3. 數據集加載案例
通過一些數據集的加載案例,真正了解數據類及數據加載器。
3.1 加載csv數據集
代碼參考如下
import torch from torch.utils.data import Dataset, DataLoader import pandas as pd ? ? class MyCsvDataset(Dataset):def __init__(self, filename):df = pd.read_csv(filename)# 刪除文字列df = df.drop(["學號", "姓名"], axis=1)# 轉換為tensordata = torch.tensor(df.values)# 最后一列以前的為data,最后一列為labelself.data = data[:, :-1]self.label = data[:, -1]self.len = len(self.data) ?def __len__(self):return self.len ?def __getitem__(self, index):idx = min(max(index, 0), self.len - 1)return self.data[idx], self.label[idx] ? ? def test001():excel_path = r"./大數據答辯成績表.csv"dataset = MyCsvDataset(excel_path)dataloader = DataLoader(dataset, batch_size=4, shuffle=True)for i, (data, label) in enumerate(dataloader):print(i, data, label) ? ? if __name__ == "__main__":test001() ?
練習:上述示例數據構建器改成TensorDataset
def build_dataset(filepath):df = pd.read_csv(filepath)df.drop(columns=['學號', '姓名'], inplace=True)data = df.iloc[..., :-1]labels = df.iloc[..., -1] ?x = torch.tensor(data.values, dtype=torch.float)y = torch.tensor(labels.values) ?dataset = TensorDataset(x, y) ?return dataset ? ? def test001():filepath = r"./大數據答辯成績表.csv"dataset = build_dataset(filepath)dataloader = DataLoader(dataset, batch_size=4, shuffle=True)for i, (data, label) in enumerate(dataloader):print(i, data, label)
3.2 加載圖片數據集
參考代碼如下:只是用于文件讀取測試
import torch from torch.utils.data import Dataset, DataLoader import os ? # 導入opencv import cv2 ? ? class MyImageDataset(Dataset):def __init__(self, folder):# 文件存儲路徑列表self.filepaths = []# 文件對應的目錄序號列表self.labels = []# 指定圖片大小self.imgsize = (112, 112)# 臨時存儲文件所在目錄名dirnames = [] ?# 遞歸遍歷目錄,root:根目錄路徑,dirs:子目錄名稱,files:子文件名稱for root, dirs, files in os.walk(folder):# 如果dirs和files不同時有值,先遍歷dirs,然后再以dirs的目錄為路徑遍歷該dirs下的files# 這里需要在dirs不為空時保存目錄名稱列表if len(dirs) > 0:dirnames = dirs ?for file in files:# 文件路徑filepath = os.path.join(root, file)self.filepaths.append(filepath)# 分割root中的dir目錄名classname = os.path.split(root)[-1]# 根據目錄名到臨時目錄列表中獲取下標self.labels.append(dirnames.index(classname))self.len = len(self.filepaths) ?def __len__(self):return self.len ?def __getitem__(self, index):# 獲取下標idx = min(max(index, 0), self.len - 1)# 根據下標獲取文件路徑filepath = self.filepaths[idx]# opencv讀取圖片img = cv2.imread(filepath)# 圖片縮放,圖片加載器要求同一批次的圖片大小一致img = cv2.resize(img, self.imgsize)# 轉換為tensorimg_tensor = torch.tensor(img)# 將圖片HWC調整為CHWimg_tensor = torch.permute(img_tensor, (2, 0, 1))# 獲取目錄標簽label = self.labels[idx] ?return img_tensor, label ? ? def test02():path = os.path.join(os.path.dirname(__file__), 'dataset')# 轉換為相對路徑path = os.path.relpath(path)dataset = MyImageDataset(path) ?dataloader = DataLoader(dataset, batch_size=8, shuffle=True) ?for img, label in dataloader:print(img.shape)print(label) ? ? if __name__ == "__main__":test02() ?
練習:1.重寫上述代碼,如果不對圖片進行縮放會產生什么結果?2.在遍歷圖片的代碼中打印圖片查看圖片效果(打印一批次即可)
# 導入opencv
import cv2
?
