度效率與資源利用的優化
6.6 hello的異常與信號處理
6.6.1 異常的類型
| 類別 | 原因 | 異步/同步 | 返回行為 |
| 中斷 | 來自I/O設備的信號 | 異步 | 總是返回到下一條指令 |
| 陷阱 | 有意的異常 | 同步 | 總是返回到下一條指令 |
| 故障 | 潛在可恢復的錯誤 | 同步 | 可能返回到當前指令 |
| 終止 | 不可恢復的錯誤 | 同步 | 不會返回 |
6.6.2 異常的處理方式
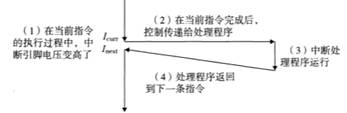
圖54 中斷處理方式
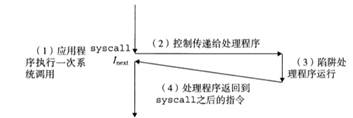
圖55 陷阱處理方式
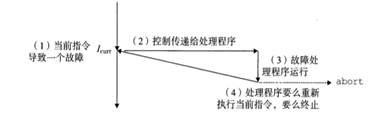
圖56 故障處理方式

圖57 終止處理方式
- Ctrl+Z:按下Crtl+Z,進程收到SIGSTP信號,hello進程掛起并向父進程發送SIGCHLD。

圖58 Ctrl+Z
運行ps命令查看進程運行狀態。
圖59ps查看進程運行狀態
運行jobs命令:
可以看到停止的作業:

圖60 jobs看停止的作業
pstree?是一個 Linux/Unix 系統工具,用于以樹狀拓撲圖直觀展示系統中所有進程間的父子關系。其核心功能與用法如下:
進程可視化
將進程按層級關系顯示為樹形結構,根節點為系統初始進程(如?systemd?或?init)
分支節點表示派生關系,例如:sshd → bash → vim
關鍵信息標注
默認隱藏線程(可通過?-T?顯示線程)
進程名旁標注進程號(PID,需?-p?參數)
高亮當前終端關聯的進程樹(-h)
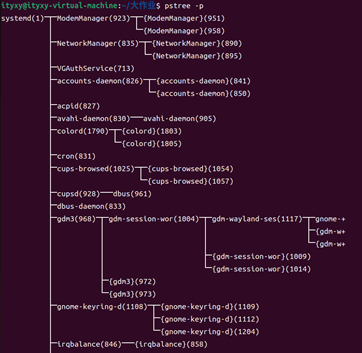
圖61 Pstree:顯示所有運行中的進程的樹狀圖
- Ctrl+C:進程收到 SIGINT 信號,結束 hello。在ps中查詢不到其PID,在job中也沒有顯示,可以看出hello已經被徹底結束。

圖62 ctrl+c
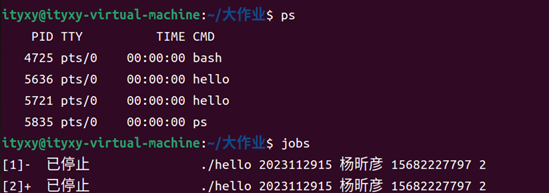
圖63 ps與jobs的運行結果
- 中途亂按:只是將屏幕的輸入緩存到緩沖區。亂碼被認為是命令。
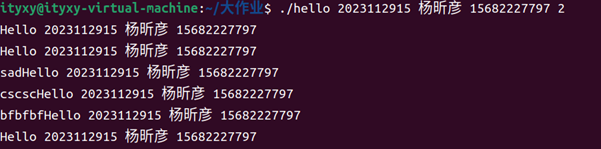
圖64 中途亂按的結果
4)Kill命令:掛起的進程被終止,在ps中無法查到到其PID。

圖65 kill指令的作用
6.7本章小結
本章系統闡述了操作系統進程的核心概念與運行機制,重點剖析了Shell作為用戶-內核交互中介的關鍵作用。通過hello可執行程序實例,深度解析了進程創建雙階段模型:fork() 采用寫時復制技術克隆父進程上下文,生成獨立PID的子進程; execve()通過清空地址空間、加載ELF文件結構、重構代碼/數據/堆棧段,實現進程映像的原子級替換。實驗環節結合命令行參數傳遞場景,驗證了信號處理機制對SIGINT(Ctrl+C)、SIGSEGV等異常事件的捕獲與響應策略,揭示了進程執行流中斷后的資源回收與狀態回傳原理。該研究完整呈現了從進程孵化、程序加載到執行監控的全鏈路技術細節,為理解UNIX系統級編程奠定了理論與實踐基礎。
第7章 hello的存儲管理
7.1 hello的存儲器地址空間
- 邏輯地址
定義:程序編譯期生成的段內偏移量,在x86架構中表現為段選擇符:偏移量`二元組(如 CS:EIP)?
實例特征:在`hello.asm`反匯編代碼中體現為代碼/數據的相對偏移(如 `0x4004e0`)?
- 線性地址
轉換機制:邏輯地址經CPU段式管理單元(Segment Unit)轉換后的連續地址空間?
分頁預處理:作為分頁機制的輸入地址,描述程序視角的連續虛擬內存布局?
示例映射: hello程序的代碼段/數據段在虛擬內存中的線性排布?
- 虛擬地址
體系結構特性:在x86保護模式下等同于線性地址(段式管理被扁平化)?
進程隔離性:每個進程獨占獨立的虛擬地址空間(如hello進程的0x400000起始代碼區)?
- 物理地址
硬件尋址:經MMU單元通過頁表(Page Table)+ TLB緩存轉換后,輸出至地址總線的電信號編碼?
實際映射:對應DRAM芯片上的物理存儲單元,如`hello`程序指令最終加載的內存條顆粒位置?
動態性:同一虛擬地址在不同時刻可能映射到不同物理地址(如進程上下文切換時)?
