前言
本案例希望建立一個UNET網絡模型,來實現對農業遙感圖像語義分割的任務。本篇博客主要包括對上一篇博客中的相關遺留問題進行解決,并對網絡結構進行優化調整以適應個人的硬件設施——NVIDIA GeForce RTX 3050。
本案例的前兩篇博客直達鏈接基于UNet算法的農業遙感圖像語義分割(下)和基于UNet算法的農業遙感圖像語義分割(上)
1.模型簡化
1.1 二分類語義分割效果解答
上一篇博客最終的預測結果為二分類的語義分割,即經過彩色映射后,結果只有黑和藍兩種顏色。原因是因為模型雖然參數更新了1400多次,但其實從遍歷數據集的角度考慮也就65個epoch.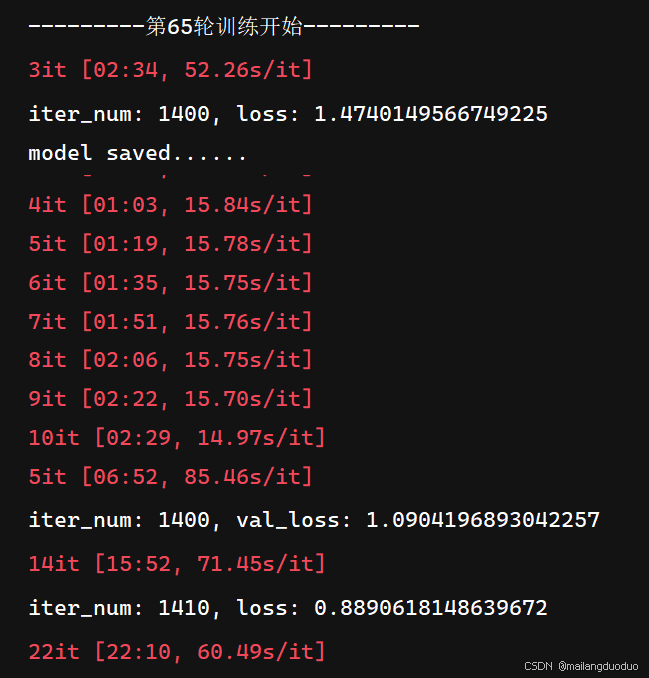
同時網絡模型參數量約7.7M,模型并未充分學習到訓練集上的信息。之所以會出現二分類的預測結果,是與模型初始化權重有關。
1.2網絡模型調整
因此針對上述情況,我將模型改成了單層的編碼器-解碼器架構,同時將Block模塊中做進一步特征融合的卷積層移除,具體結構如下所示:
class Block(nn.Module):def __init__(self, in_channels, out_channels):super(Block, self).__init__()self.relu = nn.ReLU(inplace=False)self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)# self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)def forward(self, x):x = self.conv1(x)x = self.relu(x)# x = self.conv2(x)# x = self.relu(x)return xclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.relu = nn.ReLU(inplace=False)self.pool = nn.MaxPool2d(kernel_size=2, stride=2)# 編碼器部分self.conv1 = Block(3, 32)# 解碼器部分self.up2 = nn.ConvTranspose2d(32, 32, kernel_size=2, stride=2)self.conv2 = Block(32, 32)self.conv3 = nn.Conv2d(32, 4, kernel_size=1)def forward(self, x):# 編碼器conv1 = self.conv1(x) # 32, 512, 512pool1 = self.pool(conv1) # 32, 256, 256# 解碼器up2 = self.up2(pool1) # 32, 512, 512conv2 = self.conv2(up2) # 32, 512, 512conv3 = self.conv3(conv2) # 4, 512, 512return conv3此時查看模型的信息如下所示:
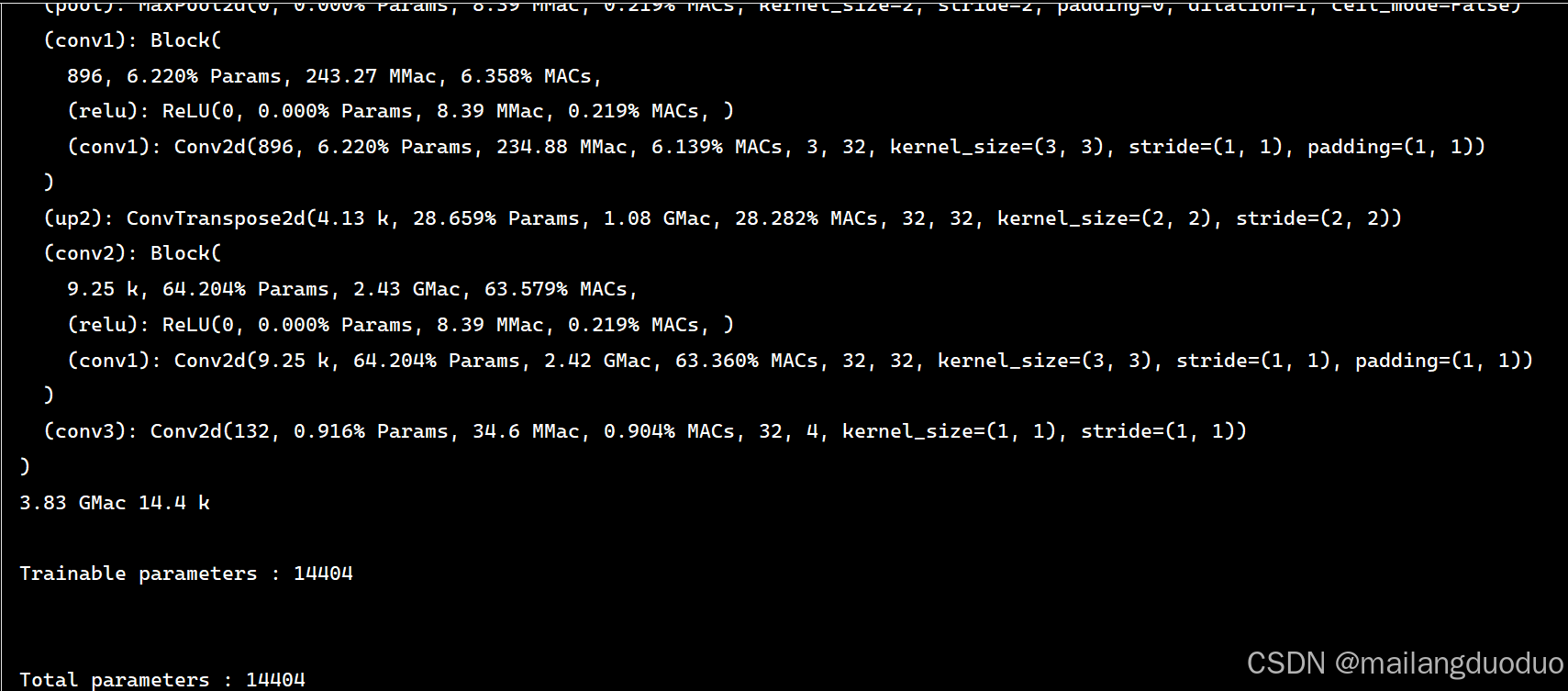
模型的參數量已經減少至14.4k,可以預見結果并不會很好。因為輸入的圖像尺寸就已經512×512×3,相比而言,該模型顯然不能充分擬合該任務。
2.訓練策略調整
