內容總結自:bilibili zomi 視頻大模型流水線并行?
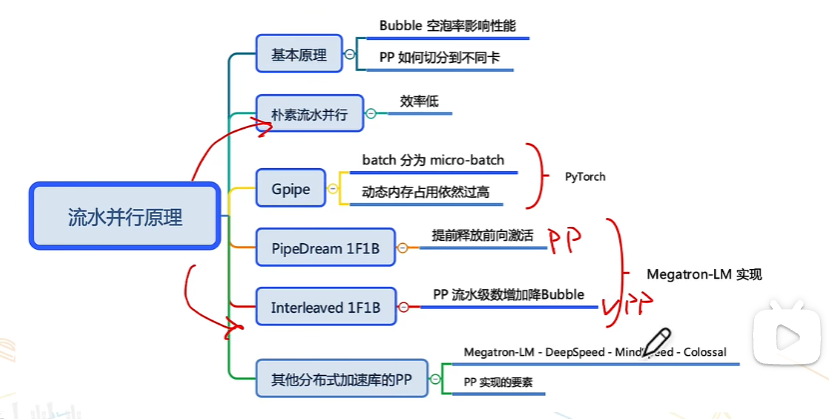
注:這里PipeDream 1F1B對應時PP,Interleaved 1F1B對應的是VPP
1、樸素流水線并行
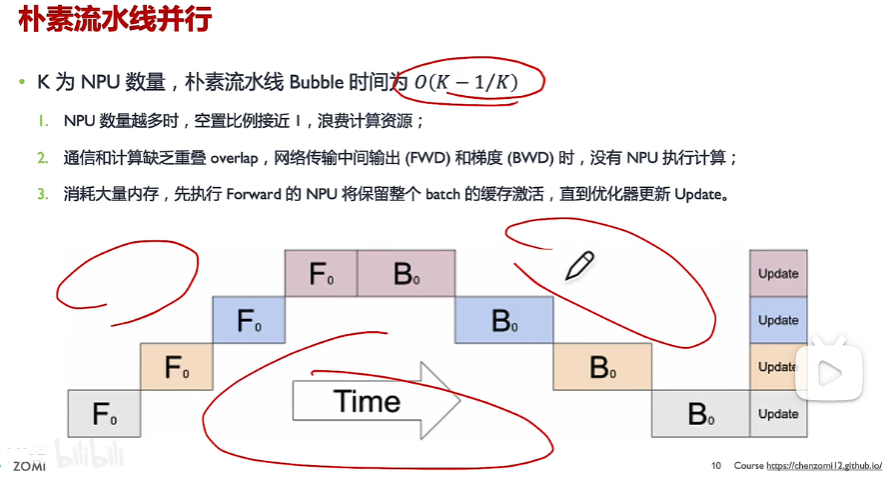
備注:
(1)紅色三個圈都為空泡時間,GPU沒有做任何計算
(2)共有4張卡,大batch size下,F0為第1次前向,依次流水線執行。所有stage完成后,再執行第1次反向B0。
(3)所有stage反向傳播完計算好梯度后,所有stage同時更新參數
GPU利用率非常低。
2、Gpipe 流水線并行
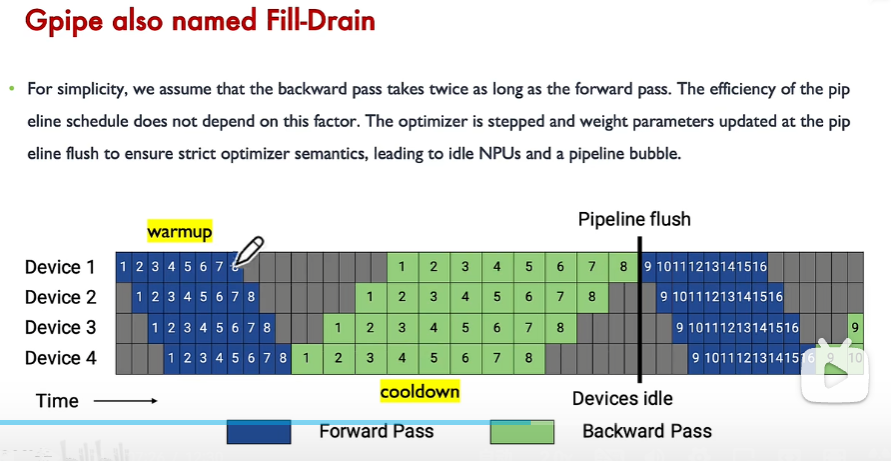
解決辦法:
(1)將大的batch size拆分為多個小的micro batch size,如數據1計算完了后,直接進入下一個stage device2計算,無需等待數據8執行完。

空泡率:
(1)micro? batch_size越高,空泡率越低
(2)m個micro-batch前向結束時,內存達到峰值,不斷增加m可能導致內存不夠。解決辦法為重計算,即部分層不存儲中間結果,在計算梯度時再重新計算中間結果。
(3)MFU 模型利用率提高
3、1F1B PP(非交錯式)
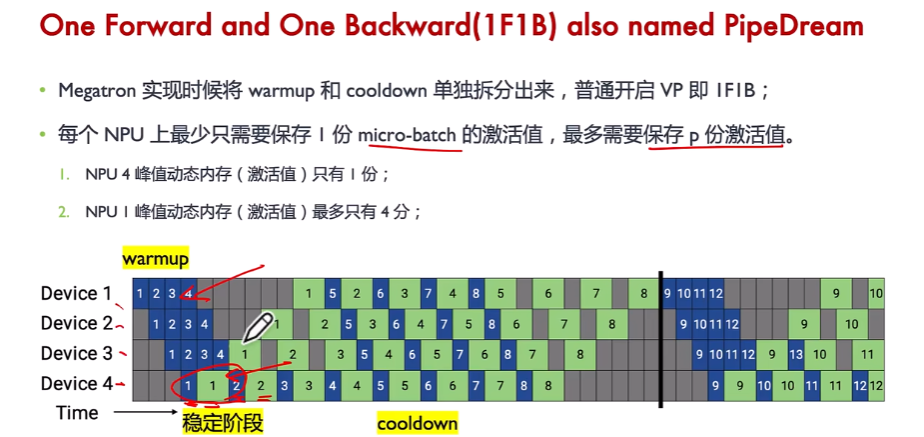
備注:
(1)在最后一個stage,即NPU4上可以看到,1次前向1次反向,交替進行,因此叫做1F1B。這個NPU上只保存了1份激活值,即前向中間結果,及時反向后釋放。而NPU1最多有4份
4、1F1B interleaving VPP(交錯式)
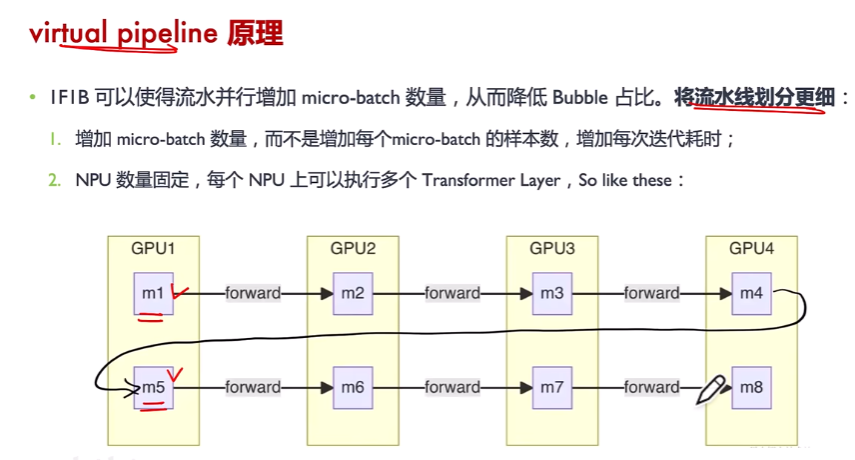
要持續降低bubble占比,有上圖兩種方式,第二種方式為將每張卡上搞多個stage。
(1)如NPU1負責第1層和第5層。按照原來的1F1B的方法,若有4張卡,分4個stage,則每張卡負責連續的2層,如NPU1負責1-2層,當數據1過來,需要在NPU1上經過2層計算后才到第二張卡。反而通過本方案,數據1過來后,只要經過1層計算,馬上到第二張卡,第二張卡及以后的等待時間變短了。這時第一張卡可以做數據2的計算。
完整的圖如下:
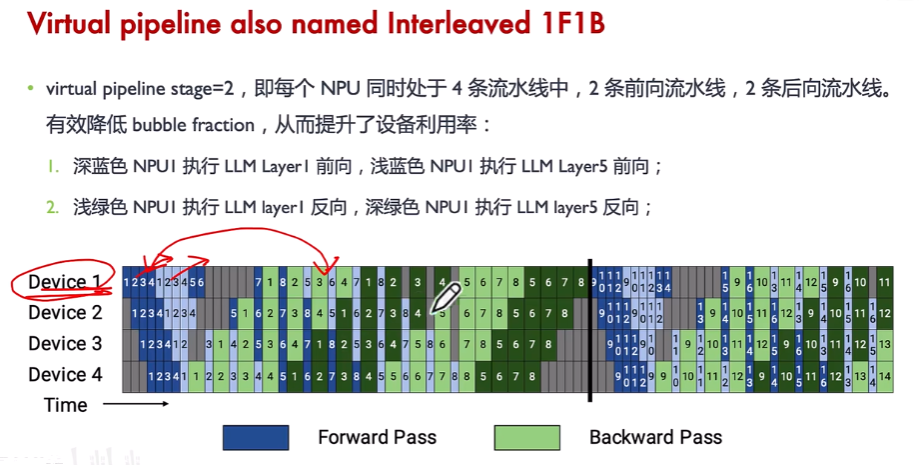
(1)這里橫坐標為時間線,如第1時刻,只有NPU1在做數據1的計算,第4時刻NPU1在做數據4計算,NPU4在做數據1的計算。
(2)第5時刻,NPU4已經完成數據1的計算了,按照上一張圖的說法,意味著數據1已經完成了第4層的計算,這時候可以回到第一張卡做數據1的第5層前向計算了。這時NPU2還在做數據4的第一層前向計算。其他的可以見圖所示。
(3)第9時刻,數據1已經完成完整的8層前向計算,在NPU4上可以做反向傳播,執行1F1B了。其他的類似。
空泡率:

5、其他的流水線并行?
