1、環境/問題介紹
- 概述:多臂老虎機問題是指:智能體在有限的試驗回合 𝑇 內,從 𝐾 臺具有未知獎賞分布的“老虎機”中反復選擇一個臂(即拉桿),每次拉桿后獲得隨機獎勵,目標是在累積獎勵最大化的同時權衡探索(嘗試不同臂以獲取更多信息)和利用(選擇當前估計最優臂)
你站在賭場前,有三臺老虎機(臂 A 、 B 、 C A、B、C A、B、C),它們的中獎概率分別為 ( p A , p B , p C ) ( p_A, p_B, p_C ) (pA?,pB?,pC?),但你并不知道具體數值。你有 100 次拉桿的機會,每次只能選擇一臺機器并拉動其拉桿,若中獎則獲得 1 枚籌碼,否則 0。你的目標是在這 100 次嘗試中,盡可能多地贏得籌碼。
這個例子直觀地展示了多臂老虎機問題的核心要素:
- 未知性:每臺機器的中獎概率對你未知。
- 試錯學習:通過拉桿并觀察結果,逐步估計每臺機器的回報。
- 探索–利用權衡:需要在嘗試新機器(探索)與選擇當前估計最優機器(利用)之間取得平衡,以最大化總收益。
2、主要算法
2.1. ε-貪心算法(Epsilon?Greedy)
1. 算法原理
以概率 ε 隨機探索,概率 1???ε 選擇當前估計最高的臂,實現簡單的探索–利用平衡。
-
這里的 ? (epsilon) 是一個介于 0 和 1 之間的小參數(例如 0.1, 0.05)。它控制著探索的程度:
-
?=0:純粹的貪婪算法 (Greedy),只利用,不探索。如果初始估計錯誤,可能永遠無法找到最優臂。
-
?=1:純粹的隨機探索,完全不利用過去的經驗。
-
0<?<1:在大部分時間利用已知最優選擇,但保留一小部分機會去探索其他可能更好的選擇。
?-Greedy 保證了即使某個臂的初始估計很差,仍然有一定概率被選中,從而有機會修正其估計值。
-
-
變種: 有時會使用隨時間衰減的 ? 值(如 ? = 1 / t ? =1/t ?=1/t 或 ? = c / log ? t ? =c / \log t ?=c/logt),使得算法在早期更多地探索,隨著信息積累越來越充分,逐漸轉向利用。
2. ε-Greedy 算法實現步驟
假設有 K K K 個臂,總共進行 T T T 次試驗。
-
初始化 (Initialization):
- 設置探索概率 ? \epsilon ?(一個小的正數)。
- 為每個臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K 初始化獎勵估計值 Q 0 ( a ) = 0 Q_0(a) = 0 Q0?(a)=0。
- 為每個臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K 初始化被選擇的次數 N 0 ( a ) = 0 N_0(a) = 0 N0?(a)=0。
-
循環執行 (Loop): 對于時間步 t = 1 , 2 , . . . , T t = 1, 2, ..., T t=1,2,...,T:
- 選擇動作 (Select Action):
- 生成一個 [0, 1) 范圍內的隨機數 p p p。
- 如果 p < ? p < \epsilon p<? (探索):
從所有 K K K 個臂中等概率隨機選擇一個臂 A t A_t At?。 - 如果 p ≥ ? p \ge \epsilon p≥? (利用):
選擇當前估計獎勵最高的臂 A t = arg ? max ? a Q t ? 1 ( a ) A_t = \arg\max_{a} Q_{t-1}(a) At?=argmaxa?Qt?1?(a)。- 注意: 如果有多個臂具有相同的最高估計值,可以隨機選擇其中一個,或按編號選擇第一個。
- 執行動作并觀察獎勵 (Execute Action & Observe Reward):
拉動選定的臂 A t A_t At?,得到獎勵 R t R_t Rt?。這個獎勵通常是從該臂的未知獎勵分布中采樣得到的。 - 更新估計值 (Update Estimates):
- 更新被選中臂 A t A_t At? 的計數: N t ( A t ) = N t ? 1 ( A t ) + 1 N_t(A_t) = N_{t-1}(A_t) + 1 Nt?(At?)=Nt?1?(At?)+1。
- 更新被選中臂 A t A_t At? 的獎勵估計值。常用的方法是增量式樣本均值:
Q t ( A t ) = Q t ? 1 ( A t ) + 1 N t ( A t ) [ R t ? Q t ? 1 ( A t ) ] Q_t(A_t) = Q_{t-1}(A_t) + \frac{1}{N_t(A_t)} [R_t - Q_{t-1}(A_t)] Qt?(At?)=Qt?1?(At?)+Nt?(At?)1?[Rt??Qt?1?(At?)]
