前言
目標檢測就是做到給模型輸入一張圖片或者視頻,模型可以迅速判斷出視頻和圖片里面感興趣的目標所有的位置和它 的類別,而當前最熱門的目標檢測的模型也就是YOLO系列了。
YOLO系列的模型的提出,是為了解決當時目標檢測的模型幀率太低而提出來的模型,英文全稱是
You only look once。
深度學習目標檢測算法分類:
(1)two-stage 兩個階段的檢測,模型舉例 Faster-RCNN Mask-Rcnn系列
? ?(2) one-stage 一個階段的檢測:YOLO系列
這兩個主要區別可以簡單理解為,兩個階段有一個選擇預選框和物體分類的一個過程,而單階段的將檢測問題轉換為一個回歸問題
下邊來詳細講解YOLO系列的各個階段的模型。
一、YOLOv1
1、模型背景
YOLOV1,是以Joseph Redmon為首的大佬們于2015年提出的一種新的目標檢測算法。它與之前的目標檢測算法如R-CNN等不同之處在于,R-CNN等目標檢測算法是兩階段算法, 步驟為先在圖片上生成候選框,然后利用分類器對這些候選框進行逐一的判斷;而YOLOv1是一階段算法,是端到端的算法,它把目標檢測問題看作回歸問題,將圖片輸入單一的神經網絡,然后就輸出得到了圖片的物體邊界框(boundingbox)以及分類概率等信息。
總結:YOLOv1直接從輸入的圖像,僅僅經過一個神經網絡,直接得到一些bounding box(位置坐標)以及每個bounding box對所有類別的一個概率情況,因為整個的檢測過程僅僅有一個網絡,所以可以直接進行端到端的優化,而無需像Faster R-CNN的分階段的優化。
end-to-end(端到端):指的是一個過程,輸入原始數據,輸出最后結果。之前的網絡Fast RCNN等這種網絡分為兩個階段,一個是預選框的生成和目標分類與邊界框回歸,具體內容大家可以自行理解。
YOLO的核心思想就是把目標檢測轉變為一個回歸問題,利用整張圖作為網絡的輸入,僅僅經過一個神經網絡,得到bounding box(邊界框) 的位置及其所屬的類別。
2、網絡結構
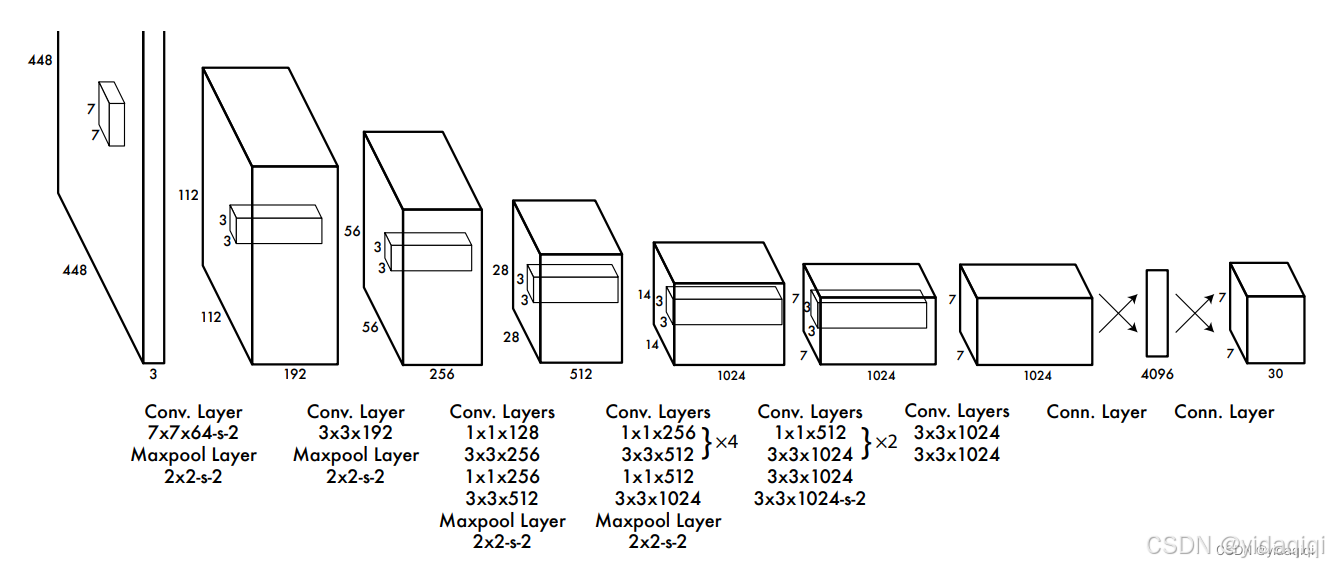
