從 GPS 數據中捕捉城市休閑熱點:空間異質性視角下的新框架
原文:Capturing urban recreational hotspots from GPS data: A new framework in the lens of spatial heterogeneity
1. 背景與意義
- 城市娛樂活動的重要性:
- 娛樂活動是城市生活的關鍵組成部分,對居民生活質量和社會經濟文化發展具有深遠的影響。
- 合理布局娛樂活動空間有助于提升居民生活品質、促進社會交往、推動城市經濟繁榮、增強城市吸引力與競爭力。
- 準確識別城市娛樂熱點區域對城市規劃者和管理者至關重要,可為城市娛樂設施布局優化、空間品質提升和可持續發展提供決策支持。
- 城市空間異質性:
- 城市空間具有復雜性和多樣性,娛樂活動分布呈現出顯著的空間異質性,即存在大量低密度區域和少量高密度的娛樂熱點區域。
- 這種空間分布特征反映了城市居民在娛樂場所選擇上的集中偏好以及城市空間資源的不均衡配置。
- 傳統娛樂熱點識別方法常忽略空間異質性特征,導致熱點界定和分析存在局限性。
- 現有方法的局限性:
- 早期研究依賴統計數據和問卷調查等方式了解居民娛樂行為和偏好,但這些方法在時間和空間分辨率上較低,難以捕捉娛樂活動的精細空間分布。
- 隨著技術發展,基于位置的大數據(如GPS軌跡數據、社交媒體簽到數據等)為娛樂熱點識別提供了新契機。
- 現有基于大數據的熱點識別框架多直接套用通用聚類算法(如K-means、DBSCAN等),這些算法處理具有空間異質性的地理數據時,需人工預定義關鍵參數,缺乏對數據空間特征的自適應性考量,導致熱點邊界不合理、聚類結果不準確等問題。
- 新框架的提出與優勢:
- 該研究提出了結合空間異質性理論和GPS軌跡數據的新框架,以更精準、高效地識別城市娛樂熱點。
- 新框架可充分發揮GPS軌跡數據時空分辨率優勢,融入空間異質性概念,更好地揭示娛樂活動在城市空間中的聚集模式和分布規律。
- 為城市規劃者和決策者提供更科學、準確的娛樂熱點分布信息,助力優化城市娛樂設施布局、提升城市空間品質、促進城市可持續發展。
- 理論意義:
- 拓展空間異質性理論在城市娛樂領域的應用,豐富城市地理學和空間分析理論體系。
- 通過與傳統聚類方法對比分析,為地理空間數據聚類分析提供新思路和方法,推動地理信息科學等相關學科發展。
- 深入探討娛樂熱點,為理解城市空間中人類活動模式和空間組織規律提供新視角,為相關領域未來研究奠定基礎。
- 實踐意義:
- 為城市規劃者和管理者提供更準確的娛樂熱點分布信息,助力優化城市娛樂設施布局和提升城市空間品質。
- 促進城市可持續發展,增強城市吸引力和競爭力,提升居民生活質量。
- 推動城市規劃與管理向科學化、精細化方向發展,為城市娛樂系統的重新設計和改進提供新的思路和方法。
2. 研究方法
-
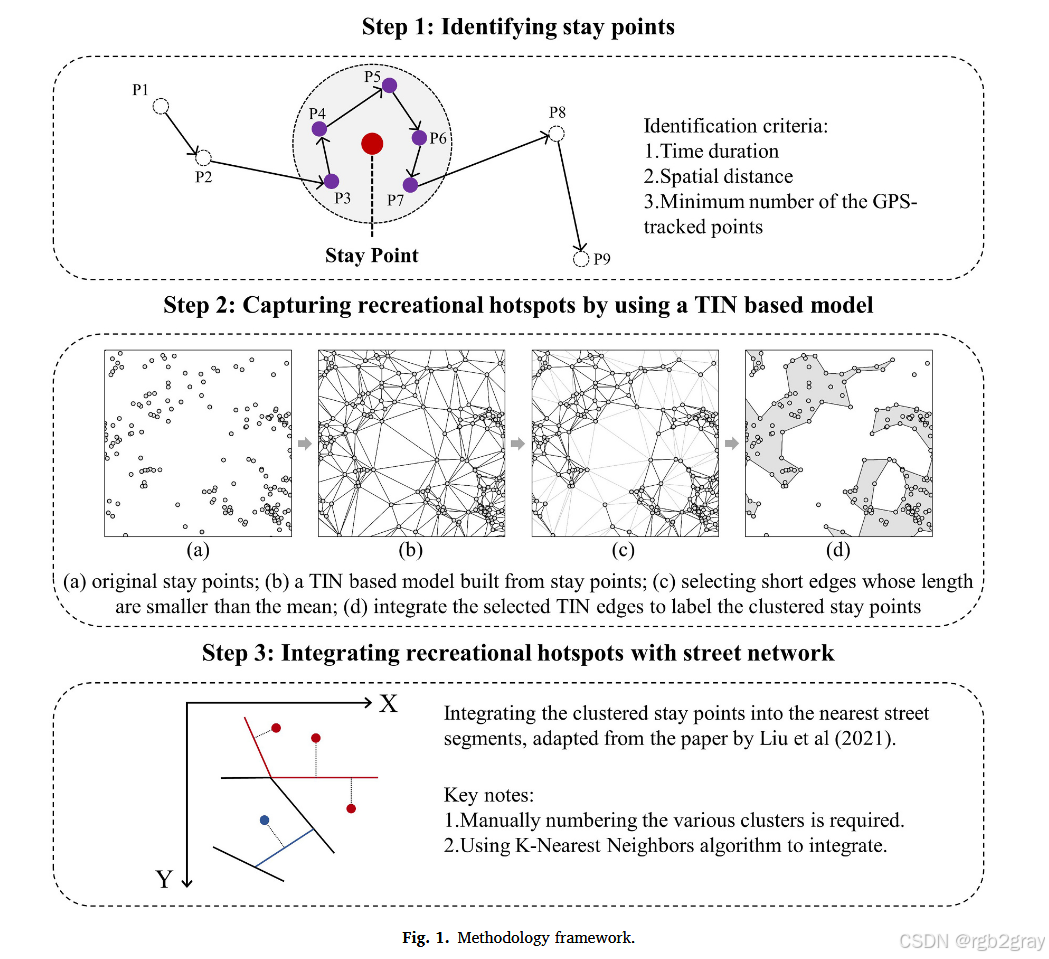