這等價于:
Q t ( A t ) = 臂? A t 到目前為止獲得的總獎勵 臂? A t 到目前為止被選擇的總次數 Q_t(A_t) = \frac{\text{臂 } A_t \text{ 到目前為止獲得的總獎勵}}{\text{臂 } A_t \text{ 到目前為止被選擇的總次數}} Qt?(At?)=臂?At??到目前為止被選擇的總次數臂?At??到目前為止獲得的總獎勵? - 對于未被選擇的臂 a ≠ A t a \neq A_t a=At?,它們的計數和估計值保持不變: N t ( a ) = N t ? 1 ( a ) N_t(a) = N_{t-1}(a) Nt?(a)=Nt?1?(a), Q t ( a ) = Q t ? 1 ( a ) Q_t(a) = Q_{t-1}(a) Qt?(a)=Qt?1?(a)。
- 選擇動作 (Select Action):
-
結束 (End): 循環 T T T 次后結束。最終的 Q T ( a ) Q_T(a) QT?(a) 值代表了算法對每個臂平均獎勵的估計。算法在整個過程中獲得的總獎勵為 ∑ t = 1 T R t \sum_{t=1}^T R_t ∑t=1T?Rt?。
3. 優缺點
優點:
- 簡單性: 概念清晰,易于理解和實現。
- 保證探索: 只要 ? > 0 \epsilon > 0 ?>0,就能保證持續探索所有臂,避免完全陷入局部最優。
- 理論保證: 在一定條件下(如獎勵有界), ? \epsilon ?-Greedy 算法可以收斂到接近最優的策略。
缺點:
- 探索效率低: 探索時是完全隨機的,沒有利用已知信息。即使某個臂的估計值已經很低且置信度很高,仍然會以 ? K \frac{\epsilon}{K} K?? 的概率去探索它。
- 持續探索: 如果 ? \epsilon ? 是常數,即使在后期已經對各臂有了較好的估計,算法仍然會以 ? \epsilon ? 的概率進行不必要的探索,影響最終的總獎勵。使用衰減 ? \epsilon ? 可以緩解這個問題。
- 未考慮不確定性: 選擇利用哪個臂時,只看當前的估計值 Q ( a ) Q(a) Q(a),沒有考慮這個估計的不確定性。
2.2. UCB (Upper Confidence Bound) 算法
1. UCB (Upper Confidence Bound) 算法
核心思想:對于每個臂(老虎機),不僅要考慮它當前的平均獎勵估計值,還要考慮這個估計值的不確定性。一個臂被選擇的次數越少,我們對其真實平均獎勵的估計就越不確定。UCB 算法會給那些不確定性高(即被選擇次數少)的臂一個“獎勵加成”,使得它們更有可能被選中。這樣,算法傾向于選擇那些 潛力高(可能是當前最佳,或者因為嘗試次數少而有很大不確定性,可能被低估)的臂。
2. UCB 算法原理
UCB 算法在每個時間步 t t t 選擇臂 A t A_t At? 時,會計算每個臂 a a a 的一個置信上界分數,然后選擇分數最高的那個臂。這個分數由兩部分組成:
- 當前平均獎勵估計值 (Exploitation Term): Q t ? 1 ( a ) Q_{t-1}(a) Qt?1?(a),即到時間步 t ? 1 t-1 t?1 為止,臂 a a a 的平均觀測獎勵。這代表了我們當前對該臂價值的最好估計。
- 不確定性加成項 (Exploration Bonus): 一個基于置信區間的項,用于量化估計值的不確定性。常見的形式是 c ln ? t N t ? 1 ( a ) c \sqrt{\frac{\ln t}{N_{t-1}(a)}} cNt?1?(a)lnt??。
因此,選擇規則為:
A t = arg ? max ? a [ Q t ? 1 ( a ) + c ln ? t N t ? 1 ( a ) ] A_t = \arg\max_{a} \left[ Q_{t-1}(a) + c \sqrt{\frac{\ln t}{N_{t-1}(a)}} \right] At?=argamax?[Qt?1?(a)+cNt?1?(a)lnt??]
