目錄
1.字符串:SDS
1.1.為什么叫做動態字符串
2.IntSet
2.1.inset如何保存大于當前編碼的最大數字?
3.Dict
3.1Dict的擴容
3.2Dict的收縮
3.3.rehash
1.字符串:SDS
SDS的底層是C語言編寫的構建的一種簡單動態字符串?簡稱SDS,是redis比較常見的數據結構。
由于以下幾種缺點,Redis并沒有直接采用C語言的字符串。
1.獲取長度需要計算
2.非二進制安全 :中間不能有 \0,否則就中斷。
3.不可修改 :char * s = "hello"??

在這里Redis會在底層的創建兩個SDS,一個是 “key” 的SDS ,一個是value。
由于不能直接采用C語言字符串,所以采用了一個結構體。

注意:len的比特位數每一位就是單位是字節
舉例:對于name字符串來說,redis底層的SDS結構體中,長度是4字節,向內存申請的字節數是4字節,flags則表示不同的編碼格式。
編碼格式有什么作用?
核心目的是優化內存使用 和 操作效率?對于不同長度的字符串可以使用不同的頭結構。

1.1.為什么叫做動態字符串
因為它具備動態擴容能力,好比一個 “hy”字符串的SDS
| len:2 | alloc:2 | flags:1 | h | y | \0 |
如果要給它追加字符”Boy“,那么它首先會申請新的內存空間
如果新的字符串空間 <?1M,那么新空間是擴展后的2倍+1
如果新的字符串空間 > 1M,那么新空間是擴展后字符串長度 + 1M + 1
這個就是內存預分配。
| len:5 | alloc:11 | flags:1 | h | y | B | o | y | \0 |
優點:
1.獲取字符串的長度時間復雜度為O(1)
2.支持動態擴容
3.二進制安全(中間可以有\0存在)
4.減少內存分配次數
2.IntSet
IntSet是Redis中集合的一種實現方式,基于整數數組來實現,并且具備長度可變,有序的特征。

encoding包含三種工作模式,表示儲存的整數大小不同:
分別可儲存2字節整數,4字節整數,8字節整數。
如果IntSet中儲存三個數那么它的儲存結構應該是這樣的:采用默認的encoding,每個數字2字節
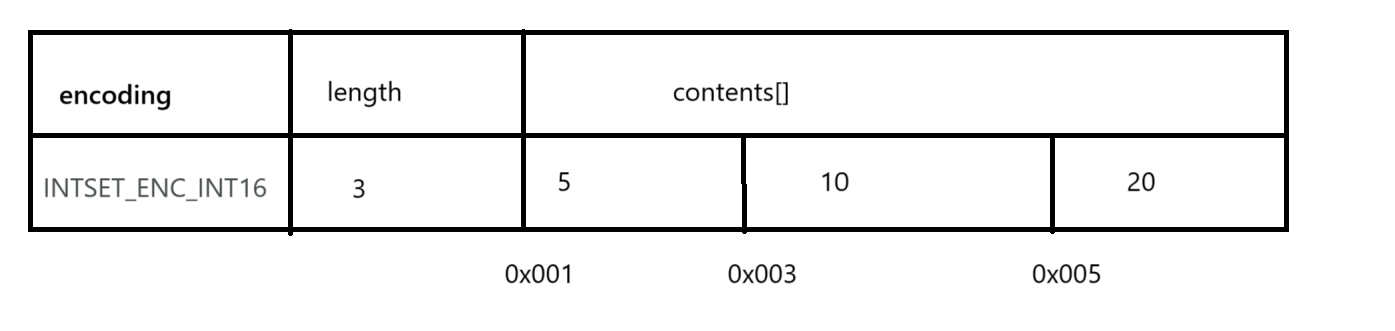
length大小是元素的個數,contents數組保存元素。
2.1.inset如何保存大于當前編碼的最大數字?
當encoding采用int16_t 也就是2個字節大小來存放每個數字,所以每個數字不應該超過兩個字節,最大是32767。當存下99999時會升級編碼的方式去找到合適大小.
