目錄標題
- 【1】AI-Generated Video Detection via Spatio-Temporal Anomaly Learning
- 【2】DeCoF: Generated Video Detection via Frame Consistency
- 【2.1】Spatiotemporal Convolutional Neural Networks (STCNN) rely on spatial artifacts
- 【2.2】Capturing Universal Spatial Artifacts is Difficult
- 【3】DeMamba: AI-Generated Video Detection on Million-Scale Benchmark
- 【4】GenVidBench: A Challenging Benchmark for Detecting AI-Generated Video
- 【5】Distinguish Any Fake Videos: Unleashing the Power of Large-scale Data and Motion Features
- 【6】On Learning Multi-Modal Forgery Representation for Diffusion Generated Video Detection
- 【7】What Matters in Detecting AI-Generated Videos like Sora?
- 【8】Turns Out I’m Not Real: Towards Robust Detection of AI-Generated Videos
- 【9】Beyond Deepfake Images: Detecting AI-Generated Videos
- 【10】Exposing AI-generated Videos: A Benchmark Dataset and a Local-and-Global Temporal Defect Based Detection Method
- Acknowledgments
【1】AI-Generated Video Detection via Spatio-Temporal Anomaly Learning
- 針對AI生成視頻帶來的偽造風險,提出了一種基于雙分支時空卷積神經網絡的檢測方法AIGVDet,通過分別建模RGB幀中的空間特征與光流圖中的時間特征,有效捕捉生成視頻中的異常痕跡,并融合兩者結果以提升判別能力。為支持模型訓練與評估,構建了大規模生成視頻數據集GVD。實驗結果表明,該方法在面對未知生成模型與視頻壓縮等干擾時仍具備良好的泛化性與魯棒性,具備成為生成視頻檢測任務穩健基線的潛力。代碼和數據集已開源于:https://github.com/multimediaFor/AIGVDet。

