SpringAI實戰鏈接
1.SpringAl實現AI應用-快速搭建-CSDN博客
2.SpringAI實現AI應用-搭建知識庫-CSDN博客
3.SpringAI實現AI應用-內置顧問-CSDN博客
4.SpringAI實現AI應用-使用redis持久化聊天記憶-CSDN博客
5.SpringAI實現AI應用-自定義顧問(Advisor)-CSDN博客
概述
通過前兩篇帖子,對SpringAI的使用應該有了大致的了解,那么本篇就需要真正去看以下SpringAI里面真正的東西了
首先先看SpringAI官方文檔-Advisors
中文版:顧問 API :: Spring AI 參考 - Spring 框架
官方:Advisors API :: Spring AI Reference
通過文檔可以知道Spring AI 框架提供了幾個內置顧問,以增強?AI 交互。以下是可用顧問的概覽:
聊天記憶顧問
????????這些顧問在聊天記憶存儲中管理對話歷史:
????????MessageChatMemoryAdvisor
????????檢索記憶并將其作為消息集合添加到提示中。這種方法保持了對話歷史的結構。請注意,并非所有 AI 模型都支持這種方法。
????????PromptChatMemoryAdvisor
????????檢索記憶并將其并入提示的系統文本中。
????????VectorStoreChatMemoryAdvisor
????????從 VectorStore 中檢索記憶并將其添加到提示的系統文本中。這個顧問對于高效搜索和檢索大型數據集中的相關信息非常有用。
問題回答顧問
????????QuestionAnswerAdvisor
????????這個顧問使用向量存儲提供問題回答能力,實現了 RAG(檢索增強生成)模式。
內容安全顧問
????????SafeGuardAdvisor
????????一個簡單的顧問,旨在防止模型生成有害或不適當的內容。
聊天記憶實例
接下來繼續使用之前的代碼,逐個驗證這些內置顧問的功能和作用
ChatMemory
想要使用聊天記憶顧問之前,先看一下聊天記憶顧問里的源碼
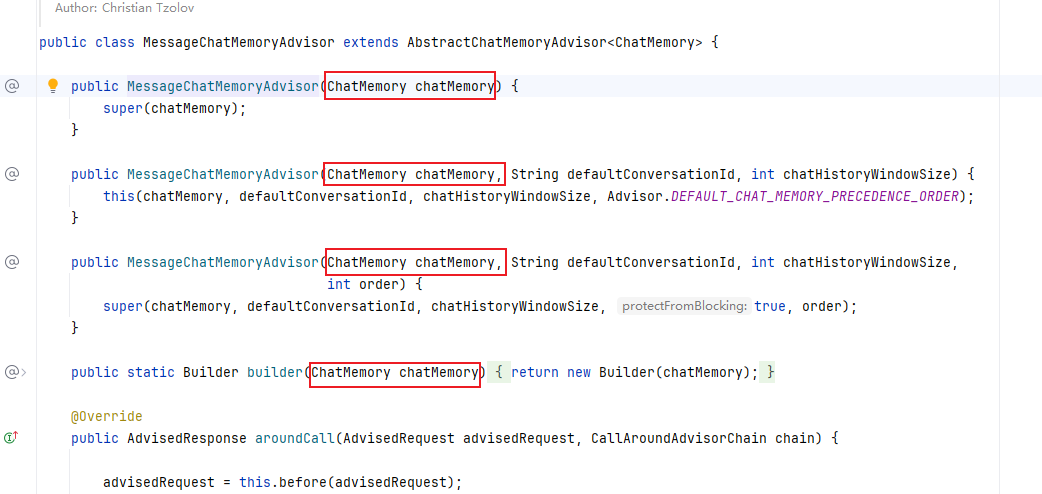
MessageChatMemoryAdvisor
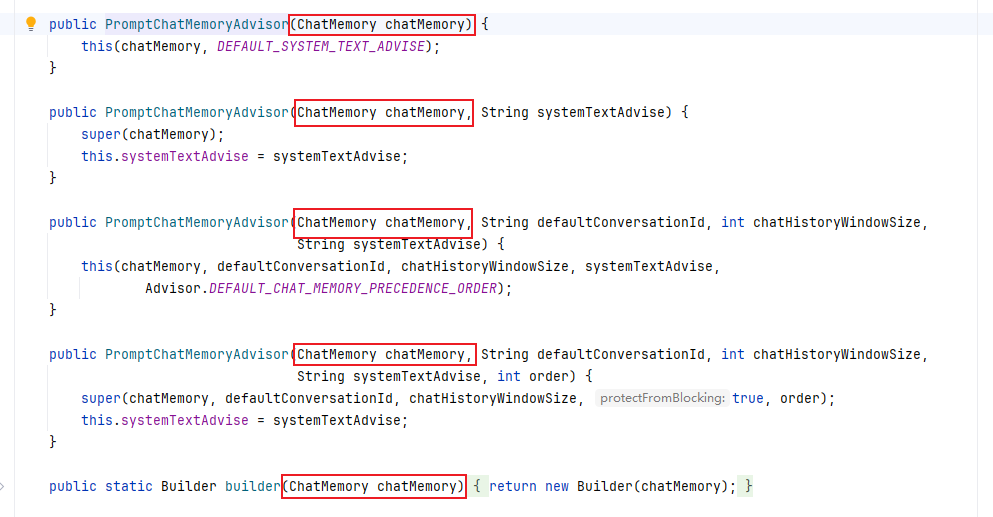
PromptChatMemoryAdvisor
VectorStoreChatMemoryAdvisor

從源碼中可以看到,兩個內置顧問的構造方法中都有ChatMemory,而VectorStoreChatMemoryAdvisor的構造方法入參的是向量庫,那就先看一下ChatMemory,它是一個內存管理容器,用于存儲和管理多輪對話中的ChatMessage。它不僅允許開發者保存消息,還提供了消息驅逐策略(Eviction Policy)、持久化存儲(Persistence)以及特殊消息處理(如SystemMessage和ToolExecutionMessage)等功能。此外,ChatMemory還與high-level組件(如AI服務)集成,便于開發者更方便地管理對話歷史。
先看一下ChatMemory里的方法
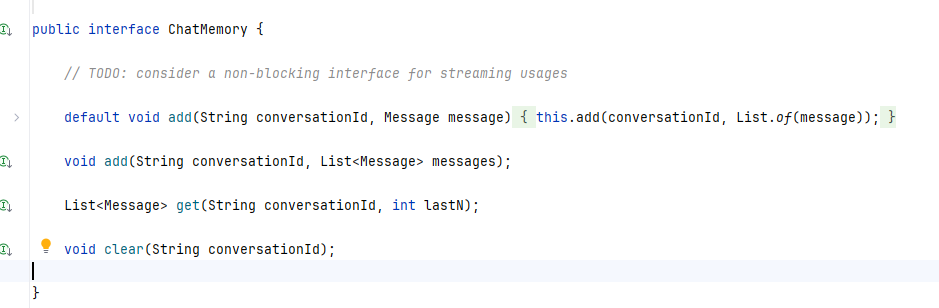
1.add(String conversationId, Message message):將單個消息添加到指定會話的對話中。
2.add(String conversationId, List<Message> messages):將消息列表添加到指定會話的對話中。