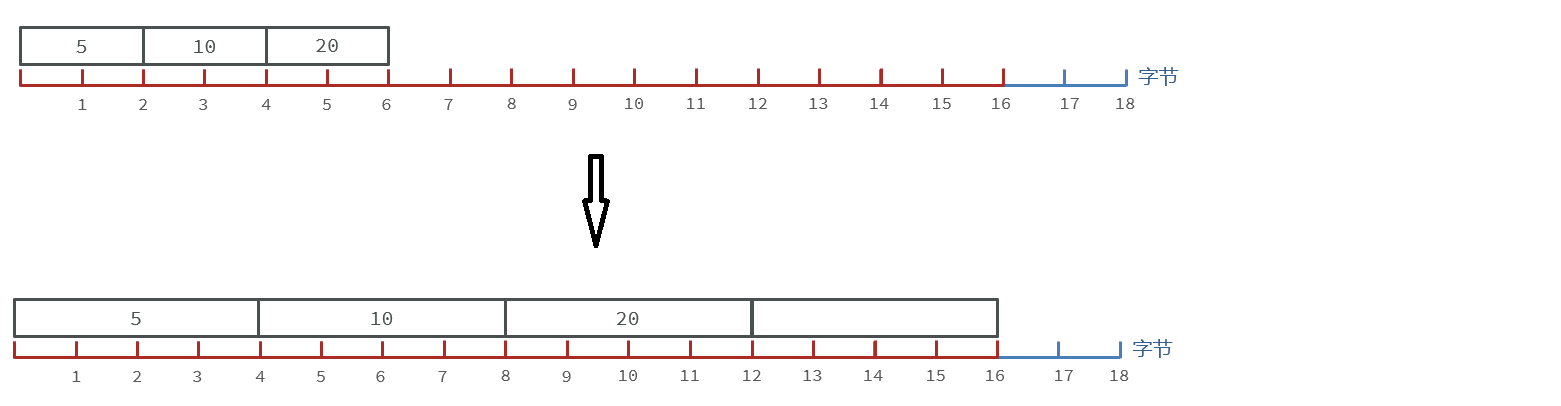
如圖是升級編碼前后的contents數組占用空間大小的情況
1.升級編碼到INT_32,每個數字占4字節
2.依次將每個元素向后拷貝到正確的位置
3.將要添加的元素放入末尾
4.最后將encoding的屬性改為INT_32,length的值更新。
源碼:
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {uint8_t valenc = _intsetValueEncoding(value);// 獲取當前值編碼uint32_t pos; // 要插入的位置if (success) *success = 1;// 判斷編碼是不是超過了當前intset的編碼if (valenc > intrev32ifbe(is->encoding)) {// 超出編碼,需要升級return intsetUpgradeAndAdd(is,value);} else {// 在當前intset中查找值與value一樣的元素的角標posif (intsetSearch(is,value,&pos)) {if (success) *success = 0; //如果找到了,則無需插入,直接結束并返回失敗return is;}// 數組擴容is = intsetResize(is,intrev32ifbe(is->length)+1);// 移動數組中pos之后的元素到pos+1,給新元素騰出空間if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);}// 插入新元素_intsetSet(is,pos,value);// 重置元素長度is->length = intrev32ifbe(intrev32ifbe(is->length)+1);return is;
}