YOLOv1的網絡結構簡單清晰,是一個最傳統的one-stage的卷積神經網絡。
網絡輸入:448*448*3的三通道圖片
中間層:由若干卷積層和最大池化層組成,用于提取圖片的抽象特征。
全連接層:由兩個全連接層組成,用來預測目標的位置和類別概率值。
網絡輸出:7*7*30的預測結果。
3、網絡細節
YOLOv1采用的是”分而治之“的策略,將一張圖片平均分成7*7個網格,每個網格分別負責預測中心點落在該網格內的坐標,回憶一下,在Faster R-CNN中,是通過一個RPN來獲得目標的感興趣區域,這種方法精度很高,但是需要額外訓練一個RPN網絡,這無疑增加了訓練的負擔。在YOLOv1中,通過劃分得到7*7個網絡,(原圖劃分),這49個網格就相當于是目標的感興趣區域。通過這種方式,我們就不需要再額外設計一個RPN網絡,這正是YOLOv1作為單階段網絡的簡單快捷之處。
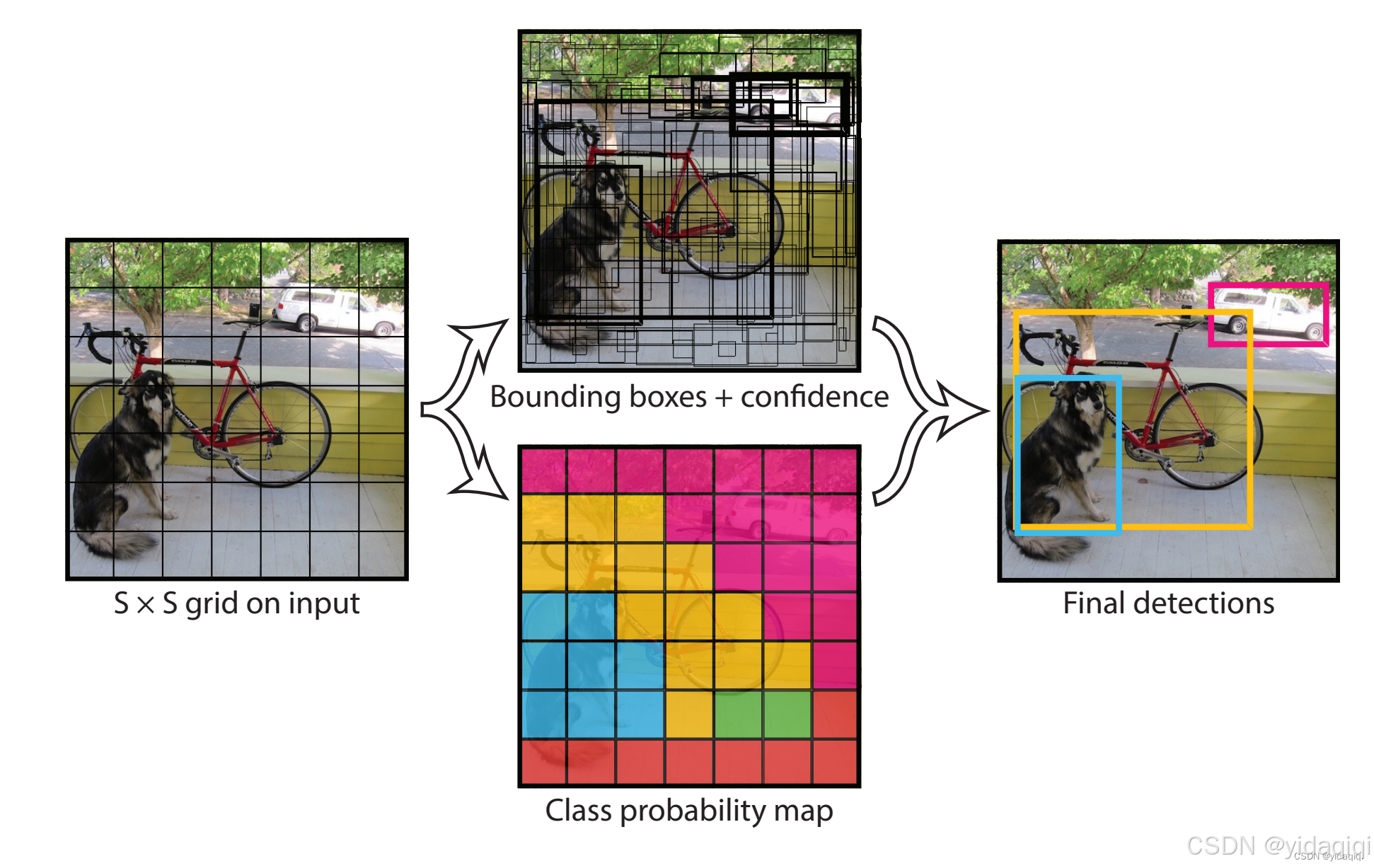
補充說明過程:
1、將一副圖像分成S*S個網格(grid cell),如果某個目標的中心落在這個網格中,那么這個網絡就負責預測這個object。(原本中是7個)
2、每個網格要預測B個bounding box,每個bounding box要預測(x,y,w,h)和confidence共五個值。文中B為2。
其中:x和y是這些邊界框的中心坐標相對于網格單元格的坐標。也就是說,x和y是邊界框中心點相對于網格單元左上角的偏移量。坐標是以網格單元格的寬度和高度為單位的相對值。因此這兩個值表示的是邊界框中心的精確位置。
w和h,這些是邊界框的寬度和高度的相對值,通常是相對于整張圖片的寬度和高度,它們表示邊界框的大小,也就是邊界框的高度和寬度的預測值,這些值通常是對整張圖片的歸一化的比例值。
confidence(置信度):描述的是邊界框的置信度(邊界框包含物體的概率)。換句話說,它衡量了邊界框中確實有物體的可信度。
3、每個網格還需要預測一個類別信息,記為C個類。文中為20,
4、總的來說,S*S個網格,每個網格預測2個bbx,還要預測20個類,那么網絡最后輸出的就是一個7*7*30.