2.1訓練損失波動解答
因為統計的損失是按照每個iter進行統計的,每次的迭代過程在該批次下的參數更新朝著當前批次損失變小的方向進行,但對其他批次可能損失會升高,因此損失波動劇烈,但整體呈下降趨勢。
這里的解決方案如下:
- 將參數更新過程中記錄的iter次數進行減少,如
將iter%10==0調整成iter%200==0 - 將參數更新過程中的記錄的結果轉換成累積量,即將10個iter中損失進行累加或者將一個epoch中的所有損失進行累加(本案例后續改進采用該方式)。
- 將參數更新過程中的記錄的結果轉換成平均量,即將10個iter中損失進行平均或者將一個epoch中的所有損失進行平均。
2.2訓練過程調整
因為本案例的數據集本身就很小,所以這里采用的是將一個epoch中的所有損失進行累加統計進行輸出可視化。同時為了避免模型參數保存冗余問題,將模型保存策略進行調整,只保存在驗證集上損失最小的模型,同時使用覆蓋原則將之前的保存模型進行覆蓋,以節省空間開銷,具體代碼調整如下:
# 創建一個 SummaryWriter 對象,用于將數據寫入 TensorBoardwriter = SummaryWriter("dataset/logs")epoch = 0best_val_loss = float('inf')# best_val_loss = 7.899# model.load_state_dict(torch.load('./models/secweights_40.pth'))while epoch < 500:epoch += 1print("---------第{}輪訓練開始---------".format(epoch))train_loss = 0for i, (img, label) in tqdm(enumerate(dataloader_train)):img = img.to(device).float()label = label.long().to(device)model.train()output = model(img)# output = torch.argmax(output, dim=1).double()# iter_num += 1loss = getLoss(output, label)train_loss += loss.item()loss.backward()optimizer.step()optimizer.zero_grad()# print("---------第{}輪訓練結束---------".format(epoch))print("第{}輪訓練的損失為:{}".format(epoch, train_loss))writer.add_scalar('Training Loss3', train_loss, epoch)if epoch % 10 == 0:# torch.save(model.state_dict(), './models/thirdweights_{}.pth'.format(epoch))val_loss = 0with torch.no_grad():model.eval()for i, (img, label) in tqdm(enumerate(dataloader_val)):img = img.to(device).float()label = label.long().to(device)output = model(img)loss = getLoss(output, label)val_loss += loss.item()print("第{}輪驗證的損失為:{}".format(epoch, val_loss))if val_loss < best_val_loss:best_val_loss = val_losstorch.save(model.state_dict(), './models/best_model2.pth')print("Saved new best model")writer.add_scalar('Validation Loss3', val_loss, epoch)writer.close()3.結果分析
3.1訓練過程損失
在訓練過程中的損失記錄如下:
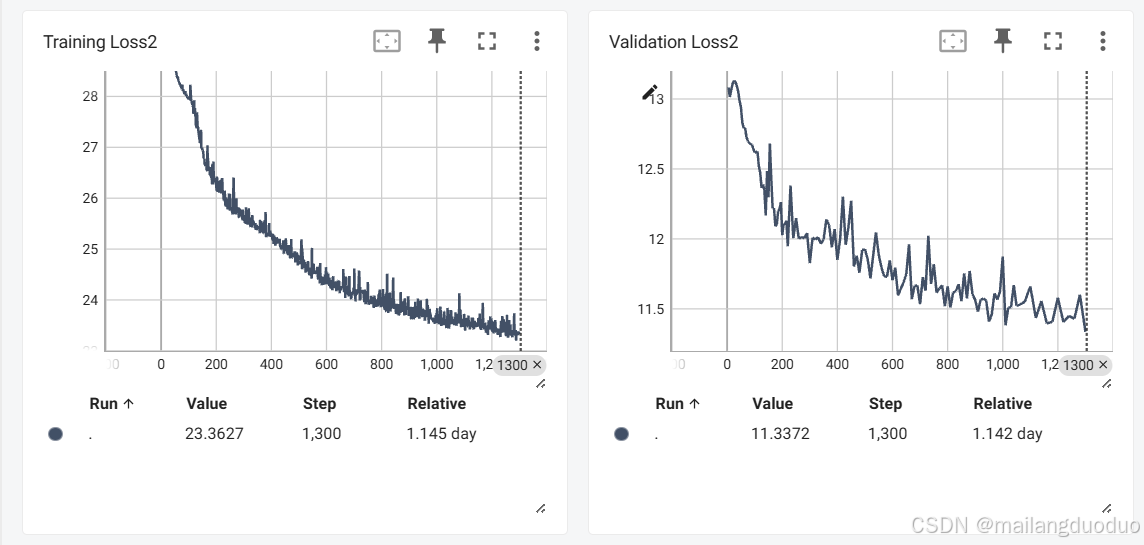
通過結果可以看出上述修改方式確實取得了不錯的效果,模型訓練集的抖動已大幅度減小。
從曲線角度考慮,訓練集損失已經趨向于平穩,同時驗證集上損失也趨向于平穩,由此判斷模型已經基本收斂,但訓練集的損失仍停留在較高水平,大概率是因為模型過于簡單,難以擬合該任務的需求。
3.2模型預測結果
這里將模型最終保存的結果加載進來,對未知圖片進行預測,代碼如下:
import matplotlib.pyplot as plt
import torch
import cv2
import numpy as np
from torch.utils.tensorboard import SummaryWriterfrom Net2 import Net# I=cv2.imread('dataset/0.9/image/16213.png')#dataset/test.png
I=cv2.imread('dataset/test.png')
I=np.transpose(I, (2, 0, 1))
I=I/255.0
I=I.reshape(1,3,512,512)
I=torch.tensor(I)
model=Net().double()
model.load_state_dict(torch.load('models/best_model2.pth'))
output=model(I)
# print(output.shape)
# print(output[0,:,:5,:5])
predicted_classes = torch.argmax(output, dim=1).squeeze(0).numpy()color_map = {0: [0, 0, 0], # 黑色1: [255, 0, 0], # 紅色2: [0, 255, 0], # 綠色3: [0, 0, 255] # 藍色
}height, width = predicted_classes.shape
colored_image = np.zeros((height, width, 3), dtype=np.uint8)
for i in range(height):for j in range(width):class_id = predicted_classes[i, j]colored_image[i, j] = color_map[class_id]plt.imshow(colored_image)
plt.axis('off')
plt.show()
print(colored_image.shape)