3.get(String conversationId, int lastN):從指定會話的對話中檢索最新的N條消息。
4.clear(String conversationId):清除指定會話的對話歷史記錄。
而ChatMemory的實現類是InMemoryChatMemory這個類再之前兩篇帖子的配置類中有實現。

InMemoryChatMemory是Spring AI框架提供的一種ChatMemory實現,它將對話歷史記錄存儲在內存中。這種實現方式具有快速訪問和檢索消息的優點,適用于快速原型開發和測試場景。由于內存是易失性存儲介質,因此InMemoryChatMemory不適用于需要長期保存聊天記錄的應用場景。
而其中的方法也為能持久化聊天記錄提供了幫助,
修改之前接口代碼中的call方法如下(簡單實現)
/*** 根據消息直接輸出回答* @param map* @return*/@PostMapping("/ai/call")public String call(@RequestBody Map<String,String> map) {String message = map.get("message");Message message1 = new UserMessage(message);String trim = chatClient.prompt().user(message).call().content().trim();Message message2 = new UserMessage(MessageType.SYSTEM, trim, new ArrayList<>(), Map.of());inMemoryChatMemory.add("123456",List.of(message1,message2));return trim;}然后再獲取聊天記錄進行(簡單實現)
/*** 查詢聊天記里* @return*/@GetMapping("/ai/chatMemory")public List<Message> chatMemory(){List<Message> messages = inMemoryChatMemory.get("123456", 10);for (Message message : messages) {System.out.println(message.getText());}return messages;}MessageChatMemoryAdvisor
了解完ChatMemory,那就開始看第一個內置顧問MessageChatMemoryAdvisor,這個也在之前的代碼中實現過,當時為了簡單實現多輪對話記憶,而且還是加在了方法上
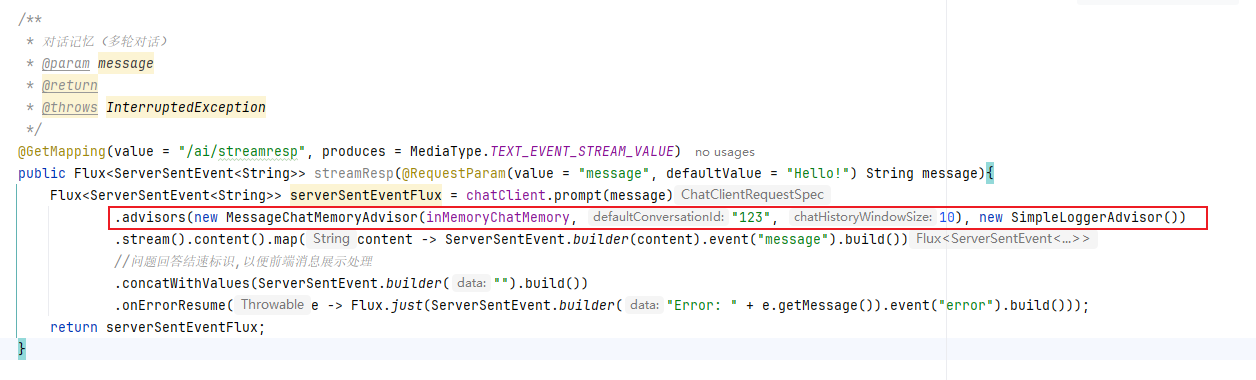
這篇帖子,我們將代碼加在配置類上,修改配置類如下,配置類中沒有配置會話id和儲存大小,是因為統一進行的配置,這種方式將chatClient注冊到spring容器的時候,還沒有辦法知道用戶的會話id,所以只能默認,儲存大小也使用默認,默認大小為100
@BeanChatClient chatClient(ChatClient.Builder builder) {return builder// 它定義了聊天機器人在回答問題時應當遵循的風格和角色定位。.defaultSystem("你是一個智能機器人,你的名字叫 Spring AI智能機器人").defaultAdvisors(new MessageChatMemoryAdvisor(inMemoryChatMemory())).build();}