框架建立:基于GPS軌跡數據,構建了一個包含三個步驟的框架來有效捕獲娛樂熱點。
- 提取停留點:首先從個體的軌跡中提取停留點。停留點是指個體在某個空間內停留較長時間的活動點,它具有時空雙重意義。通過特定的算法和條件(如空間距離和時間間隔的閾值)來判斷軌跡中的停留點,并計算出這些停留點的坐標和時間戳。
- 基于TIN模型的聚類:將提取出的停留點轉換為三角不規則網絡(TIN)模型,并利用TIN邊長來描述點的密度。根據空間異質性理論,城市中的娛樂活動呈現出重尾分布特征,因此可以通過統計TIN邊長的分布來識別高密度區域。具體來說,通過計算邊長的平均值,將邊長分為“頭”(大于平均值)和“尾”(小于平均值)兩部分,以此來劃分高密度和低密度區域。此外,還采用ht-index等指標來衡量數據的重尾層次,進一步驗證空間異質性。
- 生成熱點并整合街段:最后,將聚類后的停留點(即熱點)與其相鄰的街段進行整合。街段作為城市空間的基本單元,能夠為娛樂熱點的定義提供更符合實際情況的空間載體。通過將熱點與街段相結合,可以更準確地反映娛樂活動在城市中的實際分布,并為后續的規劃和管理提供依據。
-
關鍵概念與理論基礎:
- 空間異質性:城市空間本質上是異質的,具有非均衡的空間分布特征,如人口分布、建筑密度等。這種空間異質性在娛樂活動中也得到了體現,即娛樂活動在城市中呈現出明顯的聚集模式,形成少數高密度的熱點區域和大量低密度的區域。這種分布特征可以通過重尾分布(如冪律分布)來描述,因此在識別娛樂熱點時需要充分考慮這一特性。
- 停留點提取:停留點的提取是基于個體軌跡數據中的時空信息。通過設定空間距離和時間間隔的閾值條件,判斷軌跡中的停留行為,并計算出相應的停留點坐標和時間戳。這一過程有助于從大量的軌跡數據中篩選出與娛樂活動相關的停留點,為后續的聚類分析提供基礎數據。
- 基于TIN模型的聚類:TIN模型是一種用于表示不規則地形表面的幾何模型,其邊長可以反映點之間的密度差異。在娛樂熱點識別中,通過構建TIN模型并分析邊長的分布特征,可以有效地識別出高密度的停留點區域,即娛樂熱點。這種方法不僅考慮了空間異質性,還能夠利用幾何模型的特性來準確劃分熱點邊界。
- 街段整合:街段整合的目的是將聚類后的熱點與城市街道網絡相結合,使其更符合真實的城市場景。通過將熱點整合到街段中,可以更好地反映娛樂活動與城市空間結構之間的關系,同時也為城市規劃和管理提供了更直觀、更實用的空間信息。
3. 實驗與結果
- 案例選擇:在中國的三個典型城市區域開展實證研究,即廣州老城區、上海浦東新區核心區和天津濱海新區核心區。這三個區域在城市發展水平、功能布局和娛樂活動類型等方面具有一定的代表性,能夠為驗證新框架的有效性提供豐富的數據基礎。
