在當今大數據時代,企業對于實時數據分析的需求呈現爆發式增長。面對動輒PB級的數據量和秒級響應的業務訴求,傳統數據庫系統往往力不從心。Apache Doris作為新一代MPP分析型數據庫,憑借其獨特的索引機制,在京東、美團等企業的實時數倉場景中展現出卓越性能。本文將深入解析Doris索引設計的精妙之處。
與傳統的OLTP數據庫不同,Doris作為OLAP系統面臨著完全不同的挑戰:海量數據(單表千億級)、復雜查詢(多表Join+聚合)、實時響應(亞秒級延遲)。在這種場景下,Doris選擇了多層次互補型索引體系,通過不同粒度的索引配合,在存儲空間(僅增加5%-10%)和查詢效率之間找到完美平衡點。
其核心設計原則可概括為:
- 智能路由:通過元數據快速定位數據塊
- 分層過濾:從分區級到列級的遞進式篩選
- 計算下推:在存儲層完成最大限度的過濾
Doris 索引分類
前綴稀疏索引
Apache Doris 數據庫存儲在類似 SSTable 的數據結構中,SSTable 是一種有序的數據結構,可以按照指定的一個或多個列進行排序存儲。在查詢時加上排序列,Doris 不需要掃描全表即可快速找到需要處理的數據,降低搜索復雜度。
除了排序健,Doris 還會每隔 1024 行數據創建一個稀疏前綴索引,索引中的 Key 是當前 1024 行中第一行中排序列的值。和傳統數據庫的單列或多列索引不同,Doris 將表數據的前序列字段組成前綴索引,最大長度不超過 36 字節。比如在以下的表結構中,前綴索引中保存的數據為:user_id(8 Bytes) + age(4 Bytes) + message(prefix 20 Bytes)。
| ColumnName | Type |
|---|---|
| user_id | BIGINT |
| age | INT |
| message | VARCHAR(100) |
| max_dwell_time | DATETIME |
| min_dwell_time | DATETIME |
這里需要注意的是,前綴索引遇到 VARCHAR 類型會自動截斷,即使沒有達到 36 個字節。所以在設計前綴索引時,如果不是特別需求,不建議將 VARCHAR 字段放在最前面。
在查找前綴索引表時可以通過索引確定該行數據所在的邏輯數據塊的起始行號,由于前綴索引比較小,可以全量緩存在內存中,快速定位數據塊,提升查詢效率。
倒排索引
倒排索引將文本分成一個個詞,構建詞->文檔編號的索引,Table 的一行對應一個文檔、一列對應文檔中的一個字段。對創建了倒排索引的列,建立每個值到對應行號集合的倒排表。
倒排索引的使用范圍很廣泛,可以加速等值、范圍、全文檢索等多種類型的操作。一個表可以有多個倒排索引,查詢時多個倒排索引的條件可以任意組合。對于等值查詢,先從倒排表中查到行號集合,然后直接讀取對應行的數據,而不用逐行掃描匹配數據,從而減少 I/O 加速查詢。
創建倒排索引時可以通過 PROPERTIES 參數指定分詞器和分詞模式,滿足更加個性化的需求。
