1.?注意力認知和應用
????????AM: Attention Mechanism,注意力機制。
????????根據眼球注視的方向,采集顯著特征部位數據:

????????注意力示意圖:
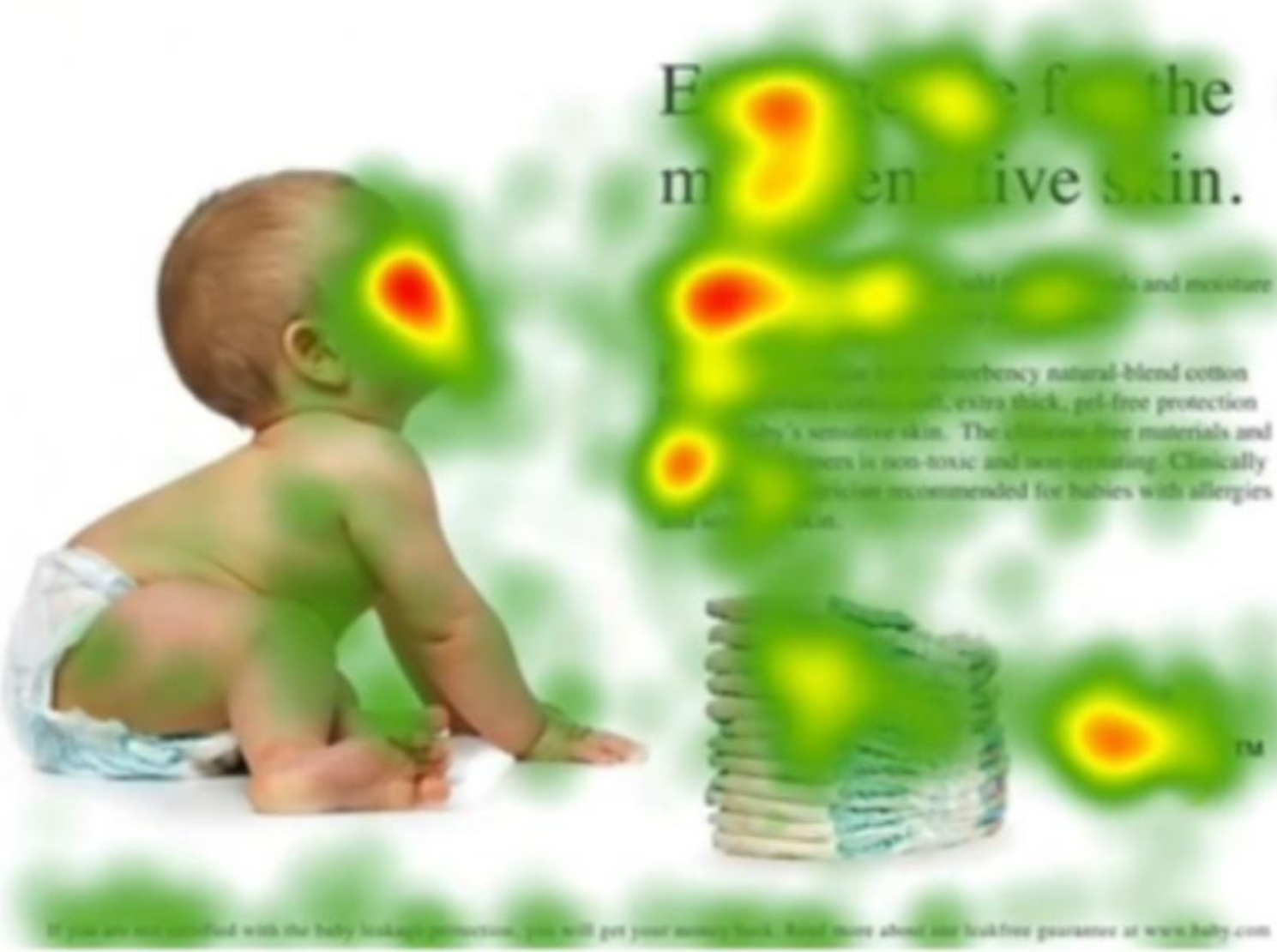
????????注意力機制是一種讓模型根據任務需求動態地關注輸入數據中重要部分的機制。通過注意力機制,模型可以做到對圖像中不同區域、句子中的不同部分給予不同的權重,從而增強感興趣特征,并抑制不感興趣區域。
????????注意力機制最初應用于機器翻譯(如Transformer),后逐漸被廣泛應用于各類任務,包括:
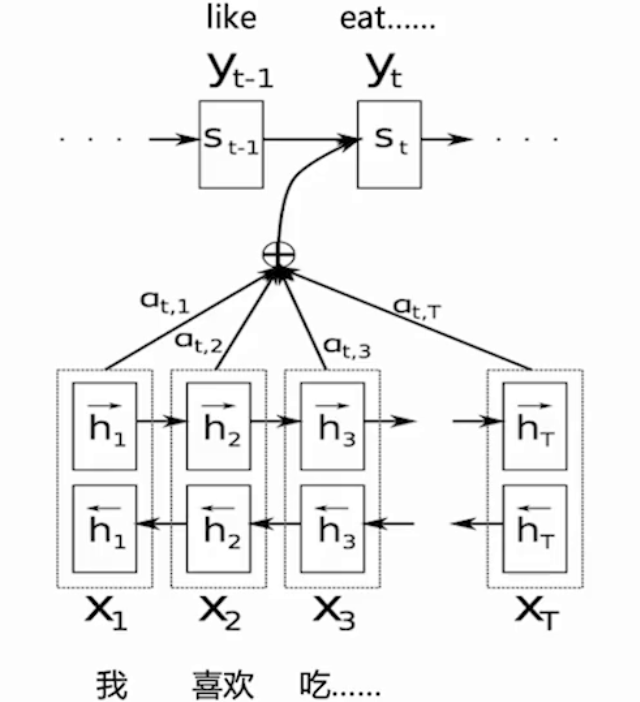
? ? ? ? 1.?NLP:如機器翻譯、文本生成、摘要、問答系統等。
|
|
|
|---|---|
| 機器翻譯 | 關鍵詞提取,摘要生成:輸入句和參考摘要之間的重疊關鍵詞(紅色)涵蓋了輸入句的重要信息,可根據這些關鍵字生成摘要 |

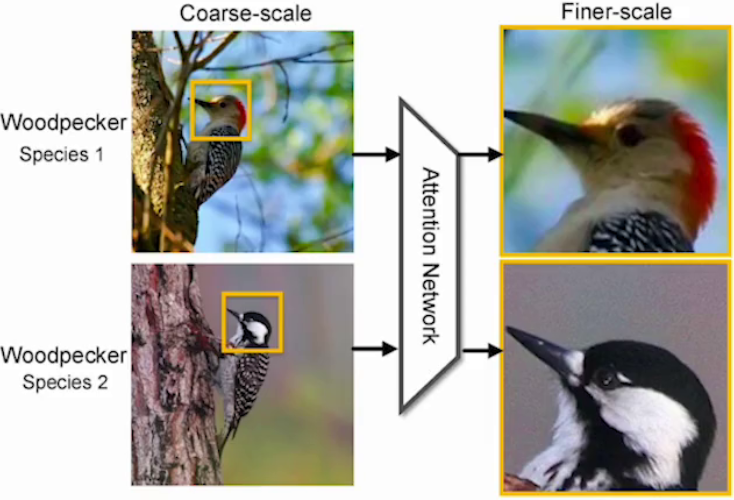
? ? ? ? 2. 計算機視覺:如圖像分類(細粒度識別)、目標檢測(顯著目標檢測)、圖像分割(圖像修復)等。
|
|
|
| 細粒度識別 | 圖像修復:監控攝像頭去除雨線、雨滴等 |
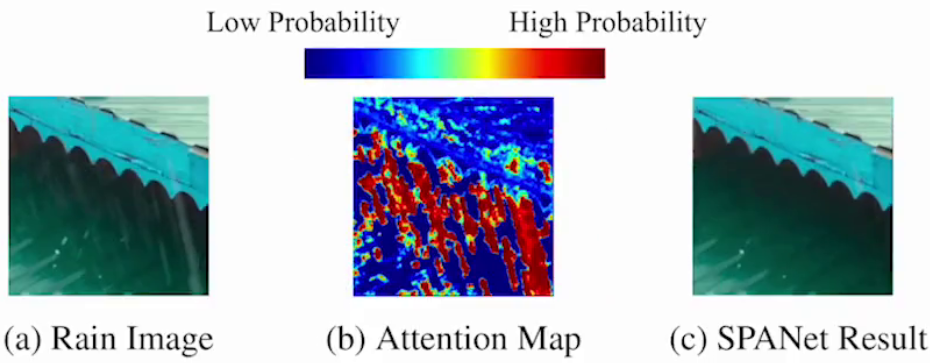
? ? ? ? 3.?跨模態任務:如圖文生成、視頻描述等。
????????這里我們學習下視覺處理中常見的典型注意力機制,如特征注意力、空間注意力以及混合注意力。
2.?通道注意力
????????對不同的特征通道進行增強或抑制,也就是賦予不同的權重參數。96個卷積核卷之后會得到不同的96個特征圖譜:邊緣、形狀、顏色等,不同的通道關注不同的特征

2.1?SENet
????????Squeeze-and-Excitation Networks:擠壓 - 和 - 激活、激發。
????????SENet模型論文: https://arxiv.org/pdf/1709.01507
2.1.1?基本認知
????????Filter SENet采用具有全局感受野的池化操作進行特征壓縮,并使用全連接層學習不同特征圖的權重,模型流程圖如下:
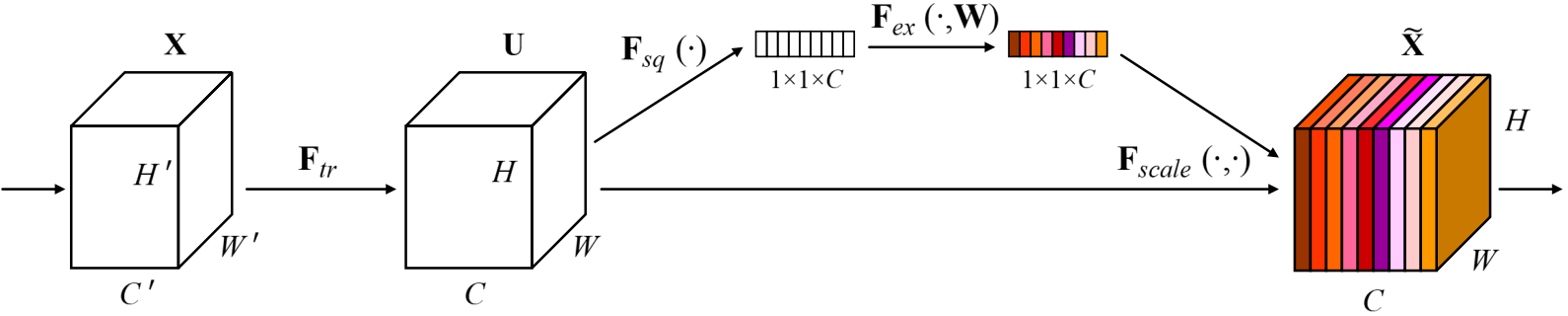
2.1.2?流程詳解
? ? ? ? 1.?Squeeze階段:該階段通過全局平均池化完成全局信息提取,公式如下:
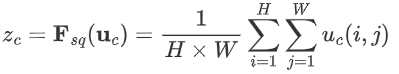
????????示意圖如下:

