目錄
前言:
引入哨兵
模擬哨兵機制
配置docker環境
基于docker環境搭建哨兵環境
對比三種配置文件
編排主從節點和sentinel
主從節點
sentinel
模擬哨兵
前言:
在前文我們介紹了Redis的主從復制有一個最大的缺點就是,主節點掛了之后沒有辦法迅速重啟,畢竟即便主節點掛了,人工干預恢復的話,也要花費許多時間,想必各位程序員也不想在夜深人靜的時候突然去公司加班就為了修復一下主節點吧?
所以,Redis引入了另一個進制,即哨兵機制,一般來說只用主從模式的話,可用性不是很高的,所以一般來說式主從模式+哨兵一起使用。
那么我們本文就是圍繞哨兵展開一系列的學習了。
引入哨兵
首先我們只是知道主從復制一旦主節點掛了之后的后果還是比較嚴重的,我們現在就來更加細化一下主節點掛了之后的修復工作。
當我們沒有引入哨兵機制的時候,主節點掛了的流程應該是這樣的:
1.先看主節點是否容易搶救,好不好搶救
2.如果主節點好搶救,那么也算是萬事大吉了
3.如果主節點不好搶救,即短時間找不到原因
? ? ? ? i)挑選一個從節點,通過slaveof no one使它成為主節點
? ? ? ? ii)把其他的從節點通過命令行slaveof newHostip newHostport的方式連接新的主節點
? ? ? ? iii)修改客戶端的配置,使得每個客戶端能夠成功連接上新的主節點,從而完成數據修改的操作
這個過程看起來簡單,但是實際上我們知道的是,這一套流程下來,多的不說,至少半個小時就耗進去了吧?
那么在這個時間段內,讀的請求無所謂,有其他的從節點支撐著,但是寫的請求呢?既然都引入了分布式系統,那么寫的請求想必也不會少到哪里去,那么這個事件給整個公司帶來的沖擊還是比較大的。
所以我們需要一個類似于監管者的角色,用來實時檢測每個節點的情況,比如某個節點掛了,這個監管者看到了就要開始干對應的事兒了。
那么,我們將這個監管者,稱之為“哨兵”。這樣我們就可以舍去對應的人工成本了。但是我們要注意的點是哨兵并不是我們的Redis服務器,它是單獨部署在其他服務器的一個Redis sentinel進程。
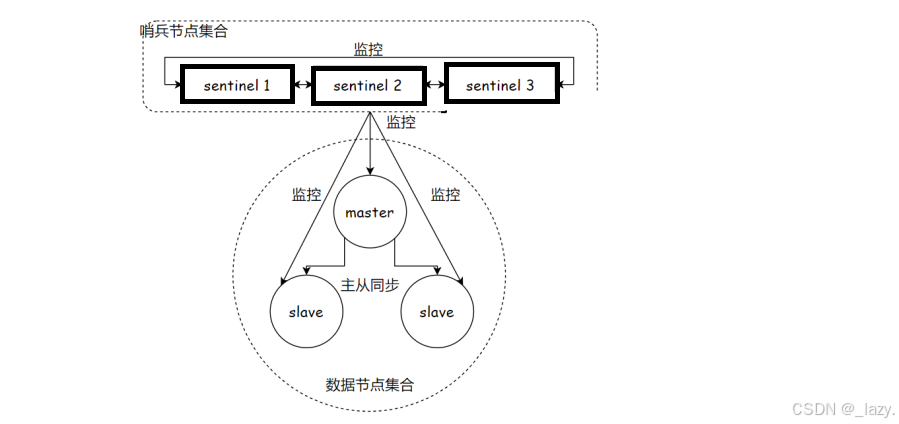
我們現在假定有三個節點,分別一個主節點兩個從節點,并且我們引入了三個哨兵,而因為哨兵本質上是一種輕量級服務,所以同時監測多個Redis服務器是完全可以的。
并且我們要清楚,哨兵檢測的機制是通過與redis-server建立tcp長連接,定時發送心跳包,如果超過既定的時間沒有收到PONG,也就代表了機器掛了。
那么我們就基于主從復制+哨兵機制的情況下,簡單概述一下主節點掛了的情況下,整個體系是如何運作的。
首先,某個節點掛了,那么哨兵會判斷是主節點還是從節點,如果是從節點,那么哨兵的一致想法都是:哦。
其次,如果是主節點掛了,那么首先監測到的哨兵會給該節點標志位s_down(主觀下線),如果多個哨兵節點都認為它下線了,那么它的標志就會變成o_down(客觀下線)。
然后,已經確定主節點已經掛了的情況下,會從多個哨兵節點里面選取一個leader,讓這個leader在剩余的節點里面選取一個主節點,選取成功之后,就會開始控制被選中的節點,通過slaveof命令等,修改主節點的配置和從節點的配置。
最后,哨兵會自動通知客戶端程序,告訴新的主節點是誰,從而完成數據同步工作。
