文章目錄
- 大模型基礎
- 大模型的使用
- 大模型訓練的階段
- 大模型的特點及分類
- 大模型的工作流程
- 分詞化(tokenization)與詞表映射
- 大模型的應用
- 進階
- agent的組成和概念
- planning規劃
- 子任務分解
- ReAct框架
- memory記憶
- Tools工具\工具集的使用
- langchain
- 認知框架
- ReAct框架
- plan-and-Execute計劃與執行
- self-ask(自問自答)
- thinking and self-refection思考并自我反思
- ReAct框架實例
- 通過llamindex實現ReAct RAG Agent
- agent數字人項目實戰
- 提示詞\提示詞工程
- prompt提示詞是什么?
- prompt結構
大模型基礎
foundational Models,基礎模型或稱基座模型,即大模型
大模型的使用
prompt engineering(提示詞工程)
大模型訓練的階段
- 預訓練
- SFT(監督微調)
- RLHF(基于人類反饋的強化學習)
大模型的特點及分類
-
適應性靈活性強
-
廣泛數據集的預訓練
-
計算資源需求大
-
參數規模大
-
大語言模型
-
多模態模型(計算機視覺\語音)
大模型的工作流程
分詞化(tokenization)與詞表映射
- 詞粒度,適用英文
- 字符粒度,中文分詞
- 子詞粒度,將單詞分解為更小的單位
- 每一個token通過預先設置好的詞表,映射為一個tokenid,這是token的身份證