# Squeeze:壓縮、降維、擠壓
self.sq = nn.AdaptiveAvgPool2d(1)? ? ? ? 2.?Excitation階段:Squeeze的輸出作為Excitation階段的輸入,經過兩個全連接層,動態地為每個通道生成權重,公式如下:
![]()
????????示意圖如下:
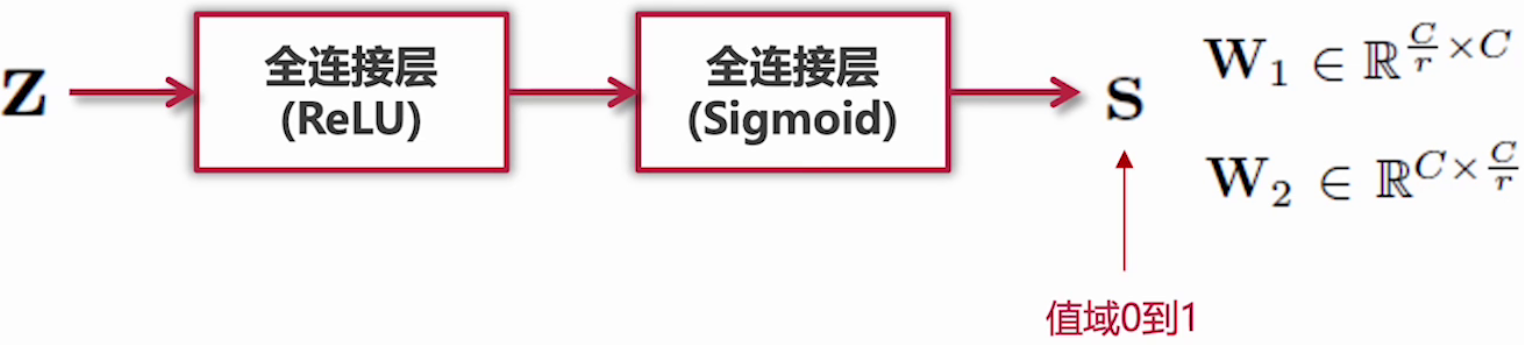
????????全連接層加入激活函數,用于引入非線性變化:
-
第一個全連接層(ReLU),將通道數從C降維為C/r。
-
r 是縮放因子,Ratio,比例的意思,用以減少運算量和防止過擬合。
-
通過第二個全連接層(si4)將維度恢復為C,輸出一個1 \times 1 \times C的權重向量。
-
權重歸一化:使用sigmoid確保權重在0~1之間。
-
該向量代表每個通道的重要性,也就是注意力的權重。
# Excitation:激活
self.ex = nn.Sequential(nn.Linear(inplanes, inplanes // r),nn.ReLU(),nn.Linear(inplanes // r, inplanes),nn.Sigmoid(),
)? ? ? ? 3.?輸出階段:特征和 Excitation階段產出的
進行相乘操作,用于對不同的通道添加權重:
![]()

def forward(self, x):# 緩存xintifi = xx = self.sq(x)x = x.view(x.size(0), -1)x = self.ex(x).unsqueeze(2).unsqueeze(3)return intifi * x2.1.3?融入模型
????????作為一種即插即用模塊,可以添加到任意的層后,只要保證輸出通道不變即可,如把SE融入到ResNet模型,如下:
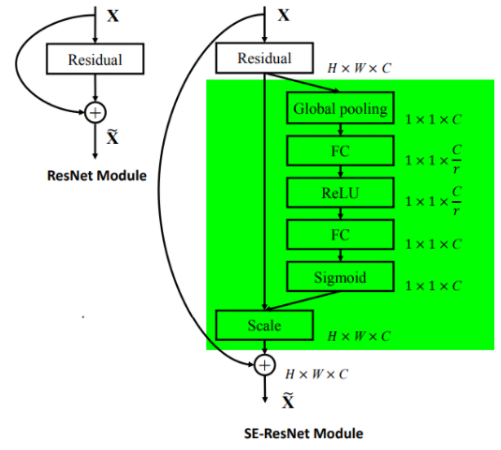
????????給ResNet-50加入SE注意力:
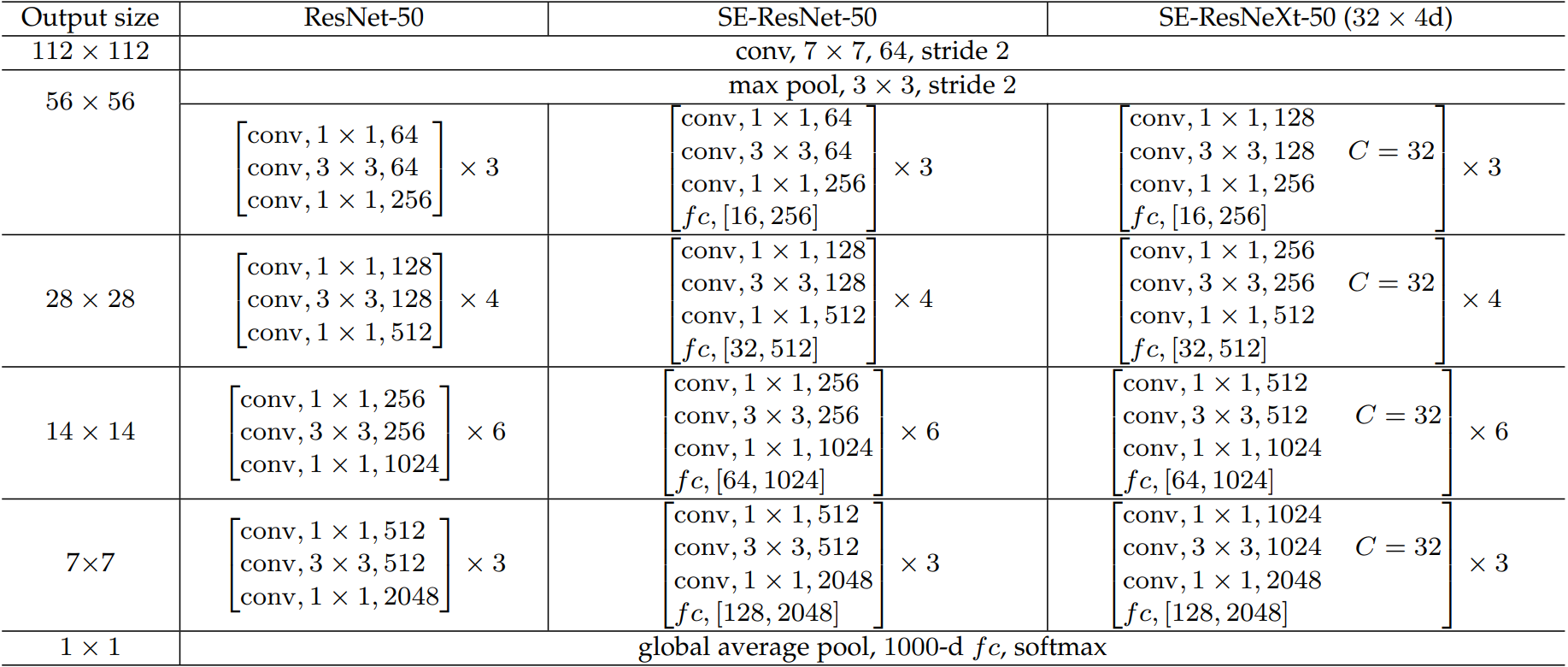
????????注解:表格中的 fc 后面的值,如 (16, 256) 或 (32, 512),表示在SE模塊中的兩個全連接層的維度變化。
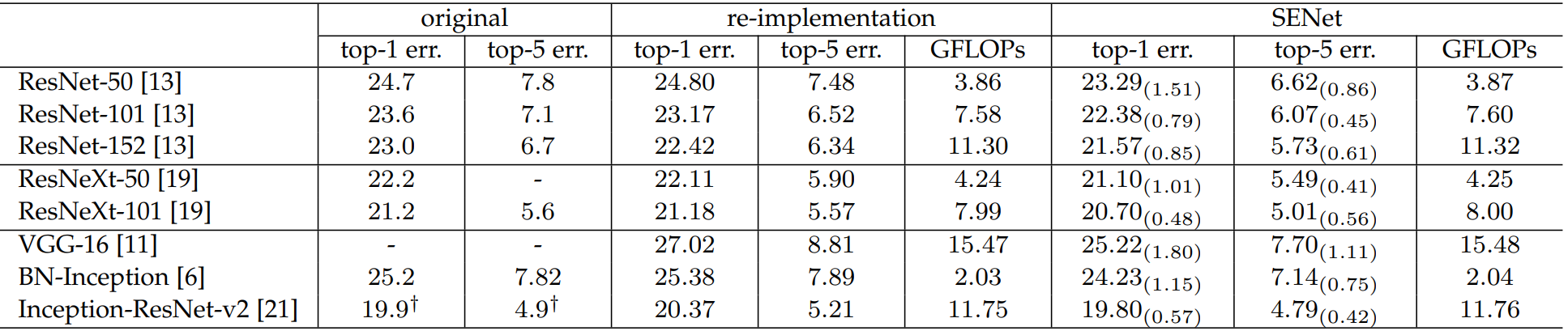
2.1.4?性能對比
????????加入SE后的性能對比表:re-implementation是SE作者復現效果
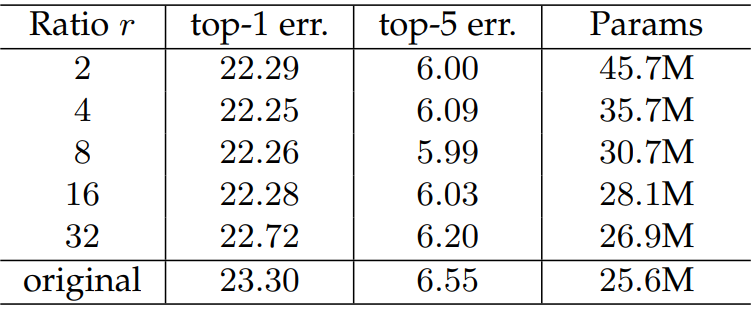
2.1.5?縮放因子
????????太小參數量大,容易過擬合。太大的話特征丟失嚴重,整體看8或16是比較不錯的選擇,具體的還是根據業務來定。
2.1.6?有無Squeeze
????????我們可以考慮不要Squeeze做平均池化,直接在Excitation階段進行卷積操作。從下標看的出來,這個Squeeze階段還是很有必要的。