?
class MyDataset(Dataset):def __init__(self, folder):
?dirnames = []self.filepaths = []self.labels = []
?for root, dirs, files in os.walk(folder):if len(dirs) > 0:dirnames = dirs
?for file in files:filepath = os.path.join(root, file)self.filepaths.append(filepath)classname = os.path.split(root)[-1]if classname in dirnames:self.labels.append(dirnames.index(classname))else:print(f'{classname} not in {dirnames}')
?self.len = len(self.filepaths)
?def __len__(self):return self.len
?def __getitem__(self, index):idx = min(max(index, 0), self.len - 1)filepath = self.filepaths[idx]img = cv2.imread(filepath)print(img.shape)# 不做圖片縮放,報:RuntimeError: stack expects each tensor to be equal size, but got [3, 1333, 2000] at entry 0 and [3, 335, 600] at entry 1img = cv2.resize(img, (112, 112))t_img = torch.tensor(img)t_img = torch.permute(t_img, (2, 0, 1))
?label = self.labels[idx]return t_img, label
?
?
def test02():path = os.path.join(os.path.dirname(__file__), 'dataset')dataset = MyDataset(path)dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
?for img, label in dataloader:
?print(img.shape, label)for i in range(img.shape[0]):im = torch.permute(img[i], (1, 2, 0))plt.imshow(im)plt.show()
?break
?
?
if __name__ == "__main__":test02()
優化:使用ImageFolder加載圖片集
ImageFolder 會根據文件夾的結構來加載圖像數據。它假設每個子文件夾對應一個類別,文件夾名稱即為類別名稱。例如,一個典型的文件夾結構如下:
root/class1/img1.jpgimg2.jpg...class2/img1.jpgimg2.jpg......
在這個結構中:
-
root是根目錄。 -
class1、class2等是類別名稱。 -
每個類別文件夾中的圖像文件會被加載為一個樣本。
ImageFolder構造函數如下:
torchvision.datasets.ImageFolder(root, transform=None, target_transform=None, is_valid_file=None)
參數解釋
-
root:字符串,指定圖像數據集的根目錄。 -
transform:可選參數,用于對圖像進行預處理。通常是一個torchvision.transforms的組合。 -
target_transform:可選參數,用于對目標(標簽)進行轉換。 -
is_valid_file:可選參數,用于過濾無效文件。如果提供,只有返回True的文件才會被加載。
import torch from torchvision import datasets, transforms import os from torch.utils.data import DataLoader from matplotlib import pyplot as plt ? torch.manual_seed(42) ? def load():path = os.path.join(os.path.dirname(__file__), 'dataset')print(path) ?transform = transforms.Compose([transforms.Resize((112, 112)),transforms.ToTensor()]) ?dataset = datasets.ImageFolder(path, transform=transform)dataloader = DataLoader(dataset, batch_size=1, shuffle=True) ?for x,y in dataloader:x = x.squeeze(0).permute(1, 2, 0).numpy()plt.imshow(x)plt.show()print(y[0])break ? ? if __name__ == '__main__':load() ?
