
- 作者:Pranav Saxena, Nishant Raghuvanshi and Neena Goveas
- 單位:比爾拉理工學院(戈瓦校區)
- 論文標題:UAV-VLN: End-to-End Vision Language guided Navigation for UAVs
- 論文鏈接:https://arxiv.org/pdf/2504.21432
主要貢獻
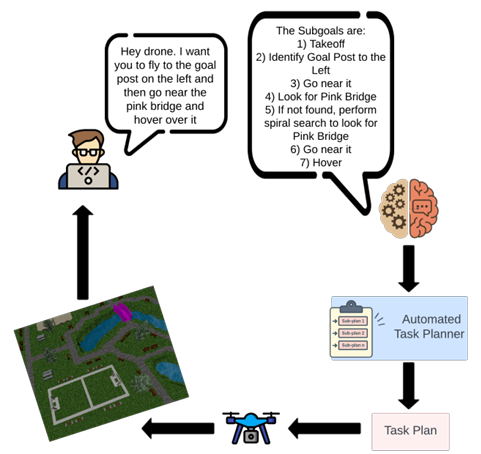
- 提出了UAV-VLN,這是一個針對無人機(UAV)的端到端視覺語言導航(VLN)框架,能夠在復雜的真實世界環境中解釋和執行自由形式的自然語言指令,填補了無人機視覺語言導航領域的研究空白。
- 構建了一個包含1000多個空中導航指令提示及其對應子計劃的新穎數據集,專門用于訓練和評估適用于3D無人機環境的大型語言模型。
- 證明了該方法能夠泛化到未見環境和指令,在室內外環境中均實現了穩健的零樣本導航性能。
研究背景
- 無人機(UAV)在室內和室外環境中承擔著越來越多的任務,如包裹遞送、空中監視和搜索救援等,這些任務要求無人機能夠在動態、以人類為中心的環境中導航,同時與靜態物體和移動主體進行交互。
- 傳統的無人機導航方法依賴于預定義的飛行路徑或基于GPS的航點,難以應對動態環境、不確定性和信息不完整的挑戰。
- 視覺語言導航(VLN)為無人機導航提供了新的方向,使無人機能夠通過視覺輸入將高級自然語言指令轉化為復雜的導航任務,但以往的VLN方法主要針對在結構化二維環境中運行的輪式或腿式機器人,對無人機的適用性有限。
研究方法
問題定義
- 任務目標:給定一個自由形式的自然語言指令 I I I 和無人機從機載RGB相機捕獲的視覺觀測流 V = { v 1 , v 2 , … , v T } V = \{v_1, v_2, \dots, v_T\} V={v1?,v2?,…,vT?},目標是預測一個控制指令序列 A = { a 1 , a 2 , … , a T } A = \{a_1, a_2, \dots, a_T\} A={a1?,a2?,…,aT?},引導無人機從起始位置到達指令中描述的目標位置或目標狀態,同時安全地穿越環境。
- 關鍵挑戰:
- 語義解析:從非結構化語言中提取可操作的目標和空間線索。
- 視覺定位:在動態、無結構的環境中,將語言引用的對象和區域與無人機的視覺視野對齊。
- 軌跡規劃:在三維空間中生成可行、安全且符合指令的飛行路徑。
- 泛化能力:在新環境中保持魯棒性,對新的指令和視覺場景具有最小的重新訓練需求。
自然語言Prompt
- 核心目標:準確理解和執行自然語言指令。
- 問題:通用的預訓練大型語言模型(如ChatGPT或Gemini)在無人機導航任務中可能會出現誤解或錯誤分類動作,且依賴云端基礎設施可能導致延遲或可用性問題。
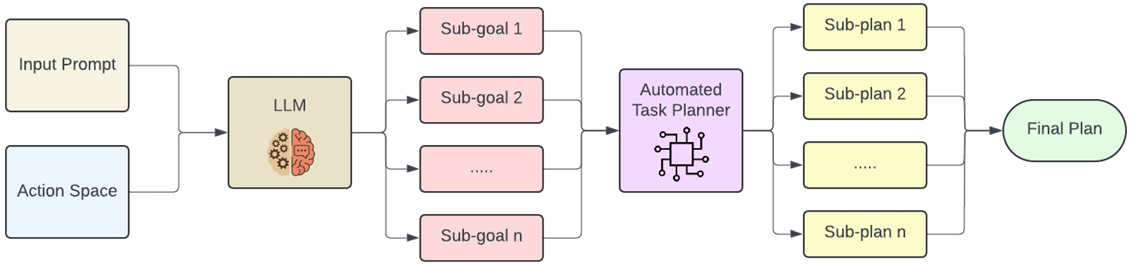
- 解決方案:采用基于領域特定數據集的微調方法。作者定制了一個無人機指令數據集,并在該數據集上微調了TinyLlama-1.1B模型,使其更好地理解無人機特定的術語、空間指令和安全關鍵細節。
- 輸入:
- 輸入提示:用戶提供的高級自然語言指令。
- 動作空間:無人機可以執行的所有有效離散動作集合。
- 輸出:微調后的LLM生成一系列中間子目標,每個子目標對應一個可執行的無人機動作。
自動化任務規劃器
- 功能:將LLM分解的高級子目標進一步轉換為具體的行動計劃,以便無人機在物理環境中執行。
- 實現:
- 利用無人機的離散動作空間,結合當前狀態和環境上下文,為每個子目標生成有效且高效的子計劃。
- 將這些子計劃組合成一個連貫的最終執行計劃,確保無人機安全且最優地完成任務。
- 技術實現:使用Robot Operating System 2(ROS 2)實現控制流程,提供模塊化、實時能力和與無人機飛行堆棧的穩健集成。