2.1.7?池化方式
????????我們也可以考慮采用最大池化,不過效果不如平均池化。因為對注意力來講更多的是維持原始信息,而不是強化特征。

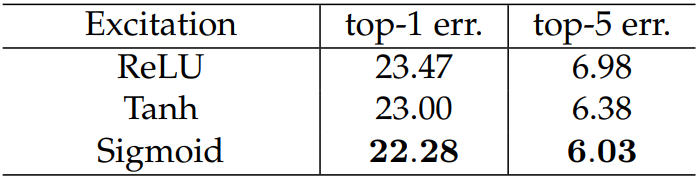
2.1.8?激活函數
????????這里是針對第二個全連接層,我們想要的是一個概率向量,無疑返回值在(0 ~ 1)之間的Sigmoid是最好的選擇。
2.1.9?網絡位置?
????????SE模塊靈活度較高,如下:
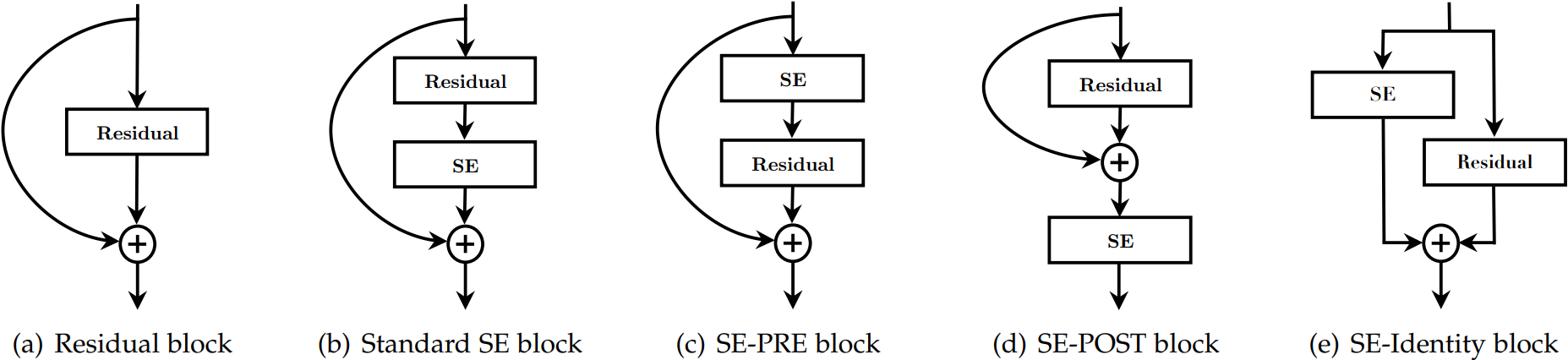
????????性能對比如下:POST模式最差
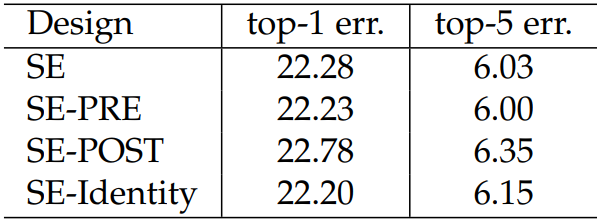
2.1.10?不同階段添加
????????比如ResNet是分很多個階段的,不同的階段添加SE模塊效果是不一樣的。
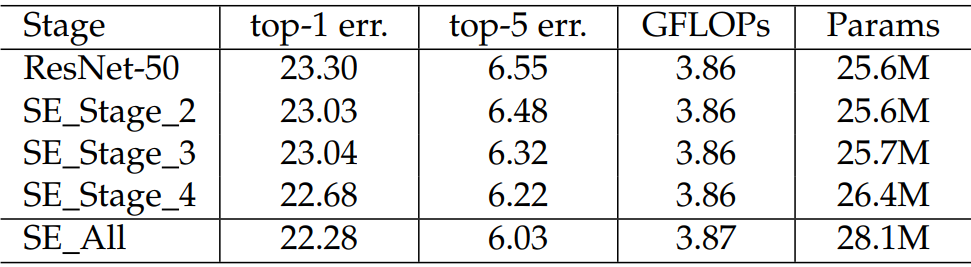
????????看的出來,越靠后的位置效果越好,因為越靠后特征學習的越好,此時加入效果就越好。當然全加SE的效果最好,不過參數量也不小。
2.2?SKNet
????????Selective Kernel Networks:可選擇的 ?卷積核尺寸
????????目的:bSKNet中的神經元可以捕獲不同尺度的目標物體,這驗證了神經元根據輸入自適應調整其感受野大小的能力。
????????SKNet論文地址:https://arxiv.org/pdf/1903.06586
2.2.1?基本認知
????????SK是對SE的改進版,可以動態調整感受野大小,分為Split-Fuse-Select共3個階段,模型流程圖如下:
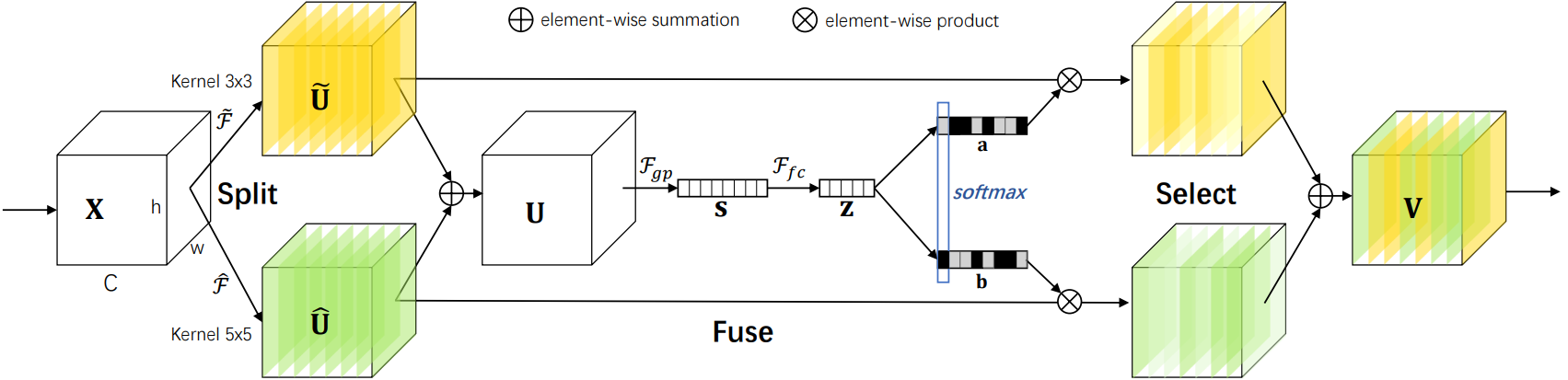
2.2.2?Split階段
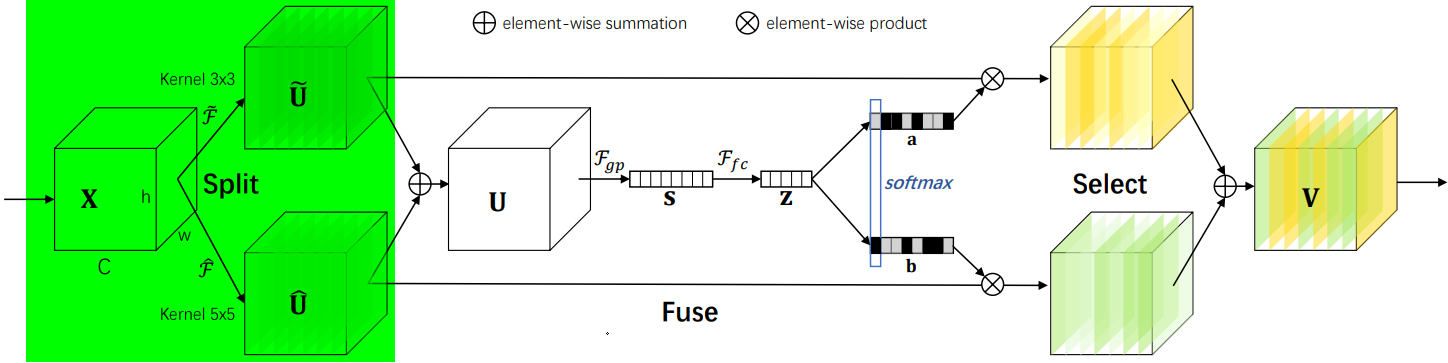
????????- 在Split階段會分出多個分支,每個分支實現不同大小的感受野,從而捕獲不同的特征。
????????- 為提高效率,傳統的5×5卷積被替換為帶有3×3卷積核和膨脹大小為2的膨脹卷積。
????????- 具體公式如下:
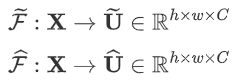
2.2.3?Fuse階段
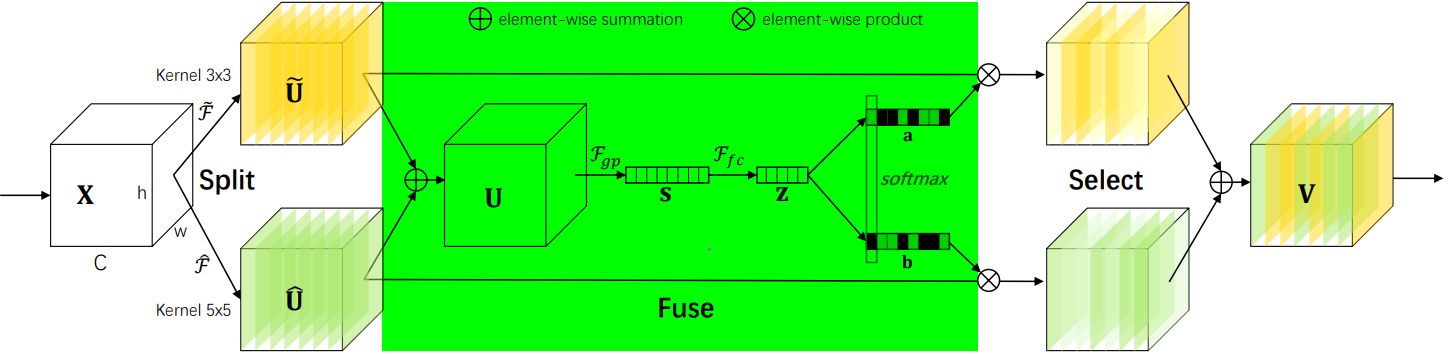
????????該階段會整合分支信息,具體步驟如下:
? ? ? ? 1.?通過element-wise summation得到 U:
? ? ? ? 2.?通過global average pooling得到特征s:就是一個平均池化操作。
? ? ? ? 3.?通過FC全連接層得到:
,其中
是batch normalization,
是ReLU,
。注意這里通過reduction ratio r 和閾值 L 兩個參數控制 z 的輸出通道 d:
,L?默認值為32。
? ? ? ? 4.?通過兩個不同的FC層(即矩陣A、B)分別得到 a 和 b,這里將通道從 d 又映射回原始通道數 C。
? ? ? ? 5.?對 a,b 對應通道 c 處的值進行 softmax 處理。
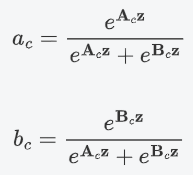
????????在公式中,,
和
分別代表不同(3×3、5×5)的卷積核經過全局池化(
)和全連接層(
)后得到的特征。a,b分別表示
和
的注意力系數。
2.2.4?Select階段
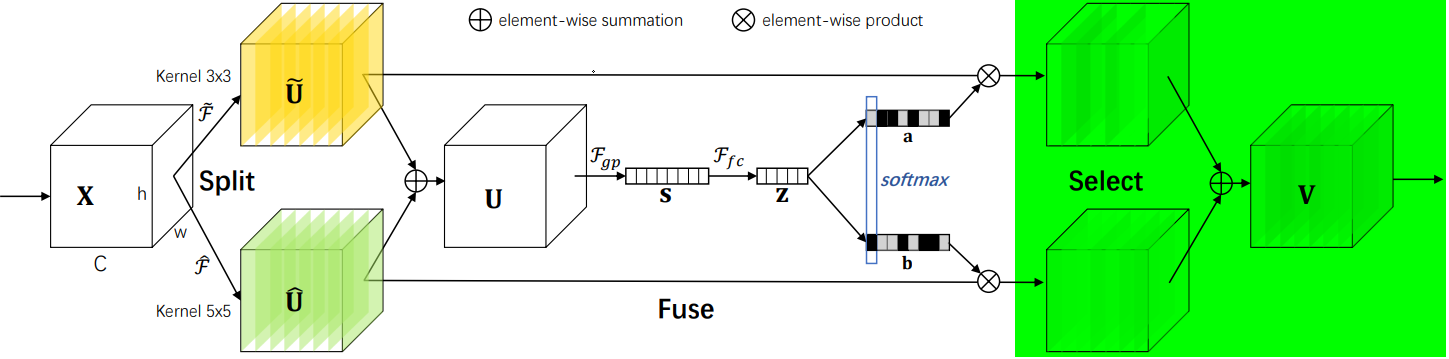
????????具體步驟如下:
? ? ? ? 1. 和
分別與 sofmax 處理后的 a,b 相乘,再相加,得到最終輸出的 V 和原始輸入 X 的維度一致。
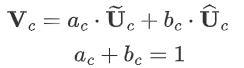
????????其中
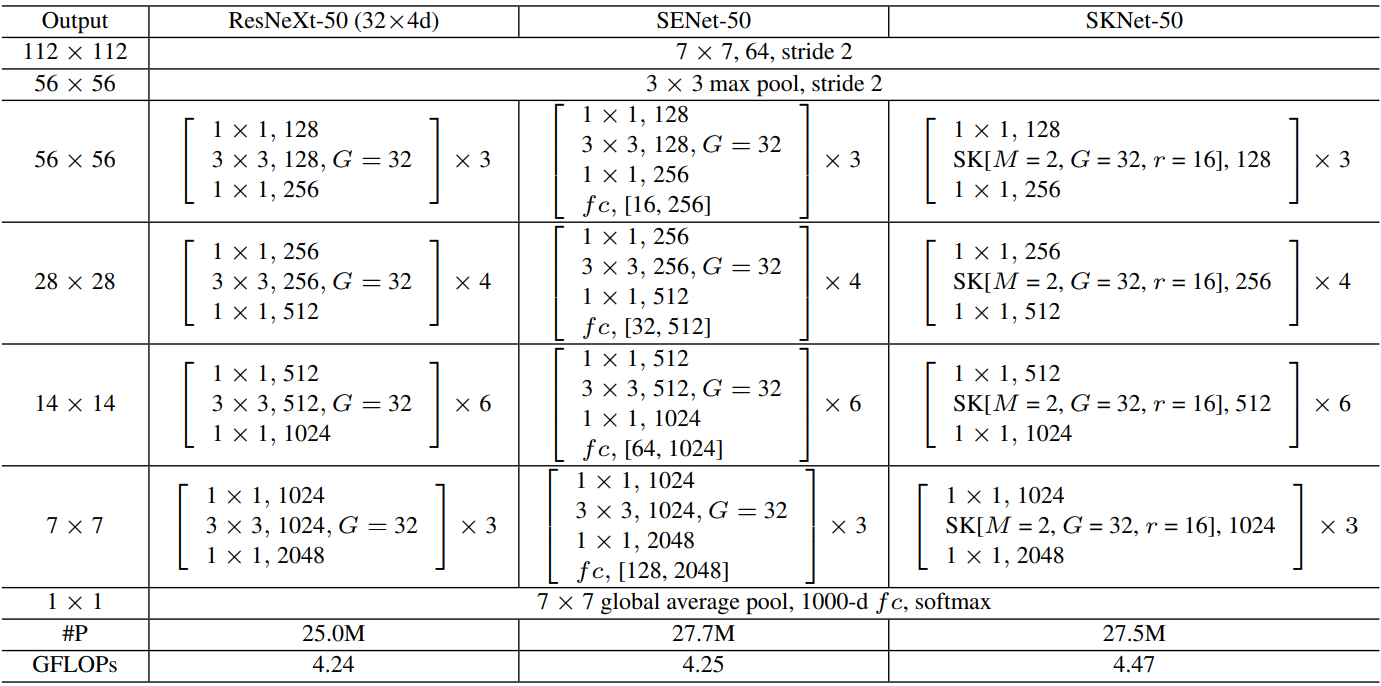
2.2.5?融入模型
????????ResNeXt加入SE和SK:
2.2.6?注意力權重分析
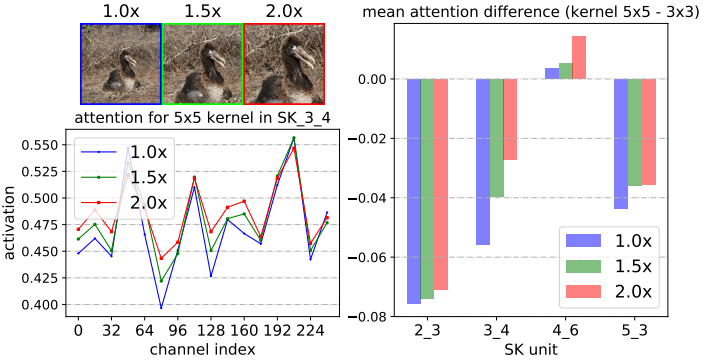
????????圖標注解:
-
通過中心裁剪和隨后的調整大小,逐步將中心對象從1.0× 擴大到2.0×
-
SK_X_Y 中的 X 代表網絡的不同層級(Stage),數字越大表示層越深。
-
Y 代表該層級中的第幾個SK模塊。
-
不同的SK模塊在不同的層級負責提取不同尺度、不同語義的特征。
-
從第2層到第5層,特征從低級(如邊緣、紋理)逐漸過渡到高級語義信息(如物體、場景等)。
-
channel index(32、64、96等) 表示不同通道編號。
-
activation表示每個通道上的注意力權重值。這個值越高,表明網絡對該通道上的特征越重視。
????????結論:
????????1. 當目標物體增大時,對大核(5×5) 的關注權值增大,這表明神經元自適應地變大。
????????2. 我們發現了一個關于自適應選擇跨深度作用的令人驚訝的模式:目標對象越大,越會將更多的注意力分配給更大的對象。
????????3. 隨著網絡加深,5x5卷積核的權重值也逐漸在變大,但在更高層時又不同。
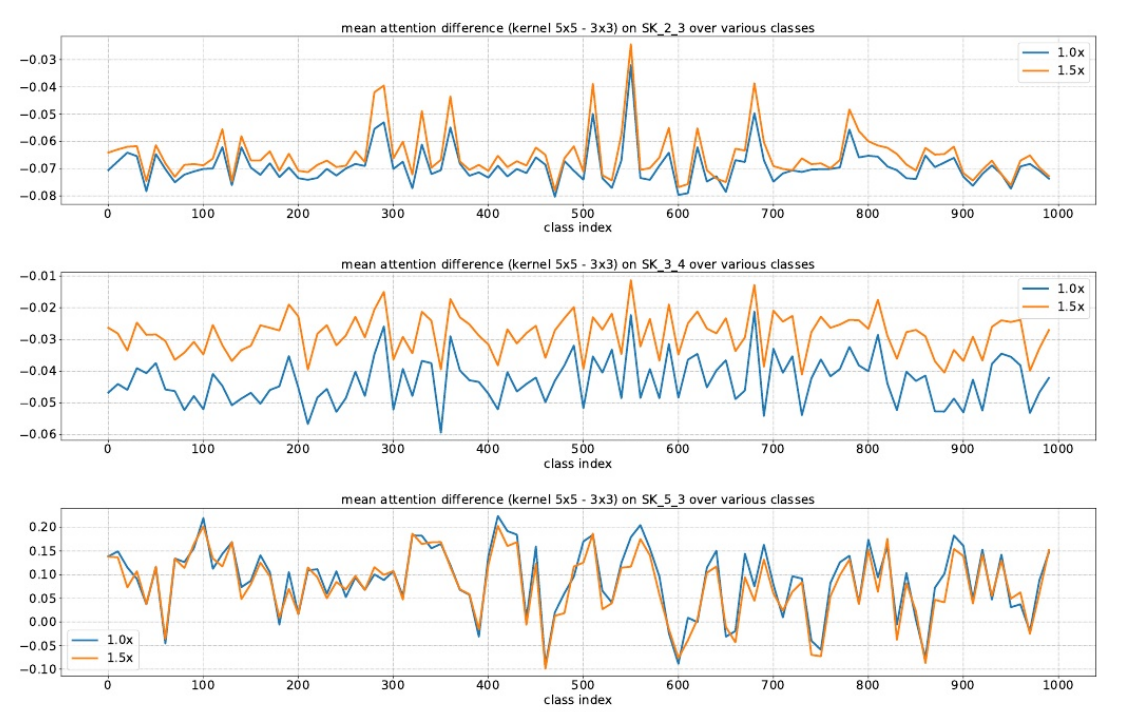
????????對于使用ImageNet上所有驗證樣本的1000個類別中的每一個,在SKNet-50的SK單元上的平均注意差(內核的平均注意值5×5減去內核的平均 注意值3×3)。在低級或中級SK單元(例如,SK 2.3, SK 34 4)上,如果目標對象變大(1.0x→1.5x),則明顯更強調5×5核。
????????結論:在低級和中級階段(例如,SK 23 3, SK 34 4),通過選擇性核機制的核。然而,在更高的層次(例如,SK 53 ?3),所有的尺度信息都丟失了,這樣的模式消失了。
????????這表明在網絡的前期,可以根據對象大小的語義感知選擇合適的核大小,從而有效地調整這些神經元的RF大小。然而,這種模式不存在于像SK 5.3這樣的非常高層中,因為對于高層表示, “尺度”部分編碼在特征向量中,與低層的情況相比, 內核大小的影響較小。
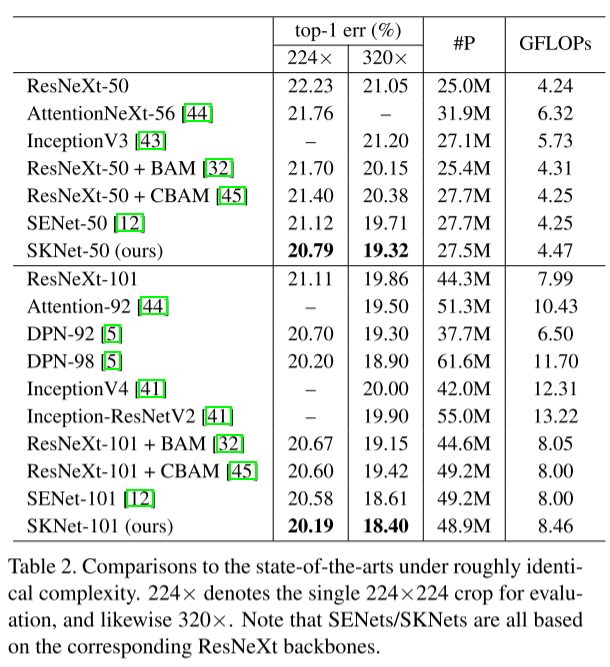
2.2.7?性能對比
3.?空間注意力
????????空間注意力(Spatial Attention)是一種專注于特征圖的空間維度的重要性分配的機制。它通過對特征圖中的特定空間位置進行加權,從而突出對任務最有貢獻的區域,抑制無關或冗余的區域,以提高模型的性能
3.1?Spatial Attention Module
????????這里介紹的空間注意力是 CBAM 中的組成模塊。
????????論文地址:https://arxiv.org/pdf/1807.06521
????????空間注意力模塊通過卷積操作為特征圖的每個空間位置生成權重,聚焦在圖像中的關鍵區域,這是對通道注意力的補充。
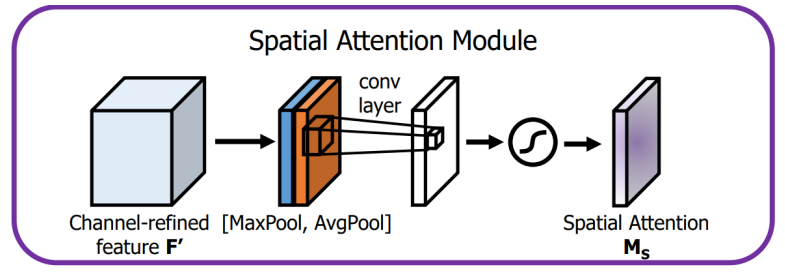
-
空間注意力模塊計算公式如下:
-
表示通道中的平均池化特征
-
表示通道中的最大池化特征
-
表示濾波器大小為 7×7 的卷積操作
-
表示 sigmoid 激活函數
-
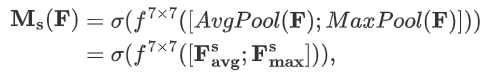
-
空間注意力模塊布局如下:
-
輸入特征:通道注意力模塊的輸出 F' 就是空間注意力模塊的輸入。
-
池化操作:
-
在 F' 的通道維度上進行全局的 MaxPool 和 AvgPool,生成 2 個二維特征圖,維度為 1 × H × W。
-
-
卷積層:
-
把池化得到的特征圖連接起來
。
-
使用一個
的卷積核對拼接后的特征圖進行卷積操作,經 Sigmoid 激活后,生成空間注意力圖
,維度為
。
-
-
輸出:
-
空間注意力圖M_S與經過通道注意力增強后的特征圖 F' 逐元素相乘,輸出最終的增強特征圖。
-
-
3.1.1?實驗結論
????????這個實驗結論是 CBAM 論文中給出的,不僅僅是添加了空間注意力,還添加了通道注意力,可以看出都比不用(baseline)效果要好