static intset* intsetUpgradeAndAdd(intset* is, int64_t value) {// 獲取當前intset編碼uint8_t curenc = intrev32ifbe(is->encoding);// 獲取新編碼uint8_t newenc = _intsetValueEncoding(value);// 獲取元素個數int length = intrev32ifbe(is->length);// 判斷新元素是大于0還是小于0 ,小于0插入隊首、大于0插入隊尾int prepend = value < 0 ? 1 : 0;// 重置編碼為新編碼is->encoding = intrev32ifbe(newenc);// 重置數組大小is = intsetResize(is, intrev32ifbe(is->length) + 1);// 倒序遍歷,逐個搬運元素到新的位置,_intsetGetEncoded按照舊編碼方式查找舊元素while (length--) // _intsetSet按照新編碼方式插入新元素_intsetSet(is, length + prepend, _intsetGetEncoded(is, length, curenc));/* 插入新元素,prepend決定是隊首還是隊尾*/if (prepend)_intsetSet(is, 0, value);else_intsetSet(is, intrev32ifbe(is->length), value);// 修改數組長度is->length = intrev32ifbe(intrev32ifbe(is->length) + 1);return is;
}總結:
1.InSet確保元素唯一,有序
2.具備類型升級,可以節省空間
3.底層采用二分查找來查詢元素
4.如果數組過長,擴容時移動元素效率不高
3.Dict
