華為云Flexus+DeepSeek征文|基于Dify構建抓取金融新聞并發送郵箱工作流
- 一、構建抓取金融新聞并發送郵箱工作流前言
- 二、構建抓取金融新聞并發送郵箱工作流環境
- 2.1 基于FlexusX實例的Dify平臺
- 2.2 基于MaaS的模型API商用服務
- 三、構建抓取金融新聞并發送郵箱工作流實戰
- 3.1 配置Dify環境
- 3.2 配置Dify工具
- 3.3 創建抓取金融新聞并發送郵箱工作流
- 3.4 使用抓取金融新聞并發送郵箱工作流
- 四、總結
一、構建抓取金融新聞并發送郵箱工作流前言
在信息爆炸的金融領域,實時獲取精準資訊是投資者和從業者的核心需求。通過Dify工作流搭建自動化新聞抓取系統,可高效聚合The Daily Upside、Edward Jones等權威平臺的關鍵信息,結合大語言模型提煉核心要點,還可以翻譯為中文,最終通過郵件定時推送,實現從數據采集到智能分發的全鏈路閉環。
華為Flexus X云服務器與MaaS平臺的核心優勢在于:Flexus X提供100+種CPU/內存柔性配比(如1:3、3:7),結合X-Turbo加速技術使MySQL/Redis等關鍵應用性能達業界6倍,顯著降低新聞處理延遲;MaaS平臺集成盤古大模型及30+預置模型,支持金融摘要一鍵生成與敏感內容攔截(攔截率90%+),并通過智能調度實現資源成本優化30%;雙平臺協同保障99.995%跨可用區高可用性,為工作流提供安全可靠的全鏈路支撐。