我們現在可以得出結論,哨兵的作用就是:監控,故障轉移,通知。那么哨兵只有一個的話,也是可以的,但是誤判的概率就比較高了,這個點涉及到s_down和o_down,后面細說,并且誤判也會存在一種情況就是因為網絡波動,畢竟網絡波動導致了丟包或者抖動,剛好哨兵就收不到對應的PONG,也就誤判了。而哨兵的個數,也應該是奇數個,這個點我們到后面的票數再細說。
以上就是引入哨兵機制后,簡單的一個恢復流程,那么里面還有更多的細節,我們先不著急。我們現在思考如何進行對應的模擬?
模擬哨兵機制
咱們這里為什么要叫哨兵模擬機制呢?因為我們現在是沒有辦法真正演示哨兵機制的,你想,哨兵是一個單獨的程序,并且在一個單獨的服務器上,先不談我們只有一臺云服務器,我們光是節點就需要6個,那么我們好像是要需要6個服務器?
那么好,如果你說咱就是去買6個服務器,我們的電腦也不一定能夠承受的了6個服務器,即便是六個輕量級的云服務器。所以我們需要一種技術讓我們的云服務器上能運行3個節點3個哨兵。畢竟對于大多數的輕量級配置(2核4G)還是難以直接操作這么多服務,畢竟我們如果直接配置,我們還需要小心的避開依賴的端口號,依賴的配置文件和依賴的數據文件,就非常繁瑣了。
這里就需要用到了docker技術了,docker就能完美解決以上的問題。
Docker 通過資源隔離、輕量虛擬化、配置自動化等手段,讓你在有限資源的機器上運行多個服務變得可控、高效且易管理。docke中引入容器和鏡像的概念,對于容器來說,我們可以理解它把實例化的內容放在了容器里面,具有隔離性,不會干擾彼此,所以我們就能躲開沖突的資源分配的問題了。Docker 使用的是宿主機內核,不會像虛擬機那樣消耗額外內存和 CPU 核心。
對于容器和鏡像來說,我們可以理解是進程和可執行程序之間的關系,我們通過鏡像,啟動了多個容器,每個容器相當于一個進程,互不打擾,我們通過對應的配置文件就可以達到我們想要的效果。
我們現在就需要配置docker的環境了。
配置docker環境
對于云服務器來說,有的云服務器是默認安裝了docker鏡像的,具體我們可以使用docker --version查看一下:
有了docker之后,我們安裝docker-compose,這兩個的關系如圖:
| 項目 | Docker | Docker Compose |
|---|---|---|
| 作用 | 管理單個容器 | 管理多個容器組成的服務 |
| 配置方式 | 命令行為主 | 配置文件(YAML) |
| 適用場景 | 啟動一個測試 Redis、Nginx | 啟動一個完整的集群、項目或環境 |
| 使用方式 | docker run, docker build | docker-compose up, docker-compose down |
| 依賴 | 獨立運行 | 基于 Docker CLI 運行(必須裝了 Docker) |
相當于Docker是一個造船廠,docker compose是造船圖紙,docker通過compose來管理這么多容器。
安裝docker-compose也非常簡單,直接apt install docker-compose -y即可:
不過我這里已經安裝好了。
然后我們需要停止一下之前的Redis服務,因為當我們使用docker的時候,啟動對應的Redis鏡像,默認的端口號都是6379,不停止redis服務就啟動docker的話,會存在端口沖突問題,導致docker啟動不了。
