達人探店
發布探店筆記
探店筆記類似點評網站的評價,往往是圖文結合,對應的表有兩個:

發布博文對應兩個接口
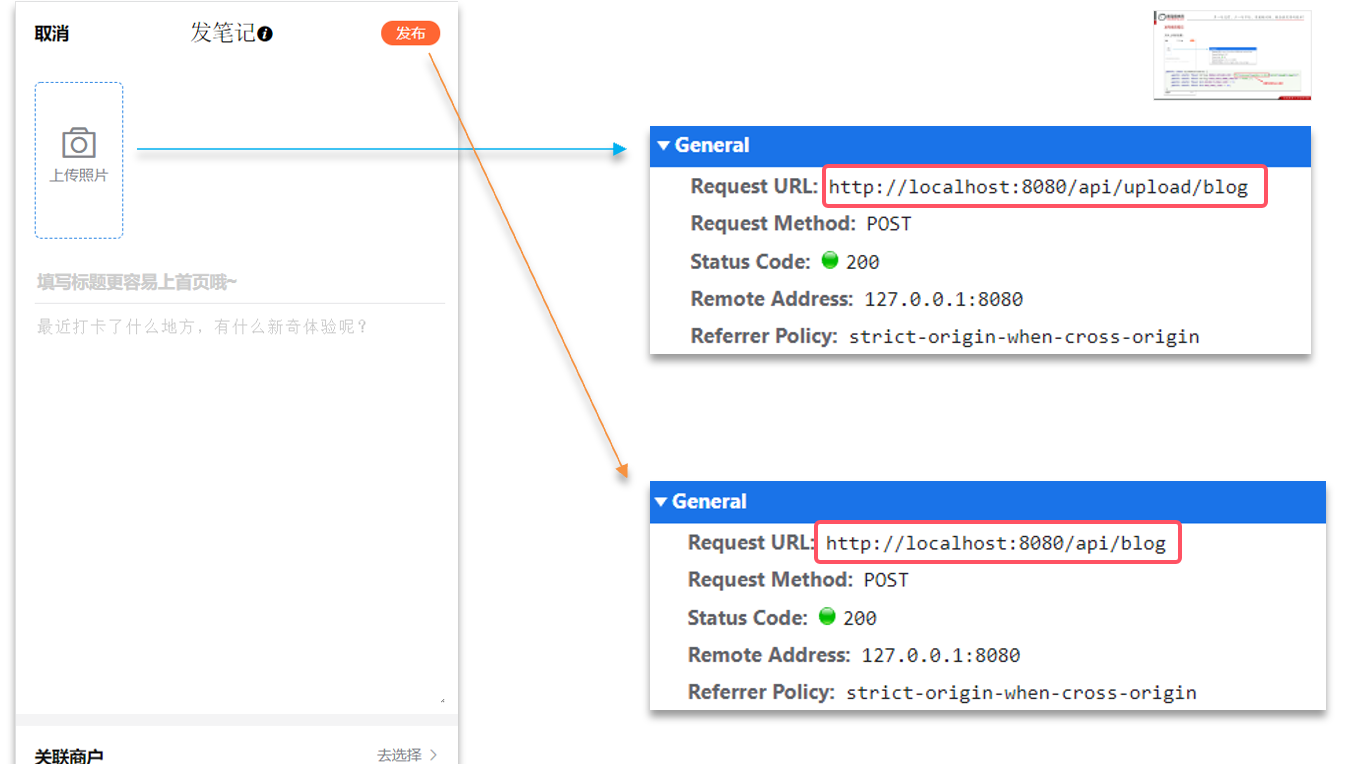
案例:實現查看發布探店筆記的接口
需求:點擊首頁的探店筆記,會進入詳情頁面,實現該頁面的查詢接口
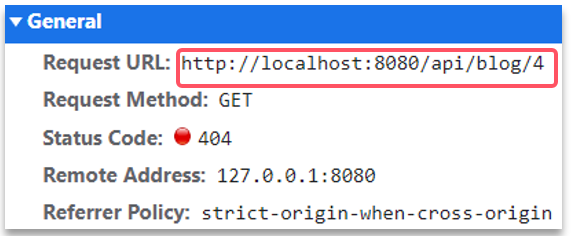
@Override
public Result queryBlogById(Long id) {// 1.查詢blogBlog blog = getById(id);if (blog == null) {return Result.fail("筆記不存在!");}// 2.查詢blog有關的用戶queryBlogUser(blog);return Result.ok(blog);
}private void queryBlogUser(Blog blog) {Long userId = blog.getUserId();User user = userService.getById(userId);blog.setName(user.getNickName());blog.setIcon(user.getIcon());}點贊
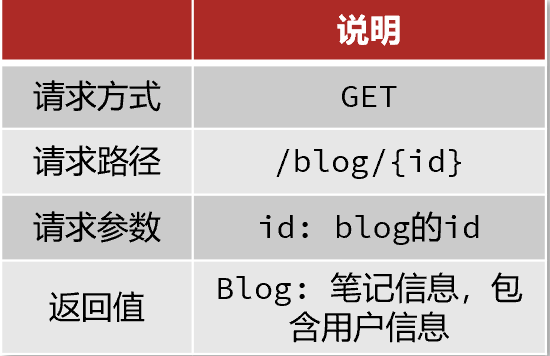
初始代碼:
@GetMapping("/likes/{id}")
public Result queryBlogLikes(@PathVariable("id") Long id) {//修改點贊數量blogService.update().setSql("liked = liked +1 ").eq("id",id).update();return Result.ok();
}問題分析:這導致一個用戶能無限點贊,明顯不合理
當前邏輯,發起請求只是給數據庫+1,所以才會出現這個問題
案例:完善點贊功能
需求:同一個用戶只能點贊一次,再次點擊則取消點贊
如果當前用戶已經點贊,則點贊按鈕高亮顯示(前端已實現,判斷字段Blog類的isLike屬性)
實現步驟:
- 給Blog類中添加一個isLike字段,判斷是否被當前用戶點贊
- 修改點贊功能,利用Redis的set集合判斷是否點贊過,未點贊過則點贊數+1,已點贊過則點贊-1
- 修改根據id查詢Blog業務,判斷當前登錄用戶是否點贊過,賦值給isLike字段
- 修改分頁查詢Blog的業務,判斷當前登錄用戶是否點贊過,賦值給isLike字段
為什么采用set集合?
因為我們的數據是不能重復的,當用戶操作后,無論他怎么操作,都是只能存在一個
具體步驟:
1.在Blog添加一個字段
@TableField(exist = false)
private Boolean isLike;2.修改代碼
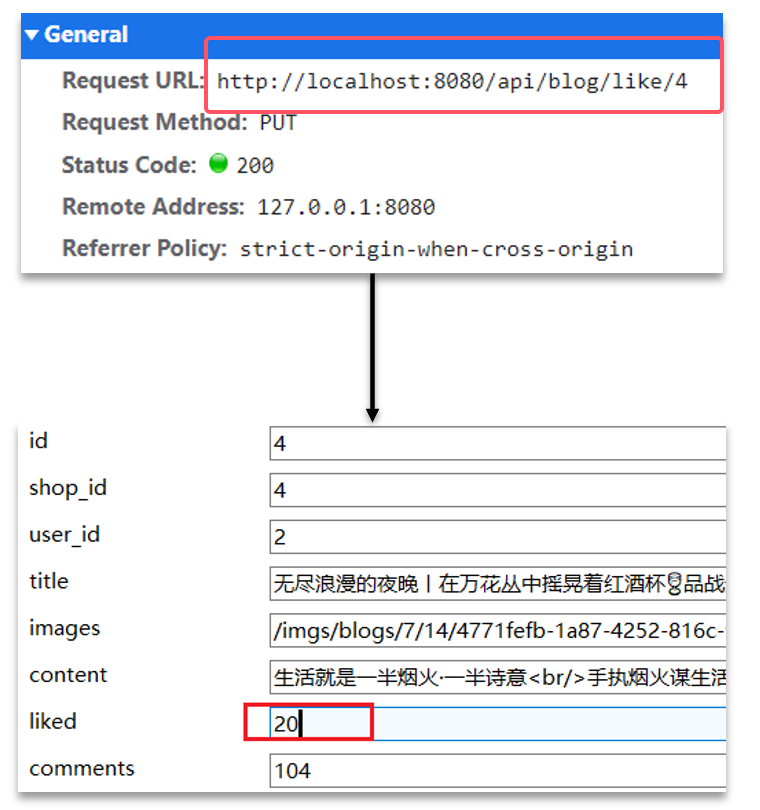
@Overridepublic Result likeBlog(Long id){// 1.獲取登錄用戶Long userId = UserHolder.getUser().getId();// 2.判斷當前登錄用戶是否已經點贊String key = BLOG_LIKED_KEY + id;Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString());if(BooleanUtil.isFalse(isMember)){//3.如果未點贊,可以點贊//3.1 數據庫點贊數+1boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();//3.2 保存用戶到Redis的set集合if(isSuccess){stringRedisTemplate.opsForSet().add(key,userId.toString());}}else{//4.如果已點贊,取消點贊//4.1 數據庫點贊數-1boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();//4.2 把用戶從Redis的set集合移除if(isSuccess){stringRedisTemplate.opsForSet().remove(key,userId.toString());}}
