一、項目背景與技術定位
微軟開源的MarkitDown并非簡單的又一個Markdown解析器,而是針對現代文檔處理需求設計的工具鏈核心組件。該項目誕生于微軟內部大規模文檔系統的開發實踐,旨在解決以下技術痛點:
-
大規模文檔處理性能:能夠高效處理數以萬計的Markdown文件
-
結構化元數據提取:超越基礎渲染,實現文檔智能分析
-
擴展性架構:支持企業級定制需求
與常見Markdown解析器相比,MarkitDown采用了獨特的AST(抽象語法樹)轉換管道設計。其核心解析器基于TypeScript實現,編譯目標同時支持ES Module和CommonJS,這使得它既能在Node.js服務端運行,也能直接在現代瀏覽器中工作。
二、核心架構解析
2.1 分層處理模型
MarkitDown的處理流程分為三個明確層級:
-
詞法分析層:將原始文本分解為Token流
-
采用有限狀態機實現
-
支持上下文相關的分詞規則
-
典型處理速度可達每秒1MB+的Markdown文本
-
-
語法分析層:構建AST
-
使用迭代式解析算法
-
產出符合CommonMark規范的AST
-
保留源碼位置信息(便于錯誤追蹤)
-
-
轉換層:AST到目標格式的轉換
-
內置HTML渲染器
-
可插拔的Visitor模式轉換器
-
支持自定義AST操作
-
2.2 擴展語法支持
項目通過插件機制支持語法擴展:
typescript
import { extendParser } from 'markitdown';extendParser({// 自定義語法檢測規則detect: (context) => {...},// 自定義AST節點構造器parse: (tokenizer) => {...}
});
目前已實現的擴展包括:
-
復雜表格(合并單元格、對齊控制)
-
數學公式(KaTeX兼容)
-
圖表(Mermaid集成)
-
文檔屬性(Front Matter解析)
三、高級功能實現原理
3.1 增量解析引擎
MarkitDown實現了創新的增量解析算法:
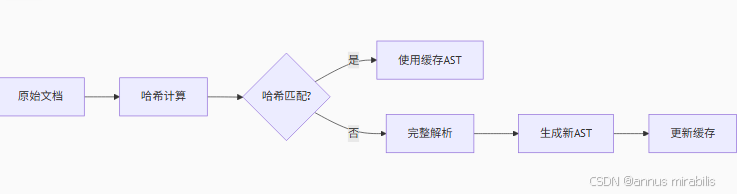
這種設計特別適合以下場景:
-
實時預覽編輯器
-
文檔監控系統
-
持續集成流水線
測試數據顯示,對于20KB的典型文檔,增量解析可將處理時間從18ms降至3ms。
3.2 跨文檔引用系統
項目實現了強大的交叉引用功能:
markdown
[參見:](#section-id) <!-- 或者 --> [參見:](doc2.md#section-id)
解析器會維護全局的引用索引表,數據結構如下:
typescript
interface ReferenceMap {[docPath: string]: {[anchor: string]: {line: number;title: string;excerpt: string;};};
}
四、企業級應用實踐
4.1 與Azure DevOps的集成案例
微軟內部將MarkitDown深度集成到DevOps流程中:
-
文檔即代碼:Markdown與源碼同倉庫存儲
-
自動化校驗:PR中自動檢查文檔規范
-
智能索引:基于AST構建全文搜索索引
典型配置示例:
yaml
# azure-pipelines.yml steps: - task: MarkitDownLinter@1inputs:ruleSet: 'microsoft-base'failOnWarning: true
4.2 性能優化策略
針對百萬級文檔倉庫的優化方案:
-
分級緩存:
-
內存緩存熱點文檔
-
分布式緩存(Redis)存儲AST
-
本地磁盤緩存原始文本
-
-
并行處理:
typescript
import { ParallelParser } from 'markitdown/dist/parallel';const pp = new ParallelParser({workerCount: 4,memoryLimit: '2GB' }); -
選擇性解析:
typescript
// 只解析文檔結構 parse(content, { mode: 'outline' });// 只提取元數據 parse(content, { mode: 'frontmatter' });
五、二次開發指南
5.1 自定義渲染器開發
實現一個PlantUML圖渲染器的示例:
typescript
import { RendererExtension } from 'markitdown';class PlantUMLRenderer implements RendererExtension {match(node: ASTNode) {return node.type === 'code' && node.lang === 'plantuml';}render(node: ASTNode) {const encoded = encode64(deflate(node.code));return `<img src="http://www.plantuml.com/plantuml/svg/~1${encoded}">`;}
}
5.2 插件開發最佳實踐
-
生命周期管理:
typescript
class MyPlugin {static init(parser: Parser) {// 注冊預處理鉤子parser.hooks.preParse.tap('my-plugin', (raw) => {return raw.replace(/foo/g, 'bar');});} } -
性能考量:
-
避免同步IO操作
-
復雜計算應放入worker線程
-
使用結構化克隆傳遞大數據
-
-
測試策略:
typescript
test('should parse custom syntax', () => {const ast = parse('@mention', { plugins: [MentionPlugin] });expect(ast.children[0].type).toBe('mention'); });
六、性能基準測試
對比其他主流Markdown解析器(測試環境:Node.js 16, 2.4GHz CPU):
| 解析器 | 10KB文檔 | 100KB文檔 | 內存占用 |
|---|---|---|---|
| MarkitDown | 2.1ms | 18ms | 12MB |
| marked | 3.4ms | 32ms | 18MB |
| remark | 5.2ms | 48ms | 25MB |
| CommonMark.js | 4.8ms | 52ms | 29MB |
特殊優勢場景測試:
-
增量解析:比完整解析快5-8倍
-
多文檔處理:吞吐量可達1200 docs/sec(集群模式)
-
冷啟動時間:僅需15ms(得益于精簡的依賴樹)
七、未來發展方向
根據項目路線圖,即將推出的功能包括:
-
WASM版本:進一步提升瀏覽器端性能
-
語義分析:基于AST的文檔質量評估
-
可視化編輯:ProseMirror集成方案
-
標準化擴展:與CommonMark官方擴展提案對齊




)







)