此時所有的接口都實現了記憶對話的功能
測試

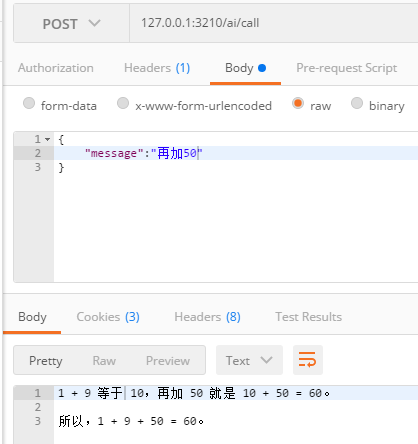
由此可見在全局都已經實現了對話記憶
PromptChatMemoryAdvisor
再來看PromptChatMemoryAdvisor,它和MessageChatMemoryAdvisor的類似,也是直接修改配置類,如下
@BeanChatClient chatClient(ChatClient.Builder builder) {return builder// 它定義了聊天機器人在回答問題時應當遵循的風格和角色定位。.defaultSystem("你是一個智能機器人,你的名字叫 Spring AI智能機器人").defaultAdvisors(
// new MessageChatMemoryAdvisor(inMemoryChatMemory())new PromptChatMemoryAdvisor(inMemoryChatMemory())).build();}
VectorStoreChatMemoryAdvisor
VectorStoreChatMemoryAdvisor 是 Spring AI 框架中的一個組件,它結合了向量存儲(VectorStore)技術來增強聊天機器人的記憶能力。這個 Advisor 利用向量數據庫存儲用戶與聊天機器人的交互歷史,包括用戶提出的問題和模型的回答。在生成新的回復時,VectorStoreChatMemoryAdvisor 會檢索與當前問題相關的歷史記錄,并將其作為上下文信息添加到提示中,從而幫助大型語言模型(LLM)生成更連貫和準確的回復。
具體實現需要將聊天記錄持久化到向量庫,下篇帖子再詳細說明聊天記錄持久化的問題
區別
看了SpringAI的官方文檔,網上也搜了一下這三個內置顧問,都說的太官方了,簡單說一下:
MessageChatMemoryAdvisor:將對話歷史以消息集合的形式存儲和傳遞。它維護了一個結構化的對話歷史記錄,通常將用戶消息和模型響應封裝為消息對象。適用于需要保持對話歷史結構的場景,例如需要明確區分用戶消息和系統消息。
PromptChatMemoryAdvisor:將對話歷史以純文本的形式合并到系統提示中。它將歷史消息轉換為一個字符串,并將其附加到系統提示的文本中。適用于需要將歷史信息作為上下文傳遞給模型的場景,尤其是當模型不支持消息集合時。
VectorStoreChatMemoryAdvisor:使用向量存儲技術將對話歷史存儲在向量數據庫中。它將對話記錄封裝為向量形式的文檔,并通過向量檢索來獲取相關的歷史信息。適用于需要高效檢索和處理大規模數據集的場景。
問題回答實例
QuestionAnswerAdvisor
這個顧問訪問的就是上篇帖子實現的向量庫,當用戶提出問題時,QuestionAnswerAdvisor會首先對知識庫進行檢索,并將匹配到的相關引用文本添加到用戶提問的后面,從而為生成的回答提供更為豐富和準確的上下文。此外,該Advisor還設定了一個默認提示詞,旨在確保回答的質量和相關性。如果在知識庫中無法找到匹配的文本,系統將可能拒絕回答用戶的問題。
實現如下:
@BeanChatClient chatClient(ChatClient.Builder builder,VectorStore vectorStore) {return builder// 它定義了聊天機器人在回答問題時應當遵循的風格和角色定位。.defaultSystem("你是一個智能機器人,你的名字叫 Spring AI智能機器人").defaultAdvisors(