}點贊排行榜
在探店筆記的詳情頁面,應該把給筆記點贊的人顯示出來,比如最早點贊的TOP5,形成點贊排行榜;接口如下:
之前的點贊是放到set集合,但是set集合是不能排序的,所以這個時候,咱么可以采用一個可以排序的set集合,就是咱們的sortedSet
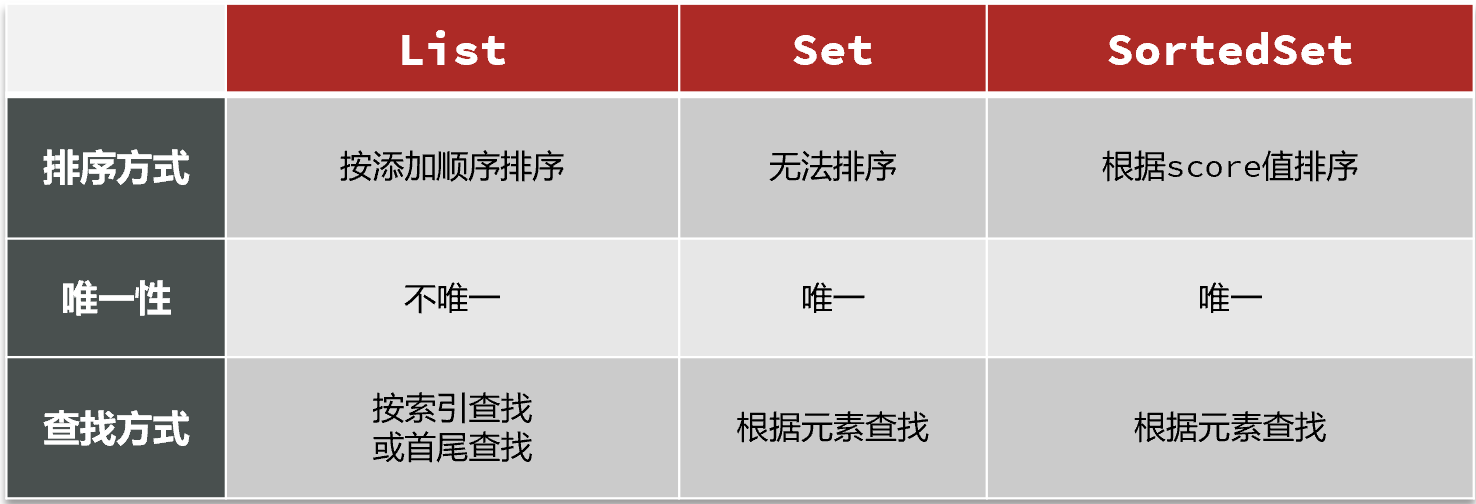
所有點贊的人,需要是唯一的,其次需要排序,可以直接鎖定使用sortedSet
案例:實現查詢點贊排行榜的接口
修改邏輯代碼
1.點贊邏輯代碼
從sortedSet集合中取出score,進行非空判斷,如果為空,說明未點贊,不為空,說明點過贊,將其從sortedSet中移出。
@Overridepublic Result likeBlog(Long id) {// 1.獲取登錄用戶Long userId = UserHolder.getUser().getId();// 2.判斷當前登錄用戶是否已經點贊String key = BLOG_LIKED_KEY + id;Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());if (score == null) {// 3.如果未點贊,可以點贊// 3.1.數據庫點贊數 + 1boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();// 3.2.保存用戶到Redis的set集合 zadd key value scoreif (isSuccess) {stringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis());}} else {// 4.如果已點贊,取消點贊// 4.1.數據庫點贊數 -1boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();// 4.2.把用戶從Redis的set集合移除if (isSuccess) {stringRedisTemplate.opsForZSet().remove(key, userId.toString());}}return Result.ok();}private void isBlogLiked(Blog blog) {// 1.獲取登錄用戶UserDTO user = UserHolder.getUser();if (user == null) {// 用戶未登錄,無需查詢是否點贊return;}Long userId = user.getId();// 2.判斷當前登錄用戶是否已經點贊String key = "blog:liked:" + blog.getId();Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());blog.setIsLike(score != null);}2.點贊列表查詢列表
@GetMapping("/likes/{id}")
public Result queryBlogLikes(@PathVariable("id") Long id) {return blogService.queryBlogLikes(id);
}@Override