二、構建抓取金融新聞并發送郵箱工作流環境
2.1 基于FlexusX實例的Dify平臺
華為云FlexusX實例提供高性價比的云服務器,按需選擇資源規格、支持自動擴展,減少資源閑置,優化成本投入,并且首創大模型QoS保障,智能全域調度,算力分配長穩態運行,一直加速一直快,用于搭建Dify-LLM應用開發平臺。
Dify是一個能力豐富的開源AI應用開發平臺,為大型語言模型(LLM)應用的開發而設計。它巧妙地結合了后端即服務(Backend as Service)和LLMOps的理念,提供了一套易用的界面和API,加速了開發者構建可擴展的生成式AI應用的過程。
參考:華為云Flexus+DeepSeek征文 | 基于FlexusX單機一鍵部署社區版Dify-LLM應用開發平臺教程
2.2 基于MaaS的模型API商用服務
MaaS預置服務的商用服務為企業用戶提供高性能、高可用的推理API服務,支持按Token用量計費的模式。該服務適用于需要商用級穩定性、更高調用頻次和專業支持的場景。
參考:華為云Flexus+DeepSeek征文 | 基于ModelArts Studio開通和使用DeepSeek-V3/R1商用服務教程
三、構建抓取金融新聞并發送郵箱工作流實戰
3.1 配置Dify環境
輸入管理員的郵箱和密碼,登錄基于FlexusX部署好的Dify網站
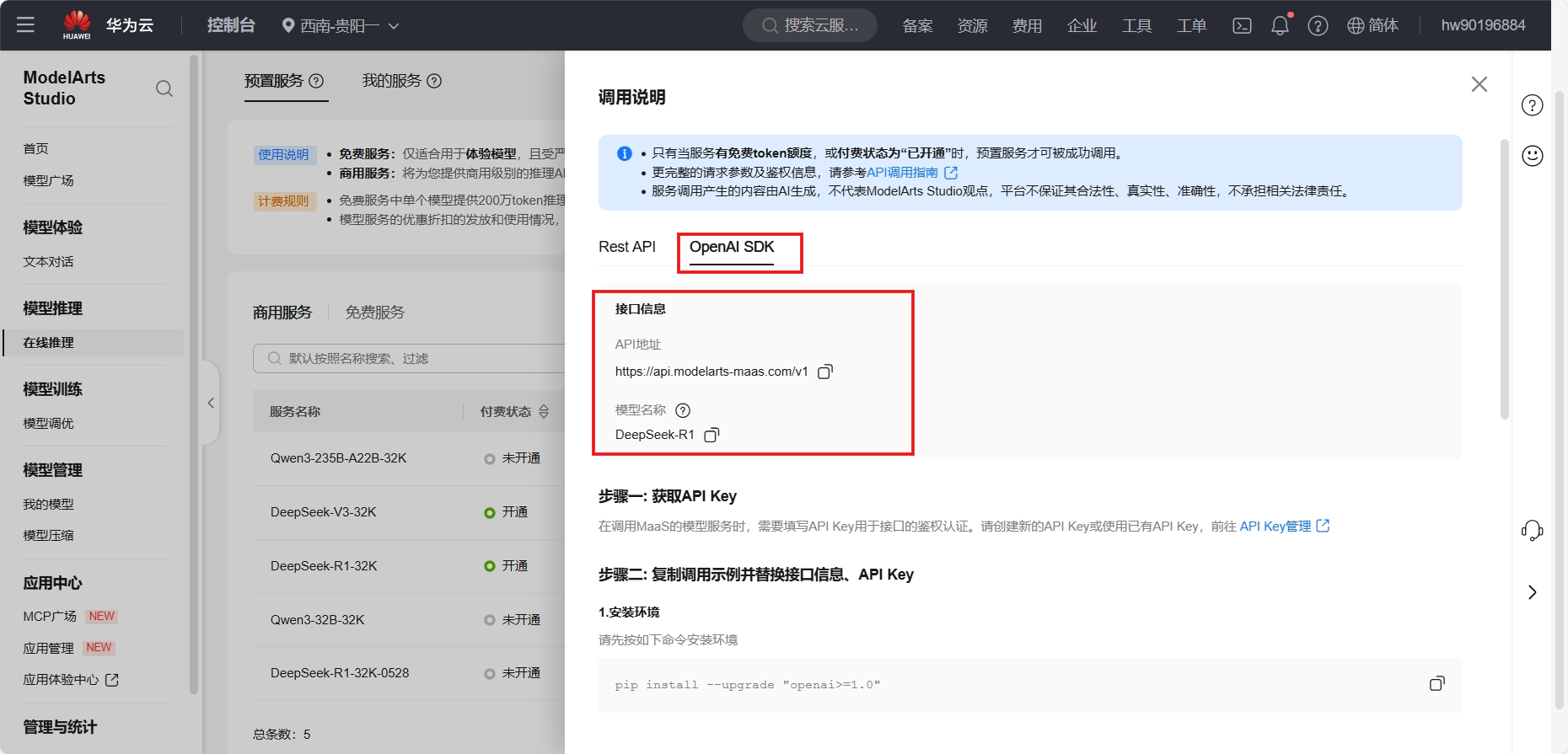