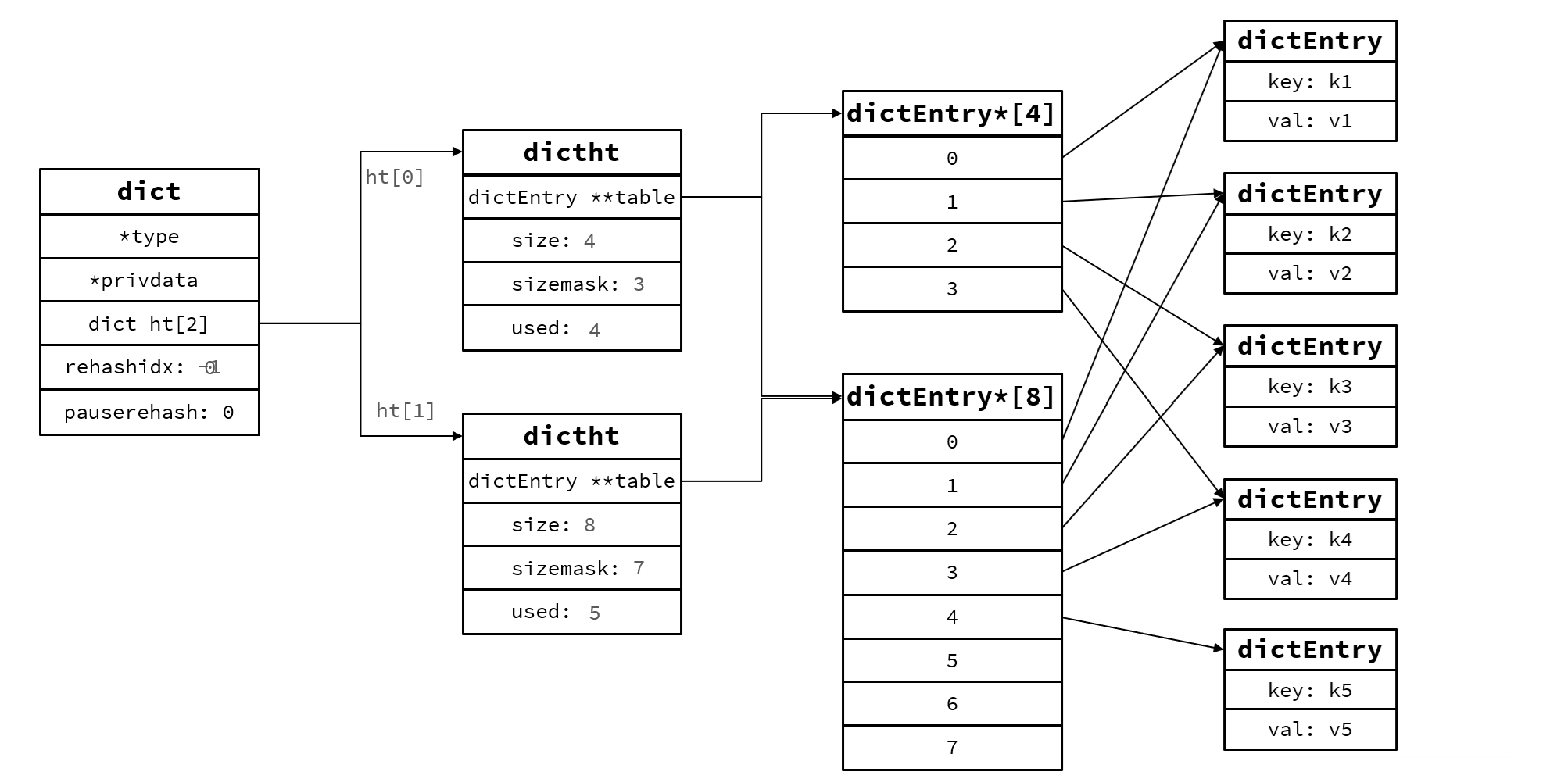
Redis是一種鍵-值型的數據庫,那么鍵和值間關系的維護就要靠Dict維護。
Dict是由三部分組成,分別是哈希表(DictHashTable) ,哈希節點(DictEntry),字典(Dict)


當向Dict添加鍵值對時,Redis首先根據key計算哈希值(h),然后利用 h & sizemask(圖上掩碼)計算出元素應放索引的位置,假設哈希值 h = 1, 則 1 & 3 = 1, 因此儲存到角標1位
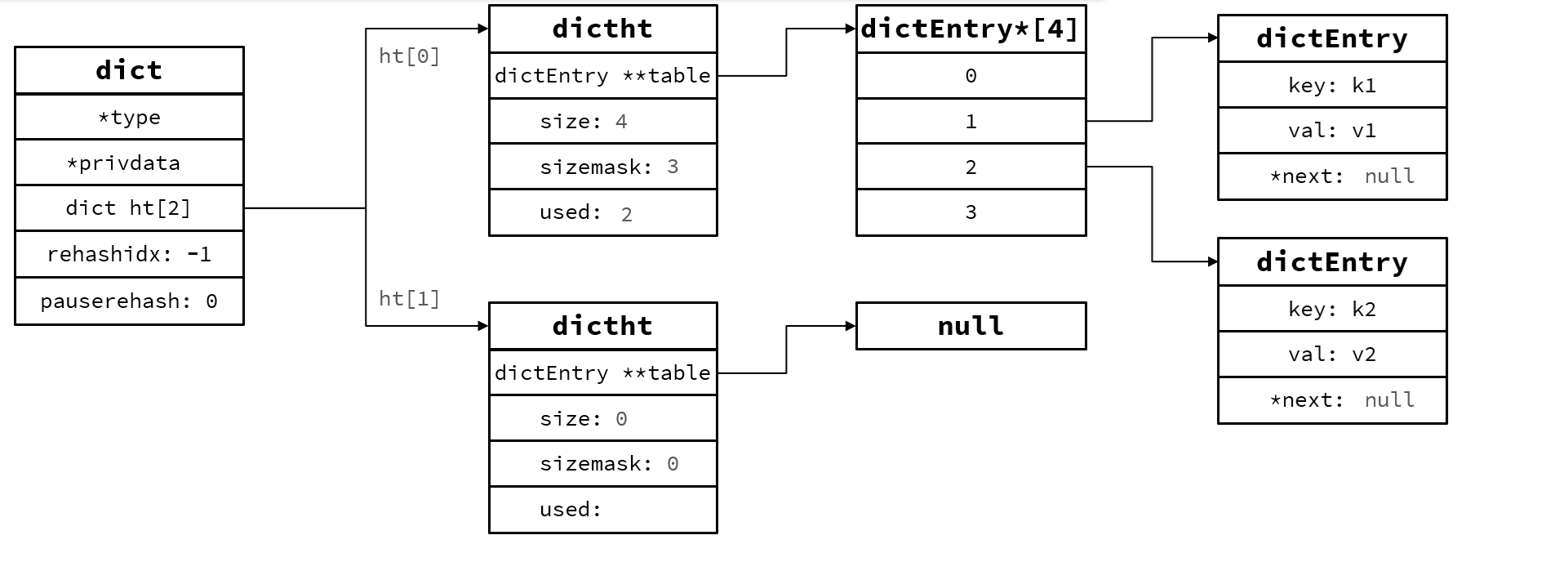
一個Dict包含兩個hash表,其中一個一般是空,rehash才使用,比如負載因子超過閾值,擴展,收縮,初始化時使用。
3.1Dict的擴容
DIct中的HashTable就是數組結合單項鏈表實現,當集合中的元素過多必然導致hash沖突,同時鏈表過長hash的查詢效率也會越來越低。
每次新增鍵值都會查詢負載因子(LoadFactor = used / size)
1.如果LoadFactor >= 1 同時服務器沒有執行BGSAVE/BGREWRITEAOF等后臺進程。
2.哈希表的LoadFactor > 5,此時就算后臺執行進程也會強制擴容。
擴容的大小為used + 1,以下是擴容操源碼
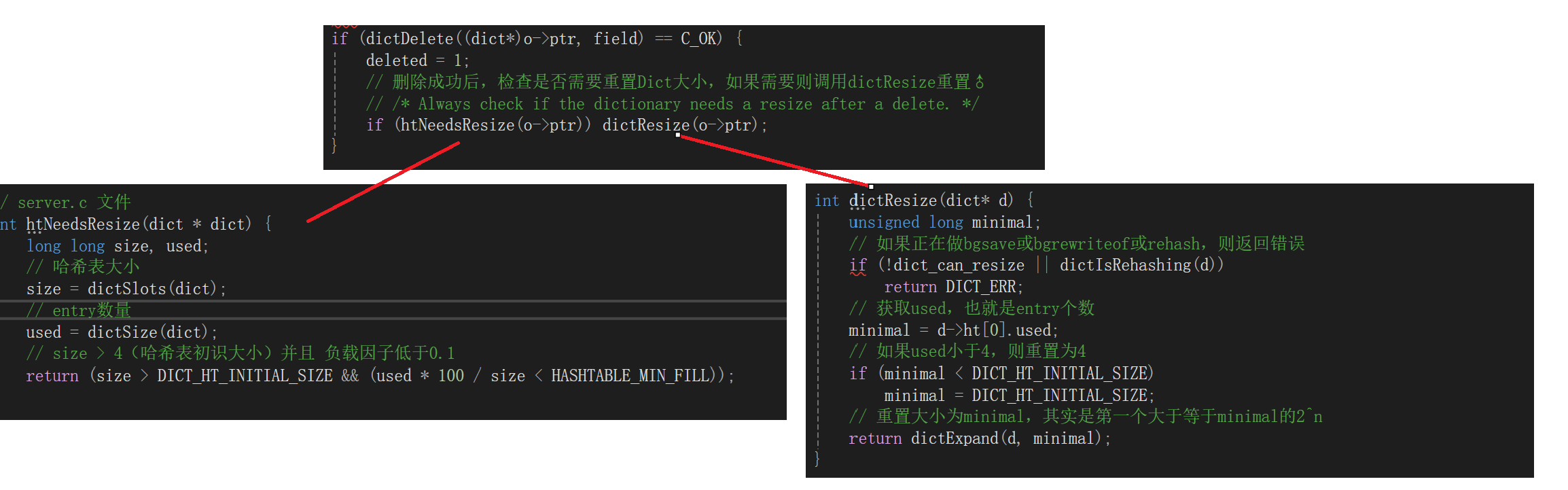
static int _dictExpandIfNeeded(dict *d){// 如果正在rehash,則返回okif (dictIsRehashing(d)) return DICT_OK;? ? // 如果哈希表為空,則初始化哈希表為默認大小:4if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);// 