BloomFileter 索引
BloomFilter 索引是基于 BloomFilter 的一種跳數索引,原理是利用 BloomFilter 跳過等值查詢指定條件不滿足的數據塊,達到減少 I/O、加速查詢的目的。通常應用在一些需要快速判斷某個元素是否屬于集合,但并不嚴格要求 100%正確的場合。
BloomFilter 是由 Bloom 在 1970 年提出的一種多哈希函數映射的快速查找算法,由一個超長的二進制位數組和一系列的哈希函數組成。二進制位數組初始全部為 0,當給定一個待查詢的元素時,這個元素會被一系列哈希函數計算映射出一系列的值,所有的值在位數組的偏移量處置為 1。
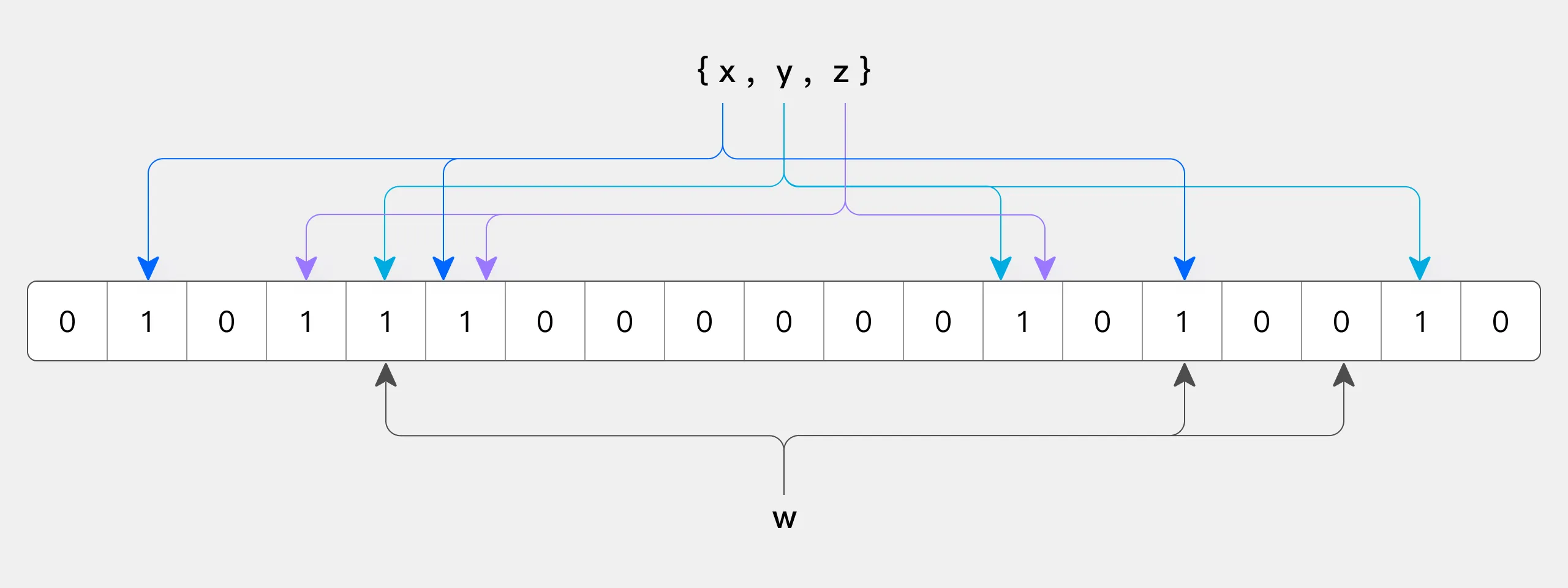
Doris BloomFilter 索引以數據塊(page)為單位構建,每個數據塊存儲一個 BloomFilter。寫入時,對于數據塊中的每個值,經過 Hash 存入數據塊對應的 BloomFilter。查詢時,根據等值條件的值,判斷每個數據塊對應的 BloomFilter 是否包含這個值,不包含則跳過對應的數據塊不讀取,達到減少 I/O 查詢加速的目的。
ZoneMap 索引
ZoneMap 索引自動維護每一列的統計信息,為每一個數據文件和數據塊記錄最大值、最小值以及是否包含 NULL 值。對于等值查詢、范圍查詢、IS NULL,可以通過最大值、最小值、是否有 NULL 來判斷數據文件和數據塊是否可以包含滿足條件的數據,如果沒有則跳過不讀對應的文件或數據塊減少 I/O 加速查詢。
前綴索引和 ZoneMap 索引是 Apache Doris 自動維護的內建智能索引,無需用戶管理。
索引特性總結
最后為了大家學習的方便,將各種索引的優缺點匯總如下。
| 類型 | 索引 | 優點 | 局限 |
|---|---|---|---|
| 點查索引 | 前綴索引 | 內置索引,性能最好 | 一個表只有一組前綴索引 |
| 點查索引 | 倒排索引 | 支持分詞和關鍵詞匹配,任意列可建索引,多條件組合,持續增加函數加速 | 索引存儲空間較大,與原始數據相當 |
| 跳數索引 | ZoneMap 索引 | 內置索引,索引存儲空間小 | 支持的查詢類型少,只支持等于、范圍 |
| 跳數索引 | BloomFilter 索引 | 比 ZoneMap 更精細,索引空間中等 | 支持的查詢類型少,只支持等于 |
| 跳數索引 | NGram BloomFilter 索引 | 支持 LIKE 加速,索引空間中等 | 支持的查詢類型少,只支持 LIKE 加速 |

是一種結構化配置語言)
實踐)


(含模型、可運行代碼、數據))
![[學習]RTKLib詳解:pntpos.c與postpos.c](http://pic.xiahunao.cn/[學習]RTKLib詳解:pntpos.c與postpos.c)
)

)



識別與重構指南)
)

)


)