將MaaS平臺的模型服務接入Dify,這里我們選擇的是DeepSeek R1商用服務,需要記住調用說明中的接口信息和 API Key 管理中API Key,若沒有可以重新創建即可
配置Dify模型供應商:設置 - 模型供應商 - 找到OpenAI-API-compatible供應商并單擊添加模型,在添加 OpenAI-API-compatible對話框,配置相關參數,然后單擊保存
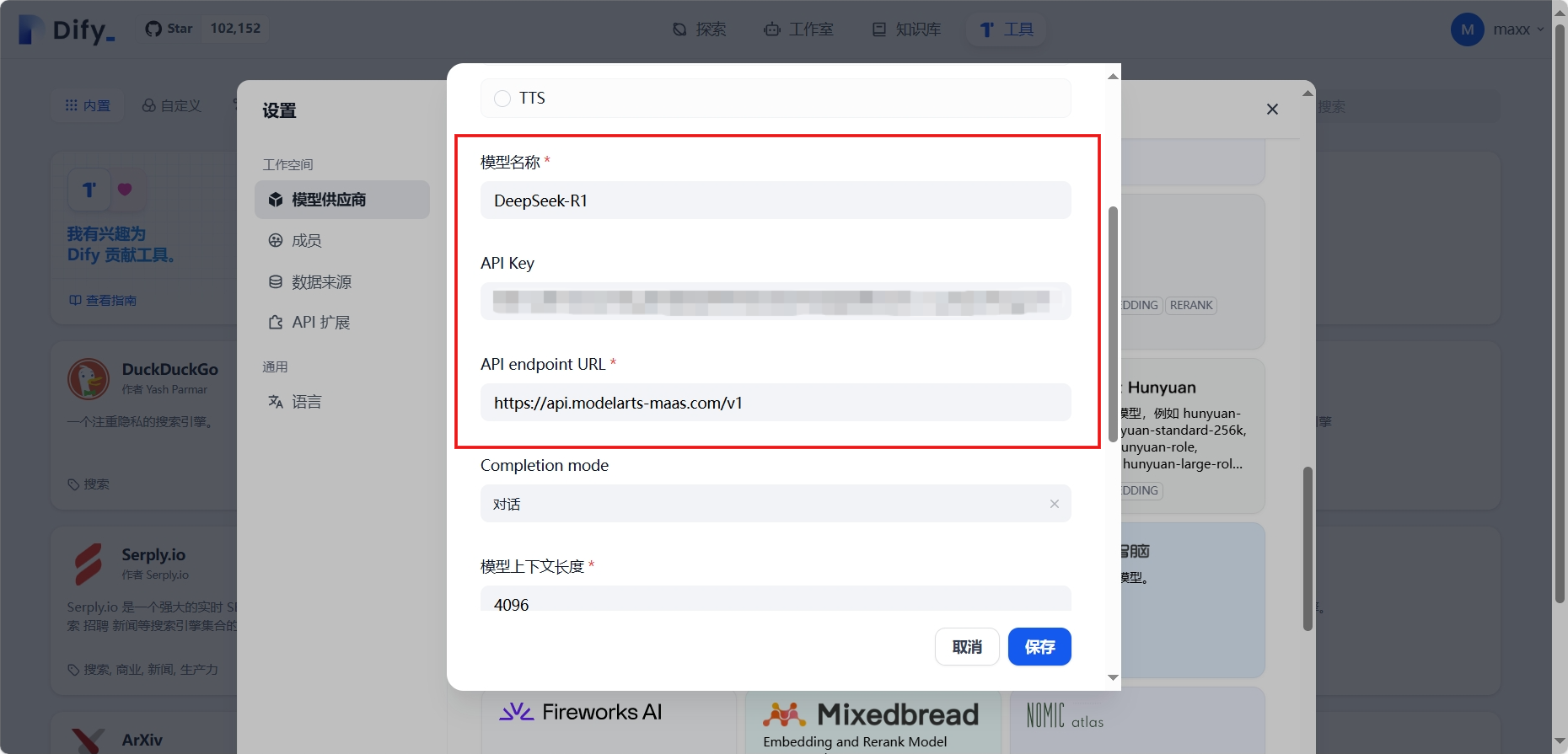
| 參數 | 說明 |
|---|---|
| 模型類型 | 選擇LLM。 |
| 模型名稱 | 填入模型名稱。 |
| API Key | 填入創建的API Key。 |
| API Endpoint URL | 填入獲取的MaaS服務的基礎API地址,需要去掉地址尾部的“/chat/completions”后填入 |
3.2 配置Dify工具
1. Firecrawl
Firecrawl 是一個強大的 API 集成,用于網絡爬蟲和數據抓取。它允許用戶提取 URL、抓取網站內容以及從網頁中檢索結構化數據。憑借其模塊化工具,Firecrawl 簡化了有效收集 Web 數據的過程。現在,您可以在應用程序工作流中使用它來自動提取和分析 Web 數據。
進入 Firecrawl API 密鑰 頁面,創建新的 API 密鑰,默認是有一個 API Key 的