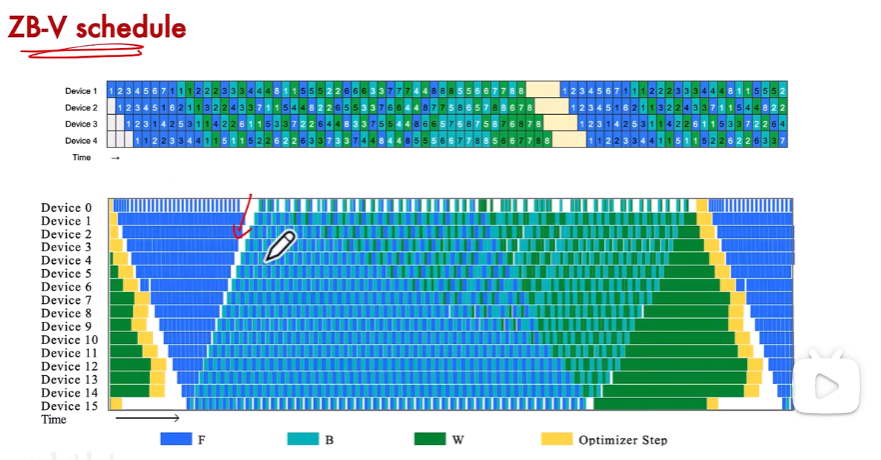
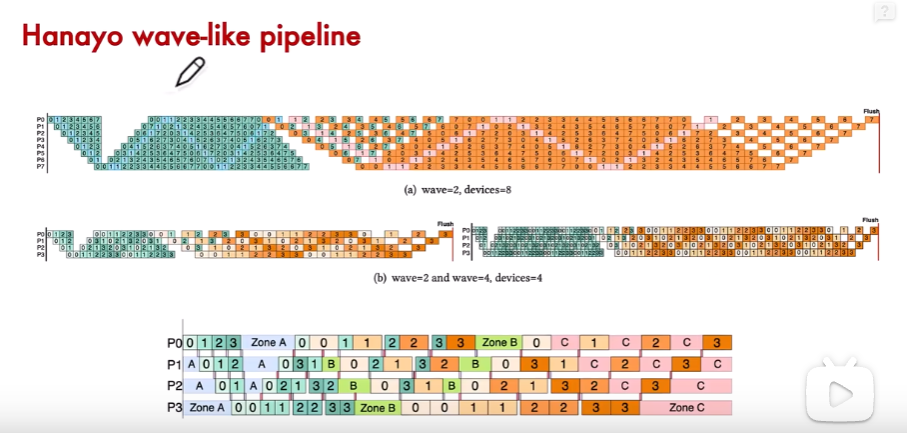
6、分布式PP實現方案
是所有并行中最難的,分為以下兩種實現方式:




7、PP 代碼實現
(1)模型實例化構建
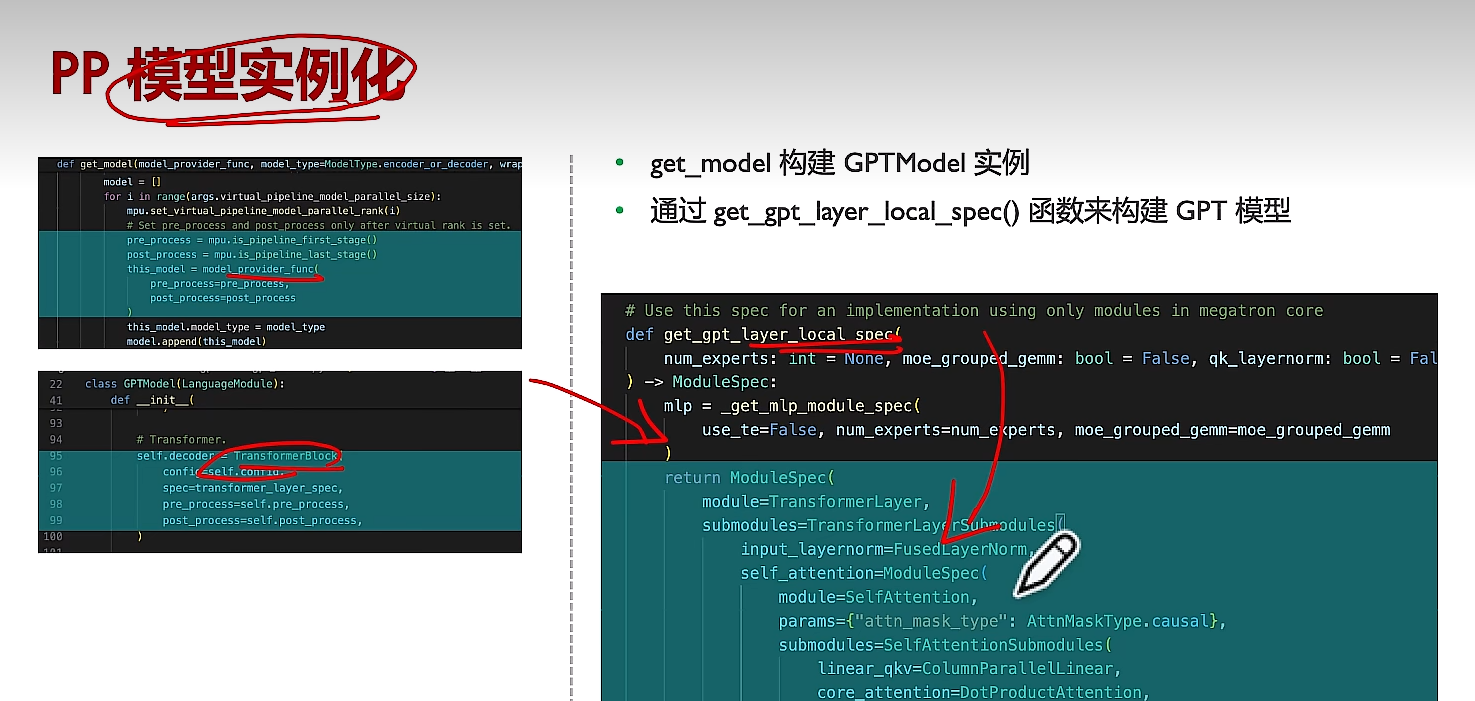
(2)每個NPU只構建對應offset的layers