public Result queryBlogLikes(Long id) {String key = BLOG_LIKED_KEY + id;// 1.查詢top5的點贊用戶 zrange key 0 4Set<String> top5 = stringRedisTemplate.opsForZSet().range(key, 0, 4);if (top5 == null || top5.isEmpty()) {return Result.ok(Collections.emptyList());}// 2.解析出其中的用戶idList<Long> ids = top5.stream().map(Long::valueOf).collect(Collectors.toList());String idStr = StrUtil.join(",", ids);// 3.根據用戶id查詢用戶 WHERE id IN ( 5 , 1 ) ORDER BY FIELD(id, 5, 1)List<UserDTO> userDTOS = userService.query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list().stream().map(user -> BeanUtil.copyProperties(user, UserDTO.class)).collect(Collectors.toList());// 4.返回return Result.ok(userDTOS);
}好友關注
關注和取關
在探店圖文的詳情頁中,可以關注發布筆記的作者.
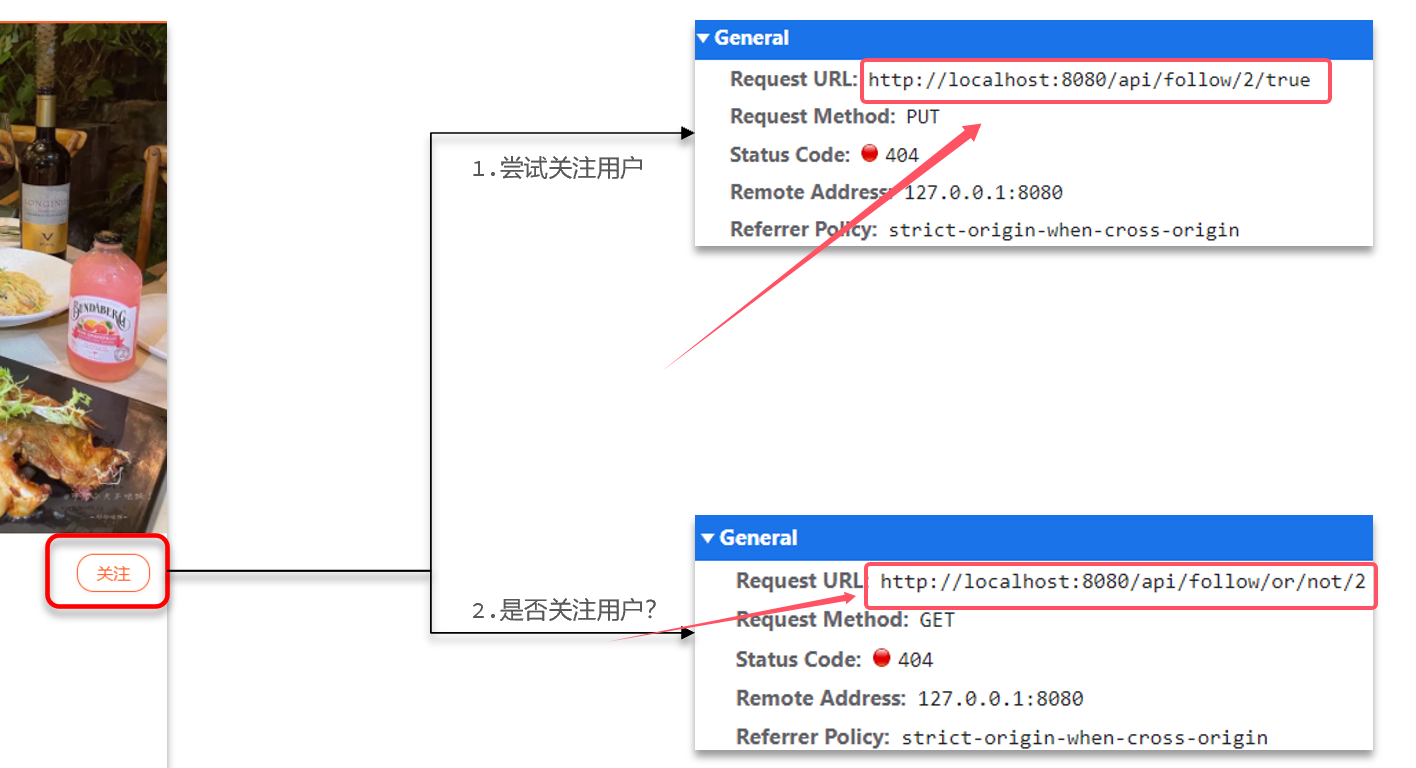
案例: 實現關注和取關功能
需求:基于該表數據結構,實現兩個接口
關注和取關接口,判斷是否關注的接口
關注是User之間的關系,是博主與粉絲的關系,數據庫中有一張tb_follow表來表示:
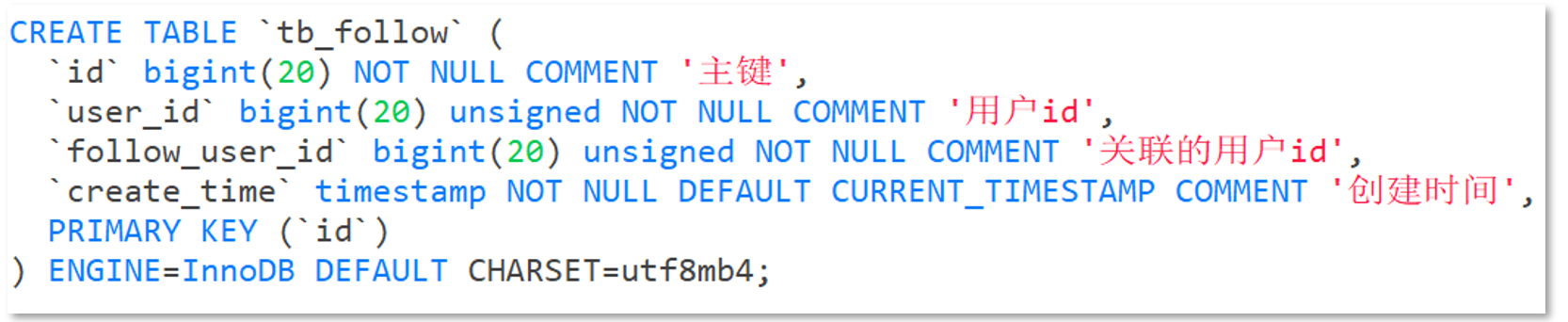
注意:這里需要把主鍵修改為自增長,簡化開發。
取消關注
@Override
public Result isFollow(Long followUserId) {// 1.獲取登錄用戶Long userId = UserHolder.getUser().getId();// 2.查詢是否關注 select count(*) from tb_follow where user_id = ? and follow_user_id = ?Integer count = query().eq("user_id", userId).eq("follow_user_id", followUserId).count();// 3.判斷return Result.ok(count > 0);}關注service
@Overridepublic Result follow(Long followUserId, Boolean isFollow) {// 1.獲取登錄用戶Long userId = UserHolder.getUser().getId();String key = "follows:" + userId;// 1.判斷到底是關注還是取關if (isFollow) {// 2.關注,新增數據Follow follow = new Follow();follow.setUserId(userId);follow.setFollowUserId(followUserId);boolean isSuccess = save(follow);} else {// 3.取關,刪除 delete from tb_follow where user_id = ? and follow_user_id = ?remove(new QueryWrapper<Follow>().eq("user_id", userId).eq("follow_user_id", followUserId));}return Result.ok();}共同關注
點擊博主頭像,可以進入到博主首頁:
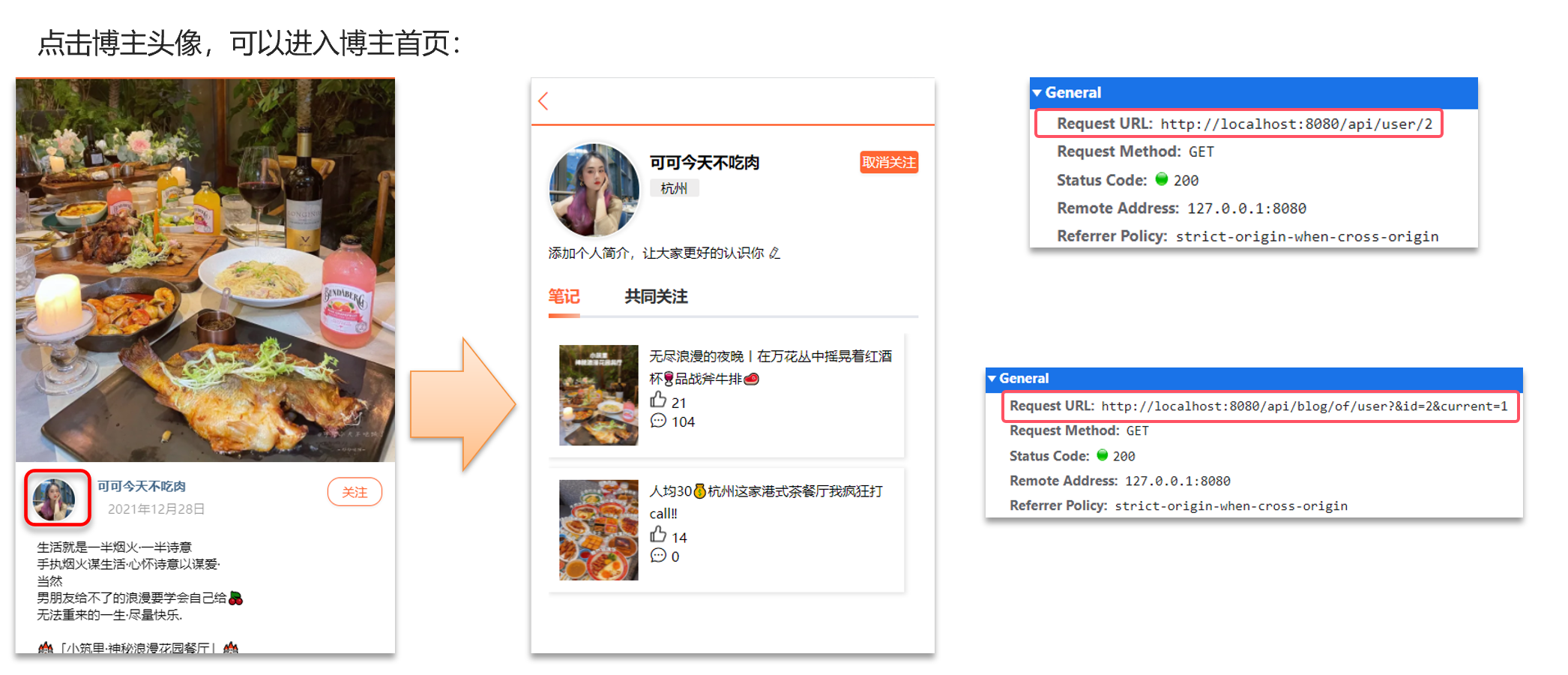
博主個人首頁依賴兩個接口
1.根據id查詢user信息

2.根據id查詢博主的探店筆記
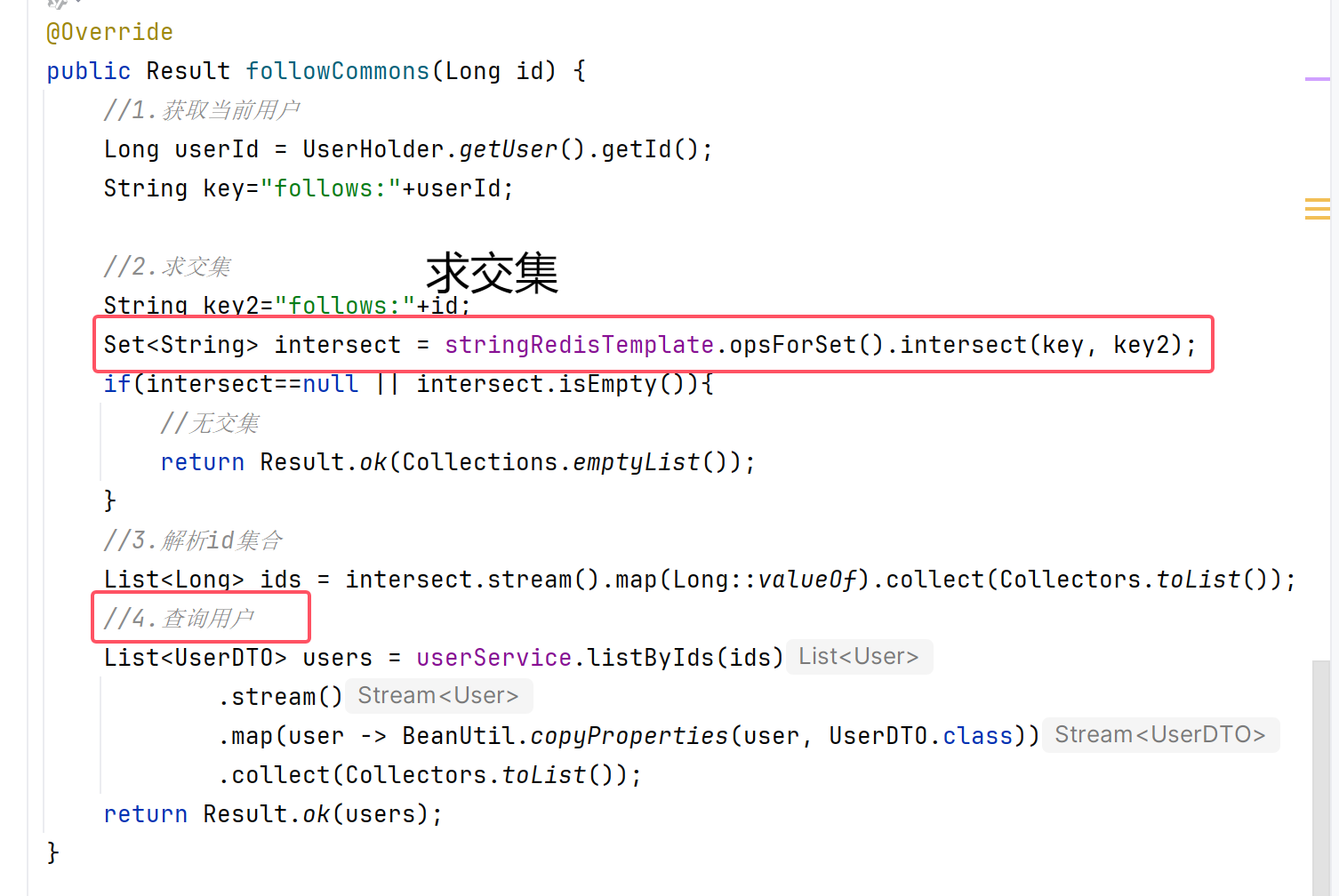
案例:實現共同關注功能
需求:利用Redis中恰當的數據結構,實現共同關注功能。在博主個人頁面展示出當前用戶與博主的共同好友。
之前使用的set集合,在set集合中,有交集并集補集的api,我們可以把兩人的關注的人分別放入到一個set集合中,任何通過api去查看這兩個set集合中的交流數據。
改造關注列表
改造原因是我們需要在用戶關注了某位用戶后,需要將數據放入到set集合中,方便后續進行共同更關注,同時當取消關注,也需要從set集合中刪除
@Override
public Result follow(Long followUserId, Boolean isFollow) {// 1.獲取登錄用戶Long userId = UserHolder.getUser().getId();String key = "follows:" + userId;// 1.判斷到底是關注還是取關if (isFollow) {// 2.關注,新增數據Follow follow = new Follow();follow.setUserId(userId);follow.setFollowUserId(followUserId);boolean isSuccess = save(follow);if (isSuccess) {// 把關注用戶的id,放入redis的set集合 sadd userId followerUserIdstringRedisTemplate.opsForSet().add(key, followUserId.toString());}} else {// 3.取關,刪除 delete from tb_follow where user_id = ? and follow_user_id = ?boolean isSuccess = remove(new QueryWrapper<Follow>().eq("user_id", userId).eq("follow_user_id", followUserId));if (isSuccess) {// 把關注用戶的id從Redis集合中移除stringRedisTemplate.opsForSet().remove(key, followUserId.toString());}}return Result.ok();
}共同關注
關注推送
????????當我們關注了用戶后,這個用戶發了動態,那么我們應該把這些數據推送給用戶,這個需求,其實我們又把他叫做Feed流,關注推送也叫做Feed流,直譯為投喂。為用戶持續的提供“沉浸式”的體驗,通過無限下拉刷新獲取新的信息。
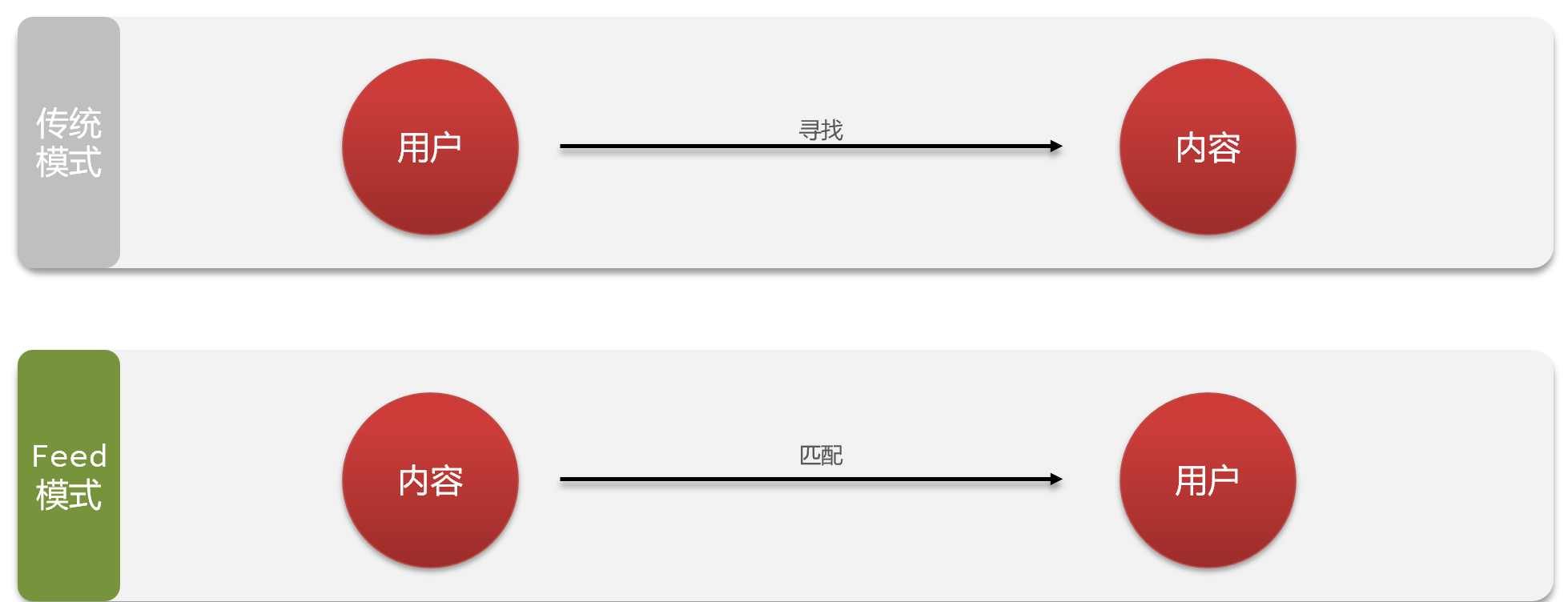
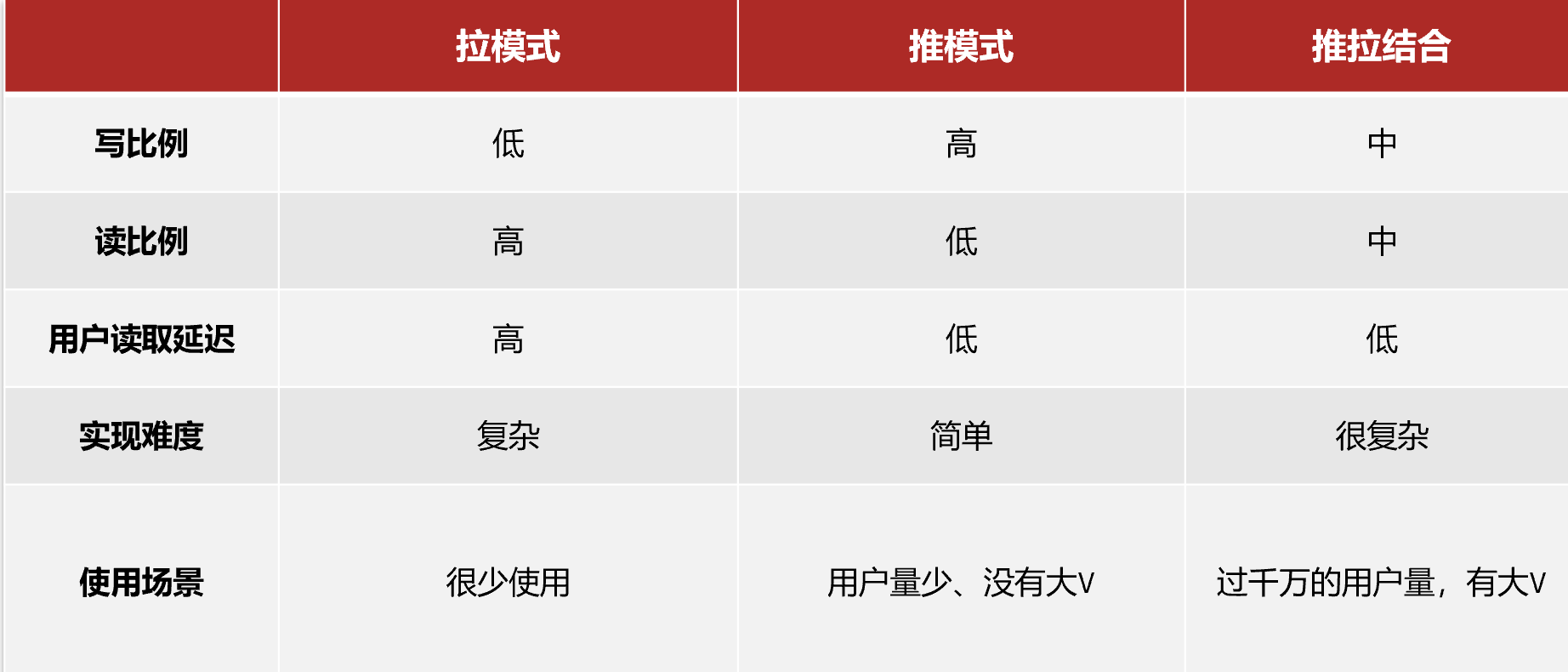
Feed流的模式
Feed流產品有兩種常見模式:
本例中的個人頁面,是基于關注的好友來做Feed流,因此采用Timeline的模式。該模式的實現方案有三種:
拉模式:也叫讀擴散。
????????該模式的核心含義就是:當張三和李四和王五發了消息后,都會保存在自己的郵箱中,假設趙六要讀取信息,那么他會從讀取他自己的收件箱,此時系統會從他關注的人群中,把他關注人的信息全部都進行拉取,然后在進行排序
優點:比較節約空間,因為趙六在讀信息時,并沒有重復讀取,而且讀取完之后可以把他的收件箱進行清楚。
缺點:比較延遲,當用戶讀取數據時才去關注的人里邊去讀取數據,假設用戶關注了大量的用戶,那么此時就會拉取海量的內容,對服務器壓力巨大。
推模式:也叫做寫擴散
????????推模式是沒有寫郵箱的,當張三寫了一個內容,此時會主動的把張三寫的內容發送到他的粉絲收件箱中去,假設此時李四再來讀取,就不用再去臨時拉取了
