簡介

FantasyTalking 的核心目標是從單一靜態圖像、音頻(以及可選的文本提示)生成高保真、連貫一致的說話肖像。研究表明,現有方法在生成可動畫化頭像時面臨多重挑戰,包括難以捕捉細微的面部表情、整體身體動作以及動態背景的協調性。該項目旨在解決這些問題,通過先進的 AI 技術實現更高質量的生成。
挑戰與動機
現有方法往往在面部表情的細膩度和身體動作的自然性上表現不佳,尤其是在動態背景的整合上。
FantasyTalking 的動機是提供一個統一的框架,能夠生成不僅限于唇部動作的動態肖像,包括表情和身體動作的控制。
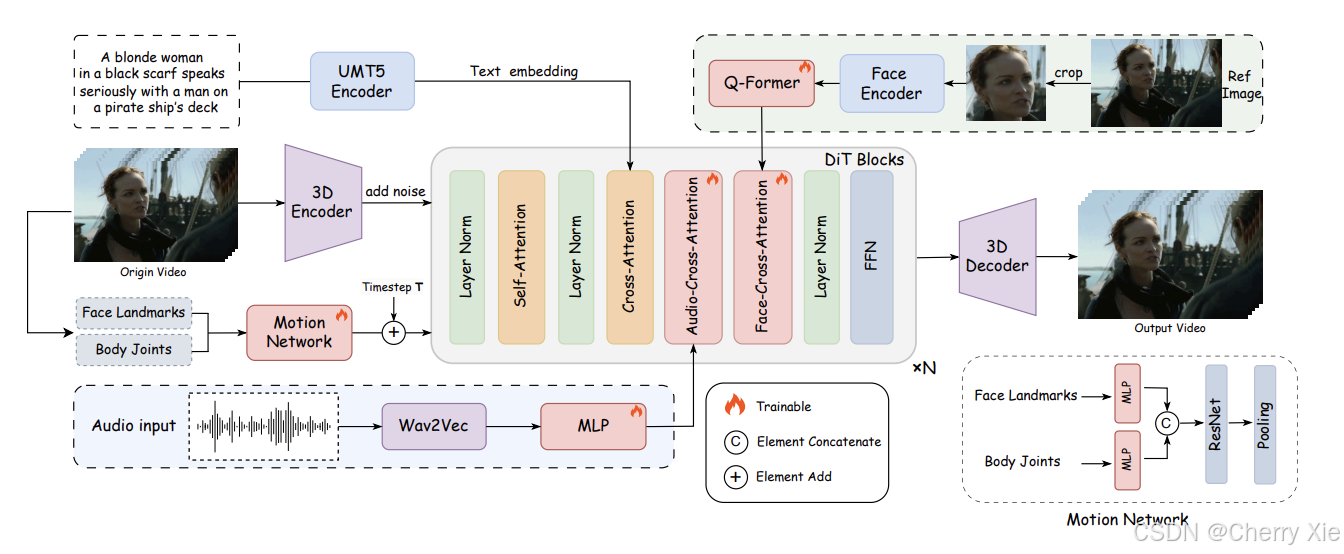
模型架構