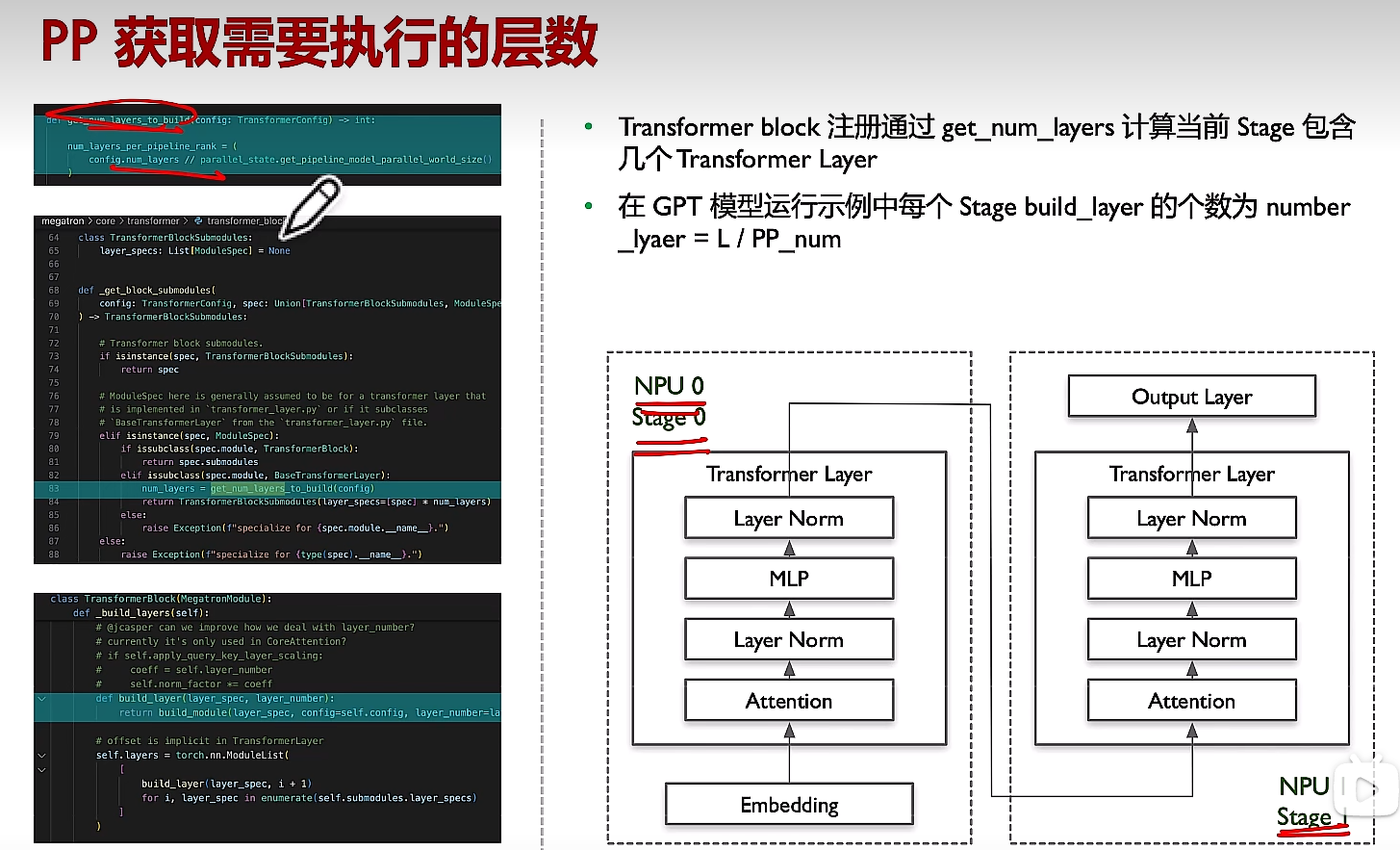
- 每個rank的層數為:總層數//pp數,若只有一層,如何分配?
- embedding和output layer如何分配到第一個NPU和最后一個NPU的,代碼在哪里?