// new MessageChatMemoryAdvisor(inMemoryChatMemory())new PromptChatMemoryAdvisor(inMemoryChatMemory()),QuestionAnswerAdvisor.builder(vectorStore).order(1).build()).build();}
測試
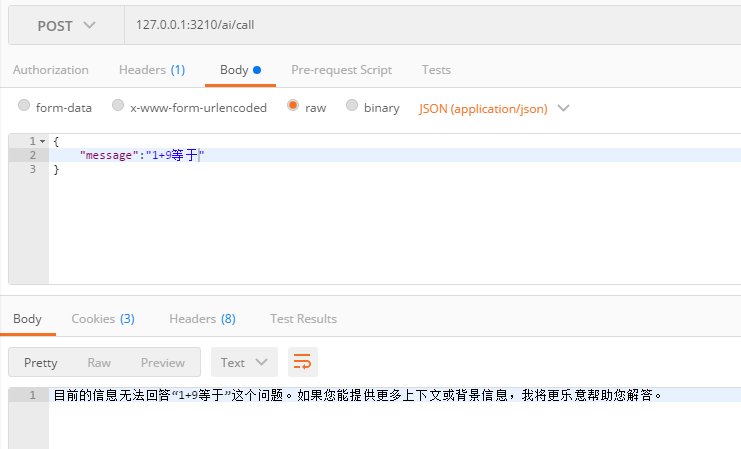

經過測試可以看到,只有問向量庫中的內容,才會進行回答
內容安全實例
SafeGuardAdvisor
這個顧問顧名思義就是過濾敏感詞匯的,具體實現如下
@BeanChatClient chatClient(ChatClient.Builder builder,VectorStore vectorStore) {return builder// 它定義了聊天機器人在回答問題時應當遵循的風格和角色定位。.defaultSystem("你是一個智能機器人,你的名字叫 Spring AI智能機器人").defaultAdvisors(
// new MessageChatMemoryAdvisor(inMemoryChatMemory())new PromptChatMemoryAdvisor(inMemoryChatMemory()),QuestionAnswerAdvisor.builder(vectorStore).order(1).build(),SafeGuardAdvisor.builder().sensitiveWords(List.of("色情", "暴力")) // 敏感詞列表.order(2) // 設置優先級.failureResponse("抱歉,我無法回答這個問題。").build() // 敏感詞過濾失敗時的響應).build();}
測試
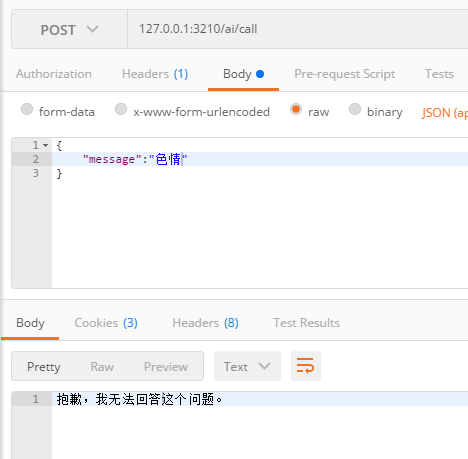
經過測試,安全顧問已經把敏感詞進行了過濾
完整代碼
AiConfig(配置文件)
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.*;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.InMemoryChatMemory;
import org.springframework.ai.chat.prompt.ChatOptions;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.List;/*** @Author majinzhong* @Date 2025/4/28 10:34* @Version 1.0*/
@Configuration
public class AiConfig {@BeanChatClient chatClient(ChatClient.Builder builder,VectorStore vectorStore) {return builder// 它定義了聊天機器人在回答問題時應當遵循的風格和角色定位。.defaultSystem("你是一個智能機器人,你的名字叫 Spring AI智能機器人")//這里可以添加多個顧問 order(優先級)越小,越先執行// 注意:顧問添加到鏈中的順序至關重要,因為它決定了其執行的順序。每個顧問都會以某種方式修改提示或上下文,一個顧問所做的更改會傳遞給鏈中的下一個顧問。// 在此配置中,將首先執行MessageChatMemoryAdvisor,將對話歷史記錄添加到提示中。然后,問答顧問將根據用戶的問題和添加的對話歷史進行搜索,從而可能提供更相關的結果。.defaultAdvisors(//內存存儲對話記憶