在模型最后是生成了98個邊界框,生成完邊界框后,通過NMS(非極大值預測)來篩選出最優的邊界框。
4、預測階段
在模型訓練完成后,向搭載玩參數的模型輸入圖片,然后得到最后結果的一個過程。
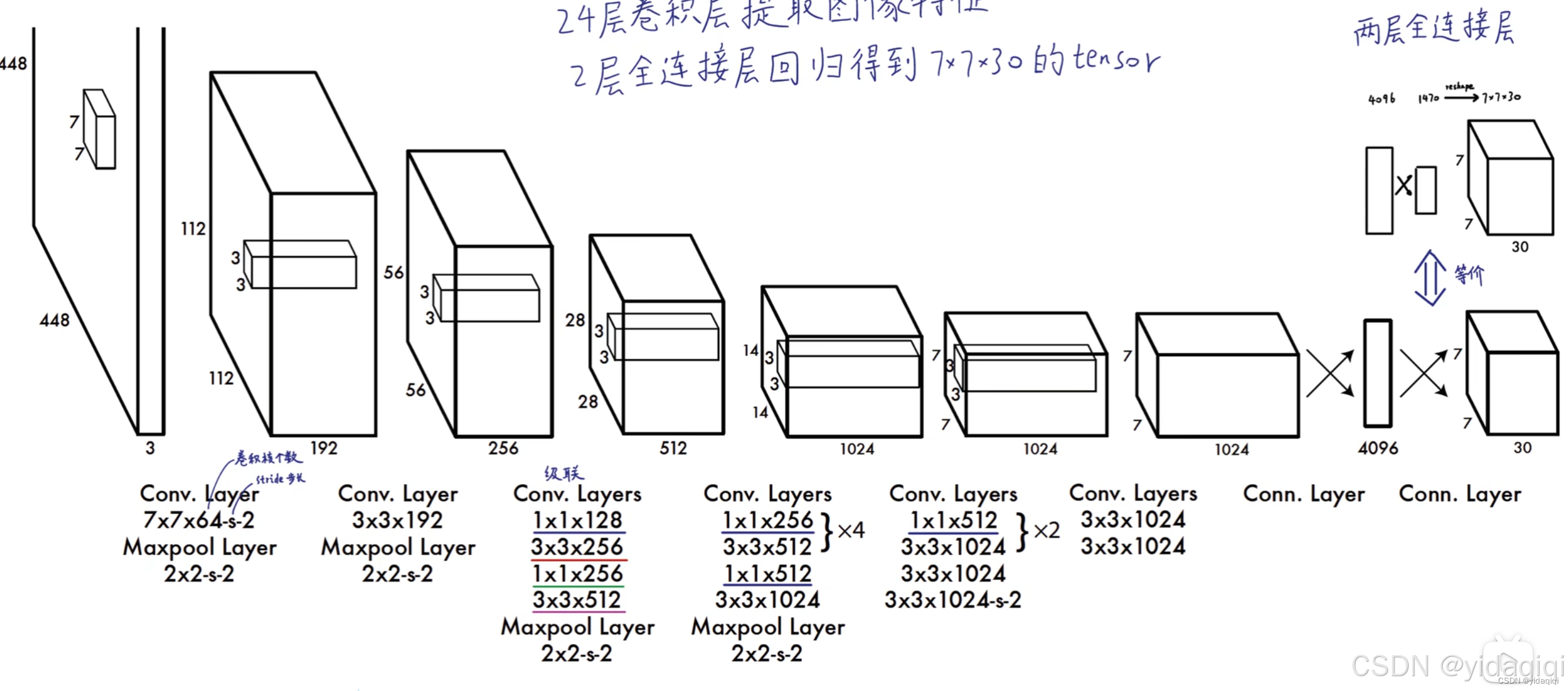
將網絡當成一個黑箱子,輸入的是一個448*448*3的RGB圖像,最后輸出的一個7*7*30的向量。
整體的網絡結構很簡單,都是卷積、池化、全連接層,一目了然。
而最后輸出的向量,包含了類別、框、置信度等結果,而我們只需要解釋這個向量就得到最后的結果了。
下面對最后輸出的向量,進行一個分析,當我們輸入一張圖片的時候,最后會生成7*7*30的向量,如何去理解呢,可以將這個向量看做成7*7個1*30的向量,也就是49個1*30的向量,這里的每個1*30的向量,對應于前面的一個grid cell,將向量拆分為兩個預測框的坐標以及預測框包含物體的置信度,和20個類別的條件概率。其中每個gridcell只會預測一個物體,也因此暴露出YOLOv1在小目標上檢測的缺陷。然后預測中又引入了NMS向量對上述的98個框進行篩選,最后才可以得出我們的結果。
5、訓練階段
這個階段,我首先主要是解釋一下幾個問題,
,首先是YOLOv1是端到端的一個網絡,也就是輸入的是原圖,輸出的是一個向量,而訓練的過程包括兩個過程,一個是前向傳播,另一個就是反向傳播,通過不斷迭代,使梯度下降,進而使損失函數最小化,這個過程。訓練的流程大致為,輸入batchsize張圖片,得出batchsize*7*7*30的一個張量,將該張量與標簽(batchsize*7*7*30的向量)計算出損失為多少,然后根據這個損失對網絡的參數進行梯度計算,不斷迭代,不斷優化參數,這樣的一個過程。我覺得這樣理解好理解的多。
這個代碼大致流程可以分為以下部分
1、超參數初始化
2、數據初始化,構造數據迭代器,因為原本一張圖片對應的標簽并不是7*7*30的一個向量,因此要對數據進行預處理,把每一個圖片的標簽變成7*7*30的一個格式。
3、網絡初始化,我這里給的代碼使ResNet50的網絡,這個網絡也叫做backbone大家以后會經常看到的,網絡結構差不多,然后輸入是bs*448*448*3,輸出就是bs*7*7*30的這樣一個結構
4、上述都可以看成初始化過程,然后就開始訓練,也就是前向傳播,反向傳播,參數優化這樣迭代的一個過程,最后保存參數。
6、損失函數
