1 triton 3.0.0 源碼結構
- triton
-
docs/:項目文檔
-
cmake/:構建配置相關
-
bin/:工具、腳本
-
CmakeLists.txt:cmake 配置文件
-
LSCENSE
-
README.md
-
Pyproject.toml:python 項目配置文件
-
utils/:項目配置文件目錄
-
unittest/:單元測試代碼
-
third_party/:第三方資源
- amd/
- f2reduce/
-
test/:測試代碼
-
python/:python 接口代碼
-
lib/:核心邏輯實現,
.cc/.cpp,核心功能的具體實現- Analysis:相關分析
- Alias.cpp:內存別名分析
- Allocation.cpp:共享內存分配相關分析
- Axisinfo.cpp:軸分析相關
- Membar.cpp:線程同步、內存屏障相關
- Conversion:dialect 之間的轉換
- TritonGPUToLLVM:tritonGPU dialect 降級到 LLVM dialect
- TritonToTritonGPU:triton dialect 降級到 tritonGPU dialect
- Dialect:各級中間表示 dialect 的定義,以及在對應 dialect 上進行的優化 pass
- triton
- IR:dialect/算子/屬性/類型的定義
- Transforms:相應中間表示上的優化 pass
- Combine.cpp:優化 select 和 load 操作的組合
- ReorderBroadcast.cpp:將通過 broad 和乘法生成的規約操作優化為點積操作
- tritonGPU
- TritonNvidiaGPU
- triton
- Target:將 llvm dialect 降級到 llvm ir,為 llvm ir 添加元數據,鏈接外部數學庫
- LLVMIR
- Tools:輔助工具頭文件,分析、調試、優化生成的代碼
CMakeLists.txt
- Analysis:相關分析
-
include/:核心邏輯定義,核心功能的
.h頭文件,提供約定和規范- triton
- Analysis
- Alias.h
- …
- Conversion
- TritonGPUToLLVM
- TritonToTritonGPU
- Dialect
- triton
- tritonGPU
- TritonNvidiaGPU
- Target
- LLVMIR
- Tools
- Analysis
- CMakeLists.txt
CMakeLists.txt
- triton
-
注:transforms 用于各級 dialect 之上,conversion 用于各級 dialect 之間
編譯流程對應源碼位置:
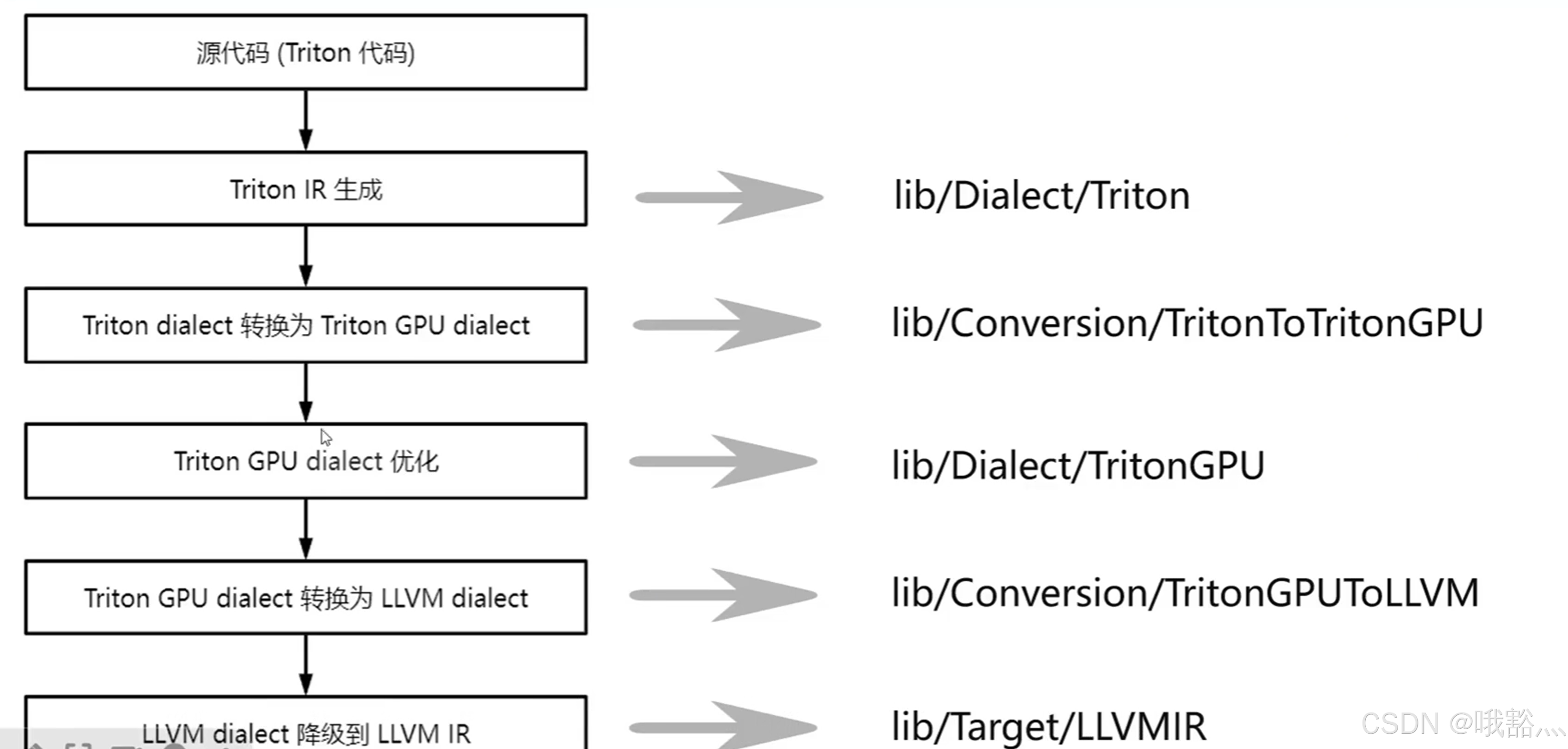
2 常用源碼位置
Triton dialect:
- OP 定義:include/triton/Dialect/IR/TritonOps.td
tt.call, tt.func, tt.return, tt.load, tt.store, tt.dot 等 OP - 優化 pass:lib/Dialect/Triton/Transforms
CombineOpsPass, ReorderBroadcastPass, RewriterTensorPointerPass, LoopUnrollPass
triton dialect --> tritonGPU Dialect:
轉換 pass:lib/Conversion/TritonToTritonGPU/TritonToTritonGPUPass.cpp
TritonGPU Dialect:
- Op 定義:include/triton/Dialect/TritonGPU/IR/TritonGPUOps.td
async_wait, alloc_tensor, insert_slice_async, convert_Layout 等 OP - Layout 屬性定義:include/triton/Dialect/TritonGPU/IR/TritonGPUAttrDefs.td
Blocked Layout, MMA Layout, DotOperand Layout, Slice Layout, Shared Layout - 優化 pass:lib/Dialect/TritonGPU/Transforms
AccelerateMatmul, Coalesce, CombineTensorSelectAndIf


 - 優化知識庫pdf文檔的識別)











 intro)



)
)