【Linux深入淺出】之全連接隊列及抓包介紹
- 理解listen系統調用函數的第二個參數
- 簡單實驗
- 實驗目的
- 實驗設備
- 實驗代碼
- 實驗現象
- 全連接隊列簡單理解
- 什么是全連接隊列
- 全連接隊列的大小
- 從Linux內核的角度理解虛擬文件、sock、網絡三方的關系
- 回顧虛擬文件部分的知識
- struct socket結構體介紹
- struct tcp_sock與struct udp_sock介紹
- struct tcp_sock
- struct inet_connection_sock結構體
- struct inet_sock結構體
- 總結
- struct udp_sock
- Tcp接收緩沖區與發送緩沖區
- 分層介紹
- tcp抓包介紹
- Linux中使用tcp dump進行抓包并分析tcp過程
- tcp dump的安裝
- tcp dump的簡單使用
- 實驗
- windows中使用wireshark進行抓包
- wireshark的安裝
- 使用telnet作為客戶端訪問云服務器上的服務器程序
- 設置wireshark過濾規則
- 使用wireshark進行抓包
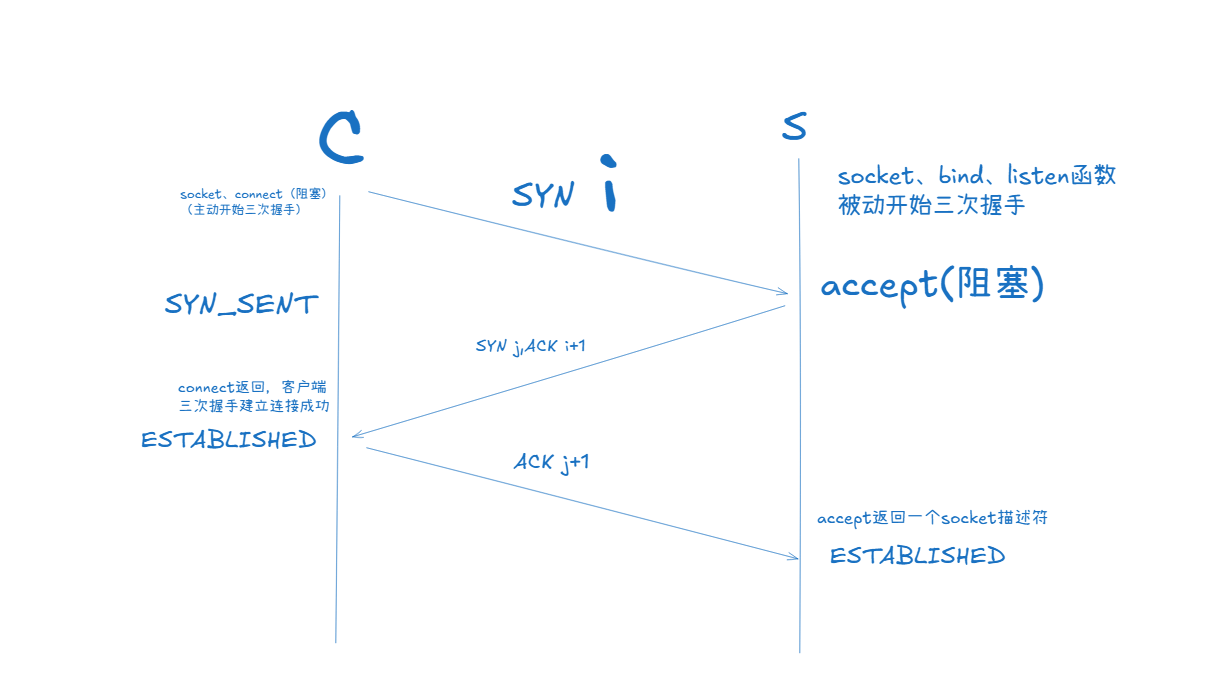
理解listen系統調用函數的第二個參數
listen函數是在進行TCP socket編程時的系統調用函數,它的功能是將普通套接字設置為監聽狀態,也就是將普通的套接字變成監聽套接字,以便它能收到來自客戶端的連接請求。