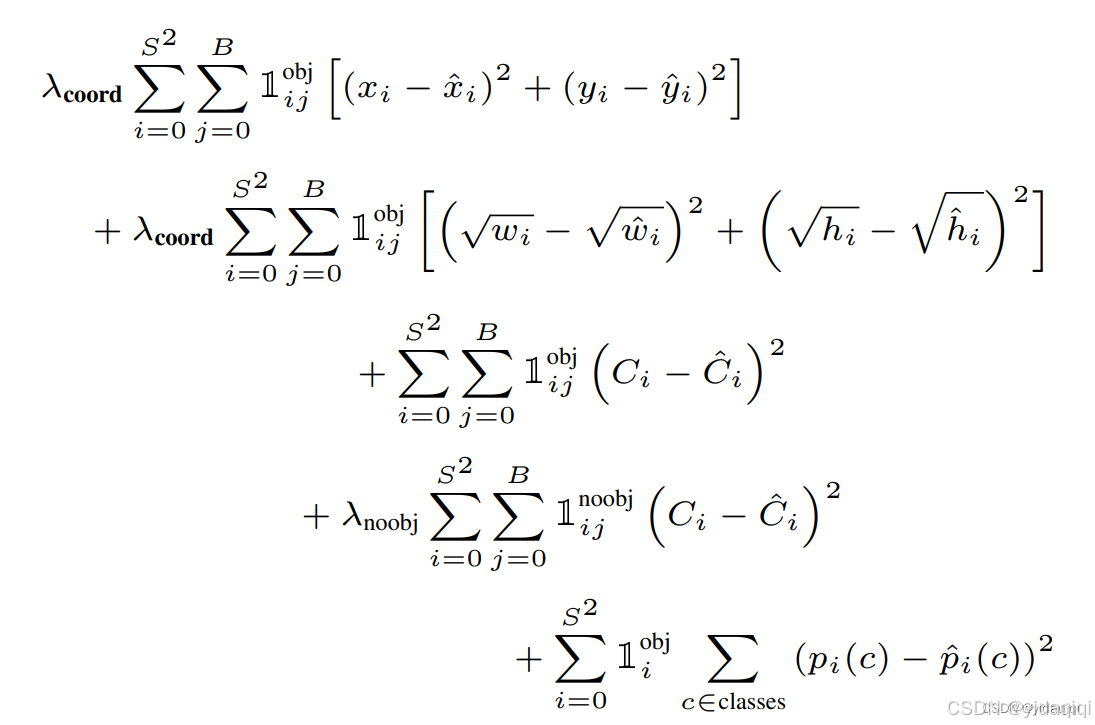
可以大致看成四個部分,
第一部分表示負責檢測物體的bounding box中心點定位誤差,要和ground truth盡可能擬合,x xx帶上標的是標注值,不帶上標的是預測值。
第二表示表示負責檢測物體的bounding box的寬高定位誤差,加根號是為了使得對小框的誤差更敏感。
第三部分:

第四部分是負責檢測物體的grid的分類誤差。
7、總結
模型優點:YOLO檢測速度非常快,標準版本的YOLO可以每秒處理45張圖像,YOLO的極速版本可以每秒處理150幀圖像,這就意味著該模型可以實時處理視頻,在當時,準確率比它高的,速度沒他快,速度比他快的,精度沒他高。
遷移能力強,能運用到其他新的領域。
局限:
1、YOLO對相互靠近的物體,以及很小的群體檢測效果不好,因為只預測了98個框。假如一張圖片有200個目標的話,根本檢測不完。
2、由于損失函數的問題,定位誤差是影響檢測效果的主要原因,尤其是大小物體的處理上。有待提高。
3、對一些不常見的角度的目標泛化性能差。
二、YOLOv2
1、模型背景
2017年,作者 Joseph Redmon 和 Ali Farhadi 在 YOLOv1 的基礎上,進行了大量改進,提出了 YOLOv2 和 YOLO9000。重點解決YOLOv1召回率和定位精度方面的不足。
YOLOv2 是一個先進的目標檢測算法,比其它的檢測器檢測速度更快。除此之外,該網絡可以適應多種尺寸的圖片輸入,并且能在檢測精度和速度之間進行很好的權衡。
相比于YOLOv1是利用全連接層直接預測Bounding Box的坐標,YOLOv2借鑒了Faster R-CNN的思想,引入Anchor機制。利用K-means聚類的方法在訓練集中聚類計算出更好的Anchor模板,大大提高了算法的召回率。同時結合圖像細粒度特征(特征融合),將淺層特征與深層特征相連,有助于對小尺寸目標的檢測。
YOLO9000 使用 WorldTree 來混合來自不同資源的訓練數據,并使用聯合優化技術同時在ImageNet和COCO數據集上進行訓練,能夠實時地檢測超過9000種物體。由于 YOLO9000 的主要檢測網絡還是YOLOv2,所以這部分以講解應用更為廣泛的YOLOv2為主。
2、網絡結構
YOLOv2 采用 Darknet-19 作為特征提取網絡,DarkNet-19,后邊的19指的是用了19個卷積層的意思。其整體結構如下:
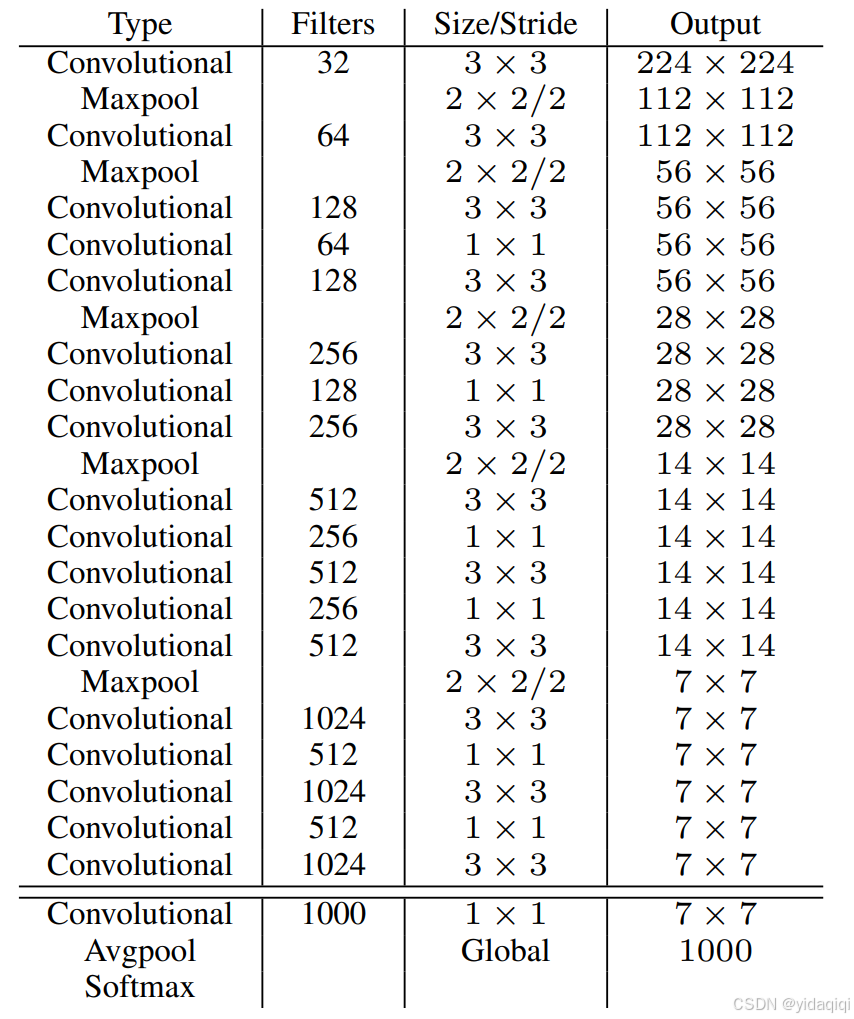
說明:
1、DarkNet-19與VGG網絡相似,使用了很多3*3的卷積核;并且每一次池化后,下一層的卷積核的通道數 = 池化輸出的通道*2
2、每一次卷積后,都增加了BN(批量標準化)進行預處理。
3、采用了降維的思想,把1*1的卷積置于3*3之間,用來壓縮特征。
4、在網絡最后的輸出增加了一個global average pooling層,這個層就是把一個二維的特征圖縮減成一個數的一個操作。
5、網絡整體上采用了19個卷積層、5個池化層。
上述流程中有很多細節之處,我簡單總結一下。
1、在YOLOv1當中有全連接層,所以在YOLOv1當中是引入了Dropout正則化,用來防止過擬合,而在YOLOv2中去掉了全連接層,引入了BN層,在每一個卷積層后都加入了BN,也就是網絡的每一層都做了歸一化,收斂起來相對簡單,引入BN層后提升了2%的MAP,目前BN層可以說是網絡模型必備的處理方法。
2、引入了1*1和全局最大值池化對網絡的參數量有很大減少,減少了計算量,提升了檢測速度。
3、網絡細節
1、引入了anchor機制
這個機制在Faster R-CNN中引入的,在YOLOV1是直接做的回歸計算出bbx(bounding box)坐標值,并且是從全連接層變化來的,這會丟失較多的的空間信息,導致定位精度不高,并且在前期訓練時很困難,很難收斂。
而YOLOv2中借鑒了Faster R-CNN中的anchor思想,使得網絡在訓練時更容易收斂。這里引入的機制,相對于FasterR-cnn中的anchor機制做了一些改進,在rcnn中是初始化設定好的anchor,而在YOLO中是通過K-means聚類的方法來選擇出的合適訓練數據集的anchor,K-means聚類在后續進行介紹。通過提前篩選得到的具有代表性先驗框Anchors,使得網絡在訓練時更容易收斂。
在Faster R-CNN算法中,是通過預測boundingbox與ground truth的位置偏移值tx和ty,間接得到的boundingbox的位置,其公式如下:
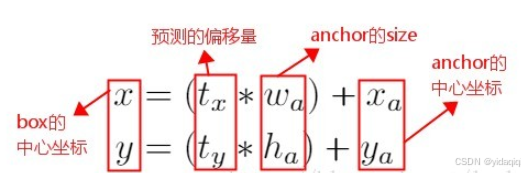
這個公式是無拘束的,預測邊界框很容易向任何方向偏移。因此,每個位置預測的邊界框可以落在圖片的任何位置,這會導致模型很不穩定。
因此YOLOv2在上述方法做了提高,預測邊界框中心點相對于該網格左上角坐標(Cx,Cy)的相對偏移量,同時為了將bounding box的中心點坐標約束在當前網格中,使用sigmoid函數將tx和ty歸一化處理,讓這個值約束在0-1,