這里我們推薦的做法是不再使用Redis服務,就使用docker服務即可。(推薦)
sudo systemctl stop redis
# 或者
sudo service redis-server stop
我們可以通過這兩個方式停止Redis的服務,記住不能使用kil -9哦。
然后我們需要使用docker獲取到redis的鏡像,畢竟沒有可執行程序我們也就沒有辦法啟動進程了。對應的命令是docker pull redis:7.2,也可以是docker pull redis:5.0.9,5.0.9的版本較老但是非常穩定,7.2的版本是最新的穩定版,體驗相對好一點,其實我們都感覺不出來所以隨便選一個了。
不過這里我們會面臨一個問題就是被墻,這是國內服務器(像騰訊云、阿里云、華為云)常見的現象,因為訪問 Docker Hub 會被墻或受限,導致連接慢、超時、甚至失敗。報錯信息常見為:
此時我們需要在etc的docker目錄下創建一個daemon.json配置文件,根據自己的云服務器添加相關配置文件,然后systemctl daemon-reexec再sudo systemctl restart docker重啟一下docker服務即可,對于騰訊云的配置文件是這樣的:
{"registry-mirrors": ["https://mirror.ccs.tencentyun.com"]
}
此時我們拉取對應的鏡像就沒有問題了。可以使用docker images查看對應的鏡像倉庫
具體的信息我們到時候更新docker會著重介紹。這里我們先看著玩即可。
基于docker環境搭建哨兵環境
現在我們已經有了對應的docker環境和對應的Redis鏡像了。那么我們前文介紹到了docker-compose是啟動對應實例的利器,并且我們是通過配置文件的方式啟動對應的實例,那么實例的相關配置也是在對應的配置文件里寫了。
問題來了,我們常見的配置文件有conf,json,xml,但是這里的配置文件可不是這里面的了,docker-compose的配置文件的格式是yml。
對比三種配置文件
我們這里簡單對比一下json,xml,yml三種配置文件。
其中最為繁瑣的配置文件當屬xml文件了,以下是一個示例:
<services><redis><image>redis:7.2</image><container_name>redis-master</container_name><ports><port>6379:6379</port></ports><volumes><volume>./data:/data</volume></volumes><command>redis-server --appendonly yes</command></redis>
</services>
這是XML文件的redis配置文件。
{"services": {"redis": {"image": "redis:7.2","container_name": "redis-master","ports": ["6379:6379"],"volumes": ["./data:/data"],"command": "redis-server --appendonly yes"}}
}
這是json的配置文件。
