推理模型在數學和邏輯推理等任務中表現出色,但常出現過度推理的情況。本文研究發現,推理模型的隱藏狀態編碼了答案正確性信息,利用這一信息可提升推理效率。想知道具體如何實現嗎?快來一起來了解吧!
論文標題
Reasoning Models Know When They’re Right: Probing Hidden States for Self-Verification
來源
arXiv:2504.05419v1 [cs.AI] 7 Apr 2025
https://arxiv.org/abs/2504.05419
文章核心
研究背景
近年來,推理模型在復雜推理能力上取得顯著進展,如OpenAI的o1和DeepSeekR1等在數學和邏輯推理任務中表現出色,其基于搜索的推理方式是重要優勢。
研究問題
- 推理模型存在過度思考的問題,在得到正確答案后仍會進行不必要的推理步驟。
- 不清楚模型在推理過程中對中間答案正確性的評估能力如何。
- 模型雖能編碼答案正確性信息,但在推理時未能有效利用該信息。
主要貢獻
- 驗證信息編碼:證實推理模型的隱藏狀態編碼了答案正確性信息,通過簡單的探測就能可靠地提取,且探測結果校準度高,在分布內和分布外示例上都有良好表現。
- 提前預測正確性:發現模型隱藏狀態包含“前瞻性”信息,能在中間答案完全生成前預測其正確性。
- 提升推理效率:將訓練好的探測模型用作驗證器,實施基于置信度的提前退出策略,在不降低性能的情況下,可減少24%的推理令牌數量,揭示了模型在利用內部正確性信息方面的潛力。
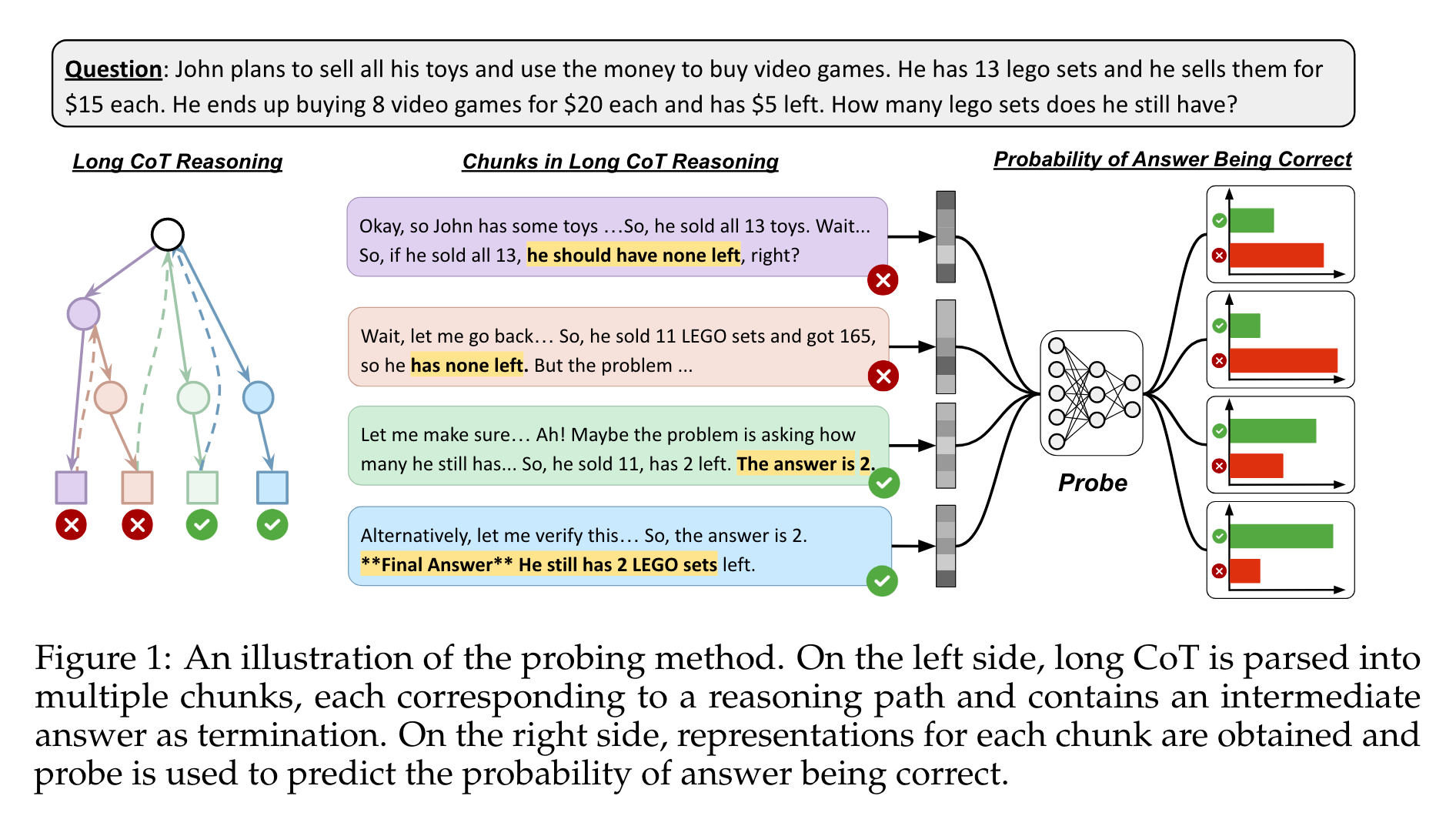
方法論精要
- 核心算法/框架:使用兩層多層感知器(MLP)作為探測模型,在推理模型生成的長思維鏈(Chain-of-Thought,CoT)基礎上,將其分割為包含中間答案的多個塊,利用該探測模型從這些塊對應的隱藏狀態中提取信息,進而預測中間答案的正確性。