下圖為anchor box 與 bounding box轉換的示意圖,其中藍色是要預測的bounding box,黑色虛線框是Anchor box。
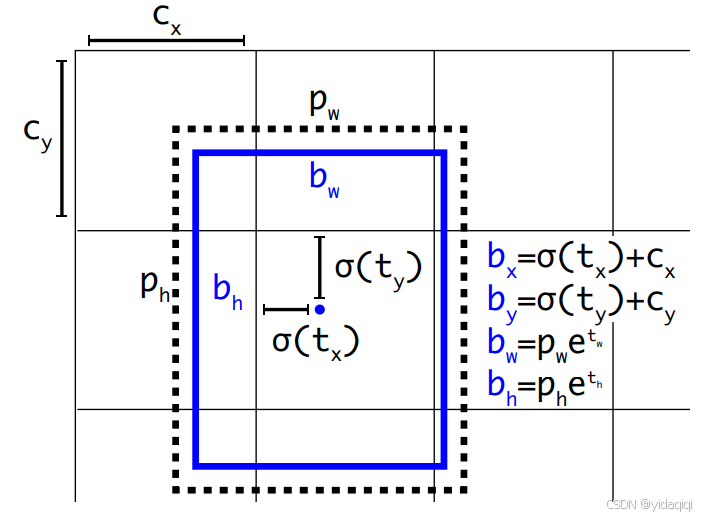
YOLOv2在最后一個卷積層輸出了13*13的feature map,意味著一張圖片被分成了13*13個網格,每個網格有5個anchor box來預測5個bounding box,每個bounding box預測得到五個值:tx、ty、tw、th和to,通過這五個值簡介預測得到的bounding box的位置的計算公式為:
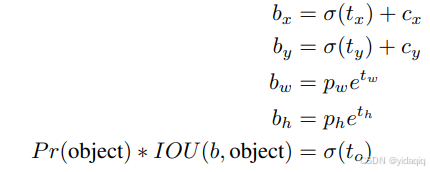
YOLOv1有一個缺陷是,一張圖片被分成了7*7的網絡,一個網格只能預測一個類,當一個網格中出現了多個類時,就無法檢測出所有的類,針對這個問題,YOLOv2做出了相對應的改進:
1、首先將YOLOv1網絡的FC層和最后一個Pooling層去掉,使得最后的卷積層的輸出可以有更高的分辨率特征。
2、然后縮減網絡,用416×416大小的輸入代替原來的448×448,使得網絡輸出的特征圖有奇數大小的寬和高,進而使得每個特征圖在劃分單元格的時候只有一個中心單元格(Center Cell)。YOLOv2通過5個Pooling層進行下采樣,得到的輸出是13×13的像素特征。
3、借鑒Faster R-CNN,YOLOv2通過引入Anchor Boxes,預測Anchor Box的偏移值與置信度,而不是直接預測坐標值。
4、采用Faster R-CNN中的方式,每個Cell可預測出9個Anchor Box,共13×13×9=1521個(YOLOv2確定Anchor Boxes的方法見是維度聚類,每個Cell選擇5個Anchor Box)。比YOLOv1預測的98個bounding box 要多很多,因此在定位精度方面有較好的改善。
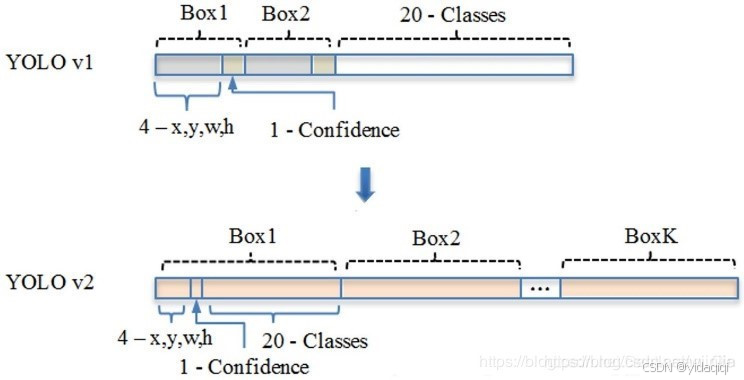
2、K-means聚類方法選擇Anchors
Faster R-CNN 中 Anchor Box 的大小和比例是按經驗設定的,不具有很好的代表性。若一開始就選擇了更好的、更有代表性的先驗框Anchor Boxes,那么網絡就更容易學到準確的預測位置了!
