FramePack 是一種下一幀(下一幀部分)預測神經網絡結構,可以逐步生成視頻。
FramePack 將輸入上下文壓縮為固定長度,使得生成工作量與視頻長度無關。即使在筆記本電腦的 GPU 上,FramePack 也能處理大量幀,甚至使用 13B 模型。
FramePack 可以使用更大的批量大小進行訓練,類似于圖像擴散訓練的批量大小。
使用 13B 模型生成 1 分鐘視頻(60 秒)以 30fps(1800 幀),所需的最低 GPU 內存為 6GB。
關于速度,在 RTX 4090 臺式機上,它以 2.5 秒/幀(未優化)或 1.5 秒/幀(teacache)的速度生成。在筆記本電腦上,比如 3070ti 筆記本電腦或 3060 筆記本電腦,它大約慢 4 倍到 8 倍。
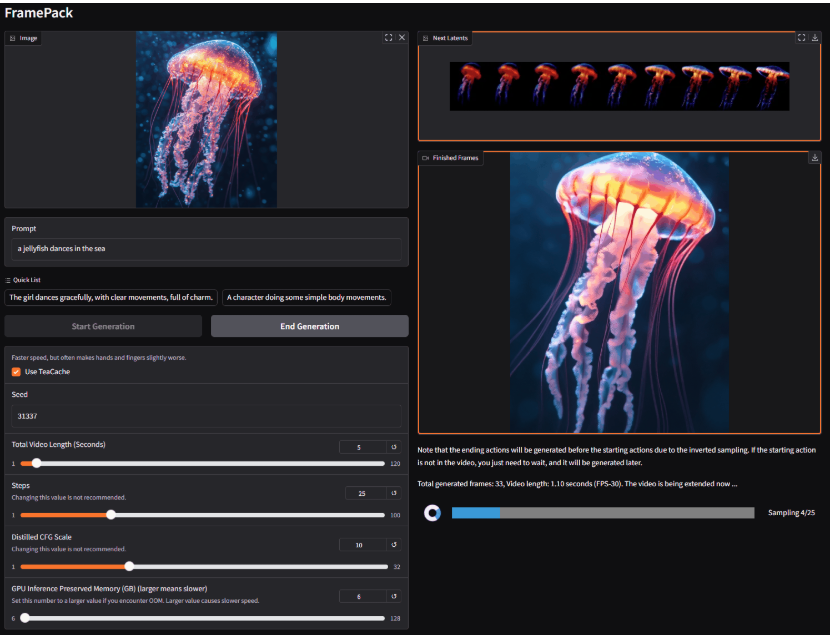
操作UI如下:
快速理解 FramePack:
下一個幀(或下一個幀部分)預測模型看起來是這樣的:
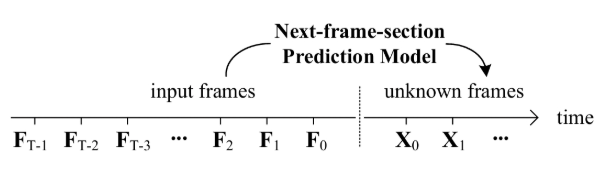
所以我們有很多輸入幀,并希望擴散一些新幀。
我們可以將輸入幀編碼成類似這樣的 GPU 布局:
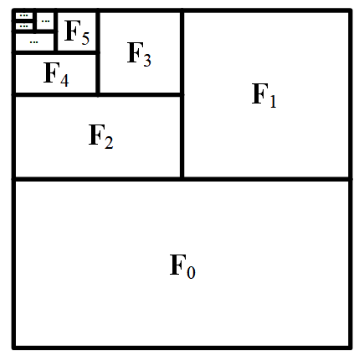
此圖表顯示了邏輯 GPU 內存布局 - 圖像幀并未拼接。
或者,比如說每個輸入幀的上下文長度。
每個幀都使用不同的 patchifying 內核進行編碼以實現這一點。
例如,在 HunyuanVideo 中,如果使用(1, 2, 2)補丁化內核,480p 幀可能是 1536 個 token。
然后,如果改為(2, 4, 4)補丁化內核,幀將是 192 個 token。
這樣,我們可以改變每個幀的上下文長度。
"更重要"的幀會分配更多的 GPU 資源(上下文長度)- 在這個例子中,F0 是最重要的,因為它是最接近"下一幀預測"目標的幀。
這是對流處理的 O(1)計算復雜度 - 是的,這是一個常數,甚至不是 O(nlogn)或 O(n)。
實際上這些是 FramePack 調度,就像這樣:

因此可以獲取不同的壓縮模式。
甚至可以讓起始幀同樣重要,這樣圖像到視頻的轉換會更加愉快
所有這些調度都是 O(1)的。
抗漂移采樣:
漂移是任何下一何-何預測模型的常見問題,漂移指的是隨著視頻變長而出現的質量退化,有時這個問題也被稱作誤差累積或曝光偏差。
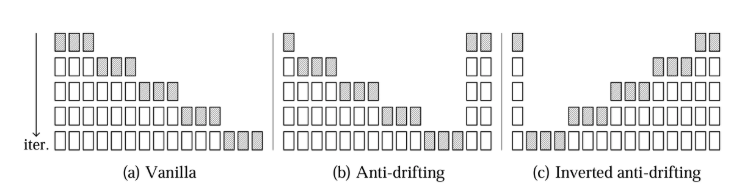
(陰影方框是每次流推理中生成的幀)
注意,只有“vanilla sampling”是因果的;“anti-drifting sampling”和“inverted anti-drifting sampling”都是雙向的。
“倒置反漂移采樣”非常重要。這種方法是唯一一種在所有推理中始終將第一幀作為近似目標的。這種方法非常適合圖像到視頻。
圖像到 5 秒(30fps,150 幀)視頻生成:

圖像轉 60 秒(30fps,1800 幀)視頻生成:

項目地址:https://github.com/lllyasviel/FramePack
模型地址:https://huggingface.co/lllyasviel/FramePackI2V_HY/tree/main




![[論文閱讀]ConfusedPilot: Confused Deputy Risks in RAG-based LLMs](http://pic.xiahunao.cn/[論文閱讀]ConfusedPilot: Confused Deputy Risks in RAG-based LLMs)
)





)