該多級映射體系通過段頁式管理(Segmentation + Paging)實現了內存安全隔離與物理資源動態分配,保障了hello等進程的高效可靠運行。地址轉換過程涉及CPU硬件(MMU)、操作系統(頁表維護)及編譯器(段描述符生成)的協同工作。
7.2 Intel邏輯地址到線性地址的變換-段式管理
??? 7.2.1段描述與段選擇符
在保護模式中,段的相關信息(如段基地址、段界限、訪問權限等)被封裝在段描述符中,每個段描述符占用 8 個字節。由于段寄存器僅有 16 位,無法直接存儲完整的段描述符信息,因此 Intel 設計了全局描述符表(GDT)和局部描述符表(LDT)來集中存放段描述符。段寄存器中存儲的是段選擇符(Segment Selector),用于索引 GDT 或 LDT 中的段描述符。段選擇符的結構如下:

圖66 kill段選擇符的結構
高 13 位:描述符索引(Index),指示段描述符在 GDT 或 LDT 中的位置。
第 2 位(TI):表指示符(Table Indicator),0 表示 GDT,1 表示 LDT。
低 2 位(RPL):請求特權級(Requested Privilege Level),用于權限檢查。
當一個新的段選擇符被加載到段寄存器中時,處理器會根據段選擇符的索引和表指示符,從 GDT 或 LDT 中獲取對應的段描述符,并將其加載到段寄存器的隱藏部分(描述符緩存)中。這樣,在后續的內存訪問中,處理器可以直接使用緩存的段描述符信息,無需再次訪問內存中的描述符表,從而提高了訪問效率。
?? 7.2.2邏輯地址到線性地址的轉換過程
在保護模式下,邏輯地址由段選擇符和段內偏移量組成。處理器將邏輯地址轉換為線性地址的過程如下:
加載段描述符:當一個新的段選擇符被加載到段寄存器中時,處理器根據段選擇符中的索引和表指示符,從 GDT 或 LDT 中獲取對應的段描述符,并將其加載到段寄存器的隱藏部分。
權限和有效性檢查:處理器根據段描述符中的權限信息和當前的特權級,檢查是否允許訪問該段。
計算線性地址:處理器將段描述符中的段基地址與段內偏移量相加,得到線性地址。
這個過程確保了內存訪問的安全性和靈活性。如果啟用了分頁機制,線性地址將進一步被轉換為物理地址。
7.2.3段寄存器與描述符緩存
x86 架構提供了六個段寄存器:CS(代碼段)、SS(堆棧段)、DS(數據段)、ES、FS 和 GS。每個段寄存器都有一個可見部分(存儲段選擇符)和一個不可見部分(描述符緩存)。當段選擇符被加載到段寄存器中時,處理器會自動將對應的段描述符加載到描述符緩存中。在后續的內存訪問中,處理器可以直接使用描述符緩存中的信息,無需再次訪問內存中的描述符表,從而提高了訪問效率。
在 x86 保護模式下,分段機制通過段選擇符和段描述符的配合,實現了從邏輯地址到線性地址的轉換。段選擇符用于索引段描述符,段描述符提供段的基地址和訪問權限等信息。處理器將段基地址與段內偏移量相加,得到線性地址。通過描述符緩存的機制,處理器可以高效地進行地址轉換,確保了內存訪問的安全性和性能。
7.3 Hello的線性地址到物理地址的變換-頁式管理
在 Linux 系統中,虛擬地址到物理地址的轉換主要依賴于分頁機制(Paging),這是虛擬內存管理的核心組成部分。分頁機制通過將虛擬內存和物理內存劃分為固定大小的頁(Page),并利用頁表(Page Table)建立虛擬頁與物理頁之間的映射關系,從而實現高效的內存管理和訪問控制。
7.3.1虛擬內存的組織結構
從概念上看,虛擬內存被組織為一個由 N 個連續字節大小的單元組成的數組,這些單元通常存儲在磁盤上。為了提高訪問速度,操作系統會將部分虛擬頁緩存在物理內存(DRAM)中,這些緩存的內存塊稱為頁(Page),每頁的大小通常為 4KB,有時也可以是更大的 2MB 或 1GB。
虛擬頁作為磁盤內容的緩存,具有以下特點:
全相聯映射:任何虛擬頁都可以映射到任何物理頁框中,這需要一個更復雜的映射函數。
寫回策略:DRAM 緩存通常采用寫回(Write-Back)策略,而不是直寫(Write-Through),以減少對內存的寫操作次數。
替換算法:由于硬件實現復雜的替換算法存在限制,DRAM 緩存的替換策略通常由操作系統在軟件層面管理。
虛擬頁集合被劃分為三個不相交的子集:
- 已緩存(Cached):當前駐留在物理內存中的頁。
- 未緩存(Uncached):尚未加載到物理內存中的頁。
- 未分配(Unallocated):尚未分配存儲空間的頁。
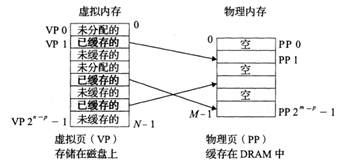