第一個參數是我們之前創建的socket描述符,那么第二個參數應該如何理解呢?直接輸出結論:backlog規定了全連接隊列的最大長度,全連接隊列是用于維護三次握手成功但是系統來不及接收的連接,backlog+1是這個隊列的長度。
簡單實驗
實驗目的
下面我們將做一個小實驗,這個實驗主要會驗證如下幾個點:
- 三次握手成功建立連接,并不需要
accept的參與,因為它是系統自動完成的,accept只是負責從全連接隊列中取走已經建立好的連接。 - backlog+1 = 全連接隊列的長度。
因為accept函數會取走全連接隊列中的連接,而且我們的實驗就是模擬系統非常忙的情況,所以 TCP server端是不需要調用accept函數的。
實驗設備
虛擬機一臺,云服務器一臺。
在同一臺設備上會影響實驗效果,因為TCP連接是雙向的,從服務器->客戶端,客戶端->服務器都會維護一個連接,所以如果在一臺設備上做實驗,會有干擾。
實驗代碼
-
TcpServer.cc:#include <iostream> #include <string> #include <cerrno> #include <cstring> #include <cstdlib> #include <memory> #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <sys/wait.h> #include <unistd.h>const static int default_backlog = 1;enum {Usage_Err = 1,Socket_Err,Bind_Err,Listen_Err };#define CONV(addr_ptr) ((struct sockaddr *)addr_ptr)class TcpServer { public:TcpServer(uint16_t port) : _port(port), _isrunning(false){}// 都是固定套路void Init(){// 1. 創建socket, file fd, 本質是文件_listensock = socket(AF_INET, SOCK_STREAM, 0);if (_listensock < 0){exit(0);}int opt = 1;setsockopt(_listensock, SOL_SOCKET, SO_REUSEADDR | SO_REUSEPORT, &opt, sizeof(opt));// 2. 填充本地網絡信息并bindstruct sockaddr_in local;memset(&local, 0, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(_port);local.sin_addr.s_addr = htonl(INADDR_ANY);// 2.1 bindif (bind(_listensock, CONV(&local), sizeof(local)) != 0){exit(Bind_Err);}// 3. 設置socket為監聽狀態,tcp特有的if (listen(_listensock, default_backlog) != 0){exit(Listen_Err);}}void ProcessConnection(int sockfd, struct sockaddr_in &peer){uint16_t clientport = ntohs(peer.sin_port);std::string clientip = inet_ntoa(peer.sin_addr);std::string prefix = clientip + ":" + std::to_string(clientport);std::cout << "get a new connection, info is : " << prefix << std::endl;while (true){char inbuffer[1024];ssize_t s = ::read(sockfd, inbuffer, sizeof(inbuffer)-1);if(s > 0){inbuffer[s] = 0;std::cout << prefix << "# " << inbuffer << std::endl;std::string echo = inbuffer;echo += "[tcp server echo message]";write(sockfd, echo.c_str(), echo.size());}else{std::cout << prefix << " client quit" << std::endl;break;}}}void Start(){_isrunning = true;while (_isrunning){sleep(1);}}~TcpServer(){}private:uint16_t _port;int _listensock; // TODObool _isrunning; };using namespace std;void Usage(std::string proc) {std::cout << "Usage : \n\t" << proc << " local_port\n"<< std::endl; } // ./tcp_server 8888 int main(int argc, char *argv[]) {if (argc != 2){Usage(argv[0]);return Usage_Err;}uint16_t port = stoi(argv[1]);std::unique_ptr<TcpServer> tsvr = make_unique<TcpServer>(port);tsvr->Init();tsvr->Start();return 0; } -
TcpClient.cc:#include <iostream> #include <string> #include <unistd.h> #include <sys/socket.h> #include <sys/types.h> #include <arpa/inet.h> #include <netinet/in.h>int main(int argc, char **argv) {if (argc != 3){std::cerr << "\nUsage: " << argv[0] << " serverip serverport\n"<< std::endl;return 1;}std::string serverip = argv[1];uint16_t serverport = std::stoi(argv[2]);int clientSocket = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);if (clientSocket < 0){std::cerr << "socket failed" << std::endl;return 1;}sockaddr_in serverAddr;serverAddr.sin_family = AF_INET;serverAddr.sin_port = htons(serverport); // 替換為服務器端口serverAddr.sin_addr.s_addr = inet_addr(serverip.c_str()); // 替換為服務器IP地址int result = connect(clientSocket, (struct sockaddr *)&serverAddr, sizeof(serverAddr));if (result < 0){std::cerr << "connect failed" << std::endl;::close(clientSocket);return 1;}while (true){std::string message;std::cout << "Please Enter@ ";std::getline(std::cin, message);if (message.empty())continue;send(clientSocket, message.c_str(), message.size(), 0);char buffer[1024] = {0};int bytesReceived = recv(clientSocket, buffer, sizeof(buffer) - 1, 0);if (bytesReceived > 0){buffer[bytesReceived] = '\0'; // 確保字符串以 null 結尾std::cout << "Received from server: " << buffer << std::endl;}else{std::cerr << "recv failed" << std::endl;}}::close(clientSocket);return 0; }
實驗現象
-
驗證:即使服務器端沒有調用
accpet函數,三次握手也能建立連接成功: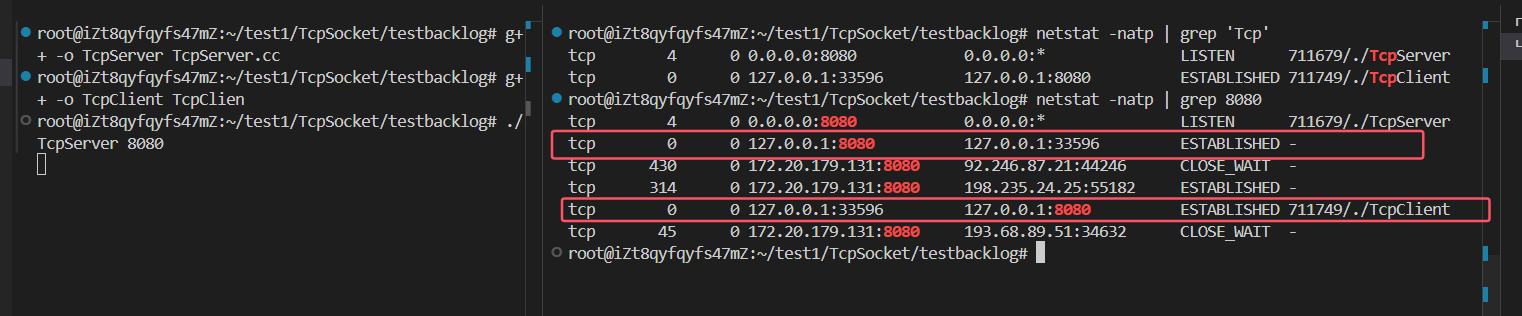
- 結論:
accept系統調用函數并不參與三次握手,它只負責從下層取走連接(socket文件描述符)。
- 結論:
-
驗證
Tcp全連接最多維護backlog+1個連接: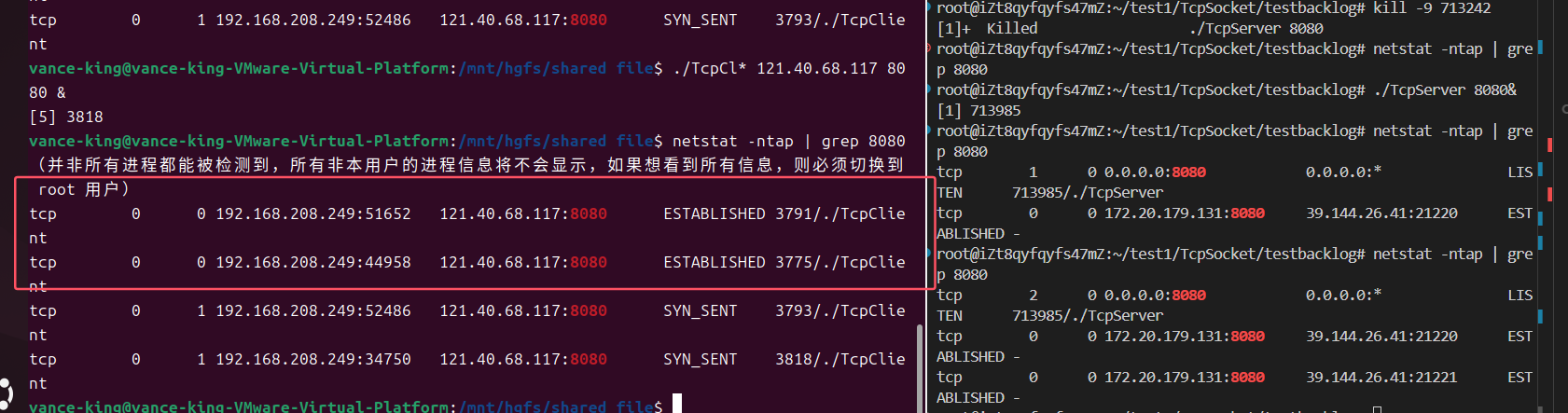
- 可以看到,我們在虛擬機中同時運行了多個
TcpClient客戶端,但最終只有兩個成功建立連接,這是因為全連接的大小不夠了所以不會接收來自客戶端的連接,只有上層調用accept拿走在全連接隊列中已經建立的連接,全連接的空間才會騰出來。
全連接隊列簡單理解
什么是全連接隊列
全連接隊列就是我們內核(傳輸層)中某個結構體中維護的一個隊列,每一個listen套接字都有一個全連接隊列:
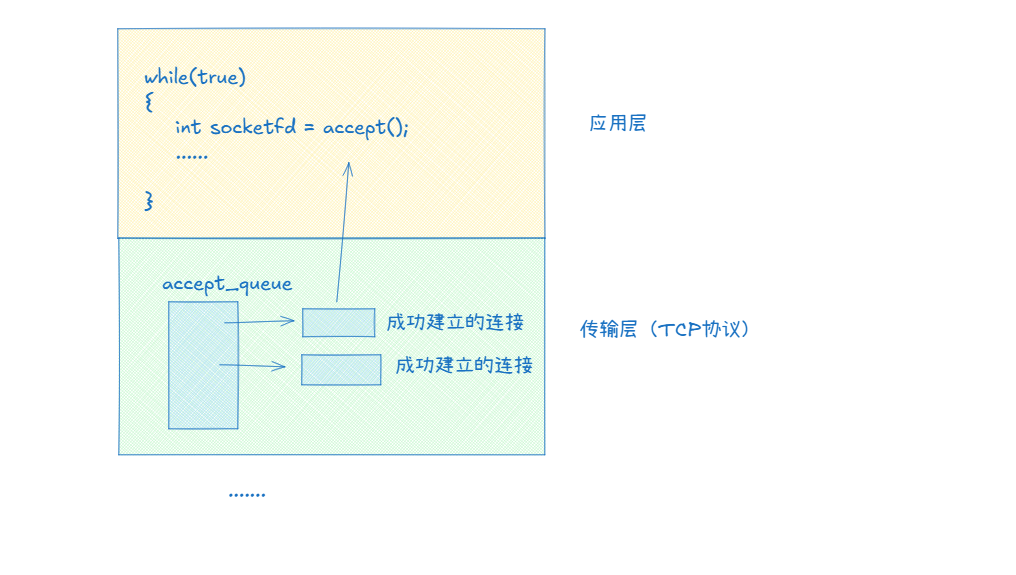
在Linux內核中所謂的連接和全連接隊列都是struct結構體,后面我們會結合Linux內核重點介紹。
- 注意:全連接隊列的大小并不是代表TcpServer服務器只能同時處理這么多,而是表示它來不及處理(來不及調用
accept)的連接的最大數量。
全連接隊列的大小
全連接隊列的本質其實是生產者消費者模型,全連接隊列作為生產者一直生產連接,而上層的accept作為消費者一直從全連接隊列中取走連接。
全連接隊列的大小不能太大,也不能太小:
- 如果backlog為0:會增加服務器的閑置率,如果有全連接隊列,那么可能只需要等待一會,服務器就有空閑可以把連接取走處理了,如果
backlog為0,直接就是三次握手建立不成功,用戶就以為你的服務已經崩潰,短時間內就不會訪問了。 - 如果backlog過大:那么處于全連接隊列結尾的用戶就可能需要等待很久來能享受到服務,這樣用戶體驗不好,還不如直接連接失敗,而且維護連接也會占用內存,用多余的內存去給服務器處理數據可能效率更高。
過去,常用的默認值可能是5或者50左右,但是現代Linux系統的默認值通常要高得多。
通常這個值有一個上限,我的Linux系統中為4096:
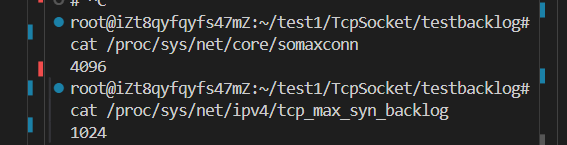
/proc/sys/net/core/somaxconn:這個內核參數定義了系統范圍內每個端口的最大監聽隊列長度。它設置了listen()函數中backlog參數的上限值。tcp_max_syn_backlog:這個文件中規定的是未完成連接請求的最大數量(半連接隊列)。
從Linux內核的角度理解虛擬文件、sock、網絡三方的關系
回顧虛擬文件部分的知識
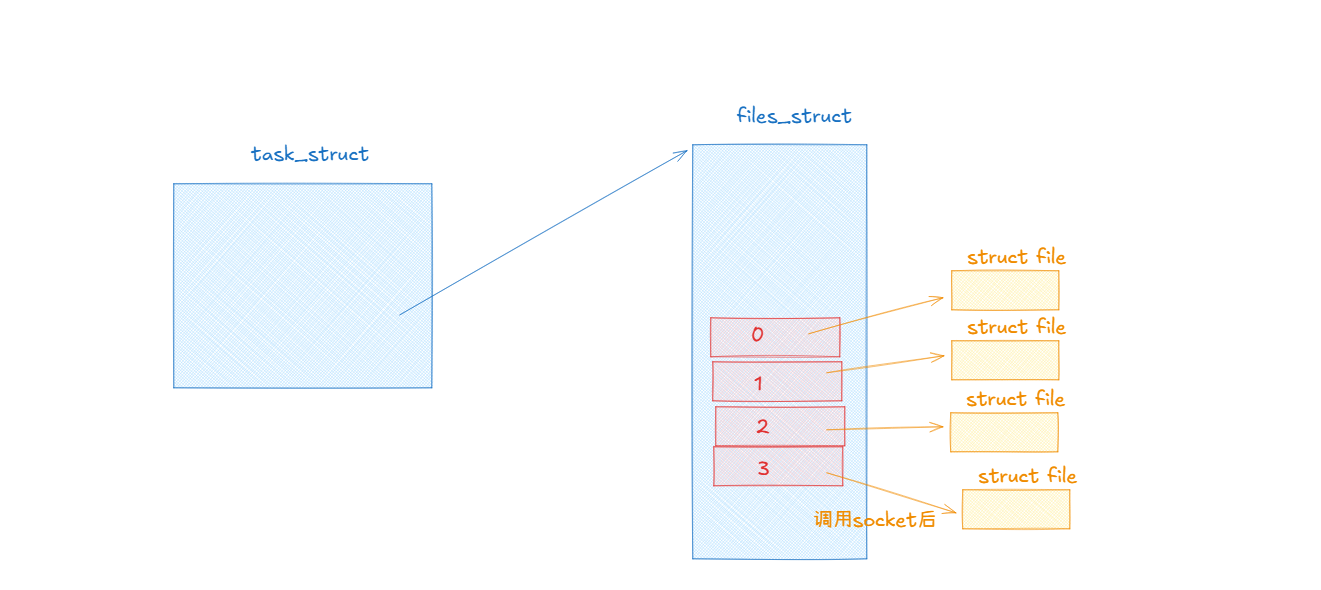
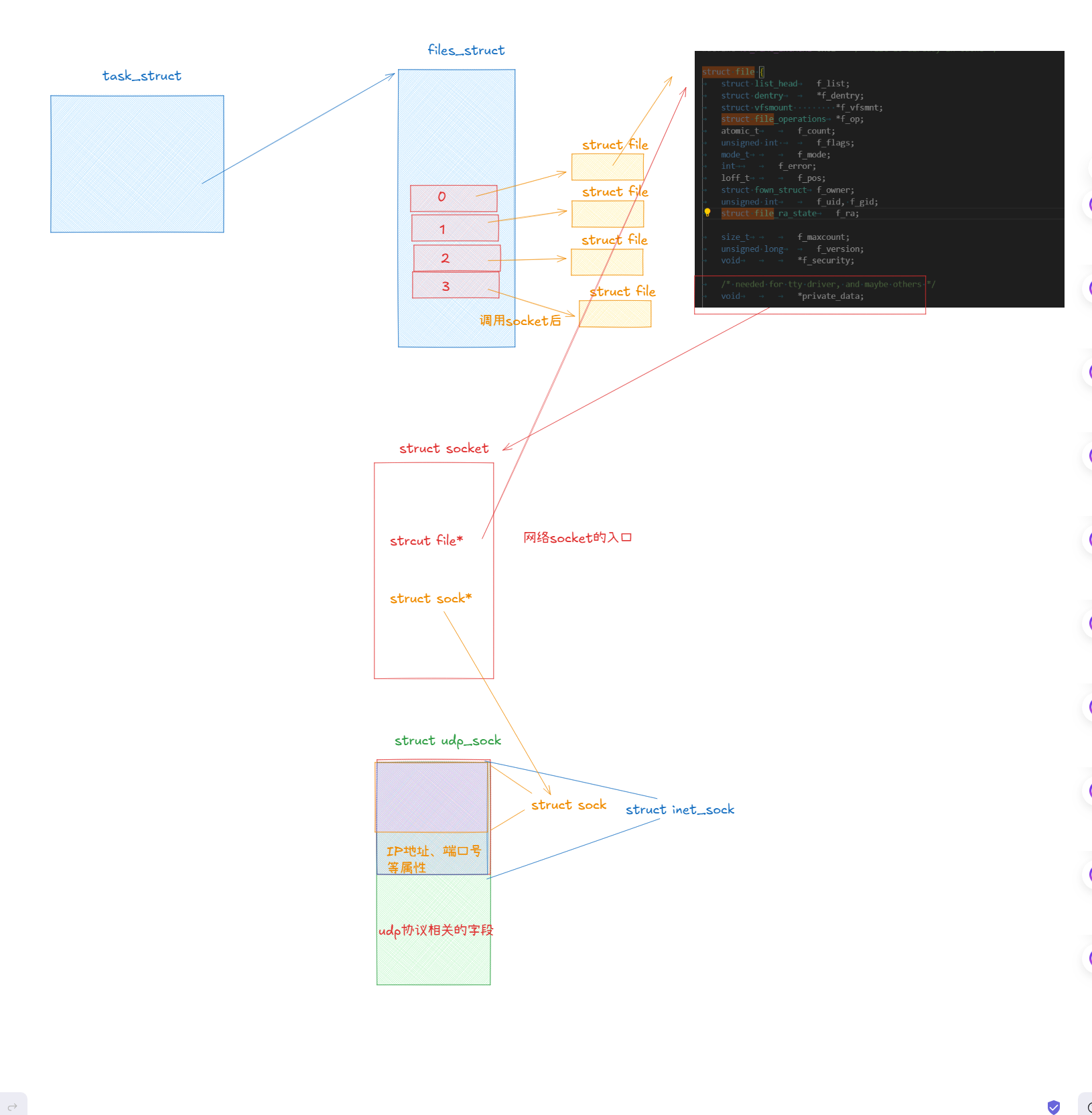
我們都知道在運行服務器程序后,系統會給這個進程創建一個task_struct結構體,它是用來描述進程的,這個結構體中又會有一個file_struct*的指針,它指向了一個file_struct的對象,這個file_struct結構體是用來管理打開的文件的,它里面有一個文件描述符表,這個文件描述符表中的每一個下標都指向struct file*對象。
但是我們的網絡socket是怎么和struct file這個結構體掛上聯系的呢?這是我們今天要解決的問題之一,因為文件描述表中的文件描述符不僅僅有普通文件的還有網絡套接字文件。
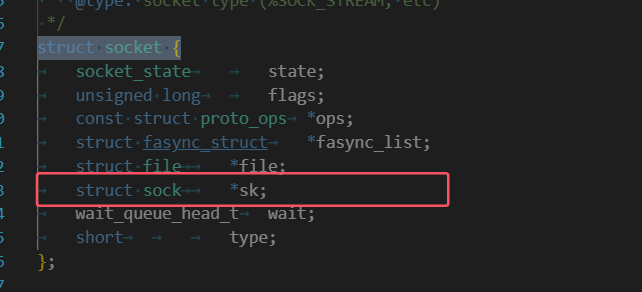
struct socket結構體介紹
struct socket {socket_state state;unsigned long flags;struct proto_ops *ops;struct fasync_struct *fasync_list;struct file *file;struct sock *sk;wait_queue_head_t wait;short type;unsigned char passcred;
};
struct socket結構體是我們網絡socket的入口,它是一個通用的套接字類型。
-
short type:表示套接字的類型,是流式套接字還是數據報式的套接字: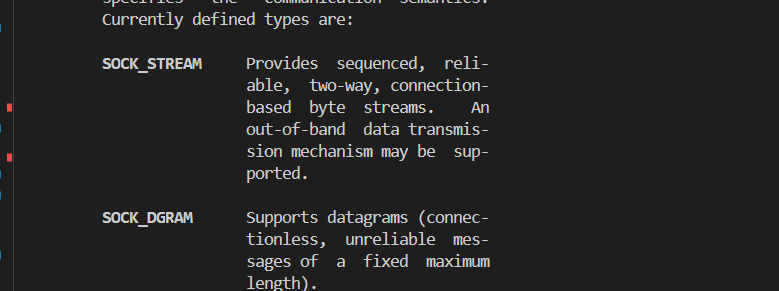
-
struct proto_ops *ops:它是一個保存各種函數方法的類型,可以通過type字段讓其指向不同的方法。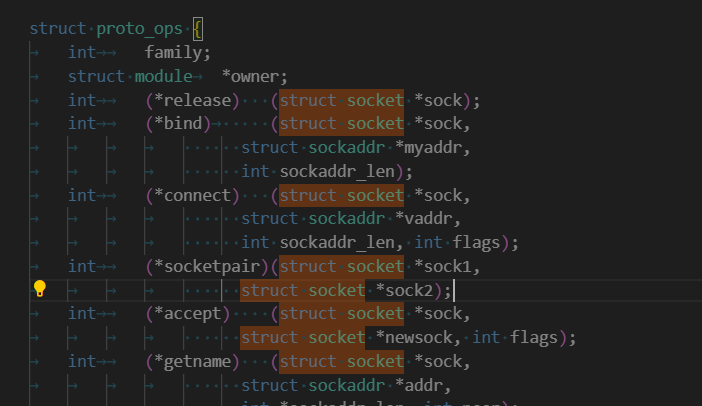
-
struct file*:指向虛擬文件層的struct file對象,但是我們不是需要通過socket文件描述符找到struct socket嘛,怎么順序反過來,別擔心,其實struct file對象中也有一個開放字段是可以指向struct socket對象的,它就是void*類型的private_data字段。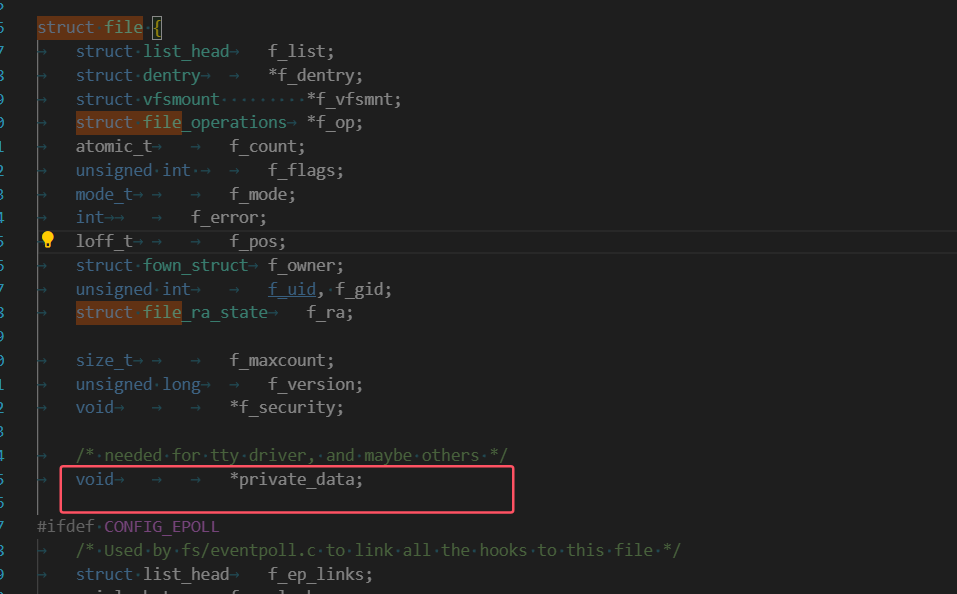
所以經過對struct socket結構體的學習,我們上面的圖可以繼續完善:
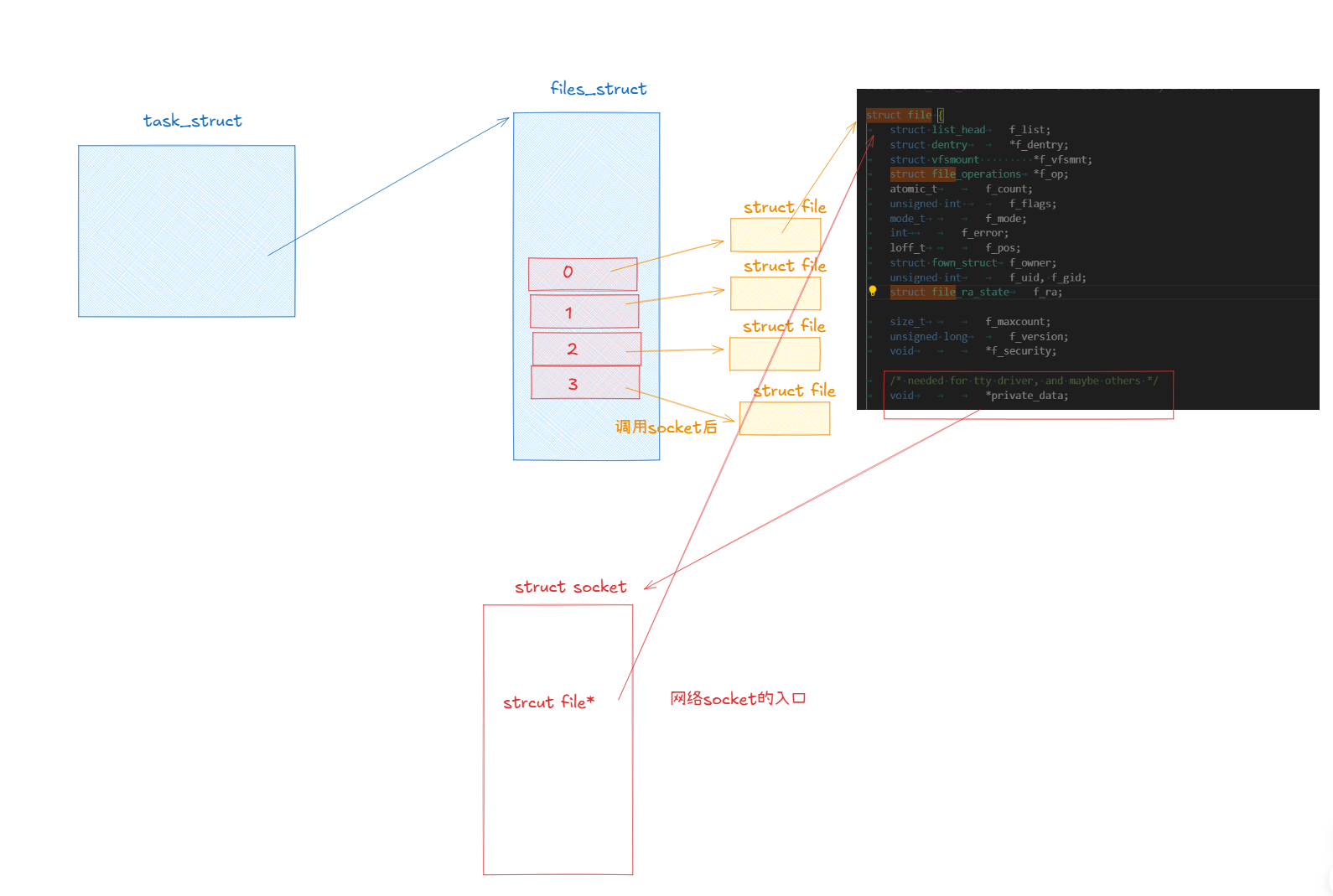