大模型的應用
理解人類或自己本身,就能很好的學會大模型應用及開發
進階
agent的組成和概念
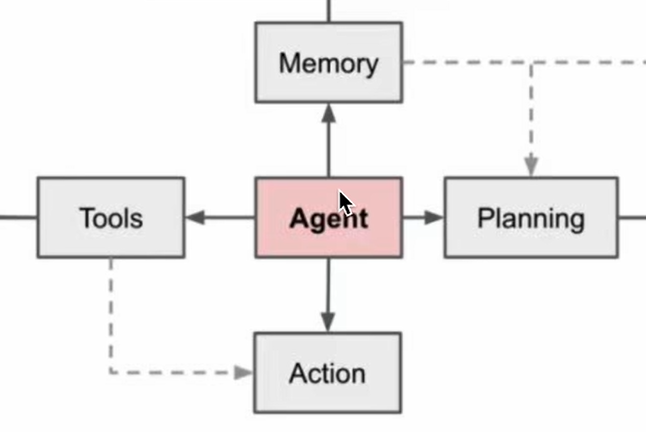
memory + tools + Planning + Action <-----agent
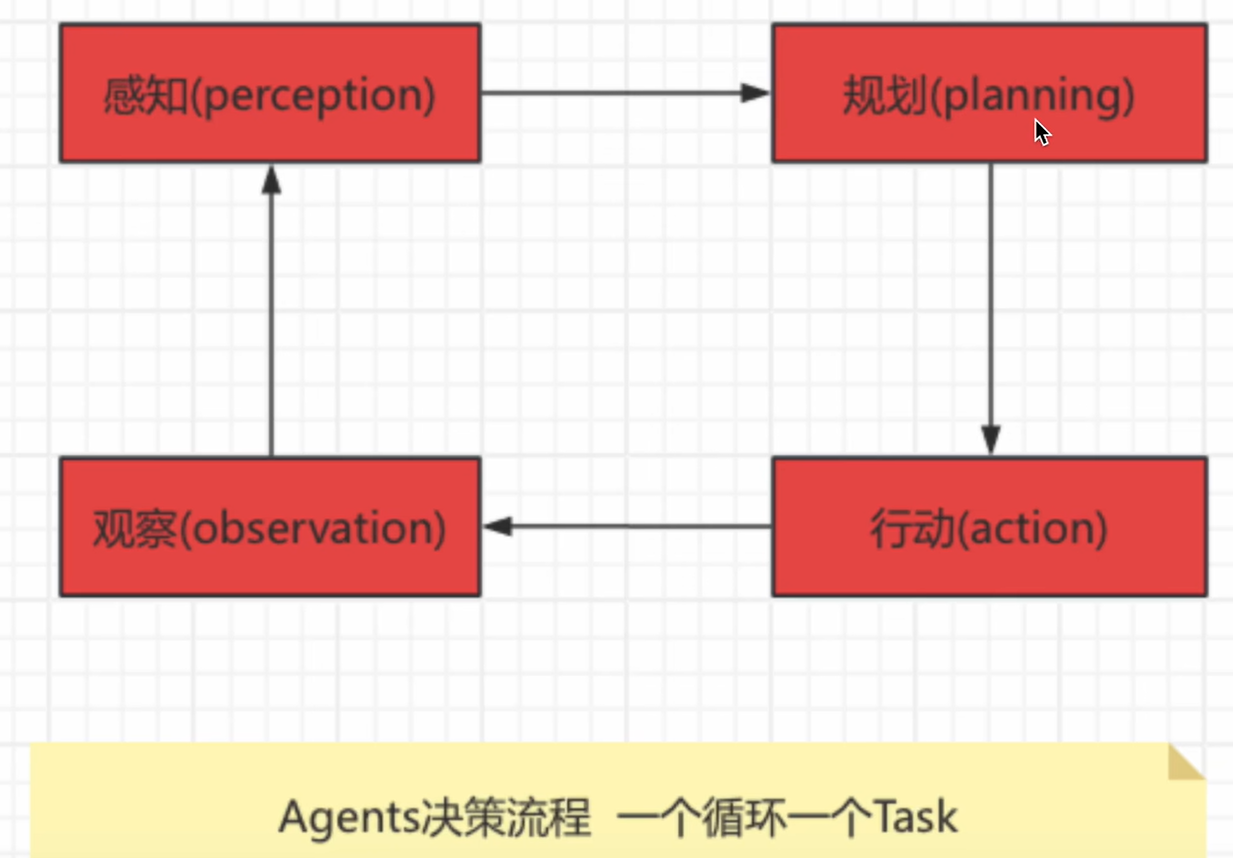
agent的決策流程
planning規劃
子任務分解
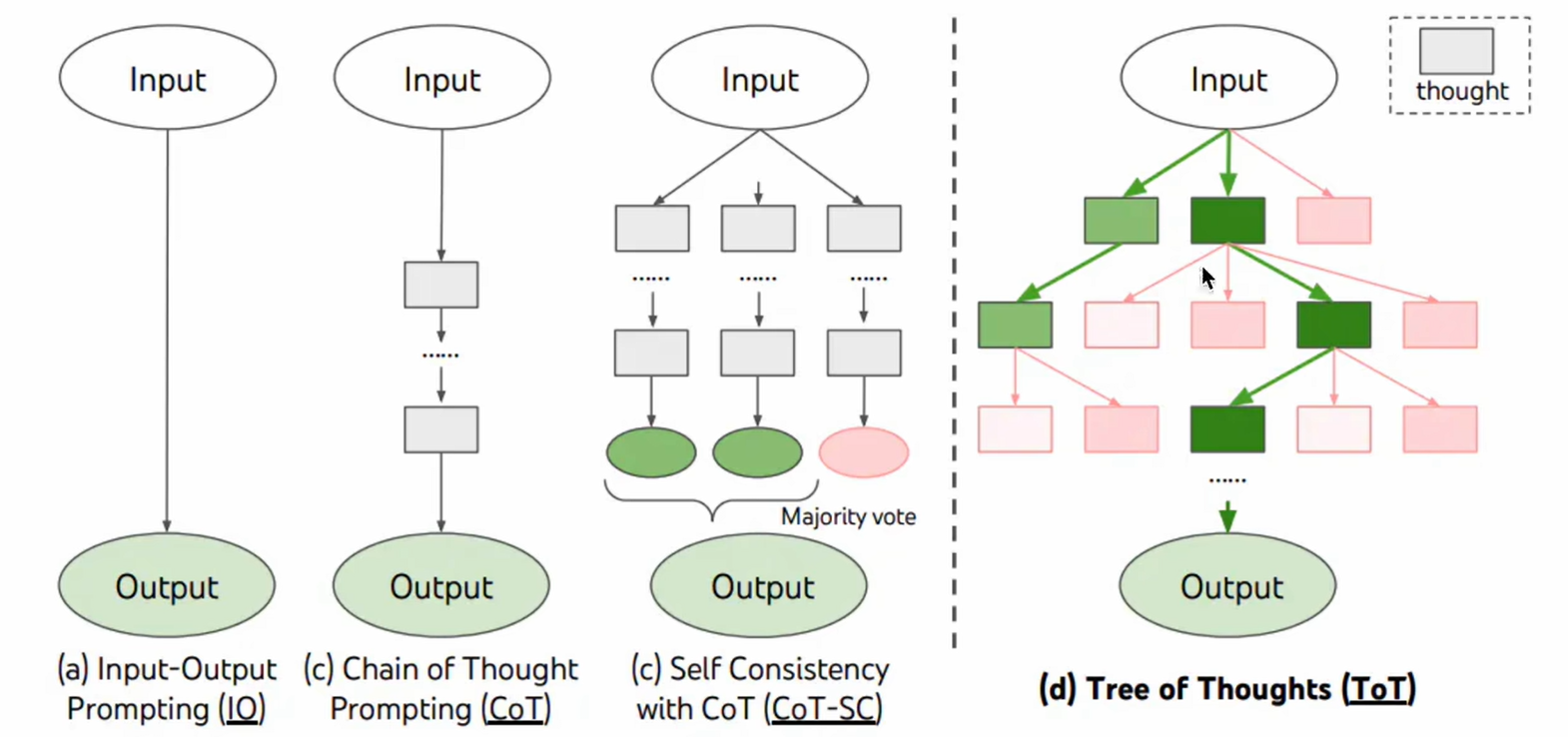
思維鏈(chain of thoughs,CoT)
思維樹(Tree of thoughs,ToT),使用深度優先或廣度優先搜索
