目錄
前言
1.用戶空間和內核空間
1.2用戶空間和內核空間的切換
1.3切換過程
2.阻塞IO
3.非阻塞IO
4.IO多路復用
4.1.IO多路復用過程
4.2.IO多路復用監聽方式
4.3.IO多路復用-select
4.4.IO多路復用-poll
4.5.IO多路復用-epoll
4.6.select poll epoll總結
4.7.IO多路復用-事件通知機制
4.8.IO多路復用-web服務流程
5.信號驅動IO?
6.異步IO
7.同步和異步
8.Redis——網絡模型
?8.1.Redis到底是單線程還是多線程?
8.2.為什么Redis要選擇單線程?
8.3.Redis單線程網絡模型的整個流程
前言
Redis 以其卓越的性能和靈活的特性,成為眾多開發者在緩存、消息隊列等場景的首選。而 Redis 強大性能的背后,其網絡模型與 IO 機制發揮著關鍵作用。數據的讀寫速度直接影響著用戶體驗。大家日常逛的電商平臺,流暢加載商品詳情頁離不開它;刷社交軟件時,點贊瞬間顯示也有它的功勞 。接下來,我們就深入挖掘一下,看看 Redis 是如何通過它們實現高效運轉的。
1.用戶空間和內核空間
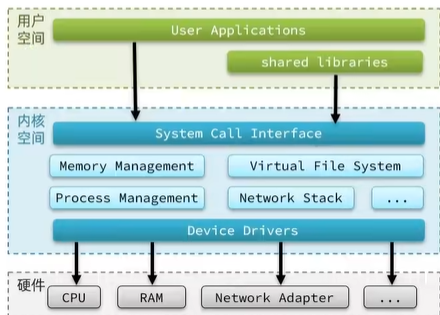
為了避免用戶應用導致沖突甚至內核崩潰,用戶應用與內核是分離的:
進程的尋址空間會劃分兩部分:內核空間,用戶空間
這就代表了一個完整的32位尋址空間
那什么是尋址空間呢?
尋址空間是指計算機系統中處理器能夠訪問的內存地址范圍。
計算機中的內存是由許多存儲單元組成的,每個存儲單元都有一個唯一的編號,這個編號就是地址。處理器通過地址來訪問內存中的數據和指令。尋址空間就是這些地址的集合,它決定了處理器能夠訪問的內存大小。
我們還要在系統權限上進行劃分,因為我們cpu運行的各種各樣的命令里邊,有一些命令風險等級比較低,有一些比較高。所以cpu會把各種各樣的命令劃分成四個不同的等級,Ring0風險等級最低,Ring3風險等級最高
- 用戶空間只能執行受限的命令(Ring3),而且不能直接調用系統資源,必須通過內核提供的接口來訪問
- 內核空間可以執行特權命令(Ring0),調用一切系統資源

1.2用戶空間和內核空間的切換
應用程序在用戶空間,內核應用在內核空間,但是我們一個進程它在執行過程中因為業務比較多,可能會執行一些普通命令和特權命令調用系統資源。因此進程會在用戶空間和內核空間之間進行一個轉換
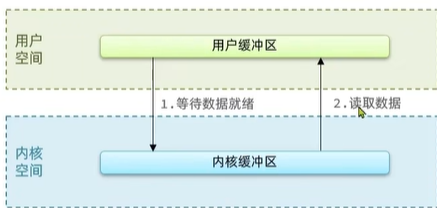
linux系統為了提高io效率,會在用戶空間和內核空間都加入緩沖區:
- 寫數據時,要把用戶緩沖數據拷貝到內核緩沖區,然后寫入設備