并且調用socket系統調用的同時就創建了struct socket、struct file并在文件描述表中申請了空間,然后還讓struct socket與struct file互相指向。
那Tcp Socket與Udp Socket豈不是沒有區別了,既然調用socket都會創建struct socket的話,別急,我們繼續往下學習。
struct tcp_sock與struct udp_sock介紹
struct tcp_sock
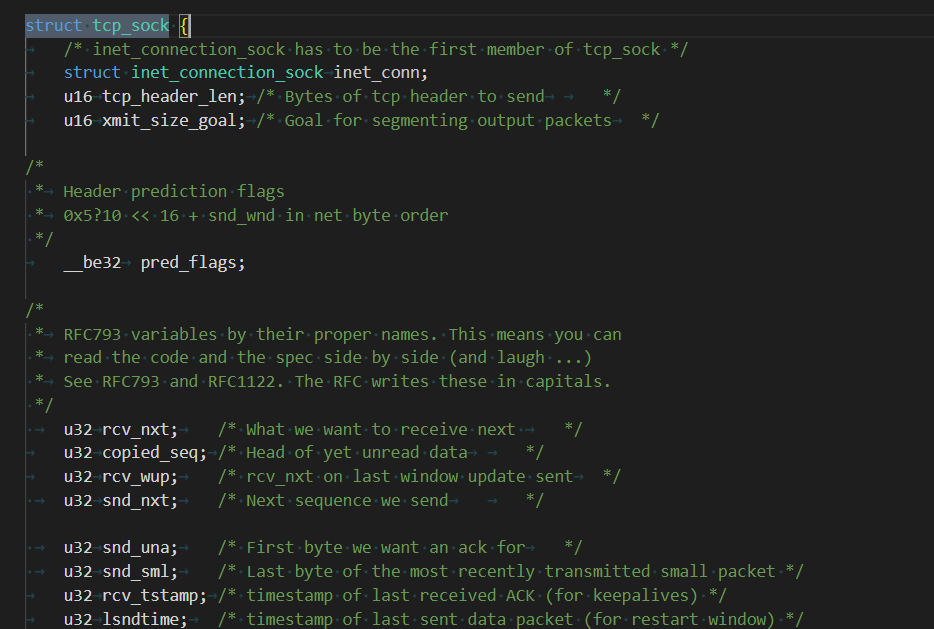
tcp_sock結構體中有很多關于tcp的字段,譬如:
int tcp_header_len:即將要發送的TCP報文的頭部的長度,以字節為單位。rcv_nxt, snd_nxt: 分別表示期望接收的下一個序列號和發送方即將發送的下一個序列號。snd_ssthresh, snd_cwnd: 慢啟動閾值和擁塞窗口大小,是擁塞控制的重要參數。
但我們更想知道,它的第一個字段struct inet_connection_sock是什么:
struct inet_connection_sock inet_conn;:光看其名稱,這個結構體肯定與連接有關。
struct inet_connection_sock結構體
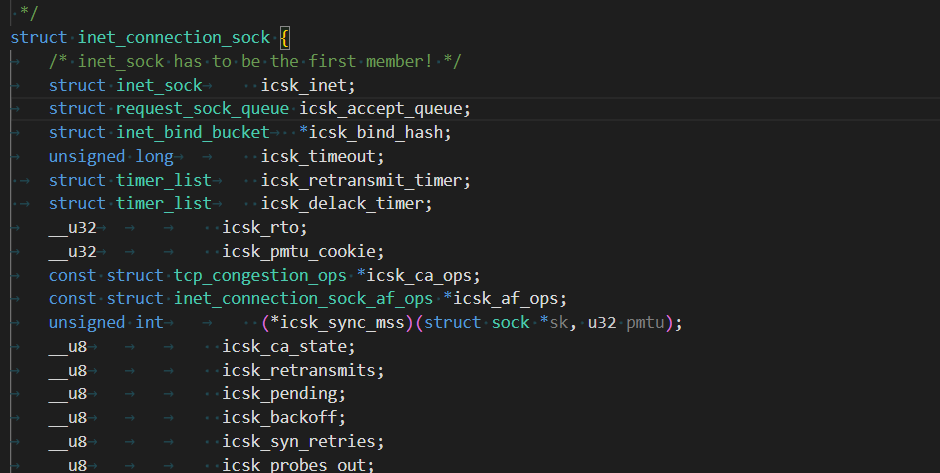
這個結構體是描述的TCP與連接相關的屬性,里面包括了全連接隊列。全連接隊列中不僅維護三次握手已經建立好的連接,也會維護只進行了二次或者一次的半連接,但是半連接的生命周期一般很短。
-
struct request_sock_queue icsk_accept_queue;:這個字段就是我們之前一直在談的全連接隊列,它由listensock維護,用于管理監聽套接字上的半連接(SYN_RCVD狀態)和全連接(ESTABLISHED狀態但未被accept()接受)隊列。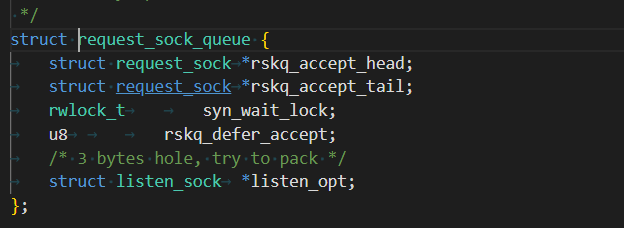
但我們最好奇的是它的第一個屬性字段:
struct inet_sock inet:這是一個struct inet_sock類型的成員,包含了通用的因特網套接字信息。tcp_sock以此為基礎,添加TCP特定的信息。
struct inet_sock結構體
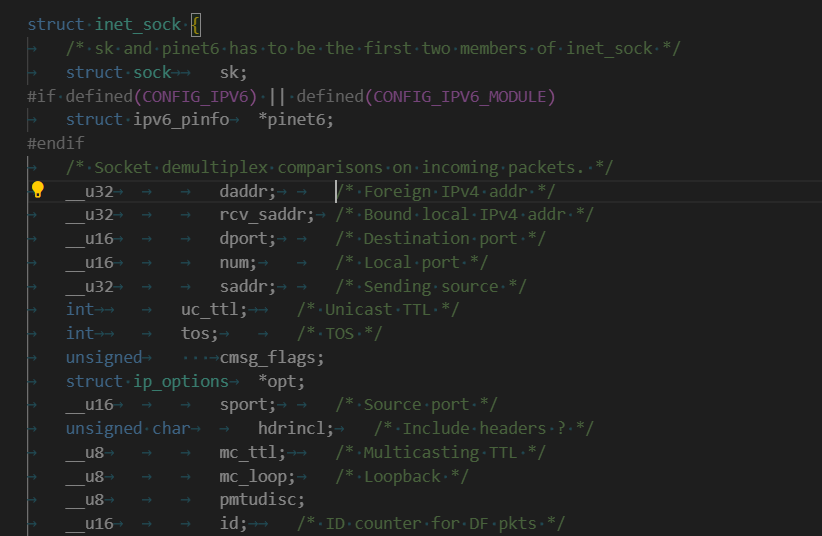
struct inet_sock結構體中存儲的是與網絡通信相關的信息,例如:
_u32 daddr:外部IPv4地址。_u32 rcv_saddr:本地IPv4地址。_u32 dport:目的端口號。
我們進行Tcp網絡通信,調用bind系統調用函數bindIP地址和端口號,不就是在往這個struct inet_sock結構體中寫數據嗎?
我們驚奇的發現這個inet_sock結構體的第一個字段的類型居然是struct sock,我們之前不是在struct socket里面見過這個字段嗎,讓struct socket指向它,不就可以通過通用套接字訪問到Tcpsock了嗎?
所以我們預測udp_sock中一定也存在struct sock字段,而且一定是在最前面。
總結
看了這么多結構體,我們可以畫圖總結一下它們的關系了:
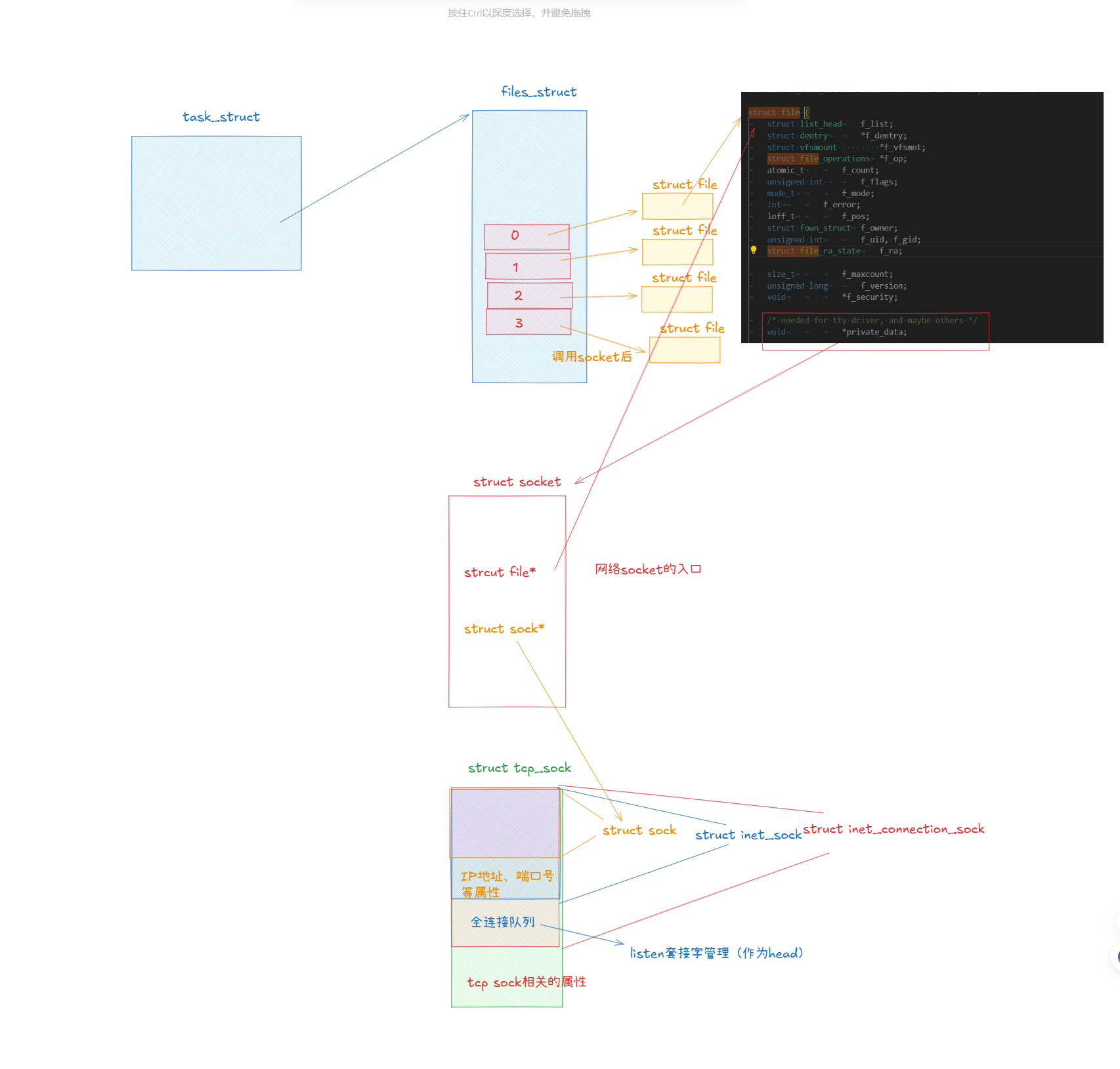
后續只需要通過socket中的struct sock*字段,通過強制類型轉化,我們就可以訪問到struct sock、struct inet_sock、struct inet_connection_sock、struct tcp_sock結構體的內容,因為它們的初始地址都是相同的,這樣通過結構體嵌套,我們就實現了C風格的多態。
那么當我們客戶端和服務器經過三次握手后,建立了一個新的連接,內核會幫助我們做哪些事情呢?
-
最最重要的是創建
struct inet_connection_sock,這表示一個新的連接,里面的inet_sock字段存儲著這個連接相關的屬性字段(IP地址、端口號)。 -
然后就是
struct tcp_sock對象,三次握手完成,內核實際上已經為這個新建立的連接創建了完整的struct tcp_sock結構體。它不僅包含了inet_connection_sock中的所有字段,還添加了許多TCP特有的屬性和方法,例如序列號管理、窗口縮放、重傳機制等。每當一個新的TCP連接被接受(即完成了三次握手),就會創建一個tcp_sock實例來管理這個連接的狀態和行為。 -
除此之外,內核還會將這個連接(隊尾的
next的struct sock*指向新連接的struct sock)加入listen套接字的全連接隊列中(做類似鏈表的操作),然后需要將隊列的元素個數加1。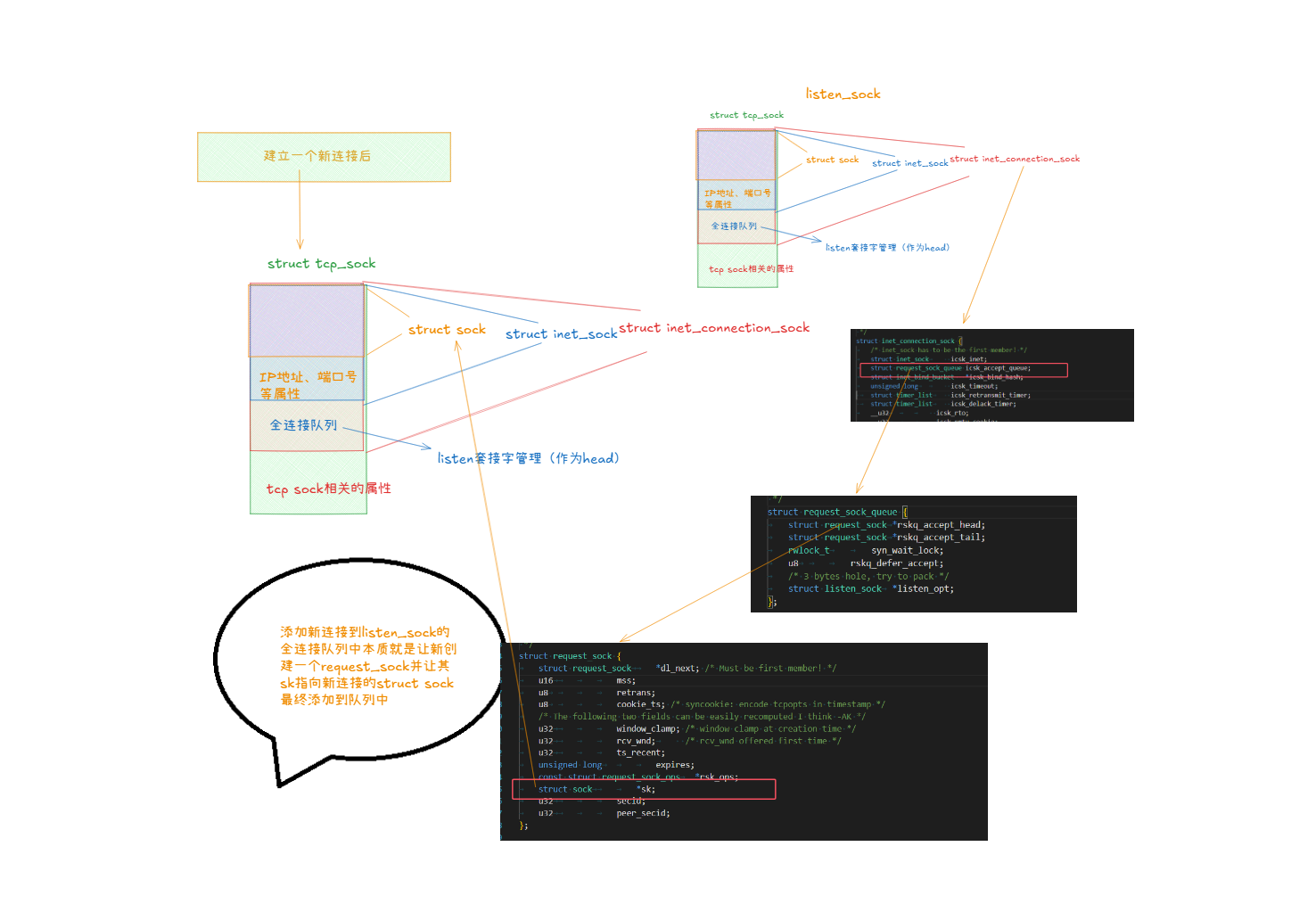
內核中會有實現上述功能的方法: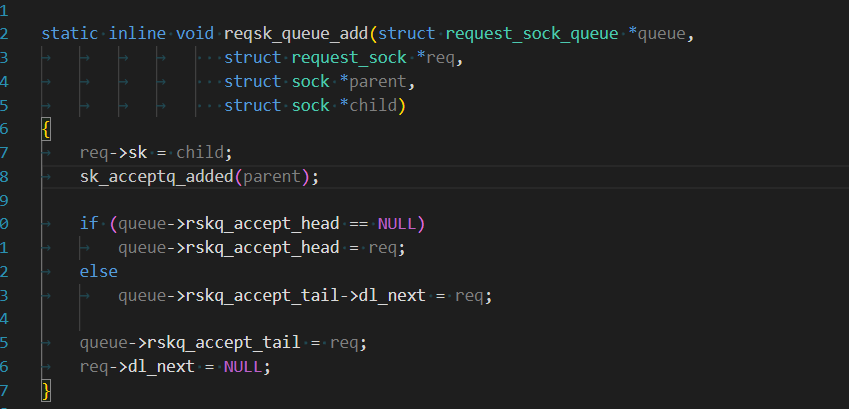
如果全連接隊列中沒有空間了,三次握手根本就不會完成,也就不會創建上述的結構體。
當調用accept函數時,它會做如下事情:
-
創建
struct socket對象(三次握手完成時并沒有創建這個通用的套接字類型),然后從全連接隊列中取出隊頭連接的struct sock*,然后賦值給struct socket的struct sock*變量,就相當與讓struct socket指向了struct tcp_sock,因為struct tcp_sock的最開始的字段是struct sock*。 -
創建
struct file,并在文件描述符表中開辟一個新的空間指向這個struct file對象。 -
最后,讓
struct file與struct socket互相引用。 -
返回文件描述符給上層。
內核中的方法
sock_map_fd就是實現類似功能的。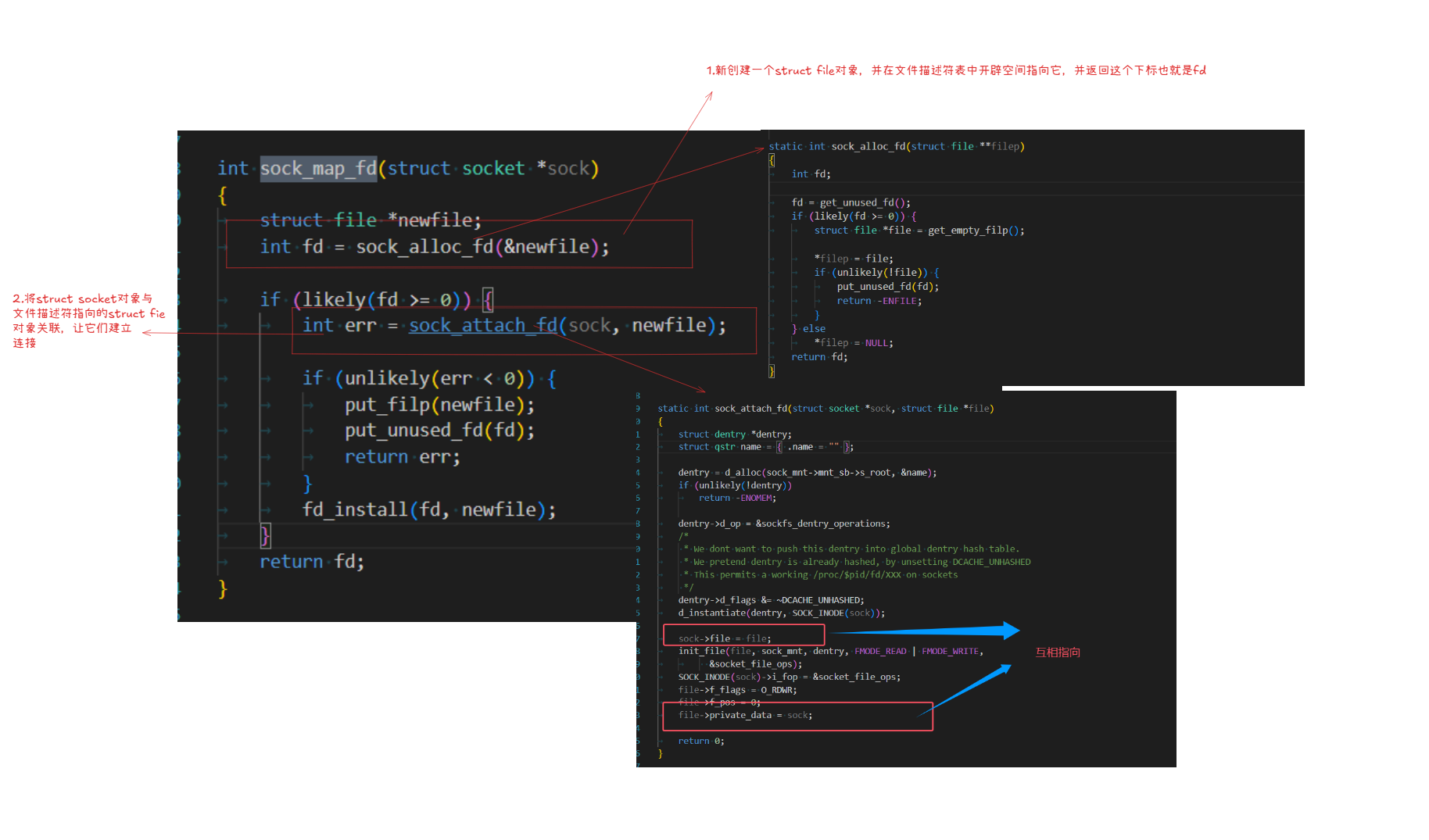
自此之后,我們就可以通過socket fd找到struct file,然后通過struct file中的private_data字段找到struct socket對象,而通用套接字的sk又指向struct tcp_sock的首地址空間的struct sock對象。然后通過強制類型轉換,可以訪問tcp這個連接相關的任何信息,包括報文、擁塞控制屬性、滑動窗口屬性、確認應答相關屬性(序號、確認序號)。
struct udp_sock
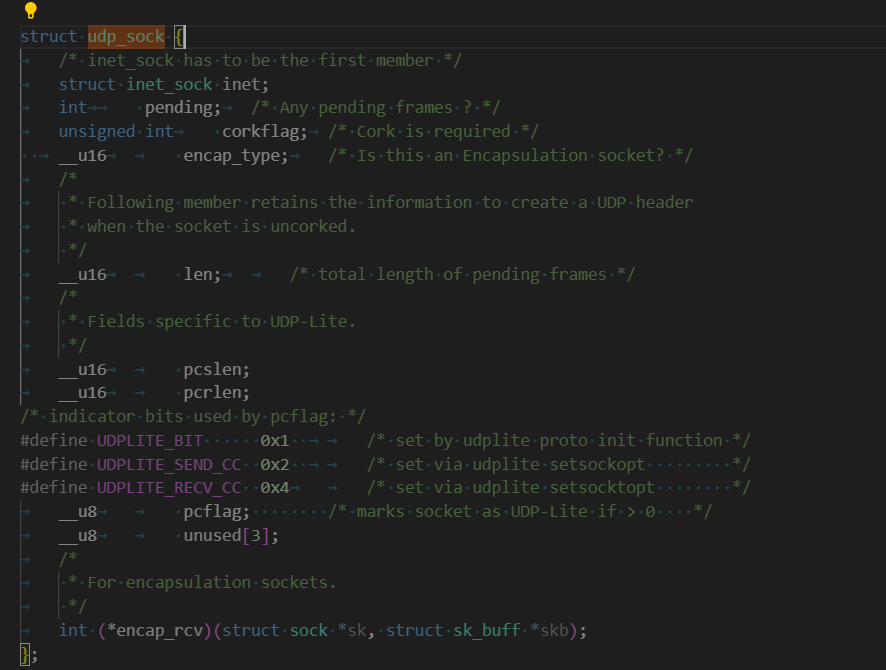
由于udp協議比tcp協議要簡單,所以udp_sock結構體的字段也要少一些。
而且由于udp是無連接的協議,所以它沒有連接相關的字段,它的第一個結構體對象就直接是struct inet_sock結構體。這和tcp的inet_sock是一樣的,因為網絡套接字部分兩者有很多相同的部分,所以可以復用。
對于udp_sock就是這樣:
Tcp接收緩沖區與發送緩沖區
我們前面不是一直談到TCP存在接收緩沖區和發送緩沖區嗎?它們在內核中是否有體現呢?
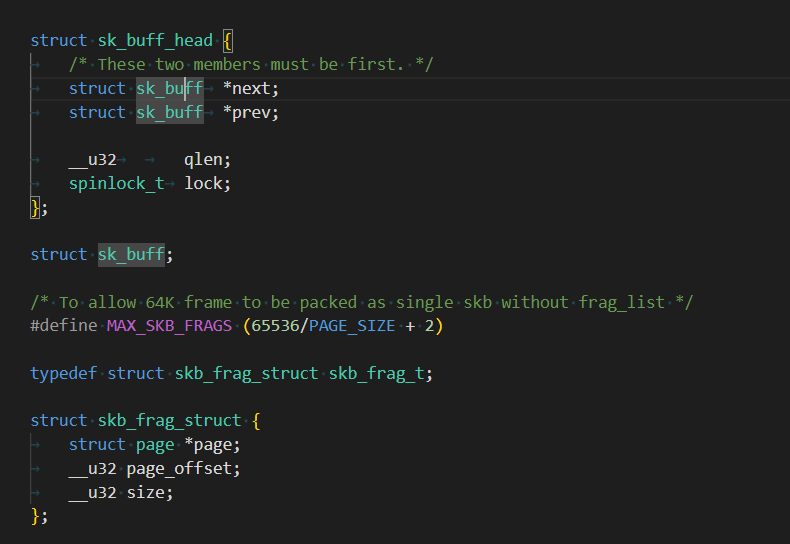
當然有,在struct sock結構體中,存在著這兩個字段:

它們就是接收緩沖區與發送緩沖區,每個連接都有單獨的struct sock,也就意味著有單獨的接收緩沖區與發送緩沖區。
sk_buff_head是這個緩沖區的類型,它是一個類似隊列的結構體:
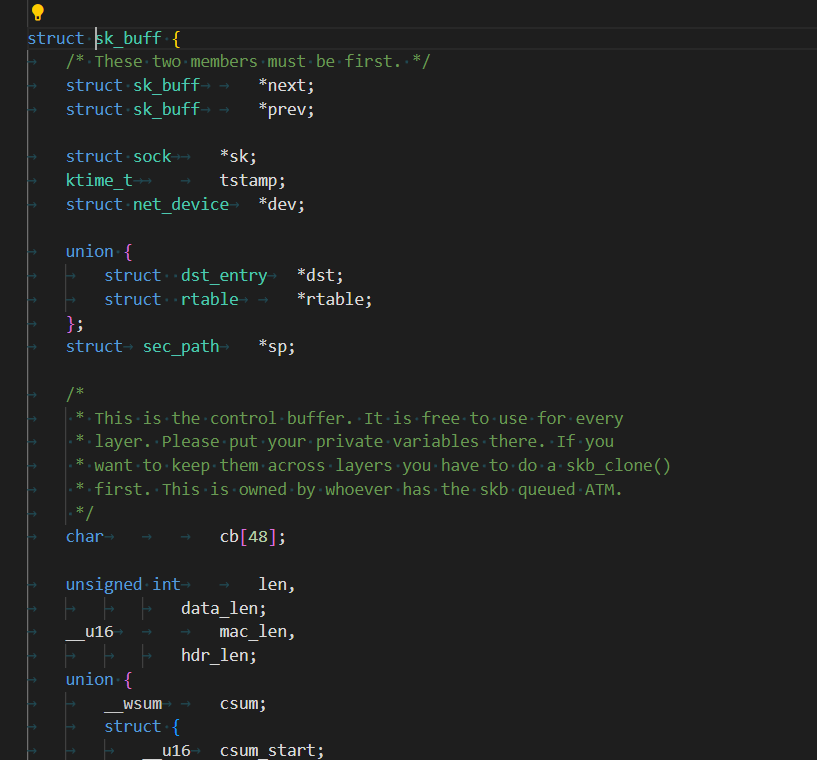
struct sk_buff是描述報文的,也就是解析出來或者即將發送的應用層的報文:
分層介紹
自此之后,虛擬文件、socket、網絡三者的關系我們就清楚了,我們也清楚了如何通過文件描述符找到關于套接字的各種信息。
它們自上而下是有層次的,可以分為虛擬文件層、通用套接字層和網絡套接字層。其中通用套接字就像是一個基類,它提供了一種通用的方式來創建各種類型的套接字,但是當網絡真的建立起來,又會有其它細微的不同。
tcp抓包介紹
Linux中使用tcp dump進行抓包并分析tcp過程
tcp dump的安裝
ubuntu下:
sudo apt update
sudp apt install -y tcpdump
通過檢查版本號驗證是否安裝成功:
tcpdump --version