FantasyTalking 的技術結構基于先進的機器學習模型和算法,具體包括以下核心組件:
核心模型
基于預訓練的視頻擴散變換器模型 Wan2.1-I2V-14B-720P,用于生成高保真的視頻內容。
音頻編碼器使用 Wav2Vec2-base-960h 處理音頻輸入,確保音頻與視頻的同步性。
音視頻對齊策略
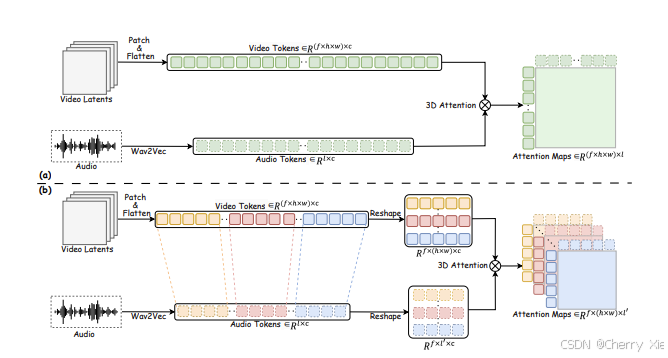
-
雙階段訓練
- 第一階段(片段級):通過對整個場景(包括頭像、背景對象和背景)進行音頻驅動的動態對齊,實現全局動作的連貫性。
- 第二階段(幀級):使用唇形追蹤掩碼(lip-tracing mask)精細調整唇部動作,以確保與音頻信號的精確同步。
-
這一策略確保了生成視頻的整體流暢性和音頻-視頻的精確匹配。
身份保留:
-
采用面部專注的交叉注意力模塊(facial-focused cross-attention module),替代傳統的參考網絡。
-
這一模塊在保持面部一致性的同時,不限制動作的靈活性,避免了身份信息丟失的問題。
動作控制
-
集成了動作強度調制模塊(motion intensity modulation module),允許用戶顯式控制面部表情和身體動作的強度。
-
這一模塊支持生成更動態的肖像,例如通過調整參數可以控制手勢、頭部轉動等動作。
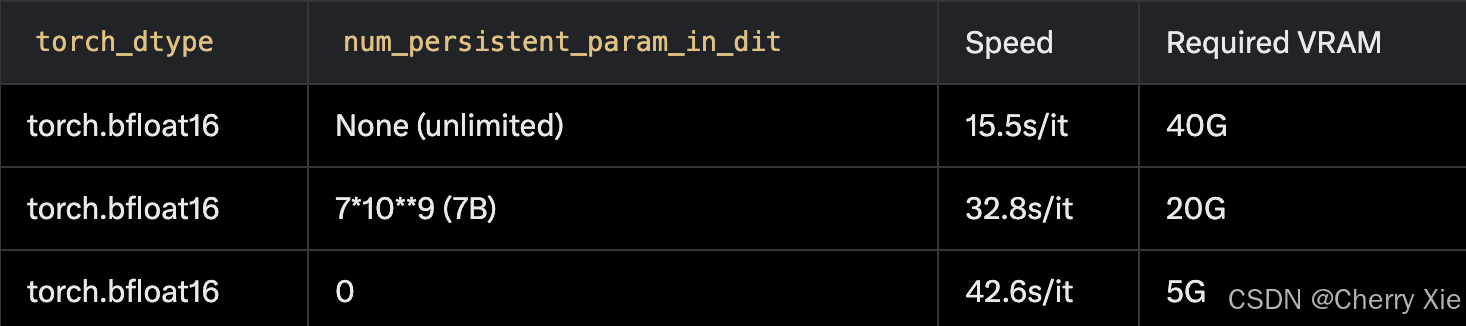
性能
在單個 A100 GPU 上(512x512 分辨率,81 幀):
-
使用 torch.bfloat16 時,速度為 15.5s/幀,VRAM 占用 40G。
-
通過限制持久參數數量,可以降低 VRAM 占用至 5G,但速度降低至 42.6s/幀。
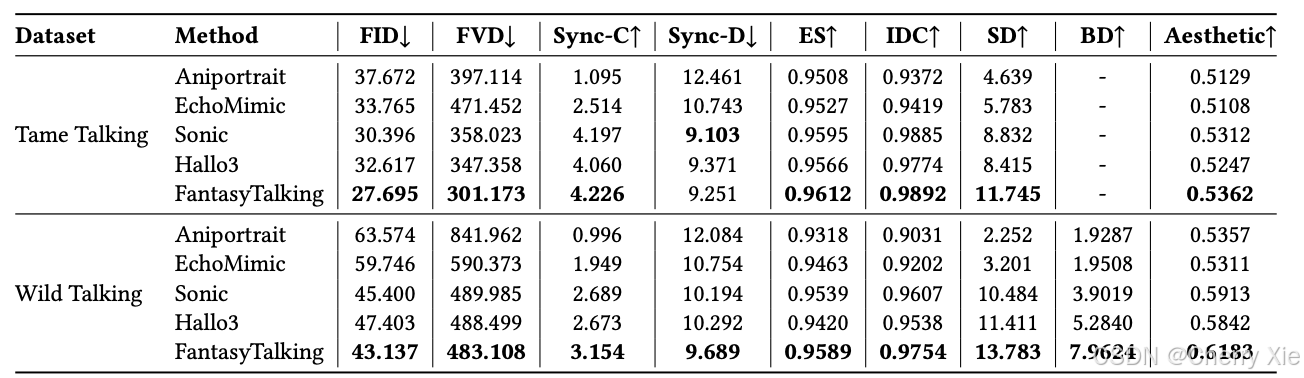
以下是性能對比表:
性能對比

看看效果
相關文獻
github項目地址:https://github.com/Fantasy-AMAP/fantasy-talking
官方地址:https://fantasy-amap.github.io/fantasy-talking/
在線體驗地址:https://huggingface.co/spaces/acvlab/FantasyTalking
技術報告:https://arxiv.org/pdf/2504.04842




![[數據處理] 3. 數據集讀取](http://pic.xiahunao.cn/[數據處理] 3. 數據集讀取)


文本到圖像的生成和編輯:綜述)

——從 Image-Text Pair 到 Instruction-Following 格式)