(3)確定執行交錯式或非交錯式的前向反向函數
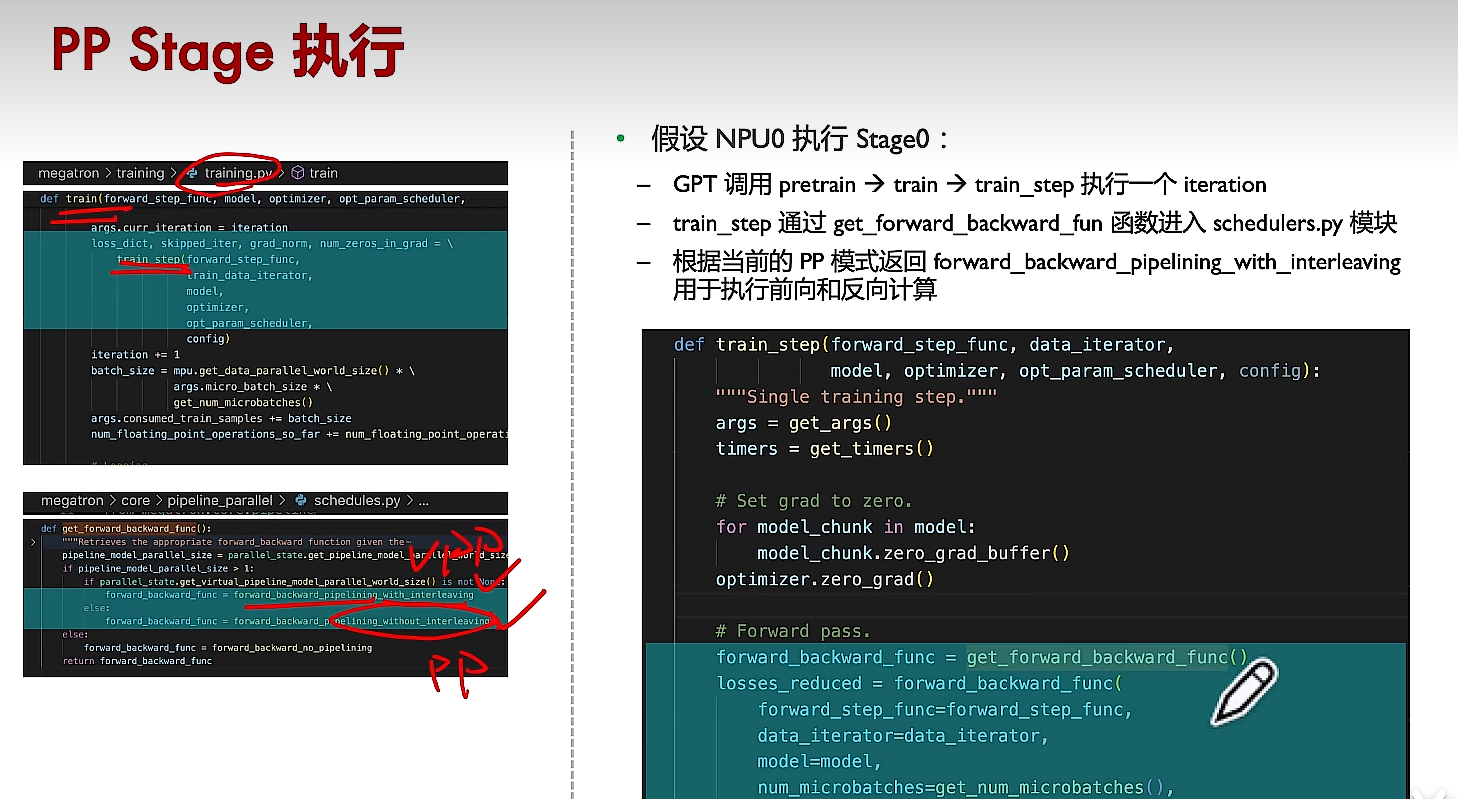
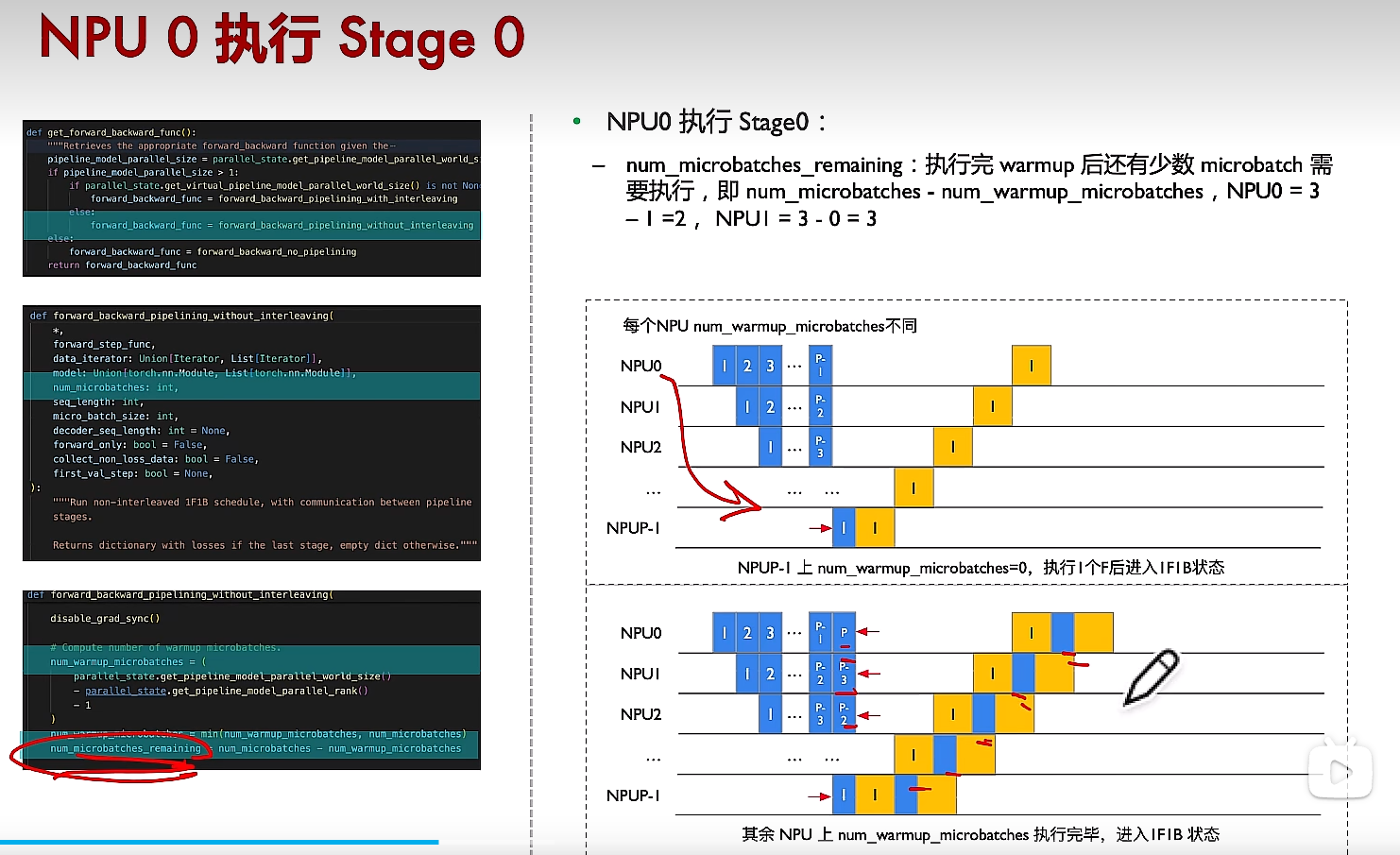 ?