- 讀數據時,要從設備讀取數據到內核緩沖區,然后拷貝到用戶緩沖區
1.3切換過程
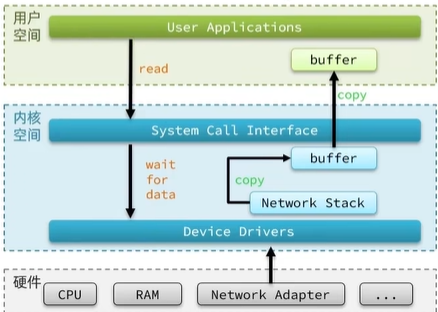
IO在用戶空間和內核空間切換流程
寫數據到磁盤過程
- 1.進程在做一些簡單運算,字符串處理,之后要把數據寫出到我們的磁盤需要調用我們的內核
- 2.寫數據先寫到緩沖區,要往磁盤寫必須要切換到內核
- 3.切換到內核,內核沒有我要寫的數據,所以要先把用戶緩沖區的數據拷貝到內核的緩沖區,然后再把緩沖區的數據寫入我們的磁盤
讀數據到用戶空間
- 1.開始用戶空間發起read的請求,請求到達內核空間判斷有沒有數據,如果要讀的是磁盤,要先去尋址wati,for data,尋址到之后把數據讀取到緩沖區
- 2.把數據從內核緩沖區拷貝到用戶空間用戶再區處理這些數據
從上圖可知IO讀寫效率的主要原因是
- 1.數據等待過程,(用戶空間讀數據發起read請求,內核空間接收到這個請求需要去尋址和把數據寫到緩沖區)
- 2.就是數據拷貝過程非常影響性能,一個空間緩沖區數據拷貝到另一個空間緩沖區
數據拷貝是由操作系統內核來完成的。
2.阻塞IO
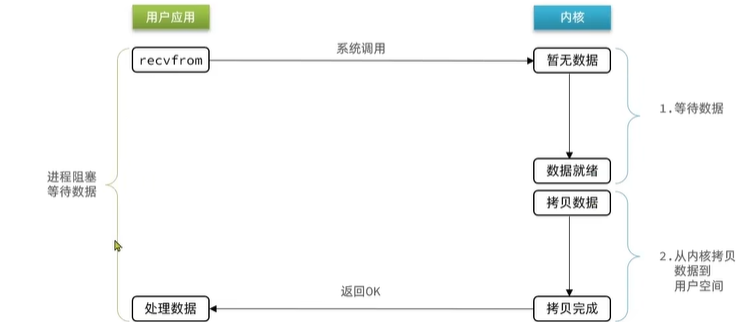
不同IO模型的差別就是在1.等待數據就緒 2.讀取數據過程
阻塞IO就是兩個階段都必須阻塞等待;
所以阻塞IO就是2.把數據寫到內核緩沖區1.把內核緩沖區數據寫到用戶空間緩沖區這兩個階段都是阻塞狀態。
3.非阻塞IO
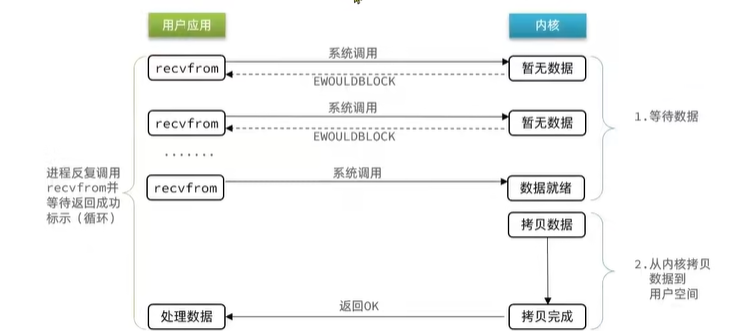
顧名思義,非阻塞IO的recvfrom操作會立即返回結果而不是阻塞用戶進程。
非阻塞IO就是第一階段不停調用recvfrom去讀取數據,讀取不到不會阻塞一直反復調用直到成功(反而讓cpu使用率增加)
然后第二階段內核拷貝數據到用戶空間依然是阻塞狀態
4.IO多路復用
無論是阻塞IO還是非阻塞IO,用戶應用在一階段都需要調用recvfrom來獲取數據,差別在于無數據時的處理方案:
- 如果調用recvfrom時,恰好沒有數據,阻塞IO會使進程阻塞,非阻塞IO使CPU空轉,都不能充分發揮CPU的作用。
- 如果調用recvfrom時,恰好有數據,則用戶進程可以直接進入第二階段,讀取并處理數據
比如服務端處理客戶端Socket時,在單線程情況下,只能依次處理每一個socket,如果正在處理的socket恰好未就緒(數據不可讀或不可寫),線程就會被阻塞,所有其它客戶端socket都必須等待,性能自然會很差。
解決方案就是數據就緒了,用戶應用就去讀取數據
用戶進程如何知道內核中數據是否就緒呢?