圖67 內存映射關系
7.3.2頁表與地址映射
頁表是一個由頁表條目(Page Table Entry, PTE)組成的數組,用于將虛擬頁地址映射到物理頁地址。每個進程都有自己的頁表,頁表常駐于主存中。在 x86 架構中,頁表通常采用多級結構(如三級或四級頁表),以減少內存占用并提高查找效率。
當處理器需要訪問某個虛擬地址時,地址轉換過程如下:
- 生成虛擬地址:CPU 生成一個虛擬地址,并將其發送給內存管理單元(MMU)。
- 查找頁表:MMU 使用虛擬地址中的頁目錄索引和頁表索引,逐級查找對應的頁表條目(PTE)。
- 獲取物理地址:如果 PTE 有效,MMU 提取其中的物理頁框號,并與頁內偏移量組合,形成完整的物理地址。
- 訪問內存:CPU 使用物理地址訪問主存,讀取或寫入數據。
為了加快地址轉換速度,處理器通常配備了翻譯后備緩沖區(Translation Lookaside Buffer, TLB),用于緩存最近使用的虛擬地址到物理地址的映射。如果 TLB 命中,MMU 可以直接獲得物理地址,避免訪問頁表。
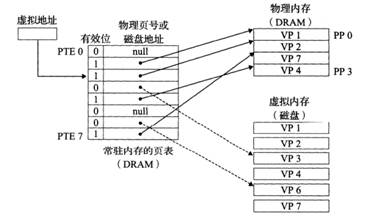
圖68 頁表的實現
下圖展示了頁式管理中虛擬地址到物理地址的轉換:
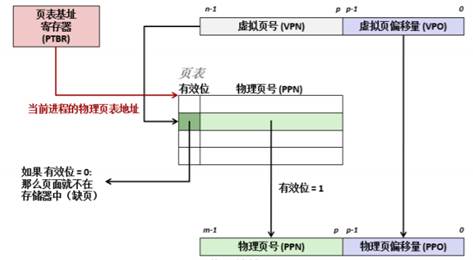
圖69 頁式管理
7.3.2缺頁異常處理
當訪問的虛擬頁不在物理內存中,即 PTE 的有效位為 0 時,會觸發缺頁異常(Page Fault)。操作系統的缺頁異常處理程序會執行以下步驟:
- 保存上下文:保存當前進程的狀態,以便在處理完異常后恢復。
- 查找頁數據:確定所需頁在磁盤上的位置。
- 選擇犧牲頁:如果物理內存已滿,選擇一個頁框進行替換(可能需要將其寫回磁盤)。
- 加載新頁:將所需頁從磁盤加載到物理內存中。
- 更新頁表:修改對應的 PTE,標記其為有效,并更新物理頁框號。
- 恢復執行:恢復進程狀態,重新執行導致缺頁的指令。
下面兩張圖展示了頁面命中和缺頁情況:
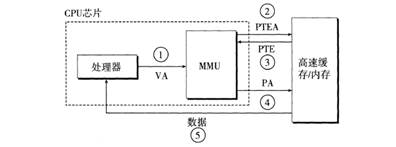
圖70 頁面命中
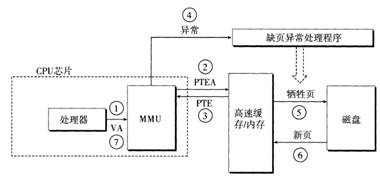
圖71缺頁
7.4 TLB與四級頁表支持下的VA到PA的變換
為了屏蔽每次 CPU 生成虛擬地址時對頁表項(PTE)訪問所引發的多級頁表遍歷延遲,現代處理器的內存管理單元(MMU)通常集成一個以內容可尋址存儲器(CAM)實現的全關聯小型緩存——翻譯后備緩沖器(TLB),用于存儲近期的虛擬頁號(VPN)到物理頁號(PPN)的映射,加速地址轉換流程。
該 TLB 在命中時僅需數個時鐘周期即可完成 VPN→PPN 的映射,其訪問延遲常低于 L1 級數據緩存的訪問延遲,從而顯著提升內存訪問的整體性能。
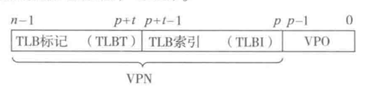
圖72 虛擬地址中用以訪問TLB的組成部分
TLB 將虛擬頁號(VPN)的高位和低位分別劃分為標記字段(TLBT)與索引字段(TLBI),并通過內容可尋址存儲器(CAM)以全關聯或組相聯方式高速緩存頁表項;MMU 在地址轉換時首先根據 TLBI 定位候選集合,再通過 TLBT 完成標簽匹配,若未命中則觸發多級頁表遍歷,將對應的頁表項(PTE)從內存加載并填充到 TLB 中。
??? 為避免單級頁表尺寸過大導致的內存浪費,x86?64(如 Intel Core?i7)采用四級頁表結構,依次由 PML4、PDPT、PD 及 PT 四級索引完成虛擬地址到物理頁號(PPN)的映射。
??? 此外,TLB 的訪問延遲僅需數個時鐘周期,其速度通常優于 L1 數據緩存,這得益于 CAM 的并行標簽比對機制及硬件預取優化,大幅提升了虛擬地址轉換的整體性能
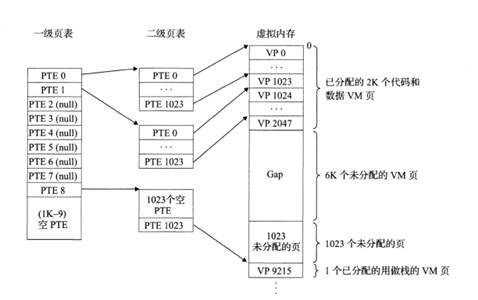
圖73 二級頁表
在四級頁表結構下,虛擬地址被拆分為四段虛擬頁號(VPN?、VPN?、VPN?、VPN?)和一段頁內偏移(VPO)。其中,第?i?級頁表的索引即對應 VPN?,而第?j?級頁表中的每個頁表項(PTE)都存儲著第?j+1?級頁表的物理基址;在第?4?級頁表中,PTE 則直接記錄了目標物理頁框號(PPN),或在需求下指向磁盤上的頁交換區。當 MMU 執行地址轉換時,若 TLB 未命中,便需依次讀取這四級 PTE,直至獲得最終的 PPN,隨后將其與頁內偏移組合,生成完整的物理地址。
