本文附帶視頻講解
【代碼宇宙019】技術方案:藍牙音響接入DeepSeek,解鎖語音交互新玩法_嗶哩嗶哩_bilibili
目錄
效果演示
核心邏輯
技術實現
大模型對話(技術: LangChain4j 接入 DeepSeek)
語音識別(技術:阿里云-實時語音識別)
語音生成(技術:阿里云-語音生成)
效果演示
核心邏輯
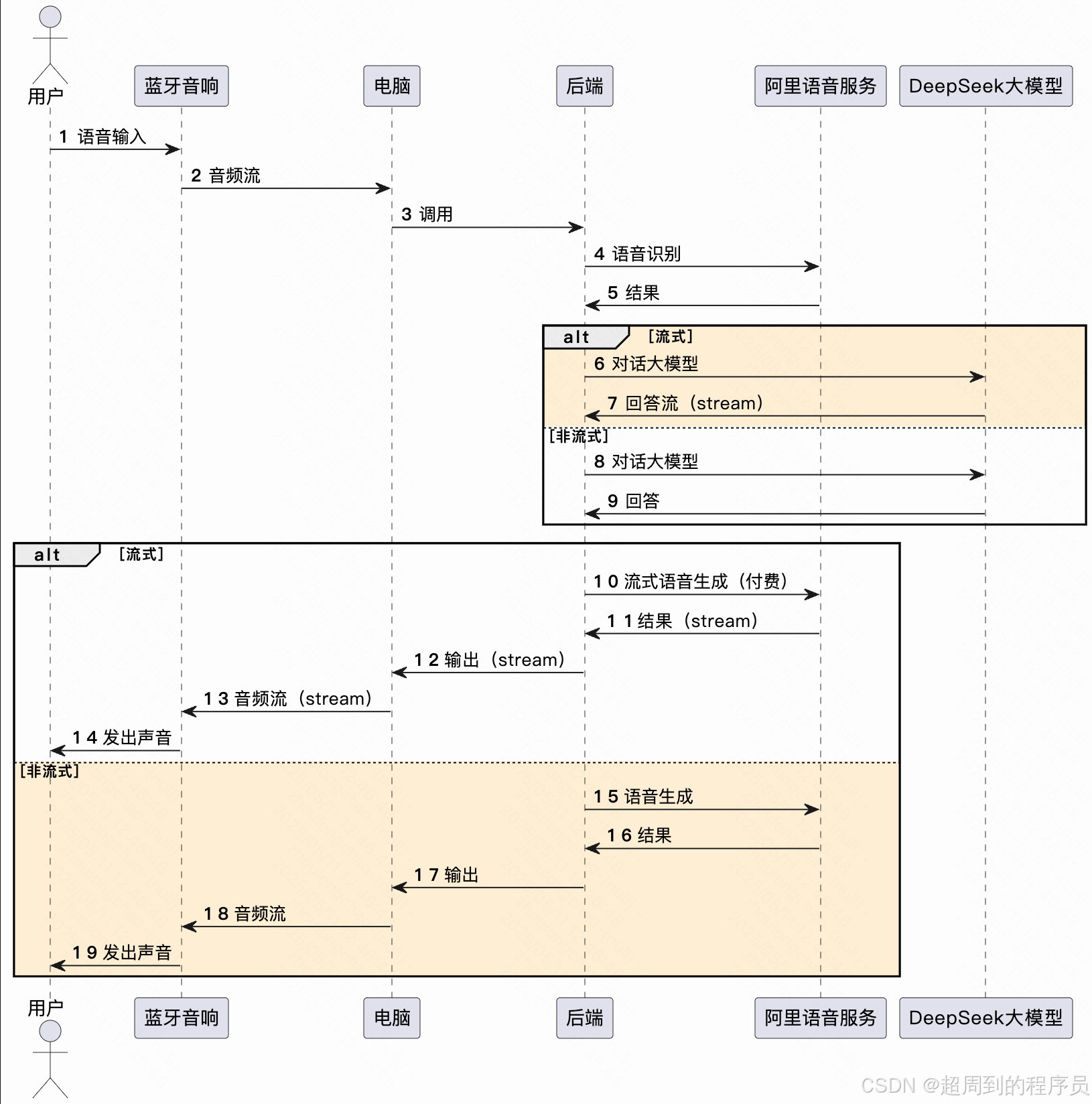
技術實現
大模型對話(技術: LangChain4j 接入 DeepSeek)
常用依賴都在這里(不是最簡),DeepSeek 目前沒有單獨的依賴,用 open-ai 協議的依賴可以兼容,官網這里有說明:OpenAI Official SDK | LangChain4j

<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-open-ai</artifactId><version>1.0.0-beta3</version>
</dependency>
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j</artifactId><version>1.0.0-beta3</version>
</dependency>
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-spring-boot-starter</artifactId><version>1.0.0-beta3</version>
</dependency>請求 ds 的核心類
package ai.voice.assistant.client;/*** @Author:超周到的程序員* @Date:2025/4/25*/import ai.voice.assistant.config.DaemonProcess;
import ai.voice.assistant.service.llm.BaseChatClient;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.SystemMessage;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.model.chat.response.ChatResponse;
import dev.langchain4j.model.chat.response.StreamingChatResponseHandler;
import dev.langchain4j.model.openai.OpenAiStreamingChatModel;import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountDownLatch;import com.alibaba.fastjson.JSON;@Component("deepSeekStreamClient")
public class DeepSeekStreamClient implements BaseChatClient {private static final Logger LOGGER = LogManager.getLogger(DeepSeekStreamClient.class);@Value("${certificate.llm.deepseek.key}")private String key;@Overridepublic String chat(String question) {if (question.isBlank()) {return "";}OpenAiStreamingChatModel model = OpenAiStreamingChatModel.builder().baseUrl("https://api.deepseek.com").apiKey(key).modelName("deepseek-chat").build();List<ChatMessage> messages = new ArrayList<>();messages.add(SystemMessage.from(prompt));messages.add(UserMessage.from(question));CountDownLatch countDownLatch = new CountDownLatch(1);StringBuilder answerBuilder = new StringBuilder();model.chat(messages, new StreamingChatResponseHandler() {@Overridepublic void onPartialResponse(String answerSplice) {// 語音生成(流式)// voiceGenerateStreamService.process(new String[] {answerSplice});