4.1.IO多路復用過程
文件描述符(File Descriptor):簡稱FD,是一個從0開始遞增的無待號整數,用來關聯Linux中的一個文件。在Linux中,一切皆文件,例如常規文件,視頻,硬件設備等,當然也包括網絡套接字(socket)。
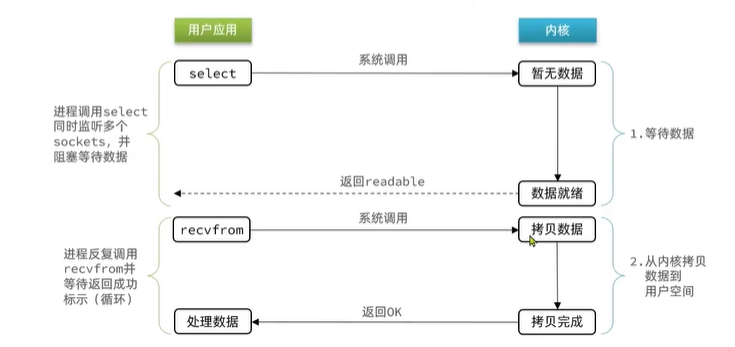
IO多路復用:是利用單個線程來同時監聽多個FD,并在某個FD可讀,可寫時得到通知,從而避免無效的等待,充分利用CPU資源IO多路復用過程:
- 用戶應用首先去調用select函數,不在是調用recvfrom(recvfrom直接是嘗試讀取數據讀的目標是具體某一個FD)
- select函數內部可以接收多個FD,也就是說可以把每個客戶端socket對應的FD,傳給select函數,然后傳入到內核中,內核就可以去檢查你要去監聽的多個FD,有沒有任何一個是就緒的,只要由任意一個或者多個就緒就會直接返回這個結果。
- 如果這n個FD都沒有就緒那么就會稍微等一會,在等待過程中其實就會有后臺進程去監聽這些FD,一旦有任意一個或者多個就緒返回結果。這個等待不可避免的。
- 拿到readable結果了就去調用recvfrom我們可以明確知道哪些FD準備好啦,然后拷貝數據返回結果(循環調用)
其實IO多路復用1.等待數據就緒用戶進程也是阻塞階段,階段二數據拷貝同樣是阻塞的
區別在于:
- 阻塞IO調用的是調用recvfrom去監聽某一個FD有沒有就緒,沒有就會阻塞
- IO多路復用調用的是select函數去監聽多個FD,只要有一個FD就緒就去處理
4.2.IO多路復用監聽方式
IO多路復用監聽FD的方式,通知的方式又有多種實現,常見的有:
select
poll
epoll
差異:
- select和poll只會通知用戶進程有FD就緒,但不確定具體是哪個FD,需要用戶進程逐個遍歷FD來確認
- epoll則會在通知用戶進程FD就緒的同時,把已就緒的FD寫入用戶空間
4.3.IO多路復用-select
select是Linux中最早的IO多路復用實現方案:
select函數:
1.nfds:這是需要監視的最大文件描述符加 1。舉例來說,若要監視的文件描述符為 3、4、5,那么
nfds的值就是5 + 1 = 6。為了能更精細地管理和監控不同類型的 IO 事件,select將FD分成三個集合
2.readfds:該集合用于監視文件描述符的可讀事件。
3.writefds:此集合用于監視文件描述符的可寫事件。
4.exceptfds:這個集合用于監視文件描述符的異常事件。執行流程:
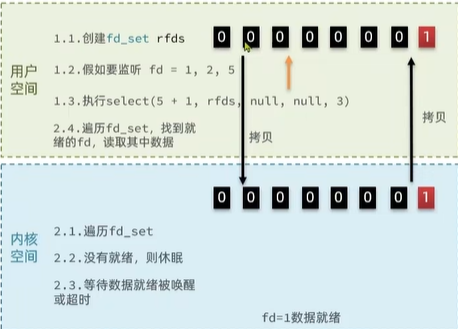
首先用戶空間
- 1.創建fd_set rfds集合
- 2.fd_set集合底層使用fds_bits[]來監聽,共可以監聽1024個Fd,要監聽哪個就把哪個位置變為1。比如要監聽fd = 1,2,5
- 3.執行select函數,把fds_bits[]數組拷貝到內核空間
內核空間
- 1.首先遍歷fd_set看有沒就緒