并確保您的賬戶余額充足,默認是有500額度的,測試發現可以運行500次爬蟲操作,還是很夠用的,似乎和爬取的數據量無關

訪問 Plugin Marketplace,找到 Firecrawl 工具,然后安裝它

授權 Firecrawl:導航到 Plugins > Firecrawl > To Authorize in Dify,然后輸入您的 API 密鑰以啟用該工具

授權成功后,我們就可以將 Firecrawl 節點添加到 Chatflow 或 Workflow 管道用于網頁爬取和數據抓取了

2. 163SMTP郵件發送
用于發送郵件的工具,使用 smtp.163.com 的電子郵件服務而不進行任何數據處理,可以使用多個電子郵件收件人。
開啟 SMTP 服務并獲取授權碼,登錄 網易郵箱,打開設置 - POP3/SMTP/IMAP,開啟 SMTP 服務,再授權密碼管理中新增授權密碼即可,注意只能查看一次,需要復制保存

訪問 Plugin Marketplace,找到 163SMTP郵件發送 工具,然后安裝它

使用此工具,需要輸入以下參數,郵箱用戶名、授權碼、收件人郵箱、主題和內容,稍后就會使用此工具發送爬取的金融新聞

3.3 創建抓取金融新聞并發送郵箱工作流
在 Dify - 工作室,創建空白應用,選擇工作流,輸入應用名稱和圖標,點擊創建

刪除其他默認節點,在開始節點后添加一個代碼執行節點,用于構建我們需要的時間格式:"tduDate": "tdu-june-23-2025",代碼參考如下
function main() {const date = new Date(new Date().toLocaleString("en-US", {timeZone: "Asia/Shanghai"}));date.setDate(date.getDate());// Ensuring the month and day are always two digitsconst day = String(date.getDate()).padStart(2, '0');const month = String(date.getMonth() + 1).padStart(2, '0'); // getMonth() returns 0-11, so add 1const year = date.getFullYear();const monthNames = ["january", "february", "march", "april", "may", "june", "july", "august", "september", "october", "november", "december"];const tduDate = `tdu-${monthNames[date.getMonth()]}-${day}-${year}`; // Updated lineconst mbDate = `${monthNames[date.getMonth()].toUpperCase().substring(0, 3)} ${date.getDate()}, ${date.getFullYear()}`;const ejDate = `${month}/${day}/${year}`; // Already updated in your codereturn {tduDate: tduDate,mbDate: mbDate,ejDate: ejDate};
}