colored_image=np.transpose(colored_image, (2, 0, 1))
writer=SummaryWriter('dataset/logs')writer.add_image('test3',colored_image)
writer.close()預測結果如下:
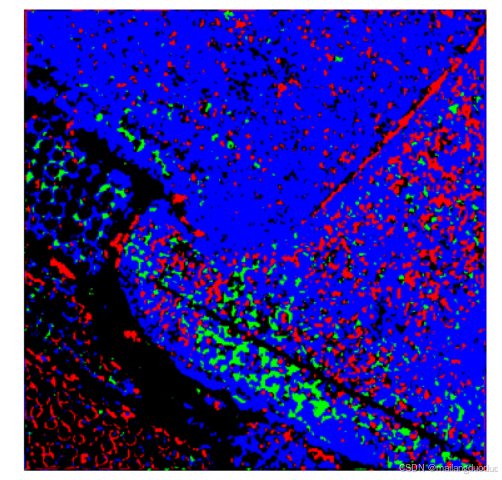
從結果角度考慮,確實實現了四分類的語義分割效果,但預測的效果并不是很好,因此需要進一步修改網絡結構。
4.網絡模型優化
具體修改主要包括引入批量規范化BatchNormalization的處理和增加了Dropout的機制以及對網絡結構調整為三層的編碼器-解碼器架構。
4.1 BatchNormalization
批量規范化的核心思想是對每一層的輸入進行歸一化處理,使得每一層的輸入分布在訓練過程中保持相對穩定。具體來說,它將輸入數據的每個特征維度都歸一化到均值為 0、方差為 1 的標準正態分布。這樣可以減少內部協變量偏移的影響,加快訓練速度。
這里還有其他的逐層歸一化方式,這里不做詳細介紹。因為BatchNormalization聚焦于小批量層面,更適用于該任務,或者說更適用視覺圖像處理方面

圖片來源:本校《深度學習》課程的PPT
4.2 Dropout的機制
Dropout的機制能有效防止過擬合,在訓練神經網絡時,它通過以一定的概率隨機將神經元的輸出設置為0,即暫時“丟棄”這些神經元及其連接,每次迭代訓練時在訓練一個不同的子網絡,通過多個子網絡的綜合效果來提高模型的泛化能力。類似于基學習器和集成學習的思想。
4.3網絡模型代碼
上述的兩種方式是針對Block模塊的,這里為了更好的擬合語義分割的任務,需要進一步加深網絡結構,考慮到硬件資源有限,于是使用的是三層編碼器-解碼器架構,修改后的網絡模型完整代碼如下:
class Block(nn.Module):def __init__(self, in_channels, out_channels, dropout_rate=0.1):super(Block, self).__init__()self.relu = nn.ReLU(inplace=False)self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(out_channels)self.dropout1 = nn.Dropout2d(p=dropout_rate)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(out_channels)self.dropout2 = nn.Dropout2d(p=dropout_rate)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.dropout1(x)x = self.conv2(x)x = self.bn2(x)x = self.relu(x)x = self.dropout2(x)return xclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.relu = nn.ReLU(inplace=False)self.pool = nn.MaxPool2d(kernel_size=2, stride=2)# 編碼器部分self.conv1 = Block(3, 