services:redis:image: redis:7.2container_name: redis-masterports:- "6379:6379"volumes:- ./data:/datacommand: redis-server --appendonly yes
這是yml文件的配置文件。
我們光從第一印象就能發現json文件和yml文件比xml文件簡潔太多了,對于xml文件來說,它敲起來可真的太繁瑣了。
那么對于json文件來說,它主要是通過花括號來表現配置的,對于yml文件來說它主要是通過縮進來表現配置的,那么在江湖上總有人戲稱yml文件是游標卡尺,因為內容一多,真就得拿個游標卡尺去比對一下了。
那么不同的配置文件有不同的優勢,我們這里主要是做一個了解。有了對文件的基本了解之后,就可以開始編排主從節點和哨兵了。
編排主從節點和sentinel
主從節點
首先編寫主從節點的配置文件:
在家目錄下創建一個redis的目錄,然后創建一個docker-compose.yml配置文件,使用vim編輯,復制這么一段配置:
version: '3'
services:redis-master:image: redis:7.2container_name: redis-masterports:- "6379:6379"command: ["redis-server", "--appendonly", "yes"]redis-slave1:image: redis:7.2container_name: redis-slave1ports:- "6380:6379"command: ["redis-server", "--appendonly", "yes", "--slaveof", "redis-master", "6379"]redis-slave2:image: redis:7.2container_name: redis-slave2ports:- "6381:6379"command: ["redis-server", "--appendonly", "yes", "--slaveof", "redis-master", "6379"]
我們從截取一段來看,image代表的是鏡像的版本,container_name代表的是容器名字,ports有兩個,6380:6379,6380代表的是宿主機的端口號,我們可以通過映射出來的6380端口號訪問這個容器,6379代表的是這個容器里面的redis分配的端口號,默認都是6379。然后是網絡,啟動的命令是和我們之前的通過命令行方式啟動服務的時候非常相似了,指定主節點。
而這里同學們大概率會有疑問了,我們之前指定主節點的時候,都是通過的slaveof hostip hostport指定的,那么這里的話,docker有自己的一套域名解析方法,可以根據對應的名字給到對應的ip。所以我們可以直接指定名字。
此時我們主從節點的配置有了,我們就可以通過命令docker-compose up -d全部啟動了:
d代表的是我們讓容器在后臺運行,不然就會一直在前臺打印對應的信息了。
我們也可以通過docker-compose log查看一下運行日志:
這是一部分,有很多的。
然后我們就可以驗證一下是否啟動成功了: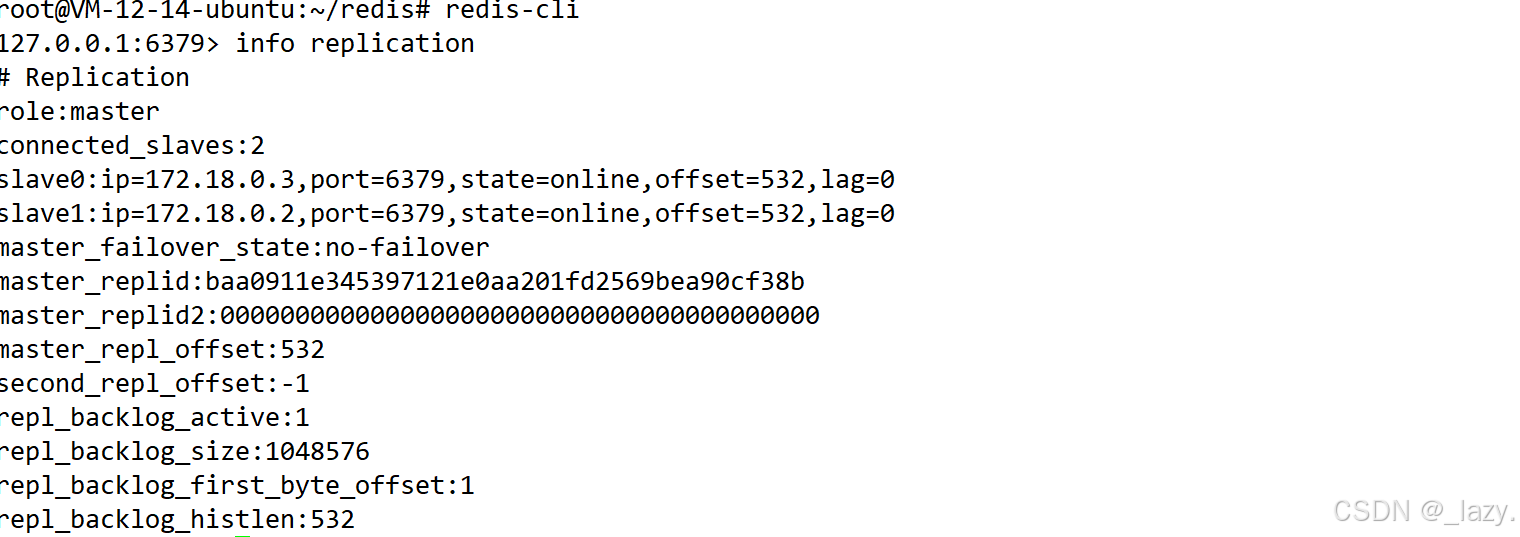
從節點這里就不驗證了,是同樣的操作。?