再添加2個并行的 Firecrawl 節點,選擇單頁面爬取即可,分別用于爬取 DAILYUPSIDE 網站 和 EDWARD JONES 網站

在 DAILYUPSIDE 節點 中配置抓取的Url為:https://www.thedailyupside.com/newsletter/{{日期獲取.tduDate#}},這里就用上了代碼執行中構建的時間參數,再填入一些其他配置,如僅抓取這些標簽、要移除這些標簽
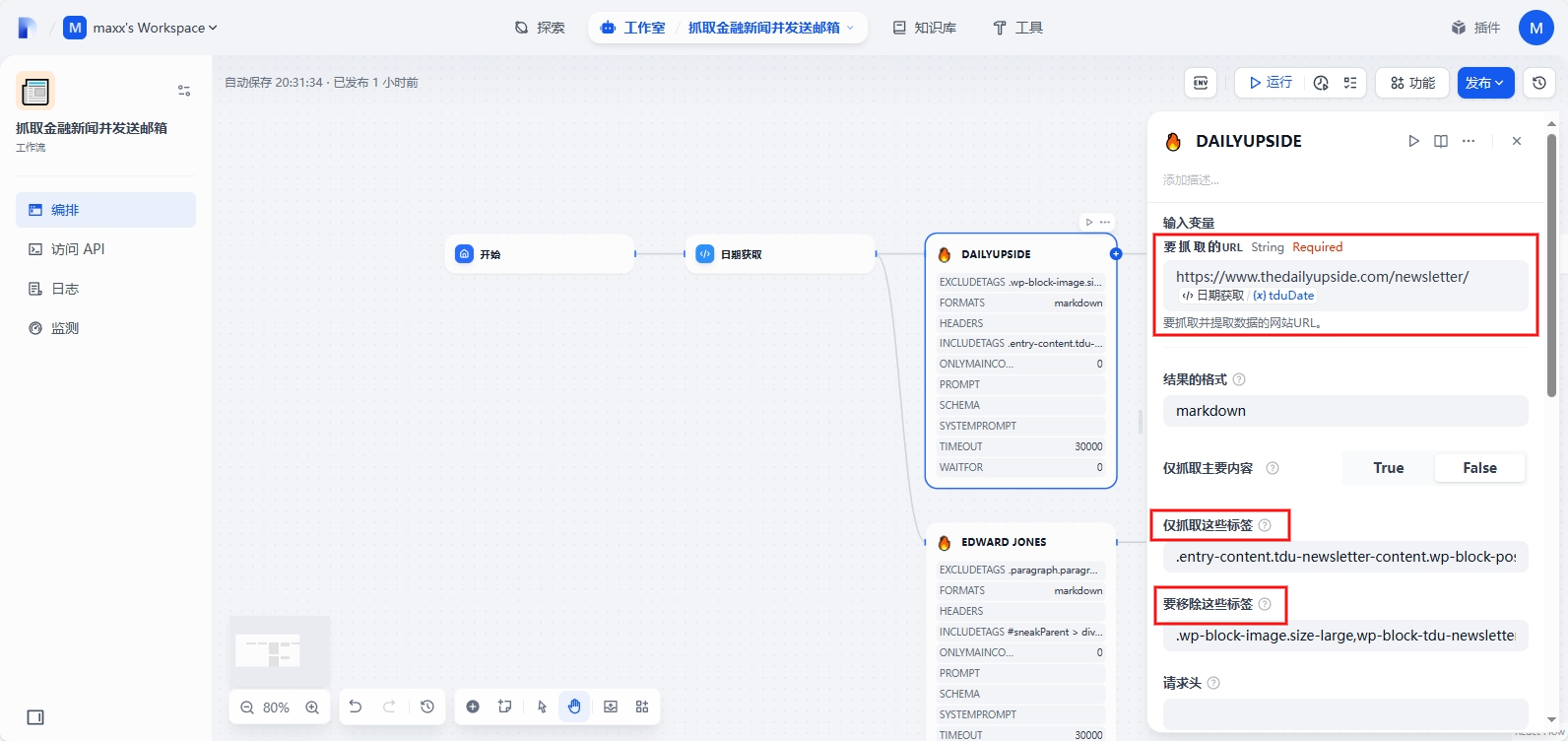
在 EDWARD JONES 節點 中配置抓取的Url為:https://www.edwardjones.com/us-en/market-news-insights/stock-market-news/daily-market-recap,也填入一些要抓取和移除的標簽參數