- 低質量的生成視頻可能會在幀中表現出一些異常現象,例如紋理異常和物理規律的違背。而那些肉眼難以分辨的高質量生成視頻,則更可能在光流圖中表現出時間上的不連續性。上圖展示了一些視頻幀及其通過RAFT方法估計得到的光流圖,其中顏色表示運動方向,明暗表示運動幅度。盡管生成視頻幀在視覺上十分逼真,但其光流圖相比真實視頻更不平滑,輪廓也更加模糊。
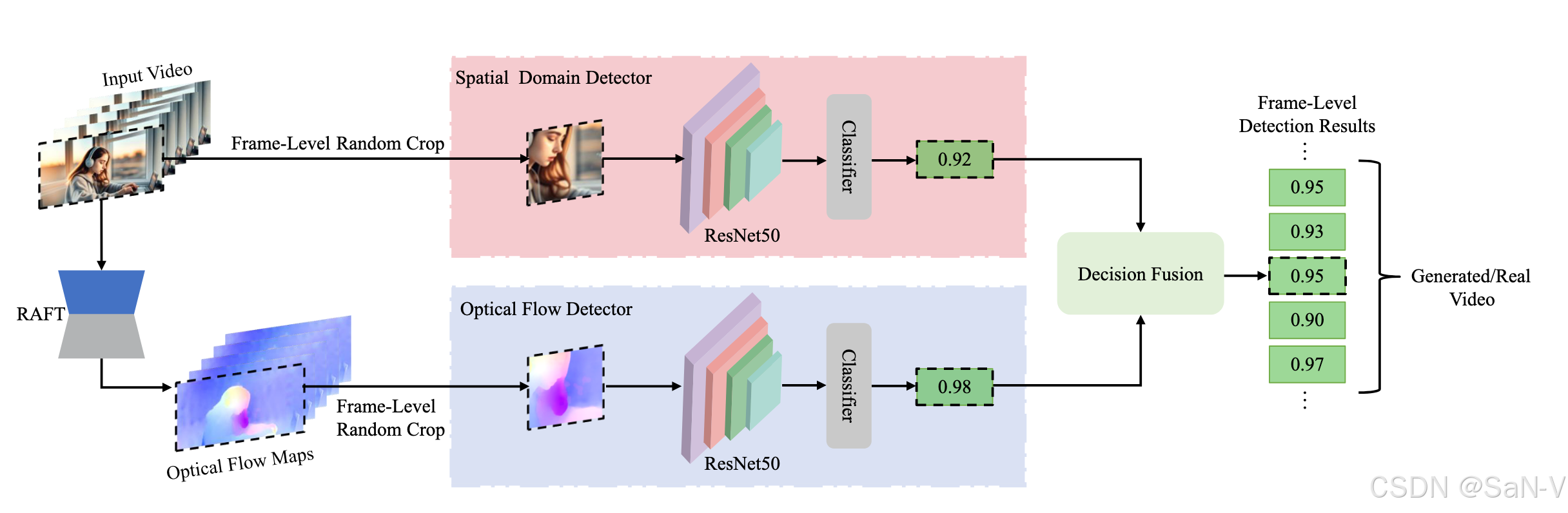
- 為了捕捉真實視頻與生成視頻之間的這些差異,我們提出了一種簡單而有效的AI生成視頻檢測模型(AIGVDet)。該模型以RGB幀及其對應的光流圖為輸入,利用雙分支的ResNet50編碼器深入挖掘這兩種模態中的異常特征。最終,我們構建了一個基于決策級融合的二分類器,有效整合多源信息以提升模型的判別能力。
- GVD數據集,涵蓋了當前最常見的兩類生成模型:文本生成視頻(Text-to-Video,T2V)和圖像生成視頻(Image-to-Video,I2V)。T2V指的是根據文本內容自動生成相應的視頻,而I2V則指根據帶有描述信息的圖像,或僅根據圖像生成視頻。
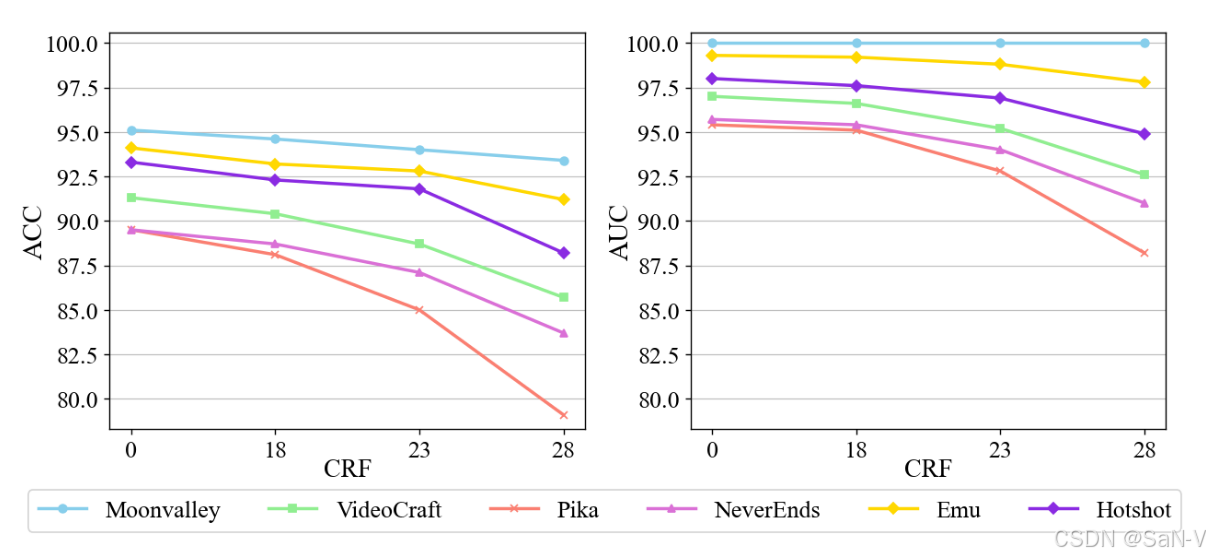
- 評估了模型在面對視頻壓縮這一現實場景中最常見后處理操作時的魯棒性。CRF是控制H.264壓縮質量的參數,我們測試了CRF為0、18、23和28的壓縮等級(其中0表示無壓縮)。對于生成視頻和真實視頻,我們均進行了重新壓縮處理。隨著壓縮程度的增加,AUC和ACC有所下降。然而,對于各個檢測模型的準確率(ACC)均維持在80%以上,AUC也始終保持在88%以上。
【2】DeCoF: Generated Video Detection via Frame Consistency
- 構建了一個包含964條提示、涵蓋多種生成模型(包括Sora與Veo)的公開數據集GVF,提出了一種基于幀一致性的檢測方法DeCoF。該方法通過消除空間偽影干擾,專注于捕捉時間偽影,具備良好的泛化性和魯棒性,在多個未知和閉源商用生成模型上均表現優異。相關代碼和數據集將開放于:https://github.com/wuwuwuyue/DeCoF。
- 偽影(Artifact)是指在圖像或視頻中出現的非自然、不真實的痕跡或失真,通常是由于壓縮、處理或生成算法造成的。偽影本質上是一種“異常”,會背離自然圖像或視頻的規律。
- 空間偽影(Spatial Artifacts):出現在單幀圖像中,如模糊、邊緣不連續、紋理異常、塊狀失真(blockiness)等。
- 時間偽影(Temporal Artifacts):出現在連續幀之間,表現為時間維度的不一致,如:
? 運動不連續:物體移動時突然“跳動”或變形。
? 光流不穩定:連續幀之間的光流場變化異常、不平滑。
? 幀間不一致:前后幀中物體的紋理、位置或狀態不協調。
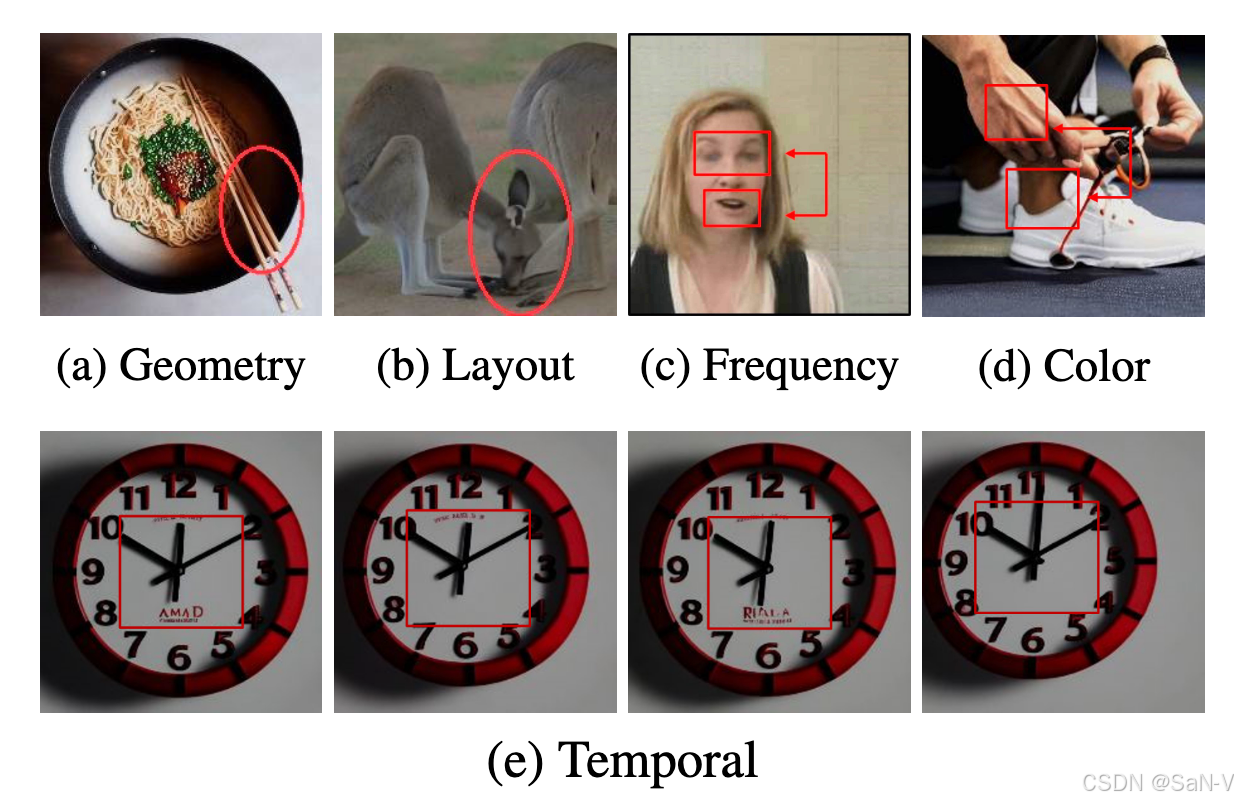
- 空間偽影包括:(a) 幾何外觀錯誤,(b) 圖像布局錯誤,(c)頻率不一致,(d) 顏色不匹配;
- 時間偽影為:(e) 幀與幀之間的不一致。
【2.1】Spatiotemporal Convolutional Neural Networks (STCNN) rely on spatial artifacts
- 為了分析 STCNN 網絡在訓練過程中到底學習了哪些信息,或者說它在區分真實與偽造視頻時依賴了哪些特征,我們設計了兩個新的探測實驗,并在相同的模型框架下構建了兩個新數據集進行測試。
- 第一個數據集將當前測試集中所有真實視頻的幀順序打亂,破壞視頻的時間連續性,以觀察模型是否可以僅通過時間不連續性來進行區分。
- 第二個數據集則從當前測試集中的偽造視頻中隨機選取一幀,并將該幀復制多次,生成一個只有單幀內容的視頻,用于觀察模型是否可以僅依賴空間偽影進行區分。
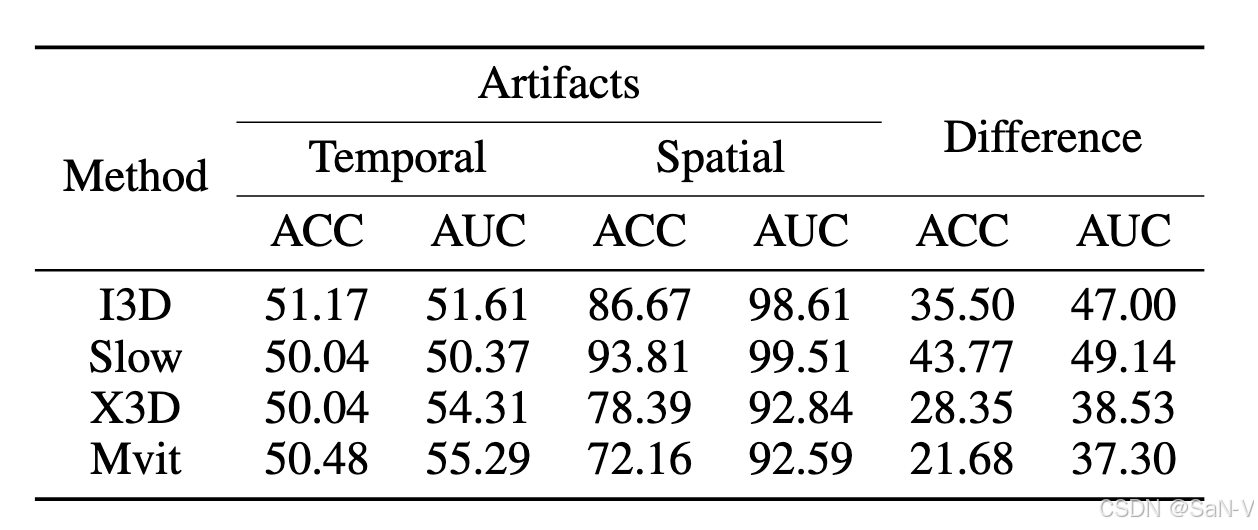
- 上表中的實驗結果表明,STCNN過于依賴空間偽影,從而將生成視頻檢測問題退化為一個二維問題。然而,僅憑 STCNN 對空間偽影的依賴仍無法解釋其在面對未見過的生成模型時缺乏泛化能力的原因。
【2.2】Capturing Universal Spatial Artifacts is Difficult
- 將當前用于生成圖像檢測的方法轉化為圖像級檢測器,并用于檢測生成視頻,在 GVF 數據集上進行測試。這些檢測器在識別特定生成模型的空間偽影方面表現出色,但同樣缺乏對未見生成模型的泛化能力。
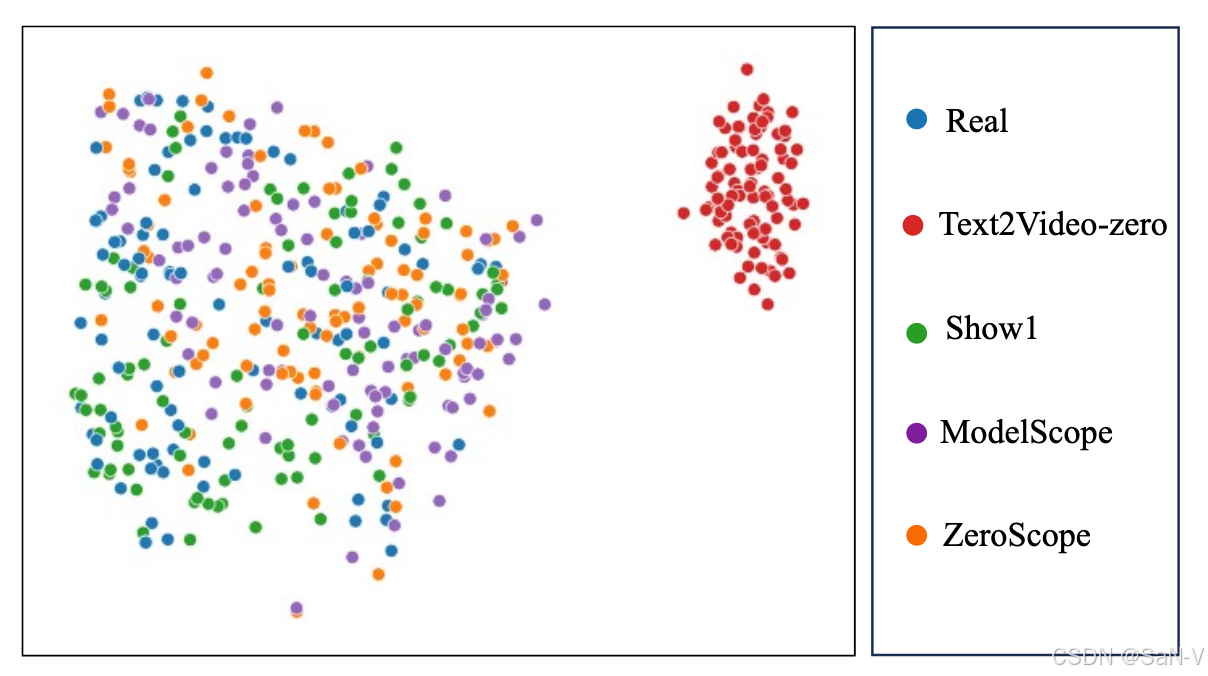

- 研究發現,雖然現有檢測器能夠有效識別由已見生成模型產生的視頻,原因在于其成功捕捉到了特定模型的空間偽影,但這些偽影在不同生成模型之間缺乏一致性,導致檢測器難以泛化至未見模型。通過對不同子數據集的特征分布進行可視化分析,以及對生成視頻幀的頻譜進行對比,實驗進一步驗證了不同模型所引入的空間偽影差異顯著,因而構建具備普適性的空間特征檢測器極具挑戰。
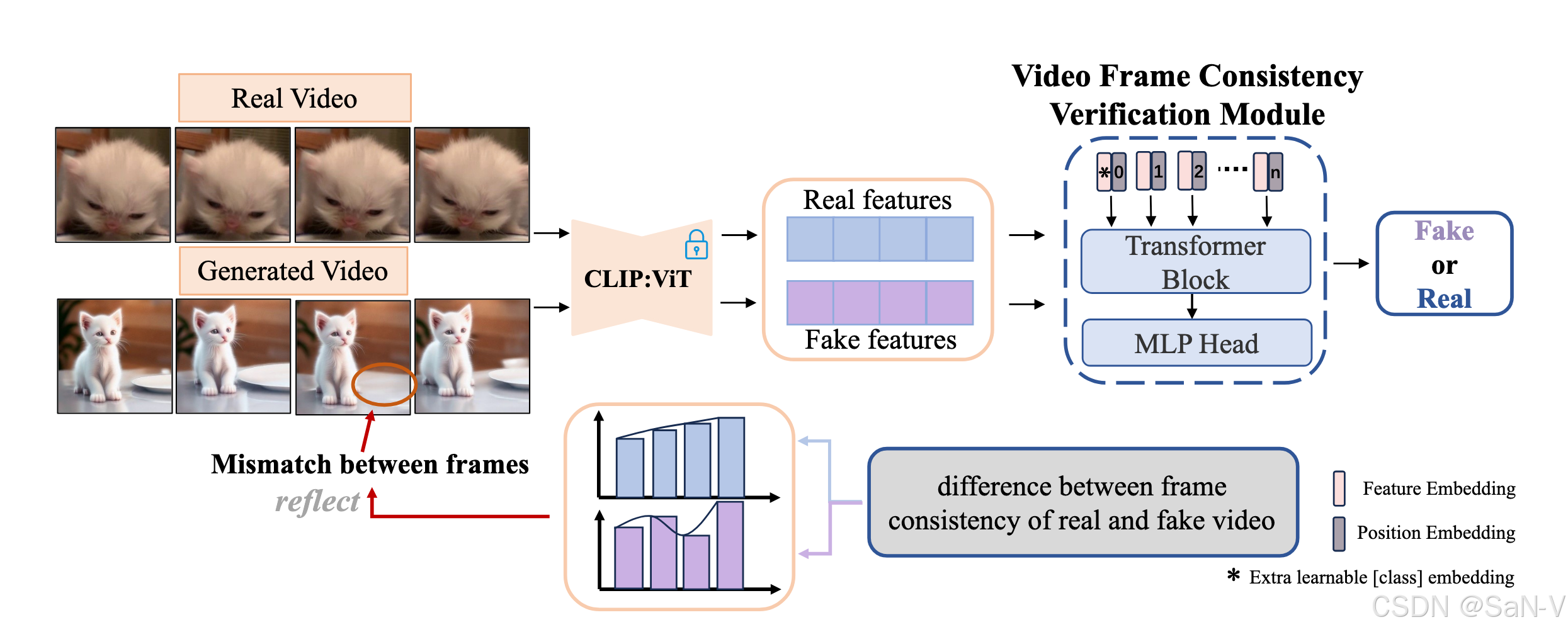
- 我們首先使用預訓練的 CLIP:VIT 提取真實視頻和生成視頻的特征,以消除空間偽影對時間偽影捕捉的影響。隨后,利用一個由兩個 Transformer 層和一個 MLP 頭組成的驗證模塊,學習真實視頻與偽造視頻在幀一致性上的差異。
