作為新能源汽車行業的從業者,你是否曾困惑于這些問題:
- 為什么同一款電動車,不同用戶的實際續航差異高達30%?
- 如何精準量化駕駛行為對電池壽命的影響?
- 車企標定的“NEDC續航”與真實路況差距的根源是什么?
這些問題的答案,都藏在汽車行駛工況的核心特征參數中——它們不僅是車輛能耗的“基因密碼”,更是連接虛擬仿真與真實場景的“數據橋梁”。本文將從工程實戰視角,為你揭開這些參數背后的科學邏輯與行業應用。
一、汽車行駛工況:新能源車的“心電圖”
如果把車輛比作人體,行駛工況曲線就是它的“心電圖”——速度的每一次波動,都對應著電機、電池、電控系統的“生命體征”。在新能源汽車領域,這張“心電圖”的價值遠超傳統燃油車:
- 電池管理:急加速時電池瞬間放電功率可達200kW以上,直接影響電池溫升與壽命。
- 能耗預測:城市擁堵工況(平均速度15km/h)的能耗可能比高速勻速工況(80km/h)高40%。
- 算法優化:自動駕駛決策模塊需要預判速度-加速度分布,規劃最低能耗路徑。
而這一切,都依賴于對七大核心特征參數的深度解析。
二、參數背后的工程密碼:從實驗室到真實世界
1. 平均速度:能耗模型的“基準線”
- 行業誤區:多數人認為平均速度越高能耗越大,但在電動車中,中速區間(40-60km/h)反而可能最優。
- 實戰案例:某車企通過分析10萬條用戶數據發現,當平均速度從30km/h提升至50km/h時,續航增加12%(得益于減少了頻繁啟停的能量損耗)。
2. 速度-加速度聯合分布:駕駛風格的“指紋”
- 數據洞察:激進駕駛(加速度標準差>0.8m/s2)會導致電池峰值溫度升高8℃,循環壽命下降15%。
- 技術應用:某BMS系統通過實時監測聯合分布,動態調整SOC(電池荷電狀態)估算策略,將續航預測誤差從7%壓縮至2%。
3. 減速段平均減速度:能量回收的“金礦”
- 量化價值:在WLTC工況下,制動能量回收可貢獻高達25%的續航提升。
- 算法突破:某車型通過優化減速段識別算法(窗口長度從5秒縮短至0.5秒),能量回收效率提升18%。
三、行業級應用:數據驅動的新能源革命
1. 測試場景庫構建
- 國際標準:聯合國ECE R137法規要求,自動駕駛測試場景庫必須包含速度標準差>15km/h的激進駕駛片段。
- 車企實踐:某造車新勢力基于20個城市的聯合分布數據,構建了全球首個“中國式加塞工況”測試模塊。
2. 用戶畫像與個性化服務
- 數據變現:某車企通過分析用戶駕駛參數,推出“續航保險”服務——激進型用戶支付更高保費,但可獲得免費電池健康檢測。
- 生態延伸:充電樁運營商利用平均速度數據,預測用戶到達充電站時的剩余電量,動態調整充電價格。
3. 虛擬仿真與數字孿生
- 降本增效:某廠商通過將真實用戶的速度標準差(σ=12.3km/h)注入仿真模型,將實車測試里程從100萬公里減少至30萬公里。
- 技術前沿:特斯拉“影子模式”持續采集全球車主的聯合分布數據,用于訓練下一代能耗預測神經網絡。
四、給從業者的三個行動指南
-
建立數據思維
- 不要只盯著“平均速度”,速度-加速度的協方差矩陣可能隱藏著續航突變的關鍵信號。
- 推薦工具:Python的Seaborn庫可快速繪制聯合分布熱力圖(見示例代碼)。
-
擁抱場景化工程
- 將NEDC/WLTC等標準工況與用戶真實參數分布對比,找到優化“缺口”。
- 案例參考:某車型在σ_v>20km/h的工況下電機效率驟降,針對性升級后投訴率下降60%。
-
關注參數鏈式反應
- 速度波動(σ_v)→ 電池充放電頻次 → 溫度梯度 → 壽命衰減,這是一個需要跨部門協同的系統工程。
五、未來趨勢:參數維度的升維戰爭
當行業還在爭論平均速度的計算方法時,頭部企業已開始探索:
- 高階參數:速度分形維度(駕駛波動復雜性)、加速度功率譜密度(能量頻域特征)
- 融合參數:速度-坡度-溫度聯合分布(山地工況建模)
- 動態參數:基于實時交通流的工況參數自適應預測
誰掌握了參數解析的深度,誰就握住了新能源時代的鑰匙。
結語
在新能源汽車行業,沒有“普通”的數據,只有“尚未挖掘”的金礦。從一條速度曲線中,我們可以解碼電池壽命、重塑駕駛體驗、甚至重構商業模式。本文僅揭示了冰山一角,后續將帶來更多硬核專題:
- 《如何用聯合分布破解冬季續航縮水之謎》
- 《基于行駛參數的電池健康度無損檢測》
點擊關注,開啟你的新能源數據進化之旅。
配套資源
以下是汽車行駛工況核心特征參數的硬核解析,包括計算思路、公式及技術要點:
1. 平均速度(Average Speed)
計算思路
- 定義:車輛在測試周期內的總行駛距離與總時間的比值。
- 關鍵點:需排除停車時間(速度=0的時間段),僅統計車輛實際移動的時間。
公式
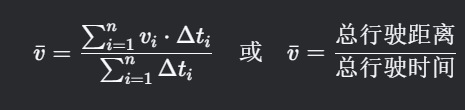
符號說明:
- v_i:第i個時間點的瞬時速度(單位:km/h 或 m/s)
- Delta t_i:第i個時間點的時間間隔(單位:s)
2. 行駛速度分布(Speed Profile)
計算思路
- 定義:速度隨時間變化的序列(時間-速度曲線)。
- 關鍵點:需按固定采樣頻率(如1Hz)采集速度數據,構建離散時間序列。
公式