// System.out.println("== answerSplice: " + answerSplice);answerBuilder.append(answerSplice);}@Overridepublic void onCompleteResponse(ChatResponse chatResponse) {countDownLatch.countDown();}@Overridepublic void onError(Throwable throwable) {LOGGER.error("chat ds error, messages:{} err:", JSON.toJSON(messages), throwable);}});try {countDownLatch.await();} catch (InterruptedException e) {throw new RuntimeException(e);}String answer = answerBuilder.toString();LOGGER.info("chat ds end, answer:{}", answer);return answer;}
}語音識別(技術:阿里云-實時語音識別)
開發參考_智能語音交互(ISI)-阿里云幫助中心
開發日志記錄——
這里在我的場景下遇到了會話斷連的問題:
- 問題場景:阿里的實時語音識別,第一次對話后 10s 如果不說話那么會斷開連接(阿里側避免過多無用連接占用),本次做的藍牙音響訴求是讓他一直保活不斷開,有需要就和它對話并且不想要喚醒詞
- 解決方式:因此這里用了 catch 斷連異常后再次執行監聽方法的方式來兼容這個問題,其實也可以定時發送一個空包過去,但是那樣不確定會不會額外增加費用,另外也要處理同時發送空包和人進行語音對話的問題,最終生成的音頻文件播放哪個的順序問題
<dependency><groupId>com.alibaba.nls</groupId><artifactId>nls-sdk-tts</artifactId><version>${ali-vioce-sdk.version}</version>
</dependency>
<dependency><groupId>com.alibaba.nls</groupId><artifactId>nls-sdk-transcriber</artifactId><version>${ali-vioce-sdk.version}</version>
</dependency>package ai.voice.assistant.service.voice;import ai.voice.assistant.config.VoiceConfig;
import ai.voice.assistant.service.llm.BaseChatClient;
import ai.voice.assistant.util.WavPlayerUtil;
import com.alibaba.nls.client.protocol.Constant;
import com.alibaba.nls.client.protocol.InputFormatEnum;
import com.alibaba.nls.client.protocol.NlsClient;
import com.alibaba.nls.client.protocol.SampleRateEnum;
import com.alibaba.nls.client.protocol.asr.SpeechTranscriber;
import com.alibaba.nls.client.protocol.asr.SpeechTranscriberListener;
import com.alibaba.nls.client.protocol.asr.SpeechTranscriberResponse;
import jakarta.annotation.PreDestroy;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Service;import javax.sound.sampled.AudioFormat;