優點:時效快,不用臨時拉取
缺點:內存壓力大,假設一個大V寫信息,很多人關注他, 就會寫很多分數據到粉絲那邊去
推拉結合模式:也叫做讀寫混合,兼具推和拉兩種模式的優點。
????????推拉模式是一個折中的方案,站在發件人這一段,如果是個普通的人,那么我們采用寫擴散的方式,直接把數據寫入到他的粉絲中去,因為普通的人他的粉絲關注量比較小,所以這樣做沒有壓力,如果是大V,那么他是直接將數據先寫入到一份到發件箱里邊去,然后再直接寫一份到活躍粉絲收件箱里邊去,現在站在收件人這端來看,如果是活躍粉絲,那么大V和普通的人發的都會直接寫入到自己收件箱里邊來,而如果是普通的粉絲,由于他們上線不是很頻繁,所以等他們上線時,再從發件箱里邊去拉信息。
案例:基于推模式實現關注推送功能
需求:
- 修改新增探店筆記的業務,在保存blog到數據庫的同時,推送到粉絲的收件箱
- 收件箱滿足可以根據時間戳排序,必須用Redis的數據結構實現
- 查詢收件箱數據時,可以實現分頁查詢
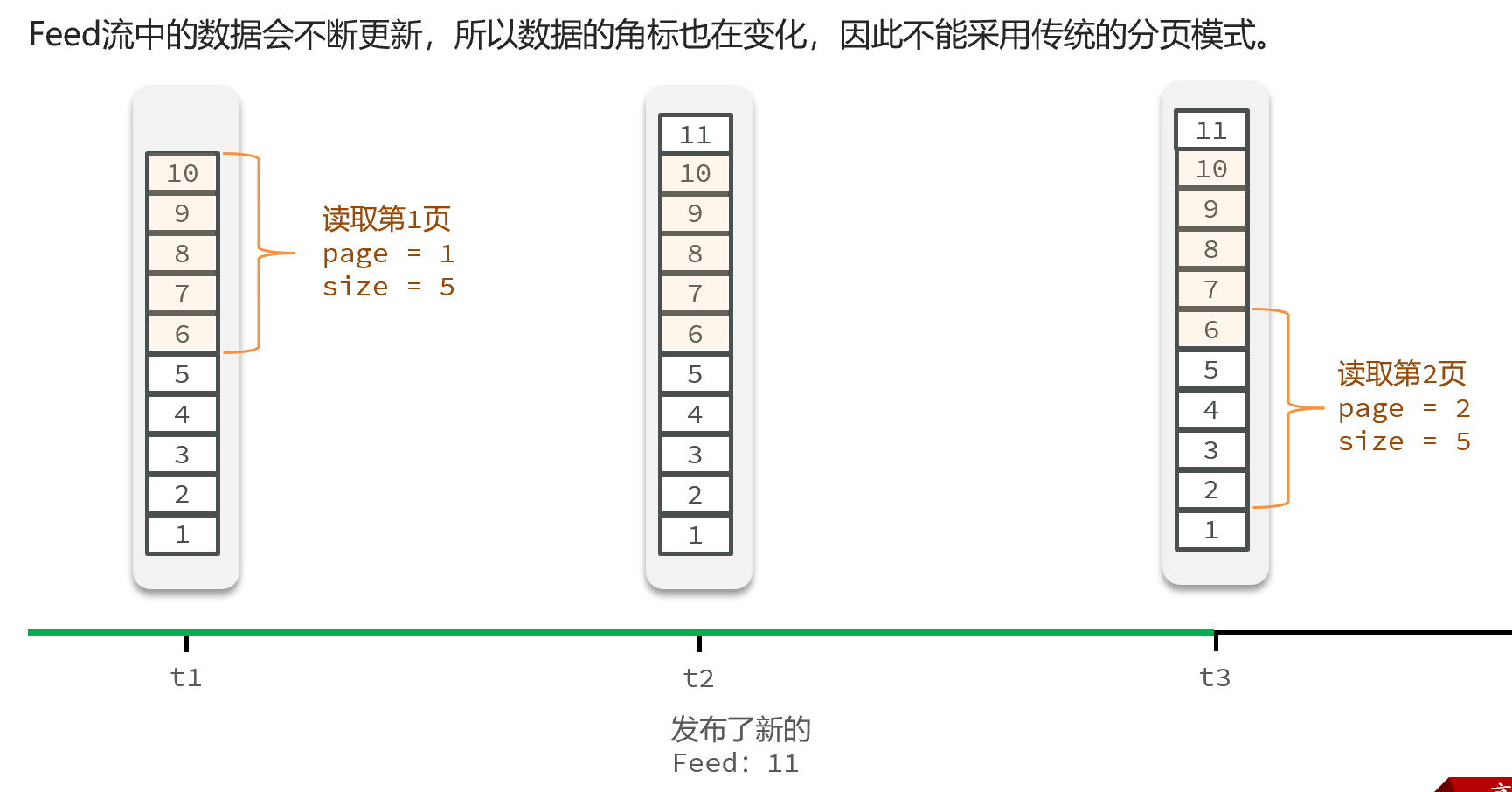
傳統了分頁在feed流是不適用的,因為我們的數據會隨時發生變化
????????假設在t1 時刻,我們去讀取第一頁,此時page = 1 ,size = 5 ,那么我們拿到的就是10~6 這幾條記錄,假設現在t2時候又發布了一條記錄,此時t3 時刻,我們來讀取第二頁,讀取第二頁傳入的參數是page=2 ,size=5 ,那么此時讀取到的第二頁實際上是從6 開始,然后是6~2 ,那么我們就讀取到了重復的數據,所以feed流的分頁,不能采用原始方案來做。
Feed流的滾動分頁
我們需要記錄每次操作的最后一條,然后從這個位置去讀取數據
舉個例子:我們從t1時刻開始,拿第一頁數據,拿到了10~6,然后記錄下當前最后一次拿取的記錄,就是6,t2時刻發布了新的記錄,此時這個11放到最頂上,但是不會影響我們之前記錄的6,此時t3時刻來拿第二頁,第二頁這個時候拿數據,還是從6后一點的5去拿,就拿到了5-1的記錄。我們這個地方可以采用sortedSet來做,可以進行范圍查詢,并且還可以記錄當前獲取數據時間戳最小值,就可以實現滾動分頁了
核心的意思:我們保存完探店筆記后,獲得到當前筆記的粉絲,然后把數據推送到粉絲的redis去。
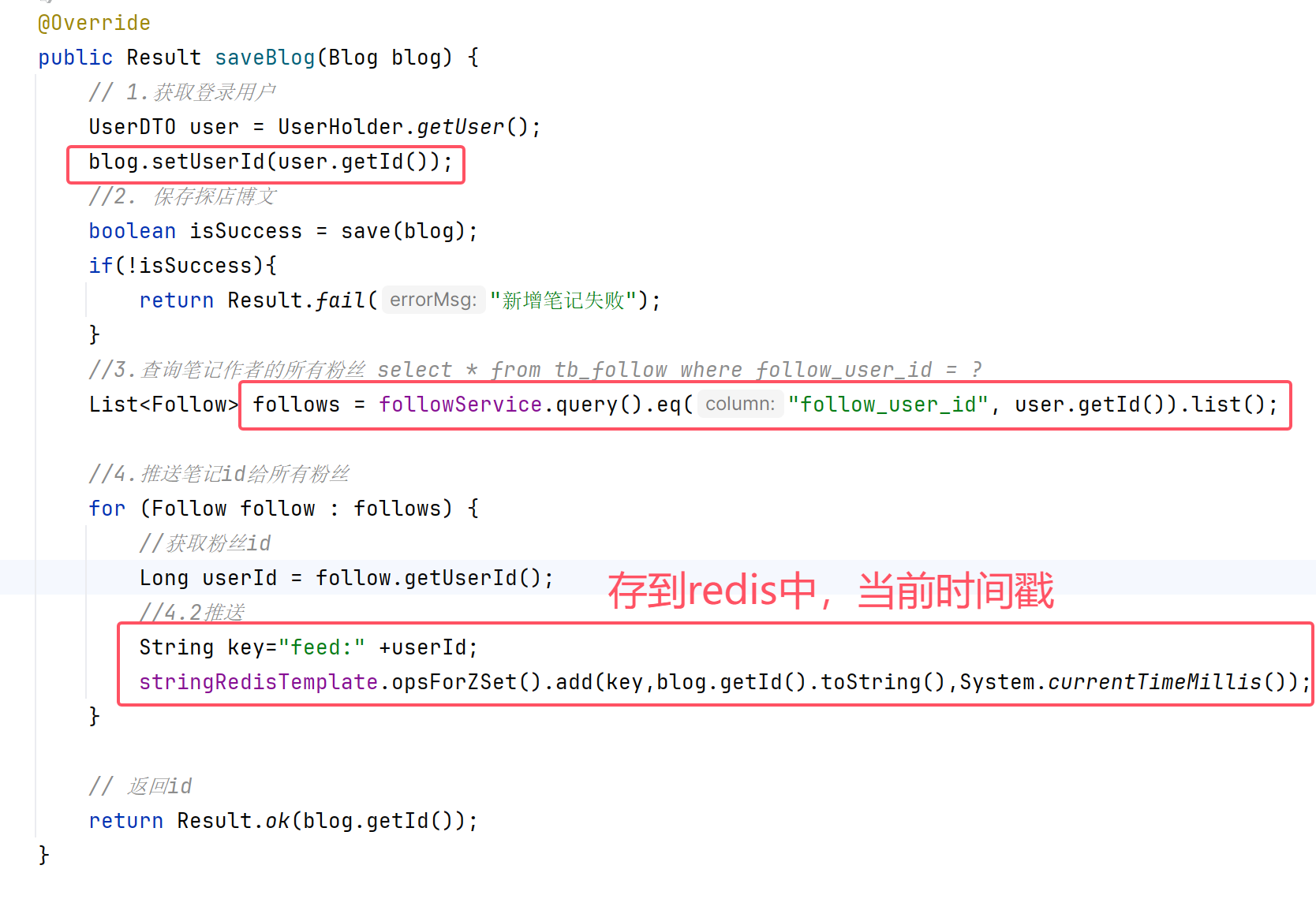
@Overridepublic Result saveBlog(Blog blog) {// 1.獲取登錄用戶UserDTO user = UserHolder.getUser();blog.setUserId(user.getId());//2. 保存探店博文boolean isSuccess = save(blog);if(!isSuccess){return Result.fail("新增筆記失敗");}//3.查詢筆記作者的所有粉絲 select * from tb_follow where follow_user_id = ?List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();//4.推送筆記id給所有粉絲for (Follow follow : follows) {//獲取粉絲idLong userId = follow.getUserId();//4.2推送String key="feed:" +userId;stringRedisTemplate.opsForZSet().add(key,blog.getId().toString(),System.currentTimeMillis());}// 返回idreturn Result.ok(blog.getId());}案例:實現分頁查詢收郵箱
需求:在個人主頁的“關注”卡片中,查詢并展示推送的Blog信息:
具體操作如下:
1、每次查詢完成后,我們要分析出查詢出數據的最小時間戳,這個值會作為下一次查詢的條件
2、我們需要找到與上一次查詢相同的查詢個數作為偏移量,下次查詢時,跳過這些查詢過的數據,拿到我們需要的數據
綜上:我們的請求參數中就需要攜帶 lastId:上一次查詢的最小時間戳 和偏移量這兩個參數。
這兩個參數第一次會由前端來指定,以后的查詢就根據后臺結果作為條件,再次傳遞到后臺。

一、定義出來具體的返回值實體類
@Data
public class ScrollResult {private List<?> list;private Long minTime;private Integer offset;
}注意:RequestParam表示接收url地址欄傳參的注解,當方法上參數的名稱與url地址欄不同時,可以通過RequestParam來指定
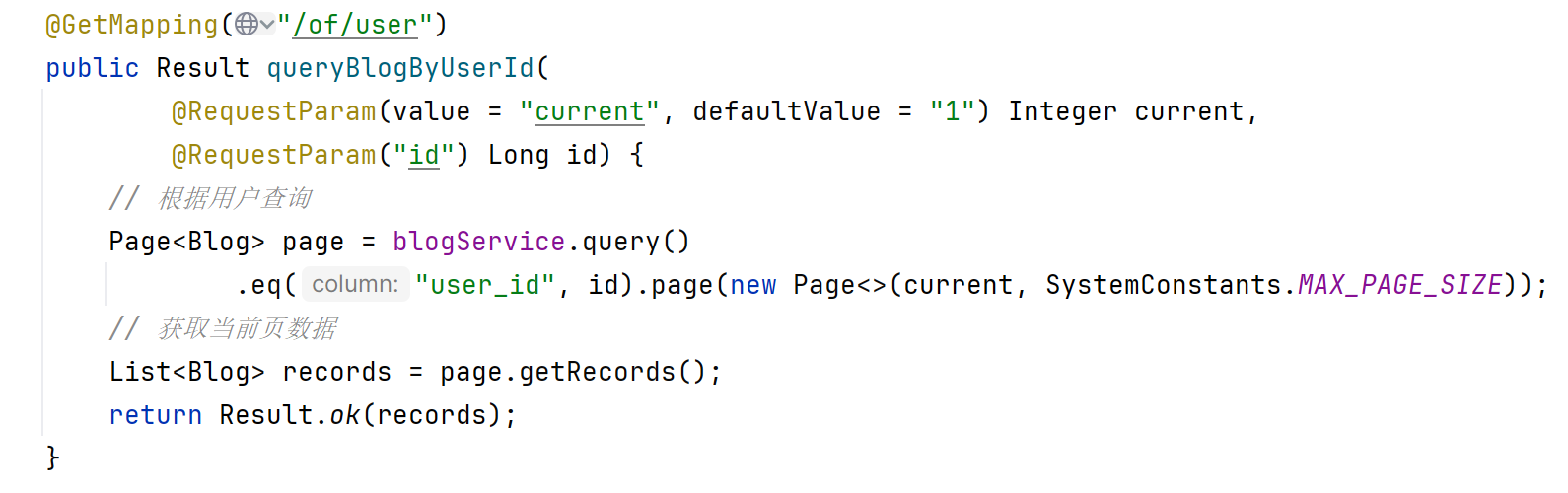
@GetMapping("/of/follow")
public Result queryBlogOfFollow(@RequestParam("lastId") Long max, @RequestParam(value = "offset", defaultValue = "0") Integer offset){return blogService.queryBlogOfFollow(max, offset);
}實現滾動分頁功能的業務流程
首先獲取當前用戶id,查詢收件箱,也就是查redis中存儲的博客

然后解析數據,獲取對應的id和時間戳
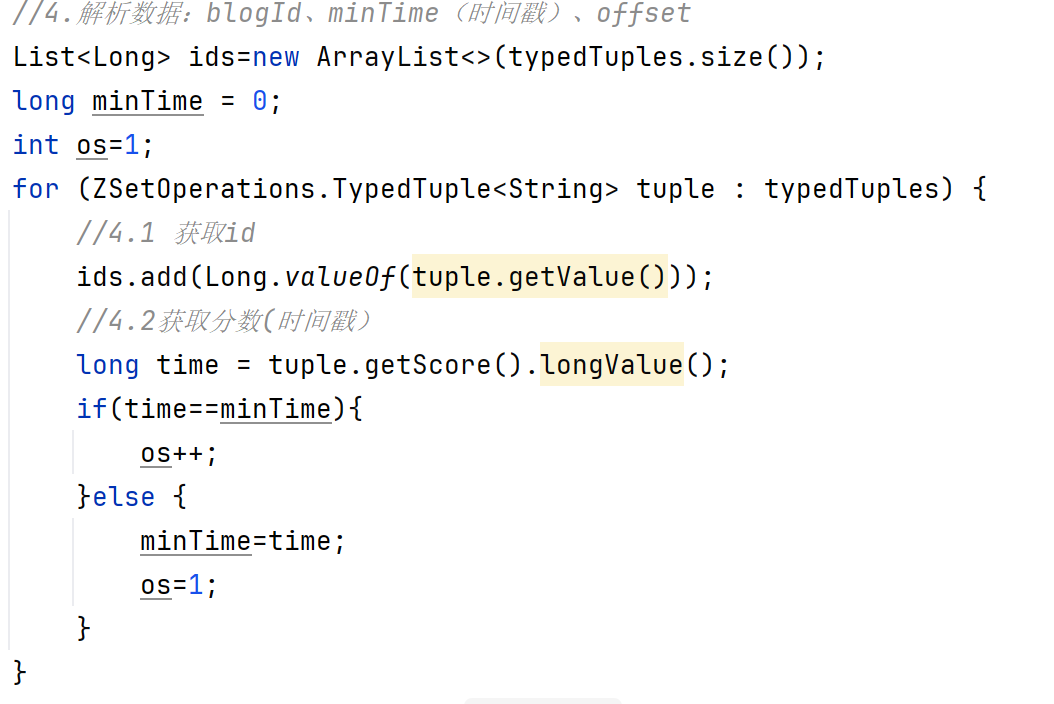
最后根據id查詢blog,按照給定的id進行排序。

查看blog有關的用戶
查詢是否被點贊
封裝數據進行返回
@Overridepublic Result queryBlogOfFollow(Long max, Integer offset) {//1.獲取當前用戶Long userId = UserHolder.getUser().getId();//2.查詢收件箱 ZREVRANGEBYSCORE key Max Min LIMIT offset countString key="feed:"+userId;//每頁最多查兩條Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, 0, max, offset, 2);//3.非空判斷if(typedTuples ==null || typedTuples.isEmpty()){return Result.ok();}//4.解析數據:blogId、minTime(時間戳)、offsetList<Long> ids=new ArrayList<>(typedTuples.size());long minTime = 0;int os=1;for (ZSetOperations.TypedTuple<String> tuple : typedTuples) {//4.1 獲取idids.add(Long.valueOf(tuple.getValue()));//4.2獲取分數(時間戳)long time = tuple.getScore().longValue();if(time==minTime){os++;}else {minTime=time;os=1;}}String idStr = StrUtil.join(",", ids);//5.根據id查詢blogList<Blog> blogs=query().in("id", ids).last("ORDER BY FIELD(id,"+idStr+")").list();for (Blog blog : blogs) {//5.1.查詢blog有關的用戶queryBlogUser(blog);//5.2.查詢blog是否被點贊isBlogLiked(blog);}//5.