sentinel
我們同樣先創建一個和redis同級的目錄redis-sentinel:
然后在這里面配置:
version: '3'services:sentinel1:image: 'redis:7.2'container_name: redis-sentinel-1restart: alwayscommand: ["redis-sentinel", "/etc/redis/sentinel.conf"]
# command: ["/bin/sh", "/wait.sh"]volumes:- ./filesentinel1:/etc/redis# - ./sentinel1.conf:/etc/redis/sentinel.conf#- ./wait.sh:/wait.shports:- "26379:26379"networks:- defaultsentinel2:image: 'redis:7.2'container_name: redis-sentinel-2restart: alwayscommand: ["redis-sentinel", "/etc/redis/sentinel.conf"]volumes:- ./filesentinel2:/etc/redis#- ./sentinel2.conf:/etc/redis/sentinel.confports:- "26380:26379"sentinel3:image: 'redis:7.2'container_name: redis-sentinel-3restart: alwayscommand: ["redis-sentinel", "/etc/redis/sentinel.conf"]volumes:- ./filesentinel3:/etc/redis# - ./sentinel3.conf:/etc/redis/sentinel.confports:- "26381:26379"
networks:default:external:name: redis_default
不過對于哨兵來說配置文件是不能使用同一份的,因為哨兵在運行的時候會對各自的配置文件進行修改,所以需要多份配置文件。
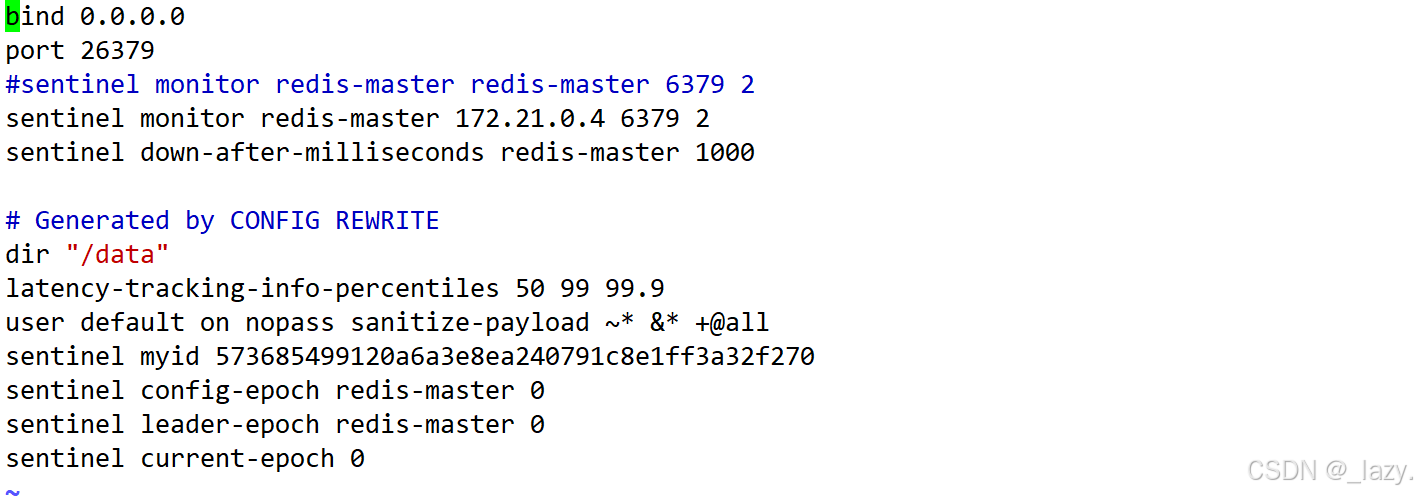
bind 0.0.0.0
port 26379
sentinel monitor redis-master redis-master 6379 2
sentinel down-after-milliseconds redis-master 1000
哨兵的配置文件如上。
對于配置文件來說,第一行代表可以訪問任意的ip,對于第二行來說代表的是端口號,sentinel默認的端口號就是26379,第三行代表的是法定票數,為2,和推薦哨兵個數為奇數有關。然后就是心跳包的截止時間了,1000ms代表的是如果1s內沒有收到PONG,就認為機器掛了。