3.1.2?構建
import torch
import torch.nn as nn# 空間注意力模塊
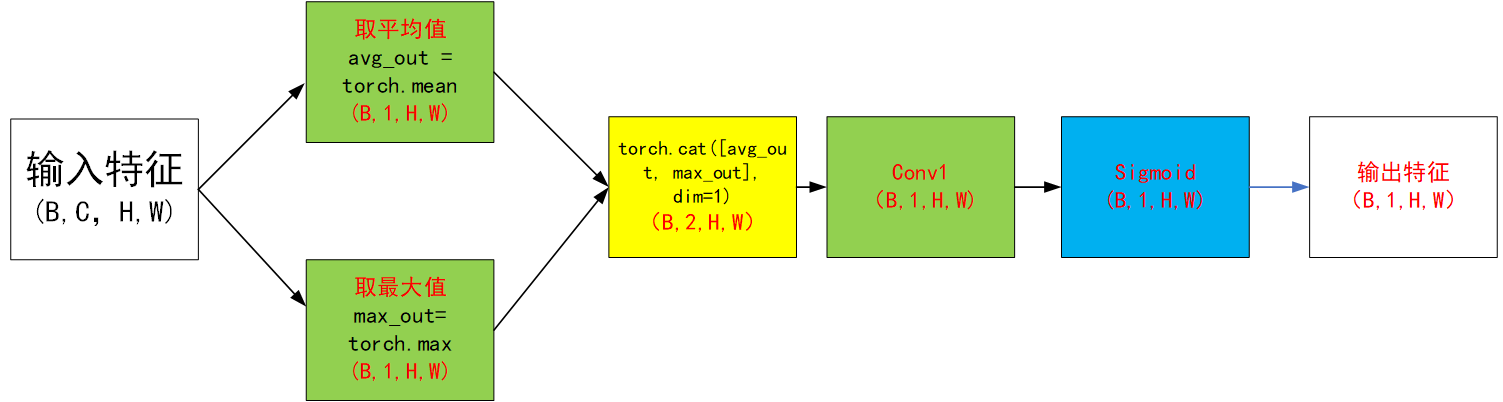
class SpatialAttentionModule(nn.Module):def __init__(self):super(SpatialAttentionModule, self).__init__()self.conv = nn.Sequential(nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3),nn.Sigmoid(),)def forward(self, x):max_pool = torch.max(x, dim=1, keepdim=True)[0]avg_pool = torch.mean(x, dim=1, keepdim=True)pool = torch.cat([max_pool, avg_pool], dim=1)out = self.conv(pool)return out3.2?Learn to Pay Attention
????????論文地址:https://arxiv.org/pdf/1804.02391。
????????源代碼地址:https://github.com/SaoYan/LearnToPayAttention。
????????空間注意力(Spatial Attention)主要用于CV,它在空間維度上選擇性地關注輸入特征圖的不同位置,從而提升模型對關鍵區域的感知能力。其實現原理是基于不同像素位置,生成對應概率掩碼,是比較低層的注意力機制。
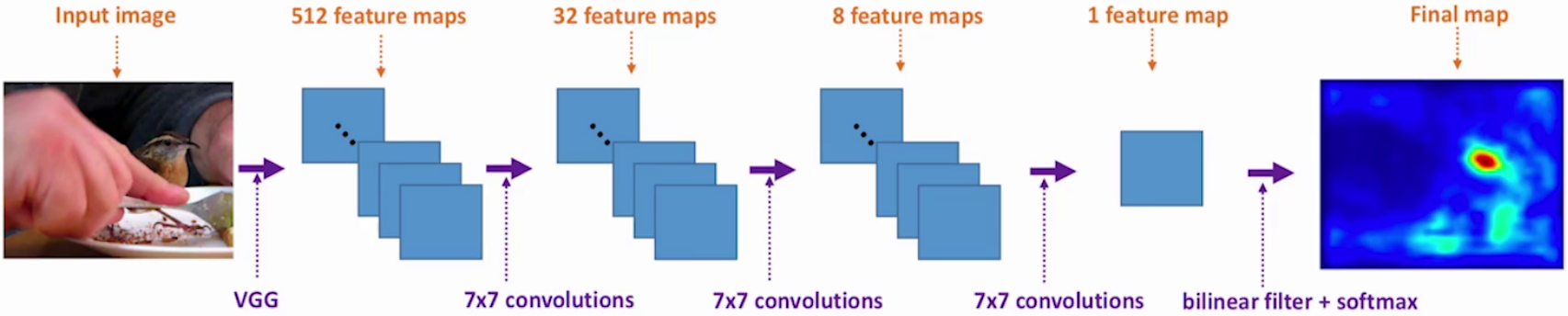
3.2.1?基本認知
????????結合全局特征和局部特征獲得注意力機制,使用加權的局部特征來識別目標。
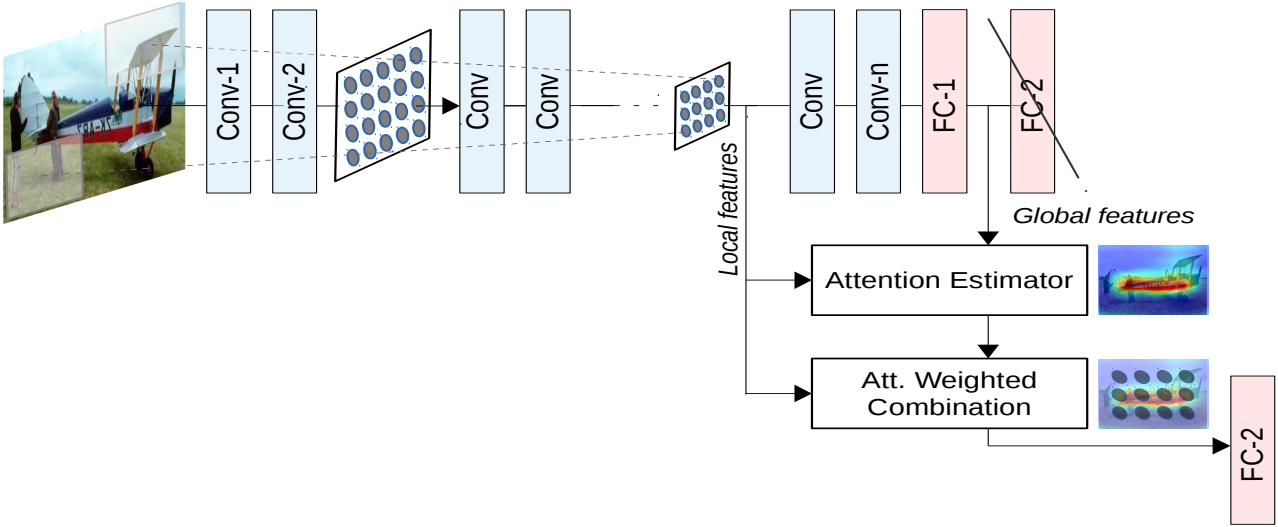
-
Local features:局部特征
如頭部、輪子、尾翼、發動機、機身標志或窗戶等,包含豐富的細節,對于識別飛機的具體種類、型號等非常有幫助。
-
Global features:全局特征
如整體形狀、輪廓、大小、相對背景中的位置等;對于識別是什么飛機很重要,如戰斗機、客機還是直升機。
-
特征融合:
在生成注意力權重前會對輸入的局部和全局特征進行融合。通過全局池化(Global Average Pooling)來獲得全局上下文信息。
-
Attention Estimator:
對輸入特征圖進行多層卷積、池化、激活等操作,用來挖掘特征之間的關系,從而生成注意力權重圖。權重圖的每個位置對應特征圖中的一個空間位置,表示該位置的重要性。
-
Att. Weighted Combination:
將生成的注意力圖與原始特征圖逐點相乘,得到加權后的特征圖。
3.2.2?融入模型
????????基于VGG16網絡的多層注意力融合:是為了適配不同大小的目標。
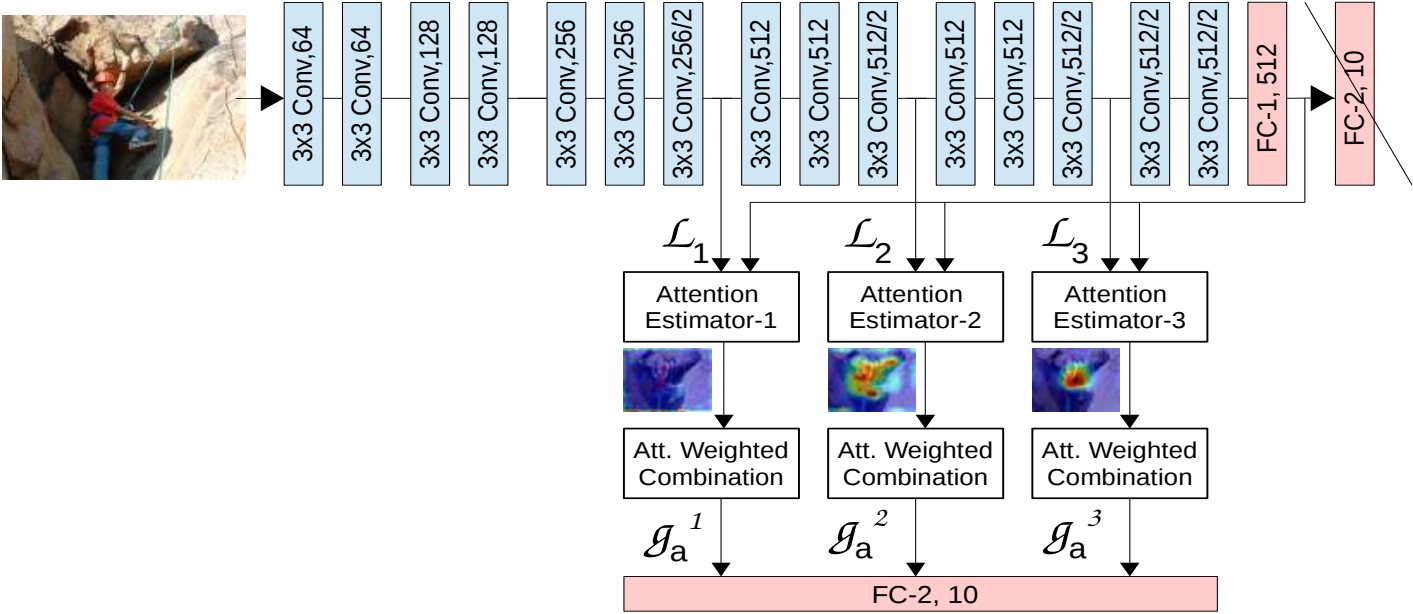
????????通過多層注意力估計器,模型能夠學會在不同的特征層次上關注有用的信息,提升分類性能。
? ? ? ? 1)流程概述:
-
局部特征向量,s表示特征圖層數:
-
(
)為VGG不同層級的局部特征向量,將
FC-1, 512的輸出 G 視作全局特征,同時移除FC-2, 10層。 -
Attention Estimator 接收 L_n 和 G 作為輸入,計算出注意力權重圖(Attention map),挖掘特征之間的關系。
-
Attention map作用于 L_n 的每個channel得到 Weighted local feature
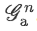 。
。 -
把各個層級下的
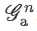 進行連接操作后得到
進行連接操作后得到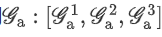
-
最后將
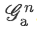 送入全連接層
送入全連接層FC-2, 10進行分類。
? ? ? ? 2)![]() 計算過程:
計算過程:
????????計算過程及關聯數學公式如下:
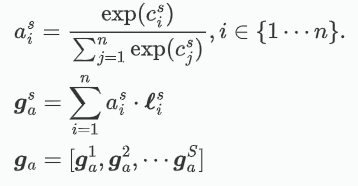
????????公式注解:
-
:第 s 層特征圖在位置 i 處的兼容性分數(compatibility score)。
-
:通過 softmax 計算得到的第 s 層特征圖在位置 i 處的注意力權重。
-
:經過注意力加權后的第 s 層特征圖的全局加權特征向量。
-
:第 s 層特征圖在位置 i 處的局部特征向量。
-
:注意力權重
相乘,表示該位置在注意力機制中的貢獻。
-
:最終得到的全局加權特征向量,它是不同層的加權特征向量
-
? ? ? ? 2)兼容性得分計算:
????????兼容性得分,compatibility score,論文給出了兩種方式:
-
內積法:兩個特征直接做點乘得到:
-
有參法:將兩個張量逐元素相加后,再經過一個全連接層進行學習, 下式中 \boldsymbol{u} 就是學習到的線性映射:
3.2.2?實驗效果
????????從可視化和數據化兩個方面進行觀察。
? ? ? ? 1)效果可視化:

????????圖閱讀注解:
????????proposed:表示加入LTPA注意力機制。
????????existing:表示加入傳統的注意力機制。
? ? ? ? 2)效果數據化
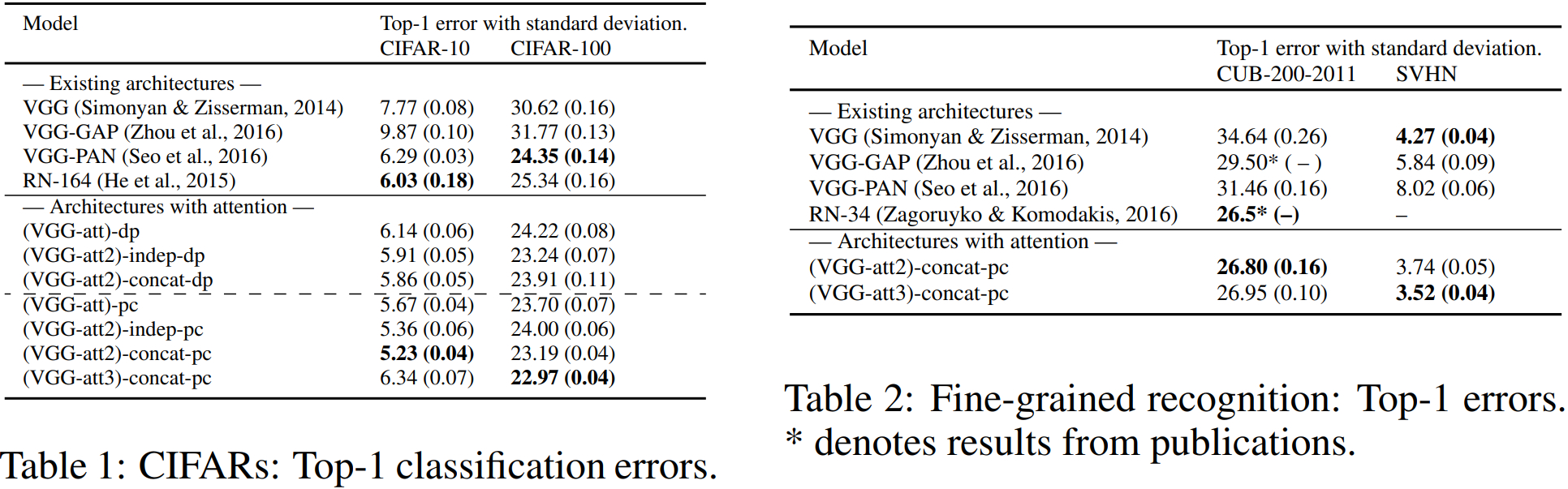
????????表閱讀注解:注意力獲取方法:pc表示有參法,dp表示內積法,最終預測策略:concat表示特征拼接后預測,indep表示多尺度獨立預測結果相加
4.?混合注意力
????????混合注意力機制(Hybrid Attention Mechanism)是一種結合空間和通道注意力的策略,旨在提高神經網絡的特征提取能力。
4.1?CBAM
????????Convolution Block Attention Module :卷積塊注意力模塊
????????論文地址:https://arxiv.org/pdf/1807.06521
4.1.1?基本認知
????????CBAM是一種輕量級的注意力模塊,它通過增加空間和通道兩個維度的注意力,來提高模型的性能。
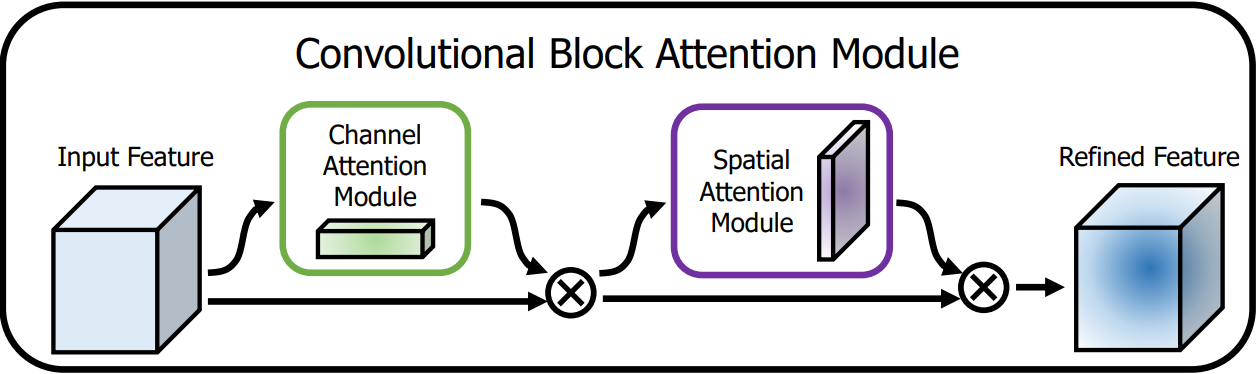
????????
????????一維的通道注意力圖:
????????二維的空間注意力圖:
????????整個注意力過程可以概括為:
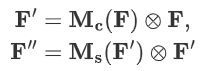
4.1.2?通道注意力模塊
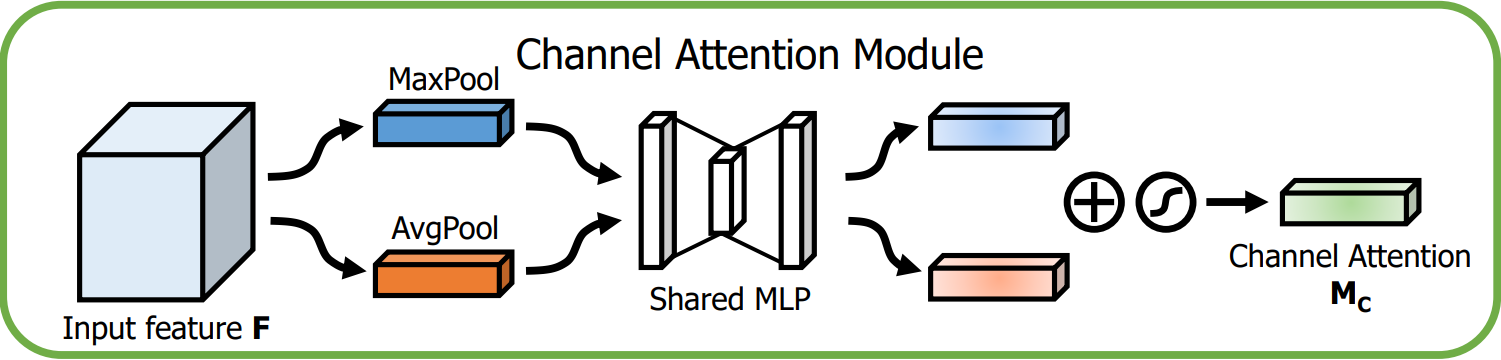
????????通道注意力模塊的目的是為每個通道生成一個注意力權重,整體流程如下圖:
????????通道注意力模塊機制公式如下:
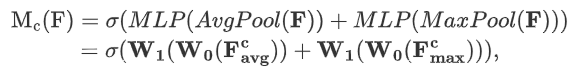
????????其中:r是縮放因子,用以減少參數量
????????通道注意力模塊機制詳情如下:
-
輸入特征:輸入特征圖 F 的尺寸為 H × W × C。
-
全局池化:
-
首先對 F 進行全局的MaxPool和AvgPool,得到兩個特征圖,尺寸為 1×1×C。
-
MaxPool提取了局部強響應特征,AvgPool提取了全局視角。
-
-
共享多層感知器(MLP):
-
池化后的2個特征向量分別送入一個共享MLP,它包含兩個全連接層,用來處理和生成通道注意力。
-
MLP的共享權重減少了參數量,同時確保兩個特征向量的變換方式是一致的。
-
MLP首先會降維為 C/r,然后升維為 C。
-
-
加法與激活:
MLP輸出的兩個特征向量逐元素相加后經Sigmoid后,生成維度為 1 × 1 × C的通道注意力圖
,表示每個通道的重要性。
-
輸出:
通道注意力圖
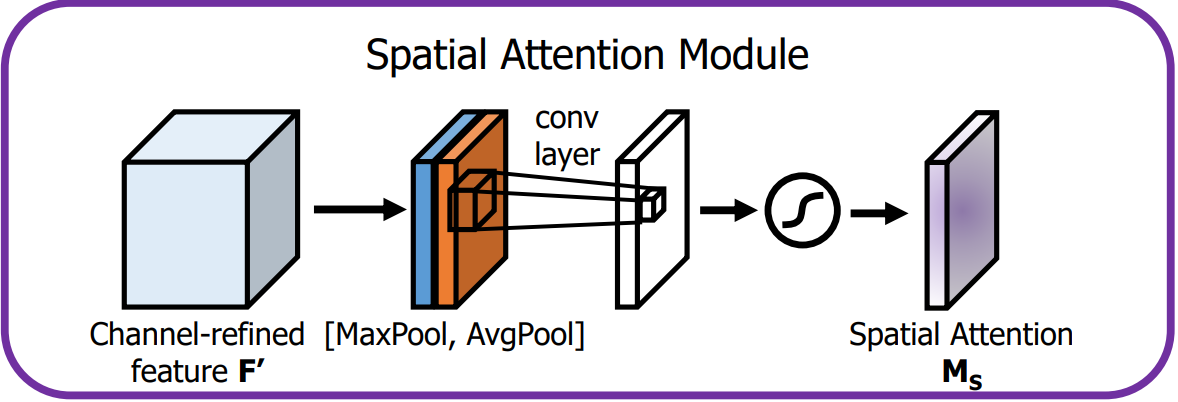
4.1.3?空間注意力模塊
????????空間注意力模塊通過卷積操作為特征圖的每個空間位置生成權重,聚焦在圖像中的關鍵區域。
????????空間注意力模塊機制公式如下:
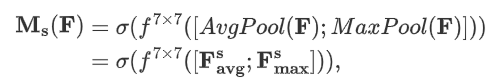
????????其中:
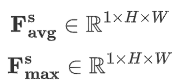
????????空間注意力模塊機制詳情如下:
-
輸入特征:通道注意力模塊的輸出 F' 就是空間注意力模塊的輸入。
-
池化操作:
-
首先在 F' 的通道維度上進行全局的MaxPool和AvgPool,生成2個二維特征圖,維度為 H × W × 1。
-
這樣可以分別提取空間上最重要的局部和全局信息。
-
-
卷積層:
將池化得到的兩個特征圖按通道維度進行連接,形成一個 H × W × 2 的特征圖,并通過大小為 7 × 7 的卷積層處理。
-
激活與輸出:
-
卷積層的輸出經Sigmoid激活后,生成單通道的空間注意力圖
-
空間注意力圖與經過通道注意力增強后的特征圖 F' 逐元素相乘,輸出最終的增強特征圖。
-
4.1.4?不同策略效果對比
? ? ? ? 1)通道注意力:加入通道注意力:可以看的出來都比不用(baseline)效果要好。