- 2.沒有就緒則睡眠,后臺監聽
- 3.等待數據就緒被喚醒或超時
- 4.fd = 1數據就緒,其他沒有就緒剔除,返回結果有幾個就緒了,拷貝到用戶空間遍歷哪個就緒了
處理完之后再次把要監聽數據放到集合里執行select去監聽往復處理數據
缺點:
- 1.需要將整個fd_set從用戶空間拷貝到內核空間,select結束還要再次拷貝回用戶空間
- 2.select無法得知具體哪個FD就緒,需要遍歷整個FD_set,
- 3.fd_set監聽的fd數量不能超過1024

4.4.IO多路復用-poll
poll模式對select模式做了簡單改進,但性能提升不明顯,部分關鍵代碼如下:
poll參數部分和select差不多主要區別在于fds,pollfd數組,沒有去劃分不同事件集合全部劃分到一個數組當中。區別是哪種事件主要在于結構體中 events屬性不同值代表不同監聽類型
revents表示實際發生的事件類型,內核會把就緒的事件類型放在這個集合里,超時時間過了還沒有就緒FD,就把這個值給成0返回給用戶空間,這樣一來就知道這個FD有沒有發生事件。
IO流程:
1.創建pollfd數組,向其中添加關注的fd信息,數組大小自定義
2.調用poll函數,將pollfd數組拷貝到內核空間,轉鏈表存儲,無上限
3.內核遍歷fd,判斷是否就緒
4.數據就緒或超時后,拷貝pollfd數組到用戶空間,返回就緒fd數量n
5.用戶進程判斷n是否大于0
6.大于0則遍歷pollfd數組,找到就緒的fd與select相比:
- select模式中的fd_set大小固定為1024,而pollfd在內核中采用鏈表,理論上無上限
- 監聽fd越多,每次遍歷消耗時間也越久,性能反而會下降

4.5.IO多路復用-epoll
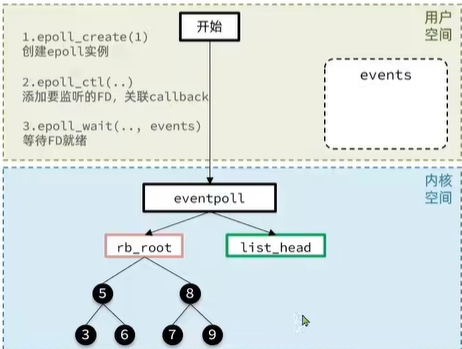
epoll模式是對select和poll的改進,它提供了三個函數:
eventpoll結構體:使用紅黑樹存儲要監聽的FD,和使用鏈表記錄就緒的FD
2.接下來我們就要去監聽FD了,會使用到第二個函數
這個函數epoll_ctl將我們一個FD添加到eventpoll里面,相當于監聽FD
傳入的參數包括(需要添加到哪個eventpoll,是增刪改哪個操作,要監聽的fd,監聽事件類型)
3.第三個函數就是等待FD的監聽就緒。函數傳入參數(eventpoll指針,空數組用于接收就緒的FD,events數組最大長度,超時時間)返回就緒的數量
那么我怎么知道哪個FD就緒了呢?空數組就派上用場了
我們把這個數組拷貝到用戶空間就知道哪些FD就緒了,不用去遍歷



4.6.select poll epoll總結
select模式存在的三大問題:
- 能監聽的FD最大不超過1024
- 每次select都需要把所有要監聽的FD都拷貝到內核空間
- 每次都要遍歷所有FD來判斷就緒狀態
poll模式的問題:
poll模式利用鏈表解決了select中監聽FD上限問題,但依然要遍歷所有FD,如果監聽較多,性能會下降
epoll模式中如何解決這些問題的?