3.3 加載官方數據集
在 PyTorch 中官方提供了一些經典的數據集,如 CIFAR-10、MNIST、ImageNet 等,可以直接使用這些數據集進行訓練和測試。
數據集:Datasets — Torchvision 0.21 documentation
常見數據集:
-
MNIST: 手寫數字數據集,包含 60,000 張訓練圖像和 10,000 張測試圖像。
-
CIFAR10: 包含 10 個類別的 60,000 張 32x32 彩色圖像,每個類別 6,000 張圖像。
-
CIFAR100: 包含 100 個類別的 60,000 張 32x32 彩色圖像,每個類別 600 張圖像。
-
COCO: 通用對象識別數據集,包含超過 330,000 張圖像,涵蓋 80 個對象類別。
torchvision.transforms 和 torchvision.datasets 是 PyTorch 中處理計算機視覺任務的兩個核心模塊,它們為圖像數據的預處理和標準數據集的加載提供了強大支持。
transforms 模塊提供了一系列用于圖像預處理的工具,可以將多個變換組合成處理流水線。
datasets 模塊提供了多種常用計算機視覺數據集的接口,可以方便地下載和加載。
參考如下:
import torch from torch.utils.data import Dataset, DataLoader import torchvision from torchvision import transforms, datasets ? ? def test():transform = transforms.Compose([transforms.ToTensor(),])# 訓練數據集data_train = datasets.MNIST(root="./data",train=True,download=True,transform=transform,)trainloader = DataLoader(data_train, batch_size=8, shuffle=True)for x, y in trainloader:print(x.shape)print(y)break ?# 測試數據集data_test = datasets.MNIST(root="./data",train=False,download=True,transform=transform,)testloader = DataLoader(data_test, batch_size=8, shuffle=True)for x, y in testloader:print(x.shape)print(y)break ? ? def test006():transform = transforms.Compose([transforms.ToTensor(),])# 訓練數據集data_train = datasets.CIFAR10(root="./data",train=True,download=True,transform=transform,)trainloader = DataLoader(data_train, batch_size=4, shuffle=True, num_workers=2)for x, y in trainloader:print(x.shape)print(y)break# 測試數據集data_test = datasets.CIFAR10(root="./data",train=False,download=True,transform=transform,)testloader = DataLoader(data_test, batch_size=4, shuffle=False, num_workers=2)for x, y in testloader:print(x.shape)print(y)break ? ? if __name__ == "__main__":test()test006() ?
1. 神經網絡基礎
1.1 生物神經元與人工神經元
神經網絡的設計靈感來源于生物神經元。生物神經元通過樹突接收信號,細胞核處理信號,軸突傳遞信號,突觸連接不同的神經元。人工神經元模仿了這一過程,接收多個輸入信號,經過加權求和和非線性激活函數處理后,輸出結果。
1.2 人工神經元的組成
人工神經元由以下幾個部分組成:
- ?輸入(Inputs)?:代表輸入數據,通常用向量表示。
- ?權重(Weights)?:每個輸入數據都有一個權重,表示該輸入對最終結果的重要性。