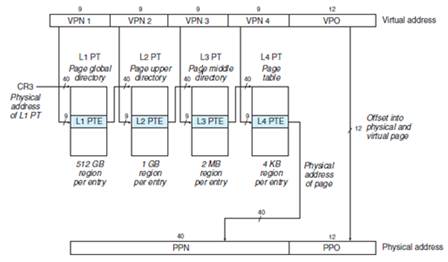
圖74 四級頁表
綜上所述,在四級頁表體系下,MMU 會先利用虛擬地址中的四段 VPN 通過 TLB 進行快速查找——若命中則直接獲得下一級頁表的物理基地址或最終的物理頁框號(PPN);若未命中,則依次訪問 PML4、PDPT、PD 和 PT 四級頁表項獲取 PPN,最終將該 PPN 與頁內偏移(VPO)拼接生成完整的物理地址(PA)。
7.5 三級Cache支持下的物理內存訪問
Core i7的內存系統如圖所示。
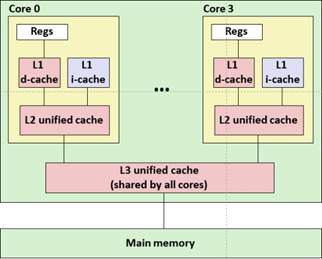
圖75 內存系統
首先,根據物理地址的 s 位組索引索引到 L1 cache中的某個組,然后在該組中查找是否有某一行的標記等于物理地址的標記并且該行的有效位為 1,若有,則說明命中,從這一行對應物理地址 b 位塊偏移的位置取出一個字節,若不滿足上面的條件,則說明不命中,需要繼續訪問下一級 cache,訪問的原理與 L1 相同,若是三級 cache 都沒有要訪問的數據,則需要訪問內存,從內存中取出數據并放入cache。
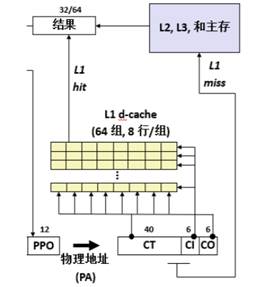
圖76 Cache訪問
7.6 hello進程fork時的內存映射
當fork函數被當前進程調用時,內核為新進程創建各種數據結構,并分配給它一個唯一的PID。為了給這個新進程創建虛擬內存,它創建了當前進程的mm_struct、區域結構和頁表的原樣副本。它將兩個進程中的頁面標記為只讀,并將兩個進程中的每個區域結構都標記為私有的寫時復制。
當fork在新進程中返回時,新進程現在的虛擬內存剛好和調用fork時存在的虛擬內存相同。當這兩個進程中的任一個后來進行寫操作時,寫時復制機制就會創建新頁面,因此,也就為每個進程保持了私有地址空間的概念。
7.6.1 fork()時的內存映射
(1)進程創建階段
操作系統通過以下方式創建子進程:
新建獨立的進程控制塊(PCB),建立進程管理結構
繼承父進程的關鍵上下文(包括打開的文件描述符、信號處理程序、內存映射表等)
(2)虛擬內存繼承
子進程通過以下方式共享父進程內存資源:
獲得與父進程完全一致的虛擬地址空間映射表
所有虛擬頁表項初始設置為與父進程共享物理頁幀(此時尚未進行物理內存復制)
(3)寫時復制優化
內存資源的動態管理機制:
共享的物理內存頁被標記為寫保護狀態
當任一進程(父/子)嘗試執行寫操作時觸發頁錯誤異常
內核攔截異常后執行物理頁復制,為修改進程分配獨立的新物理頁
僅復制被修改的特定內存頁(4KB粒度),保持未修改頁的共享狀態
7.6.2 寫時復制(COW)具體過程
fork()調用時,子進程會繼承父進程的虛擬地址空間,但并不會立即復制所有物理內存。通過寫時復制技術,父子進程共享相同的物理頁,直到有寫操作發生時,才會分配新的物理頁。這樣可以高效地管理內存,并減少 fork()的開銷。這種機制對于創建新進程和高效利用內存資源非常重要。
(1)寫操作觸發頁錯誤:嘗試寫入只讀頁會觸發頁錯誤。
(2)操作系統處理頁錯誤:操作系統檢測到這是寫時復制情況。
(3)復制物理頁:操作系統為寫入操作分配一個新的物理頁,并將舊頁的數據復制到新頁。
(4)更新頁表:更新進程的頁表,使得該虛擬頁映射到新的物理頁,并將頁標記為可寫。
(5)完成寫操作:進程繼續執行寫操作。
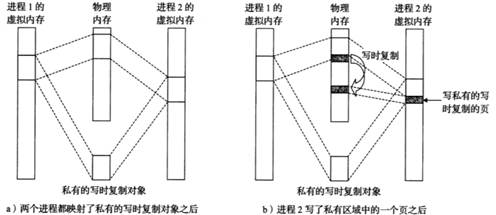
圖77 寫時復制
7.7 hello進程execve時的內存映射
execve 函數調用駐留在內核區域的啟動加載器代碼,在當前進程中加載并運 行包含在可執行目標文件 hello 中的程序,用 hello 程序有效地替代了當前程序。 加載并運行 hello 需要以下幾個步驟:
1.系統調用進入與權限檢查
進程從用戶態觸發 sys_execve,切換到內核態,并檢查調用者對目標文件的可執行權限。
同時核實當前進程是否有能力改變其映像(如是否被 ptrace 附加、是否為 set?uid/set?gid 等)。
2.清理舊的用戶空間映射
內核調用 mm_release() 等函數,撤銷當前進程所有進程空間(struct mm_struct)中的用戶態內存映射(VMA),包括代碼、數據、堆、棧及任何匿名或文件映射。
這意味著所有原來打開的匿名頁和文件映射都被卸載,引用計數減少,必要時回收頁面。
3.建立新程序的地址空間布局
解析 ELF 頭與各段(segment)