YOLOv2 使用 K-means 聚類方法得到 Anchor Box 的大小,選擇具有代表性的尺寸的Anchor Box進行一開始的初始化。傳統的K-means聚類方法使用標準的歐氏距離作為距離度量,這意味著大的box會比小的box產生更多的錯誤。因此這里使用其他的距離度量公式。聚類的目的是使 Anchor boxes 和臨近的 ground truth boxes有更大的IOU值,因此自定義的距離度量公式為 :
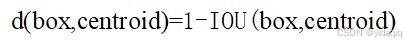
到聚類中心的距離越小越好,但IOU值是越大越好,所以使用 1 - IOU;這樣就保證距離越小,IOU值越大。具體實現方法如下:

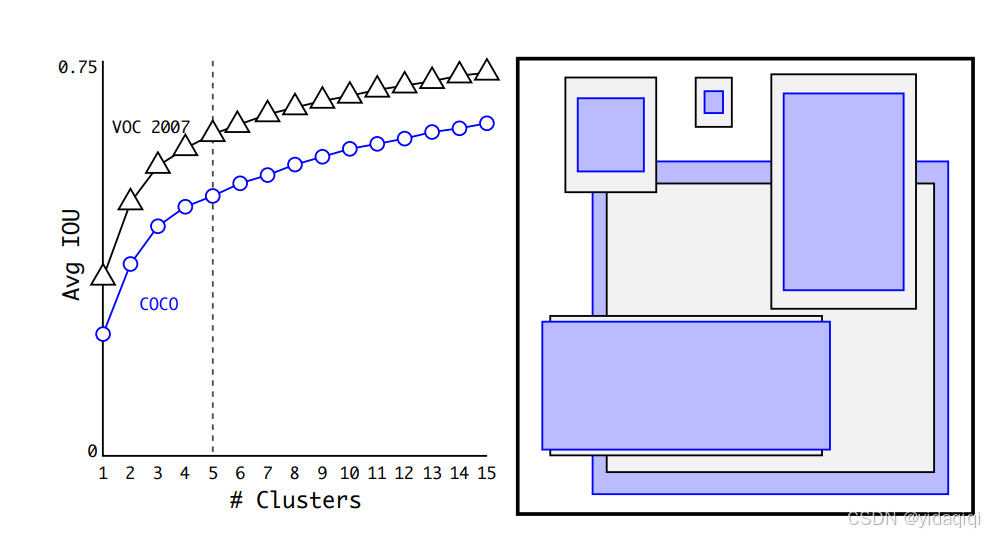
?如下圖所示,是論文中的聚類效果,其中紫色和灰色也是分別表示兩個不同的數據集,可以看出其基本形狀是類似的。
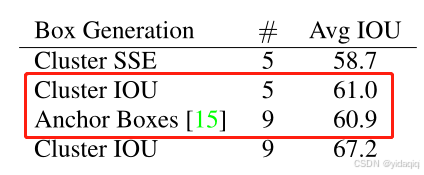
從下表可以看出,YOLOv2采用5種 Anchor 比 Faster R-CNN 采用9種 Anchor 得到的平均 IOU 還略高,并且當 YOLOv2 采用9種時,平均 IOU 有顯著提高。說明 K-means 方法的生成的Anchor boxes 更具有代表性。為了權衡精確度和速度的開銷,最終選擇K=5。
3、特征融合 Fine-Grained Features
細粒度特征,就是不同層之間的特征融合,和殘差里面的概念很像,就是把淺層特征和深層特征融合在一起。YOLOv2通過添加了一個Passthrough Layer,把淺層特征和深層特征在不同的通道上進行融合,具體操作是:先獲取淺層的26*26的特征圖,再將最后輸出的13*13的特征圖進行拼接,再輸入檢測器進行檢測,以此來提高對小目標的檢測能力。
Passthrough層與ResNet網絡的shortcut類似,以前面更高分辨率的特征圖為輸入,然后將其連接到后面的低分辨率特征圖上。前面的特征圖維度是后面的特征圖的2倍,passthrough層抽取前面層的每個2×2的局部區域,然后將其轉化為channel維度,對于26×26×512的特征圖,經Passthrough層處理之后就變成了13×13×2048的新特征圖(特征圖大小降低4倍,而channles增加4倍),這樣就可以與后面的13×13×1024特征圖連接在一起形成13×13×3072的特征圖,然后在此特征圖基礎上卷積做預測。示意圖如下:
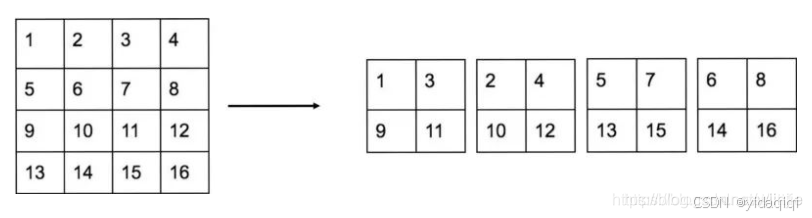
4、總結
在VOC2007數據集上進行測試,YOLOv2在速度為67fps時,精度可以達到76.8的mAP;在速度為40fps時,精度可以達到78.6的mAP,可以在速度和精度之間進行平衡。
三、YOLOv3
1、模型背景
2018年,作者Redmon又在YOLOv2的基礎上做了一些改進,特征提取部分(backbone)網絡結構darknet53代替了原來的darknet19,利用特征金字塔網絡實現了多尺度預測,分類方法使用邏輯回歸代替了softmax,在兼顧實時性的同時保證了目標檢測的準確性。
從YOLOv1到YOLOv3,每一代性能的提升都與backbone(骨干網絡)的改進密切相關。在YOLOv3中,作者不僅提供了darknet-53,還提供了輕量級的tiny-darknet。如果你想要檢測精度與速度兼具,可以選擇darknet-53作為backbone;如果希望達到更快的檢測速度,精度方面可以妥協,那么tiny-darknet是最好的選擇。總之,YOLOv3的靈活性使得在實際工程中得到很多人的青睞。
2、網絡結構
相比于YOLOv2的骨干網絡,YOLOv3進行了較大的改進。借助殘差網絡的思想,YOLOv3將原來的darknet-19改進成了darknet-53,論文中給出的整體結構如下。
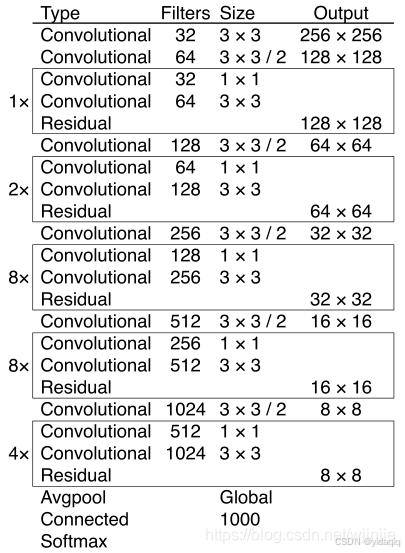
DarkNet-53主要是由1*1和3*3的卷積核組成。每個卷積層之后包含一個批量歸一化層和一個Leaky Relu,加入這兩個部分的目的是防止過擬合。卷積層、批量歸一化層以及Leaky Relu共同組成DarkNet-53中的基本卷積單元DBL。因為在DarkNet-53中包含53個這樣的DBL,所以稱為Darknet-53.