import javax.sound.sampled.AudioSystem;
import javax.sound.sampled.DataLine;
import javax.sound.sampled.TargetDataLine;/*** @Author:超周到的程序員* @Date:2025/4/23 此示例演示了從麥克風采集語音并實時識別的過程* (僅作演示,需用戶根據實際情況實現)*/
@Service
public class VoiceRecognitionService {private static final Logger LOGGER = LoggerFactory.getLogger(VoiceRecognitionService.class);@Autowiredprivate NlsClient client;@Autowiredprivate VoiceConfig voiceConfig;@Autowiredprivate VoiceGenerateService voiceGenerateService;@Autowired
// @Qualifier("deepSeekStreamClient")@Qualifier("deepSeekMemoryClient")private BaseChatClient chatClient;public SpeechTranscriberListener getTranscriberListener() {SpeechTranscriberListener listener = new SpeechTranscriberListener() {//識別出中間結果.服務端識別出一個字或詞時會返回此消息.僅當setEnableIntermediateResult(true)時,才會有此類消息返回@Overridepublic void onTranscriptionResultChange(SpeechTranscriberResponse response) {// 重要提示: task_id很重要,是調用方和服務端通信的唯一ID標識,當遇到問題時,需要提供此task_id以便排查LOGGER.info("name: {}, status: {}, index: {}, result: {}, time: {}",response.getName(),response.getStatus(),response.getTransSentenceIndex(),response.getTransSentenceText(),response.getTransSentenceTime());}@Overridepublic void onTranscriberStart(SpeechTranscriberResponse response) {LOGGER.info("task_id: {}, name: {}, status: {}",response.getTaskId(),response.getName(),response.getStatus());}@Overridepublic void onSentenceBegin(SpeechTranscriberResponse response) {LOGGER.info("task_id: {}, name: {}, status: {}",response.getTaskId(),response.getName(),response.getStatus());}//識別出一句話.服務端會智能斷句,當識別到一句話結束時會返回此消息@Overridepublic void onSentenceEnd(SpeechTranscriberResponse response) {LOGGER.info("name: {}, status: {}, index: {}, result: {}, confidence: {}, begin_time: {}, time: {}",response.getName(),response.getStatus(),response.getTransSentenceIndex(),response.getTransSentenceText(),response.getConfidence(),response.getSentenceBeginTime(),response.getTransSentenceTime());if (response.getName().equals(Constant.VALUE_NAME_ASR_SENTENCE_END)) {if (response.getStatus() == 20000000) {// 