tcp dump的簡單使用
-
捕獲所有網絡接口中的報文:
sudo tcpdump -i any tcp-i:interface是接口的意思,any代表任何,-i any的意思就是捕獲所以網絡接口中的報文。tcp:只捕獲tcp報文。
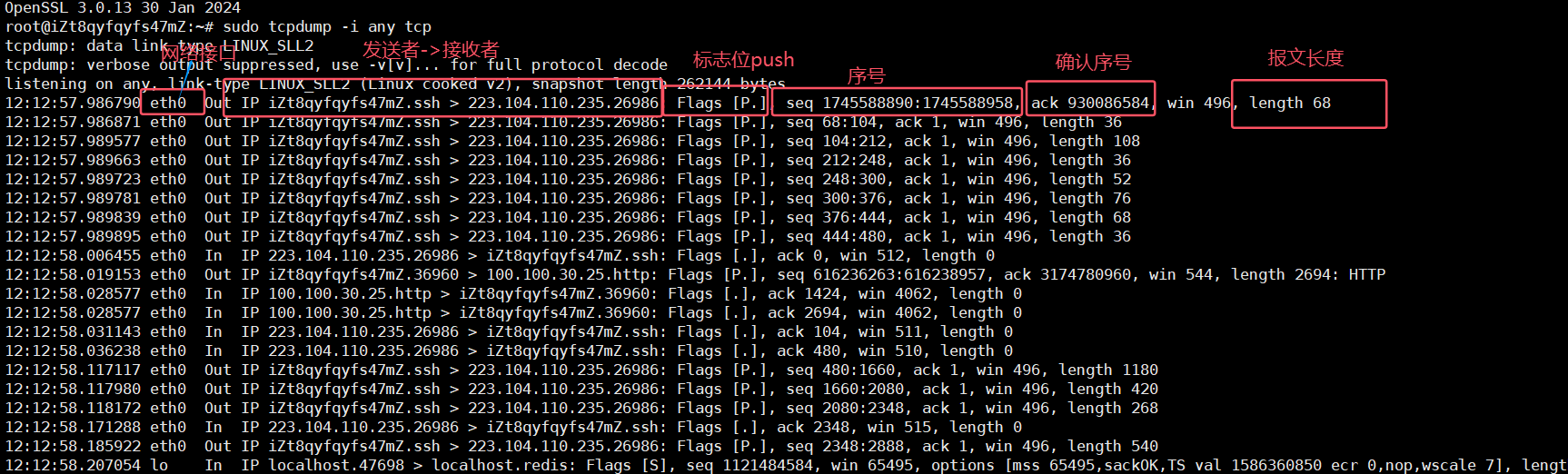
-
捕獲指定網絡接口的報文:
sudo tcpdump -i [本機某網絡接口名稱] tcp我們可以通過命令
ifconfig查看本主機的所有網絡接口: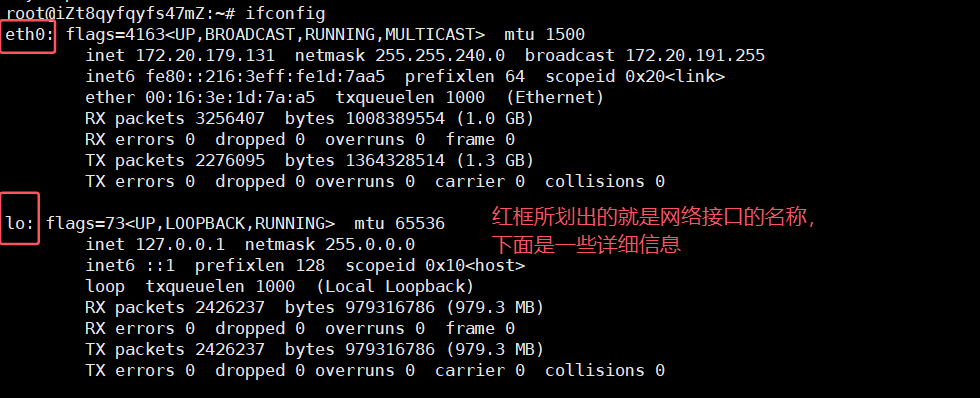
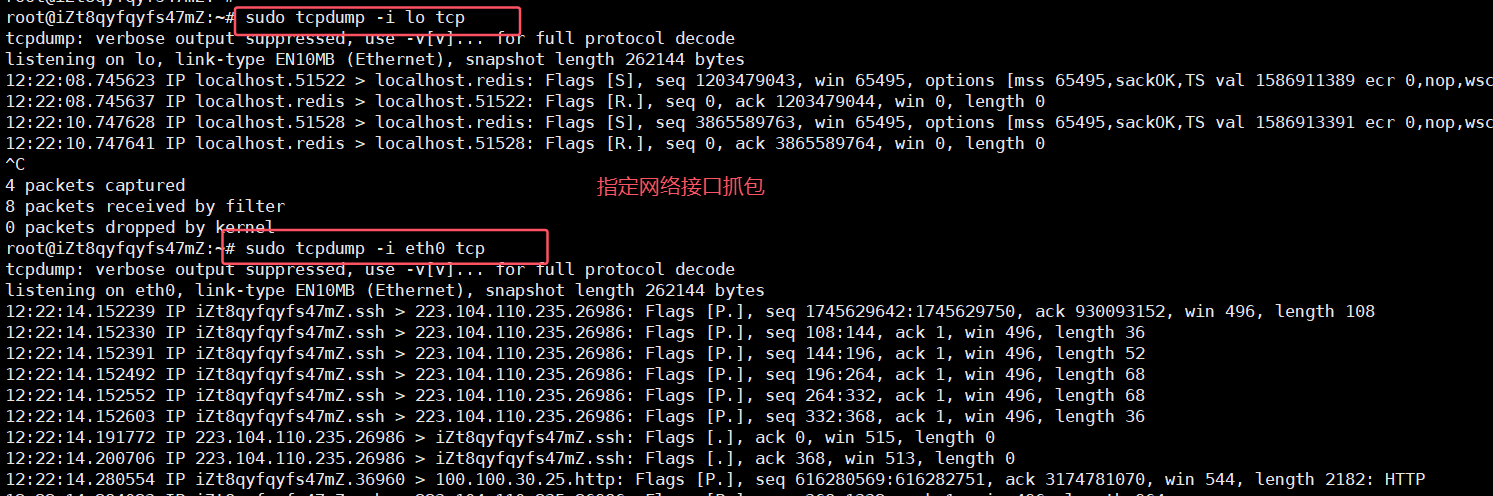
-
捕獲指定源IP的報文:
sudo tcpdump src host 192.168.0.1 and tcp上述命令的含義是:捕獲源IP地址為
192.168.0.1的到達本主機的tcp報文: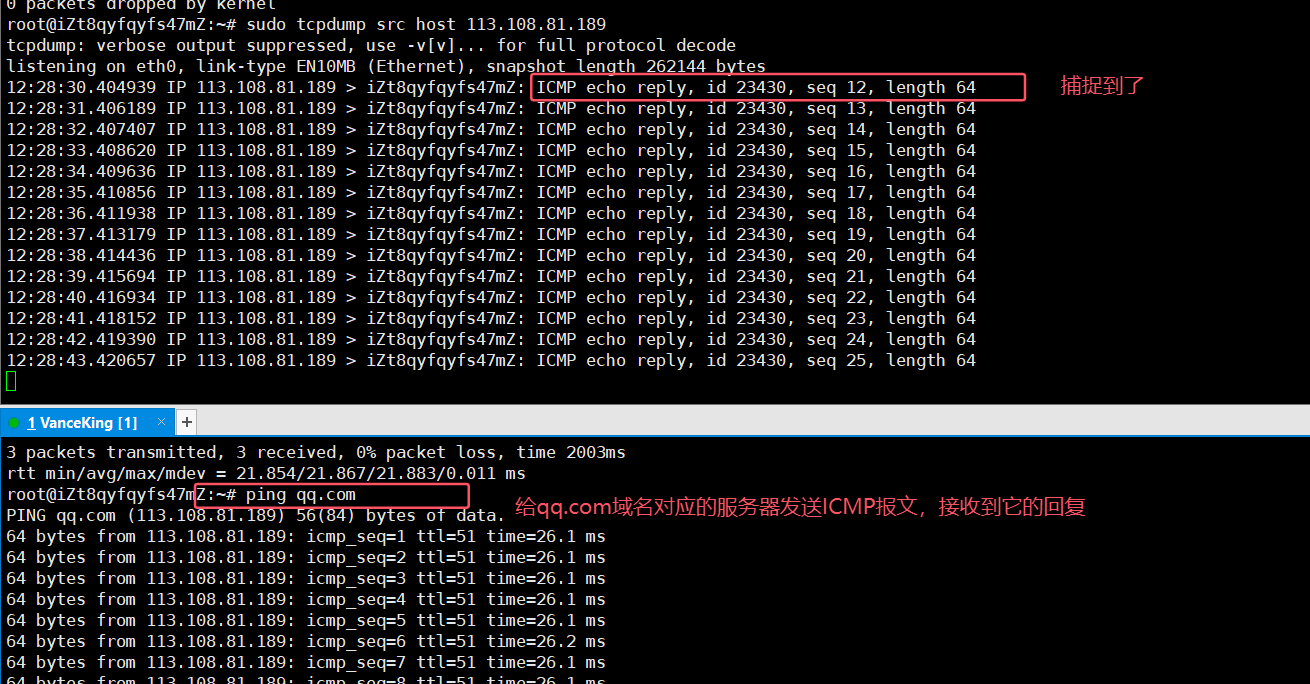
-
現在的一般后端服務器都會使用反向代理來實現負載均衡技術,在大型應用或服務中,通常會部署多個反向代理服務器以提高性能、增加可用性和提供冗余。所以可能就會出現多次
ping qq.com這個相同的域名,得到來自不同公網IP服務器的回復,這也不用驚訝,所以上面的實驗存在一定的運氣的成分。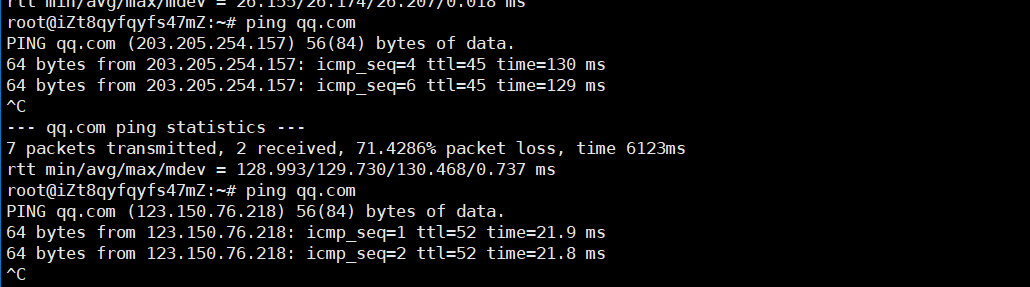
- 上面的顯示的
公網IP可能是反向代理服務器的IP地址,而不是后端服務真正的公網IP。
- 上面的顯示的
-
-
捕獲指定目的IP地址的報文:
sudo tcpdump dst host 192.168.0.1 and tcp上面命令的含義是捕獲目的IP地址為
192.168.0.1的tcp報文: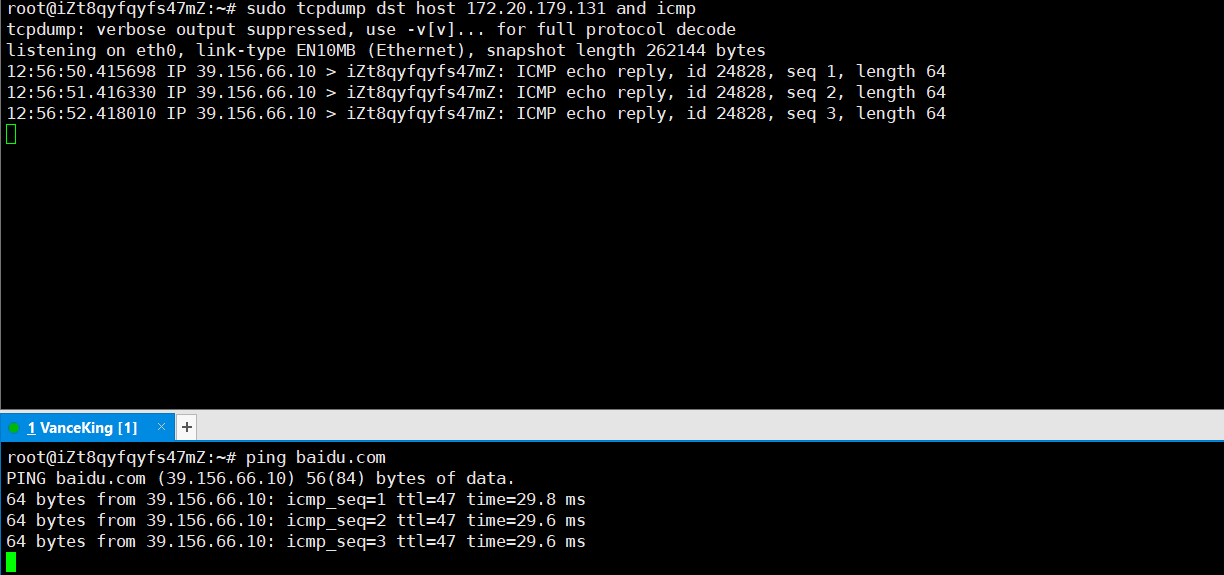
-
注意這個目的IP為什么是
iZt8qyfqyfs47mZ呢?云服務提供商使用類似的隨機字符串作為實例ID或設備標識:
你也可以去云服務網站的控制臺修改這個實例名稱。
-
但是如果我們希望它顯示
IP地址,而不是顯示云服務器的實例名稱該怎么辦呢?加上選項-n即可: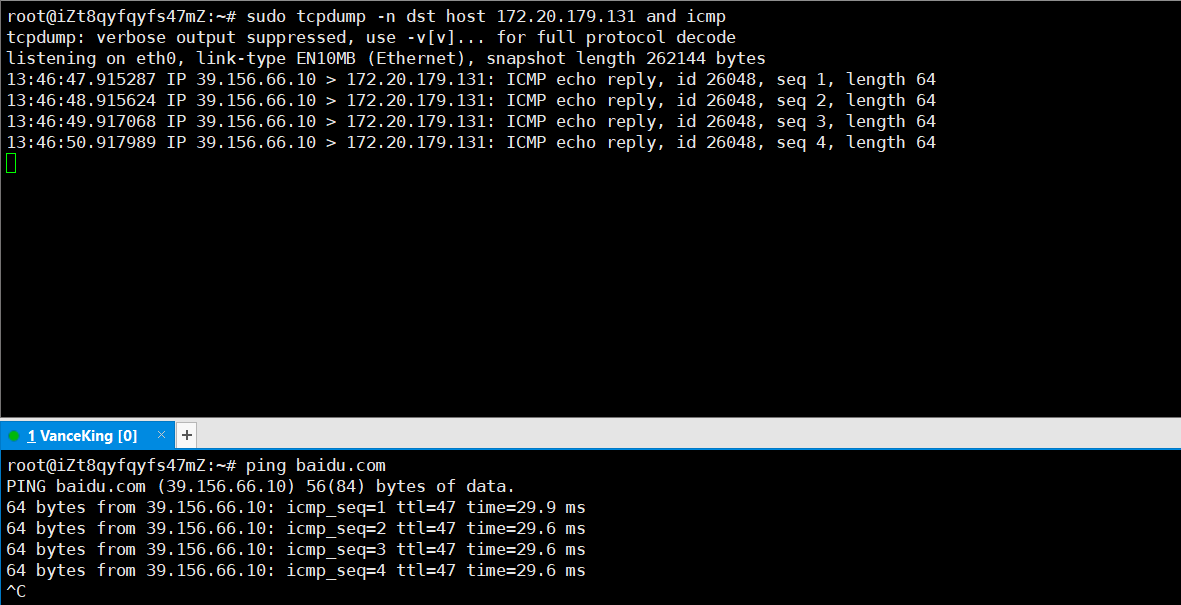
-
-
捕獲特定端口號的
TCP報文:-
使用
port關鍵字可以捕獲特定端口號的報文,例如捕獲80端口的TCP報文(通常是http請求):sudo tcpdump port 80 and tcp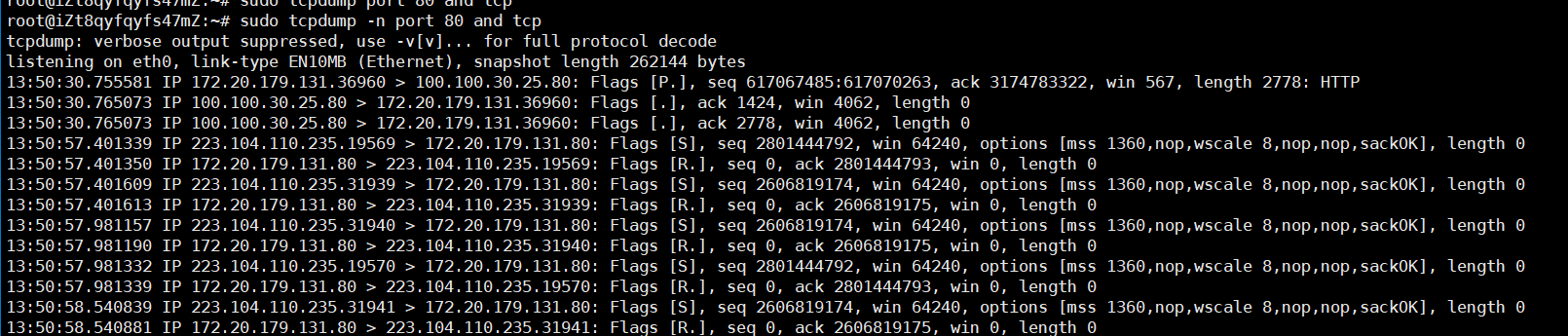
-
實驗
使用tcpdump工具,一般以捕獲特定端口的形式居多,代碼和上述的驗證listen系統調用函數的第二個參數的代碼一樣,簡單的tcp echo服務器:
-
服務器不給客戶端發送數據,也不
accept接受連接:
-
將客戶端在虛擬機上運行,觀察抓包現象:
-
三次握手:

- 因為三次握手是沒有發送數據的,所以
length為0。
- 因為三次握手是沒有發送數據的,所以
-
當我們虛擬機客戶端給服務器發送數據報文,但是服務器收到該報文,發送的
ack報文數據為0,沒有發送數據報文,我們有理由相信,服務器根本沒有將這個連接拿上來給用戶,但是三次握手肯定成功了,并且ack報文是OS自動發送的,不需要用戶參與:
- 看了一下代碼果然沒有將連接拿上來。
-
-
-
將
accept函數注釋取消后繼續實驗:-
三次握手部分(依舊正常):Flags中的
S代表SYN標志位,win是窗口大小(用于滑動窗口中確定窗口大小),可以看到雙方還協商了mss的大小。
-
服務器接收數據,發送數據:

現在收發數據都正常了。

-
四次揮手部分,客戶端主動退出:

-
就只有客戶端給服務器發送了
FIN報文,服務器OS自動給它回復了一個ACK報文,服務器并沒有斷開連接,我們有理由相信,服務器端忘記close關閉socket描述符了。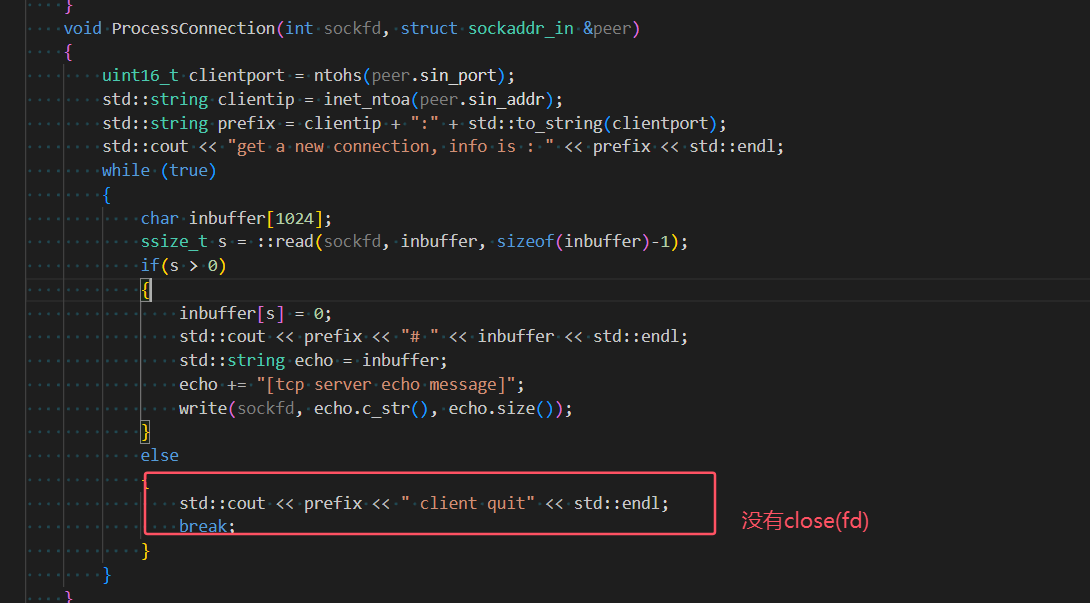
-
-
-
服務器端在客戶端關閉連接后也要正常關閉連接,修改代碼后繼續測試四次揮手的過程:

-
不是說四次揮手嗎,為什么只有三次呢,我們有理由相信,在客戶端給服務器發送
FIN報文后,服務器立馬就給客戶端發送了FIN報文,并且這個時間和系統自動發送ACK報文的時間幾乎是同時,所以觸發了捎帶應答,如果我們讓服務器sleep上1s再關閉socketfd,就可以看到四次揮手: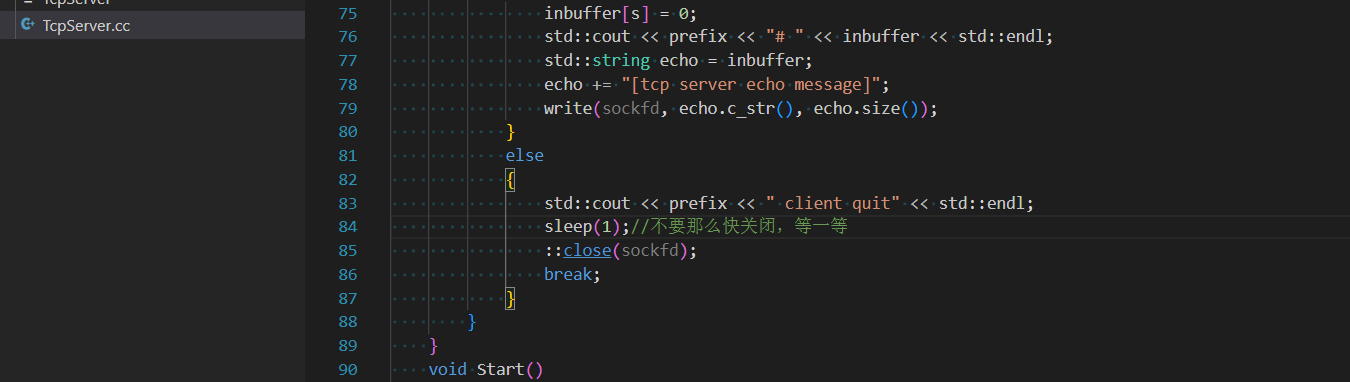
-
sleep后的結果:
-
windows中使用wireshark進行抓包
wireshark的安裝
wireshark-4.4.3-x64.exe
下載好之后,直接安裝即可,沒有太多要注意的地方。
使用telnet作為客戶端訪問云服務器上的服務器程序
默認windows上telnet服務是沒有打開的,我們可以手動打開,打開telnet教程
設置wireshark過濾規則
-
首先選擇你想捕獲哪個網卡的流量(上行和下行):
-
選擇好之后,頂部工具欄點捕獲,點開始,就可以開始捕獲該網卡的流量:
-
默認是捕獲經過該網絡接口的流量:
-
在頂部可以設置過濾規則,我們設置
ip為服務器ip,只關心服務器所在的端口號8888:ip.addr == 121.40.68.117 && tcp.port == 8888頂部過濾欄是綠色說明語法沒有問題:

使用wireshark進行抓包
-
啟動服務器程序:

-
啟動windows上的
telnet服務:telnet [服務器公網ip] [端口號]
- 進入這個界面就代表啟動成功了。
-
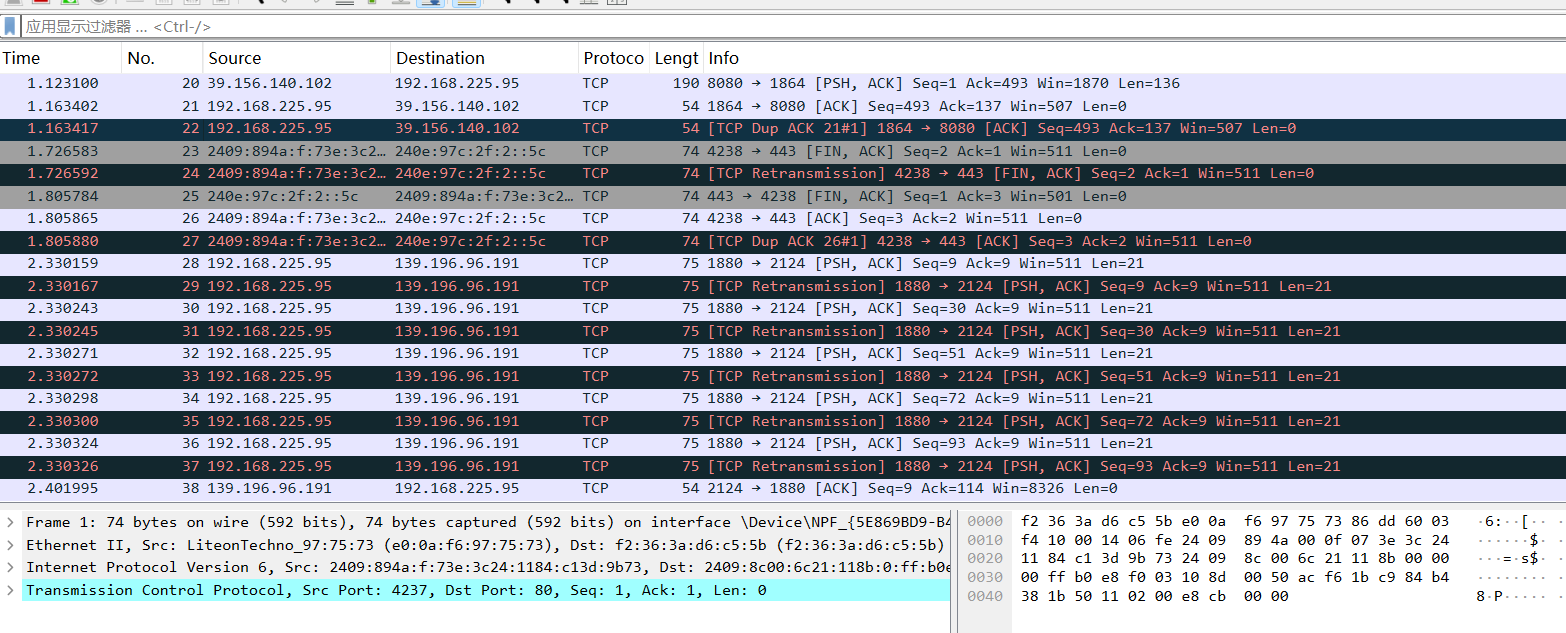
觀察報文:
-
三次握手:

-
telnet發送1字節的數據: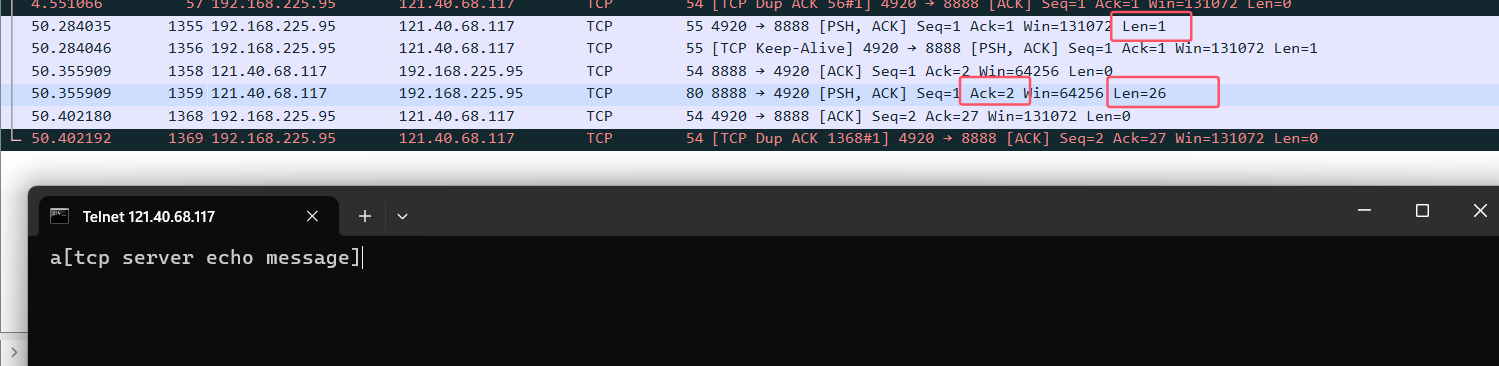
點擊某一個包,下面可以看到更詳細的信息:
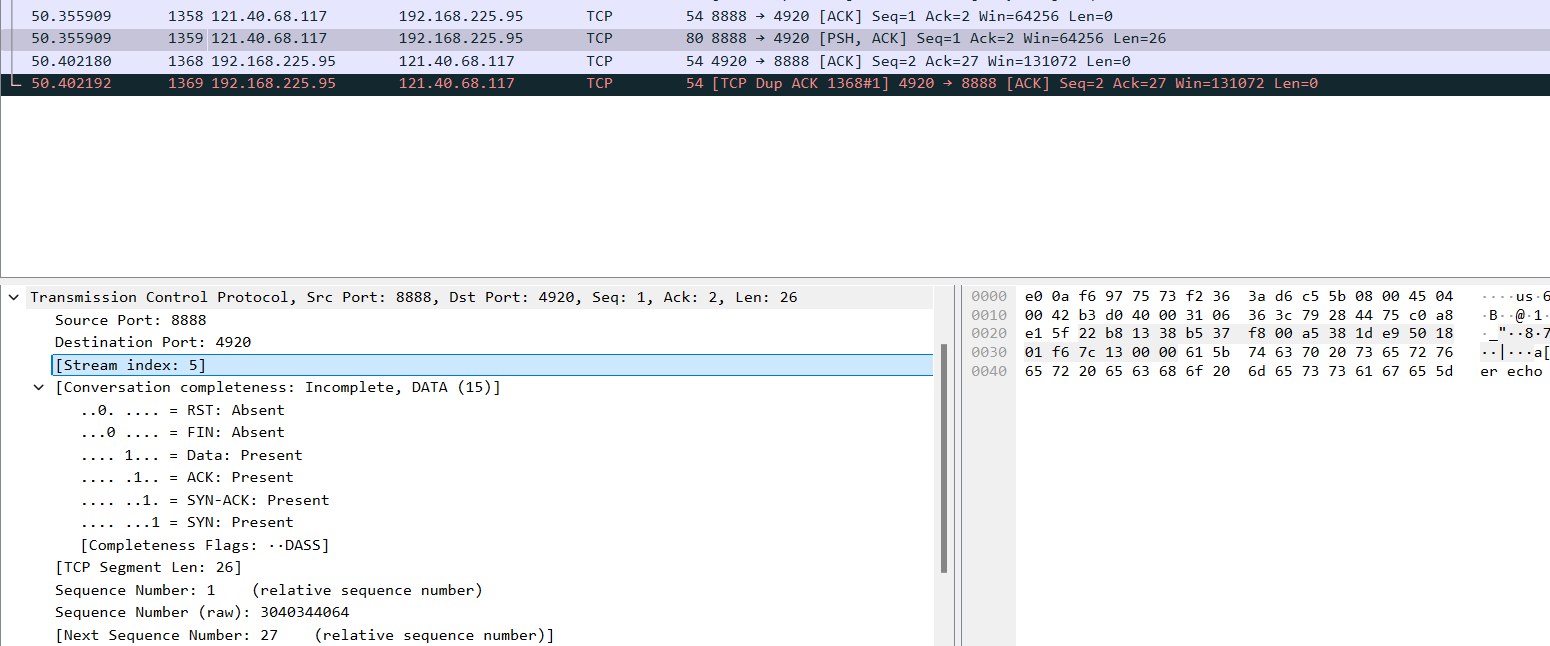
-
-
四次揮手,telnet輸入
ctrl ]進入命令行模式,然后點quit就可退出:
紅色的報文為超時重傳。

(含模型、可運行代碼、數據))
![[學習]RTKLib詳解:pntpos.c與postpos.c](http://pic.xiahunao.cn/[學習]RTKLib詳解:pntpos.c與postpos.c)
)

)



識別與重構指南)
)

)


)