- 在實際檢測場景中,檢測器對未見過的擾動的魯棒性同樣至關重要。在這里,我們主要關注兩種擾動對檢測器的影響:高斯模糊和JPEG壓縮。高斯模糊在三個級別(σ = 1, 2, 3)下添加,JPEG壓縮在五個級別(質量 = 90, 80, 70, 60, 50)下添加。
【3】DeMamba: AI-Generated Video Detection on Million-Scale Benchmark
- 針對缺乏高質量數據集的問題,作者提出了首個百萬級大規模 AI 生成視頻檢測數據集 GenVideo,并設計了兩個評估任務衡量檢測器的泛化能力與魯棒性。
? 跨生成器分類任務:評估訓練后的檢測器在面對不同生成器時的泛化能力;
? 退化視頻分類任務:評估檢測器在面對傳播過程中質量下降的視頻時的魯棒性。 - 此外,作者還提出了一個即插即用的增強模塊——Detail Mamba(DeMamba),該模塊通過分析視頻在時間和空間維度上的不一致性來識別 AI 生成視頻,代碼與數據集將開放于:https://github.com/chenhaoxing/DeMamba。
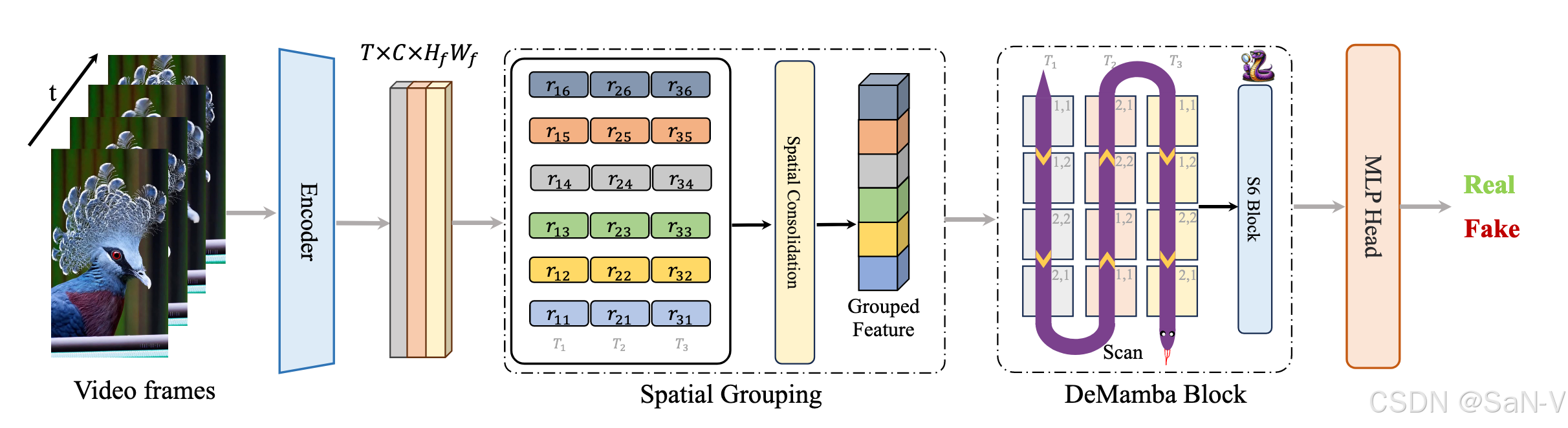
- 該方法包括特征編碼器、DeMamba模塊和MLP分類頭。首先,使用最先進的視覺編碼器(如CLIP和XCLIP)對視頻幀進行編碼,生成特征序列。
- 然后,通過DeMamba模塊對這些特征進行空間整合和時空一致性建模。該模塊通過連續掃描策略有效捕捉視頻幀之間的復雜時空關系。
- 最后,聚合全局和局部特征,結合MLP進行視頻的真偽分類。該模型通過二元交叉熵損失進行訓練,旨在提高檢測AI生成視頻的準確性和魯棒性。
- 由于生成方法迭代迅速,我們提出了跨數據集泛化任務,用于測試檢測器的泛化能力。具體來說,該任務包括兩種類型:1)多對多泛化任務;2)一對多泛化任務。
- 多對多泛化任務指在10個基準類別上進行訓練,然后在各個子集及ood上的平均檢測性能進行測試。
- 一對多泛化任務參考了AI生成圖像檢測的相關設定,與多對多不同,它是在一個基準類別上訓練,并在各個子集及ood上測試泛化性能。
- ood(Out-Of-Distribution),在訓練數據分布之外的視頻子集,即模型在訓練時未見過的視頻類型或生成方式,用于測試模型的泛化能力。
- 研究了八種不同類型擾動對檢測器的影響,包括:H.264壓縮、JPEG壓縮、翻轉(FLIP)、裁剪(Crop)、文字水印、圖像水印、高斯噪聲和顏色變換。
【4】GenVidBench: A Challenging Benchmark for Detecting AI-Generated Video

- GenVidBench是一個面向 AI 生成視頻檢測任務的大規模、高質量數據集,具備跨來源、跨生成器、涵蓋多種先進視頻生成模型以及豐富語義分類等特點,旨在提升檢測模型的泛化能力和魯棒性,并為研究者開發和評估生成視頻檢測方法提供標準基準和實驗支持。