- 基于epoll實例中的紅黑樹保存要監聽的FD,理論上無上限,而且增刪改查效率都非常高,性能不會隨監聽FD數量增多而下降
- 每個FD只需要執行一次epoll_ctl添加到紅黑樹,以后每次epol_wait無需傳遞任何參數,無需重復拷貝到Fd到內核空間
- 內核會將就緒的FD拷貝到用戶空間的知道位置,用戶進程無需遍歷所有FD就知道就緒的FD是誰
4.7.IO多路復用-事件通知機制
但FD有數據可讀時,我們調用epoll_wait就可以得到通知。但是事件通知的模式有兩種:
- LevelTriggered:簡稱lLT.當FD有數據可讀時,會重復通知多次,直至數據處理完成。是epoll的默認模式。
- EdgeTriggered:簡稱LT.當FD有數據可讀時,只會被通知一次,不管數據是否處理完成。
舉個栗子:
- 假設一個客戶端socket對應的fd已經注冊到了epoll實例中
- 客戶端socket發送了2kb的數據
- 服務端調用epoll_wait,得到通知說fd就緒
- 服務端從fd讀取了1kb數據
- 回到步驟3(再次調用epoll_wait,形成循環)
總結:
ET模式避免了LT模式可能出現驚群現象
ET模式最好結合非阻塞IO讀取FD數據,相比LT會復雜一些
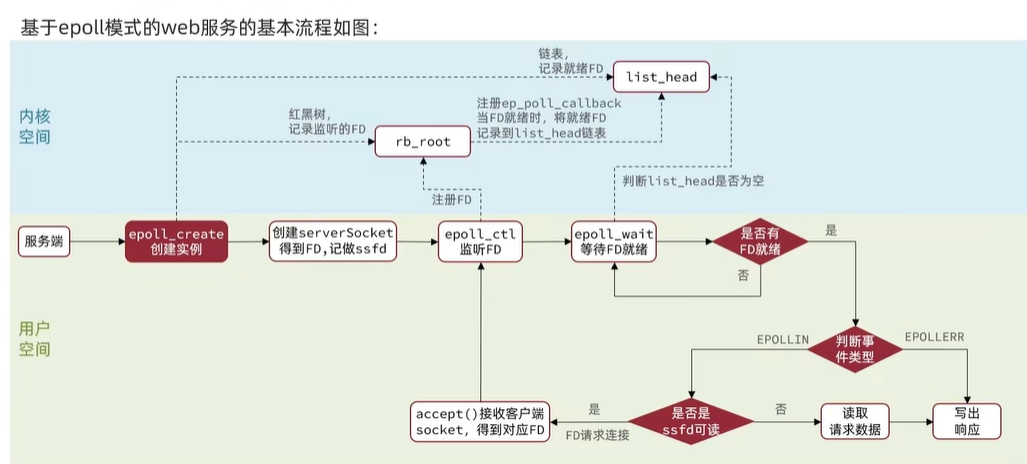
4.8.IO多路復用-web服務流程
serverSocket:接收客戶端請求
5.信號驅動IO?