再接入LLM節點,分別解析2個爬蟲得到信息,模型都選用華為Maas通過的DeepSeek R1模型,上下文填入上一步 Firecrawl 的輸出變量

DAILYUPSIDE REPORTER 系統提示詞參考:
<instructions>
根據提供的Markdown英文新聞,你的任務是列出新聞并逐一進行總結。英文行文按照如下格式來提供,其中[Title], [Content], [NewsType]為占位符:
[NewsType(auto, economics, indicators, inflation)]\n
# [Title]
[Content]
以及
## Extra Upside
- **[Title]:** [Content]對于每一條新聞,你需要使用以下模板創建中文總結:標題:xxx
內容:xxx
\n\n---\n\n
標題:xxx
內容:xxx標題與內容應該為中文。并且標題應具有吸引力,并涵蓋新聞中的三個要素:誰、何時、發生了什么。內容應是對新聞的概括性陳述。以下是需要遵循的步驟:1. 閱讀提供的Markdown英文新聞。
2. 剔除最后有“\*”的“新聞”,因為該“新聞”是廣告
2. 識別每條新聞中的關鍵要素:誰、何時、發生了什么。
3. 為每條新聞創建一個包含這些關鍵要素的吸引人的標題。
4. 撰寫一條概括性陳述,總結每條新聞的內容。
5. 對于內容中提到關鍵數據、成果、舉措或事件以及任何吸引眼的內容,通過markdown bold語法進行重點展示。請確保你的輸出不包含任何XML標簽。
</instructions>
EDWARD JONES REPORTER 系統提示詞參考:
<instructions>
根據提供的Markdown英文新聞,你的任務是列出新聞并逐一進行總結。英文行文按照如下格式來提供,其中[Title], [Content], [NewsType]為占位符:
**[Date(Thursday, 01/30/2025 a.m.)]**\n\n
**[Title] –** [Content] ...對于每一條新聞,你需要使用以下模板創建中文總結:標題:xxx
內容:xxx
\n\n---\n\n
標題:xxx
內容:xxx標題與內容應該為中文。并且標題應具有吸引力,并涵蓋新聞中的三個要素:誰、何時、發生了什么。內容應是對新聞的概括性陳述。以下是需要遵循的步驟:1. 請選擇日期為{{#1739247876689.ejDate#}}的新聞進行閱讀,不要閱讀日期為其他事件的新聞內容。
2. 閱讀提供的Markdown英文新聞。
3. 識別每條新聞中的關鍵要素:誰、何時、發生了什么。
4. 為每條新聞創建一個包含這些關鍵要素的吸引人的標題。
5. 撰寫一條概括性陳述,總結每條新聞的內容。
5. 對于內容中提到關鍵數據、成果、舉措或事件以及任何吸引眼的內容,通過markdown bold語法進行重點展示。請確保你的輸出不包含任何XML標簽。
</instructions>

再將2個并行節點添加到代碼執行節點,用于拼接2個網站的新聞信息,輸入變量為2個LLM節點的輸出變量,執行的拼接代碼參考:
def main(daily_upside: str, edward_jones: str) -> dict:return {"result": daily_upside +"\n\n---\n\n"+ edward_jones,}

再添加節點 - 工具 - 163SMTP郵件發送,輸入5個必要的參數,主題為:今日新聞+時間戳,內容則為輸出格式整理節點的輸出變量還有三個變量使用環境變量填入
環境變量是一種存儲敏感信息的方法,如 API 密鑰、數據庫密碼等。它們被存儲在工作流程中,而不是代碼中,以便在不同環境中共享。