那么在這里我們著重解釋一下command部分和volumes部分: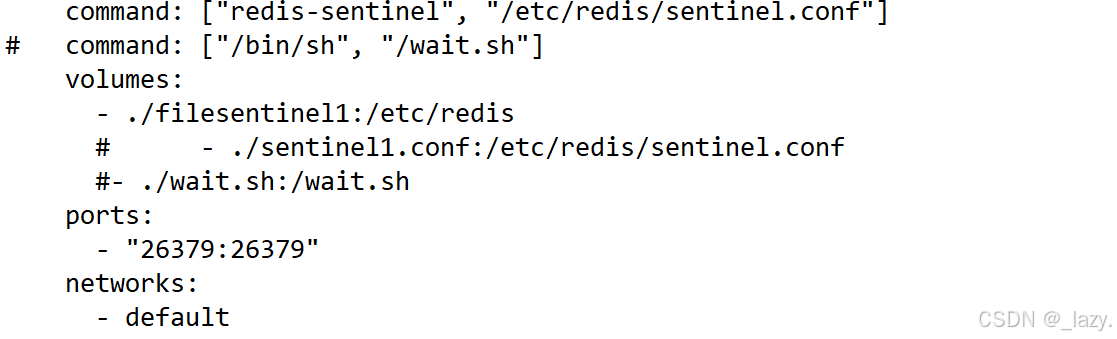
對于command部分,就是容器啟動的時候,要去/etc/redis/的這個目錄里面找sentinel.conf文件,而我們在volumes部分,將/etc/redis目錄映射為了宿主機的./filesentinel1,即我們讓它在這個目錄里面找sentinel.conf文件。
那么我們的理念就是,不管怎么樣,只要能讓它在宿主機里面找到sentinel.conf文件就行,那么我們也可以把sentinel.conf改為sentinel1.conf或者sentinel2.conf,只要能讓它在我們映射的部分找到就可以了。
所以我們也可以把三份配置文件放在一個目錄下,然后對command來說,路徑最后的配置文件更改為對應的配置文件名就可以了,只要能找到就可以了。?
此時我們的配置就全部完成了!
然后我們嘗試啟動一下,啟動之后我們使用docker-compose?logs查看:
這個的原因是因為哨兵節點不認識redis節點,原因是因為網絡:
首先我們要清楚,docker-compose一下啟動了N個容器,那么N個容器就處在一個局域網里面,而我們再啟動其他的容器,就是另一個局域網了,默認這兩個局域網是不互通的。
但是這里,我們有的時候會面臨一個非常痛苦的問題,即我們明明配置成功了,但是不管如何sentinel和redis節點都沒有共享一個網絡,筆者在這里碰到的原因是因為:sentinel啟動的時候DNS沒有準備好,導致DNS解析失敗。
面對這個問題我們又兩種方法,一種是直接使用ip,讓sentinel不進行DNS解析的工作的,一種是使用腳本,當sentinel啟動的時候檢測DNS是否啟動,如果啟動了再進行DNS的解析工作。
腳本如下:
#!/bin/sh
echo "waiting...."
until ping -c1 redis-master >/dev/null 2>&1; dosleep 1
done
echo 'starting...'
exec redis-server /etc/redis/sentinel.conf --sentinel

如果我們不想使用DNS解析,我們可以使用上圖的方式,直接使用對應的ip地址即可。我們可以使用這個命令查看與redis-master相關的網絡信息,這里我們就可以看到不同節點的ip地址了。

那么現在,我們就能通過docker-compose logs查看到哨兵節點確實是正在監測對應的節點。
我們也確實看到了對應的文件發生了修改。
不過當我們啟動節點時候,推薦的是先啟動主從節點,然后再啟動哨兵節點,如果先
模擬哨兵
現在我們就簡單模擬一下主節點掛了的場景。
目前全部正常運行,然后我們掛了主節點。
通過命令docker stop redis-master即可:
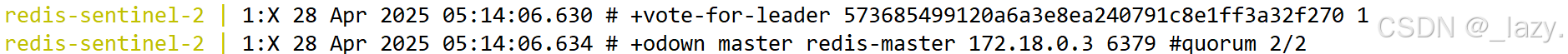

?
