? ? ? ?大家好,我是帶我去滑雪!
? ? ? ?肺炎是全球范圍內致死率較高的疾病之一,尤其是在老年人、免疫系統較弱的患者群體中,更容易引發嚴重并發癥。傳統上,肺炎的診斷依賴于醫生的臨床經驗以及影像學檢查,尤其是X光片,它在肺炎的早期篩查和診斷中扮演了至關重要的角色。然而,X光片的讀取不僅需要專業的放射科醫生,而且受到經驗和疲勞等因素的影響,導致診斷結果的準確性存在一定的偏差。近年來,人工智能(AI)技術,尤其是深度學習在醫學影像領域取得了顯著進展。通過深度學習模型,計算機能夠高效地從大量影像數據中學習到復雜的模式,并實現對疾病的自動識別和分類,極大地提高了診斷的速度和準確性。遷移學習作為深度學習的一種重要方法,能夠通過在已有的、大規模的醫學圖像數據上預訓練模型,并遷移到肺炎X光片的分類任務上,減少對大量標注數據的需求,這對資源有限、標注困難的醫學領域尤為重要。
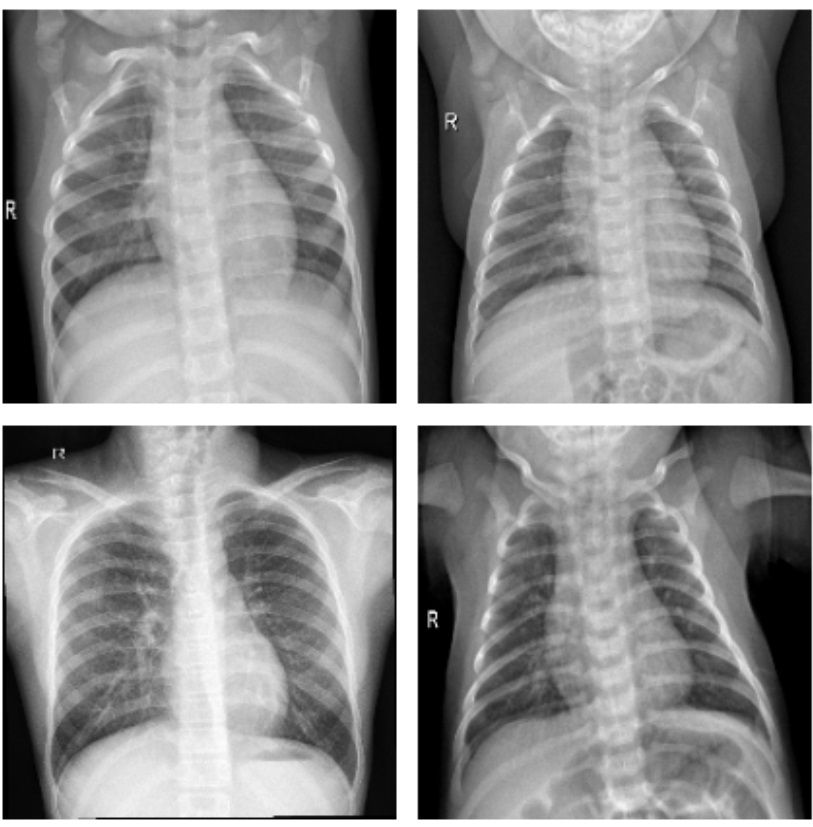
? ? ? ? 基于遷移學習的肺炎X光片診斷分類研究,不僅可以緩解醫生在實際工作中因繁重工作負擔導致的診斷錯誤問題,還能夠通過高效、準確的自動化診斷方法,在早期篩查中提供幫助,尤其是在偏遠地區或醫療資源匱乏的環境中,為患者提供及時的診療建議,極大地促進了醫療資源的合理分配。此外,該研究的成功實現還可以為其他疾病的X光片圖像診斷提供借鑒,推動人工智能技術在醫學領域的廣泛應用。下面開始代碼實戰。
目錄
(1)導入相關模塊
(2)構建數據集
(3)加載訓練的網絡
(4)調整模型
(5)設置測試集加載參數
(1)導入相關模塊
import os
from PIL import Image
from glob import globimport torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoaderfrom torchvision import transforms
from torchvision.models import resnet50, ResNet50_Weights
(2)構建數據集
class ChestXRayDataset(Dataset):def __init__(self,dataset_dir,transform=None) -> None:self.dataset_dir = dataset_dirself.transform = transform# 獲取文件夾下所有圖片路徑self.dataset_images = glob(f"{self.dataset_dir}/**/*.jpeg", recursive=True)# 獲取數據集大小def __len__(self):return len(self.dataset_images)# 讀取圖像,獲取類別def __getitem__(self, idx):image_path = self.dataset_images[idx]image_name = os.path.basename(image_path)image = Image.open(image_path)if "NORMAL" in image_name:category = 0else:category = 1if self.transform:image = self.transform(image)return image, category
(3)加載訓練的網絡
def prepare_model():# 加載預訓練的模型resnet50_weight = ResNet50_Weights.DEFAULTresnet50_mdl = resnet50(weights=resnet50_weight)# 替換模型最后的全連接層num_ftrs = resnet50_mdl.fc.in_featuresresnet50_mdl.fc = nn.Linear(num_ftrs, 2)return resnet50_mdldef train_model():# 確定使用CPU還是GPUif torch.cuda.is_available():device = "cuda:0"else:device = "cpu"# 加載模型model = prepare_model()model = model.to(device)model.train()# 設置loss函數和optimizercriterion = nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)# 設置訓練集數據加載相關變量batch_size = 32chest_xray = r"E:\工作\碩士\博客\博客99-深度學習醫學特征提取\deeplea test\deeplea test\archive\chest_xray"train_dataset_dir = os.path.join(chest_xray, "train")train_transforms = transforms.Compose([transforms.ToTensor(),transforms.Lambda(lambda x: x.repeat(3, 1, 1) if x.size(0) == 1 else x),transforms.Resize((224, 224)),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])train_dataset = ChestXRayDataset(train_dataset_dir, train_transforms)train_dataloader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True)(4)調整模型