識別完一句話,調用大模型String answer = chatClient.chat(response.getTransSentenceText());voiceGenerateService.process(answer);WavPlayerUtil.playWavFile("/Users/zhoulongchao/Desktop/file_code/project/p_me/ai-voice-assistant/tts_test.wav");}}}//識別完畢@Overridepublic void onTranscriptionComplete(SpeechTranscriberResponse response) {LOGGER.info("task_id: {}, name: {}, status: {}",response.getTaskId(),response.getName(),response.getStatus());}@Overridepublic void onFail(SpeechTranscriberResponse response) {// 重要提示: task_id很重要,是調用方和服務端通信的唯一ID標識,當遇到問題時,需要提供此task_id以便排查LOGGER.info("語音識別 task_id: {}, status: {}, status_text: {}",response.getTaskId(),response.getStatus(),response.getStatusText());}};return listener;}public void process() {SpeechTranscriber transcriber = null;try {// 創建實例,建立連接transcriber = new SpeechTranscriber(client, getTranscriberListener());transcriber.setAppKey(voiceConfig.getAppKey());// 輸入音頻編碼方式transcriber.setFormat(InputFormatEnum.PCM);// 輸入音頻采樣率transcriber.setSampleRate(SampleRateEnum.SAMPLE_RATE_16K);// 是否返回中間識別結果transcriber.setEnableIntermediateResult(true);// 是否生成并返回標點符號transcriber.setEnablePunctuation(true);// 是否將返回結果規整化,比如將一百返回為100transcriber.setEnableITN(false);//此方法將以上參數設置序列化為json發送給服務端,并等待服務端確認transcriber.start();AudioFormat audioFormat = new AudioFormat(16000.0F, 16, 1, true, false);DataLine.Info info = new DataLine.Info(TargetDataLine.class, audioFormat);TargetDataLine targetDataLine = (TargetDataLine) AudioSystem.getLine(info);targetDataLine.open(audioFormat);targetDataLine.start();System.out.println("You can speak now!");int nByte = 0;final int bufSize = 3200;byte[] buffer = new byte[bufSize];while ((nByte = targetDataLine.read(buffer, 0, bufSize)) > 0) {// 直接發送麥克風數據流transcriber.send(buffer, nByte);}transcriber.stop();} catch (Exception e) {LOGGER.info("語音識別 error: {}", e.getMessage());// 臨時兼容,用于保持連接在邏輯上不斷開,否則默認10s不說話會自動斷連process();} finally {if (null != transcriber) {transcriber.close();}}}@PreDestroypublic void shutdown() {client.shutdown();}
}語音生成(技術:阿里云-語音生成)
開發參考_智能語音交互(ISI)-阿里云幫助中心