內核讀取 ELF 可執行文件頭(ELF64_Ehdr),根據 program header 表(PHDR)里各 LOAD 段的偏移和大小,分別在進程的地址空間中創建對應的 VMA,并調用 do_mmap_pgoff() 將 .text、.data 區域以私有寫時復制(private COW)的方式映射到文件內容。
.bss 和 堆/棧 區域
.bss 區段沒有文件數據,只需要在虛擬區間內請求相應大小的匿名映射(全零頁);
堆通常從符號 brk 開始,后續動態分配時按需擴展;
用戶棧(ULOWER_STACK 附近)也是用匿名映射,但初始僅分配少量頁面,后續通過缺頁中斷自動擴展。
4.加載動態鏈接器與共享庫
如果這個 ELF 是動態可執行文件(ET_DYN + PT_INTERP),內核首先把動態鏈接器(如 /lib64/ld?linux?x86?64.so.2)映射到地址空間,然后由鏈接器負責加載并重定位依賴的共享對象(如 libc.so.6)。
鏈接器在用戶態(而非內核態)完成符號解析與重定位,設置各共享庫的基址和 GOT/PLT 等。
5.構造棧幀:argv/envp/auxv
內核在用戶棧頂壓入 argc、argv 字符串指針數組、envp 數組,以及一組輔助向量(auxv),包含了諸如平臺標識、頁大小、程序入口點、動態鏈接器基址等信息,供動態鏈接器和程序啟動時使用。
6.設置進程上下文并跳轉到入口
更新 current->mm、current->active_mm 等指針;
重置信號處理、文件描述符的 close-on-exec 標志;
最后,將用戶態寄存器(包括程序計數器 PC / RIP)設置為 ELF 頭中指定的 e_entry,然后執行 return_to_user_mode(),開始執行 hello 的第一條指令。
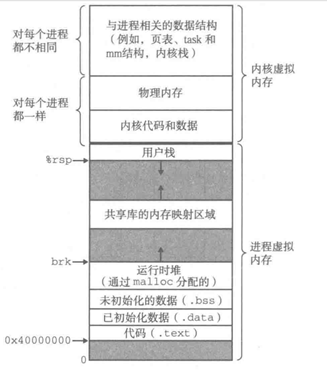
圖78 虛擬內存
7.8 缺頁故障與缺頁中斷處理
缺頁故障是操作系統管理虛擬內存時的一種核心機制,當程序試圖訪問尚未加載到物理內存的虛擬內存頁面時便會觸發。現代計算機通過虛擬內存技術為每個進程提供獨立的虛擬地址空間,使得程序能夠使用比實際物理內存更大的內存資源,但這些虛擬內存頁面可能存儲在物理內存或磁盤(如交換空間)中。當 CPU 訪問某個虛擬地址時,內存管理單元(MMU)會查詢頁表,若發現對應的頁表項標記為“無效”(即頁面不在物理內存中),則會產生缺頁故障。?
此時,操作系統會暫停當前進程,進入內核態處理該故障:首先檢查訪問的虛擬地址是否合法(例如是否存在越界或權限錯誤),若合法則從物理內存中分配一個空閑頁框,若無空閑頁框則通過頁面置換算法(如 LRU、FIFO)將某個頁面換出到磁盤,隨后從磁盤(可能是交換文件或程序文件)中讀取目標頁面到物理內存,并更新頁表以標記該頁面為“有效”。最終,系統會重新執行觸發缺頁的指令,使程序繼續運行。?
缺頁故障分為三種類型:次要缺頁(頁面已在內存緩存中,僅需更新頁表,無磁盤 I/O)、主要缺頁(需從磁盤加載頁面,耗時較長)和無效缺頁(訪問非法地址導致進程終止,如段錯誤)。其常見原因包括程序初次加載代碼數據、內存訪問的局部性變化(如遍歷新數組)或物理內存不足導致的頻繁頁面置換(即“抖動”現象)。?
盡管缺頁是內存擴展的必要機制,但頻繁的主要缺頁(尤其是涉及磁盤 I/O 時)會顯著拖慢程序性能。例如,在首次訪問動態分配的大數組元素時,若頁面未預加載,每次訪問都可能觸發缺頁。為優化性能,可通過預加載頁面、調整頁面大小、減少內存碎片或增加物理內存等手段降低缺頁頻率,從而提升系統效率。
下圖對VP3的引用不命中,從而觸發缺頁。
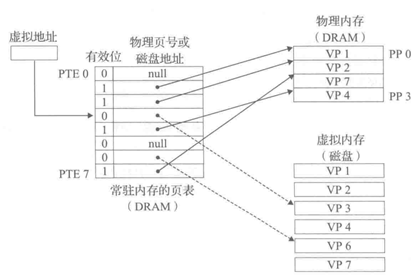
圖79 缺頁
缺頁之后,缺頁處理程序選擇VP4作為犧牲頁,并從磁盤上用VP3的副本取代它。在缺頁處理程序重新啟動導致缺頁的指令之后,該指令將從內存中正常地讀取字,而不會再產生異常。、
缺頁中斷處理是操作系統在程序訪問未加載到物理內存的虛擬頁面時觸發的核心機制。當CPU通過頁表發現目標頁面不在物理內存時,會暫停當前進程并交由操作系統處理:首先檢查訪問地址的合法性,若合法則分配物理頁框,隨后從磁盤加載所需頁面到內存,更新頁表并標記為“有效”,最后重新執行被中斷的指令。此過程若涉及磁盤I/O會顯著延遲程序運行,而頁面已緩存時則無需磁盤操作,效率更高。該機制保障了虛擬內存的靈活性,但頻繁缺頁會嚴重拖累系統性能。
7.9動態存儲分配管理