? ? ? ? 2)疊加空間注意力:在通道注意力的基礎之上加入空間注意力,就是混合注意力:效果最好的就是CBAM,并且池化不需要參數。
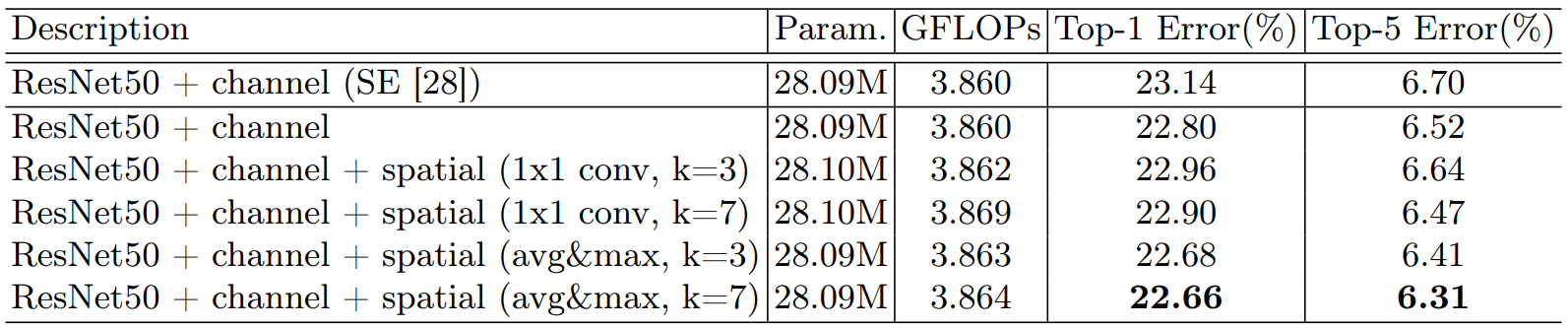
? ? ? ? 3)疊加順序:空間注意力和通道注意力位置調整效果對比:還是CBAM的效果好。