- 關鍵參數設計原理:由于數據集存在類別不平衡問題,多數中間答案正確,因此使用加權二元交叉熵損失函數。其中, w w w是訓練數據中負樣本與正樣本的比例, α \alpha α是縮放不平衡權重的超參數,通過調整這些參數來優化探測模型的訓練。
- 創新性技術組合:
- 數據處理創新:設計了一套獨特的數據處理流程。首先,收集推理模型針對任務數據集中每個問題的響應,將推理過程中封裝在標記內的推理痕跡提取出來,并以 “\n\n” 為分隔符拆分成段落。通過檢測段落中的 “wait”“double-check”“alternatively” 等關鍵詞來識別新推理路徑的起始點,然后將同一推理路徑的段落合并成一個塊。接著,借助 Gemini 2.0 Flash 工具,從每個塊中提取中間答案(若存在),并與真實答案對比判斷其正確性。對于相鄰且不包含中間答案的塊,將其與最近的含答案塊合并。最終,每個合并后的塊都包含一個中間答案以及由 Gemini 生成的表示答案正確性的二進制標簽,形成 ( c 1 , y 1 ) , ( c 2 , y 2 ) , . . . ( c k , y k ) {(c_{1}, y_{1}),(c_{2}, y_{2}), ...(c_{k}, y_{k})} (c1?,y1?),(c2?,y2?),...(ck?,yk?) 這樣的數據結構,為后續探測模型的訓練提供了豐富且準確的數據。
- 模型訓練創新:在訓練探測模型時,采用將長 CoT 分段處理后得到的塊數據進行訓練。對于每個塊 c i c_{i} ci? ,選取其最后一個令牌位置的最后一層隱藏狀態作為該塊的表示 e i e_{i} ei?,以此構建探測數據集 D = ( e i , y i ) i = 1 N D={(e_{i}, y_{i})}_{i=1}^{N} D=(ei?,yi?)i=1N?,這種基于塊的隱藏狀態表示方式能夠有效捕捉推理過程中每個中間步驟的特征信息,為準確訓練探測模型奠定了基礎。同時,結合加權二元交叉熵損失函數進行訓練,進一步提升了模型在不平衡數據上的訓練效果。