動態內存分配器作為內存管理的核心組件,主要負責管理進程虛擬內存中的堆區域。該機制將堆空間組織為多個離散的內存區塊集合,每個區塊表征一段連續的虛擬內存單元,其狀態可分為已分配(allocated)或空閑(free)兩種形態。
已分配區塊由應用程序顯式聲明占用,這些內存單元被鎖定為專用狀態直至釋放。與之對應的空閑區塊則處于待分配狀態,其內存資源可被動態調度以滿足新的內存請求。特別需要指出的是,內存區塊的狀態轉換遵循明確的規則:空閑區塊僅能通過顯式的分配請求轉為占用狀態,而已分配區塊的釋放既可通過程序員的顯式操作完成,也可能由內存分配器通過垃圾回收等隱式機制自動實現。這種雙模式釋放機制有效平衡了開發靈活性與內存安全性,構成現代內存管理體系的重要特征。
內存管理中的分配器技術可分為兩大范式:顯式分配器與隱式分配器,二者在內存回收機制上存在本質差異。
1. 顯式分配器:采用開發者主導的內存管理模式,要求程序員通過特定指令(如C語言的free())主動釋放不再使用的內存塊。這種機制將內存生命周期管理的責任賦予開發者,雖能實現精準控制,但也存在內存泄漏(Memory Leak)或重復釋放(Double Free)等風險,典型代表包括C標準庫的malloc/free接口。
2. 隱式分配器:通過自動垃圾回收(Garbage Collection, GC)機制實現內存自治,其核心在于動態追蹤內存塊的引用狀態。當分配器檢測到某內存塊不再被任何指針引用時,自動將其標記為可回收資源并釋放。該機制有效避免了人為管理失誤,但需要運行時系統維護對象引用圖譜(如Java虛擬機),且可能引入GC暫停等性能開銷。
帶邊界標簽的隱式空閑鏈表分配器原理:
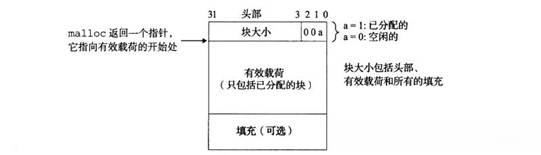
圖80 隱式空閑鏈表分配器
每個塊可以增加四字節的頭部和四字節的腳部保存塊大小和是否分配信息,可以在 常數時間訪問到每個塊的下一個和前一個塊,使空閑塊的合并也變為常數時間,而且可以遍歷整個鏈表。隱式空閑鏈表即為,利用邊界標簽區分已分配塊和未分配塊,根據不同的分配策略(首次適配、下一次適配、最佳適配),遍歷整個鏈表,一旦找到符合要求的空閑塊,就把它的已分配位設置為1,返回這個塊的指針。隱式空閑鏈表并不是真正的鏈表,而是"隱式"地把空閑塊連接了起來(中間夾雜著已分配塊)。
顯式空閑鏈表的基本原理:
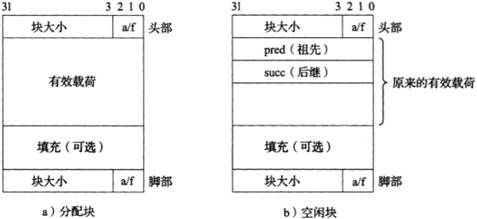
圖81 顯式空閑鏈表分配器
使用雙向鏈表而不是隱式空閑鏈表,使首次適配的分配時間從塊總數的線 性時間減少到了空閑塊數量的線性時間。種方法使用后進先出的順序維護鏈表,將新釋放的塊在鏈表的開始處。使用LIFO的順序和首次適配的放置策略,分配器會最先檢查最近使用過 的塊,在這種情況下,釋放一個塊可以在線性的時間內完成,如果使用了邊界 標記,那么合并也可以在常數時間內完成。按照地址順序來維護鏈表,其中鏈 表中的每個塊的地址都小于它的后繼的地址,在這種情況下,釋放一個塊需要 線性時間的搜索來定位合適的前驅。平衡點在于,按照地址排序首次適配比 LIFO 排序的首次適配有著更高的內存利用率,接近最佳適配的利用率。
動態內存管理通過兩種基本方法實現:顯式管理由開發者手動分配(如malloc)和釋放(如free)內存,精準高效但易引發泄漏或錯誤;隱式管理則依賴垃圾回收器(GC)自動追蹤無引用內存并釋放,簡化開發但可能引入性能波動。核心策略包括:采用首次適應、最佳適應等算法搜索空閑內存塊;通過塊合并或內存壓縮減少碎片;利用內存池預分配資源提升效率,或通過分離空閑鏈表、伙伴系統分層優化分配。例如, printf可能在處理不定長輸出時調用malloc動態申請緩沖區,此時內存池技術可減少頻繁分配的開銷。動態內存管理需權衡空間與時間效率,在控制碎片、降低延遲和保證靈活性之間尋求平衡,是系統性能優化的關鍵環節。
7.10本章小結
本章如同構建一套“城市級內存管理體系”:?
1. 虛擬地址空間是程序視角的“虛擬城市地圖”,段式管理如同將城市劃分為商業區、住宅區等專屬分區(Intel分段機制),而頁式管理則像將城市土地細化為標準尺寸的模塊化拼圖(內存分頁),通過VA到PA轉換實現“虛擬地圖坐標”到“物理土地定位”的精準映射;?
2. 物理內存訪問相當于在城市真實地塊上建設施工,進程fork/execve時的內存映射如同為新建城區快速復制或重建規劃藍圖;?
3. 缺頁中斷類似施工時發現某地塊未開發,立即觸發“物流補貨系統”調撥資源(加載物理頁),而動態內存分配則是城市中靈活調配臨時倉庫的物流調度中心(堆管理),協調內存資源的實時供需。?