為了更加清晰了解DarkNet-53的網絡結構,可以看下面這張圖:
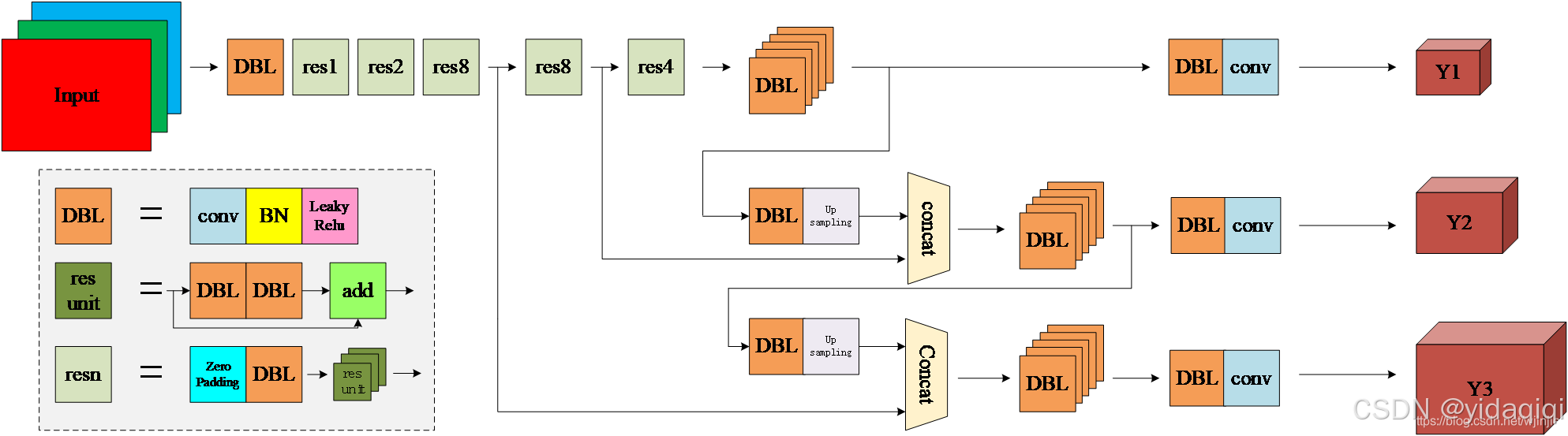
網絡結構其實看的話,不是算很復雜。下面對主要的幾個單元進行解釋。
1、DBL:一個卷積層、一個BN層和一個Leaky ReLU組成的基本卷積單元。
這個是組成網絡的基本組成單元,其中的話,中間層經過一個DBL后,特征圖的大小不會發生變化
2、res unit:輸入通過兩個DBL后,再與原輸入進行add;這是一種常規的殘差單元。殘差單元的目的是為了讓網絡可以提取到更深層次的特征,同時避免出現梯度消失或者爆炸。
通過一個殘差塊后,特征圖的尺寸并沒有發生變化,不管是特征圖的長寬,還是特征圖的通道數,都沒有發生變化。
3、resn:其中的n表示的是n個res unit;所以resn = Zero Padding +DBL+n*res unit
4、concat:將darknet-53的中間層和后面的某一層的上采樣進行張量拼接,達到多尺度特征融合的目的。這與殘差層的add操作是不一樣的,拼接會擴充張量的維度,而add直接相加不會導致張量維度的改變。
Y1、Y2、Y3:分別表示YOLOv3三種尺度的輸出。
與darkNet-19對比可知,darkNet-53主要做了如下改進。
1、沒有采用最大池化層,而是采用步長為2的卷積層進行下采樣。
2、為了防止過擬合,每個卷積層后加入了一個BN層和一個Leaky ReLU。
3、引入了殘差網絡的思想,目的是為了讓網絡可以提取到更深層的特征,同時為了防止出現梯度的消失和爆炸。
4、將網絡的中間層和后面某一層的上采樣進行張量拼接,達到多尺度特征融合的目的。
3、改進之處
YOLOv3最大的改進之處還在于網絡結構的改進,由于上面已經講過了。因此下面主要對其他改進方面進行介紹。
1、多尺度預測
為了能給預測多尺度的目標,YOLOv3選了三種不同shape的Anchors,同時每種Anchors具有三種不同的尺度,一共9種不同大小的Anchors。在COCO數據集上選擇的9種Anchors的尺寸如下圖紅色框所示:

借鑒特征金字塔網的思想,YOLOv3設計了三種不同尺度的網絡輸出Y1、Y2、Y3、目的是為了預測不同尺度的坐標,由于每一個尺度網格都負責預測3個邊界框,且COCO數據集有80個類。所以網絡輸出的張量應該是:N*N*(3*(5+1+80)).由下采樣次數不同,得到的N不同,最終,Y1、Y2、Y3的shape分別為:[13, 13, 255]、[26, 26, 255]、[52, 52, 255]。可見參見原文:

先寫到這里,后續有時間再寫。
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?


















利用C11模擬偽閉包實現連接的安全回收)
:Agent系統的應用架構與落地實)