當負載因子(used/size)達到1以上,并且當前沒有進行bgrewrite等子進程操作// 或者負載因子超過5,則進行 dictExpand ,也就是擴容if (d->ht[0].used >= d->ht[0].size &&(dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio){// 擴容大小為used + 1,底層會對擴容大小做判斷,實際上找的是第一個大于等于 used+1 的 2^nreturn dictExpand(d, d->ht[0].used + 1);}return DICT_OK;
}
首先判斷是否正在rehash 是就返回ok,否則向下執行。如果哈希表是空的就會初始化4個單位,
如果負載因子 >=?1 ,并且沒有進行后臺進程 或者 負載因子>= 5. 開始進行擴容。
3.2Dict的收縮
DIct除擴容之外還可以 收縮,每次執行刪除后如果 負載因子 < 0.1 就會執行。
3.3.rehash
不管是擴容還是收縮,每次變化都會導致size 和 sizemask(掩碼)變化,而key的查詢與sizemask有關。所以必須對哈希表中每一個key重新計算索引,插入新的哈希表,這個過程就是rehash。
1.重新計算hash表的realeSize,值取決于當前要做的是擴容還是收縮
擴容:則新的size是第一個 >= dict.ht[0].used + 1 的 2^n
刪除:則新的size是第一個 >= dict.ht[0].used 的 2^n (不小于 4)
2.按照新的realeSize申請內存空間,創建dictht,并賦值給dict.ht[1]
3.設置dict.rehashidx = 0,標識開始rehash
4.將dict.ht[0]的每個dictEntry都rehash到dict.h1
5.將dict.ht[1]的值賦給dict.ht[0] ,給dict.ht[1]初始化為 空哈希表,釋放原來的dict.ht[0]的內存。