開發日志記錄——
- 非線程安全:在調用完阿里的語音生成能力后,得到了音頻文件,和播放打通的方法是建立一個臨時文件,生成和播放都路由到這個文件,因為這個項目只是個人方便分階段單元測試用可以這么寫,如果有多個客戶端,那么這種方式就不是線程安全的
- 回答延遲:這里我是使用的普通版的語音合成能力,初次接入支持免費體驗 3 個月,其實可以使用流式語音合成能力,是另一個 sdk,具體可見文檔:流式文本語音合成使用說明_智能語音交互(ISI)-阿里云幫助中心 因為目前流式語音合成能力需要付費,因此沒有接入流式,因此每次需要收集完 ds 大模型的回答流之后才可以進行語音生成,會有 8s 延遲
官網有 100 多種音色可以選:
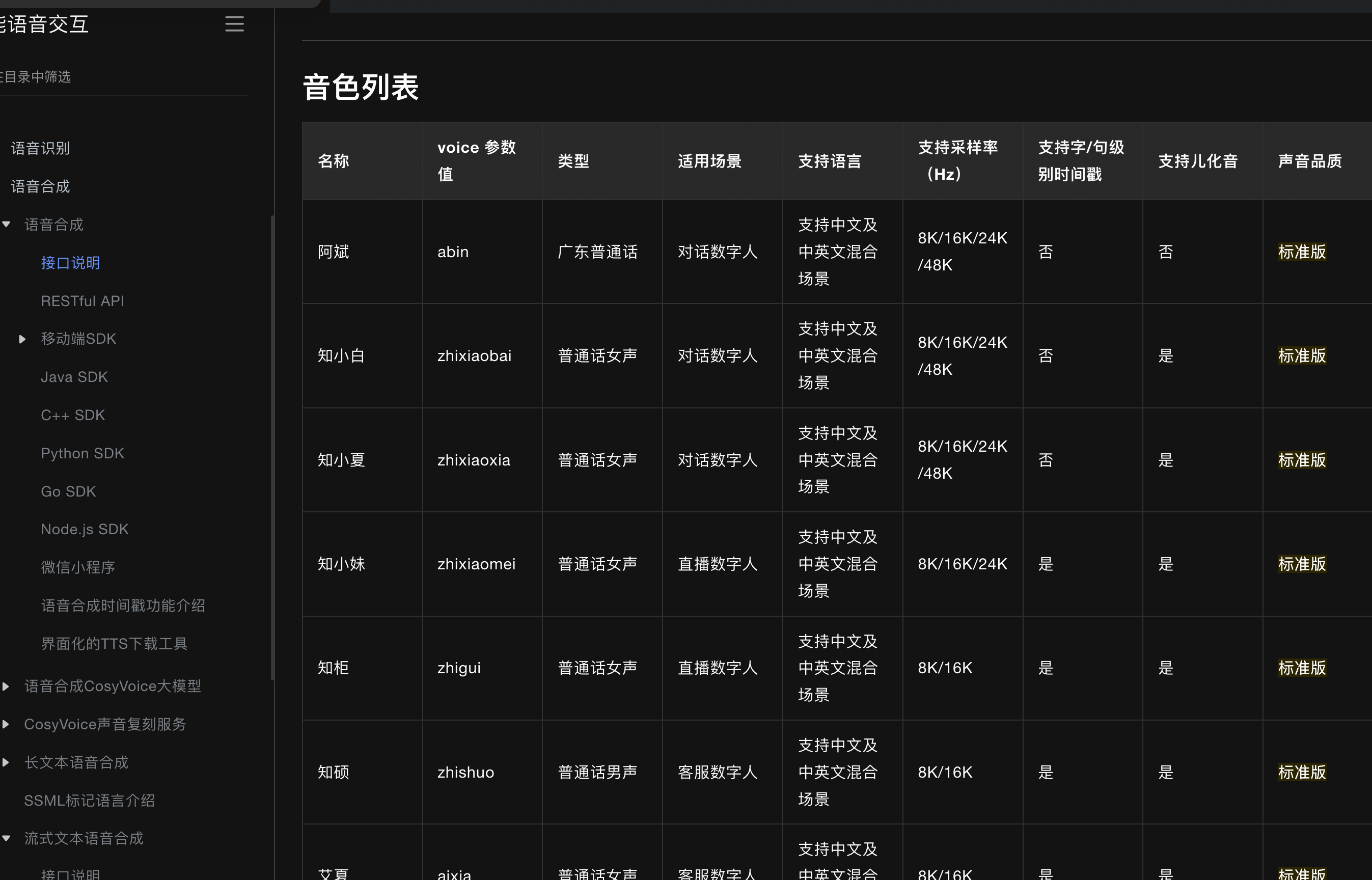
<dependency><groupId>com.alibaba.nls</groupId><artifactId>nls-sdk-tts</artifactId><version>${ali-vioce-sdk.version}</version>
</dependency>
<dependency><groupId>com.alibaba.nls</groupId><artifactId>nls-sdk-transcriber</artifactId><version>${ali-vioce-sdk.version}</version>
</dependency>package ai.voice.assistant.service.voice;import ai.voice.assistant.config.VoiceConfig;
import com.alibaba.nls.client.protocol.NlsClient;
import com.alibaba.nls.client.protocol.OutputFormatEnum;
import com.alibaba.nls.client.protocol.SampleRateEnum;
import com.alibaba.nls.client.protocol.tts.;
import com.alibaba.nls.client.protocol.tts.SpeechSynthesizerListener;
import com.alibaba.nls.client.protocol.tts.SpeechSynthesizerResponse;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.util.concurrent.ScheduledExecutorService;/*** @Author:超周到的程序員* @Date:2025/4/23* 語音合成API調用* 流式合成TTS* 首包延遲計算*/
@Service
public class VoiceGenerateService {private static final Logger LOGGER = LoggerFactory.getLogger(VoiceGenerateService.class);private static long startTime;@Autowiredprivate VoiceConfig voiceConfig;@Autowiredprivate NlsClient client;private static SpeechSynthesizerListener getSynthesizerListener() {SpeechSynthesizerListener listener = null;try {listener = new SpeechSynthesizerListener() {File f = new File("tts_test.wav");FileOutputStream fout = new FileOutputStream(f);private boolean firstRecvBinary = true;//語音合成結束@Overridepublic void onComplete(SpeechSynthesizerResponse response) {// TODO 當onComplete時表示所有TTS數據已經接收完成,因此這個是整個合成延遲,該延遲可能較大,未必滿足實時場景LOGGER.info("name:{} status:{} outputFile:{}", response.getStatus(), f.getAbsolutePath(), response.getName());}//語音合成的語音二進制數據@Overridepublic