- GenVidBench數據集不僅包含真實與偽造視頻的標簽,還提供豐富的語義內容標簽,例如物體類比、場景位置和動作行為等
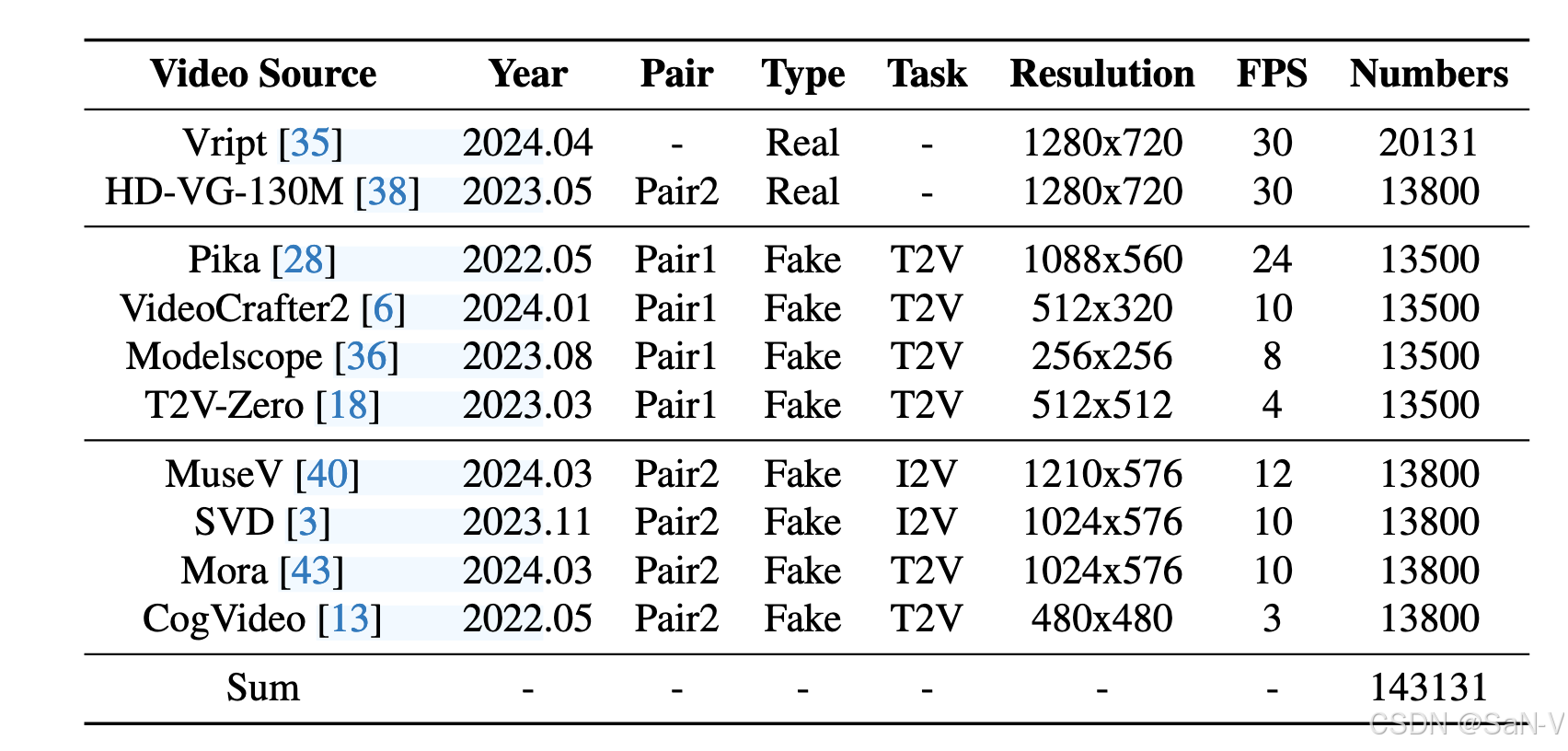
-
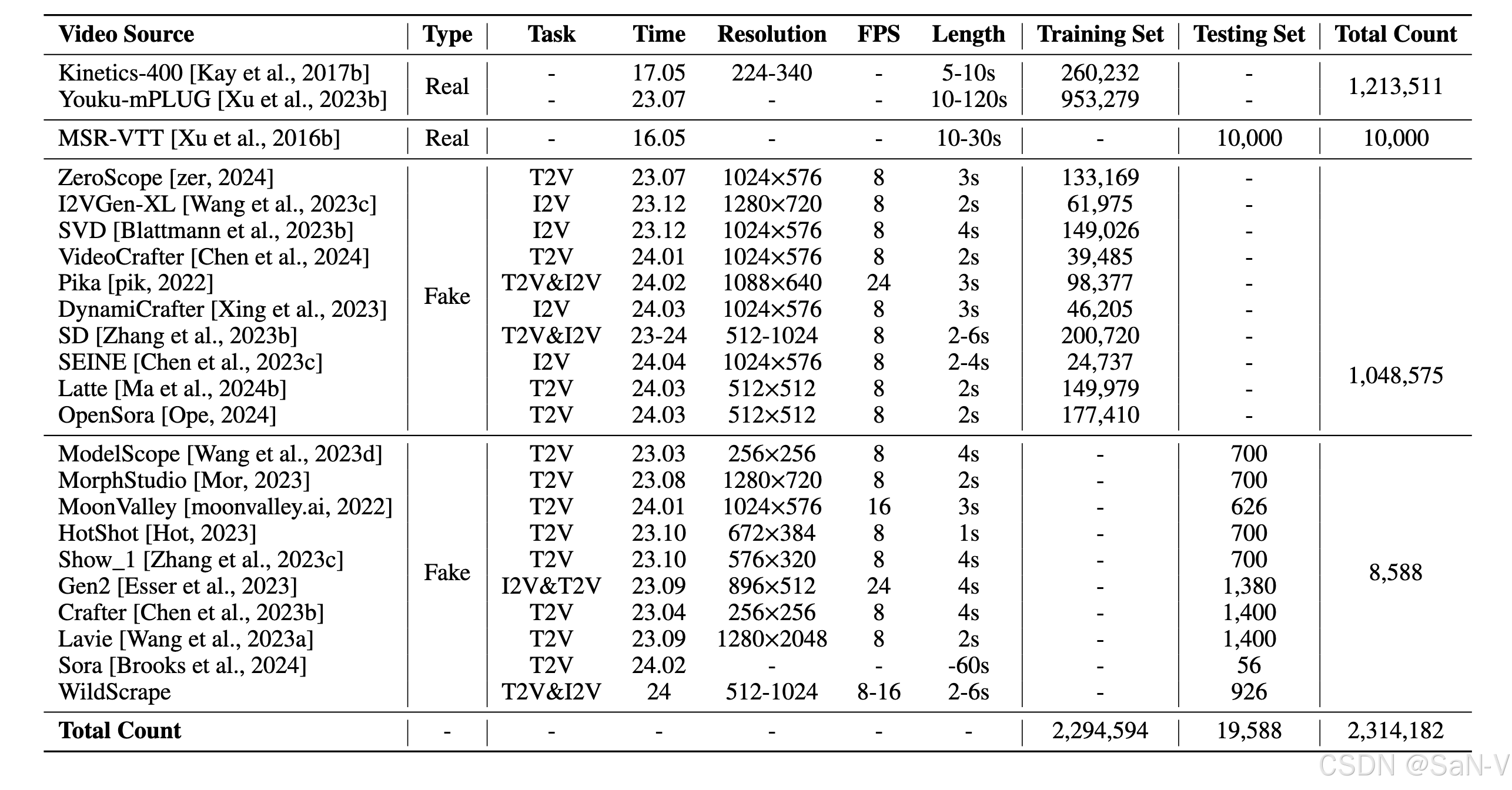
上表是GenVidBench 數據集中真實與生成視頻的統計信息。GenVidBench 包含由8種先進生成器生成的8個偽造視頻子集以及2個真實視頻子集。視頻對是根據生成來源(如文本提示或圖像)進行劃分的。

-
GVD 和 GenVideo 是之前的兩個重要數據集,但它們有一些局限性,比如缺乏原始的生成提示、圖像、視頻對、語義標簽和跨來源設置。這意味著這些數據集在訓練集和測試集內容相似時,無法有效區分不同場景的問題。
-
GVF 嘗試解決這些問題,提供了提示、圖像、視頻對和語義標簽,但由于數據集規模較小(僅2.8k個視頻),它仍然面臨規模不足的問題。同時,它也沒有跨來源設置,這使得它在多樣性和挑戰性方面有所欠缺。
-
GenVidBench 是一種改進的數據集,規模達到100,000個視頻,涵蓋了語義標簽和用于生成視頻的提示/圖像,并進行了跨來源設置,從而使其在假視頻檢測方面更具挑戰性。
-
“跨來源設置”(Cross-source setting)指的是在數據集的訓練集和測試集中,使用來自不同來源(例如,不同的視頻生成模型、不同的輸入數據或不同的生成環境)的數據。這種設置的目的是增加數據的多樣性,并減少模型在訓練時可能學習到的偏差,使其能夠更好地適應不同來源的視頻生成,從而提高檢測器的泛化能力。簡單來說,跨來源設置增加了數據集的多樣性和復雜性,是一種為了提升AI生成視頻檢測器性能而采用的策略。
-
“視頻對”(Video pairs)指的是一對相關的兩段視頻,通常用于比較和分析。在生成視頻檢測的上下文中,視頻對通常由以下兩種類型組成:
-
真實視頻與生成視頻對:一個視頻來自真實世界,而另一個視頻則是由AI生成模型生成的。這對視頻可以用來進行真假視頻的對比,幫助檢測器識別和區分AI生成的視頻和真實視頻。
-
相同提示的生成視頻對:對于生成視頻,可能會使用相同的輸入提示或條件生成不同的視頻。這種情況下,視頻對中的兩個視頻來自相同的生成模型,但它們是基于相同的輸入生成的,可以用來分析不同生成模型或不同生成參數下,AI生成的視頻之間的差異。
-
在檢測任務中,視頻對的使用有助于訓練模型識別兩個視頻之間的異同,特別是在對比真假視頻時,可以通過直接比較它們的內容、特征、風格等來提高檢測的精度。
-
【5】Distinguish Any Fake Videos: Unleashing the Power of Large-scale Data and Motion Features