技術要點:
- 數據清洗:剔除異常值(如負速度或超物理極限速度)。
- 插值處理:對缺失數據采用線性插值或樣條插值。
3. 最大速度與最小速度(Max/Min Speed)
計算思路
- 定義:測試周期內速度的全局最大值和最小值。
- 關鍵點:需排除瞬態噪聲(如傳感器誤差導致的異常峰值)。
公式

4. 速度標準偏差(Speed Standard Deviation)
計算思路
- 定義:速度序列的離散程度,反映駕駛激烈程度。
- 關鍵點:使用無偏估計(樣本標準差)。
公式
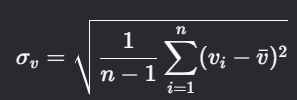
5. 加速度標準偏差(Acceleration Standard Deviation)
計算思路
- 定義:加速度序列的波動性,表征駕駛平穩性。
- 關鍵點:加速度通過速度差分計算,需平滑處理以減少噪聲。
公式
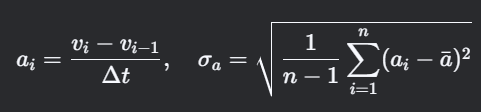
技術要點:
- 加速度計算需采用中心差分法或低通濾波(如Savitzky-Golay濾波器)抑制高頻噪聲。
6. 減速段平均減速度(Mean Deceleration in Braking Phases)
計算思路
- 定義:所有減速階段((a < 0))的減速度絕對值均值。
- 關鍵點:需識別連續減速區間(如加速度連續負值超過閾值)。
公式
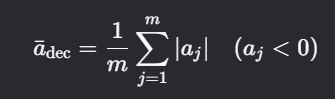
技術要點:
- 減速段識別算法:滑動窗口檢測連續負加速度區間(如窗口長度≥3秒)。
7. 速度-加速度聯合分布(Speed-Acceleration Joint Distribution)
計算思路
- 定義:速度與加速度的二維概率密度分布,反映駕駛工況的動力學特征。
- 關鍵點:分箱統計或核密度估計(KDE)。
公式
分箱統計法:
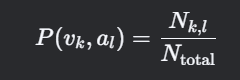
- N_k,l:速度落在第k個區間且加速度落在第l個區間的樣本數。
- 區間劃分:速度按10 km/h間隔分箱,加速度按0.1 m/s2間隔分箱。
核密度估計(KDE):
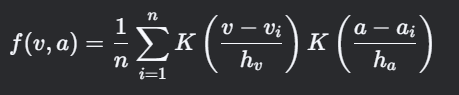
- K:高斯核函數
- h_v, h_a:帶寬參數(通過Silverman法則優化)。
關鍵計算流程總結
- 數據預處理:
- 剔除異常值,插值補全缺失數據。
- 對速度序列進行平滑濾波(如移動平均)。
- 基礎參數計算:
- 平均速度、極值、標準差。
- 加速度計算:
- 差分法或濾波法生成加速度序列。
- 減速段提取:
- 滑動窗口識別連續負加速度區間。
- 聯合分布建模:
- 分箱統計或核密度估計生成二維分布矩陣。
示例代碼(Python)
import numpy as np
import pandas as pd
from scipy import stats# 1. 加載速度時間序列數據(示例)
time = np.arange(0, 3600, 1) # 1小時數據,1Hz采樣
speed = np.random.uniform(0, 120, 3600) # 模擬速度數據(0-120 km/h)# 2. 計算平均速度(排除停車時間)
moving_mask = speed > 0 # 排除速度為0的時間
avg_speed = np.mean(speed[moving_mask])# 3. 計算加速度(中心差分法)
dt = 1 # 1秒間隔
accel = np.gradient(speed[moving_mask], dt)# 4. 減速段平均減速度
decel_mask = accel < 0
mean_decel = np.mean(np.abs(accel[decel_mask])) if np.any(decel_mask) else 0# 5. 速度-加速度聯合分布(分箱統計)
v_bins = np.arange(0, 130, 10) # 速度分箱(0-120 km/h,10 km/h間隔)
a_bins = np.arange(-3, 3.1, 0.1) # 加速度分箱(-3~3 m/s2,0.1間隔)
joint_dist, v_edges, a_edges = np.histogram2d(speed[moving_mask], accel, bins=[v_bins, a_bins], density=True
)
應用場景
- 能耗建模:聯合分布用于構建車輛能耗MAP圖。
- 駕駛風格分析:標準差參數量化駕駛激進程度。
- 測試工況設計:基于統計特征復現實路駕駛循環(如WLTC、NEDC)。
通過上述方法,可全面量化汽車行駛工況的動力學特征,支撐新能源汽車的算法開發與性能驗證。

)
)
