封裝并返回ScrollResult r=new ScrollResult();r.setList(blogs);r.setOffset(os);r.setMinTime(minTime);return Result.ok(r);}@Overridepublic Result queryBlogById(Long id) {//1.查詢blogBlog blog = getById(id);if(blog==null){return Result.fail("筆記不存在");}//2.查詢blog有關的用戶queryBlogUser(blog);//3.查詢blog是否被點贊isBlogLiked(blog);return Result.ok(blog);}private void isBlogLiked(Blog blog) {//1.獲取登錄用戶UserDTO user = UserHolder.getUser();if(user==null){//用戶未登錄,無需查詢是否點贊return;}Long userId = user.getId();//2.判斷當前用戶是否已經點贊String key="blog:liked:"+blog.getId();Double score= stringRedisTemplate.opsForZSet().score(key, userId.toString());blog.setIsLike(score!=null);}附近商戶
GEO數據結構
GEO就是Geolocation的簡寫形式,代表地理坐標。Redis在3.2版本中加入了對GEO的支持,允許存儲地理坐標信息,幫助我們根據經緯度來檢索數據。常見的命令有:
* GEOADD:添加一個地理空間信息,包含:經度(longitude)、緯度(latitude)、值(member)
* GEODIST:計算指定的兩個點之間的距離并返回
* GEOHASH:將指定member的坐標轉為hash字符串形式并返回
* GEOPOS:返回指定member的坐標
* GEORADIUS:指定圓心、半徑,找到該圓內包含的所有member,并按照與圓心之間的距離排序后返回。6.以后已廢棄
* GEOSEARCH:在指定范圍內搜索member,并按照與指定點之間的距離排序后返回。范圍可以是圓形或矩形。6.2.新功能
* GEOSEARCHSTORE:與GEOSEARCH功能一致,不過可以把結果存儲到一個指定的key。
導入店鋪數據到GEO
????????當我們點擊美食之后,會出現一系列的商家,商家中可以按照多種排序方式,我們此時關注的是距離,這個地方就需要使用到我們的GEO,向后臺傳入當前app收集的地址(我們此處是寫死的) ,以當前坐標作為圓心,同時綁定相同的店家類型type,以及分頁信息,把這幾個條件傳入后臺,后臺查詢出對應的數據再返回。
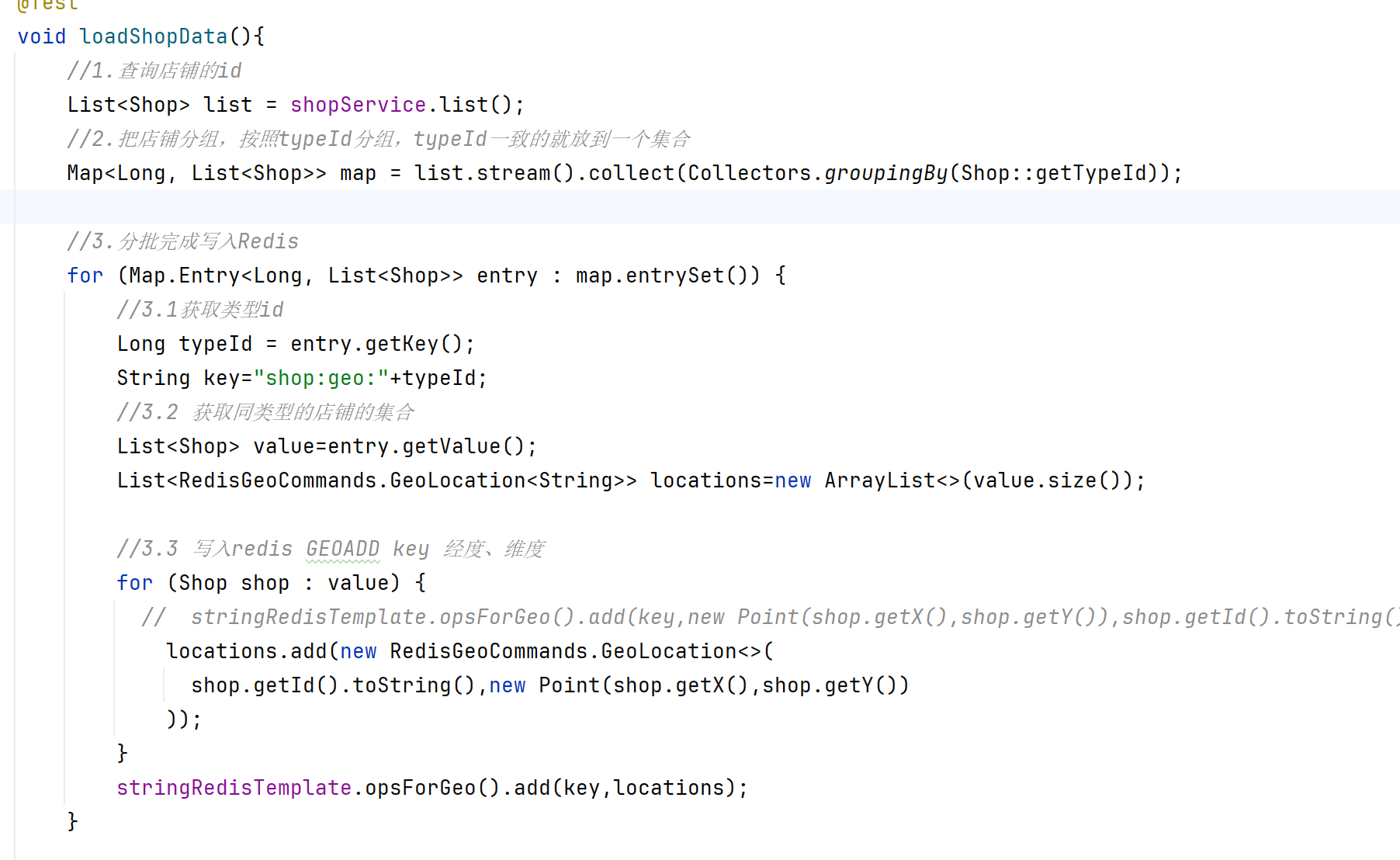
????????我們要做的事情是:將數據庫表中的數據導入到redis中去,redis中的GEO,GEO在redis中就一個menber和一個經緯度,我們把x和y軸傳入到redis做的經緯度位置去,但我們不能把所有的數據都放入到menber中去,畢竟作為redis是一個內存級數據庫,如果存海量數據,redis還是力不從心,所以我們在這個地方存儲他的id即可。
????????但是這個時候還有一個問題,就是在redis中并沒有存儲type,所以我們無法根據type來對數據進行篩選,所以我們可以按照商戶類型做分組,類型相同的商戶作為同一組,以typeId為key存入同一個GEO集合中即可
寫一個測試,把按typeId分類的商戶存入到GEO中
實現附近商戶功能
1.導入pop依賴文件
SpringDataRedis的2.3.9版本并不支持Redis 6.2提供的GEOSEARCH命令,因此我們需要提示其版本,修改自己的POM
2.