讓我們解析這個公式:
- Q t ? 1 ( a ) Q_{t-1}(a) Qt?1?(a): 臂 a a a 在 t ? 1 t-1 t?1 時刻的平均獎勵估計。
- N t ? 1 ( a ) N_{t-1}(a) Nt?1?(a): 臂 a a a 在 t ? 1 t-1 t?1 時刻之前被選擇的總次數。
- t t t: 當前的總時間步(總拉桿次數)。
- ln ? t \ln t lnt: 總時間步 t t t 的自然對數。隨著時間的推移, t t t 增大, ln ? t \ln t lnt 也緩慢增大,這保證了即使一個臂的 N ( a ) N(a) N(a) 很大,探索項也不會完全消失,所有臂最終都會被持續探索(盡管頻率會降低)。
- c c c: 一個正常數,稱為探索參數。它控制著不確定性加成項的權重。 c c c 越大,算法越傾向于探索; c c c 越小,越傾向于利用。理論上 c = 2 c=\sqrt{2} c=2? 是一個常用的選擇,但在實踐中可能需要調整。
工作機制:
- 如果一個臂 a a a 的 N t ? 1 ( a ) N_{t-1}(a) Nt?1?(a) 很小,那么分母 N t ? 1 ( a ) \sqrt{N_{t-1}(a)} Nt?1?(a)? 就很小,導致不確定性加成項很大。這使得該臂即使 Q t ? 1 ( a ) Q_{t-1}(a) Qt?1?(a) 不高,也有較高的 UCB 分數,從而被優先選擇(探索)。
- 隨著一個臂被選擇的次數 N ( a ) N(a) N(a) 增加,不確定性項會逐漸減小,UCB 分數將越來越依賴于實際的平均獎勵 Q ( a ) Q(a) Q(a)(利用)。
- ln ? t \ln t lnt 項確保了隨著時間的推移,即使是那些表現似乎較差的臂,只要它們的 N ( a ) N(a) N(a) 相對較小,其 UCB 分數也會緩慢增長,保證它們不會被完全放棄。
處理 N ( a ) = 0 N(a)=0 N(a)=0 的情況: 在算法開始時,為了避免分母為零,通常需要先將每個臂都嘗試一次。
3. UCB 算法實現步驟
假設有 K K K 個臂,總共進行 T T T 次試驗。
-
初始化 (Initialization):
- 設置探索參數 c > 0 c > 0 c>0。
- 為每個臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K 初始化獎勵估計值 Q 0 ( a ) = 0 Q_0(a) = 0 Q0?(a)=0 (或一個較大的初始值以鼓勵早期探索)。
- 為每個臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K 初始化被選擇的次數 N 0 ( a ) = 0 N_0(a) = 0 N0?(a)=0。
-
初始探索階段 (Initial Exploration Phase):
- 為了確保每個臂至少被選擇一次(避免后續計算 ln ? t N ( a ) \sqrt{\frac{\ln t}{N(a)}} N(a)lnt?? 時出現除以零),先將每個臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K 都拉動一次。
- 這通常會占用前 K K K 個時間步( t = 1 t=1 t=1 到 t = K t=K t=K)。對于每個 t = a t=a t=a (其中 a a a 從 1 到 K K K):
- 選擇臂 A t = a A_t = a At?=a。
- 執行動作,觀察獎勵 R t R_t Rt?。
- 更新 N t ( a ) = 1 N_t(a) = 1 Nt?(a)=1。
- 更新 Q t ( a ) = R t Q_t(a) = R_t Qt?(a)=Rt?。
- (其他臂的 N N N 和 Q Q Q 保持為 0 或初始值)。
-
主循環階段 (Main Loop): 對于時間步 t = K + 1 , . . . , T t = K+1, ..., T t=K+1,...,T:
- 計算所有臂的 UCB 分數: 對于每個臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K,計算其 UCB 值:
UCB t ( a ) = Q t ? 1 ( a ) + c ln ? t N t ? 1 ( a ) \text{UCB}_t(a) = Q_{t-1}(a) + c \sqrt{\frac{\ln t}{N_{t-1}(a)}} UCBt?(a)=Qt?1?(a)+cNt?1?(a)lnt??- 注意:此時 N t ? 1 ( a ) ≥ 1 N_{t-1}(a) \ge 1 Nt?1?(a)≥1 且 t ≥ K + 1 ≥ 2 t \ge K+1 \ge 2 t≥K+1≥2,所以 ln ? t ≥ ln ? 2 > 0 \ln t \ge \ln 2 > 0 lnt≥ln2>0。
- 選擇動作 (Select Action):
選擇具有最高 UCB 分數的臂:
A t = arg ? max ? a UCB t ( a ) A_t = \arg\max_{a} \text{UCB}_t(a) At?=argamax?UCBt?(a)- 如果存在多個臂具有相同的最高分數,可以隨機選擇其中一個。
- 執行動作并觀察獎勵 (Execute Action & Observe Reward):
拉動選定的臂 A t A_t At?,得到獎勵 R t R_t Rt?。 - 更新估計值 (Update Estimates):
- 更新被選中臂 A t A_t At? 的計數: N t ( A t ) = N t ? 1 ( A t ) + 1 N_t(A_t) = N_{t-1}(A_t) + 1 Nt?(At?)=Nt?1?(At?)+1。
- 使用增量式樣本均值更新被選中臂 A t A_t At? 的獎勵估計值:
Q t ( A t ) = Q t ? 1 ( A t ) + 1 N t ( A t ) [ R t ? Q t ? 1 ( A t ) ] Q_t(A_t) = Q_{t-1}(A_t) + \frac{1}{N_t(A_t)} [R_t - Q_{t-1}(A_t)] Qt?(At?)=Qt?1?(At?)+Nt?(At?)1?[Rt??Qt?1?(At?)] - 對于未被選擇的臂 a ≠ A t a \neq A_t a=At?,它們的計數和估計值保持不變: N t ( a ) = N t ? 1 ( a ) N_t(a) = N_{t-1}(a) Nt?(a)=Nt?1?(a), Q t ( a ) = Q t ? 1 ( a ) Q_t(a) = Q_{t-1}(a) Qt?(a)=Qt?1?(a)。
- 計算所有臂的 UCB 分數: 對于每個臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K,計算其 UCB 值:
-
結束 (End): 循環 T T T 次后結束。
4. 優缺點
優點:
- 智能探索: 相較于 ? \epsilon ?-Greedy 的隨機探索,UCB 的探索更有針對性,優先探索那些潛力更大(不確定性高)的臂。
- 無需設置 ? \epsilon ?: 它不需要像 ? \epsilon ?-Greedy 那樣設定探索概率 ? \epsilon ?(盡管需要設定探索參數 c c c)。
- 性能優越: 在許多平穩(Stationary)的 MAB 問題中,UCB 及其變種通常比 ? \epsilon ?-Greedy 表現更好,尤其是在試驗次數較多時。
- 良好的理論性質: UCB 算法有很強的理論支持,其累積遺憾(Regret)通常被證明是對數級別的( O ( log ? T ) O(\log T) O(logT)),這是非常理想的性能。
缺點:
- 需要知道總時間步 t t t: 標準 UCB 公式需要用到總時間步 t t t 的對數 ln ? t \ln t lnt。
- 對參數 c c c 敏感: 探索參數 c c c 的選擇會影響算法性能,可能需要根據具體問題進行調整。
- 對非平穩環境敏感: 標準 UCB 假設臂的獎勵分布是固定的(平穩的)。在獎勵分布隨時間變化的環境(非平穩)中,其性能可能會下降(因為舊的觀測數據可能不再準確)。有一些變種(如 D-UCB, SW-UCB)用于處理非平穩環境。
- 計算開銷: 每次選擇都需要計算所有臂的 UCB 分數,雖然計算量不大,但比 ? \epsilon ?-Greedy 的貪婪選擇略高。
2.3. Thompson Sampling 湯普森采樣算法
1. Thompson Sampling 算法簡介
核心思想:
- 維護信念分布: 對每個臂 a a a 的未知獎勵參數(例如,伯努利臂的成功概率 p a p_a pa?)維護一個后驗概率分布。這個分布反映了基于已觀察到的數據,我們對該參數可能取值的信念。
- 采樣: 在每個時間步 t t t,為每個臂 a a a 從其當前的后驗分布中抽取一個樣本值 θ a \theta_a θa?。這個樣本可以被看作是該臂在當前信念下的一個“可能”的真實參數值。
- 選擇: 選擇具有最大采樣值 θ a \theta_a θa? 的那個臂 A t A_t At?。
- 更新信念: 觀察所選臂 A t A_t At? 的獎勵 R t R_t Rt?,然后使用貝葉斯定理更新臂 A t A_t At? 的后驗分布,將新的觀測信息融合進去。
這種方法的巧妙之處在于,選擇臂的概率自動與其后驗分布中“該臂是最優臂”的概率相匹配。
- 如果一個臂的后驗分布集中在較高的值(即我們很確定它很好),那么從中采樣的值很可能最高,該臂被選中的概率就高(利用)。
- 如果一個臂的后驗分布很寬(即我們對它的真實值很不確定),那么即使其均值不是最高,它也有機會采樣到一個非常高的值而被選中,從而實現探索。
2. Thompson Sampling 算法原理
在這種情況下,通常使用 Beta 分布 作為成功概率 p a p_a pa? 的先驗和后驗分布,因為 Beta 分布是伯努利似然函數的共軛先驗 (Conjugate Prior)。這意味著,如果先驗是 Beta 分布,并且觀測數據來自伯努利分布,那么后驗分布仍然是 Beta 分布,只是參數會更新。
- Beta 分布: Beta ( α , β ) (\alpha, \beta) (α,β) 由兩個正參數 α \alpha α 和 β \beta β 定義。其均值為 α α + β \frac{\alpha}{\alpha + \beta} α+βα?。 α \alpha α 可以看作是“觀測到的成功次數 + 1”, β \beta β 可以看作是“觀測到的失敗次數 + 1”(這里的“+1”來自一個常見的 Beta(1,1) 均勻先驗)。分布的形狀由 α \alpha α 和 β \beta β 控制,當 α + β \alpha+\beta α+β 增大時,分布變得更窄,表示不確定性降低。
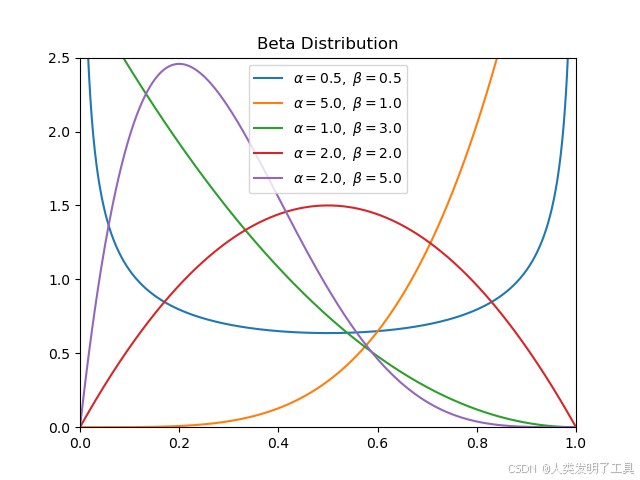
算法流程中的關鍵步驟:
- 初始化: 為每個臂 a a a 設置 Beta 分布的初始參數,通常為 α a = 1 , β a = 1 \alpha_a = 1, \beta_a = 1 αa?=1,βa?=1。這對應于一個 Beta(1, 1) 分布,即 [0, 1] 上的均勻分布,表示在沒有任何觀測數據之前,我們認為 p a p_a pa? 在 [0, 1] 區間內取任何值的可能性都相同。
- 采樣: 在每個時間步 t t t,為每個臂 a a a 從其當前的后驗分布 Beta ( α a , β a ) (\alpha_a, \beta_a) (αa?,βa?) 中獨立抽取一個隨機樣本 θ a \theta_a θa?。
- 選擇: 選擇使得 θ a \theta_a θa? 最大的臂 A t = arg ? max ? a θ a A_t = \arg\max_a \theta_a At?=argmaxa?θa?。
- 更新: 假設選擇了臂 A t A_t At? 并觀察到獎勵 R t ∈ { 0 , 1 } R_t \in \{0, 1\} Rt?∈{0,1} :
- 每個臂 a a a 的獎勵是 0 (失敗) 或 1 (成功)
- 如果 R t = 1 R_t = 1 Rt?=1 (成功),則更新臂 A t A_t At? 的參數: α A t ← α A t + 1 \alpha_{A_t} \leftarrow \alpha_{A_t} + 1 αAt??←αAt??+1。
- 如果 R t = 0 R_t = 0 Rt?=0 (失敗),則更新臂 A t A_t At? 的參數: β A t ← β A t + 1 \beta_{A_t} \leftarrow \beta_{A_t} + 1 βAt??←βAt??+1。
- 未被選擇的臂的參數保持不變。
隨著觀測數據的增加,每個臂的 Beta 分布會變得越來越集中(方差減小),反映了我們對其真實成功概率 p a p_a pa? 的信念越來越確定。
3. Thompson Sampling 算法實現步驟
假設有 K K K 個臂,總共進行 T T T 次試驗。