- ?偏置(Bias)?:一個額外的可調參數,用于調整模型的輸出。
- ?加權求和:將輸入乘以對應的權重后求和,再加上偏置。
- ?激活函數(Activation Function)?:將加權求和后的結果轉換為輸出結果,引入非線性特性。
數學表示如下:
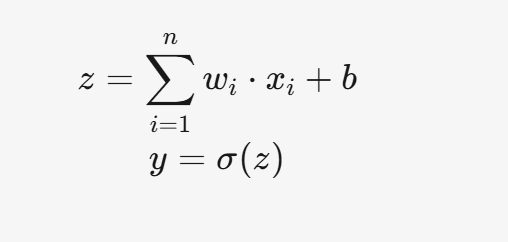
其中,σ(z)?是激活函數。
2. 神經網絡結構
2.1 基本結構
神經網絡由以下三層構成:
- ?輸入層(Input Layer)?:接收外部數據,不進行計算。
- ?隱藏層(Hidden Layer)?:位于輸入層和輸出層之間,進行特征提取和轉換。隱藏層可以有多層,每層包含多個神經元。
- ?輸出層(Output Layer)?:產生最終的預測結果或分類結果。
2.2 全連接神經網絡
全連接神經網絡(Fully Connected Neural Network,FCNN)是前饋神經網絡的一種,每一層的神經元與上一層的所有神經元全連接。全連接神經網絡常用于圖像分類、文本分類等任務。
2.2.1 特點
- ?權重數量大:由于全連接的特點,權重數量較大,計算量大。
- ?學習能力強:能夠學習輸入數據的全局特征,但對高維數據的局部特征捕捉能力較弱。
2.2.2 計算步驟
- ?數據傳遞:輸入數據逐層傳遞到輸出層。
- ?激活函數:每一層的輸出通過激活函數處理。
- ?損失計算:計算預測值與真實值之間的差距。
- ?反向傳播:通過反向傳播算法更新權重以最小化損失。
3. 激活函數
激活函數在神經網絡中引入非線性,使網絡能夠處理復雜的任務。以下是幾種常見的激活函數及其特點。
3.1 Sigmoid
3.1.1 公式
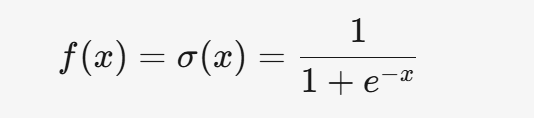
3.1.2 特點
- 將輸入映射到 (0, 1) 之間,適合處理概率問題。
- 梯度消失問題嚴重,容易導致訓練速度變慢。
- 計算成本較高。
3.1.3 應用場景
- 一般用于二分類問題的輸出層。
3.2 Tanh
3.2.1 公式
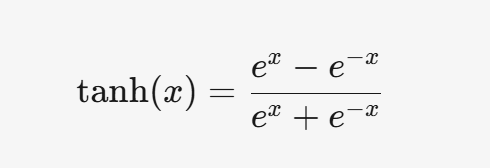
3.2.2 特點
- 輸出范圍為 (-1, 1),是零中心的,有助于加速收斂。
- 對稱性較好,適合隱藏層。
- 仍然存在梯度消失問題。
3.2.3 應用場景
- 適用于隱藏層,但不如 ReLU 常用。
3.3 ReLU
3.3.1 公式
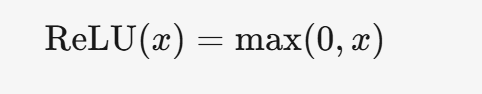
3.3.2 特點
- 計算簡單,適合大規模數據訓練。
- 緩解梯度消失問題,適合深層網絡。
- 存在神經元死亡問題,即某些神經元可能永遠不被激活。
3.3.3 應用場景
- 深度學習中最常用的激活函數,適用于隱藏層。
3.4 Leaky ReLU
3.4.1 公式
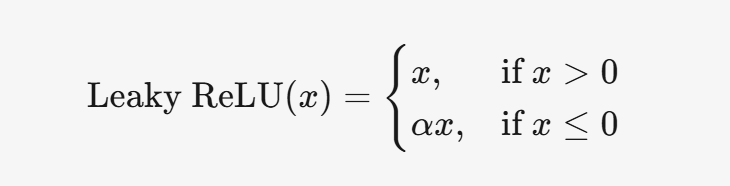
3.4.2 特點
- 解決了 ReLU 的神經元死亡問題。
- 計算簡單,但需要調整超參數?α。
3.4.3 應用場景
- 適用于隱藏層,尤其是 ReLU 效果不佳時。
3.5 Softmax
3.5.1 公式
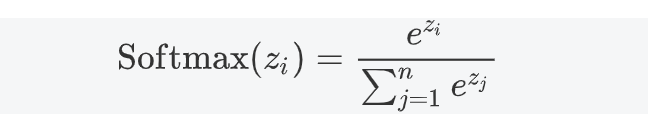

3.5.2 特點
- 將輸出轉化為概率分布,適合多分類問題。
- 放大差異,使概率最大的類別更突出。
- 存在數值不穩定性問題,需進行數值調整。
3.5.3 應用場景
- 用于多分類問題的輸出層。
4. 激活函數的選擇
4.1 隱藏層
- 優先選擇 ReLU。
- 如果 ReLU 效果不佳,嘗試 Leaky ReLU 或其他激活函數。
- 避免使用 Sigmoid,可以嘗試 Tanh。
4.2 輸出層
- 二分類問題選擇 Sigmoid。
- 多分類問題選擇 Softmax。
5. 總結
神經網絡是深度學習的核心,理解其結構和激活函數的作用至關重要。人工神經元是神經網絡的基本單元,通過加權求和和激活函數實現非線性變換。全連接神經網絡是最基本的神經網絡結構,廣泛應用于各類任務。激活函數在神經網絡中引入非線性,增強了網絡的表達能力。不同激活函數適用于不同的場景,合理選擇激活函數可以顯著提升模型性能。












![[HOT 100] 1964. 找出到每個位置為止最長的有效障礙賽跑路線](http://pic.xiahunao.cn/[HOT 100] 1964. 找出到每個位置為止最長的有效障礙賽跑路線)


)

是什么)