視覺輸入
- 目標:結合語言理解分析視覺輸入,確定無人機的目標位置。
- 挑戰:無人機不僅要準確感知環境,還要根據自然語言指令對感知結果進行語義定位。
- 解決方案:采用開放詞匯對象檢測器Grounding DINO,利用文本查詢的語義豐富性定位視覺輸入中的相關實體。
- 輸入:指令和微調后的TinyLlama-1.1B模型處理后的文本。
- 輸出:目標對象或區域的描述符,用于在相機流中定位目標。
- 功能:
- 解釋指令以識別目標對象或地標。
- 使用Grounding DINO在相機流中定位這些目標。
- 根據無人機與檢測到的實體之間的空間關系生成基于語義的子目標。
終止條件
- 重要性:準確判斷何時終止導航任務與執行路徑本身同等重要。過早或過晚終止可能導致無人機懸停、漂移或錯過目標位置。
- 終止邏輯:
- 目標對象檢測:使用Grounding DINO確認當前視野中是否存在指令中指定的目標對象或地標。
- 接近度檢查:使用預定義的空間閾值驗證無人機是否在目標的可接受范圍內。
- 指令滿足:驗證從指令中派生的子目標是否已成功執行。
- 實現:終止邏輯集成在ROS 2控制堆棧中,確保任務結束時無人機狀態的安全處理,并為未來擴展(如用戶發起的停止信號或任務失敗時的動態重新規劃)提供支持。
實驗
實驗設置
- 硬件:在配備Nvidia GTX 1650 GPU的筆記本電腦上運行,模擬真實無人機配備的計算能力。
- 模擬器:使用Gazebo Garden與ROS 2進行仿真,無人機配備Pixhawk飛行控制器和底部安裝的單目相機。
- 評估指標:使用成功完成任務的比例(Success Rate, SR)和路徑效率(Success Rate Weighted by Inverse Path Length, SPL)進行評估。
評估場景
實驗在四個不同場景中進行,每個場景包含15個不同的導航任務:
- 倉庫
- 公園
- 房屋社區
- 辦公室
基線方法
- DEPS:使用LLM進行中間推理,通過描述環境、解釋子目標、規劃候選動作并選擇可行計劃。
- VLMNav:使用Gemini 2.0 Flash作為零樣本和端到端的語言條件導航策略。
實驗結果

- UAV-VLN在所有場景中的表現均優于基線方法,顯示出更高的成功完成任務的比例和路徑效率。
- 例如,在“公園”場景中,UAV-VLN的成功率達到93.33%,路徑效率為0.0792,而DEPS的成功率為86.67%,路徑效率為0.0733;VLMNav的成功率為73.33%,路徑效率為0.0755。
消融研究
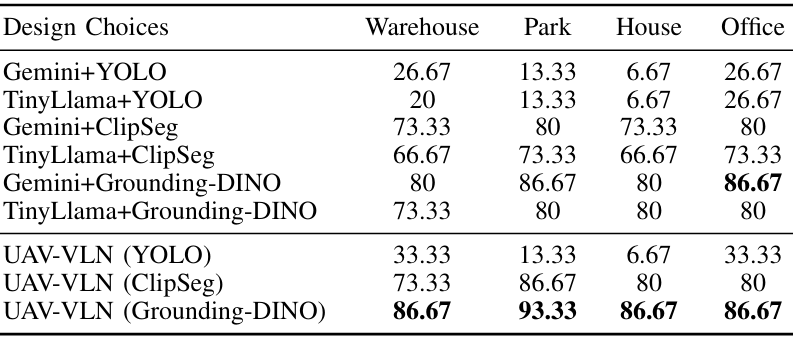
- 不同LLM和視覺模型的組合:實驗結果表明,使用開放詞匯模型(如CLIPSeg和Grounding DINO)比封閉詞匯模型(如YOLO)表現更好,能夠更好地泛化到不同場景。
- 微調的重要性:微調后的TinyLlama-1.1B模型在所有場景中均優于未微調的模型,強調了針對無人機任務定制語言模型的重要性。
結論與未來工作
- UAV-VLN通過結合微調的大型語言模型的語義推理能力和開放詞匯視覺定位,顯著提高了指令遵循準確性和路徑效率,能夠在復雜動態環境中實現穩健的導航。
- 未來工作計劃將導航歷史和輕量級語義映射納入系統,幫助無人機進行全局推理,避免冗余探索并規劃更高效的路徑,使UAV-VLN系統更接近于在具有挑戰性的開放世界環境中實現真正可擴展和終身導航的目標。


MMA(KeyCloak身份服務器/OutBox Pattern))



)

)
)