郵箱用戶名:username,收件人郵箱:receiver,授權碼:secret

最后添加結束節點,標志工作流執行完畢,輸出發送163郵件通知節點的結果

編排工作流后點擊右上角的運行,進行測試,查看整個流程可以看到先獲取當前日期,再進入2個并行的爬取新聞過程,再分別進行LLM總結爬取內容,最后格式整理并發送郵件

整個流程50秒就完成了

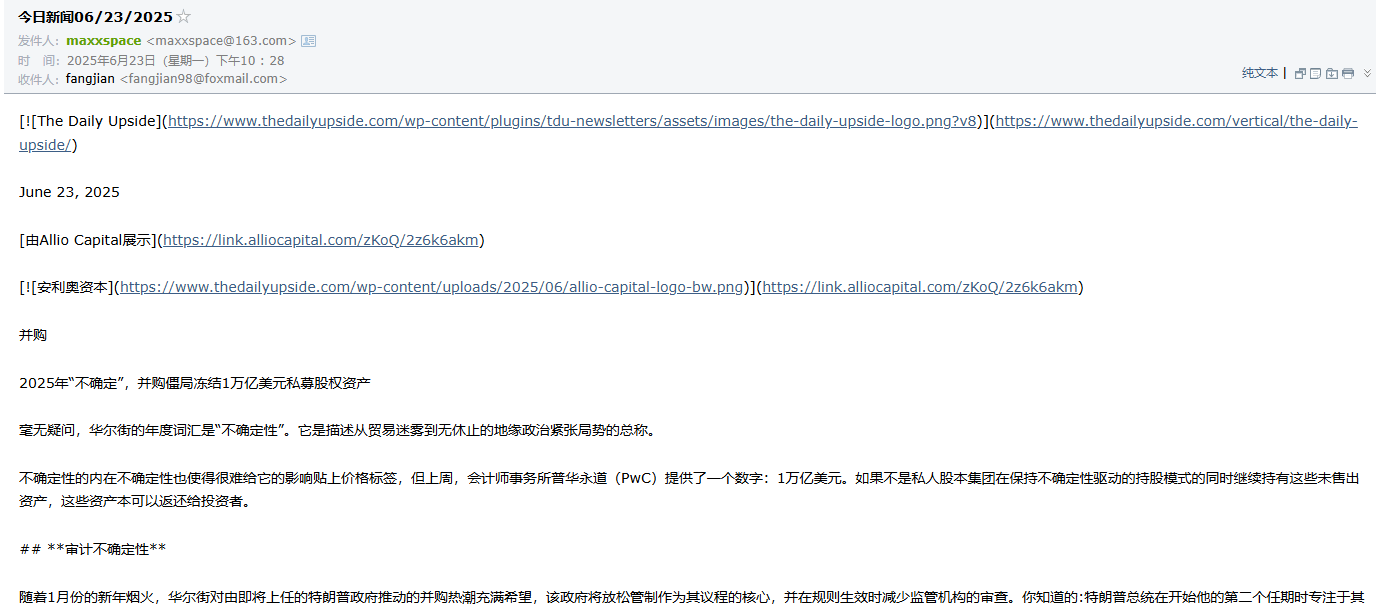
打開我們的收件郵箱查看到如下的內容,標題為 今日新聞06/23/2025,輸出的內容是 markdown 格式的,我們這里是沒有進行中文翻譯的,因為爬取的網站的英文,這里也就是英文了,可以在 LLM節點 中添加提示詞中文輸出

測試完成就可以發布更新到探索頁面了,發布后選擇運行就可以獲得一個在線運行的工作流的網頁!
3.4 使用抓取金融新聞并發送郵箱工作流
在探索 - 抓取金融新聞并發送郵箱中開啟新對話

在運行一次Tab頁中點擊運行即可執行工作流

為了區別測試的內容,我在LLM節點最后都加上了一個提示詞:最后將所有內容翻譯成中文輸出,查看接收到的郵件效果,格式還是有點問題的,需要根據爬取的不同新聞網站的樣式再優化
四、總結
該工作流革新了傳統手動篩選模式,以動態日期生成、并行抓取和AI摘要技術大幅提升效率,降低信息過載風險。通過自動化整合與精準推送,用戶可快速掌握市場動態,為投資決策提供實時支持,同時推動金融信息處理向智能化、結構化躍遷。
通過本次Dify工作流實踐,深刻體會到其可視化編排與AI無縫集成的核心價值:僅需拖拽HTTP抓取、LLM摘要、郵件推送等節點,即可快速構建從金融新聞采集→智能精煉→定時分發的全自動化鏈路,將傳統手動處理耗時從幾小時壓縮至5分鐘。華為Flexus X云服務器提供精準彈性的CPU/內存配比,有效支撐多源數據并行抓取;MaaS平臺內置的盤古大模型則實現關鍵信息的高精度提純與敏感內容攔截。整體部署過程印證了低代碼開發+云原生算力在落地企業級自動化場景中的高效性與可靠性,真正實現數據流動自動化、信息獲取結構化、決策支持實時化的核心目標,化繁為簡,智能提效。
















)


與 OpenSearch(OS))