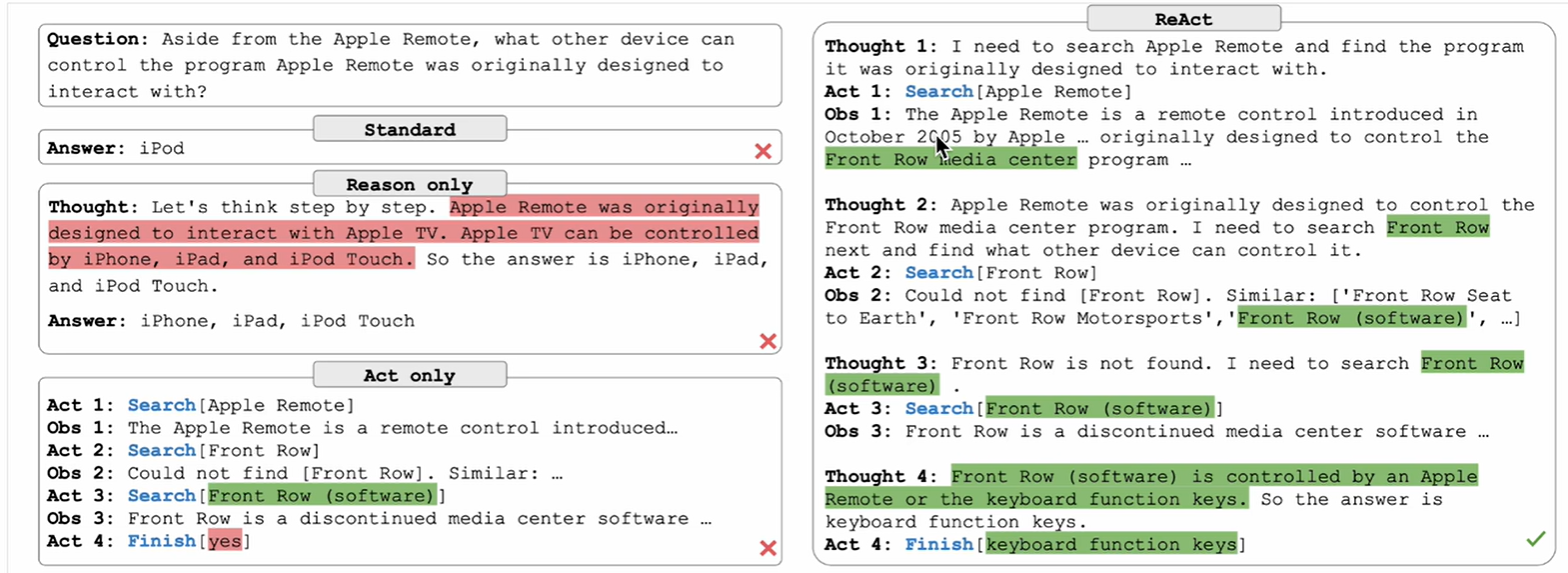
ReAct框架
搜索高端手機,最好用的手機
組合推理和行動.首先通過推理確定搜索"蘋果手機",并從外部環境中觀察結果.隨著推理的深入,識別出需要搜索…幾輪交互后,得出標準答案
memory記憶
智能體中的記憶機制
- 形成記憶,大模型訓練參數得到的記憶
- 短期記憶,當前任務的暫存記憶
- 長期記憶,長期保留的信息,通常用向量數據庫來存儲和檢索
Tools工具\工具集的使用
使用工具突破大模型本身的限制
langchain
agent只是實現智能體的框架,真正的大腦還是LLM
認知框架
ReAct框架
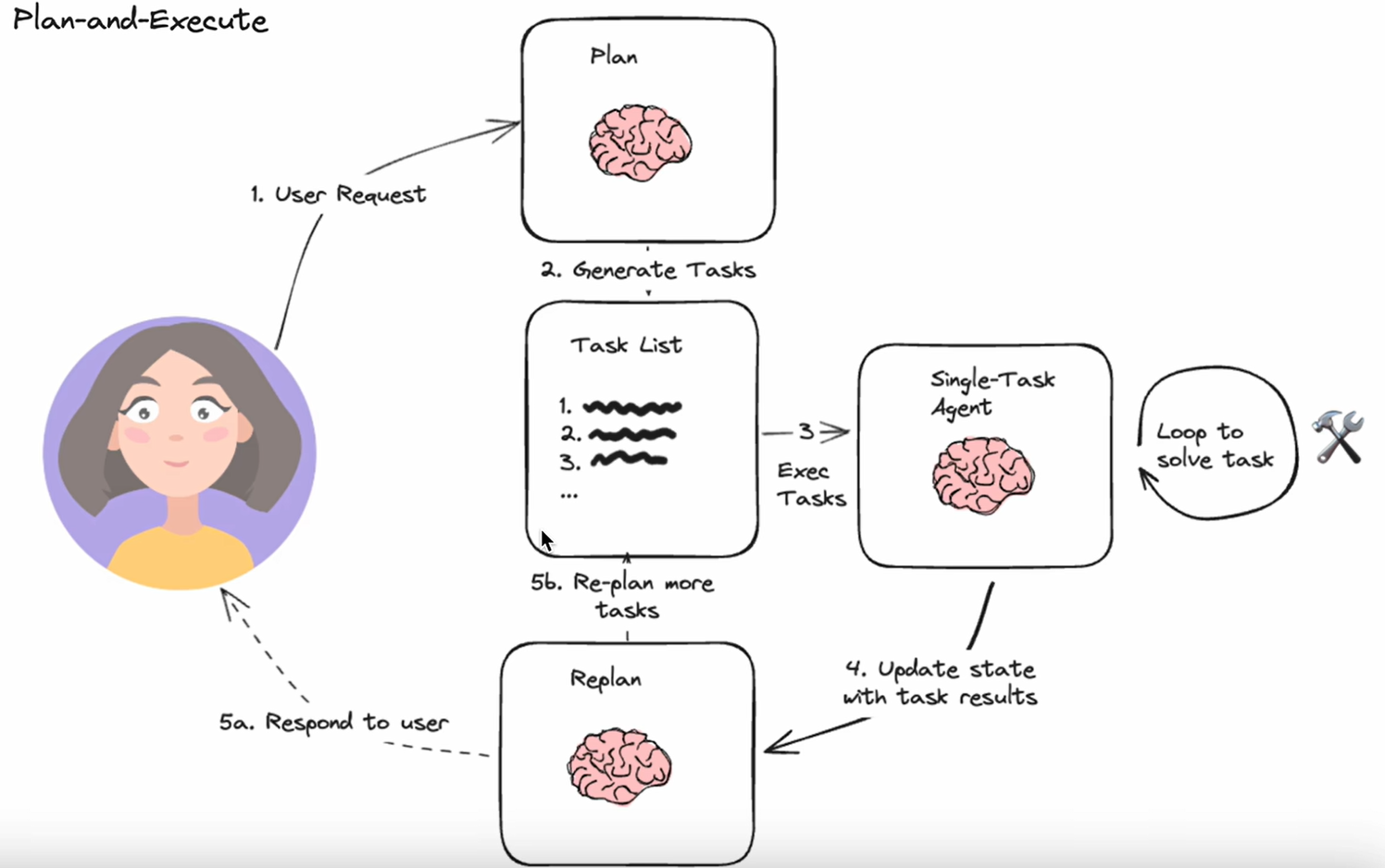
plan-and-Execute計劃與執行