這套體系從規劃到執行,貫穿虛擬構想、物理實施與動態調度,構建了程序運行的“內存生態城市”。
第8章 hello的IO管理
8.1 Linux的IO設備管理方法
設備的模型化:文件
設備管理:unix io接口
這種將設備映射為文件的設計,使內核能夠提供一套簡單而統一的應用層接口,也就是經典的 Unix I/O。無論是磁盤、終端還是網絡設備,應用程序都可以通過以下四步以一致的方式與它們交互:
打開文件、定位文件指針、讀寫數據)、關閉文件
通過這種“萬物皆文件”的理念,Linux 實現了設備訪問的高度模塊化和可擴展性,使得新設備的接入僅需遵循文件接口規范即可,無需為每種設備開發獨立的調用接口。
8.2 簡述Unix IO接口及其函數
Unix I/O 接口的幾種操作:
1. 打開與創建:
open() / openat()打開一個已存在的文件或設備,并返回一個新的文件描述符;同時可指定標志如 O_RDONLY、O_CREAT、O_CLOEXEC 等。
creat()相當于 open(path, O_CREAT|O_WRONLY|O_TRUNC, mode) 的簡化接口,用于創建并打開新文件。
2. 關閉
close()關閉指定的文件描述符,釋放內核中對應的打開表項。
3. 數據傳輸
read()從文件描述符對應的文件或設備中讀取最多 nbytes 字節到用戶緩沖區,返回實際讀取的字節數。
write()將用戶緩沖區中的最多 nbytes 字節寫入到對應的文件或設備,返回實際寫入的字節數。
pread() / pwrite()與 read/write 類似,但在不改變文件偏移量的前提下指定讀取/寫入的文件偏移位置。
4. 文件偏移定位
lseek()調整文件描述符的當前偏移量,可用于隨機訪問或基于當前位置/文件開頭/文件末尾的尋址。
5. 控制與屬性查詢
ioctl()向設備或文件描述符發送特殊控制指令,用于配置硬件或查詢底層驅動狀態。
fcntl()對文件描述符執行各種操作,如設置非阻塞(F_SETFL, O_NONBLOCK)、獲取/設置 close-on-exec 標志、復制描述符等。
6. 描述符復制
dup() / dup2() / dup3()復制一個已有的文件描述符,生成新的描述符指向同一內核打開表項,可用于重定向標準輸入/輸出。
7. I/O 多路復用
select() / pselect()監視一組文件描述符的可讀、可寫或異常狀態,支持超時等待。
poll()
類似 select,使用 pollfd 數組并支持更多事件類型,解決了文件描述符數量限制的問題。
epoll(Linux 專有:epoll_create1、epoll_ctl、epoll_wait)面向大規模并發場景設計的高效多路復用接口。
8. 內存映射
mmap()將文件或設備映射到進程虛擬內存空間,讀寫時直接在地址空間操作,可用于高性能 I/O 或與硬件共享內存。
munmap()取消先前的映射,釋放對應的虛擬地址區間。
Unix I/O 函數:
1. int open(const char *pathname, int flags, mode_t mode)
open 函數用指定的 pathname 打開(或創建)一個文件,并返回對應的文件描述符。返回值為進程中尚未使用的最小整型描述符。flags 參數指定訪問方式(如只讀、只寫、創建、截斷、關閉執行時繼承等),mode 參數則在創建新文件時定義文件的權限位(如所有者讀寫、組讀、其他人讀等)。
2. int close(int fd);
close 函數關閉參數 fd 指定的文件描述符,使其不再引用任何文件或設備,并將該描述符返還給系統以供后續 open 使用。若這是最后一個指向該文件的描述符,則會釋放相關資源,例如移除任何記錄鎖,且若文件已被刪除,則此時才真正回收磁盤空間。操作成功返回 0,失敗返回 -1 并設置 errno。
3. ssize_t read(int fd, void *buf, size_t count);
read 函數嘗試從描述符 fd 當前的文件偏移位置讀取最多 count 字節的數據到用戶提供的緩沖區 buf。返回值為實際讀取的字節數;若返回 0 則表示已到達文件末尾 (EOF),返回 -1 則表示發生錯誤并設置 errno。在支持隨機定位的文件上,每次讀取后文件偏移量會自動向后移動相應的字節數。
4. ssize_t write(int fd, const void *buf, size_t count);
write 函數將用戶緩沖區 buf 中最多 count 字節的數據寫入到描述符 fd 對應的文件或設備。返回值為實際寫入的字節數;若寫入失敗則返回 -1 并設置 errno。對于非阻塞文件描述符,寫入量可能少于請求量,調用者需根據返回值決定后續操作。
8.3 printf的實現分析
顯示信息先由?vsprintf?生成,再通過?write?系統調用輸出,最后通過陷阱指(int?0x80?或?syscall)進入內核。
先找到 printf 的函數定義:

圖82 printf的函數定義
其中,va_start() 與 va_end() 用于處理可變參數。在訪問任何可變參數之前,必須先通過 va_start(argptr, fmt) 初始化參數指針 argptr;隨后,每次調用 va_arg(argptr, type) 即可按指定類型依次取出下一個參數。參數取完后,函數返回之前務必調用 va_end(argptr),以確保堆棧狀態得以正確恢復。之后,printf 會調用 Unix I/O 函數 write,將 printbuf 緩沖區中長度為 i 的字節輸出到屏幕——這里 i 即由 vsprintf(printbuf, fmt, args) 返回的字符數,因此 vsprintf 的作用至關重要。
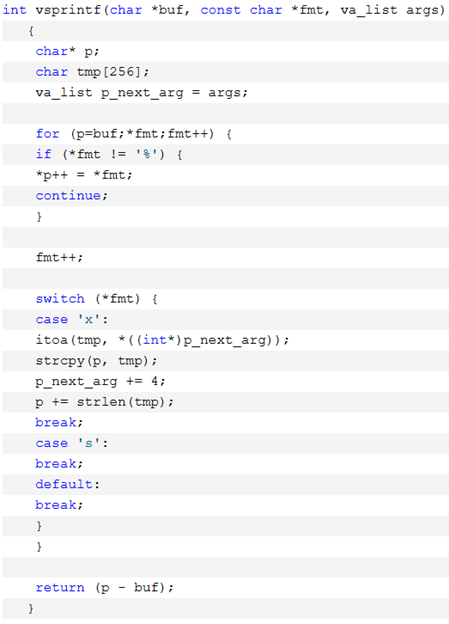
圖83 vsprintf代碼
vsprintf 的作用是根據 printf 的格式字符串和參數,將格式化后的結果寫入緩沖區 buf 中,并返回生成字符串的長度。隨后,write 系統調用負責輸出:在 Linux 中,write(fd, buf, count) 的第一個參數 fd 為文件描述符,其中 1 表示標準輸出。其匯編實現先將 fd、buf 和 count 分別加載到指定寄存器,然后執行中斷指令(如 int 0x80 或 syscall),觸發內核的系統調用入口;內核將緩沖區中的數據通過總線傳遞至顯存(VRAM)。顯示芯片依照刷新頻率逐行讀取 VRAM 中的 RGB 像素數據,并通過信號線將每個像素點傳輸至液晶顯示器,最終將格式化后的字符串呈現于屏幕上。字符顯示過程涉及:將 ASCII 碼映射到字模庫,再將字模點陣寫入 VRAM,完成從字符到屏幕顯示的整個流水線。