32)self.conv2 = Block(32, 64)self.conv3 = Block(64, 128)# 解碼器部分self.up4 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)self.conv4 = Block(128, 64)self.up5 = nn.ConvTranspose2d(64, 32, kernel_size=2, stride=2)self.conv5 = Block(64, 32)self.conv6 = nn.Conv2d(32, 4, kernel_size=1)def forward(self, x):# 編碼器conv1 = self.conv1(x) # 32, 512, 512pool1 = self.pool(conv1) # 32, 256, 256conv2 = self.conv2(pool1) # 64, 256, 256pool2 = self.pool(conv2) # 64, 128, 128conv3 = self.conv3(pool2) # 128, 128, 128# 解碼器up4 = self.up4(conv3) # 64, 256, 256conv4 = torch.cat([up4, conv2], dim=1) # 128, 256, 256conv4 = self.conv4(conv4) # 64, 256, 256up5 = self.up5(conv4) # 32, 512, 512conv5 = torch.cat([up5, conv1], dim=1) # 64, 512, 512conv5 = self.conv5(conv5) # 32, 512, 512conv6 = self.conv6(conv5) # 4, 512, 512return conv6
5.改進模型結果分析
訓練策略和之前保持不變,這里就不重復解釋,只對結果進行說明。
5.1訓練過程損失
訓練過程損失記錄如下:
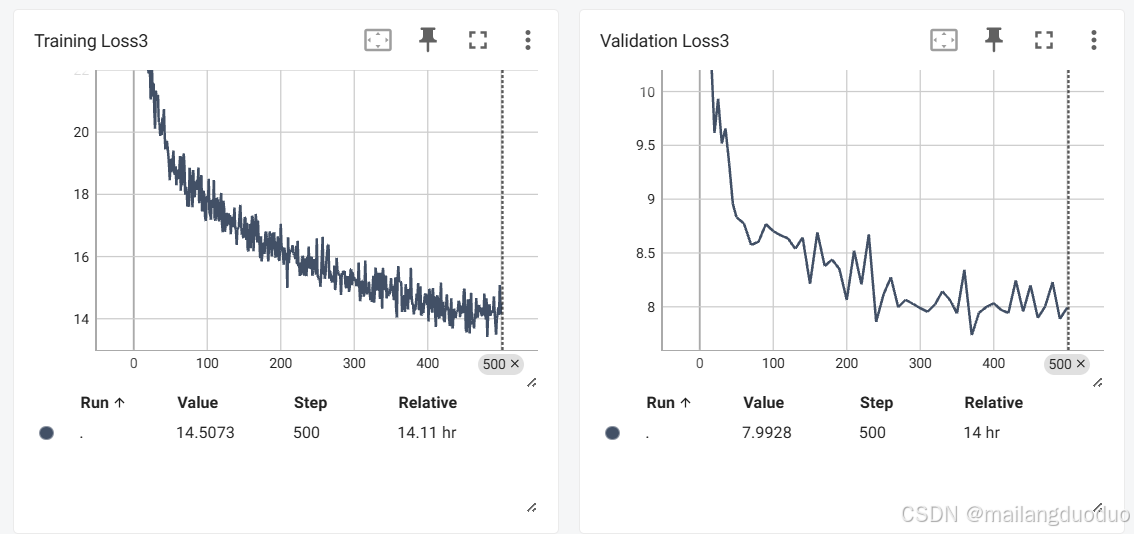
通過結果看到,訓練集和驗證集損失也基本趨于平穩,因此判斷模型基本收斂。
5.2模型預測結果
將之前訓練好的模型參數加載進來,對未知圖片進行預測,結果如下:
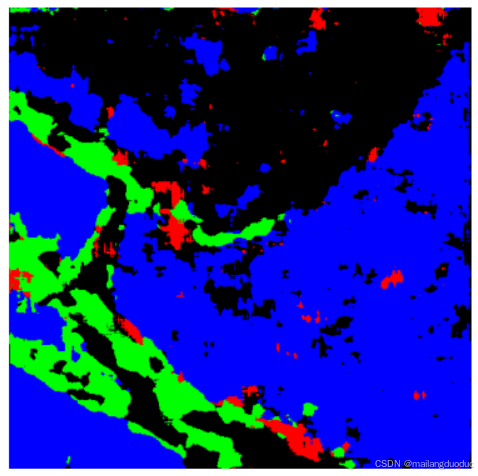
通過結果可以看出,預測結果相對于之前有了很大的改善,基本實現了語義分割的效果,只是在微小內容上,識別的并不準確。可能是因為模型還是不夠復雜,不足以擬合該任務。
6.結語
至此,基于UNET算法的農業遙感圖像語義分割任務到此結束,期望能夠對你有所幫助。同時該項目也是我接觸的第一個語義分割項目,解釋的如有不足還請批評指出!!!
--AnimationVisibility)












Day14!!!C/C++)




![后端[特殊字符][特殊字符]看前端之Row與Col](http://pic.xiahunao.cn/后端[特殊字符][特殊字符]看前端之Row與Col)
![[特殊字符] SpringCloud項目中使用OpenFeign進行微服務遠程調用詳解(含連接池與日志配置)](http://pic.xiahunao.cn/[特殊字符] SpringCloud項目中使用OpenFeign進行微服務遠程調用詳解(含連接池與日志配置))