-
初始化 (Initialization):
- 對于每個臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K:
- 設置 Beta 分布參數 α a = 1 \alpha_a = 1 αa?=1。
- 設置 Beta 分布參數 β a = 1 \beta_a = 1 βa?=1。
- 對于每個臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K:
-
循環執行 (Loop): 對于時間步 t = 1 , 2 , . . . , T t = 1, 2, ..., T t=1,2,...,T:
- 采樣階段 (Sampling Phase):
- 對于每個臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K:
- 從 Beta 分布 Beta ( α a , β a ) (\alpha_a, \beta_a) (αa?,βa?) 中抽取一個隨機樣本 θ a \theta_a θa?。
- (這需要一個能夠從 Beta 分布生成隨機數的函數庫,例如 Python 的
numpy.random.beta)。
- 對于每個臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K:
- 選擇動作 (Select Action):
- 找到使得樣本值 θ a \theta_a θa? 最大的臂:
A t = arg ? max ? a ∈ { 1 , . . . , K } θ a A_t = \arg\max_{a \in \{1, ..., K\}} \theta_a At?=arga∈{1,...,K}max?θa? - 如果存在多個臂具有相同的最大樣本值,可以隨機選擇其中一個。
- 找到使得樣本值 θ a \theta_a θa? 最大的臂:
- 執行動作并觀察獎勵 (Execute Action & Observe Reward):
- 拉動選定的臂 A t A_t At?,得到獎勵 R t ∈ { 0 , 1 } R_t \in \{0, 1\} Rt?∈{0,1}。
- 更新后驗分布 (Update Posterior):
- 如果 R t = 1 R_t = 1 Rt?=1:
α A t ← α A t + 1 \alpha_{A_t} \leftarrow \alpha_{A_t} + 1 αAt??←αAt??+1 - 如果 R t = 0 R_t = 0 Rt?=0:
β A t ← β A t + 1 \beta_{A_t} \leftarrow \beta_{A_t} + 1 βAt??←βAt??+1
- 如果 R t = 1 R_t = 1 Rt?=1:
- 采樣階段 (Sampling Phase):
-
結束 (End): 循環 T T T 次后結束。
4. 優缺點
優點:
- 性能優異: 在實踐中,Thompson Sampling 通常表現非常好,經常優于或至少媲美 UCB 算法,尤其是在累積獎勵方面。
- 概念優雅且自然: 基于貝葉斯推理,提供了一種原則性的方式來處理不確定性并通過概率匹配來平衡探索與利用。
- 易于擴展: 可以相對容易地適應不同的獎勵模型(如高斯獎勵,只需將 Beta-Bernoulli 更新替換為 Normal-Normal 或 Normal-Inverse-Gamma 更新)。
- 無需手動調整探索參數: 不像 ? \epsilon ?-Greedy 的 ? \epsilon ? 或 UCB 的 c c c 需要仔細調整(雖然先驗選擇也可能影響性能,但通常對標準先驗如 Beta(1,1) 較為魯棒)。
- 良好的理論性質: 具有較好的理論累積遺憾界。
缺點:
- 需要指定先驗: 作為貝葉斯方法,需要為參數選擇一個先驗分布。雖然通常有標準選擇(如 Beta(1,1)),但在某些情況下先驗的選擇可能影響早期性能。
- 計算成本: 需要在每個時間步從后驗分布中采樣。對于 Beta 分布,采樣通常很快,但對于更復雜的模型,采樣可能比 UCB 的直接計算更耗時。
- 實現略復雜: 相較于 ? \epsilon ?-Greedy,需要理解貝葉斯更新規則并使用能進行分布采樣的庫。






/FormatMessage 的區別)

)

檢測工具)






)