8.4 getchar的實現分析
當用戶按下按鍵時,鍵盤控制器會生成對應的掃描碼并觸發一個中斷請求,內核隨即暫停當前進程,轉而執行鍵盤中斷處理程序。該程序首先從鍵盤控制器讀取掃描碼,將其轉換為 ASCII 碼,然后將得到的字符放入系統的鍵盤緩沖區中。
再來看 getchar 的實現:
int getchar(void)
{
static char buf[BUFSIZ];
static char* bb=buf;
static int n=0;
if(n==0)
{
n=read(0,buf,BUFSIZ);
bb=buf;
}
return(--n>=0)?(unsigned char)*bb++:EOF;
}
這里,getchar 調用了 read,而 read 又通過系統調用 (int 0x80 或 syscall) 將緩沖區中保存的 ASCII 字符讀入到用戶空間。read 會一直讀取,直到碰到回車符(或達到緩沖區大小),然后返回實際讀取的字節數。getchar 則每次只取出其中的第一個字符,其余字符仍留在輸入緩沖區,供后續調用使用。
8.5本章小結
Linux I/O 設備管理方法
介紹了 Linux 如何將所有 I/O 設備統一抽象為文件(“萬物皆文件”),并通過文件模型對設備進行管理,包括 block 設備、字符設備和網絡設備的掛載與訪問方式。
Unix I/O 接口及其系統調用
闡述了 Unix I/O 的四大基本流程:打開(open)、定位(lseek)、讀寫(read/write)和關閉(close),并補充了多路復用(select/poll/epoll)、控制操作(ioctl/fcntl)、內存映射(mmap)等擴展接口。
printf 函數實現分析
解析了 printf 內部如何借助 vsprintf 將格式化字符串與參數轉換生成輸出文本,隨后調用 write 系統調用通過中斷陷阱(int?0x80 或 syscall)將數據寫入標準輸出,并最終由顯存和顯示硬件完成屏幕顯示。
getchar 函數實現原理
描述了鍵盤中斷處理流程——掃描碼讀取、轉換為 ASCII 并存入內核緩沖區;以及用戶態 getchar 如何通過一次 read 系統調用批量讀取緩沖區內容,再逐字符返回,剩余字符留在輸入緩沖區中以供后續調用。
通過本章學習,全面掌握 Linux 內核對 I/O 設備的抽象與管理機制,Unix I/O 接口的使用范式,以及常用 C 標準庫函數(printf、getchar)底層調用流程的實現細節。
結論
1.預處理階段
hello.c 經由預處理器(cpp)展開宏、處理 #include 和條件編譯,生成純文本的中間文件 hello.i。
2.編譯階段
編譯器前端(如 gcc -S)將 hello.i 轉換為匯編代碼 hello.s,完成語法分析與中間代碼生成。
3.匯編階段
匯編器(如 as)將 hello.s 匯編成機器碼,產出可重定位的目標文件 hello.o,并在符號表中記錄外部引用。
4.鏈接階段
鏈接器(ld)把 hello.o 與所依賴的庫(靜態或動態)合并,解決符號引用,生成可執行文件 hello。
5.運行階段
Shell 進程調用 fork() 復制出子進程,再通過 execve("hello", …) 將新進程的地址空間替換為 hello 的映像。
運行中,虛擬地址被加載并重定位至物理內存(最終映射為物理地址 PA),程序調用諸如 printf、getchar 等函數,與 Linux 的 I/O 子系統交互。
6.退出與回收
程序結束后由父進程(Shell)通過 wait() 收集子進程的退出狀態,內核回收其所有資源,包括頁表、文件描述符和內存映射。
二.深度體驗與收獲
1.每一步都非“黑箱”
從簡單的一行 printf("Hello\n"),其實背后要經歷預處理、編譯、匯編、鏈接、系統調用、內存管理等多道工序,方能展現在屏幕上。
只有親自跟蹤過各個中間文件與工具輸出,才能真正理解編譯鏈(toolchain)的嚴謹與魔力。
2.系統設計的精巧與嚴密
鏈接器的符號解析、動態鏈接的重定位機制、寫時復制(COW)策略、段式地址空間管理、I/O 的“萬物皆文件”抽象……每個細節都體現了系統設計者的智慧。
從邏輯到性能,內核與運行時庫無縫協作,保障了程序的可移植性、可維護性與高效性。
3.理論與實踐的結合
CSAPP(《深入理解計算機系統》)不僅停留在紙面概念,而是要求我們動手驗證、在真實環境中排錯,才能將抽象知識轉化為直觀感受。
例如,查看匯編輸出發現調用約定、參數傳遞與棧幀布局的差異,加深了對 CPU 架構與 ABI 的理解。
4.學習路程的意義
從源代碼到機器指令,再到硬件顯示過程,每一步都凝聚了計算機系統的復雜性,也展現了其可控性與可預測性。正如流水線中每個微小周期都精確計算、緩存層級巧妙加速,操作系統與編譯器同樣為我們的程序護航。
三、致謝與展望
回顧這一學期的學習旅程,深感計算機系統的博大精深,也體會到不斷鉆研與動手實驗的重要性。衷心感謝授課教師的耐心講解與答疑,也感謝同學們的相互討論。雖然我們剛剛踏上征途,但正是這些基礎奠定了未來探索更深層次系統編程、操作系統原理與編譯技術的信心與動力。
附件
| 文件名稱 | 描述介紹 |
| hello.c | 源程序文件 |
| hello.i | hello.c通過預處理器cpp預處理后的文本文件 |
| hello.s | hello.i通過編譯器ccl編譯后的匯編程序 |
| hello.o | hello.s通過匯編器as匯編后的文件 |
| hello | hello.o通過鏈接器ld鏈接后的可執行文件 |
| Objdump_hello.ohello.o | 反匯編文件 |
| Objdump_hello hello | 反匯編文件 |
參考文獻
[1] CSDN_專業開發者社區_已接入DeepSeekR1滿血版
[2]DeepSeek | 深度求索
[3] https://github.com.
[4]Randal E.Bryant David R.O'Hallaron.深入理解計算機系統(第三版).機械工業出版社

)




Java/python/JavaScript/C/C++/GO最佳實現)
)





)