// new MessageChatMemoryAdvisor(inMemoryChatMemory()),new PromptChatMemoryAdvisor(inMemoryChatMemory()),// QuestionAnswerAdvisor 此顧問使用矢量存儲提供問答功能,實現RAG(檢索增強生成)模式QuestionAnswerAdvisor.builder(vectorStore).order(1).build(),// SafeGuardAdvisor是一個安全防護顧問,它確保生成的內容符合道德和法律標準。SafeGuardAdvisor.builder().sensitiveWords(List.of("色情", "暴力")) // 敏感詞列表.order(2) // 設置優先級.failureResponse("抱歉,我無法回答這個問題。").build(), // 敏感詞過濾失敗時的響應// SimpleLoggerAdvisor是一個記錄ChatClient的請求和響應數據的顧問。這對于調試和監控您的AI交互非常有用,建議將其添加到鏈的末尾。new SimpleLoggerAdvisor()).defaultOptions(ChatOptions.builder().topP(0.7) // 取值越大,生成的隨機性越高;取值越低,生成的隨機性越低。默認值為0.8.build()).build();}@BeanChatMemory inMemoryChatMemory() {return new InMemoryChatMemory();}
}
AdvisorController(測試接口)
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.memory.InMemoryChatMemory;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.MessageType;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.web.bind.annotation.*;import java.util.ArrayList;
import java.util.List;
import java.util.Map;import static org.springframework.ai.chat.client.advisor.AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY;
import static org.springframework.ai.chat.client.advisor.AbstractChatMemoryAdvisor.CHAT_MEMORY_RETRIEVE_SIZE_KEY;/*** @Author majinzhong* @Date 2025/5/6 14:22* @Version 1.0*/
@CrossOrigin
@RestController