- 數據來源與預處理:所使用的GPS數據主要來自一個名為“2bulu”的戶外娛樂網站/應用程序,該平臺包含大量由用戶分享的軌跡數據。在數據預處理階段,研究者對數據進行了篩選和清洗,以確保數據的準確性和相關性。具體步驟包括:選擇與娛樂活動相關的軌跡類型或標簽;對選定的軌跡進行人工復查;校準GPS定位信息等。
- 空間異質性驗證:在進行熱點識別之前,對三個案例的停留點進行重尾分布檢查。結果表明,所有案例的TIN邊長均呈現出厚尾分布特征,ht指數均遠大于閾值3,這驗證了娛樂停留點在空間分布上具有顯著的異質性,符合研究的預期和理論基礎。
- 熱點識別結果:
- 廣州老城區:娛樂熱點主要集中在中西部區域,而靠近珠江新城的東部區域熱點相對較少。此外,珠江北岸的熱點密度高于南岸,除了南岸的中山大學校園內有一些明顯的熱點。這反映出廣州老城區的娛樂活動主要集中在傳統商業區和文化教育機構附近。
- 上海浦東新區核心區:娛樂熱點形成了沿黃浦江東岸的娛樂“帶”,包括多個熱點,如濱江公園、陸家嘴金融區等。同時,在上海國際旅游度假區內也有幾個相鄰的熱點,如迪士尼樂園及其周邊設施。這顯示出上海浦東新區的娛樂活動與城市濱水空間和大型旅游項目的分布密切相關。
- 天津濱海新區核心區:娛樂熱點分布較為集中,主要集中在新區的商業CBD,形成明顯的單中心模式。核心區域外的熱點則較為稀疏。這表明天津濱海新區的娛樂活動主要圍繞著核心商務區展開,可能與其城市規劃和功能布局有關。
- 結果驗證:通過將識別出的熱點與實際城市功能區進行疊加分析,發現大部分娛樂熱點位于大型公共空間內,如公園、廣場、游樂園、歷史文化街區和商業綜合體等。這與城市居民對娛樂空間的偏好一致。同時,研究還與其他學者在同一地區的研究結果進行對比,發現具有一致性,進一步證明了新框架的可靠性和有效性。此外,相關政府文件和發展規劃也為研究結果提供了支持,例如上海國際旅游度假區的發展規劃等。
4. 方法比較
- 對比方法:為了驗證新框架的有效性和優越性,研究者將其與三種常用的聚類方法——K-means、DBSCAN和CFSFDP進行了比較。這些方法都是基于密度的聚類算法,在數據聚類分析中具有廣泛的應用。
- 對比結果:
-
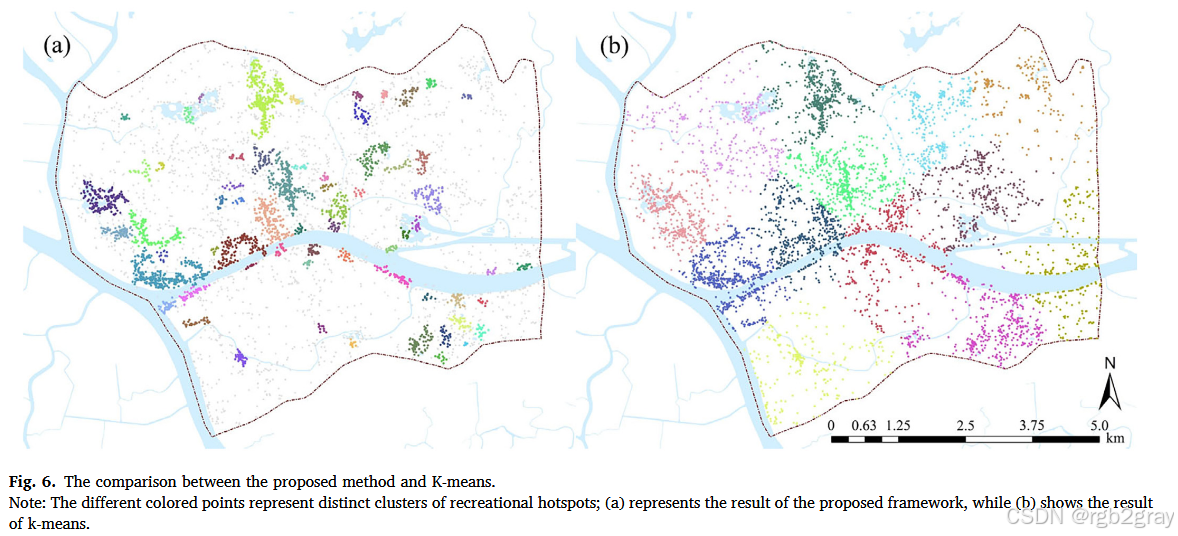
與K-means相比:K-means算法雖然能夠成功將停留點分組并標記每個簇的中心,但它的主要缺點在于無法定義熱點的空間范圍。這是因為K-means側重于將數據點劃分為不同的簇,而不考慮簇的形狀和邊界。因此,它無法準確地反映娛樂熱點的實際空間覆蓋范圍,與本研究的目的不符。
-
與DBSCAN相比:在DBSCAN算法的推薦距離閾值下,其聚類結果難以清晰地展示娛樂熱點的結構。例如,在距離閾值為150米或220米時,DBSCAN會將大部分中央區域的停留點識別為一個整體的巨大熱點,而無法區分出其中的細節結構。相比之下,新框架的S_Dbw指數顯著優于DBSCAN,表明新框架能夠更準確地捕捉熱點的空間分布特征。

-