? ? ? ? 4)不同模型:不同模型對比:主打一個CBAM就是好。
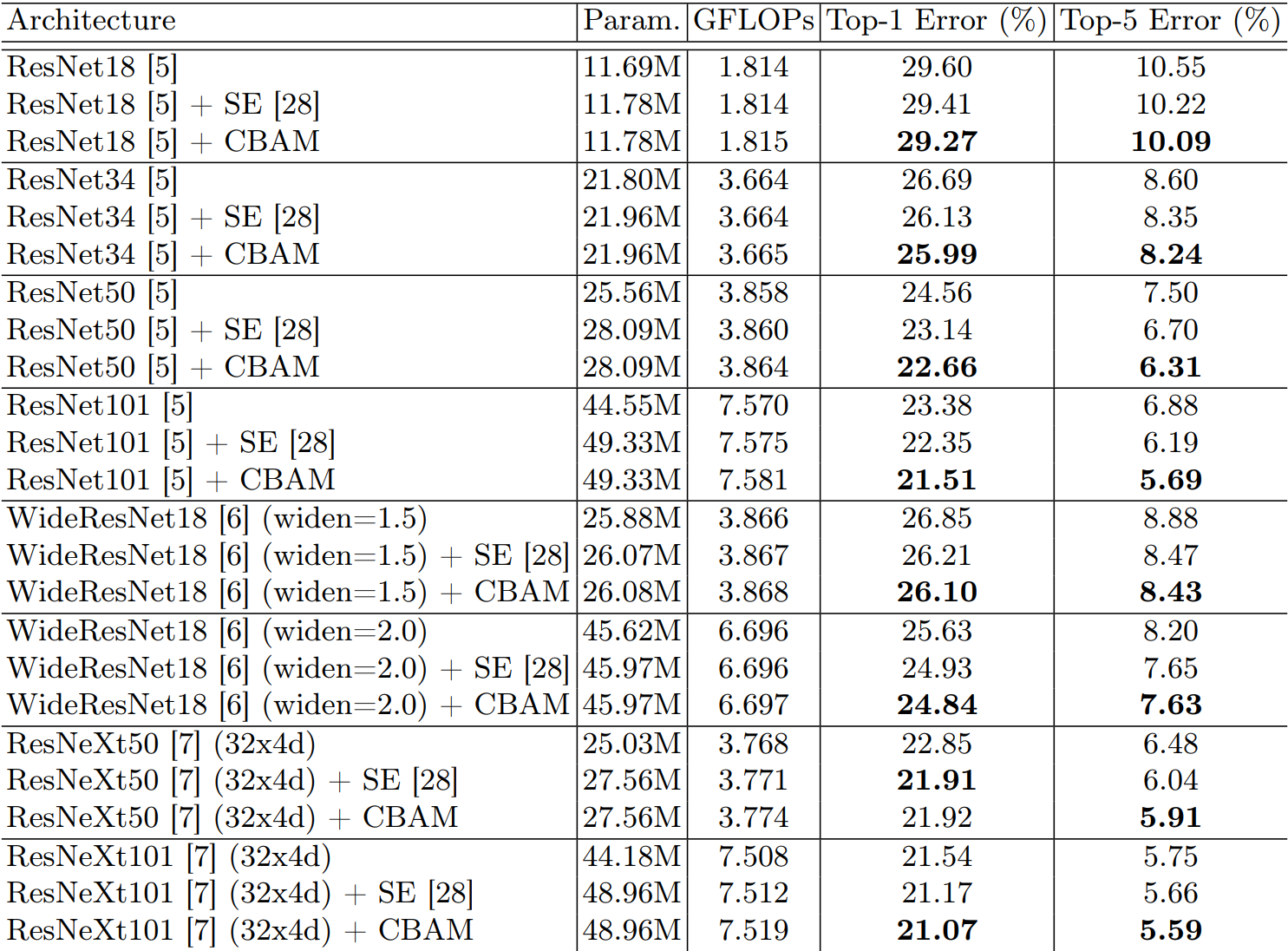
? ? ? ? 5)輕量級模型:在一些輕量級模型上的效果還是很明顯的。
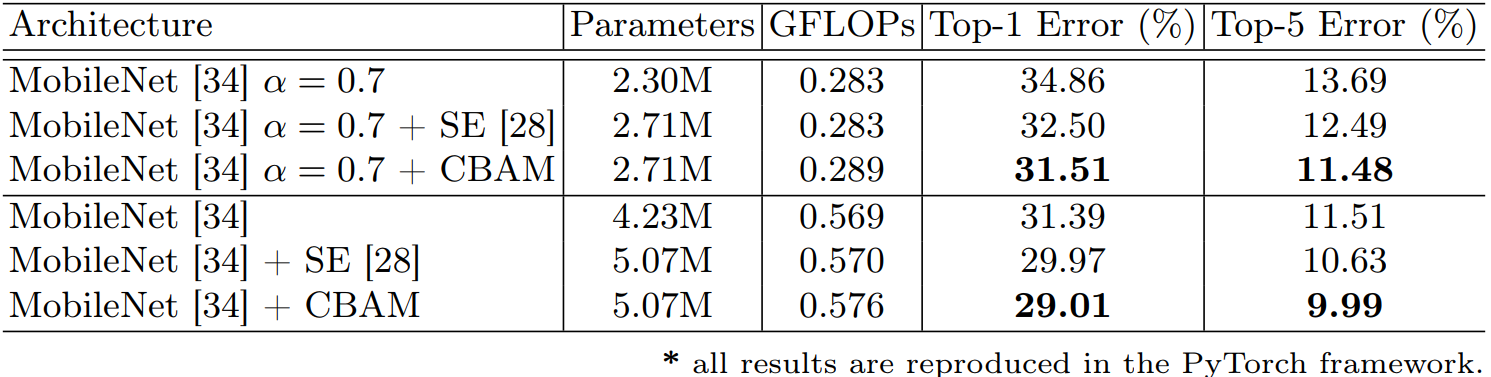
? ? ? ? 6)注意力可視化:可視化的方式對比。

