目錄
1 EXPLAIN命令簡介
1.1 什么是EXPLAIN命令?
1.2 EXPLAIN命令的語法
2 解讀執行計劃中的MapReduce階段
2.1 執行計劃的結構
2.2 Hive查詢執行流程
2.3 MapReduce階段的詳細解讀
3 識別性能瓶頸
3.1 數據傾斜
3.2 Shuffle開銷
3.3 性能瓶頸識別與優化
4 總結
在大數據處理中,Hive作為Hadoop生態中的核心組件,廣泛應用于數據倉庫和數據分析場景。然而,隨著數據量的增長和查詢復雜度的提升,Hive查詢的性能問題逐漸成為開發者和數據工程師關注的焦點。為了優化Hive查詢性能,深入理解查詢的執行計劃至關重要。Hive提供了EXPLAIN命令,可以幫助我們分析查詢的執行計劃,識別性能瓶頸,從而進行針對性的優化。
1 EXPLAIN命令簡介
1.1 什么是EXPLAIN命令?
EXPLAIN是Hive中用于分析查詢執行計劃的命令。通過 EXPLAIN,我們可以查看查詢的詳細執行步驟,包括MapReduce階段、數據流、操作符等信息。這些信息對于優化查詢性能至關重要。
1.2 EXPLAIN命令的語法
EXPLAIN [FORMATTED|EXTENDED|DEPENDENCY|AUTHORIZATION] query;
- FORMATTED:以易讀的格式輸出執行計劃
- EXTENDED:輸出更詳細的執行計劃信息,包括操作符的詳細信息
- DEPENDENCY:顯示查詢依賴的表和分區
- AUTHORIZATION:顯示查詢的授權信息
2 解讀執行計劃中的MapReduce階段
2.1 執行計劃的結構
Hive查詢的執行計劃通常分為以下幾個階段:
- Parse:解析SQL語句,生成抽象語法樹(AST)
- Semantic Analysis:語義分析,驗證表和列的存在性
- Logical Plan:生成邏輯執行計劃
- Optimization:優化邏輯執行計劃
- Physical Plan:生成物理執行計劃
- MapReduce:將物理計劃轉換為MapReduce任務
2.2 Hive查詢執行流程