那么我們現在看到了具體的一個投票過程,其中我們也看到了s_down和o_down,其中s_down代表的是主觀下線,也就是哨兵節點主觀認為這個節點掛了,那么當其他哨兵認為這個節點下線的時候,就會觸發o_down,即多個哨兵同時認為是它下線了,并且我們也看到了vote-for-leader,代表開始投票了,選取一個leader,并且一般誰先發現的,就先給自己投票,然后其他的也給它投票,這樣就快速的選取了leader用來推進主節點的再次選擇。
為什么分為s_down和o_down?
因為哨兵如果因為網絡抖動等問題收不到PONG是比較常見的事,所以我們就需要讓多個哨兵同時確定。
對于投票過程來說,先是選出了對應的leader,然后是通過三個方面選取對應的主節點,分別是優先級,offset,runid。
其中對于優先級來說是影響最大的,在啟動節點的時候會有相關的字段描述它的優先級,在它對應的配置文件里。但是默認的優先級都是一樣的,如果我們不修改的話,優先級是一樣的,即難以分出勝負,所以我們需要用到offset,我們可以根據從節點和主節點的offset對比,看誰的進度更加貼合于主節點,誰更貼合誰就當主節點,如果offset都一樣了。就要用到runid了,這個runid我們在主從復制的部分提到過,我們當時說的就是在哨兵里面會用到,它其實是一個隨機數,大小全看天命,到時候就通過runid來選取即可,單純是比大小。
我們現在簡單展開一下哨兵節點是奇數個的原因,你也看到了,有投票,如果投票是大于了哨兵個數的一半,那么它就是leader,那么,如果哨兵個數是偶數的話,出現了對半開的情況豈不是很尷尬?所以我們非常建議哨兵的個數是奇數個。
并且我們發現,redis-master重啟之后,它變成了slave節點。
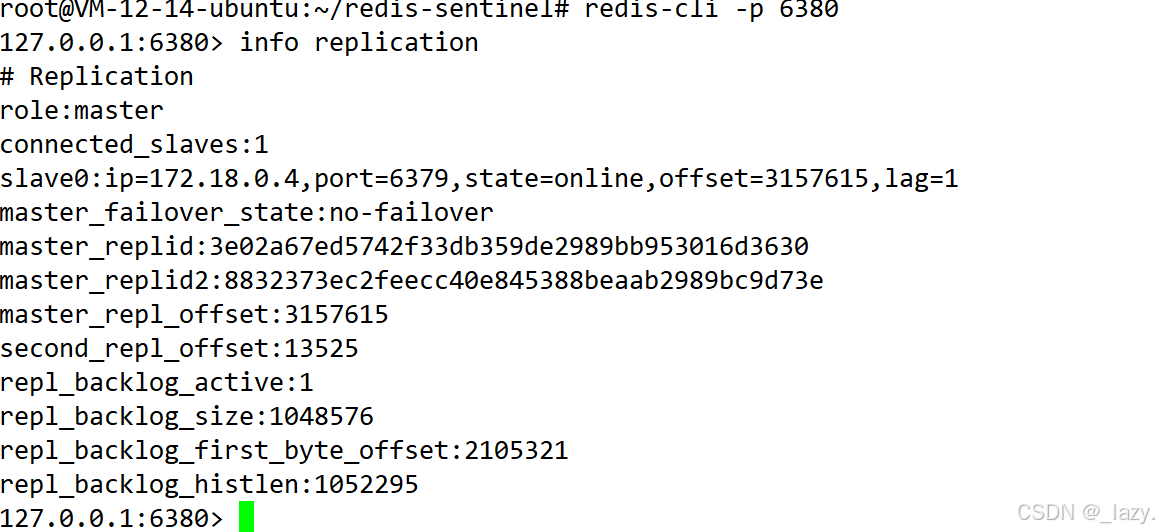
且6380變成了主節點。?
以上就是哨兵機制的全部內容~
感謝閱讀!


)

:走出數據誤區,擁抱創業愿景)












的表)