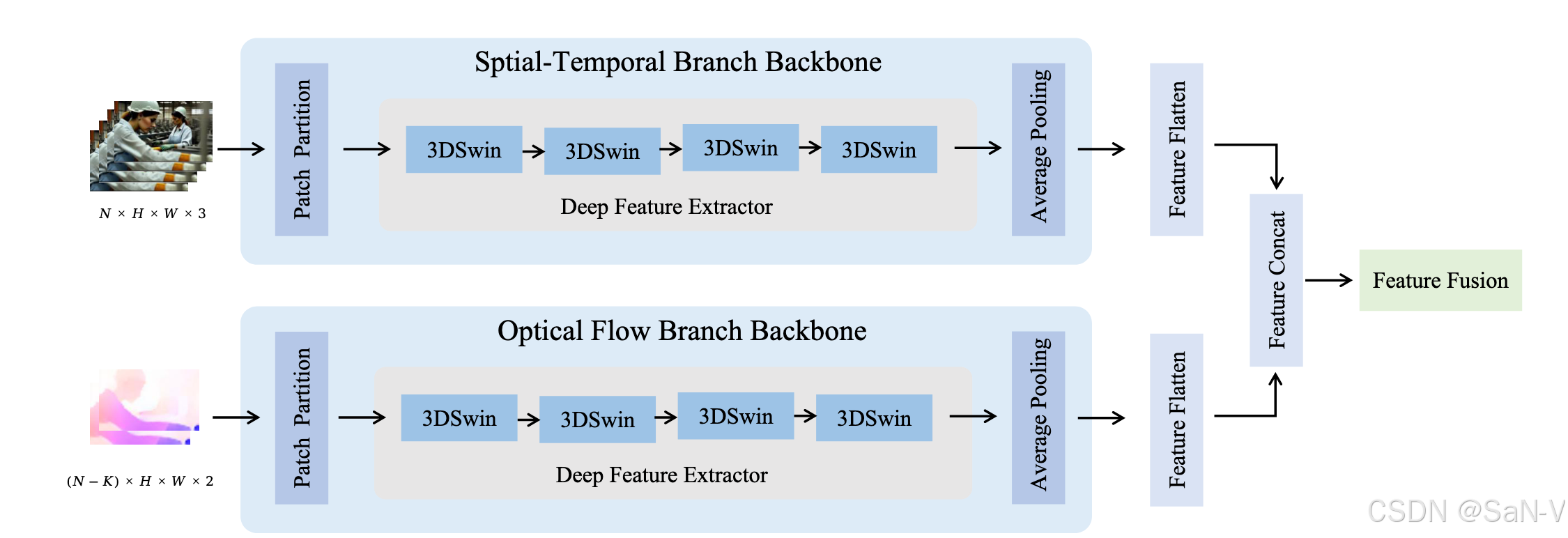
- DuB3D 架構概覽:上方分支表示外觀建模組件,從原始視頻內容中提取時空特征;下方分支表示運動建模組件,從光流中提取運動特征。
- 上方分支處理連續的 N 幀圖像,下方分支則使用間隔為 K 幀的視頻幀對來計算光流作為輸入。
- 在網絡中,“3DSwin” 指的是 Video Swin Transformer 的階段模塊。
【6】On Learning Multi-Modal Forgery Representation for Diffusion Generated Video Detection
- 提出了一種創新算法,稱為多模態檢測(MM-Det),用于檢測擴散生成的視頻。MM-Det 利用大規模多模態模型(LMMs)深層次的感知能力和綜合理解能力,通過在其多模態空間中生成多模態偽造表示(MMFR),提升其對未知偽造內容的檢測能力。此外,MM-Det 還引入了一種幀內與跨幀注意力機制(IAFA),用于時空域中的特征增強;并通過動態融合策略優化偽造特征的融合表現。我們還構建了一個涵蓋多種偽造視頻的綜合性擴散視頻數據集,稱為Diffusion Video Forensics(DVF)。
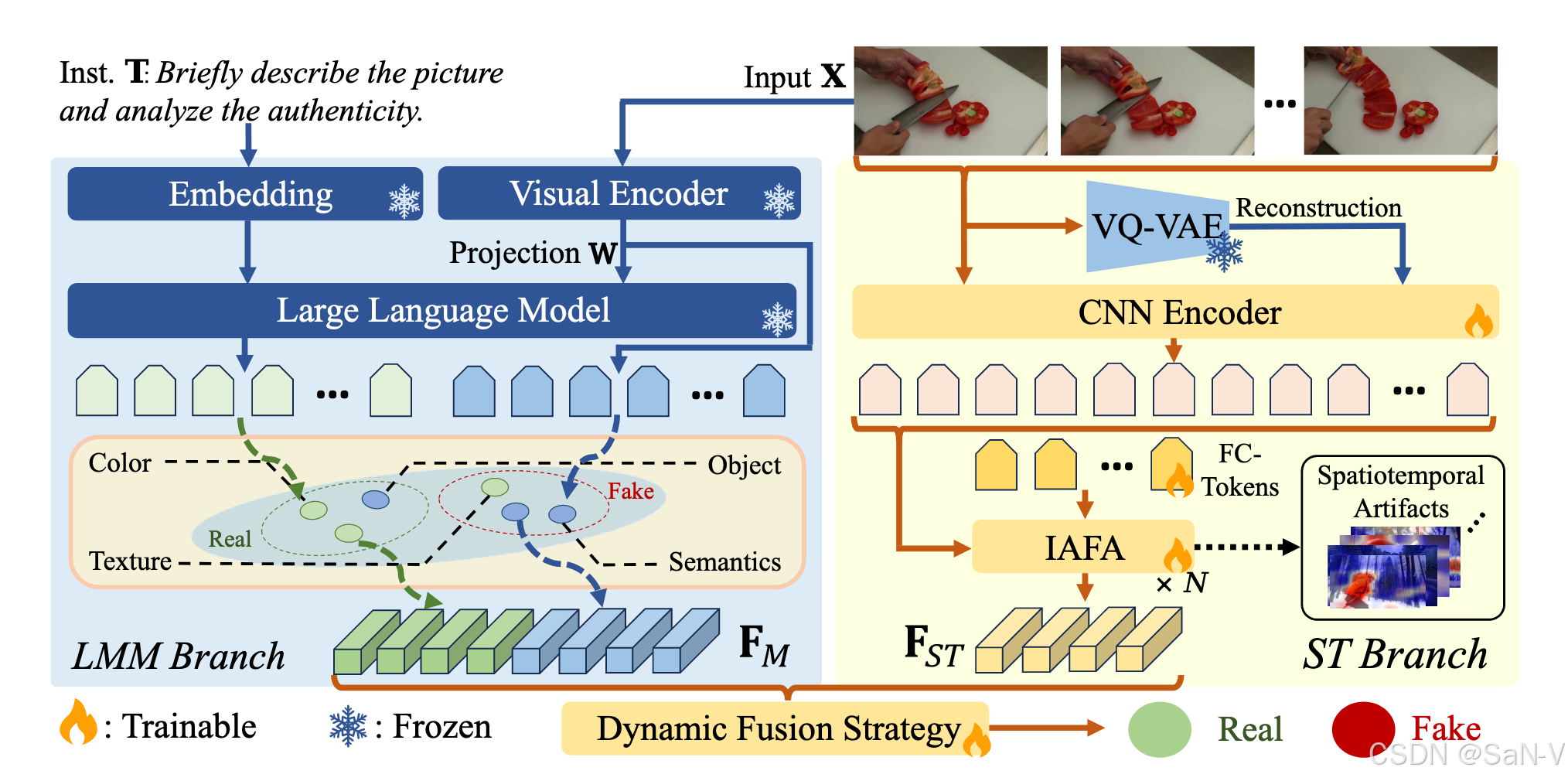
- 多模態檢測網絡(MM-Det)的架構。給定一個輸入視頻,大規模多模態模型(LMM)分支接收視頻幀和提示語,生成多模態偽造表示(MMFR)。從視覺編碼器和大語言模型中提取的隱藏狀態組成了 MMFR,用于捕捉不同擴散生成視頻中的偽造痕跡。
- 在時空(ST)分支中,視頻首先通過 VQ-VAE 進行重構,放大擴散偽造中的細節差異,隨后輸入至 CNN 編碼器,并經過“幀內與幀間注意力機制”(IAFA)模塊。IAFA 用于提取基于空間偽影和時間不一致性的特征。
- 最后,采用動態融合策略將兩種特征結合,用于最終的偽造檢測判斷。
- 為了分析我們方法的魯棒性,我們基于常見的后處理操作對 MM-Det 進行了額外的評估。我們選擇了高斯模糊(σ = 3)、JPEG 壓縮(質量 Q = 90)、縮放(比例為 0.7)、旋轉(角度為 90°)以及上述所有操作的組合,作為現實場景中未見的擾動。測試樣本從 DVF 數據集中選取,共包含 500 個真實視頻和 500 個偽造視頻。如表 S3 所示,MM-Det 在這些操作下的性能下降介于 0.9%(JPEG 壓縮)到 5.8%(高斯模糊)之間,所有結果均高于 86%。這表明我們的方法在這些干擾下依然具有良好的有效性。
【7】What Matters in Detecting AI-Generated Videos like Sora?