for epoch in range(5):print_batch = 50running_loss = 0running_corrects = 0for i, data in enumerate(train_dataloader):inputs, labels = datainputs = inputs.to(device)labels = labels.to(device)optimizer.zero_grad()outputs = model(inputs)_, preds = torch.max(outputs, 1)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += (loss.item() * batch_size)running_corrects += torch.sum(preds == labels.data)if i % print_batch == (print_batch - 1): # print every 100 mini-batchesaccuracy = running_corrects / (print_batch * batch_size)print(f'Epoch: {epoch + 1}, Batch: {i + 1:5d} Running Loss: {running_loss / 50:.3f} Accuracy: {accuracy:.3f}')running_loss = 0.0running_corrects = 0checkpoint_name = f"epoch_{epoch}.pth"torch.save(model.state_dict(), checkpoint_name)def test_model():if torch.cuda.is_available():device = "cuda:0"else:device = "cpu"# 加載模型checkpoint_name = "epoch_4.pth"model = prepare_model()model.load_state_dict(torch.load(checkpoint_name, map_location=device))model = model.to(device)model.eval()
(5)設置測試集加載參數
batch_size = 32chest_xray = r"E:\工作\碩士\博客\博客99-深度學習醫學特征提取\deeplea test\deeplea test\archive\chest_xray"test_dataset_dir = os.path.join(chest_xray, "test")test_transforms = transforms.Compose([transforms.ToTensor(),transforms.Lambda(lambda x: x.repeat(3, 1, 1) if x.size(0) == 1 else x),transforms.Resize((224, 224)),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])test_dataset = ChestXRayDataset(test_dataset_dir, test_transforms)test_dataloader = DataLoader(test_dataset,batch_size=batch_size,shuffle=False)# 在測試集測試模型with torch.no_grad():preds_list = []labels_list = []for i, data in enumerate(test_dataloader):inputs, labels = datainputs = inputs.to(device)labels = labels.to(device)outputs = model(inputs)_, preds = torch.max(outputs, 1)preds_list.append(preds)labels_list.append(labels)preds = torch.cat(preds_list)labels = torch.cat(labels_list)# 計算評價指標corrects_num = torch.sum(preds == labels.data)accuracy = corrects_num / labels.shape[0]# 輸出評價指標print(f"Accuracy on test dataset: {accuracy:.2%}")if __name__ == "__main__":train_model()test_model()
輸出結果:

更多優質內容持續發布中,請移步主頁查看。
?若有問題可郵箱聯系:1736732074@qq.com?
博主的WeChat:TCB1736732074
? ?點贊+關注,下次不迷路!
?







![[數據結構]哈希表](http://pic.xiahunao.cn/[數據結構]哈希表)





)