- SQL Query:輸入SQL查詢語句
- Parse:解析SQL語句,生成抽象語法樹(AST)
- Semantic Analysis:驗證表和列的存在性,確保查詢語義正確
- Logical Plan:生成邏輯執行計劃,描述查詢的邏輯操作
- Optimization:優化邏輯執行計劃,提高查詢效率
- Physical Plan:生成物理執行計劃,描述查詢的具體執行步驟
- MapReduce Execution:將物理計劃轉換為MapReduce任務并執行
- Query Result:返回查詢結果
2.3 MapReduce階段的詳細解讀
在 EXPLAIN的輸出中,MapReduce階段通常包含以下信息:
- Map Operator Tree:描述Map階段的操作符
- Reduce Operator Tree:描述Reduce階段的操作符
- Group By Operator:描述分組操作
- Select Operator:描述選擇操作
- Join Operator:描述連接操作
- 示例:
EXPLAIN
SELECT department, COUNT(*) as emp_count
FROM employees
GROUP BY department;3 識別性能瓶頸
3.1 數據傾斜
數據傾斜是Hive查詢中常見的性能問題,通常發生在 GROUP BY或 JOIN操作中。數據傾斜會導致某些Reducer任務處理的數據量遠大于其他任務,從而拖慢整體查詢速度。識別方法:
- 檢查EXPLAIN輸出中的Group By Operator和Join Operator,觀察是否有某些鍵值的數據量異常大
- 使用COUNT和GROUP BY分析數據分布
解決方案:
- 使用隨機數對數據進行分桶
- 增加Reducer數量
- 使用skewjoin優化連接操作
3.2 Shuffle開銷
Shuffle是MapReduce階段中數據從Map任務傳輸到Reduce任務的過程,通常會產生較大的網絡和磁盤開銷。識別方法:
- 檢查EXPLAIN輸出中的Reduce Operator Tree,觀察Shuffle數據量
- 使用Hadoop的JobTracker或YARN的ResourceManager查看Shuffle階段的詳細指標
解決方案:
- 優化數據分區,減少Shuffle數據量
- 使用壓縮技術減少網絡傳輸開銷
- 調整Reducer數量,平衡Shuffle負載
3.3 性能瓶頸識別與優化
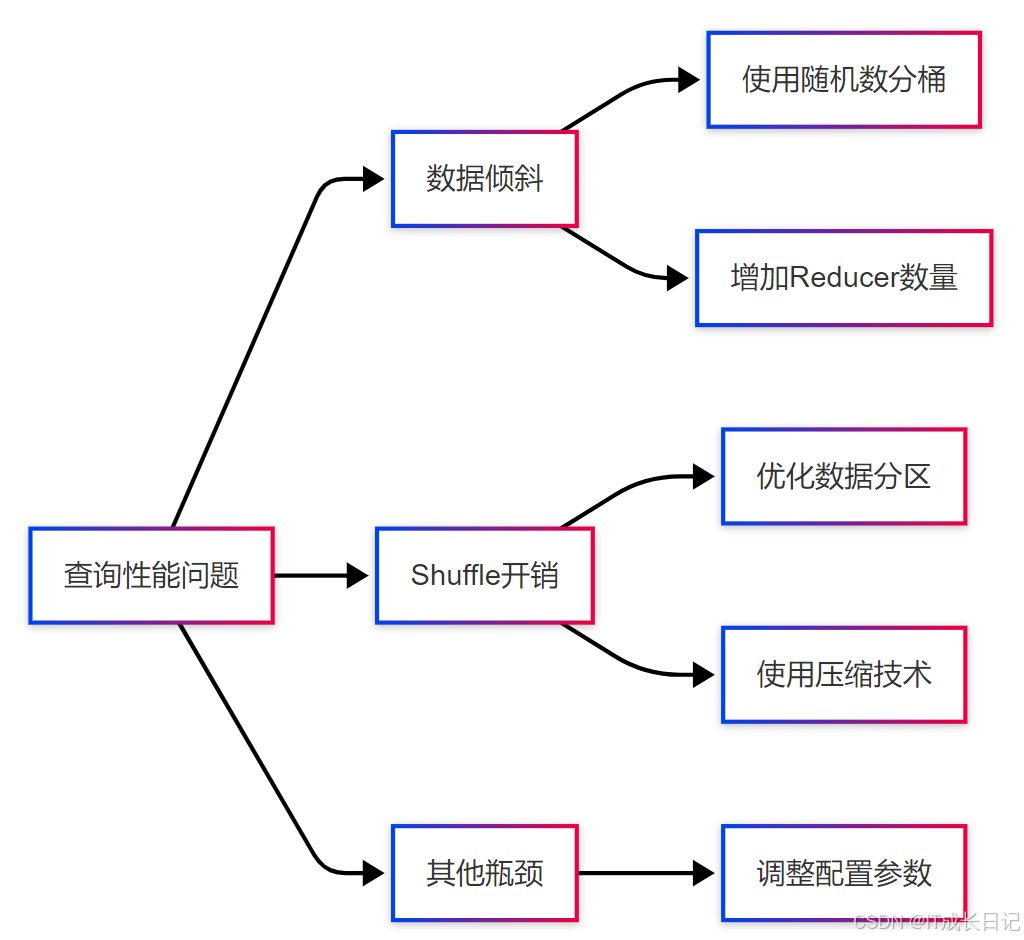
- 查詢性能問題:發現查詢性能不佳
- 數據傾斜:識別數據傾斜問題,采取分桶或增加Reducer數量等措施
- Shuffle開銷:識別Shuffle開銷問題,優化數據分區或使用壓縮技術
- 其他瓶頸:調整Hive配置參數,優化查詢性能
4 總結
EXPLAIN命令是Hive性能優化的重要工具,通過分析執行計劃中的MapReduce階段,我們可以識別查詢的性能瓶頸,如數據傾斜和Shuffle開銷,并采取針對性的優化措施。
)




notificationManager.cancelAll)




![[PRO_A7] SZ501 FPGA開發板簡介](http://pic.xiahunao.cn/[PRO_A7] SZ501 FPGA開發板簡介)


)



--AnimationVisibility)