void onMessage(ByteBuffer message) {try {if (firstRecvBinary) {// TODO 此處是計算首包語音流的延遲,收到第一包語音流時,即可以進行語音播放,以提升響應速度(特別是實時交互場景下)firstRecvBinary = false;long now = System.currentTimeMillis();LOGGER.info("tts first latency : " + (now - VoiceGenerateService.startTime) + " ms");}byte[] bytesArray = new byte[message.remaining()];message.get(bytesArray, 0, bytesArray.length);fout.write(bytesArray);} catch (IOException e) {e.printStackTrace();}}@Overridepublic void onFail(SpeechSynthesizerResponse response) {// TODO 重要提示: task_id很重要,是調用方和服務端通信的唯一ID標識,當遇到問題時,需要提供此task_id以便排查LOGGER.info("語音合成 task_id: {}, status: {}, status_text: {}",response.getTaskId(),response.getStatus(),response.getStatusText());}@Overridepublic void onMetaInfo(SpeechSynthesizerResponse response) {
// System.out.println("MetaInfo event:{}" + response.getTaskId());}};} catch (Exception e) {e.printStackTrace();}return listener;}public void process(String text) {SpeechSynthesizer synthesizer = null;try {//創建實例,建立連接synthesizer = new SpeechSynthesizer(client, getSynthesizerListener());synthesizer.setAppKey(voiceConfig.getAppKey());//設置返回音頻的編碼格式synthesizer.setFormat(OutputFormatEnum.WAV);//設置返回音頻的采樣率synthesizer.setSampleRate(SampleRateEnum.SAMPLE_RATE_16K);//發音人synthesizer.setVoice("jielidou");//語調,范圍是-500~500,可選,默認是0synthesizer.setPitchRate(50);//語速,范圍是-500~500,默認是0synthesizer.setSpeechRate(30);//設置用于語音合成的文本synthesizer.setText(text);synthesizer.addCustomedParam("enable_subtitle", true);//此方法將以上參數設置序列化為json發送給服務端,并等待服務端確認long start = System.currentTimeMillis();synthesizer.start();LOGGER.info("tts start latency " + (System.currentTimeMillis() - start) + " ms");VoiceGenerateService.startTime = System.currentTimeMillis();//等待語音合成結束synthesizer.waitForComplete();LOGGER.info("tts stop latency " + (System.currentTimeMillis() - start) + " ms");} catch (Exception e) {e.printStackTrace();} finally {//關閉連接if (null != synthesizer) {synthesizer.close();}}}public void shutdown() {client.shutdown();}
}






)
)




)

)