與CFSFDP相比:CFSFDP算法在三種場景下均不如新框架。在高密度簇中,CFSFDP會將自然屬于一個簇的停留點分為多個簇;而在低密度簇中,其檢測范圍較大,導致一些停留點被誤分類。此外,CFSFDP在定義簇邊界方面也存在不足,無法像新框架那樣清晰地劃分娛樂熱點的范圍。通過S_Dbw測量結果也進一步證實了新框架在聚類準確性方面的優勢。
-
- 討論:綜合來看,新框架在目的適用性、聚類速度和準確性方面均優于三種傳統方法。其優勢主要歸因于對城市空間異質性的深入理解和利用。由于城市活動的聚集性,城市空間往往呈現出極不均勻的分布模式,即空間異質性。新框架通過結合空間異質性理論,能夠更有效地識別出娛樂熱點的分布特征,而傳統的聚類方法在處理具有空間異質性的地理數據時可能存在一定的局限性。
5. 結論與未來工作
- 研究貢獻:本研究提出了一種新的基于GPS軌跡數據和空間異質性理論的娛樂熱點識別框架,通過在廣州、上海和天津三個城市的實證研究,驗證了該框架的有效性和可靠性。與傳統聚類方法相比,新框架在多個方面表現出優越性,為城市娛樂系統的重新設計和改進提供了新的思路和方法。這一研究不僅拓展了空間異質性理論在城市娛樂領域的應用,還為城市規劃和管理提供了更有價值的決策支持。
- 研究局限:盡管新框架在實證研究中表現出色,但研究中所使用的數據并不完全代表所有城市居民。例如,“2bulu”平臺的數據可能主要集中在年輕人群體,而對老年人等其他群體的關注度不足。因此,研究結果可能存在一定的偏差。然而,需要指出的是,本研究的重點在于提出一種方法論框架,而非進行全面的實證調查。如果能夠采用更全面的GPS數據源,新框架的準確性有望進一步提高,從而更好地服務于城市規劃和管理實踐。
- 未來研究方向:未來的研究可以從以下幾個方面展開:一是深入探討環境特征對娛樂熱點空間質量的影響,例如地形、植被、氣候等因素如何影響娛樂活動的分布和質量;二是引入Alexander的“生活結構”理論,從更深層次解釋娛樂熱點的空間分布和形成機制,為城市娛樂空間的優化提供更豐富的理論支持;三是探索新框架在其他具有空間異質性特征的地理空間主題中的應用潛力,如城市交通流量分析、土地利用變化研究等,以進一步驗證和拓展該框架的適用性和有效性。
6. 其他
import pandas as pd
import numpy as np
from sklearn.cluster import DBSCAN
import matplotlib.pyplot as plt# 讀取GPS軌跡數據
# 假設數據包含經度、緯度、時間戳等列
columns = ['time', 'latitude', 'longitude']
data = pd.read_csv('gps_data.csv', names=columns)# 數據預處理
# 轉換時間為時間戳
data['time'] = pd.to_datetime(data['time'])