4.2?BAM
????????Bottleneck Attention Module:瓶頸注意力模塊。
????????論文地址:https://arxiv.org/pdf/1807.06514
4.2.1?基本認知
????????BAM是通過在空間和通道兩個維度上分別構建注意力模塊,它們是**并行處理**的。
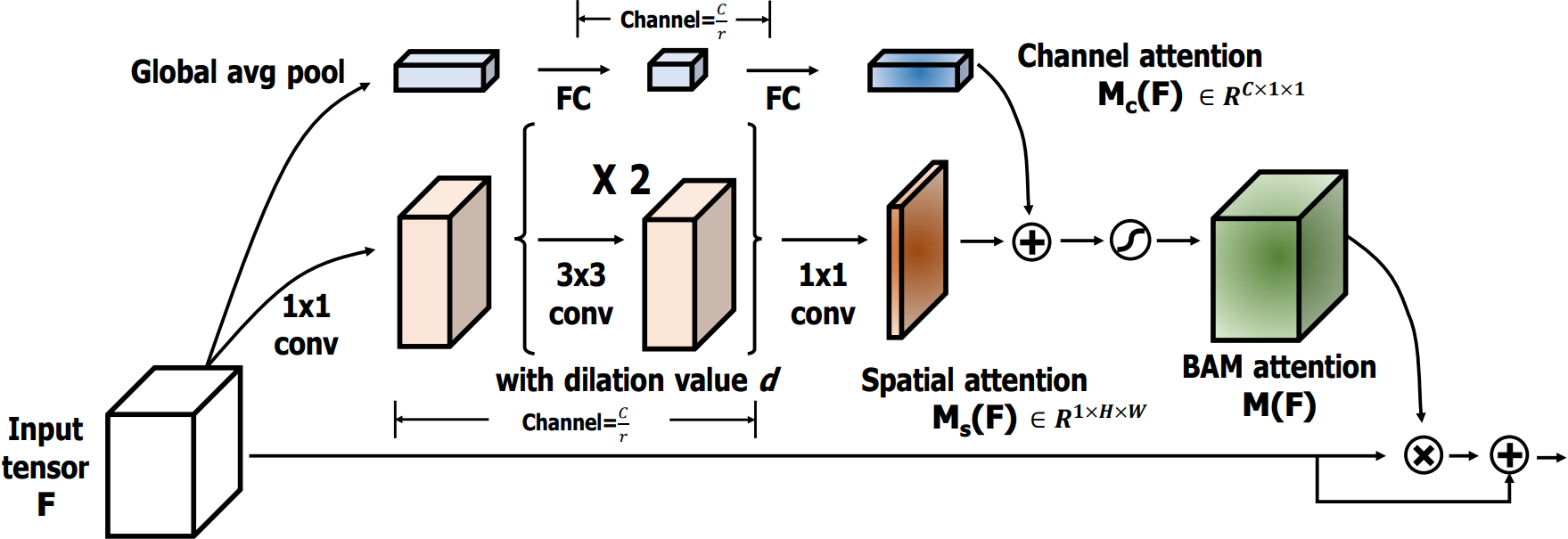
????????其中:形狀不同的張量會自動進行廣播機制。
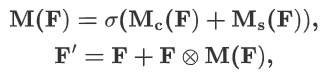
4.2.2?通道注意力模塊
????????通道注意力公式表達如下:
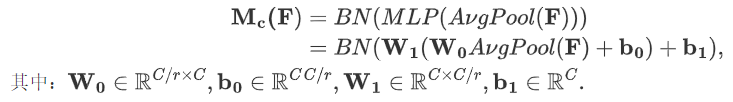
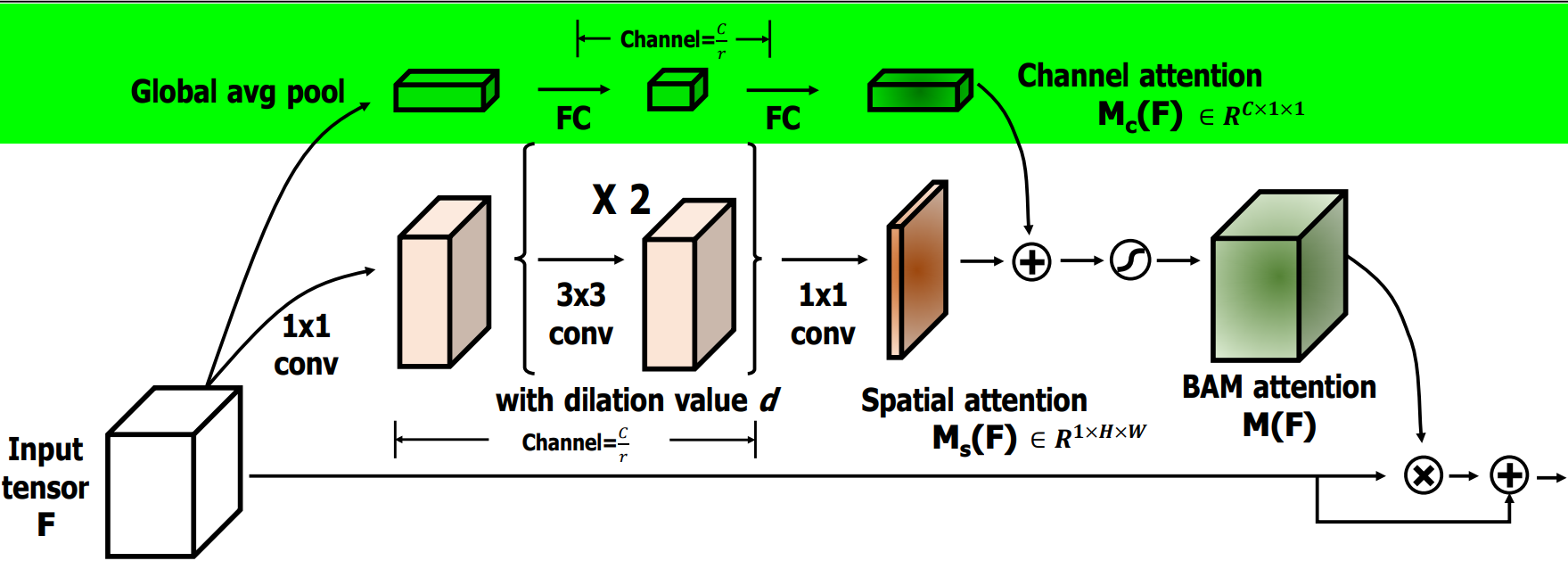
????????通道注意力流程如下:
-
全局平均池化:對輸入特征 F 進行GlobalAvgPooling,保留通道的重要全局信息。
-
全連接層:池化后的特征通過兩個FC,第一個FC降維,第二個FC則恢復到原通道數 C。這一過程可以學習通道間的依賴關系。
-
通道注意力:通過激活函數 Sigmoid 生成通道注意力圖 M_c(F),用于對原始通道進行加權,強調重要通道,抑制不重要通道。
4.2.3?空間注意力模塊
????????空間注意力公式表達如下:
![]()
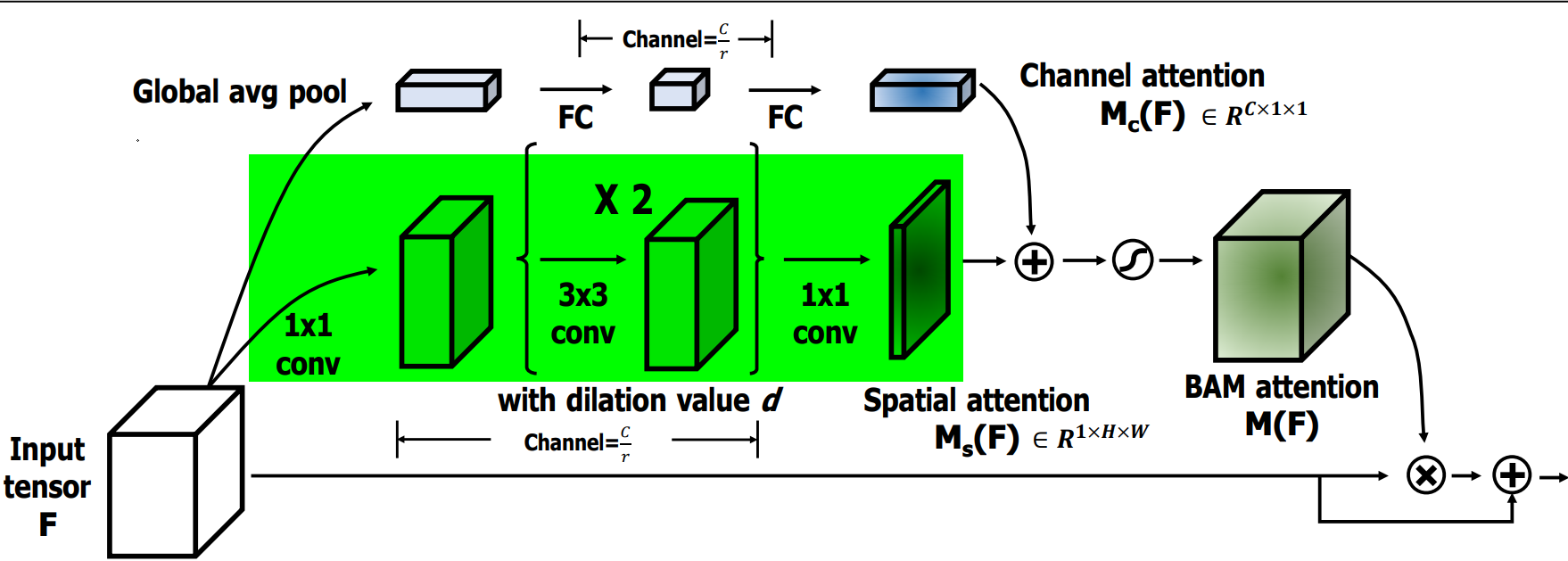
????????空間注意力流程如下:
-
1×1卷積:對輸入特征 F 進行一次卷積操作,用于壓縮通道維度并保持原始的空間信息,壓縮因子是 r=16。
-
膨脹卷積:使用兩層膨脹卷積(Dilated Convolution),膨脹率為 d=4。這樣既擴大了感受野,又不增加參數量,幫助模型在空間維度上捕捉更廣的上下文信息。
-
空間注意力生成:卷積操作生成一個空間注意力圖 M_s(F),用于標識出空間維度上哪些位置更重要。
4.2.4?注意力融合
????????通道和空間注意力融合:和
相加后,通過Sigmoid處理,生成最終的注意力圖
。
4.2.5?注意力應用
-
BAM注意力圖 M(F) 應用到 F 上,從而對特征圖進行重新加權。
-
殘差連接:將加權后的特征圖與輸入特征 F 進行相加,形成殘差連接。
這樣不僅保留了原始特征信息,還讓網絡學習到重要的注意力區域。
4.2.6?實驗結果
????????對比不同情況下的模型效果。
? ? ? ? 1)超參數配置:
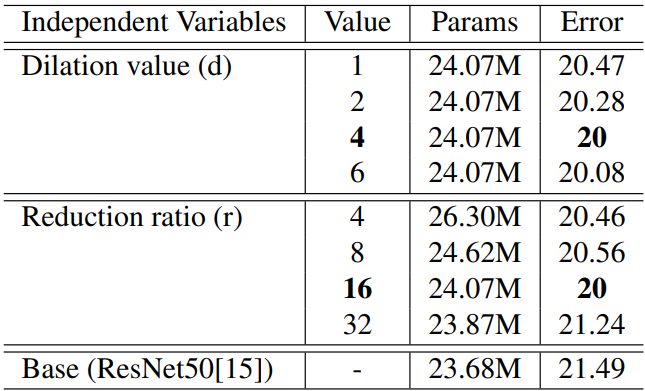
????????超參數:膨脹卷積的膨脹系數、FC的縮放因子
? ? ? ? 2)融合方式:
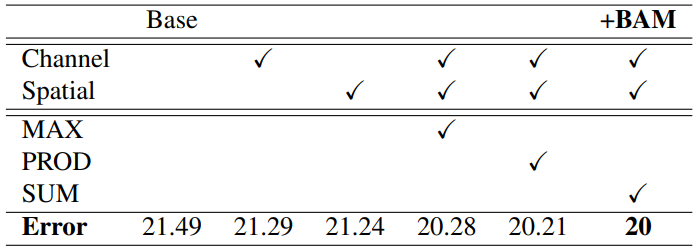
????????融合方式不同,效果也不同,最總就是兩個注意力并行后相加效果最好。
? ? ? ? 3)模型橫向對比:
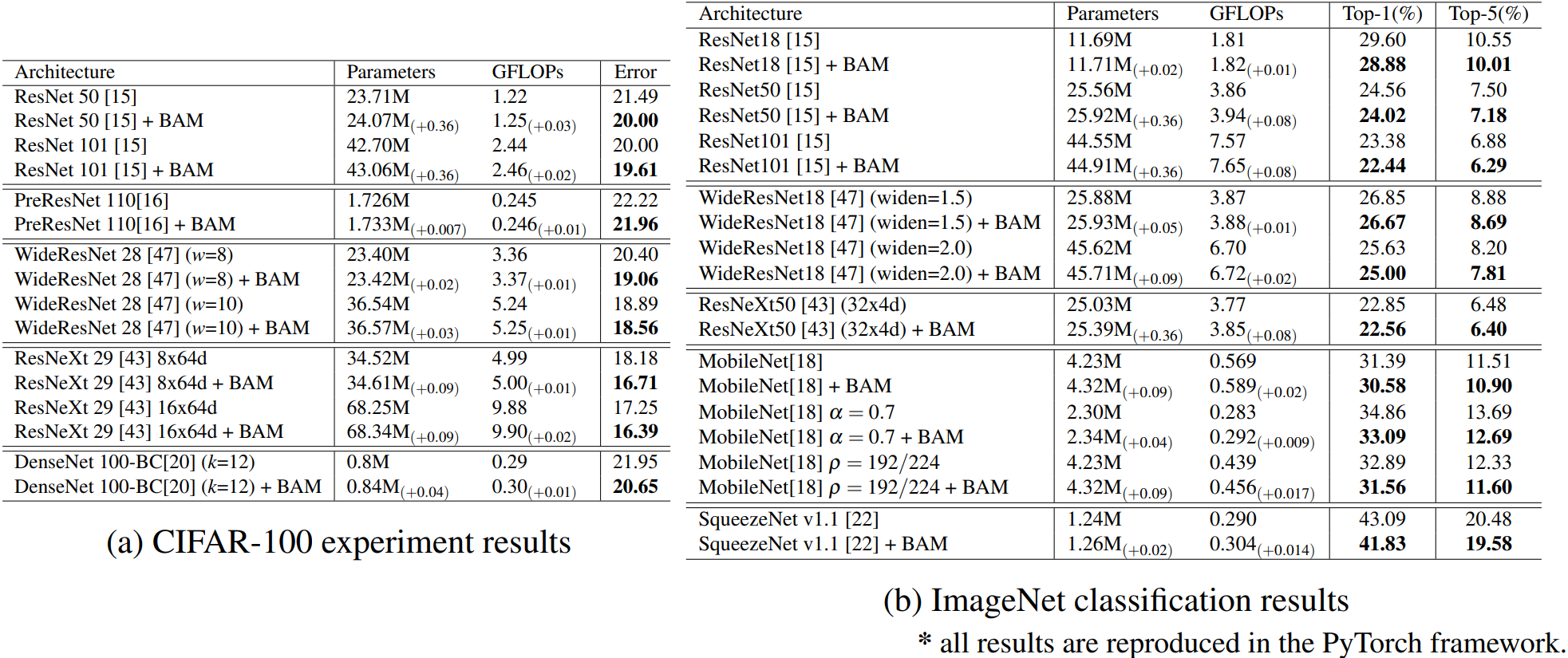
????????可以看的出來,加入BAM之后,都有明顯的效果提升,說明這種方式是有效的且通用的。



完全指南】面向對象編程入門)



)





--- 版本1(Client端))