- 實驗驗證方式:選擇數學推理(GSM8K、MATH、AIME)和邏輯推理(KnowLogic)任務的數據集,使用開源的DeepSeek - R1 - Distill系列模型以及QwQ - 32B模型。通過在不同數據集上訓練和測試探測模型,對比不同模型的性能,并將訓練好的探測模型作為驗證器,與靜態提前退出策略對比,評估推理效率和準確性。
實驗洞察
- 性能優勢:在分布內實驗中,所有探測模型的ROC - AUC得分均高于0.7,預期校準誤差(ECE)低于0.1。例如,R1 - Distill - Qwen - 32B在AIME數據集上的ROC - AUC得分超過0.9。在跨數學推理數據集的實驗中,部分探測模型具有良好的泛化性,如在MATH和GSM8K數據集上訓練的探測模型在兩個數據集之間轉移時,ROC - AUC和ECE表現良好。
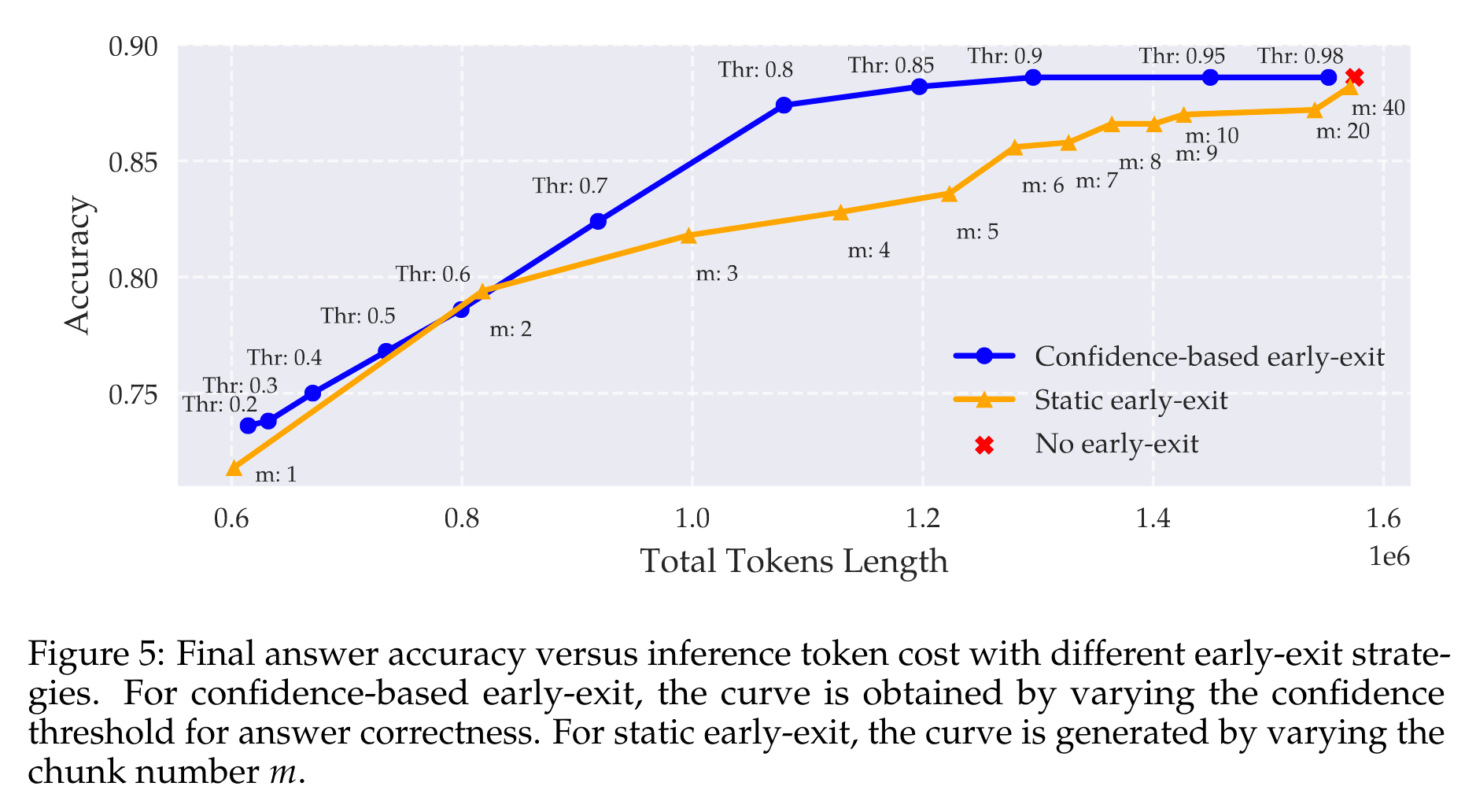
- 效率突破:使用基于探測模型置信度的提前退出策略,在MATH數據集上,當置信度閾值設為0.85時,推理準確率與不提前退出時大致相同(88.2%),但生成的令牌數量減少了約24%;當閾值設為0.9時,推理準確率為88.6%,令牌數量減少19%。且在節省相同數量令牌的情況下,該策略比靜態提前退出策略的準確率高5%。
- 消融研究:訓練非推理模型(Llama - 3.1 - 8B - Instruct)的探測模型并與推理模型對比,發現非推理模型探測模型的性能更差,分類得分更低,校準誤差更高,表明答案正確性的編碼信息在推理模型中更顯著,與長CoT推理能力相關。同時,研究發現推理模型在中間答案生成前,隱藏狀態就編碼了正確性信息,且靠近答案生成位置的段落,探測模型性能更好。
本文由AI輔助完成。
)







)