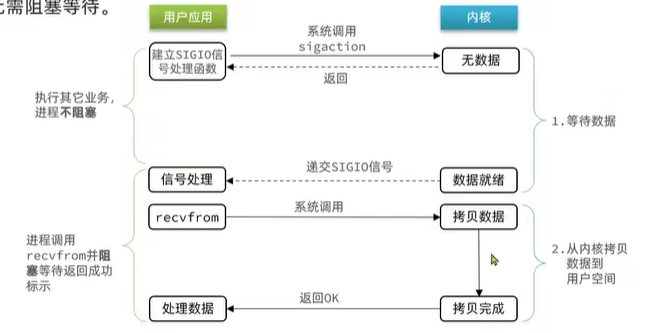
信號驅動IO是內核建立SIGIO的信號管理并設置回調,但內核有FD就緒時,會發出SIGIO信號通知用戶,期間用戶可以執行其它業務,無需阻塞等待。
首先信號驅動IO第一階段處理流程:
- 用戶進程一上來不是調用recvfrom,而是系統調用sigaction指定FD綁定信號處理函數,立即結束不用阻塞等待,
- 如果沒有數據內核幫我們監聽如果有數據了幫我們去喚醒并且提交一個信號給我們用戶進程,
- 之前建立的SIGIO信號處理函數就去處理這個信號,整個過程用戶不用去等待可以去干其他事情
第二階段和其他阻塞IO一致
那么你可能會問這個IO這么好為什么不用而要去用多路復用IO?
當有大量IO操作時,信號較多,SIGIO處理函數不能及時處理可能導致信號隊列溢出
而且內核空間與用戶空間頻繁的信號交互性能也較低。
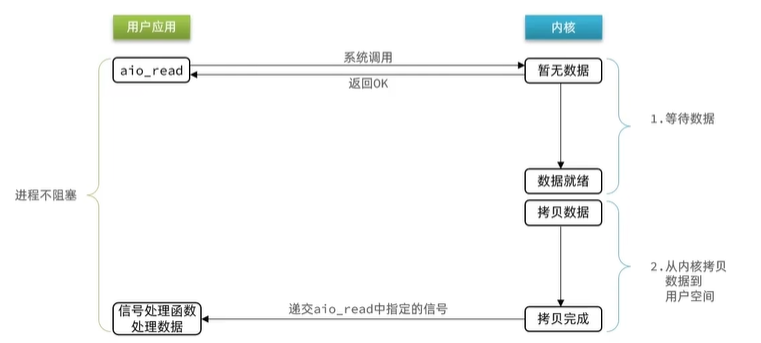
6.異步IO
異步IO的整個過程都是非阻塞的,用戶進程調用完異步API后盡可以去做其他事情,內核等待數據就緒并拷貝到用戶空間后才會遞交信號,通知用戶進程。
- 1.異步IO并沒有調用recvfrom函數而是調用aio_read通知內核說我想讀哪個FD,讀到哪里去就結束了。
- 2.內核把數據準備就緒再把數據拷貝完成通知用戶進程
異步IO在兩個階段都是非阻塞的
這種模式聽著非常好但是高并發場景下如果對異步 I/O 的并發度控制不當,可能會導致系統資源過度使用,從而影響性能。
過多的異步網絡請求可能會導致網絡擁塞,降低系統的響應速度。
7.同步和異步
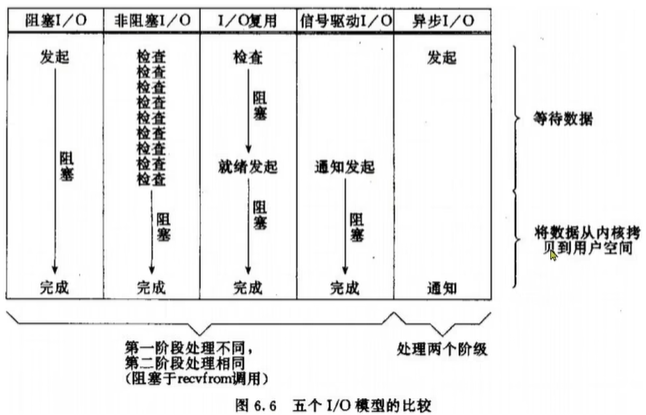
IO操作是同步還是異步,關鍵看數據在內核空間與用戶空間的拷貝過程(數據讀寫的IO操作),也就是階段二是同步還是異步:
?
8.Redis——網絡模型
?8.1.Redis到底是單線程還是多線程?