@GetMapping("/of/type")
public Result queryShopByType(@RequestParam("typeId") Integer typeId,@RequestParam(value = "current", defaultValue = "1") Integer current,@RequestParam(value = "x", required = false) Double x,@RequestParam(value = "y", required = false) Double y
) {return shopService.queryShopByType(typeId, current, x, y);
}@Overridepublic Result queryShopByType(Integer typeId, Integer current, Double x, Double y) {// 1.判斷是否需要根據坐標查詢if (x == null || y == null) {// 不需要坐標查詢,按數據庫查詢Page<Shop> page = query().eq("type_id", typeId).page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE));// 返回數據return Result.ok(page.getRecords());}// 2.計算分頁參數int from = (current - 1) * SystemConstants.DEFAULT_PAGE_SIZE;int end = current * SystemConstants.DEFAULT_PAGE_SIZE;// 3.查詢redis、按照距離排序、分頁。結果:shopId、distanceString key = SHOP_GEO_KEY + typeId;GeoResults<RedisGeoCommands.GeoLocation<String>> results = stringRedisTemplate.opsForGeo() // GEOSEARCH key BYLONLAT x y BYRADIUS 10 WITHDISTANCE.search(key,GeoReference.fromCoordinate(x, y),new Distance(5000),RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance().limit(end));// 4.解析出idif (results == null) {return Result.ok(Collections.emptyList());}List<GeoResult<RedisGeoCommands.GeoLocation<String>>> list = results.getContent();if (list.size() <= from) {// 沒有下一頁了,結束return Result.ok(Collections.emptyList());}// 4.1.截取 from ~ end的部分List<Long> ids = new ArrayList<>(list.size());Map<String, Distance> distanceMap = new HashMap<>(list.size());list.stream().skip(from).forEach(result -> {// 4.2.獲取店鋪idString shopIdStr = result.getContent().getName();ids.add(Long.valueOf(shopIdStr));// 4.3.獲取距離Distance distance = result.getDistance();distanceMap.put(shopIdStr, distance);});// 5.根據id查詢ShopString idStr = StrUtil.join(",", ids);List<Shop> shops = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list();for (Shop shop : shops) {shop.setDistance(distanceMap.get(shop.getId().toString()).getValue());}// 6.返回return Result.ok(shops);}用戶簽到
BitMap用法
用戶一次簽到,就是一條記錄,假如有1000萬用戶,平均每人每年簽到次數為10次,則這張表一年的數據量為 1億條
每簽到一次需要使用(8 + 8 + 1 + 1 + 3 + 1)共22 字節的內存,一個月則最多需要600多字節
我們如何能夠簡化一點呢?其實可以考慮小時候一個挺常見的方案,就是小時候,咱們準備一張小小的卡片,你只要簽到就打上一個勾,我最后判斷你是否簽到,其實只需要到小卡片上看一看就知道了
我們可以采用類似這樣的方案來實現我們的簽到需求。
我們按月來統計用戶簽到信息,簽到記錄為1,未簽到則記錄為0.
把每一個bit位對應當月的每一天,形成了映射關系。用0和1標示業務狀態,這種思路就稱為位圖(BitMap)。這樣我們就用極小的空間,來實現了大量數據的表示
Redis中是利用string類型數據結構實現BitMap,因此最大上限是512M,轉換為bit則是 2^32個bit位。
BitMap的操作命令有:
* SETBIT:向指定位置(offset)存入一個0或1
* GETBIT :獲取指定位置(offset)的bit值
* BITCOUNT :統計BitMap中值為1的bit位的數量
* BITFIELD :操作(查詢、修改、自增)BitMap中bit數組中的指定位置(offset)的值
* BITFIELD_RO :獲取BitMap中bit數組,并以十進制形式返回
* BITOP :將多個BitMap的結果做位運算(與 、或、異或)
* BITPOS :查找bit數組中指定范圍內第一個0或1出現的位置
案例:簽到功能
需求:實現簽到接口,將當前用戶當天簽到信息保存到Redis中
思路:我們可以把年和月作為bitMap的key,然后保存到一個bitMap中,每次簽到就到對應的位上把數字從0變成1,只要對應是1,就表明說明這一天已經簽到了,反之則沒有簽到。
我們通過接口文檔發現,此接口并沒有傳遞任何的參數,沒有參數怎么確實是哪一天簽到呢?這個很容易,可以通過后臺代碼直接獲取即可,然后到對應的地址上去修改bitMap。
UserController
@PostMapping("/sign")public Result sign(){return userService.sign();}UserServiceImpl
@Override
public Result sign() {// 1.獲取當前登錄用戶Long userId = UserHolder.getUser().getId();// 2.獲取日期LocalDateTime now = LocalDateTime.now();// 3.拼接keyString keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));String key = USER_SIGN_KEY + userId + keySuffix;// 4.獲取今天是本月的第幾天int dayOfMonth = now.getDayOfMonth();// 5.寫入Redis SETBIT key offset 1stringRedisTemplate.opsForValue().setBit(key, dayOfMonth - 1, true);return Result.ok();
}簽到統計
什么是連續簽到天數?
從最后一次簽到開始向前統計,直到遇到第一次簽到為止,計算總的簽到次數,就是連續簽到次數。
Java邏輯代碼:獲得當前這個月的最后一次簽到數據,定義一個計數器,然后不停的向前統計,直到獲得第一個非0的數字即可,每得到一個非0的數字計數器+1,直到遍歷完所有的數據,就可以獲得當前月的簽到總天數了
如何得到本月到今天為止的所有簽到數據?
????????假設今天是10號,那么我們就可以從當前月的第一天開始,獲得到當前這一天的位數,是10號,那么就是10位,去拿這段時間的數據,就能拿到所有的數據了,那么這10天里邊簽到了多少次呢?統計有多少個1即可。
如何從后往前遍歷每個bit位?
注意:bitMap返回的數據是10進制,哪假如說返回一個數字8,那么我哪兒知道到底哪些是0,哪些是1呢?我們只需要讓得到的10進制數字和1做與運算就可以了,因為1只有遇見1 才是1,其他數字都是0 ,我們把簽到結果和1進行與操作,每與一次,就把簽到結果向右移動一位,依次內推,我們就能完成逐個遍歷的效果了。
與1做與運算,就能得到最后一個bit位。
隨后右移1位,下一個bit位就成為了最后一個bit位。
案例:實現簽到統計功能
需求:實現下面接口,統計當前用戶截止當前時間在本月的連續簽到天數
有用戶有時間我們就可以組織出對應的key,此時就能找到這個用戶截止這天的所有簽到記錄,再根據這套算法,就能統計出來他連續簽到的次數了
@GetMapping("/sign/count")
public Result signCount(){return userService.signCount();
}@Override
public Result signCount() {// 1.獲取當前登錄用戶Long userId = UserHolder.getUser().getId();// 2.獲取日期LocalDateTime now = LocalDateTime.now();// 3.拼接keyString keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));String key = USER_SIGN_KEY + userId + keySuffix;// 4.獲取今天是本月的第幾天int dayOfMonth = now.getDayOfMonth();// 5.獲取本月截止今天為止的所有的簽到記錄,返回的是一個十進制的數字 BITFIELD sign:5:202203 GET u14 0List<Long> result = stringRedisTemplate.opsForValue().bitField(key,BitFieldSubCommands.create().get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)).valueAt(0));if (result == null || result.isEmpty()) {// 沒有任何簽到結果return Result.ok(0);}Long num = result.get(0);if (num == null || num == 0) {return Result.ok(0);}// 6.循環遍歷int count = 0;while (true) {// 6.1.讓這個數字與1做與運算,得到數字的最后一個bit位 // 判斷這個bit位是否為0if ((num & 1) == 0) {// 如果為0,說明未簽到,結束break;}else {// 如果不為0,說明已簽到,計數器+1count++;}// 把數字右移一位,拋棄最后一個bit位,繼續下一個bit位num >>>= 1;}return Result.ok(count);
}擴展——關于使用bitmap來解決緩存穿透的方案
緩存穿透:發起了一個數據庫不存在的,redis里邊也不存在的數據,通常你可以把他看成一個攻擊
解決方案:
*? 判斷id<0
* 如果數據庫是空,那么就可以直接往redis里邊把這個空數據緩存起來
第一種解決方案:遇到的問題是如果用戶訪問的是id不存在的數據,則此時就無法生效
第二種解決方案:遇到的問題是:如果是不同的id那就可以防止下次過來直擊數據
所以如何解決呢?
我們可以將數據庫的數據,所對應的id寫入到一個list集合中,當用戶過來訪問的時候,我們直接去判斷list中是否包含當前的要查詢的數據,如果說用戶要查詢的id數據并不在list集合中,則直接返回,如果list中包含對應查詢的id數據,則說明不是一次緩存穿透數據,則直接放行。
UV統計
* UV:全稱Unique Visitor,也叫獨立訪客量,是指通過互聯網訪問、瀏覽這個網頁的自然人。1天內同一個用戶多次訪問該網站,只記錄1次。
* PV:全稱Page View,也叫頁面訪問量或點擊量,用戶每訪問網站的一個頁面,記錄1次PV,用戶多次打開頁面,則記錄多次PV。往往用來衡量網站的流量。
通常來說UV會比PV大很多,所以衡量同一個網站的訪問量,我們需要綜合考慮很多因素,所以我們只是單純的把這兩個值作為一個參考值
UV統計在服務端做會比較麻煩,因為要判斷該用戶是否已經統計過了,需要將統計過的用戶信息保存。但是如果每個訪問的用戶都保存到Redis中,數據量會非常恐怖,那怎么處理呢?
Hyperloglog(HLL)是從Loglog算法派生的概率算法,用于確定非常大的集合的基數,而不需要存儲其所有值。相關算法原理大家可以參考:https://juejin.cn/post/6844903785744056333#heading-0
Redis中的HLL是基于string結構實現的,單個HLL的內存**永遠小于16kb**,**內存占用低**的令人發指!作為代價,其測量結果是概率性的,**有小于0.81%的誤差**。不過對于UV統計來說,這完全可以忽略。



)



詳細講解進程的組成與特性,狀態與轉換)

)