- 在本研究中,從三個基本維度出發——外觀、運動和幾何,探討了這一差距,并將真實視頻與當前最先進的 AI 模型 Stable Video Diffusion 所生成的視頻進行比較。為此,我們利用三維卷積網絡訓練了三個分類器,分別針對外觀(使用視覺基礎模型特征)、運動(使用光流信息)和幾何結構(使用單目深度信息)進行偽造檢測。每個分類器在定性和定量上均表現出出色的偽造視頻識別能力,這表明當前的 AI 生成視頻仍易被識別,真實與偽造視頻之間依然存在顯著差距。
- 此外,我們通過 Grad-CAM(能夠在輸入圖像上高亮顯示模型關注的區域,也就是說,它告訴我們模型是“看著”圖像的哪個部分來判斷某一類別的) 技術進一步定位了 AI 生成視頻在外觀、運動和幾何層面上的系統性缺陷。最后,我們提出了一種專家集成模型(Ensemble-of-Experts),融合了外觀、光流和深度信息以提升偽造視頻檢測的魯棒性與泛化能力。該模型甚至能夠高精度地檢測由 Sora 生成的視頻,即便在訓練階段從未見過任何 Sora 的樣本。這表明,真實與偽造視頻之間的差距具有一定的普適性,可推廣到不同的視頻生成模型中。
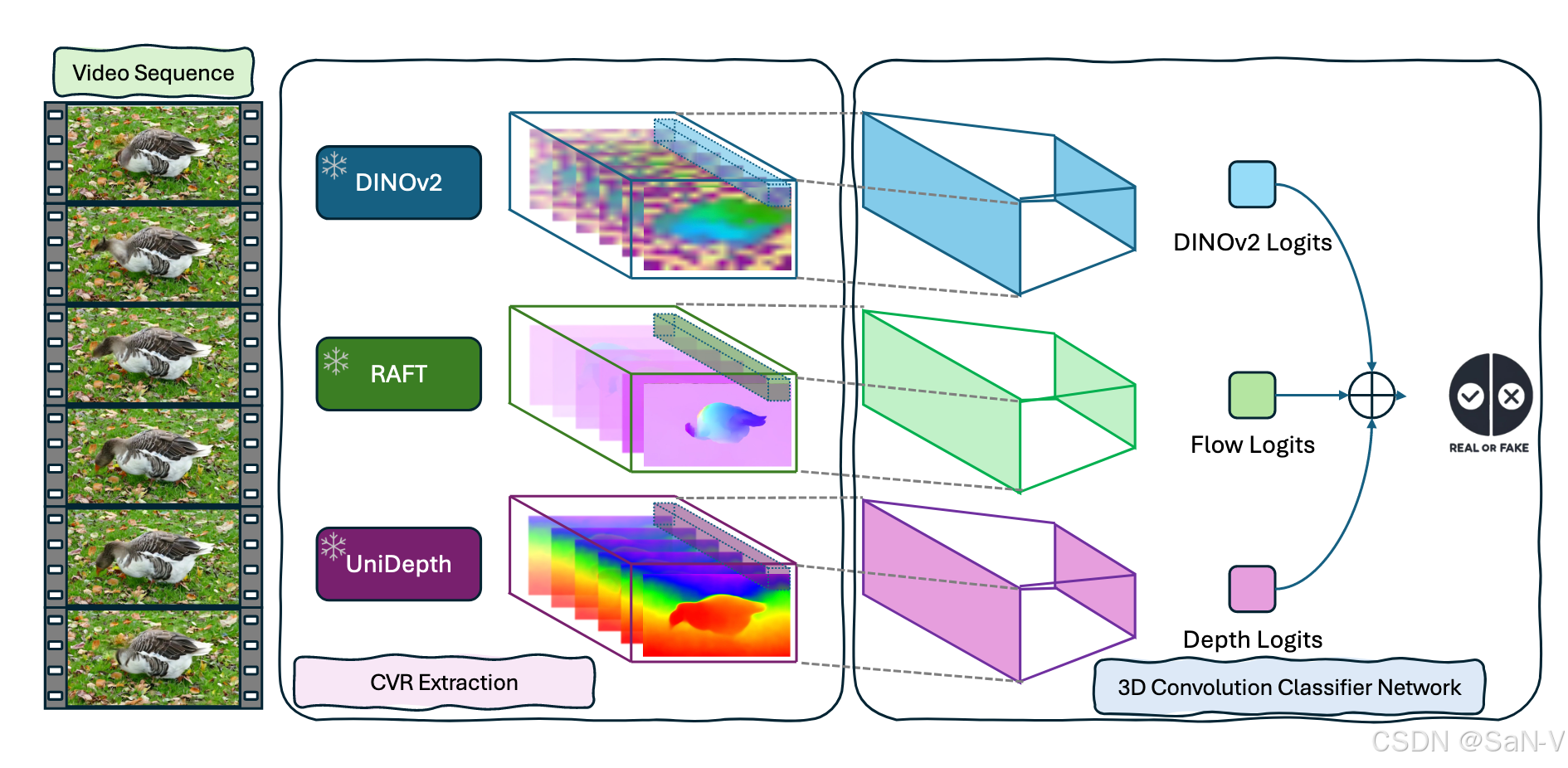
- Ensembled Experts模型的整體框架概覽。每個CVR分類器都會獨立評估輸入視頻的真實性。各個分類器生成的logits被集成,用于構建最終的專家集成模型。
- Logits是指神經網絡輸出層在激活函數(如 softmax)之前的原始輸出值,通常是一個實數向量,表示每個類別的“未歸一化置信度”。
【8】Turns Out I’m Not Real: Towards Robust Detection of AI-Generated Videos
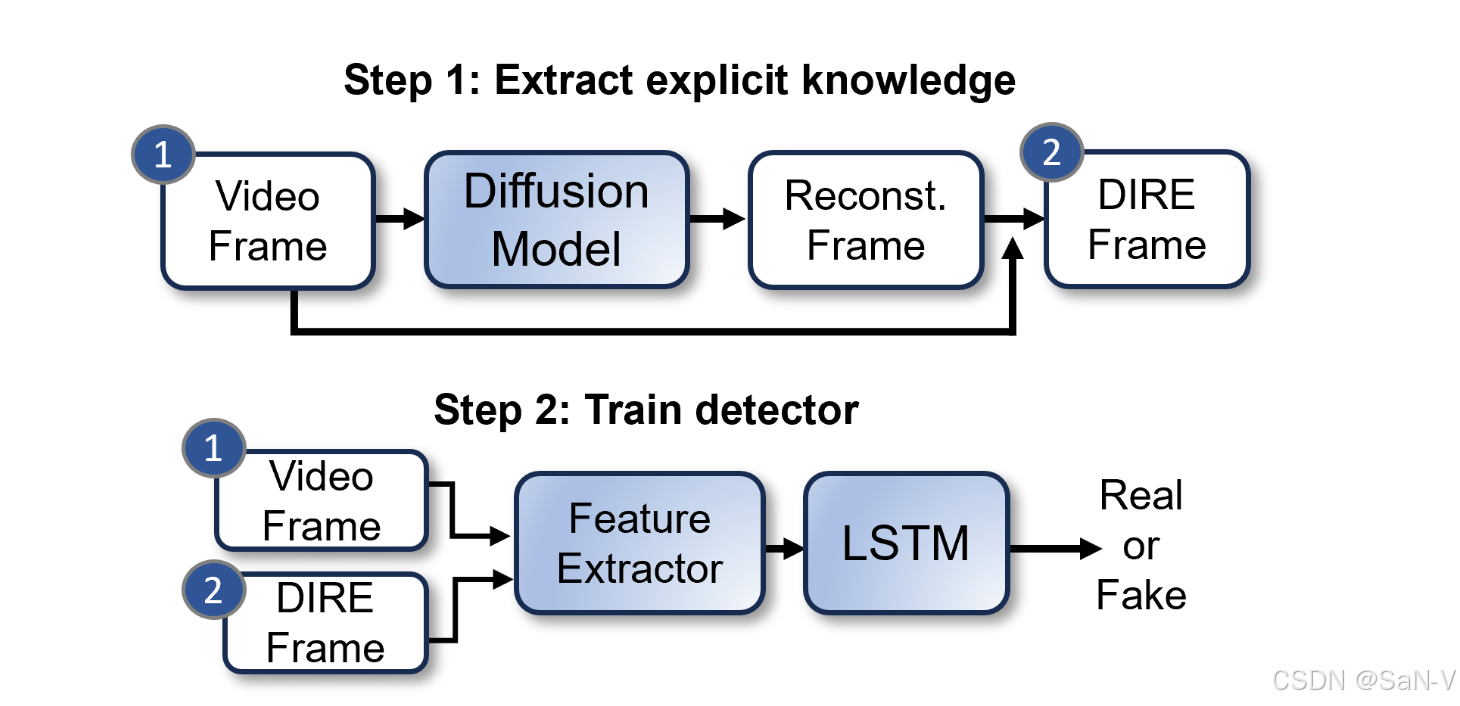
- 與以往僅利用DIRE值訓練CNN檢測器的先進方法不同,DIVID同時利用RGB幀和DIRE值,結合簡單的CNN+LSTM架構,能夠捕捉視頻中的時間信息,并從多個視頻幀中提取顯式知識。
- 擴散重建誤差(DIRE),這是一種通過擴散模型對圖像進行重建后,與原圖之間的差異來衡量的誤差,用于輔助檢測圖像或視頻的真實性。

- 與擴散生成圖像相比,真實圖像的DIRE值通常更大。
【9】Beyond Deepfake Images: Detecting AI-Generated Videos
- 本文展示了合成圖像檢測器無法可靠檢測AI生成的視頻,并證明這一問題并非由H.264壓縮帶來的降級效應所致。
- 我們發現合成視頻生成器留下的取證痕跡與合成圖像生成器顯著不同,導致圖像檢測器在視頻檢測中表現不佳。