data['timestamp'] = data['time'].astype(np.int64) // 10**9# 提取停留點
def extract_stay_points(data, dr=250, tr=600): # tr單位為秒stay_points = []i = 0while i < len(data):j = i + 1while j < len(data):# 計算兩點之間的距離(這里簡化為歐氏距離,實際應用中建議使用Haversine公式計算地理坐標距離)distance = np.sqrt((data.loc[i, 'latitude'] - data.loc[j, 'latitude'])**2 + (data.loc[i, 'longitude'] - data.loc[j, 'longitude'])**2)if distance > dr:breakj += 1# 計算停留時間duration = (data.loc[j-1, 'timestamp'] - data.loc[i, 'timestamp'])if duration >= tr and (j - i) >= 4: # 至少有4個連續點# 計算平均坐標和時間avg_lat = data.loc[i:j, 'latitude'].mean()avg_lon = data.loc[i:j, 'longitude'].mean()avg_time = data.loc[i:j, 'timestamp'].mean()stay_points.append([avg_lat, avg_lon, avg_time])i = jstay_points = pd.DataFrame(stay_points, columns=['latitude', 'longitude', 'timestamp'])return stay_pointsstay_points = extract_stay_points(data)# 聚類分析
# 使用DBSCAN算法進行聚類
coordinates = stay_points[['latitude', 'longitude']].values
db = DBSCAN(eps=0.001, min_samples=5).fit(coordinates) # eps可根據具體坐標單位調整# 可視化結果
plt.scatter(coordinates[:, 1], coordinates[:, 0], c=db.labels_, cmap='viridis', marker='o', s=50)
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.title('Clustering of Stay Points')
plt.show()

















)