?
這里面num_microbatches_remaining為對應rank還有多少個micro batchs沒有執行完。
(3)3個步驟,接收、前向計算、發送
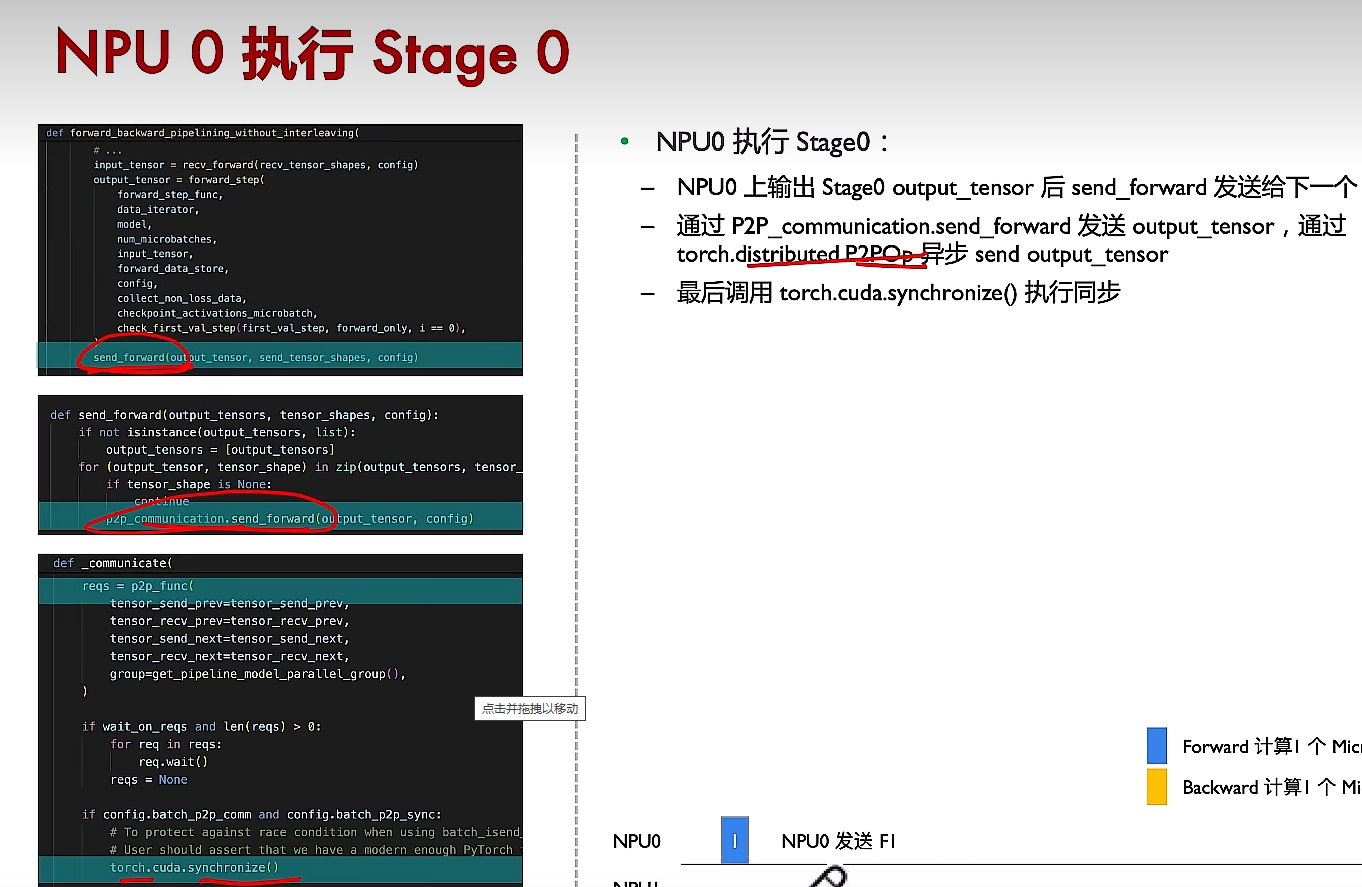
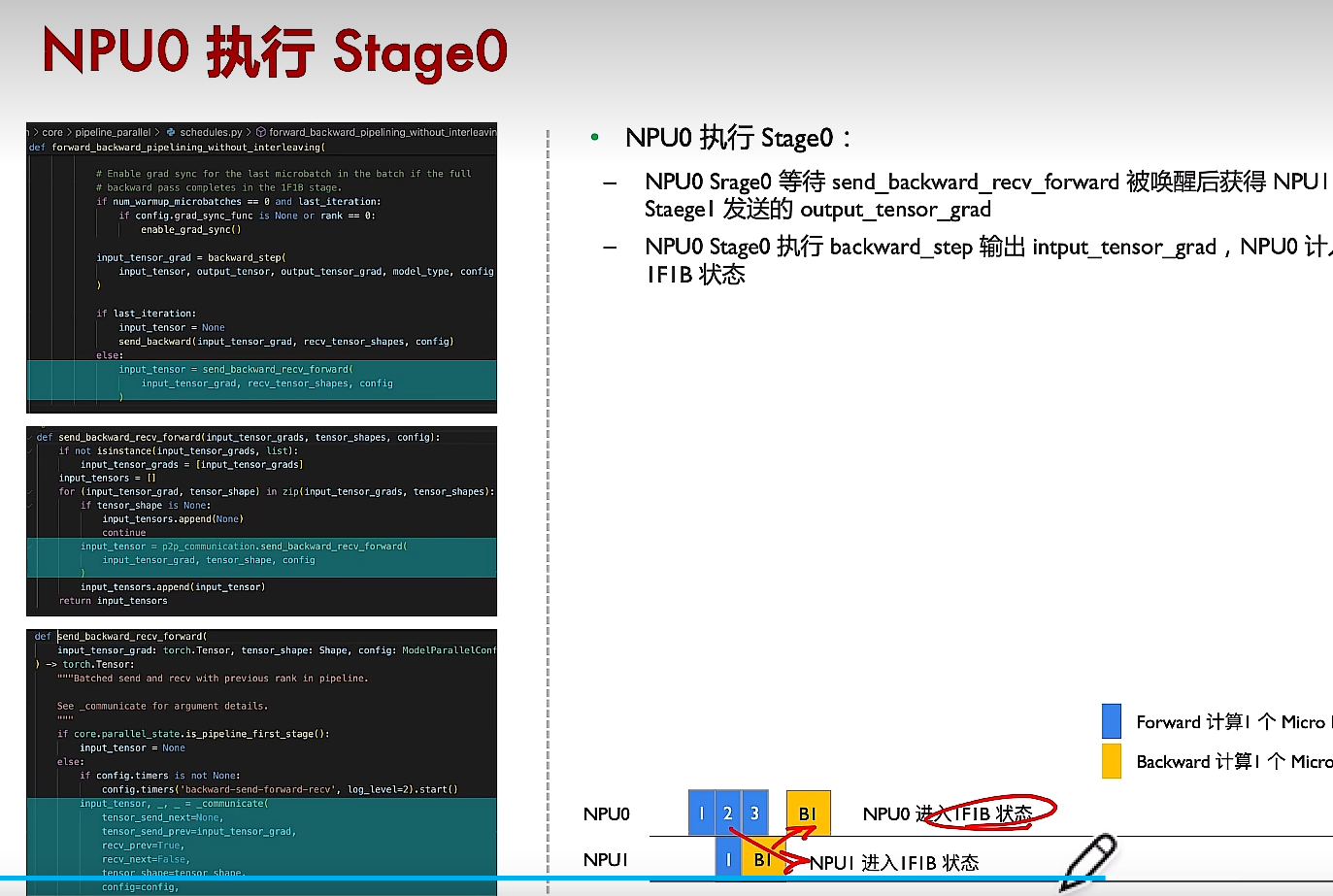
(4)反向傳播
 ?
?
NPU0和NPU1在不斷通訊,NPU1完成B1反向傳播時,會將結果發給NPU0,同時等待數據2前向計算的結果。?
?



![[C++] 一個線程打印奇數一個線程打印偶數](http://pic.xiahunao.cn/[C++] 一個線程打印奇數一個線程打印偶數)