- 同時,我們展示了合成視頻的取證痕跡可以被學習,并在H.264再壓縮的情況下實現可靠的視頻檢測和生成源歸屬。盡管通過零樣本遷移檢測新生成器的視頻具有挑戰性,但少量樣本學習能準確檢測新生成器的視頻。此外,本文創建了一個公開的合成視頻數據集,可用于訓練和評估合成視頻檢測器的性能。
【10】Exposing AI-generated Videos: A Benchmark Dataset and a Local-and-Global Temporal Defect Based Detection Method
- 基于對生成視頻中時間缺陷的分析,我們提出了一個新穎的檢測框架,綜合考慮局部運動信息與全局外觀變化。同時,設計了基于通道注意力的特征融合模塊,能夠自適應地結合局部與全局時間線索,以揭示偽造視頻。
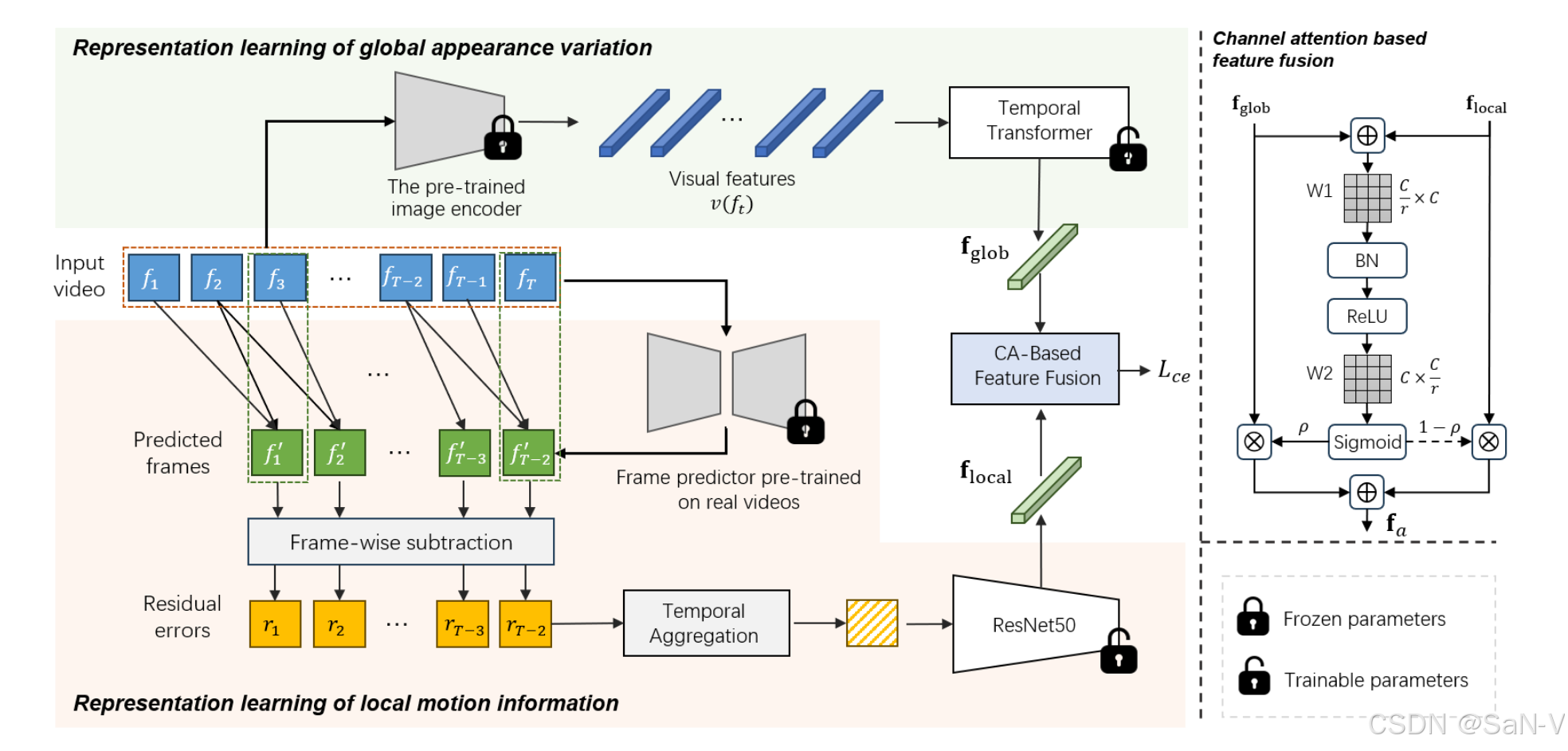
- 首先訓練一個僅使用真實視頻的幀預測模型,以學習真實視頻中的正常運動規律。隨后,在檢測階段,該模型用于預測視頻幀之間的運動變化,并將預測誤差作為衡量視頻局部運動異常的依據。由于真實視頻在時間上具有較強的連續性,其預測誤差通常較小,而偽造視頻的誤差相對較大。為了增強特征的穩定性和泛化能力,研究者還設計了一個時間聚合機制,對誤差序列進行整合,減弱復雜時空內容的干擾。最終,這些聚合后的運動特征被送入編碼器,提取用于檢測的視頻局部運動信息。
- 采用 BEiT v2 作為預訓練的視覺特征提取器,它基于掩碼圖像建模框架,并通過向量量化蒸餾降低了視覺特征對圖像細節變化的敏感性,同時保留高級語義信息。因此,全局外觀變化的特征學習過程可表示為:輸入幀的視覺特征依時間順序輸入至可訓練的時間 Transformer 模型中,從而獲取表示全局外觀變化的特征表示。
- 基于通道注意力(Channel Attention, CA)的特征融合模塊,用于融合局部運動特征與全局外觀特征。
- 魯棒性評估:在視頻中進行 比特錯誤(Bit Error) 操作,通常是指在視頻的二進制數據中人為地引入隨機的比特翻轉,以模擬傳輸過程中由于信道噪聲或硬件錯誤造成的數據破壞。這是模擬網絡傳輸錯誤或存儲介質損壞的一種常見方式。
Acknowledgments
- I would like to express my sincere gratitude to the authors of the cited works for their valuable contributions to this field. Their research laid the foundation for this review, and their insights greatly enriched the discussion.


)
)
 的深入解析)









》閱讀筆記:p4-p5)