1.如果僅僅聊Redis的核心業務部分(命令處理),答案是單線程
2.如果是聊整個Redis,那么答案就是多線程
在Redis版本迭代過程中,在兩個重要的事件節點上引入了多線程的支持:
Redis v4.0:引入多線程異步處理耗時較長的任務,例如異步刪除命令unlink
Redis v6.0:在核心網絡模型中引入多線程,進一步提高對于多核cpu的利用率
8.2.為什么Redis要選擇單線程?
1.拋開持久化不談,Redis是純內存操作,執行速度非常快,它的性能瓶頸是網絡延遲而不是執行速度,因此多線程并不會帶來巨大的性能提升
2.多線程會導致過多的上下文切換,帶來不必要的開銷
3.引入多線程會面臨線程安全問題,必然要引入線程鎖,這樣的安全手段,實現復雜度增高,而且性能也會大打折扣
8.3.Redis單線程網絡模型的整個流程
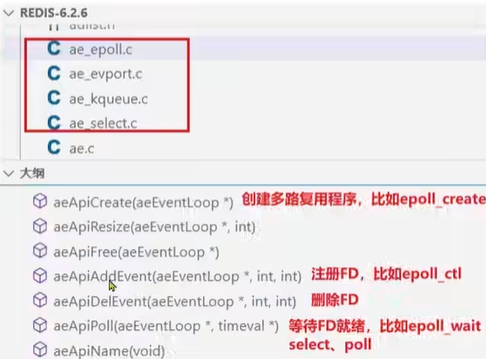
Redis通過IO多路復用來提高網絡性能,并且支持各種不同的多路復用實現,并且將這些實現進行封裝,提供了統一的高性能事件庫AE:
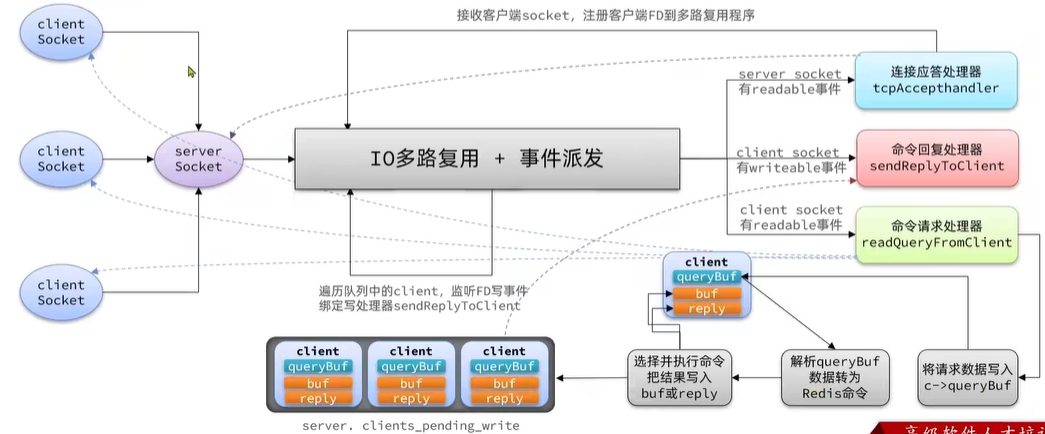
整體來看,Redis的網絡模型就是基于"IO多路復用 + 事件派發機制",總之就是客戶端請求來了之后,我們都會做多路復用的事件監聽,無論是什么類型的事件.然后我提前定義好各種各樣的事件處理器.對于不同的事件,我就派發給不同的事件處理器來處理..
性能瓶頸:Redis6.0版本中引入了多線程,目的是為了提高IO讀寫效率。因此在 “解析客戶端命令,寫出相應結果”?時采用了多線程。核心的執行命令執行,IO多路復用模塊依然采用的時由主線程執行。
1.就是Client socket有readable事件交給命令請求處理器,然后將請求數據寫入querybuf并解析數據這是一個IO過程
2.觸發寫事件,往客戶端寫數據這里又會有一次網絡IO,收到網絡帶寬,網絡狀態影響。