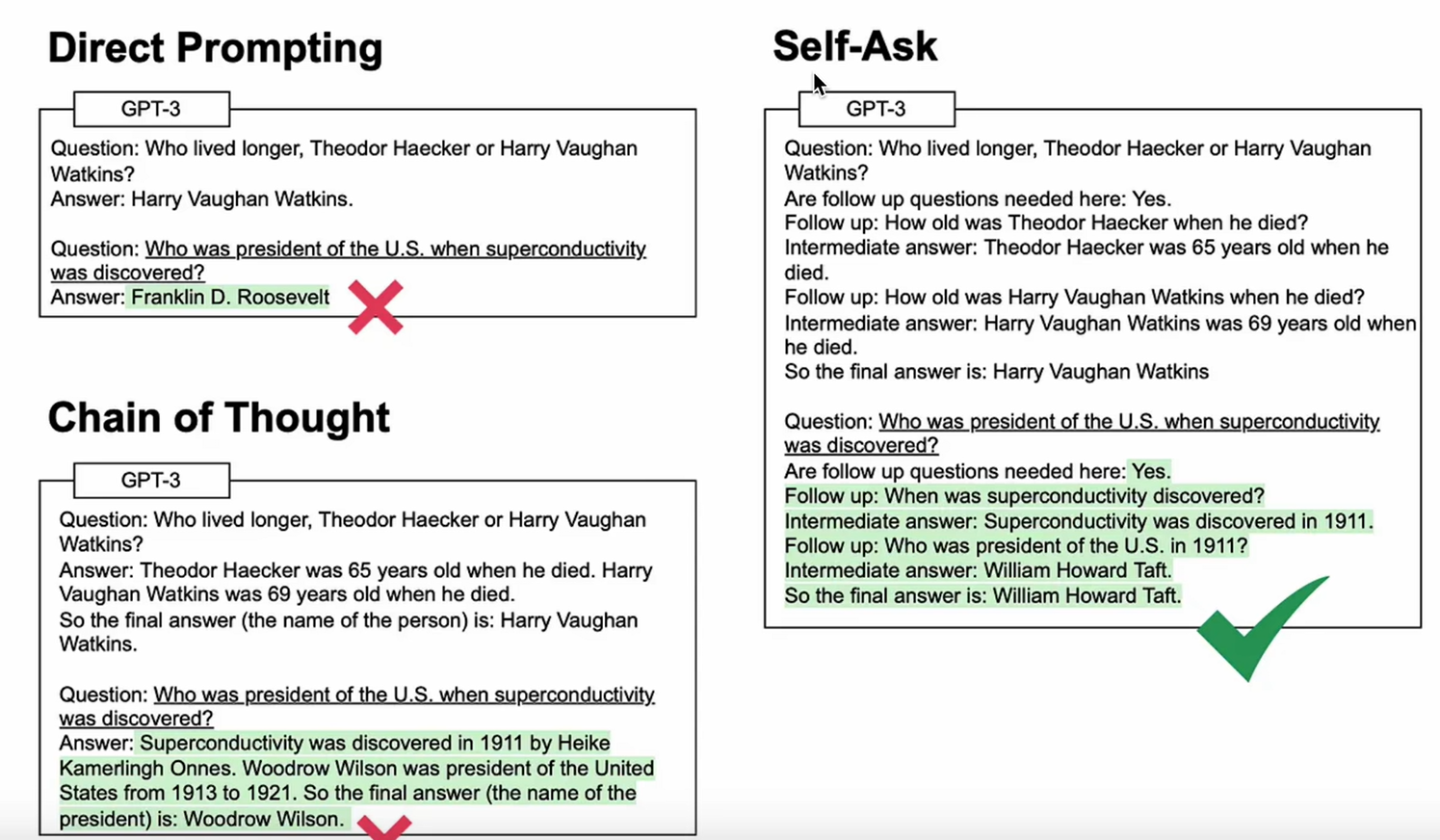
self-ask(自問自答)
thinking and self-refection思考并自我反思
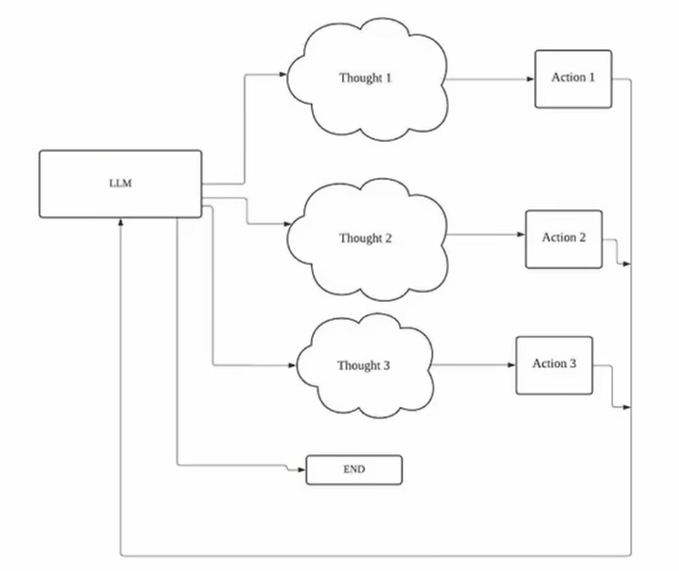
ReAct框架實例
我的理解是langchain已經在這些認知框架中把提示詞封裝好了,不用我們去手寫了
通過llamindex實現ReAct RAG Agent
agent數字人項目實戰
技術棧:agent + RAG + webRPC + docker
一些技術是要收費的
提示詞\提示詞工程
以上我的理解是對的,不同適用場景的AI工具,就是將提示詞工程提前封裝了,不用再讓用戶\使用者麻煩地定義\構建提示詞
- 精確性
- 靈活性多樣性
- 風格
prompt提示詞是什么?
適用大模型時,向其輸入的指令
prompt構建的原則?
- 清晰明確,提供充足的上下文
- 使用標點符號更清晰
- 用樣例數據指引模型輸出
- 分步驟引導
- 一般用json格式,效果最好
prompt結構
- context上下文(上下文),角色\任務\知識
- instruction命令,步驟\思維鏈\示例
- input data輸入數據,句子\文章\問題
- output indicator,輸出格式



題解)





)




![[吾愛出品] 網文提取精靈_4.0](http://pic.xiahunao.cn/[吾愛出品] 網文提取精靈_4.0)