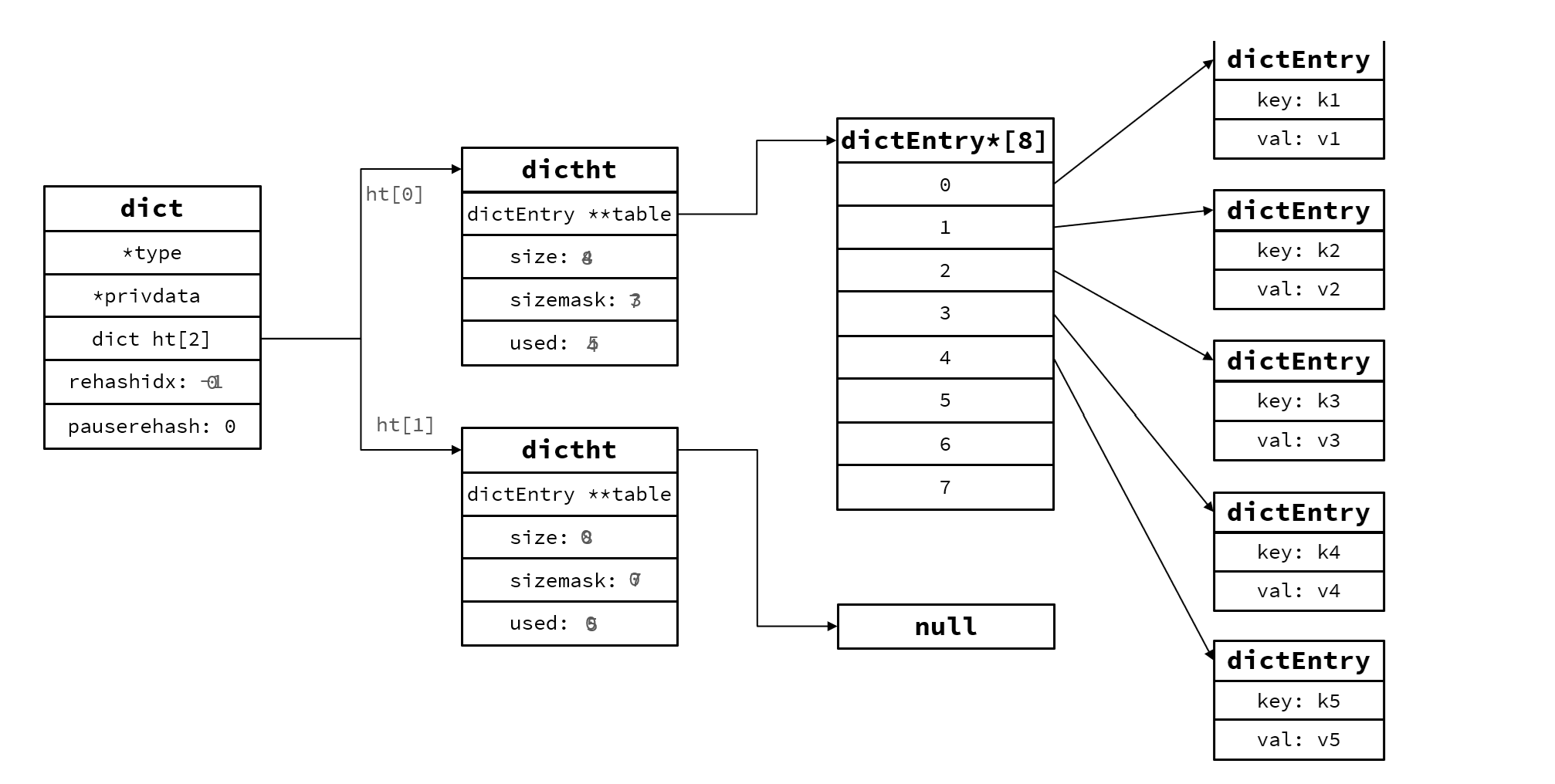
rehash不是一次能夠完成的,如果數據百萬entry則需要分批次完成,否則可能導致線程阻塞
所以叫漸進式rehash
1.重新計算hash表的realeSize,值取決于當前要做的是擴容還是收縮
擴容:則新的size是第一個 >= dict.ht[0].used + 1 的 2^n
刪除:則新的size是第一個 >= dict.ht[0].used 的 2^n (不小于 4)
2.按照新的realeSize申請內存空間,創建dictht,并賦值給dict.ht[1]
3.設置dict.rehashidx = 0,標識開始rehash
4.將dict.ht[0]的每個dictEntry都rehash到dict.h1
5.每次增刪查改都檢查dict.rehashidx是否 > -1,如果是則將dict.ht[0].table[rehashidx]的entry鏈表rehash到dict.ht[1],并且將rehashidx++,直到所有數據都rehsh到dict.ht[1]
6.將dict.ht[1]的值賦給dict.ht[0] ,給dict.ht[1]初始化為 空哈希表,釋放原來的dict.ht[0]的內存。
7.rehashidx賦值-1,代表rehash結束
8.在rehash過程中,新增操作,則直接寫入ht[1],查詢、修改和刪除則會在dict.ht[0]和dict.ht[1]依次查找并執行。這樣可以確保ht[0]的數據只減不增,隨著rehash最終為空













:剖析用戶價值與商業模式拼圖)




![[計算機科學#2]:從繼電器到晶體管的電子計算機發展史(龐然大物的進化)](http://pic.xiahunao.cn/[計算機科學#2]:從繼電器到晶體管的電子計算機發展史(龐然大物的進化))