public class AdvisorController {// 負責處理OpenAI的bean,所需參數來自properties文件private final ChatClient chatClient;//對話記憶private final InMemoryChatMemory inMemoryChatMemory;public AdvisorController(ChatClient chatClient,InMemoryChatMemory inMemoryChatMemory) {this.chatClient = chatClient;this.inMemoryChatMemory = inMemoryChatMemory;}/*** 普通聊天* @param message* @param sessionId* @return*/@GetMapping("/ai/generateCall")public String generateCall(@RequestParam(value = "message", defaultValue = "講個笑話") String message, @RequestParam String sessionId) {return chatClient.prompt().user(message).advisors(advisorSpec -> advisorSpec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, sessionId).param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10)).call().content().trim();}/*** 根據消息直接輸出回答* @param map* @return*/@PostMapping("/ai/callAdvisor")public String call(@RequestBody Map<String,String> map) {String message = map.get("message");Message message1 = new UserMessage(message);String trim = chatClient.prompt().user(message).call().content().trim();Message message2 = new UserMessage(MessageType.SYSTEM, trim, new ArrayList<>(), Map.of());inMemoryChatMemory.add("123456",List.of(message1,message2));return trim;}/*** 查詢聊天記里* @return*/@GetMapping("/ai/chatMemory")public List<Message> chatMemory(){List<Message> messages = inMemoryChatMemory.get("123456", 10);for (Message message : messages) {System.out.println(message.getText());}return messages;}
}代碼中的這個方法設置了記憶對話的對話id和存儲的大小
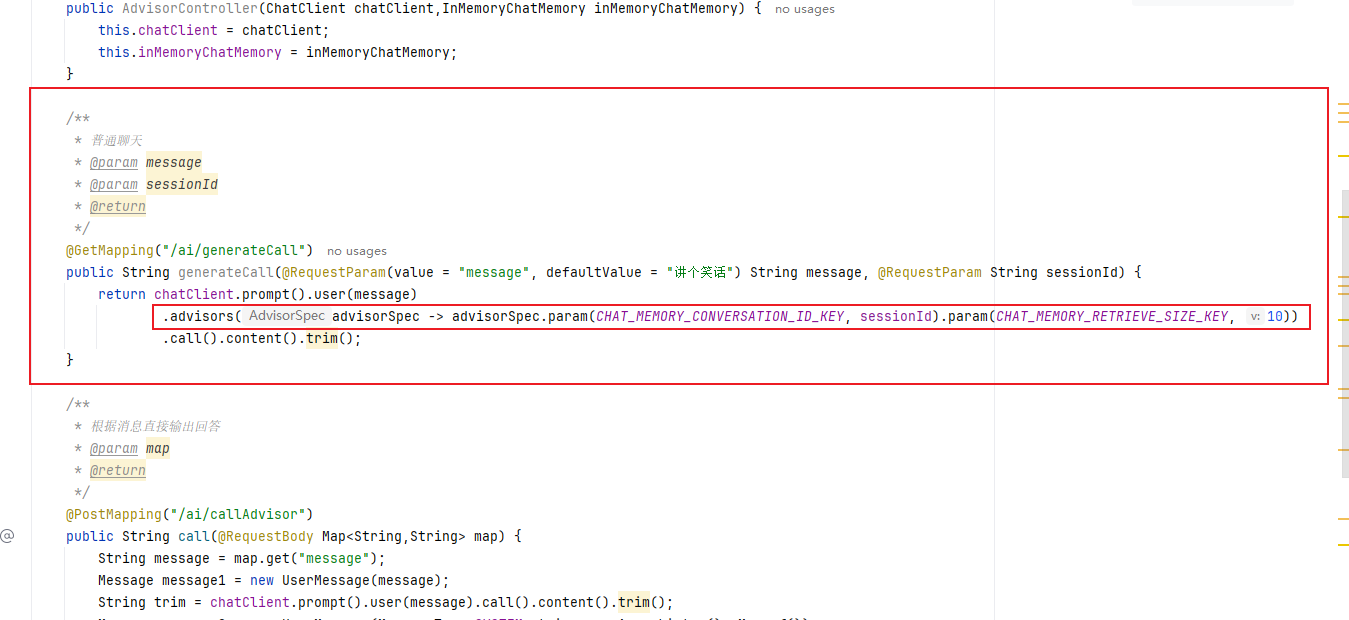
)
)





![[dify]官方模板DeepResearch工作流學習筆記](http://pic.xiahunao.cn/[dify]官方模板DeepResearch工作流學習筆記)
)



![[20250507] AI邊緣計算開發板行業調研報告 ??(2024年最新版)?](http://pic.xiahunao.cn/[20250507] AI邊緣計算開發板行業調研報告 ??(2024年最新版)?)


)



