一、邊緣計算場景的算力困境
在NVIDIA Jetson Orin NX(64TOPS INT8)平臺上部署視頻分析任務時,開發者面臨三重挑戰:
-
動態負載波動
視頻流分辨率從480p到4K實時變化,幀率波動范圍20-60FPS -
能效約束
設備功耗需控制在15W以內(被動散熱) -
多任務耦合
典型場景需同步處理:
- 目標檢測(YOLOv8s)
- 行為識別(SlowFast)
- 語義分割(DeepLabv3)
二、MoE架構的核心技術解析
2.1 混合專家系統設計原理
動態路由機制表達式:
g = GatingNetwork(x) # 門控網絡
e_k = TopK(g, k=2) # 稀疏激活
y = sum(e_i * Expert_i(x) for i in e_k)
架構特性:
- 動態權重分配:根據輸入特征自動選擇專家子網
- 條件計算:平均激活1.3個專家(k=2時)
- 異構專家:支持CNN/Transformer混合架構
2.2 Jetson Orin硬件適配策略

三、實時視頻分析系統實現
3.1 環境配置
# 刷寫JetPack 6.0鏡像
sudo apt-get install tensorrt=9.0.1.4 \python3-libnvinfer-dev=9.0.1 \cuda-toolkit-12-2# 安裝MoE訓練框架
git clone https://github.com/mosaicml/examples
pip install -e ./examples/moe
3.2 MoE模型設計
class VideoMoE(nn.Module):def __init__(self):self.backbone = ResNet34(pretrained=True) # 特征提取self.gate = nn.Sequential(nn.AdaptiveAvgPool2d(1),nn.Linear(512, 8)) # 8個專家self.experts = nn.ModuleList([YOLOv8Tiny(), # 專家1:檢測SlowFastX(scale=0.5), # 專家2:行為DeepLabMicro(), # 專家3:分割# ...其余5個專家])def forward(self, x):feats = self.backbone(x)gate_logits = self.gate(feats)weights = F.softmax(gate_logits, dim=-1)top2_idx = torch.topk(weights, k=2, dim=-1)[1]# 動態計算out = 0for idx in top2_idx:expert = self.experts[idx]out += weights[..., idx] * expert(feats)return out
3.3 動態調度算法
class DynamicScheduler:def __init__(self):self.frame_counter = 0self.energy_budget = 15 # 功耗閾值(W)def adjust_params(self, res, fps):# 基于幀率調整處理分辨率target_res = min(res, 1280*720*(30/fps))# 根據剩余電量調整專家數量if get_battery() < 20%:self.k = 1 # 激活單個專家else:self.k = 2return target_res, self.k
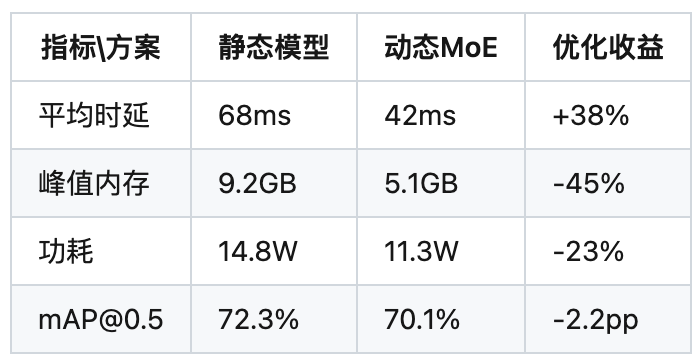
四、多場景性能評估
測試環境:
- 硬件:Jetson Orin NX 16GB
- 數據集:COCO2017驗證集(視頻化處理)
- 輸入流:3840x2160@30fps H.264
五、關鍵優化技術剖析
5.1 專家網絡量化
采用混合精度量化策略:
- 門控網絡:FP16(保持路由精度)
- 專家網絡:INT8(加速計算)
量化配置示例:
from torch.ao.quantization import QConfigMappingqconfig = QConfigMapping()
qconfig.set_module_type(ExpertBlock, get_default_qat_qconfig('qnnpack'))
5.2 內存復用策略
# 專家間共享緩存
expert_buffers = [allocate_shared_memory(256MB)]def run_expert(idx, x):with torch.no_grad():expert = experts[idx]expert.load_state(experts_buffers[idx]) # 快速加載return expert(x)
六、典型部署場景方案
場景1:智能交通監控
- 任務需求:同時檢測車輛、識別違章行為、追蹤軌跡
- MoE配置:
專家1:YOLOv8-nano(車流檢測)
專家2:ConvLSTM(軌跡預測)
專家3:Transformer(行為分類)
場景2:工業質檢
- 動態調度策略:
- 正常流水線:激活1個專家(YOLOv8檢測)
- 異常觸發時:激活3個專家(檢測+定位+缺陷分類)
七、挑戰與改進方向
7.1 現存問題
- 動態路由引入約15%額外計算開銷
- 專家間負載不均衡(部分專家利用率<10%)
- 多專家并行時的內存競爭
7.2 優化路線圖
- 硬件感知路由:根據當前GPU溫度/DLA負載調整專家選擇
- 專家蒸餾:將多個專家知識提煉到單個網絡
- 自適應k值:基于內容復雜度動態選擇激活專家數
八、延伸思考
- MoE與模型壓縮的結合:探索專家網絡的量化感知訓練
- 跨設備協同計算:將計算密集型專家卸載到邊緣服務器
- 在線學習機制:基于視頻流內容動態更新專家參數
實驗配置說明
- 測試視頻時長:5分鐘(9000幀)
- 環境溫度:25℃±2℃(無主動散熱)
- 基線模型:YOLOv8s + DeepLabv3聯合模型
)
-后端 請求頭校驗,jwt退出登錄,mybaits實現數據庫用戶校驗)
APC注入)



)
openjdk17 c++源碼垃圾回收安全點信號函數處理線程阻塞)










)
